






こんにちは。R&D Divisionの山本です。
みなさん、Blob Storage使ってますか?
どんな形式のデータでも格納でき、容量あたりの利用料も安いので私の大好きなサービスの一つです。
ただ、格納したデータを分析するのは中々大変です。
機械学習で予測モデル作成する場合、まず最初にどんなデータを使うのかを知るため、データの内容をじっくりと観察します。その際に、Blob Storageに格納されている多数のファイルをダウンロードしてExcelで開いてみたり、SQL Databaseを立ててデータをインポートしたりするのですが、これらの作業はあまり生産的とは言えません。
そこで、今回はAzure Databricksを利用して効率的にBlob Storageに格納されたデータを分析していきましょう。
Databricks利用の準備
今回は分析対象のサンプルデータとしてUCI Machine Learning Repositoryで提供されているWine Qualityデータを用います。下記URLからwinequality-white.csvをダウンロードしてください。
https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/
winequality-white.csvの各項目の意味合いは以下になります。
- fixed acidity: 酒石酸濃度
- volatile acidity: 酢酸濃度
- citric acid: クエン酸濃度
- residual sugar: 残留糖分濃度
- chlorides: 塩化ナトリウム濃度
- free sulfur dioxide: 遊離亜硫酸濃度
- total sulfur dioxide: 総亜硫酸濃度
- density: 密度
