






皆さん、こんにちは!
FIXER R&D Division の山本です。
先日、当社のセミナールーム(東京・浜松町)で実施したML Opsハンズオンセミナーも大盛況でした。ご参加いただいた皆様、ありがとうございました。次回開催も計画中です。今回は参加できなかった方もメンバー登録してチェックしておいてもらえると嬉しいです。
https://fixer-lab.connpass.com/event/133303/
さて、だいぶ期間が空いてしまいましたがこのシリーズでは、5月29〜30日に開催された、皆さんおなじみのMicrosoft技術者向けカンファレンス《de:code 2019》で講演した内容から、前・中・後編に分け、少し内容を整理してお伝えしております。(講演スライドはこちら)
前編ではモデル開発の自動化を解説(こちら)し、
中編ではGitHubとAzure DevOpsを連携させてML Opsの実現方法を解説(こちら) しました。今回の後編とあわせてご参照ください。
モデルが登録されたことをトリガーに動作するML Opsの構築
中編ではGitHubへPushされたことをトリガーに、Azure DevOps内でコードを実行しML Opsを実現していました。
この方法では、Azure Notebooksなどで精度検証しながらモデル作成を行ったのにもかかわらず、Azure DevOpsの処理中で改めてもう一度モデル作成が行われ、無駄なリソース利用が発生してしまいます。また、特にAutoMLを利用してトレーニングとモデル作成の自動化を行っていると、Azure Notebooksで作成したモデルとAzure DevOpsの処理で作成されたモデルが異なってしまうことがあります。
この後編では、こういった問題を回避するため、Azure DevOpsの処理中ではモデル作成を行わず、Azure Notebooksなどで作成したモデルをAzure Machine Learning Serviceに登録し、登録したことをトリガーにAzure DevOpsを起動、登録されたモデルのコンテナイメージ化やデプロイを行う方式を実現します。
Azure DevOpsの設定
Azure Machine Learning Service にモデルが登録されたことをトリガーにAzure DevOpsを動かすには、Azure ML Serviceに接続するモジュール(コネクタ)をAzure DevOpsにインストールする必要があります。下記のリンクの[Get it Free]からインストールしてください。
