





こんにちは。こんにちは。R&D Divisionの山本です。
今回の記事はコードを書かずに機械学習をしてみよう!その2の続きとなります。
前回は利用している各モジュールの解説を行いましたが、今回は作成した予測モデルの予測精度を上げる方法について解説します。
まず、もっとも試しやすいのは、利用するアルゴリズムを変えてみることです。今まではLinear Regressionを使ってましたが、他のアルゴリズムを使って予測モデルを作成し、評価内容を確認します。
同じデータを使ってモデルを作成する部分をもう一つ作りました。利用しているアルゴリズムはDecision Forest Regressionです。
Score Modelで試した内容をEvaluation Modelで評価します。Evaluation Modelに複数入力すると、評価内容を比較することができます。
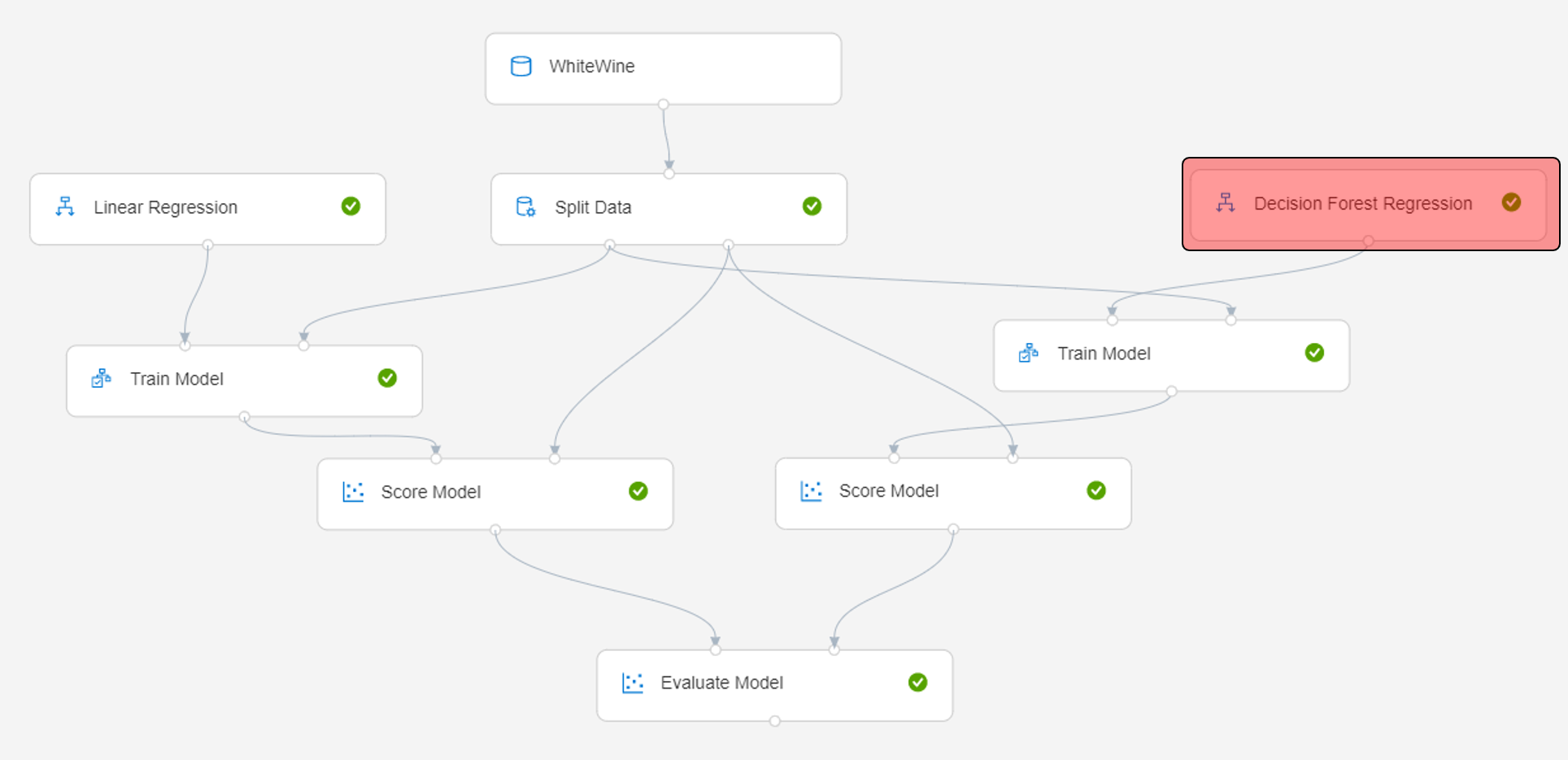
Evaluation Modelの結果を確認します。出力とログの視覚化をクリックします。
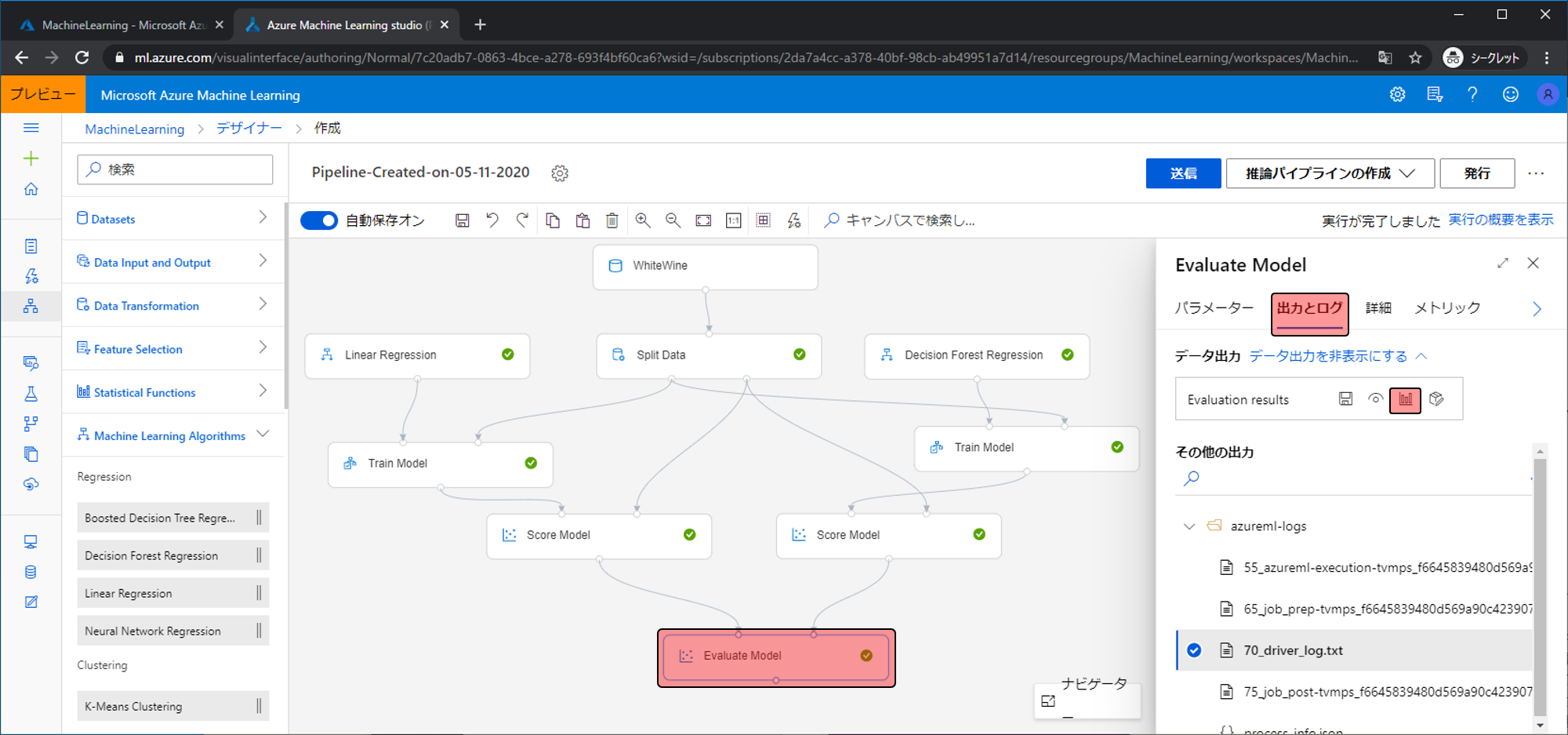