- pH: 水素イオン濃度
- sulphates: 硫酸カリウム濃度
- alcohol: アルコール度数
- quality: ワインの評価
次にAzureにリソースを作成していきます。今回作成するのはAzure DatabricksとStorage Accountの2つです。
まずはAzure Databricksを作成します。下記URLからAzure Portalへ移動し、リソースの作成をクリックします。
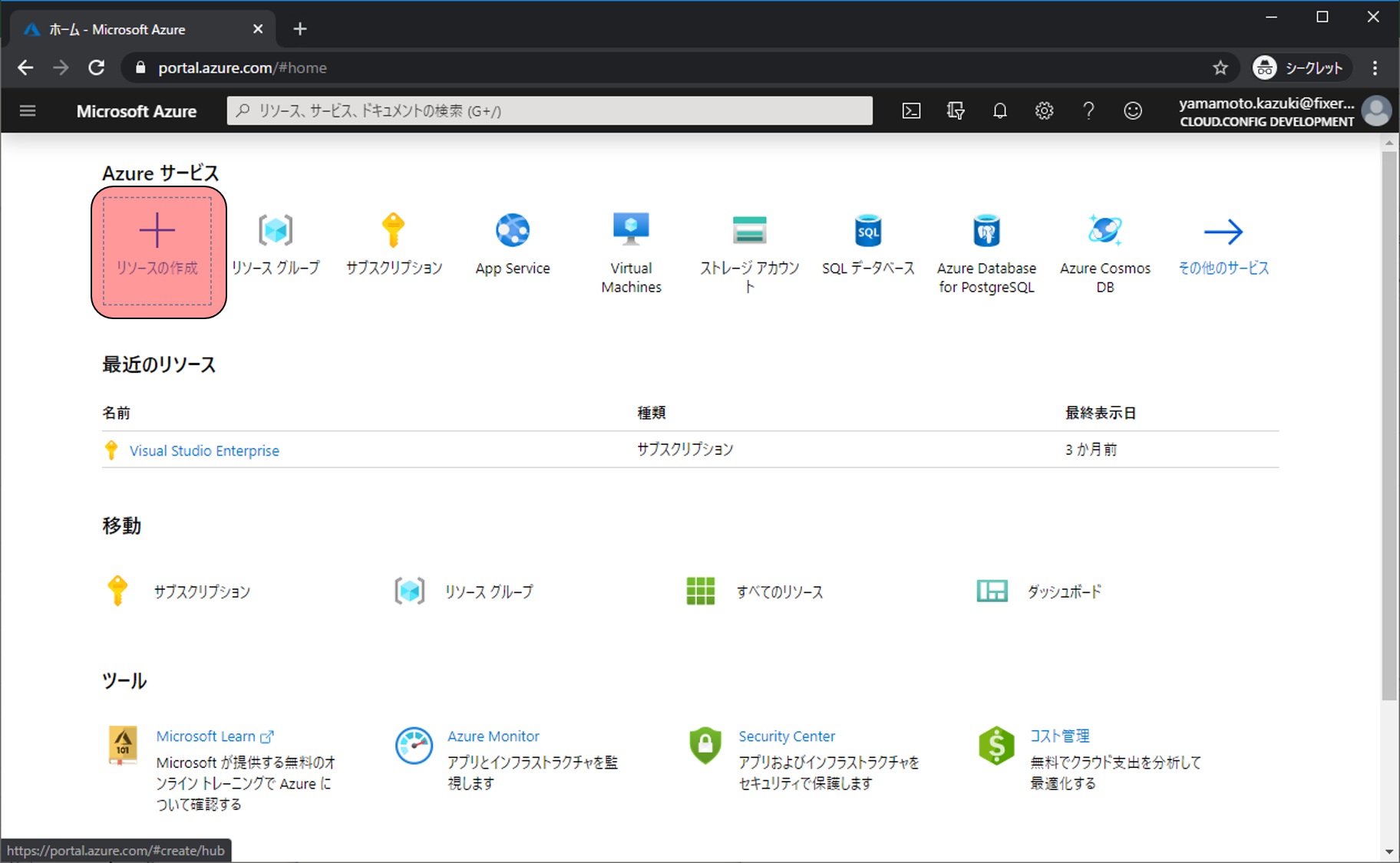
検索欄にAzure Databricksと入力します。
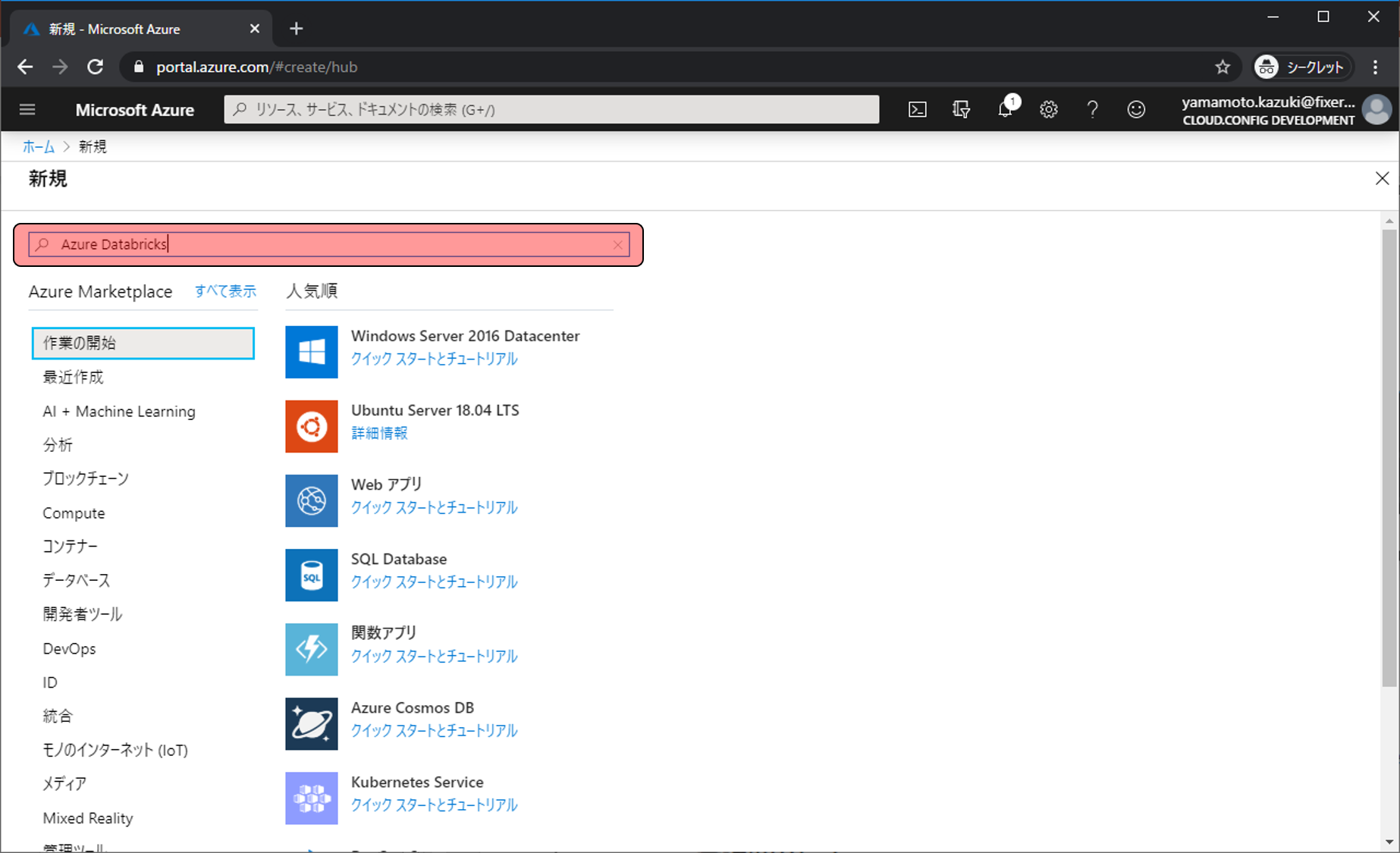
Azure Databricksの概要等が表示されます。作成をクリックします。
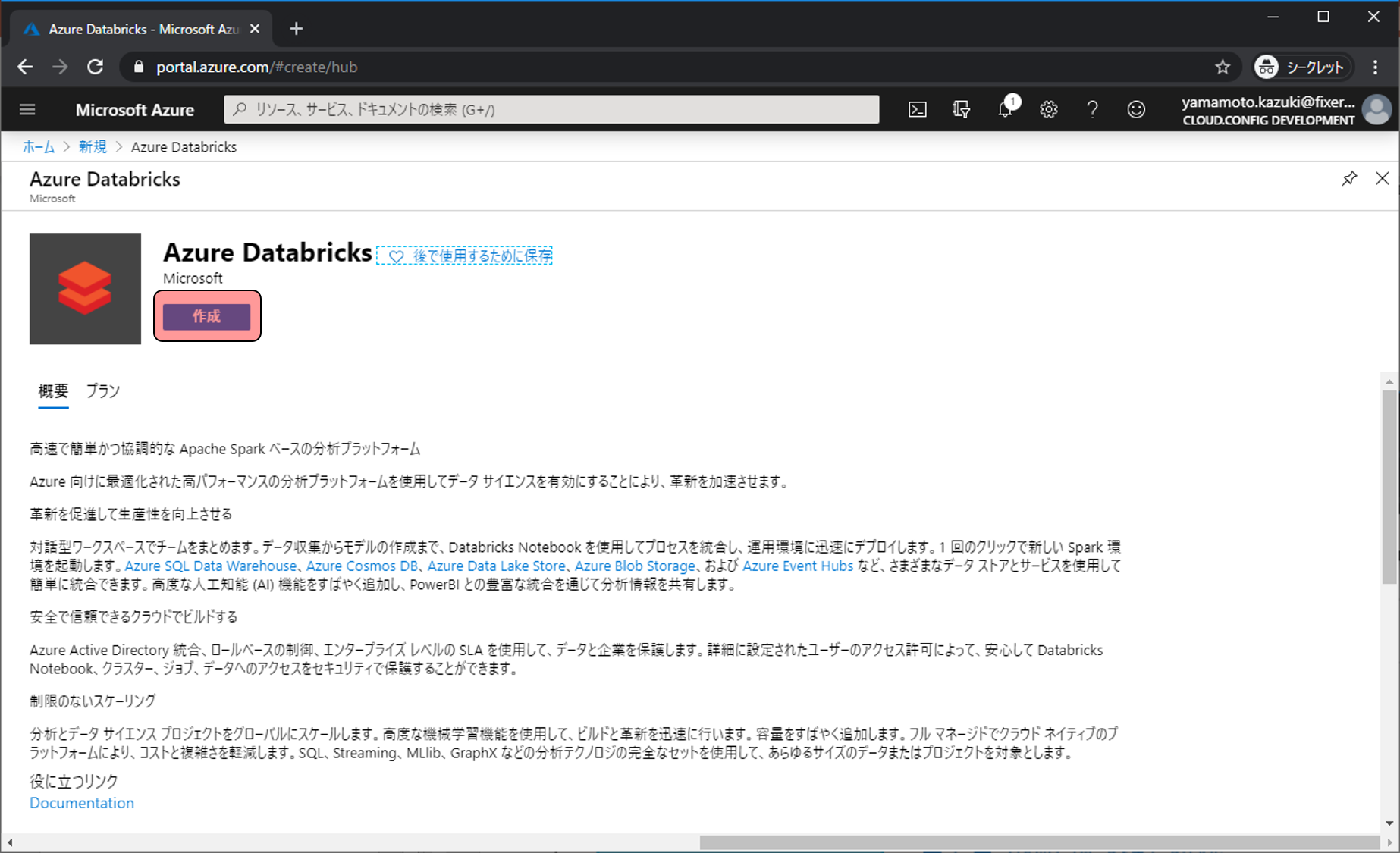
リソースを作成するに当たって、いくつか入力や選択する項目があるので、埋めて確認及び作成をクリックします。
- サブスクリプション: 課金が紐づくサブスクリプションの選択
- リソースグループ: 任意の文字列 → これから作成していくリソース群を格納する場所の名前
- ワークスペース名: 任意の文字列 → 作成するリソースに付ける名前
- 場所: 任意のリージョン → リージョンによって料金が微妙に異なります。また、現在地から遠い場所を利用するとアクセスも遅くなるので注意。料金の詳細はこちら
- 価格レベル: Standard → StandardとPremiumを選べる。レベルによって機能や値段が異なります。詳しくはこちら
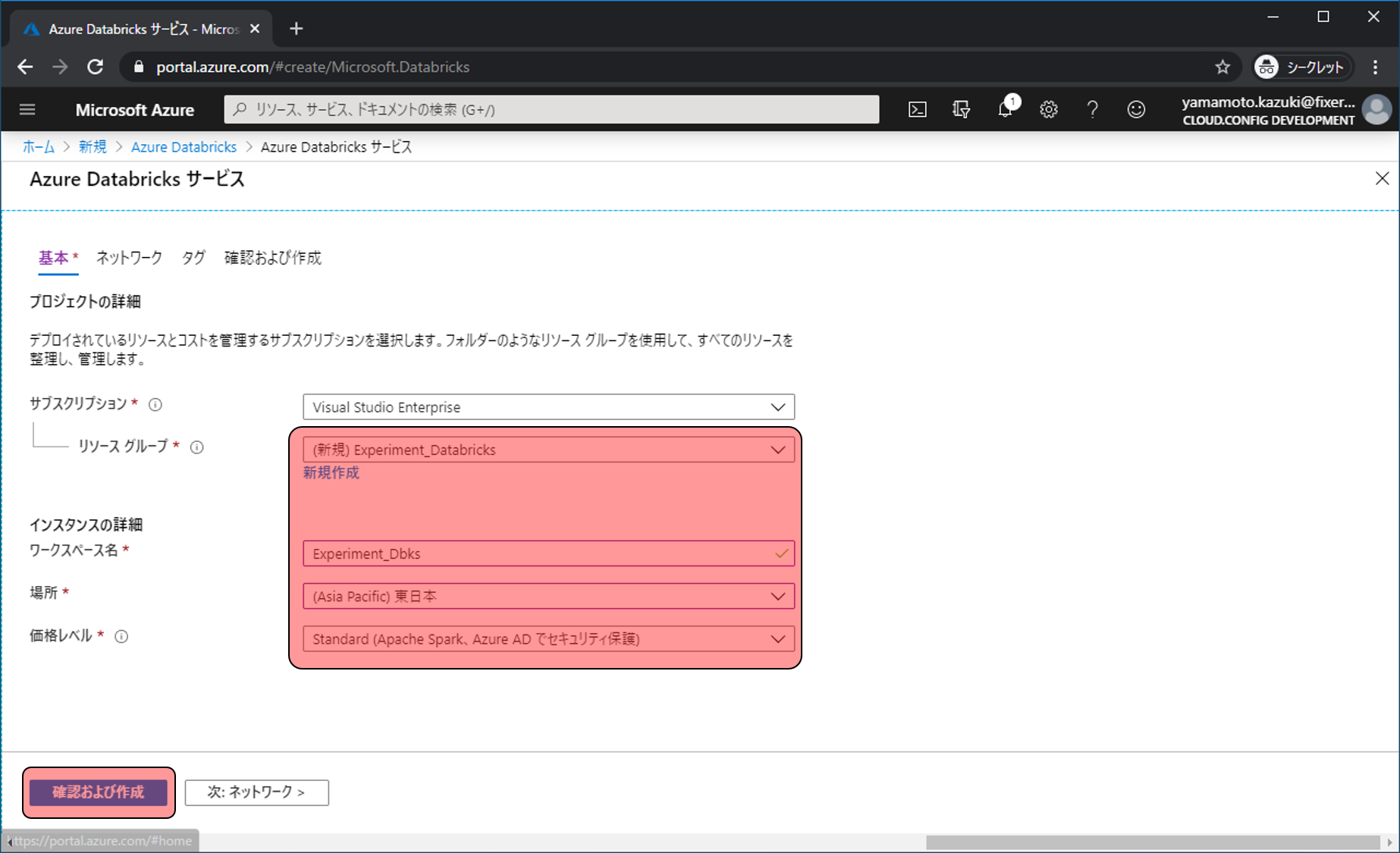
設定内容の確認画面が表示されます。作成をクリックします。