https://marketplace.visualstudio.com/items?itemName=ms-air-aiagility.vss-services-azureml
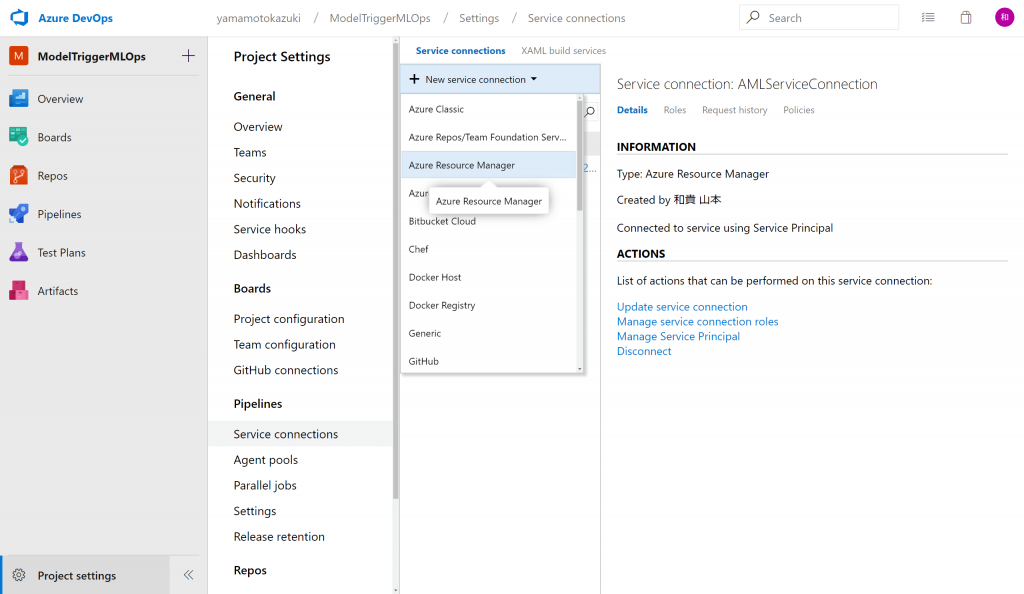
Azure DevOpsで、Machine Learningと接続させたいプロジェクトの[Project setting]を開き、[Service connections]を選択、[New service connection]をクリックして表示されるプルダウンの[Azure Resource Manager]をクリックします。
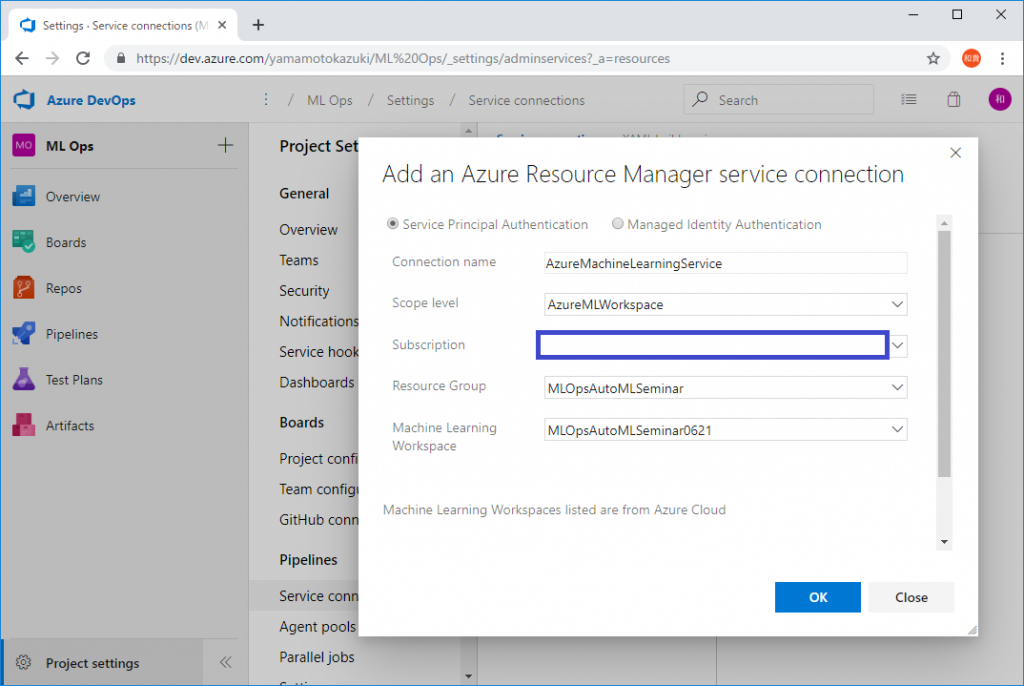
設定画面が表示されるので、[Scope level]をAzureMLWorkspaceにセットし、接続したいAzure Machine Learning Serviceの情報を設定して[OK]をクリックします。
これでモデルの登録をトリガーにする準備ができました。
次に、実行させるPythonのソースコード一式を、Azure DevOpsのソース管理ツールであるAzure Reposに保存します。(Azure ReposでなくGitHubを使うこともできますが、今回は構成をシンプルにするため、簡易的にAzure Reposを使います。)
[Repos]をクリックして[Files]を選択、画面下部の[Initialize]をクリックして、まずはソースコードを管理する環境を作成します。
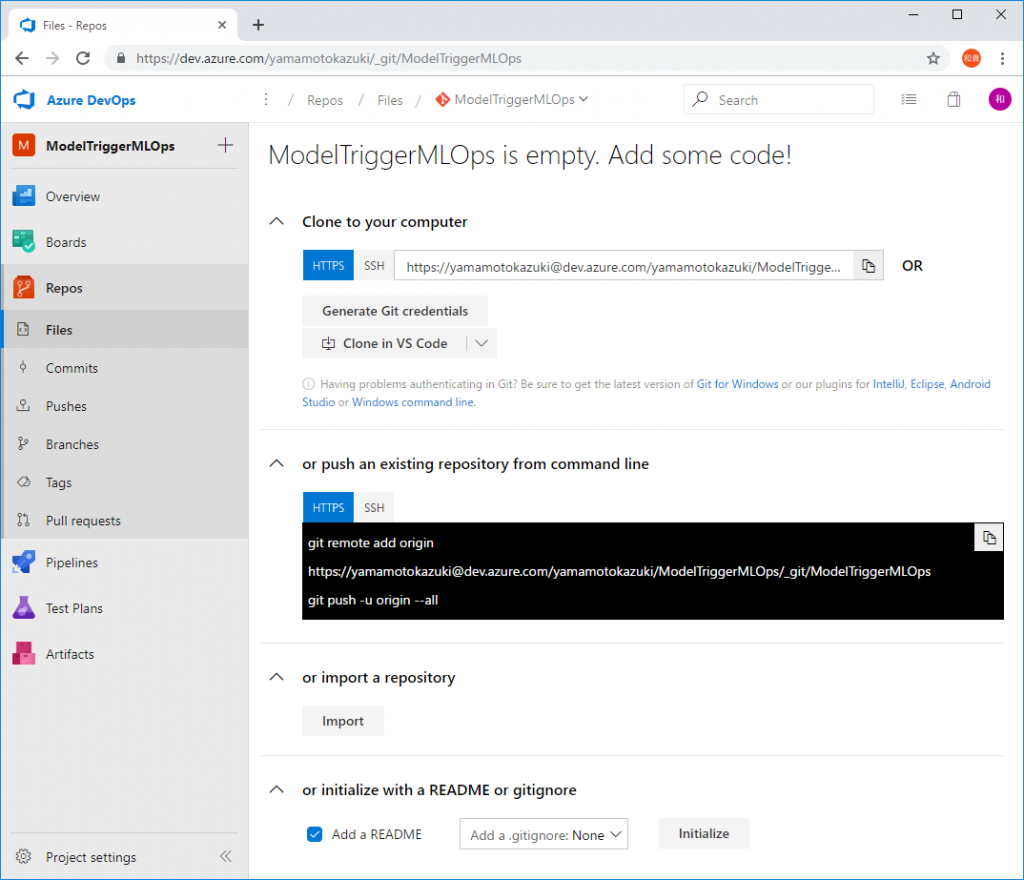
[New]をクリックしてファイルを追加します。
追加するファイルは以下の4つです。
#!/bin/bash
python --version
pip install azure-cli==2.0.46
pip install --upgrade azureml-sdk[cli]# Conda environment specification. The dependencies defined in this file will
# be automatically provisioned for runs with userManagedDependencies=False.
# Details about the Conda environment file format:
# https://conda.io/docs/user-guide/tasks/manage-environments.html#create-env-file-manually
name: project_environment
dependencies:
# The python interpreter version.
# Currently Azure ML only supports 3.5.2 and later.
- python=3.6.2
- pip:
- azureml-sdk[automl]==1.0.43
- numpy
- scikit-learn
- py-xgboost<=0.80
import pickle
import json
import azureml.train.automl
import pandas as pd
from sklearn.externals import joblib
from azureml.core.model import Model
def init():
global model
model_path = Model.get_model_path(model_name='UsedCarPriceForecast')
model = joblib.load(model_path)
def run(rawdata):
try:
data = json.loads(rawdata)['data']
df = pd.DataFrame(data,columns=["メーカー","燃料タイプ","ドアの数","車体形状","駆動輪","エンジンの場所","ホイールベース","長さ","幅","高さ","エンジンサイズ"])
result = model.predict(df)
except Exception as e:
result = str(e)
return json.dumps({"error": result})
return json.dumps({"result": result.tolist()})from azureml.core import Workspace
from azureml.core.authentication import InteractiveLoginAuthentication
from azureml.core.image import ContainerImage, Image
from azureml.core.model import Model
from azureml.core.webservice import Webservice, AciWebservice
# AzureML Serviceとの接続
cli_auth = InteractiveLoginAuthentication()
ws = Workspace.get(
name="【AzureML Service名】",
subscription_id="【サブスクリプションID】",
resource_group="【リソースグループ名】",
auth=cli_auth
)
service_name = 'usedcarprice'
# モデルの読み込み
model=Model(ws, '【対象のモデル名】')
# イメージの作成
image_config = ContainerImage.image_configuration(execution_script="scoring.py",
runtime="python",
conda_file="condaEnv.yml")
image = Image.create(ws, service_name, [model], image_config)
