






皆さん、こんにちは!
FIXER R&D Divisionの山本です。
今日は5月29〜30日に開催された、皆さんおなじみのMicrosoft技術者向けカンファレンス《de:code 2019》で講演した内容から、少し内容を整理して前・中・後編に分けてお伝えする、中編です!(講演スライドはこちら)
【お知らせ】ハンズオンセミナー開催!(浜松町、参加無料)ここで解説する内容を実際に体験して習得してもらうため、6月21日(金)に東京・浜松町でハンズオンセミナーを開催します。下記のURLからぜひ参加お申し込みください。遠方で参加いただけない方のためにオンラインでのライブ配信も予定しています。
https://fixer-lab.connpass.com/event/133303/
前編ではモデル開発の自動化を解説しました。ここからは“MLOps”の実現方法の解説です。少し長くなりますので、中編と後編に分けて解説します。
ML Opsの実現
中編は、GitHubに分類器・分析モデルを格納しての、MLOps環境の構築です。 作成した分類器・分析モデル(機械学習のソースコード)をGitHubにPushすると、それをトリガーにしてAzrure DevOpsが起動し、そのソースコードの内容を実行します。
ソースコードには、トレーニング(学習)を行う実行環境の作成やトレーニングの実施、学習済みモデルを格納したコンテナイメージの作成、デプロイといったことを実行するコードが含まれています。
今回は前編の環境を引き続き利用しますので、前編の内容を参考にAzure Notebooksがクローンされている前提で解説を進めます。
Azure NotebooksからGitHubへPush
まずはソースコードをGitHubにPushするところからです。
クローンしたAzure Notebooksに作成済みのソースコードがありますので、それをGitHubにPushしましょう。Azure Notebookの画面中央あたりに、クレジットカードのような見た目の、ターミナルを表すアイコンがあるのでクリックします。
するとターミナル画面が開きます。このターミナルは、Notebookの実行環境にアクセスするターミナルで、PythonやAzureML SDK、Gitコマンド等は最初からセットアップされています。ここでGitコマンドを利用して、ご自身のGitHubアカウントで適宜リポジトリを作成し、そこにPushしてみてください。
Azure DevOpsの設定
GitコマンドからGitHubに手動でPushすることができたら、次はAzure DevOpsとの連携です。Azure DevOpsを設定し、指定したリポジトリへのPushをトリガーにしてAzure DevOpsのパイプラインが起動されるように設定します。
パイプラインというのは、CI/CDで実行される一連の操作、ワークフローのことです。Azure DevOpsにはビルドパイプラインとデプロイパイプラインという2種類のパイプラインを定義することができるようになっています。