3分程度待つとデプロイが完了します。これでAzure Databricksの準備が完了しました。
次にデータを格納しておくBlob Storageを準備します。Azure Databricksのときと同様にリソースの作成画面に移動し、検索欄にStorage accountと入力してStorage account - blob, file, table, queueをクリックします。
Storage accountの概要等が表示されます。作成をクリックします。
リソースを作成するに当たって、いくつか入力や選択する項目があるので、埋めて確認及び作成をクリックします。
- サブスクリプション: 課金が紐づくサブスクリプションの選択
- リソースグループ: Azure Databricksを作成したリソースグループと同じもの
- ストレージアカウント名: 任意の文字列 → 作成するストレージに付ける名前
- 場所: 任意のリージョン → リージョンによって料金が微妙に異なります。また、現在地から遠い場所を利用するとアクセスも遅くなるので注意。料金の詳細はこちら
- パフォーマンス: Standard → StandardとPremiumがあり、PremiumだとSSDを利用するが、料金が高くなる。アカウント種類がBlob Strageの場合、Standardしか選べない
- アカウント種類: Blob Storage → 利用するサービスによって変更。TableやQueueを利用する場合はStandardV2を選択
- レプリケーション: ローカル冗長ストレージ → データをどのようにレプリケーションするかを選択
- アクセス層: ホット → データに対するアクセス頻度によってホットとクールを選択
設定内容の確認画面が表示されます。作成をクリックします。