image.wait_for_creation(show_output=True)
# すでに同名のサービスがあるか確認
service_name = 'usedcarprice'
svcs = [svc for svc in Webservice.list(ws) if svc.name==service_name]
if len(svcs) == 1:
print('Deleting prior {} deployment'.format(service_name))
svcs[0].delete()
# イメージのデプロイ
aciconfig = AciWebservice.deploy_configuration(cpu_cores=1,
memory_gb=1,
description='Forecast used car prices')
service = Webservice.deploy_from_image(workspace=ws,
image=image,
name=service_name,
deployment_config=aciconfig)
service.wait_for_deployment(show_output=True)
print(service.scoring_uri)CreateImageAndDeployToACI.py はお使いの環境に合わせて数カ所書き換えてください。書き換えに必要な情報の一部は、Azureポータルで確認できます。
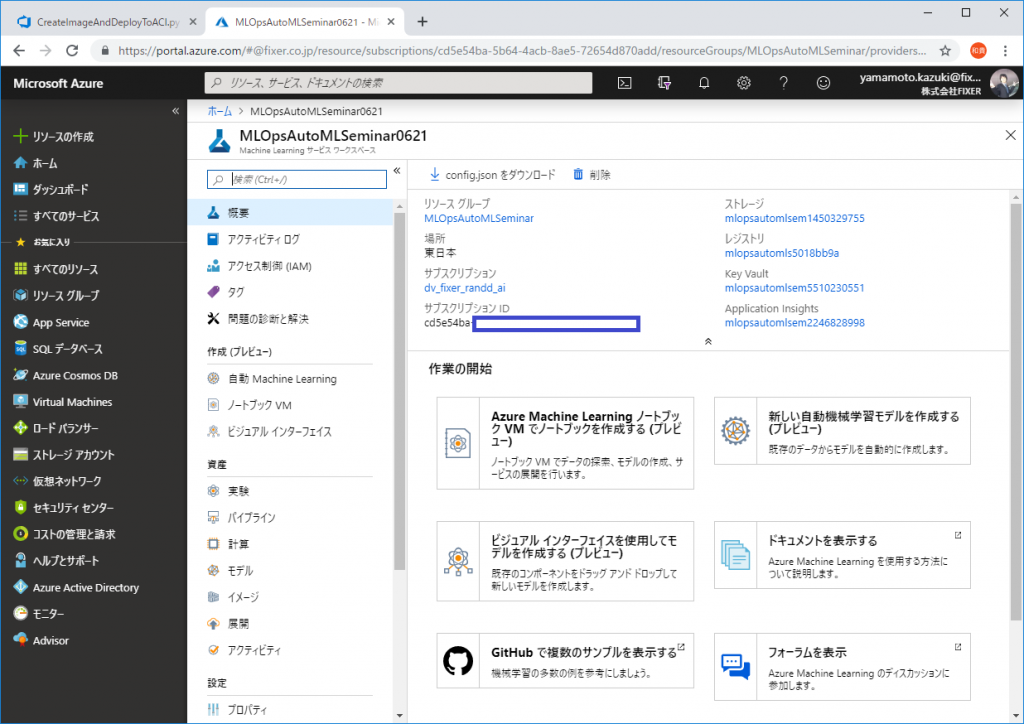
【AzureML Service名】