デプロイパイプラインでは、ソースをリポジトリから取得して関連モジュールなどをダウンロード ⇒ ビルド(や機械学習のトレーニング)を実行 ⇒ ビルド/学習済みモジュールやコンテナイメージなどの成果物をACR(Azure Container Registory)のレジストリに格納します。※ACR以外にもAzure DevOpsのArtifactやAzure ML Service内に格納することもできます。
一方、デプロイパイプラインでは、ArtifactやACRなどのレジストリからコンテナなどの実行モジュールを取得 ⇒ WebAppsやAKS(Azure Kubernetes Service)などの実行環境にデプロイ、といったことを行います。
それでは、Azure DevOpsで[New pipeline]から新しいビルドパイプラインを作成します。
https://azure.microsoft.com/ja-jp/services/devops/
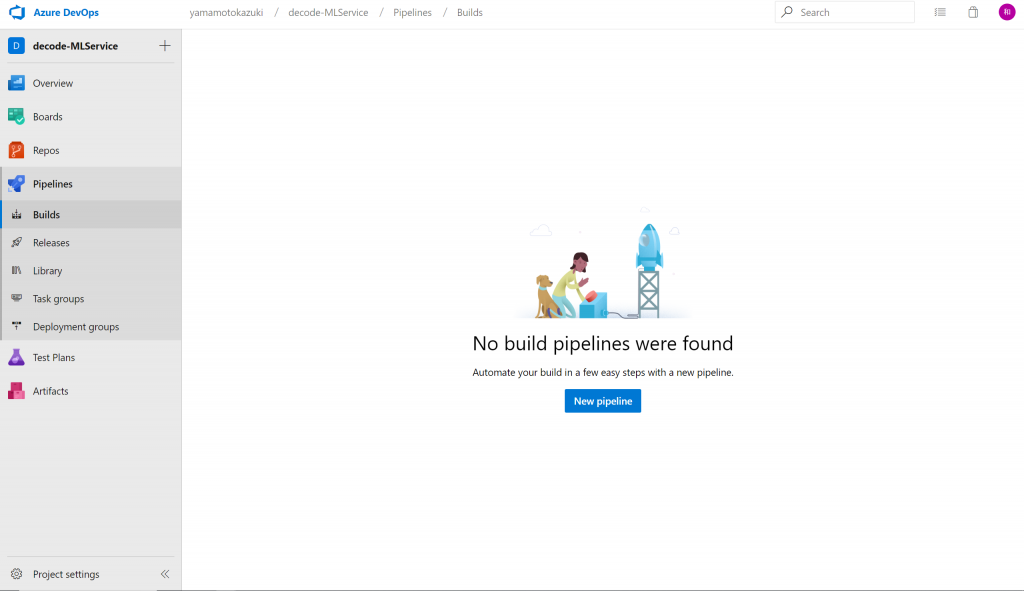
Select a sourceでGitHubを選択し、対象リポジトリとブランチを選びます。これで、GitHubへのソースのPushをトリガーに、パイプラインを起動できるようになります。
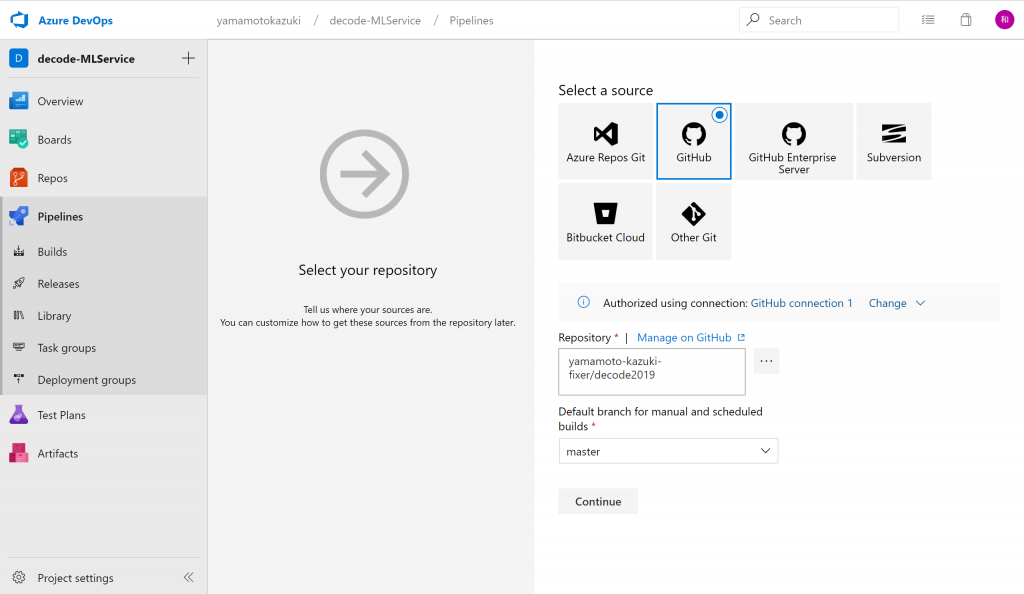
次に、テンプレートからパイプラインの雛形を選択できますが、今回は利用せずに独自のパイプラインを作りますので、Empty jobを選択します。
続いて、実行するパイプラインの各ステップを順次設定していきます。GUIベースで追加できる設定しやすい「パーツ」が揃っていますので、画面中央の「 Agent job 1」の横にある「+」をクリックし、追加していきます。
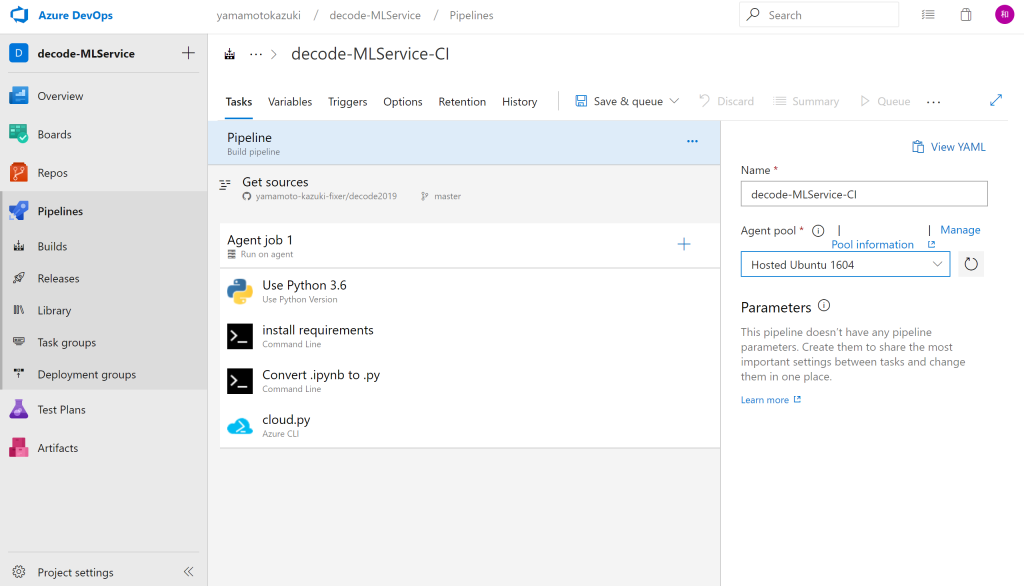
まず、Azure Notebooks上で作成した(クローンしてきた)Pythonスクリプトを実行させるための準備を行います。
利用するPythonのバージョンを指定したいので 「Use Python Version」というパーツを使います。「Version spec」という項目で「3.6」を選択します。
次に「Command Line」というパーツを追加し、下記のコマンドを書きます。
pip installで MLのスクリプト(Pythonスクリプト)の実行に必要なモジュールをまとめてインストールしています。インストールする内容はAzure Notebooksの中でrequirements.txtに記述しておきます。(クローンしたNotebookの中のrequirements.txtには、既に必要な内容が記載済みですので、そのまま利用できます。)
pip install --upgrade -r requirements.txt「Command Line」をもう1つ追加し、次のコマンドを書きます。このコマンドでは、Azure Notebooksで作成した.ipynbファイルを.pyファイルの形式に変換します。
jupyter nbconvert --to python cloud.ipynbここまででMLの処理を記述したPythonスクリプトを実行する準備ができたので、実際に実行します。 「Azure CLI」というパーツを追加し、下記のコマンドを記載します。