上がLinear Regressionの結果、下がDecision Forest Regressionの結果になります。今回は比較するためCoefficient_of_Determinationに着目します。
すると、Linear Regressionのときは0.269なのに対してDecision Forest Regressionは0.437と高くなりました。値が1に近いほうが優れているため、Decision Forest Regressionで作ったモデルのほうが優れていることがわかります。

他のアルゴリズムの結果も見てみましょう。Boosted Decision Tree RegressionとNeural Network Regressionを使った結果です。どちらもDecision Forest Regressionの0.437ほど高くはなりませんでした。
Decision Forest Regression以外のアルゴリズムも設定を調整すればが0.437以上になる可能性はありますが、アルゴリズムの設定調整は専門知識も必要なので今回は行いません。

次にモデル作成に利用するデータを制限することでモデルの精度向上を目指します。一般的には、データの項目は多いほうが良いとされますが、予測したいものと関係が薄い項目はノイズになってしまいます。例えば身長を予測したいときに、1週間の平均読書時間は関係が薄いです。
今回のワインの評価予測でも、評価との関係が薄い項目があるかもしれません。そして、それを学習データから外すことで予測精度が高くなる可能性があります。
まずは評価(quality)と他の項目の相関係数を確認します。今回はエクセルで確認しました。
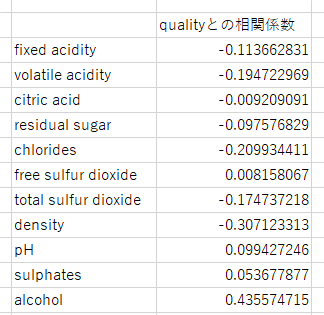
絶対値でみると、free sulfur dioxideが0.008で一番小さい(評価との関係が薄い)ので、この項目を外してみます。
項目の選択にはSelect Columns in Datasetを使います。WhiteWineとSplit Dataの間に配置します。このSelect Columns in Datasetでは、入力されたデータから指定した項目を削除したものを出力します。つまり13項目入力し、2項目削除したら出力されるのは11項目のデータになります。
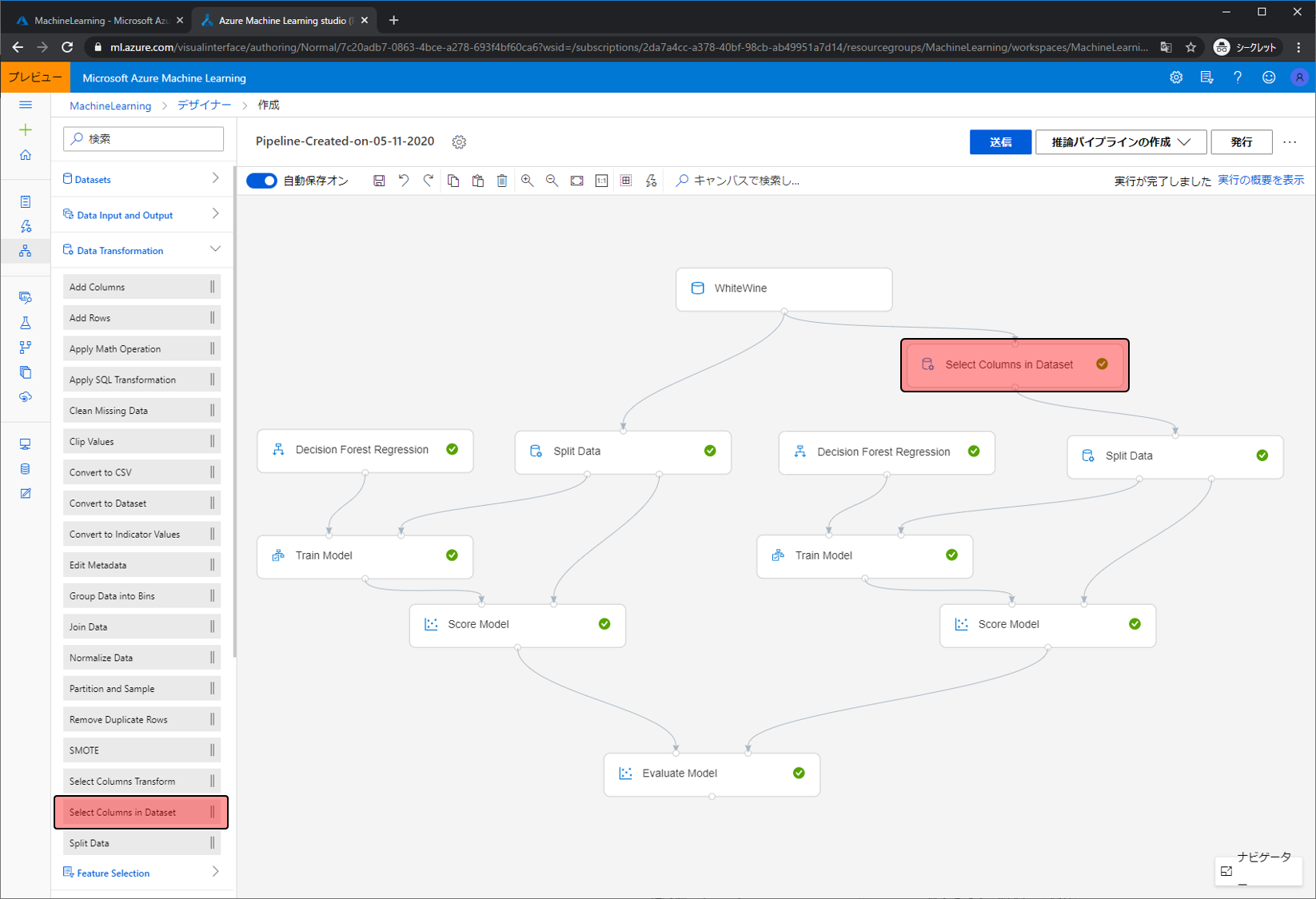