Azure ML Service作成時につけた名前(下の画像ではMLOpsAutoMLSeminar0621)
【サブスクリプションID】
サブスクリプションIDに書かれた文字列(下の画像ではcd5e54ba~~~)
【リソースグループ名】
リソースグループに書かれた文字列(下の画像では MLOpsAutoMLSeminar)
【対象のモデル名】
デプロイの対象となるモデルの名前(前編・中編のcloud.pyコードで作成したPyTorchMNISTなど)
次にモデル登録で動作するReleaseパイプラインを構築します。[New Pipeline]をクリックします。
モデルをリリース(デプロイ)するためのテンプレートが多数用意されていますが、今回は空の状態から作成するので[Empty job]を選択します。
[Add an artifact]をクリックして、[Source Type]にAzureML Model Artifactを選択し、トリガーの対象となるモデルを選択します。
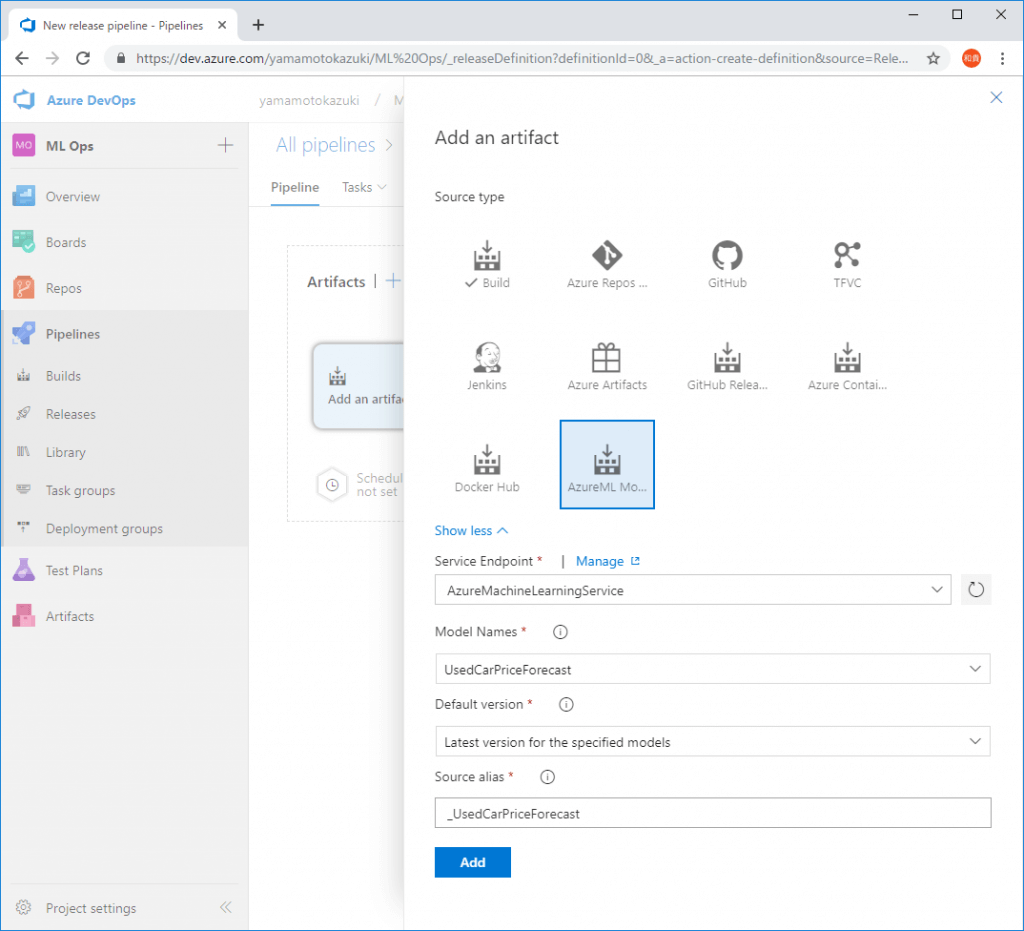
設定ができたらArtifactsの欄のイナズママークをクリックし、Continuous deployment triggerをEnableにすることで設定をオンにします。
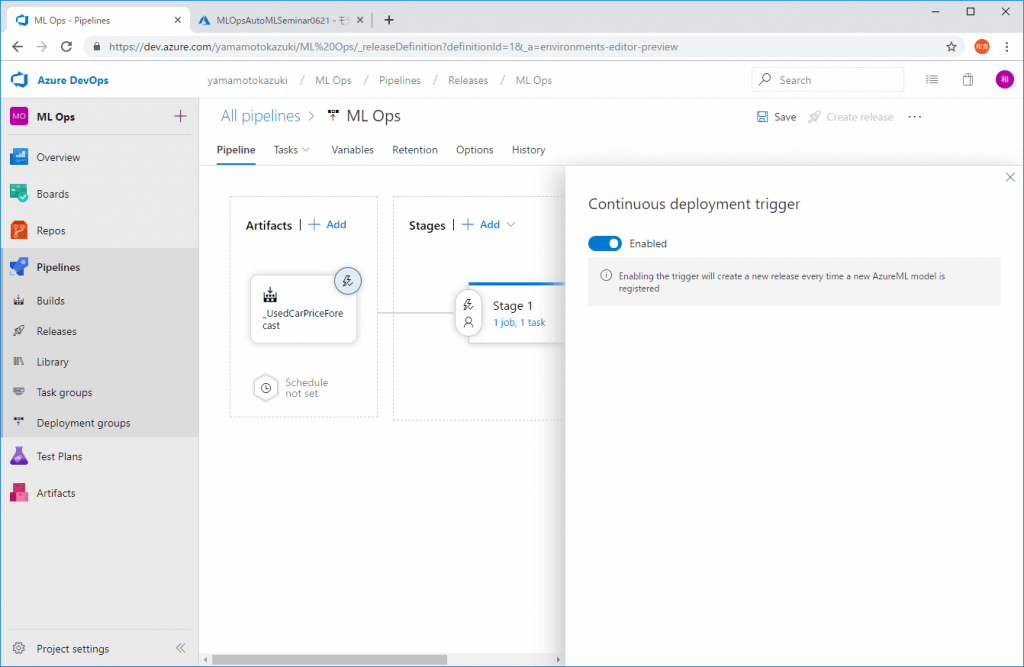
これでモデルが登録(更新)されたときに、このパイプラインが起動します。
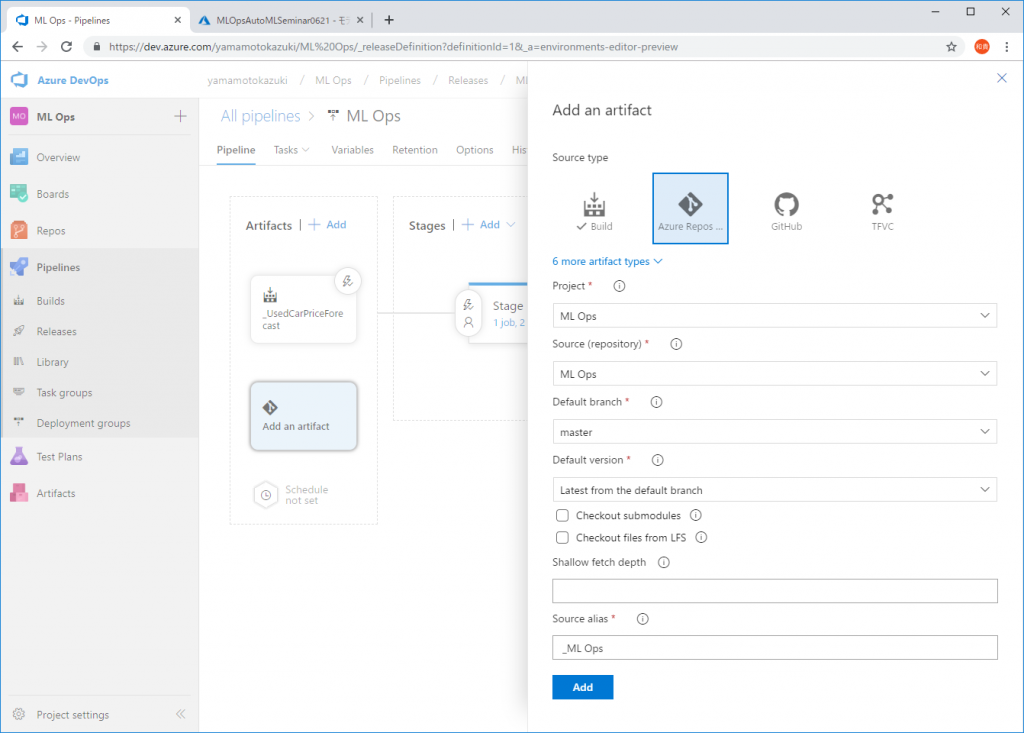
パイプラインが起動されたらAzure Reposに格納したコードを利用するよう、下図のようにArtifactを追加します。