少しするとデプロイが完了します。これでStorage Accountの作成は完了です。
次はBlob Storageにデータを登録します。リソースに移動をクリックします。
Storage Accountの管理画面に移動したら、データを格納するためのコンテナーをまずは作成します。画面中央のコンテナーをクリックします。
+コンテナーをクリックすると、右に入力欄が表示されるので、名前に任意の文字列(今回はdata)を入力し、作成をクリックします。
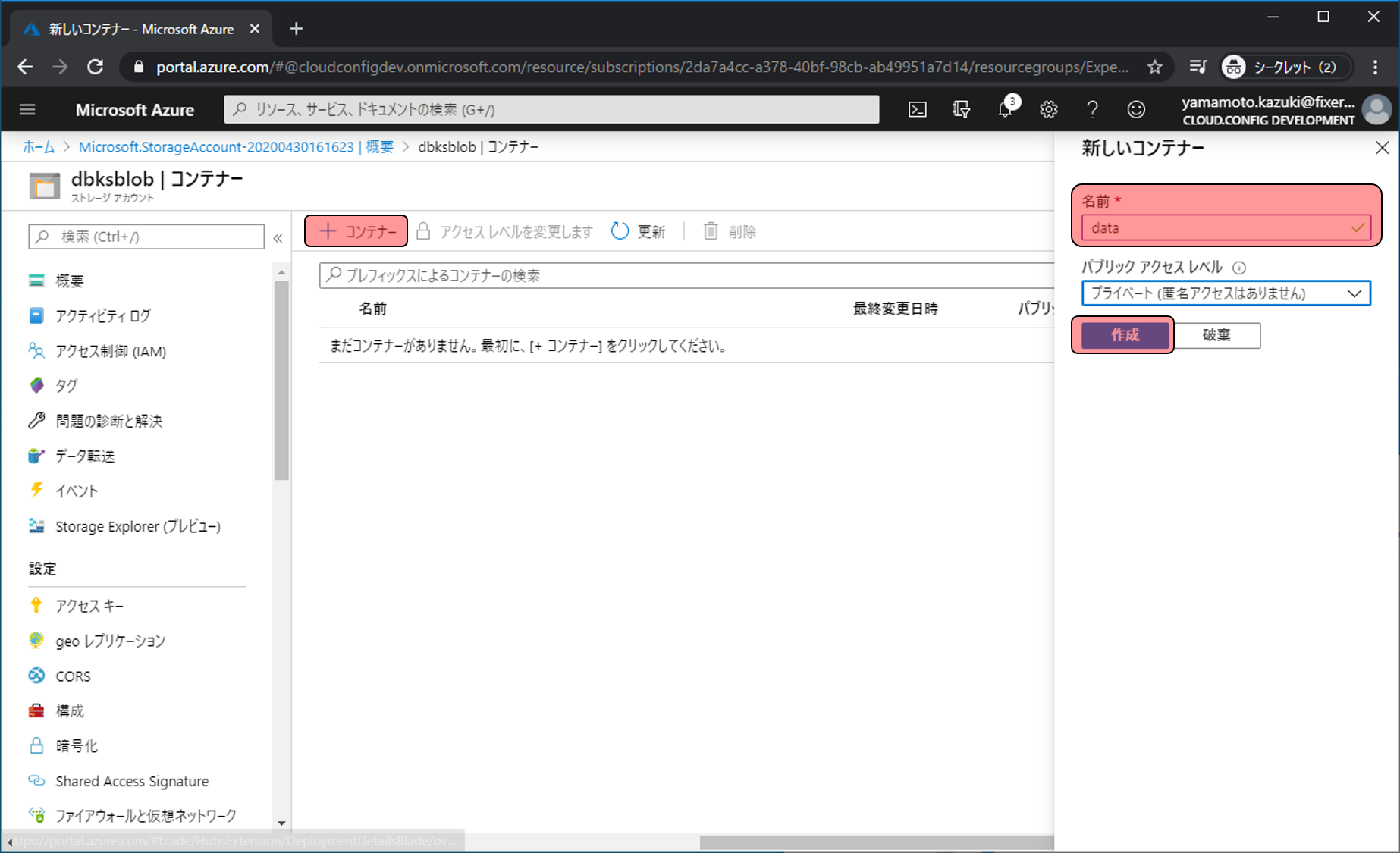
作成されたdataコンテナーをクリックします。
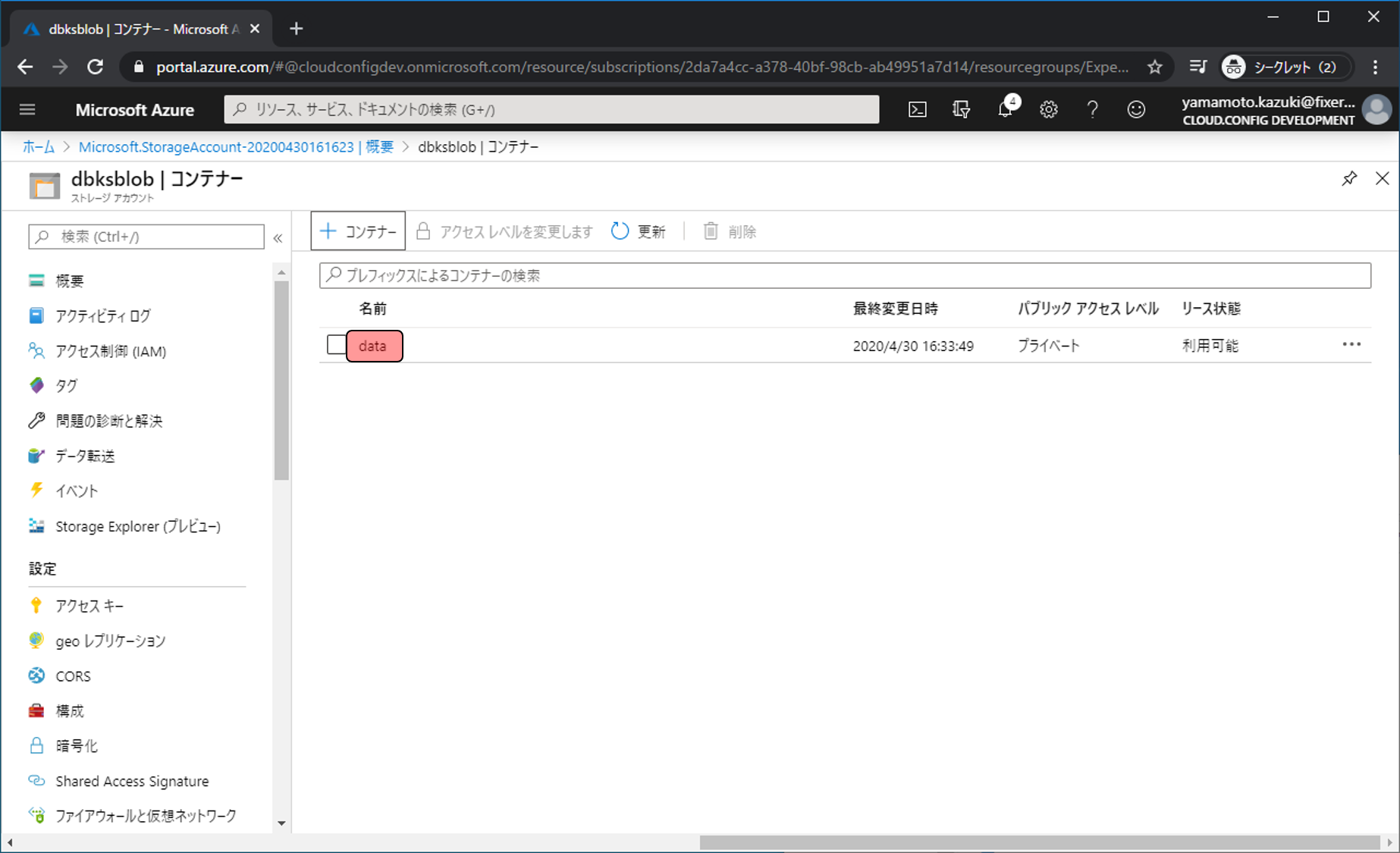
↑アップロードをクリックし、右に表示された入力欄で最初にダウンロードしたファイルをアップロード対象として選択し、アップロードをクリックします。
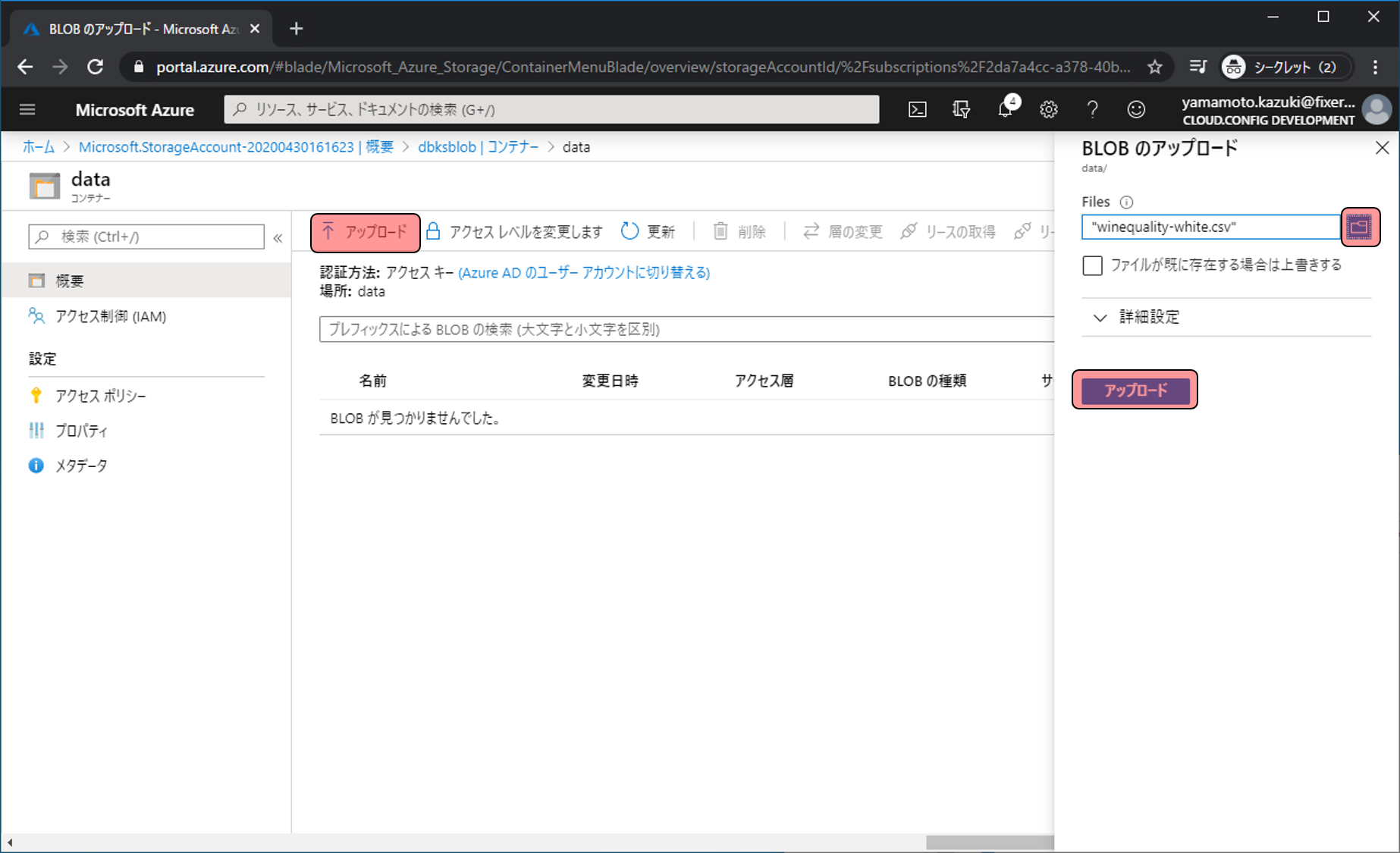
アップロードしたファイルが表示されれば完了です。
次はAzure Databricksからアップロードしたファイルなどにアクセスするためのキーを取得します。上の方にある(ストレージアカウント名) | コンテナー(今回はdbksblob | コンテナー)をクリックします。
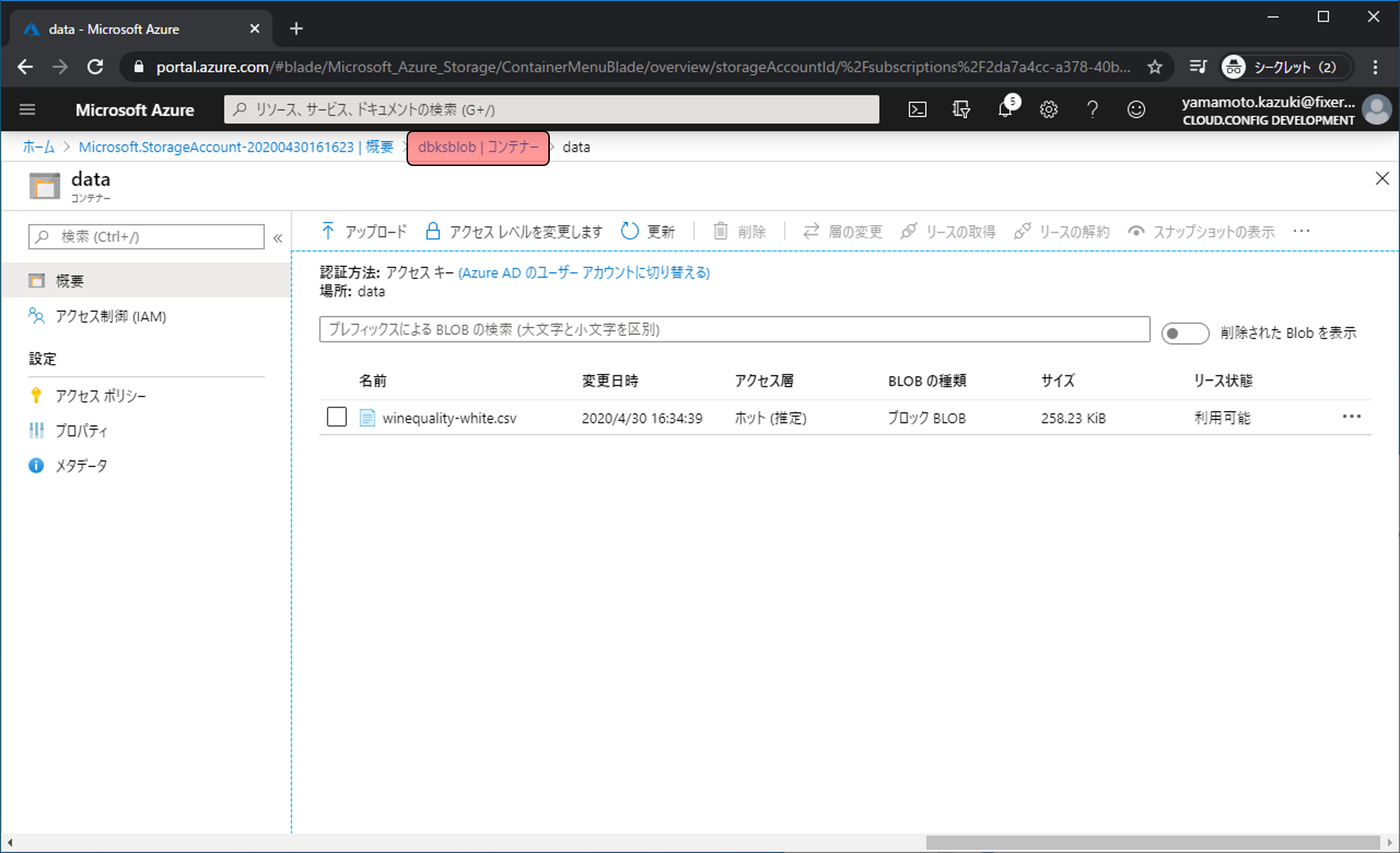
アクセスキーをクリックします。
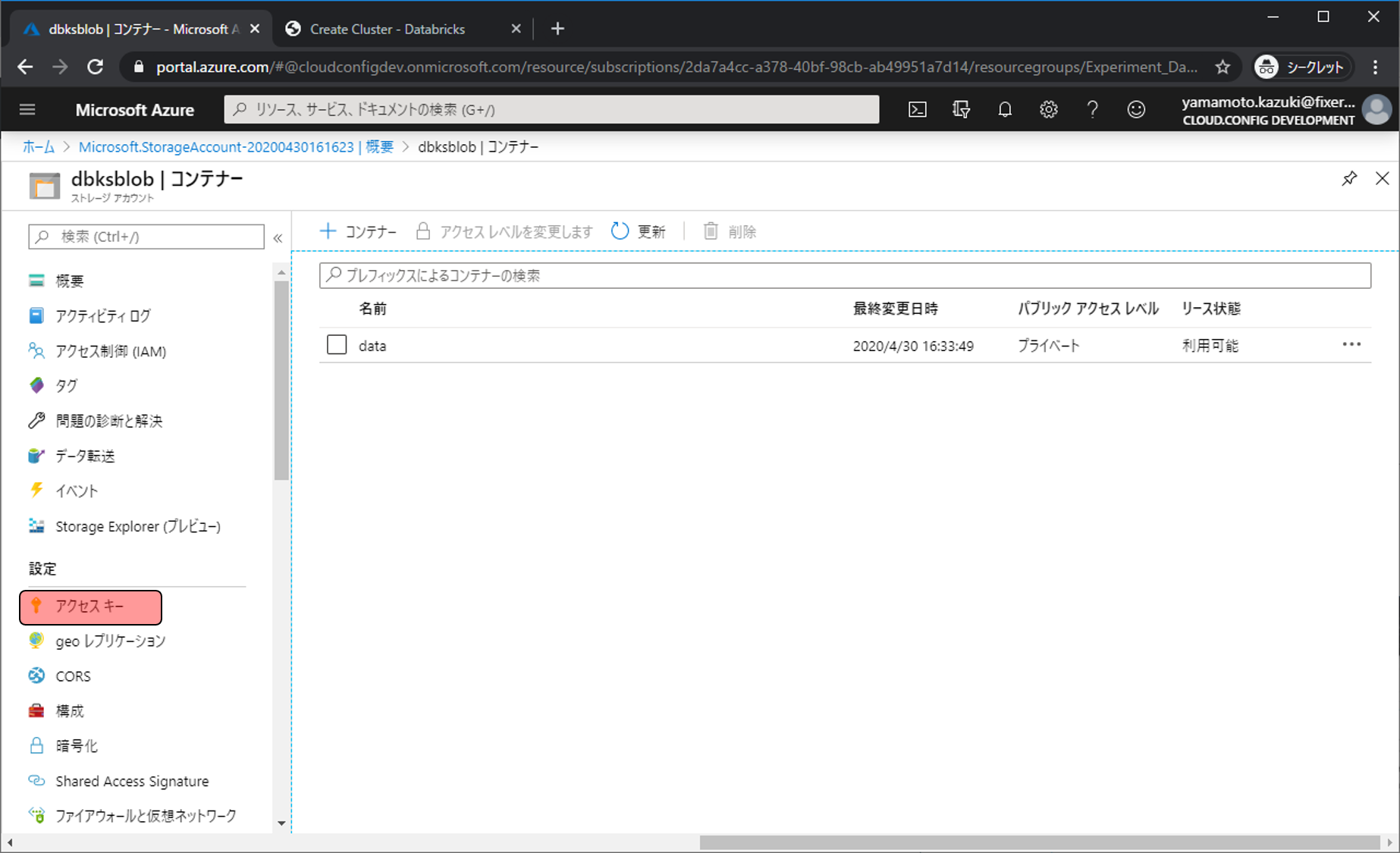
Key 1のキーをメモ帳等にコピーしておきます。これでStorage Accountで行う作業は終わりです。作成したAzure Databricksの管理画面に移動するため概要をクリックします。
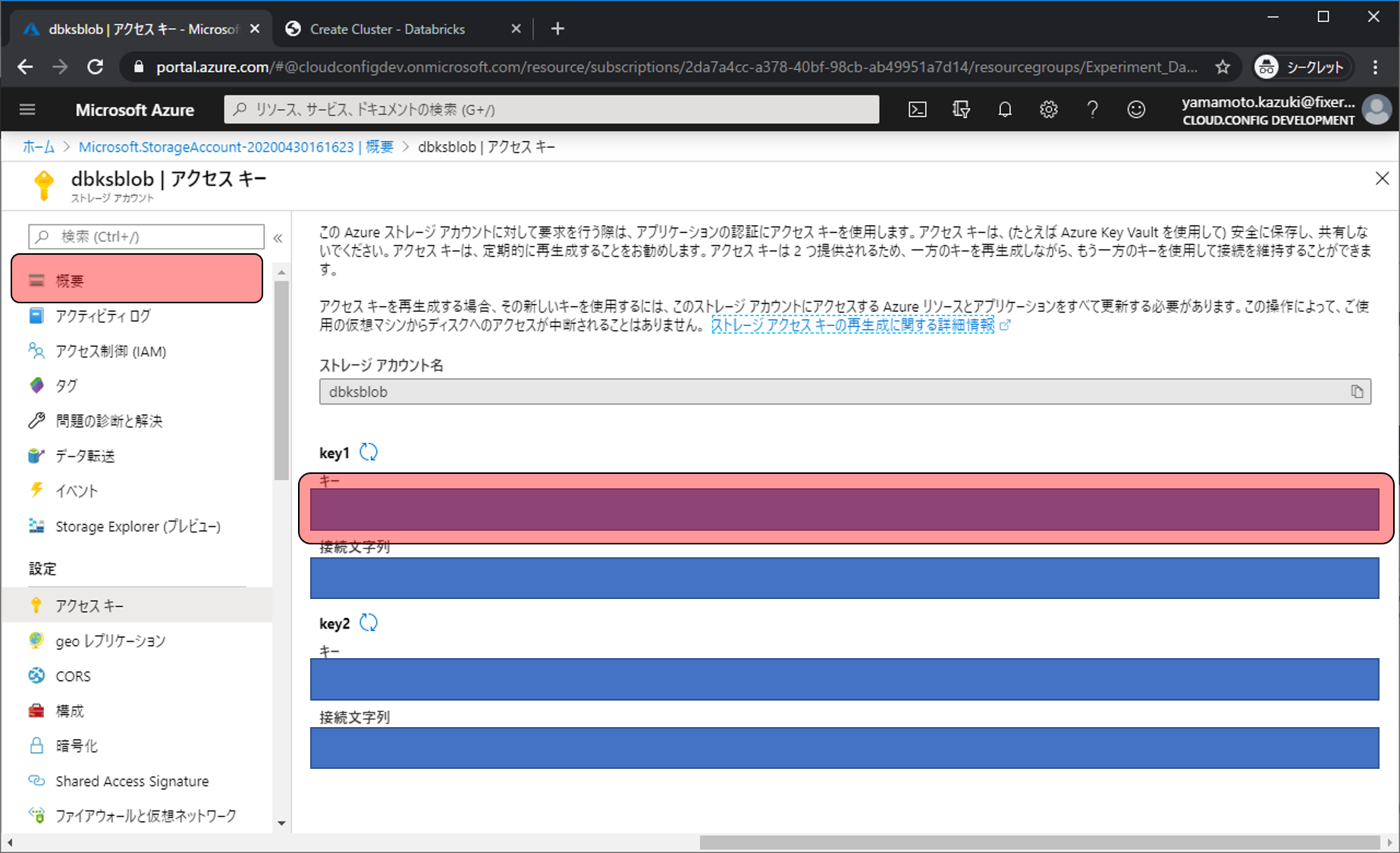