python cloud.pyこれでAzure DevOpsの準備は完了しました。Azure Notebooks で作成したMLのスクリプトを GitHub に Push すると、そのスクリプトが実行されます。Azure Notebooks 内で MLのスクリプトを見た方はお気づきかもしれませんが、MLスクリプト自体はAzure DevOpsのインスタンス内で実行される一方で、MLのトレーニング(学習)はAzure DevOpsのインスタンスではなくAzure ML Serviceで行われます。「cloud.py」のコードの中でAzure ML Service内にVMを作成しており、それを利用します。
Azure ML Serviceとの接続を指定している部分が下記のコードです。このコードで指定したAzure ML Serviceに接続し、もしその環境にAzure ML Serviceが存在しない場合は、新規に作成します。
from azureml.core.authentication import InteractiveLoginAuthentication
print("SDK Version:", azureml.core.VERSION)
#with open("aml_config/config.json") as f:
# config = json.load(f)
# 自身のAzureサブスクリプションIDやAzure ML Serviceがある(もしくは作りたい)場所を指定
workspace_name = config["workspace_name"]
resource_group = config["resource_group"]
subscription_id = config["subscription_id"]
location = config["location"]
cli_auth = InteractiveLoginAuthentication()
try:
ws = Workspace.get(
name=workspace_name,
subscription_id=subscription_id,
resource_group=resource_group,
auth=cli_auth
)
except:
# this call might take a minute or two.
print("Creating new workspace...")
ws = Workspace.create(
name=workspace_name,
subscription_id=subscription_id,
resource_group=resource_group,
# create_resource_group=True,
location=location,
auth=cli_auth
)
# print Workspace details
print("nWorkspace configuration succeeded. You are all set!")