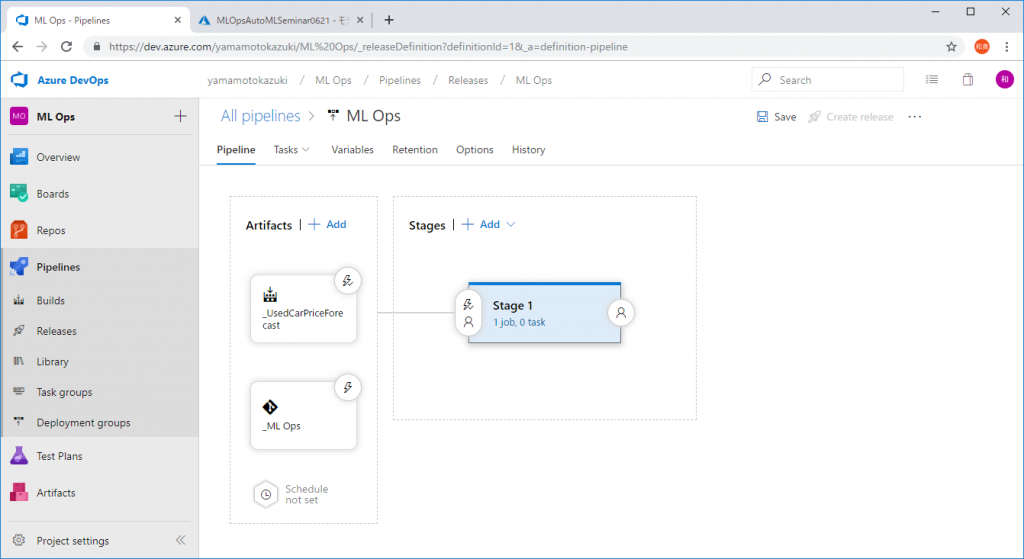
次に、パイプライン動作時に実行させるスクリプトなどを設定します。[Stage 1]をクリックします。
ここでパイプライン動作時に実行するフロー(パイプライン)を組み上げます。まずはパイプラインの実行環境を選択します。今回はUbuntuを使うので[Agent pool]をHosted Ubuntu 1604に変更します。
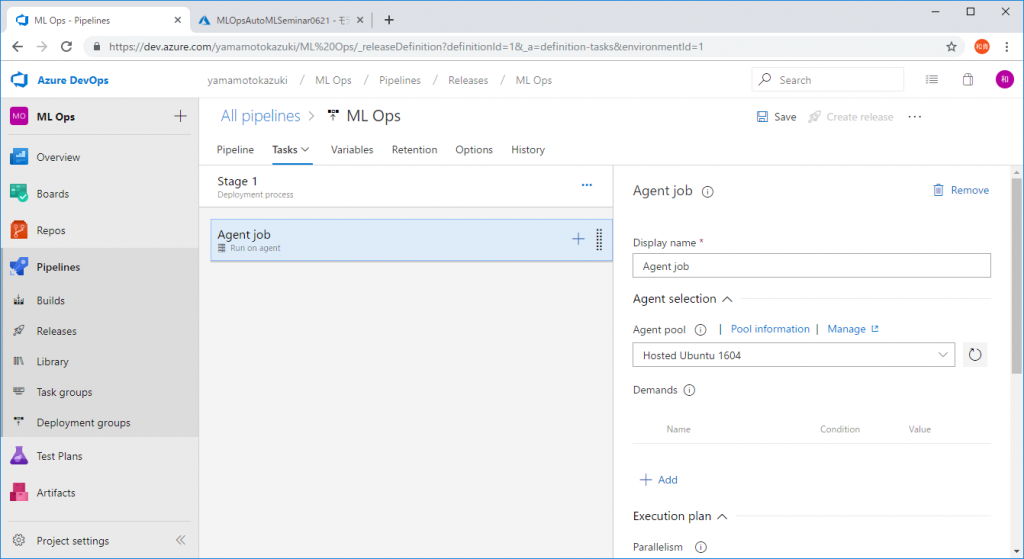
OSが選択されましたので、今度は実行環境の”中身”を整えていきます。Agent jobの隣の[+]ボタンをクリックして、[Use Python Version]というモジュールを追加します。利用するPythonのバーションを3.6に指定します。
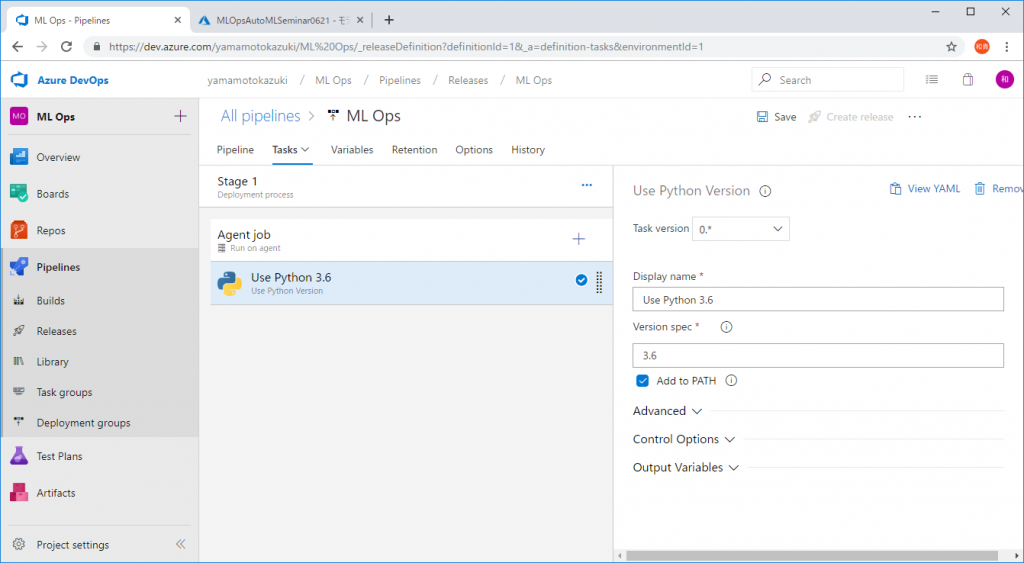
次にPythonコードの実行に必要なPythonモジュールをインストールする設定です。先程と同様に[+]ボタンをクリックして、今度は[Bash]モジュールを追加します。
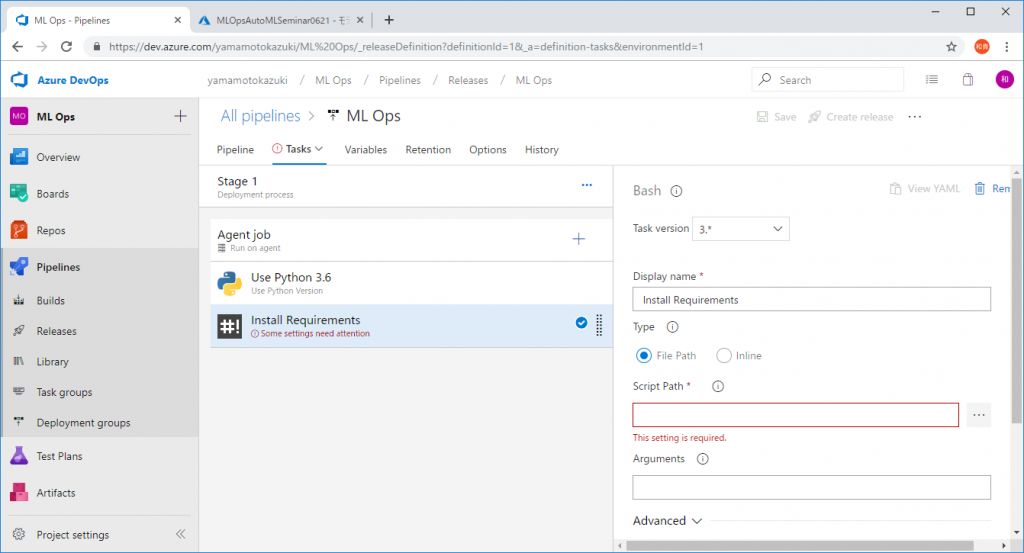
[Script Path]を入力するように求められるので、 先程Azure Reposに上げた[install_requirements.sh]を指定します。
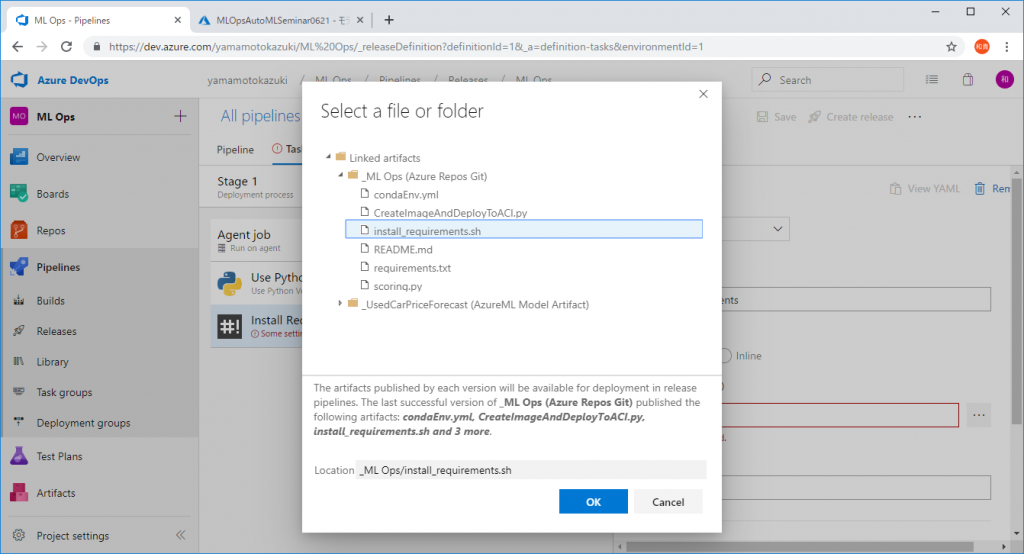
ここまでで、実行する環境が完成しました。
次は実行するコードの指定です。Azure ACIモジュールを追加します。