リソースグループのリンクをクリックします。
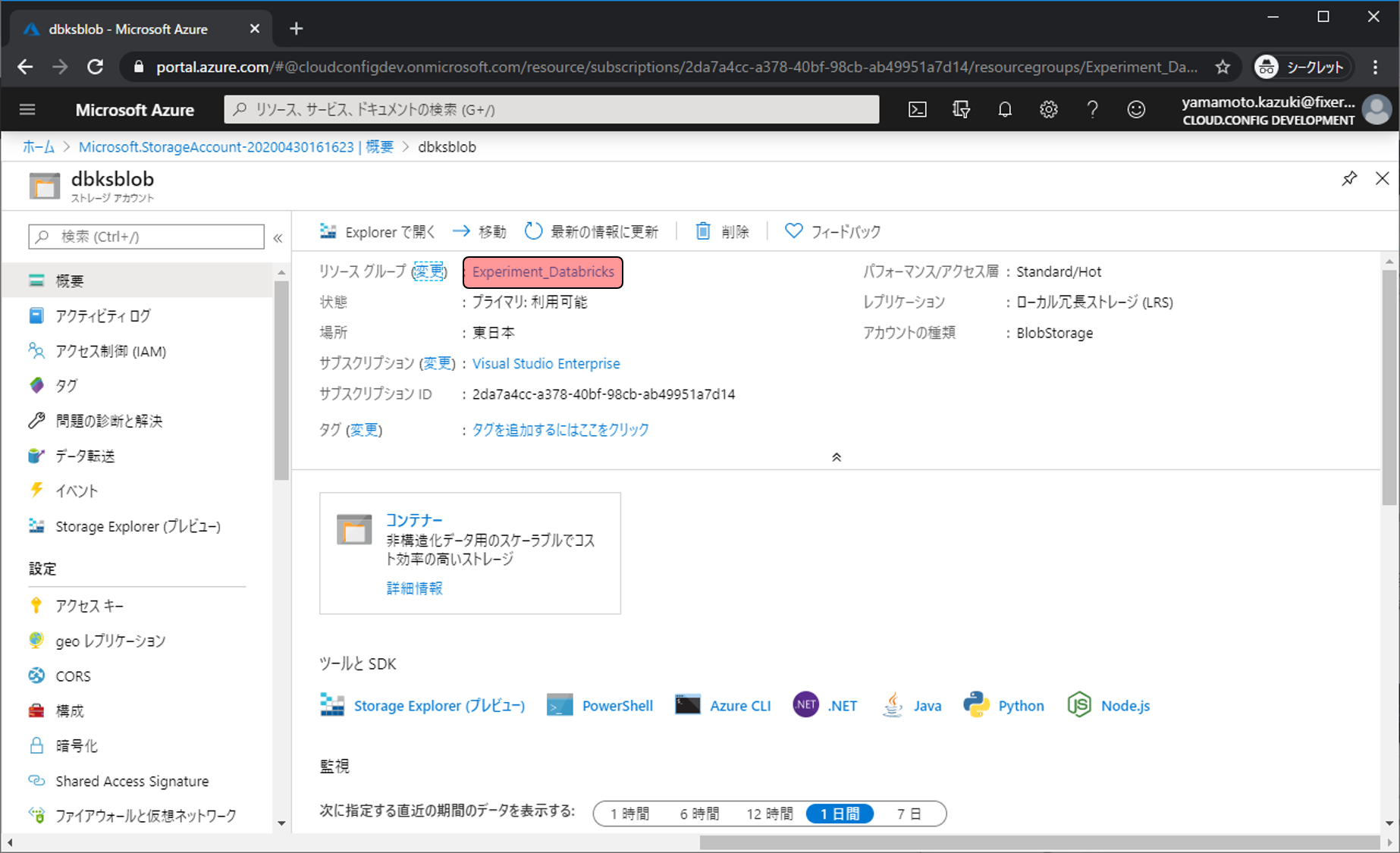
最初に作成したAzure Databricksがあるので、クリックします。
Databricksの管理画面に移動できました。
Databricksの具体的な利用はAzureポータルからはできません。専用のワークスペースに移動する必要があります。ワークスペースの起動をクリックします。
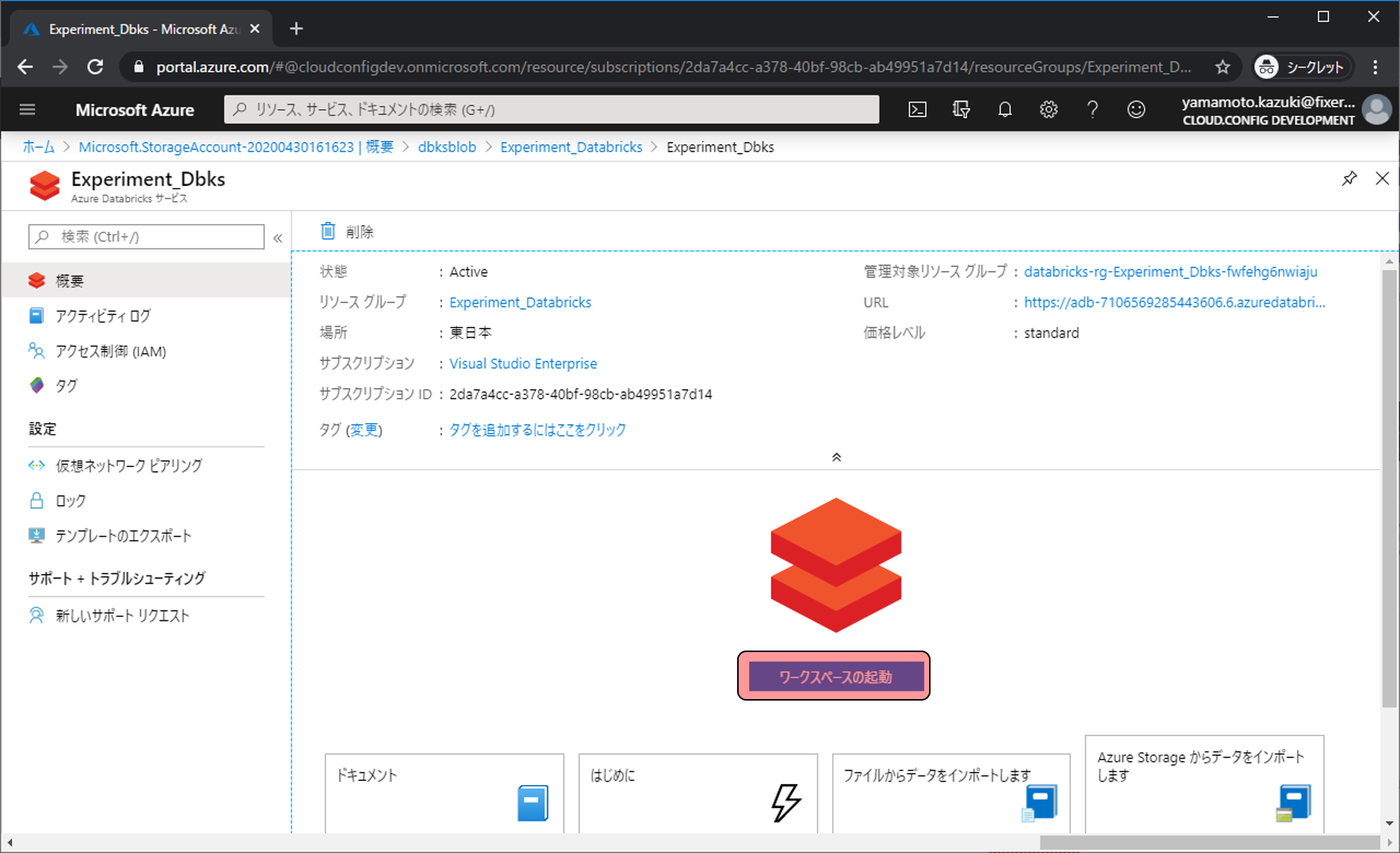
Blob上のデータをクエリで利用する
Azure Databricksのワークスペースに移動しました。ここでデータ分析などを行います。まずは、分析用のクラスター(VM)を作成します。New Clusterをクリックします。
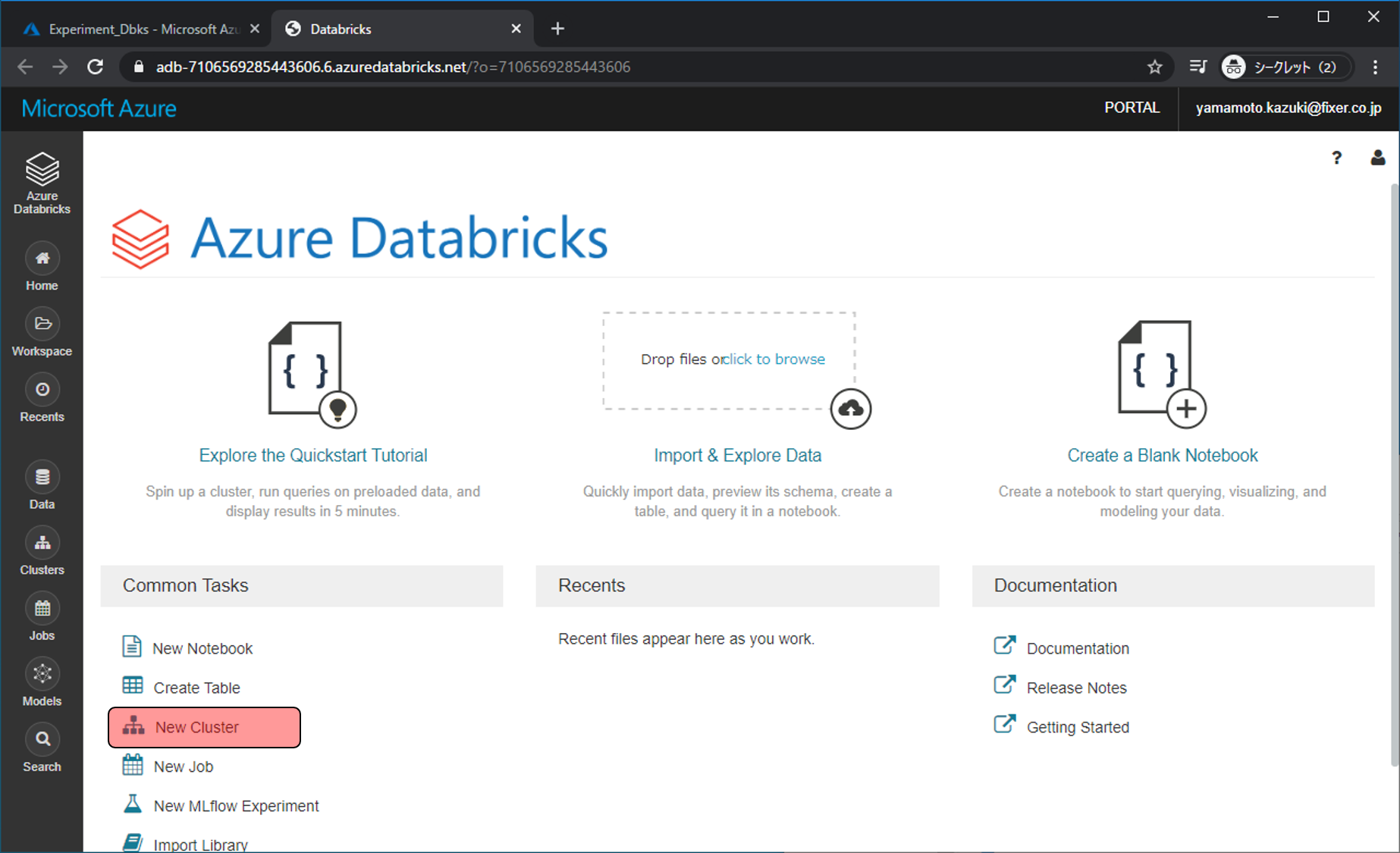
いくつか設定項目がありますが、今回入力・変更をする項目は以下です。設定が完了したらCreate Clusterをクリックします。
- Cluster Name: 任意の文字列
- Enable autoscaling: チェックを外す → チェックしておくと、負荷に応じてノード数が増え、処理時間が短くなるが、料金もノード数分高くなる
- Worker Type: Standard_F4s → VMのサイズになります。今回はCPU性能の高いFシリーズを利用
- Workers: 1 → 料金を抑えるために、Workerの数を1台にします
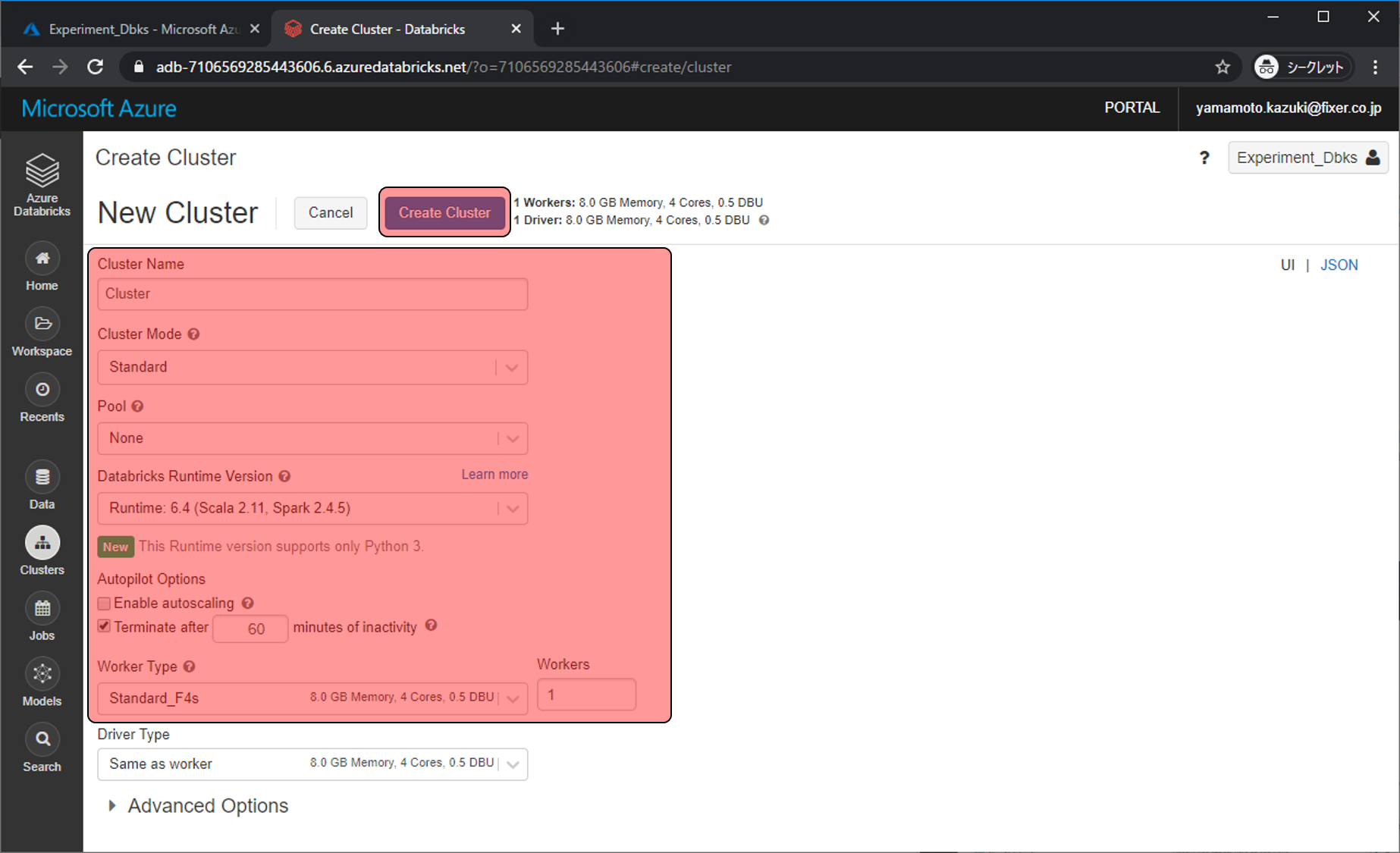
作成が開始され、5分程度待つとStateがRunningになります。Runningになったら左上のAzure Databricksをクリックしてメインページに戻ります。