print("Using workspace below;")
print(ws.name, ws.resource_group, ws.location, ws.subscription_id, sep="n")以下の部分ではAzure ML ServiceにVMを作成しています。VMの種類・サイズはStandard_NC6というものを指定しており、これはGPUを搭載していて、並列計算を行うMLのトレーニングに適しています。
cluster = 'decode2019-MLOps'
try:
compute = ComputeTarget(workspace=ws, name=cluster)
print('Found existing compute target "{}"'.format(cluster))
except ComputeTargetException:
print('Creating new compute target "{}"...'.format(cluster))
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6', min_nodes=0, max_nodes=6)
compute = ComputeTarget.create(ws, cluster, compute_config)
compute.wait_for_completion(show_output=True)その後、作成したVMでトレーニングを実行し、学習が終わったモデル Azure ML Serviceに登録 ⇒ コンテナイメージの作成、ACI(Azure Container Instances)へのデプロイを行います。
Azure DevOpsで処理実行が完了すると、作成されてコンテナが動いているACIをAzureポータルで確認できます。
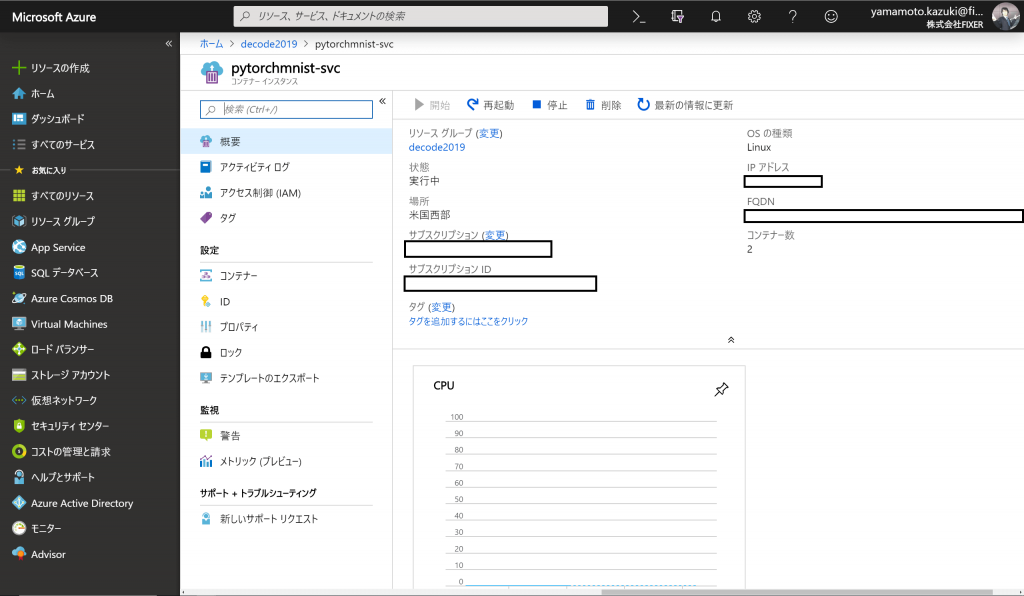
作成されたコンテナは、ACI上でAPIを提供しているので、Postmanなどでコールすると動作を確認できます。
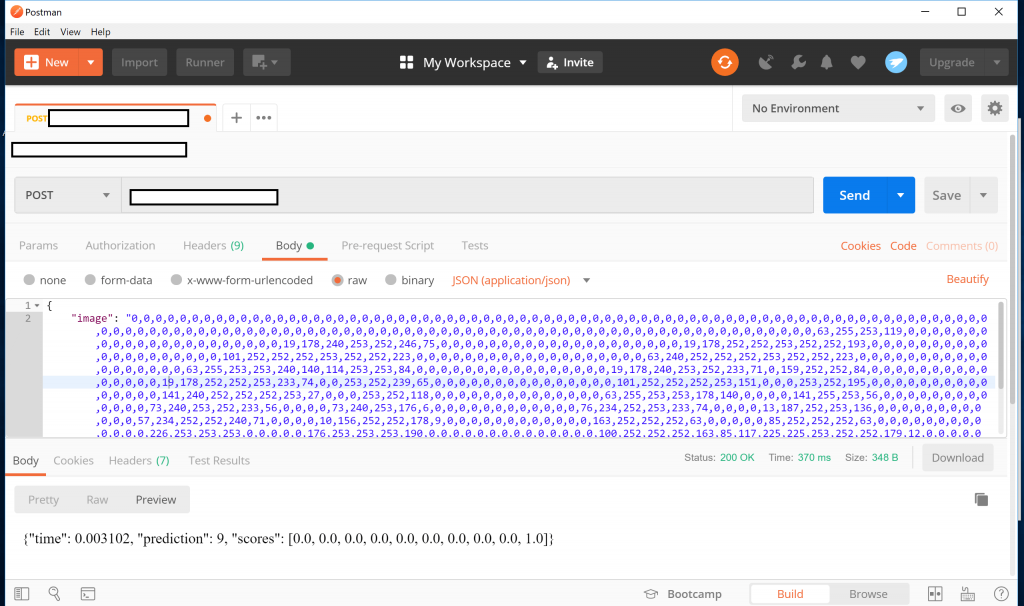
これでGitHubを介して機械学習のトレーニング、コンテナ作成、デプロイまでを実現するML Opsパイプラインが実現できました。
今回はデプロイまでをビルドパイプラインで行ってしまっていますが、学習済みモデルの登録までをビルドパイプラインで行い、ACIやAKSへのデプロイをリリースパイプラインですることもできます。
後編では、モデルの学習と本番環境への反映(デプロイ)とを適切に分離し、より実用的・現実的する方法を解説します。お楽しみに!











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