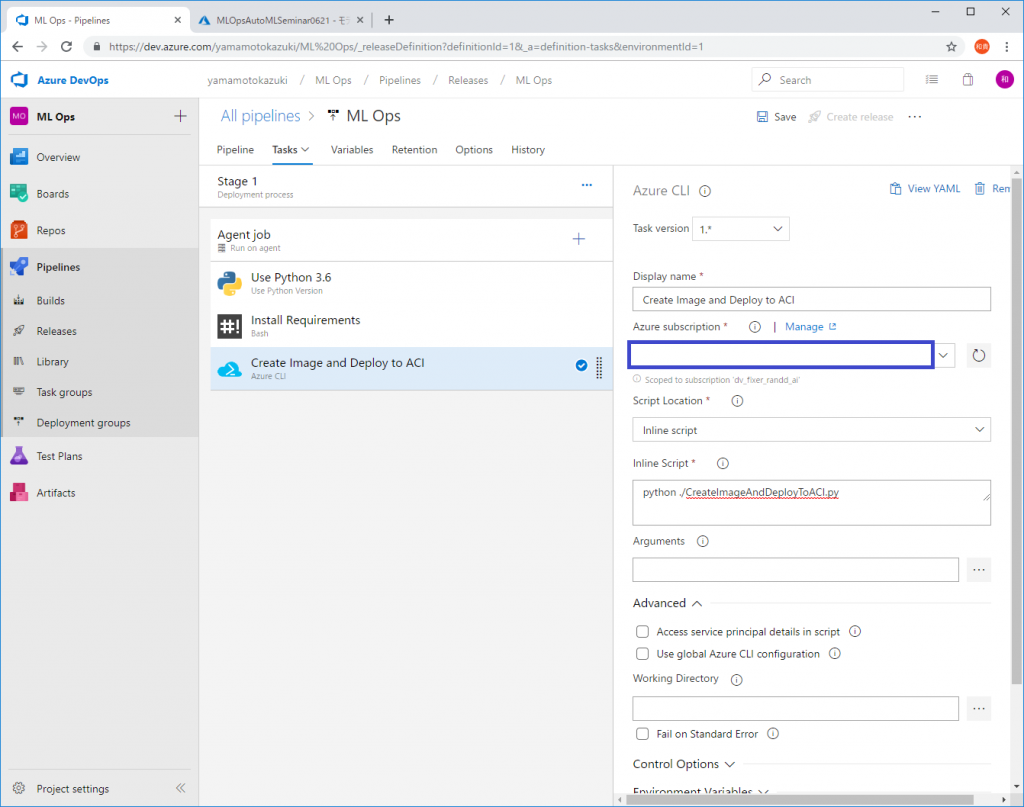
追加したACIモジュールの設定で[Inline Script]に下記の通り記述します。
python ./CreateImageAndDeployToACI.pyWorking Directoryの欄でスクリプトを実行するディレクトリを指定する必要がありますので、Azure Repos上の[_ML Ops]ディレクトリを設定します。
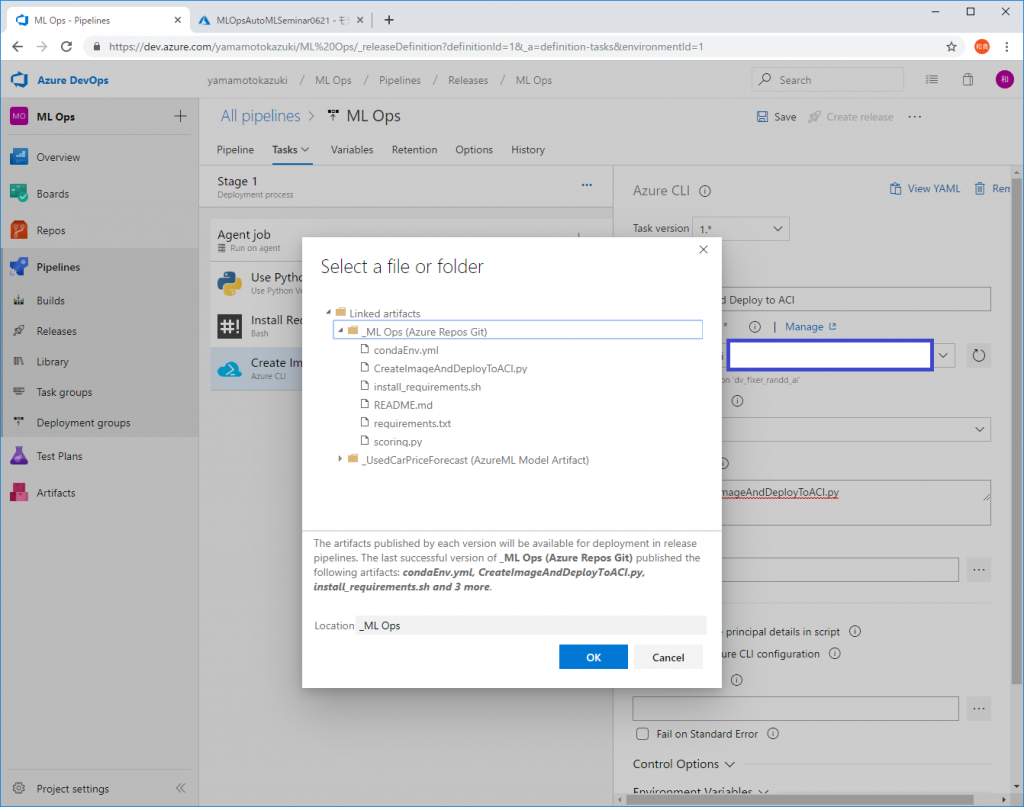
これでモデル登録をトリガーにしてコンテナイメージを作成、ACI(Azure Container Instances)にデプロイするパイプラインがML Opsで構築できました。
モデルを登録すると以下のようにパイプラインが実行されます。
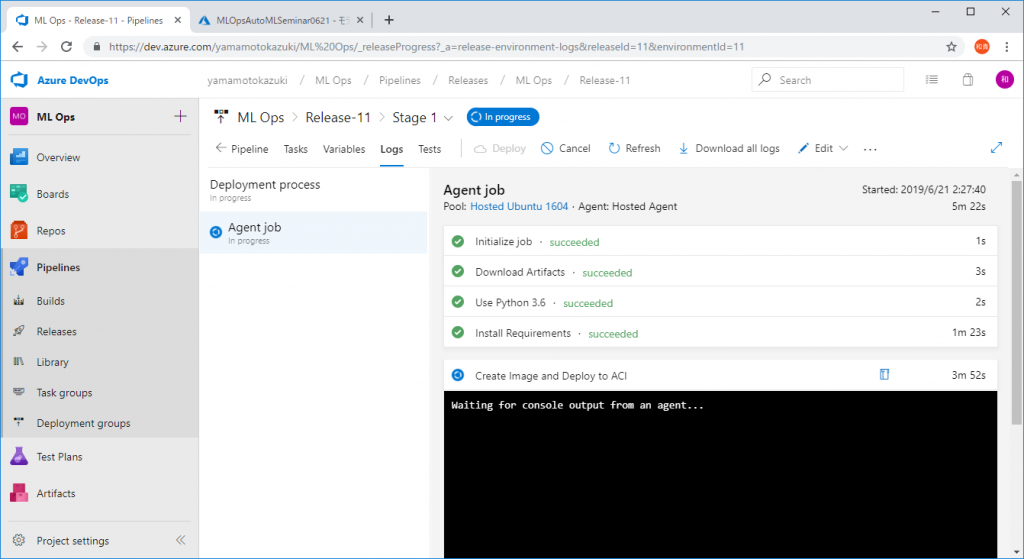
中編と同様に、完了するとチェックマークが付いていきます。
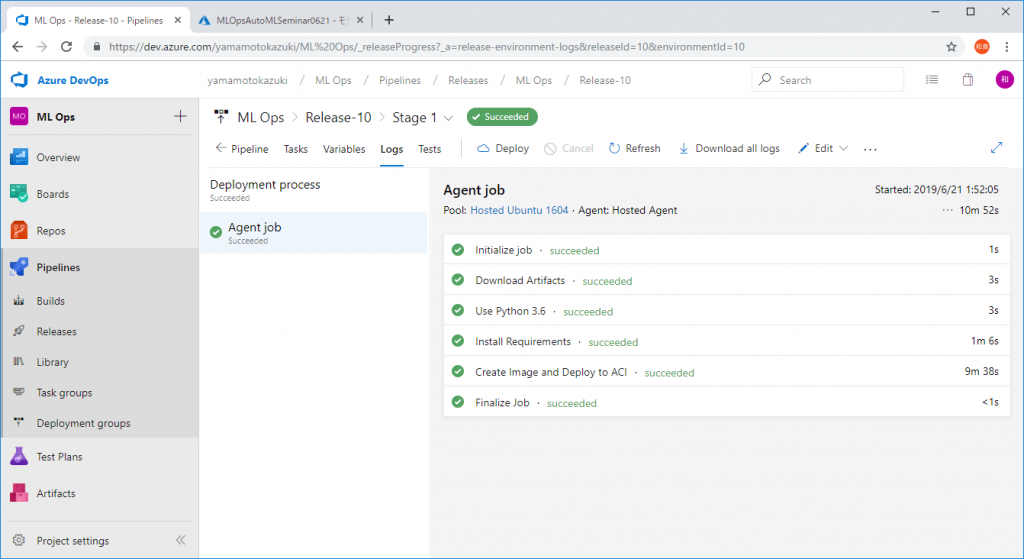
以上がML Opsの実装解説です。
これにさらに学習用データの蓄積機能や予測精度を監視する機能を追加していくと、モデルの精度低下を検出してモデル再作成を自動実行し、精度を自分で維持するML Opsの発展系・自立型MLシステムを作ることができます。
またの機会に、この内容についても詳しく解説したいと思いますので、ぜひ皆さんお楽しみにください。
お読みいただきありがとうございました。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