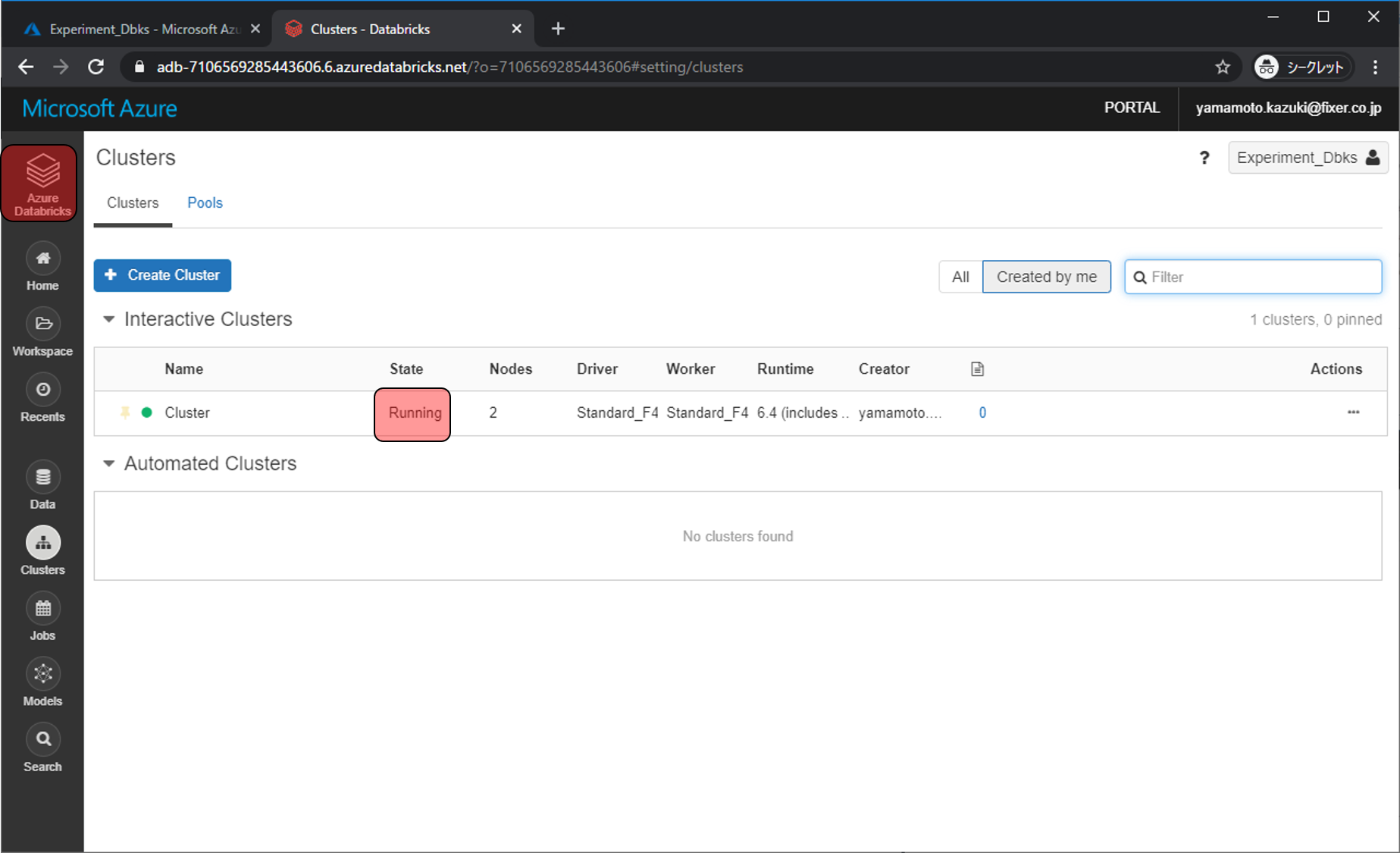
ここからはNotebookでPythonを使っていきます。New Notebookをクリックします。
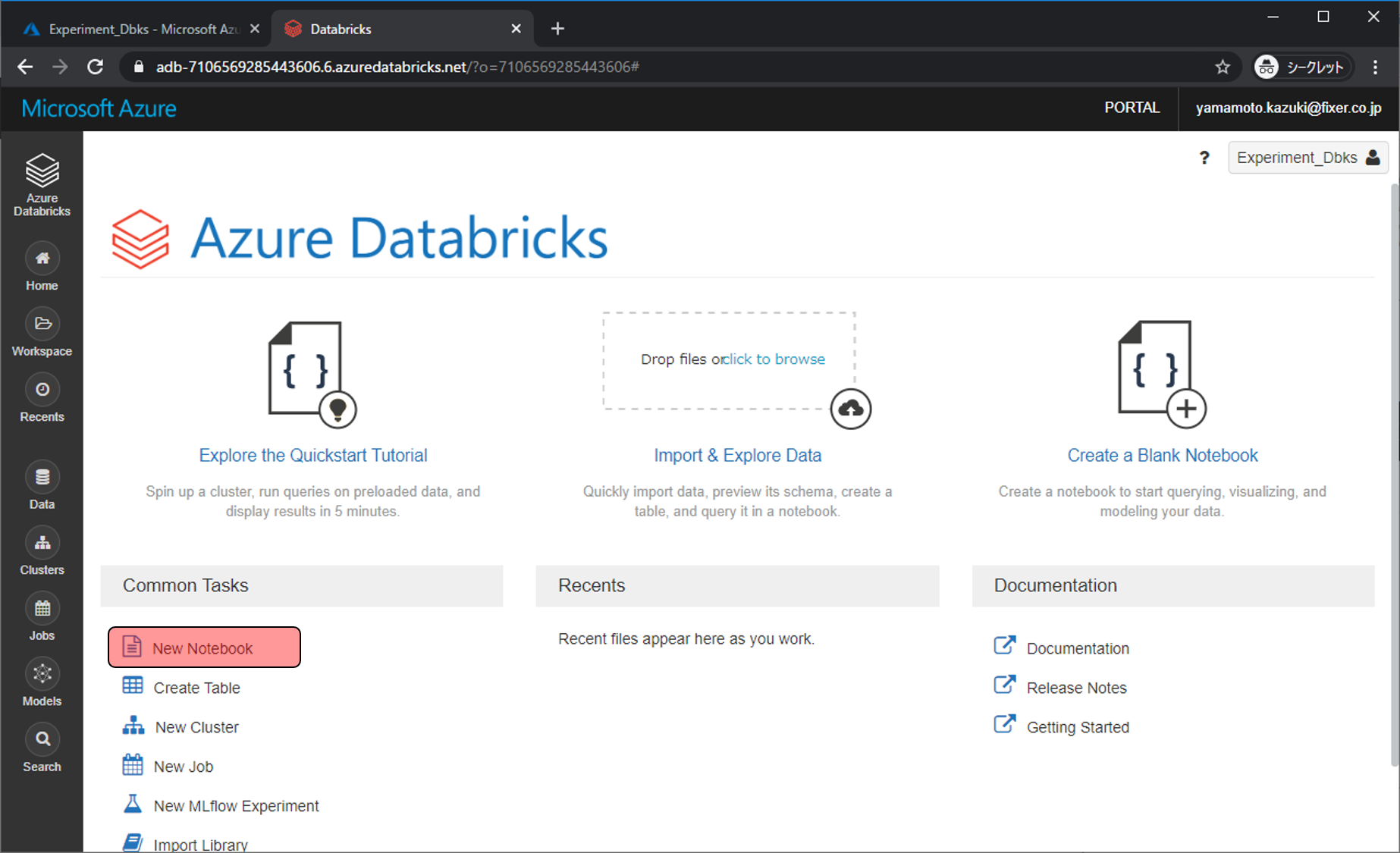
Notebookの名前や、言語、どのClusterで利用するかを選び、Createをクリックします。
- Name: 任意の文字列
- Language: Python
- Cluster: 先程作成したクラスター
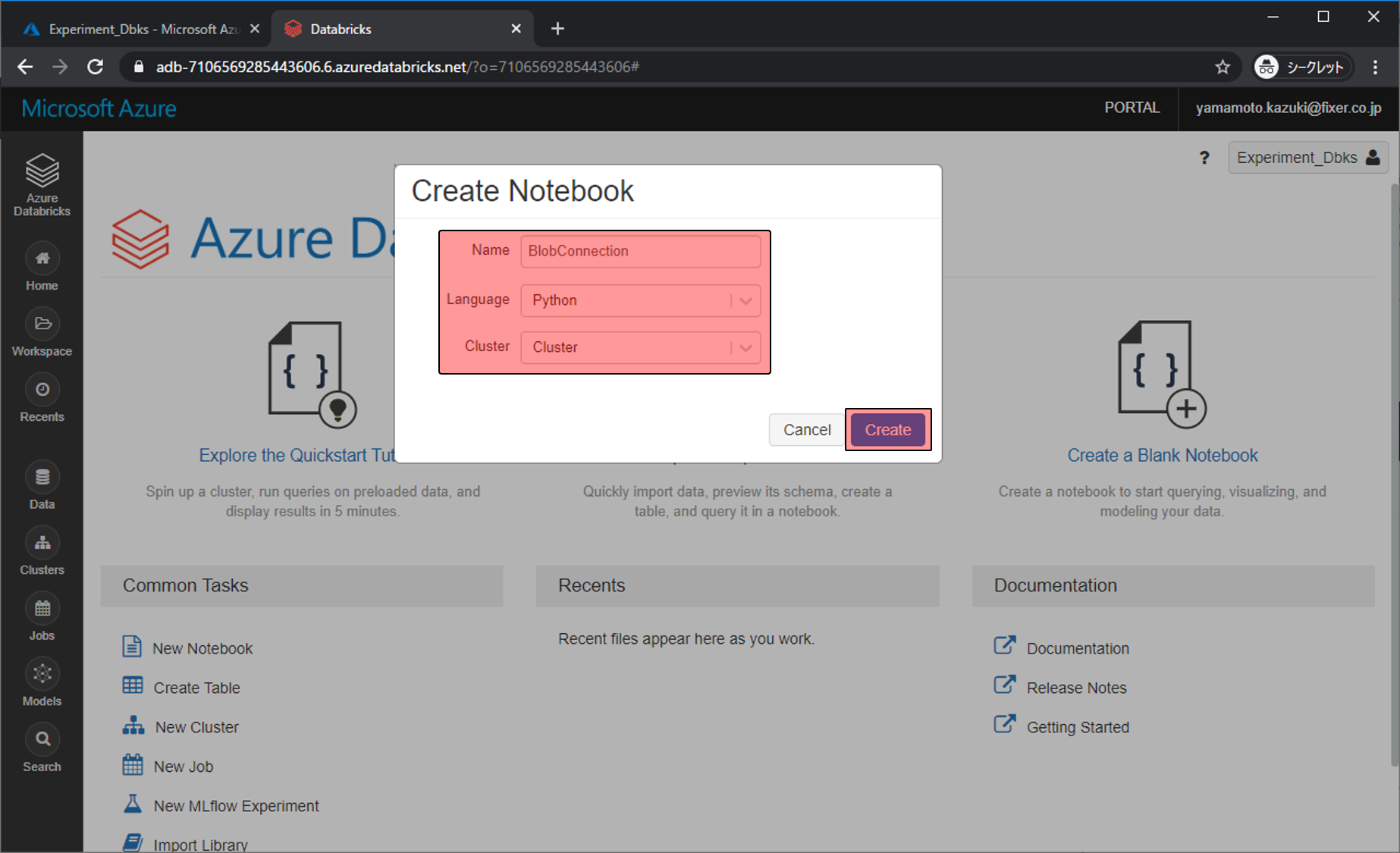
Pythonをよく使うひつにとっては見慣れたNotebookのような画面が表示されます。ここにPythonコードを書き、Blobの情報をクエリで取得します。
書くコードは大きくわけ、下記の3つです。
- BlobのコンテナーをAzure Databricksにマウント
- マウントしたデータをクエリで読み取れるように読込
- クエリと実行
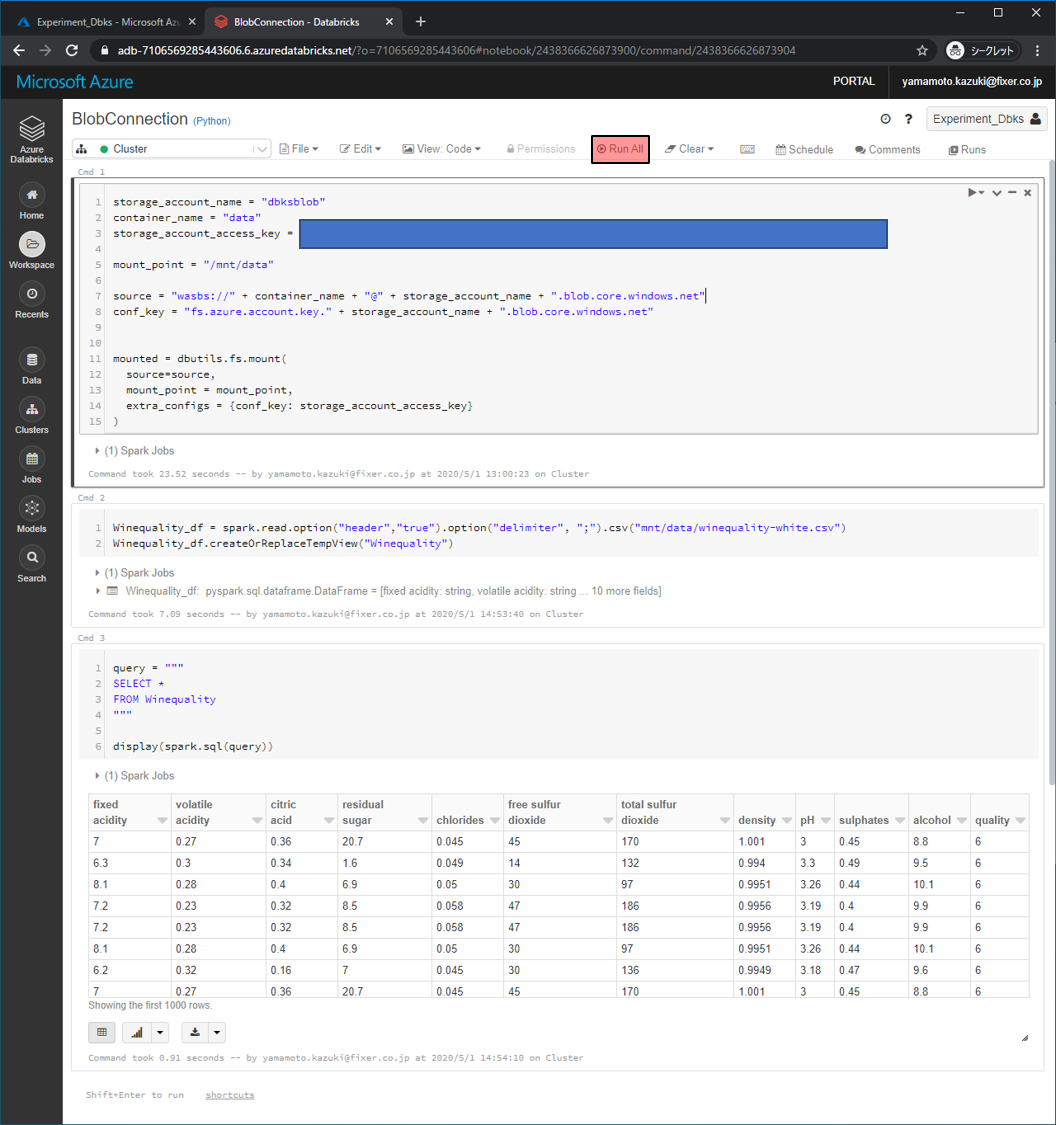
まずは「BlobのコンテナーをAzure Databricksにマウント」をします。先程作成したストレージアカウント名やコンテナー名、アクセスキーを下記のコードの中に書き加えてください。今回の場合は下記のようになります。
- 任意のマウント先ディレクトリ名: data
- ストレージアカウント名: dbksblob
- コンテナー名: data
- ストレージアカウントアクセスキー: (シークレット)
mount_name= "(任意のマウント先ディレクトリ名)"
storage_account_name = "(ストレージアカウント名)"
container_name = "(コンテナー名)"