使わない項目を指定します。Select Columns in Datasetの設定画面で列の編集をクリックします。
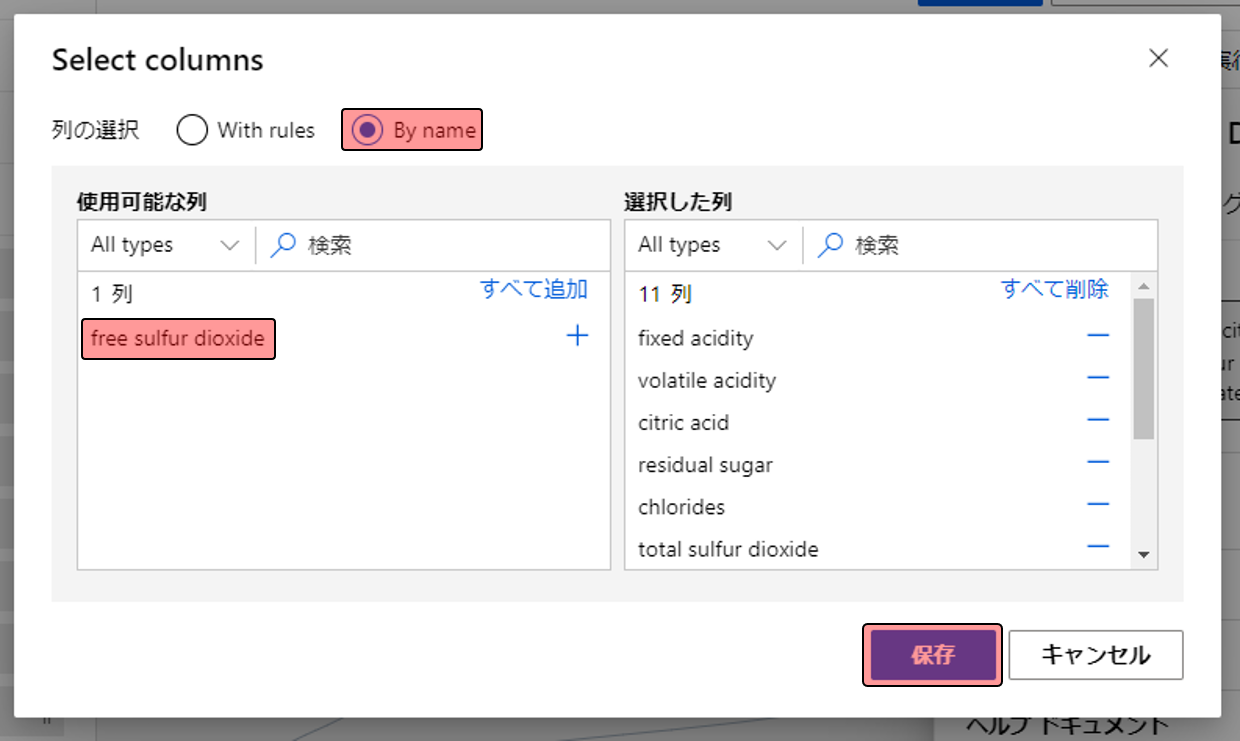
By nameを選択し、使わない項目(free sulfur dioxide)だけ残して、それ以外は[+]をクリックして右に移し、保存をクリックします。
これで相関関係がなかったfree sulfur dioxideを使わずに予測モデルを作り、評価を行います。
評価した結果が以下になります。値が下がってしまいました。free sulfur dioxide単体ではqualityとの関係が薄かったかもしれませんが、他の項目と組み合わさると価値が高かったようです。

他の項目でも試してみましょう。これはfixed acidityを除いた結果です。若干値が高くなりました。このfixed acidityは予測モデルを作るときのノイズとなっていたようです。

今回は予測精度を上げる方法としてアルゴリズムを変える方法とデータを選定する方法を紹介しました。
ぜひ、これらを活用して予測モデルをより良いものにしてみてください。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