storage_account_access_key = "(ストレージアカウントアクセスキー)"
mount_point = "/mnt/" + mount_name
source = "wasbs://" + container_name + "@" + storage_account_name + ".blob.core.windows.net"
conf_key = "fs.azure.account.key." + storage_account_name + ".blob.core.windows.net"
mounted = dbutils.fs.mount(
source=source,
mount_point = mount_point,
extra_configs = {conf_key: storage_account_access_key}
)「マウントしたデータをクエリで読み取れるように読込」をします。今回のBlobにあげたファイルの名前は「winequality-white.csv」なので、ファイル名をそのように設定し、区切り文字が「,」ではなく「;」だったため、区切り文字に指定を変えています。
その後、クエリとして扱うときのテーブル名として「Winequality」という名前をつけています
Winequality_df = spark.read.option("header","true").option("delimiter", ";").csv("mnt/data/winequality-white.csv")
Winequality_df.createOrReplaceTempView("Winequality")これでBlob上のデータをクエリで扱うための準備が整いました。クエリを作成して、実行します。
作成したクエリはオーソドックスな上から10行のデータを取得するものです。
query = """
SELECT *
FROM Winequality
"""
display(spark.sql(query))各コードを書いて実行をします。実行はRun Allをクリックルすると行えます。クエリで取得した結果が表示されます。
集計などもできます。
query = """
SELECT
quality,
COUNT(*) AS n
FROM
Winequality
GROUP BY
quality
ORDER BY
quality
"""
display(spark.sql(query))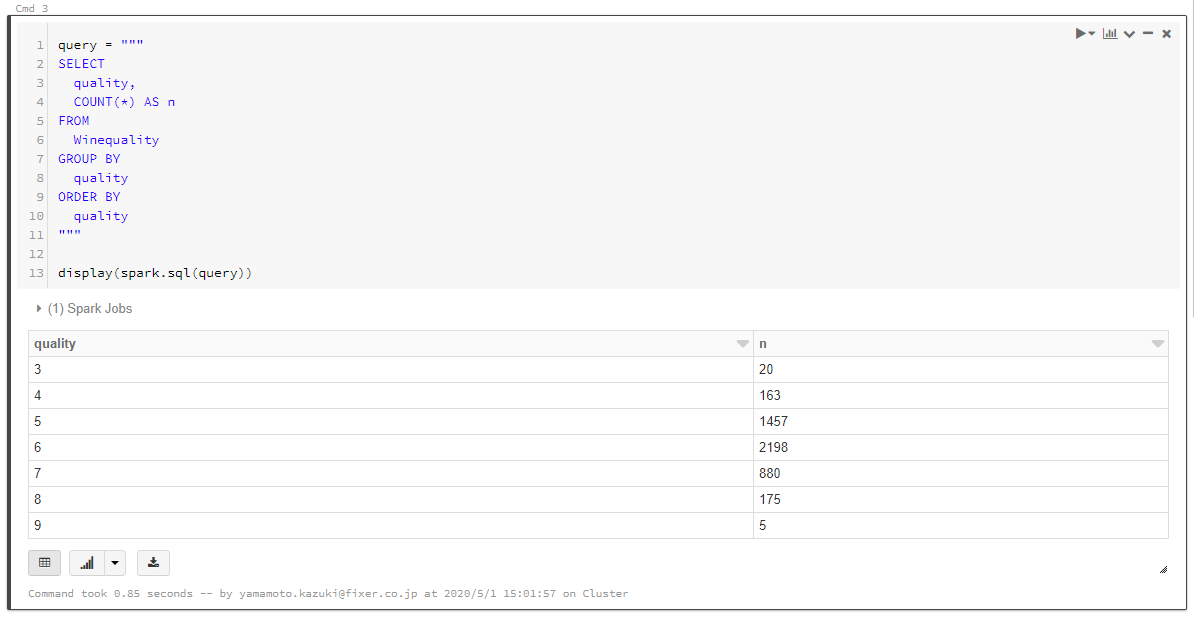
さらに、読み込むファイルの指定をワイルドカードにすると、複数ファイル同時に扱えます。(今回は赤ワインの情報を追加でBlobにアップロードし、マウントし直しました)
もちろん、データ数が増えたので集計結果も変わります。
Winequality_df = spark.read.option("header","true").option("delimiter", ";").csv("mnt/data/*.csv")
Winequality_df.createOrReplaceTempView("Winequality")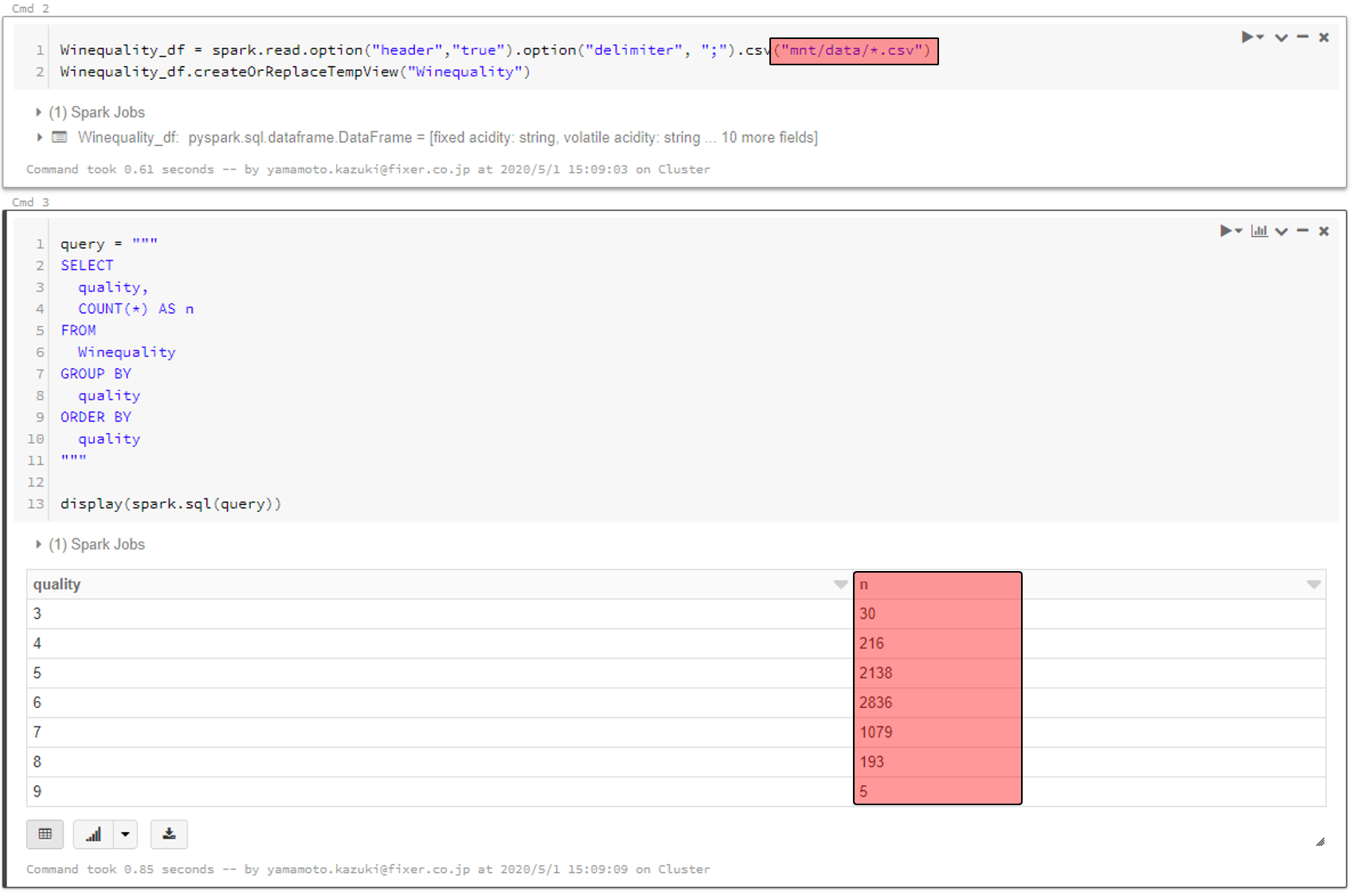
いかがだったでしょうか。Azure Databricksを使うとBlobのなかに貯めていたデータも簡単に分析できるようになるので、皆さんも是非使ってみてください。
それでは!











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
