


 2023-10-03
2023-10-03


こんにちは、株式会社FIXERの村上です。
2023年9月28日、ついにAmazon Bedrock(AWS 生成系AIサービス)が一般提供になりました🎉
Amazon Bedrock が一般利用可能に – 基盤モデルを利用した生成系 AI アプリケーションの構築とスケール
今年の4月中旬に米国Amazonから発表があり、AWSパートナーなどの一部のIT企業でプライベートプレビューが開始されていました。それから5ヶ月余りの時を経て、一般利用提供(GA)として公開されました。
■ 利用可能なAWSリージョン
2023年9月29日時点で、以下の4つのリージョンが利用可能です。
- バージニア北部(us-east-1)
- オハイオ(us-east-2)
- オレゴン(us-west-2)
- シンガポール(ap-southeast-1)
日本国内の東京リージョンや大阪リージョンはまだサポートされていません。バージニア北部とシンガポールを試してみましたが、バージニア北部の方が基盤モデルの申請が迅速に承認されたり、基盤モデルのバージョンがより新しい場合があり、現時点では開発や技術検証において、このバージニア北部の利用をお勧めします。
■ 利用可能な基盤モデル
2023年9月29日時点で、以下の5つのAIモデルを利用できます。
- AI21 Labs Jurassic-2(J2)
- Amazon Titan
- Anthropic Claude
- Cohere
- Stability AI
利用するためには、リージョンごとで「Edit」から利用申請が必要です。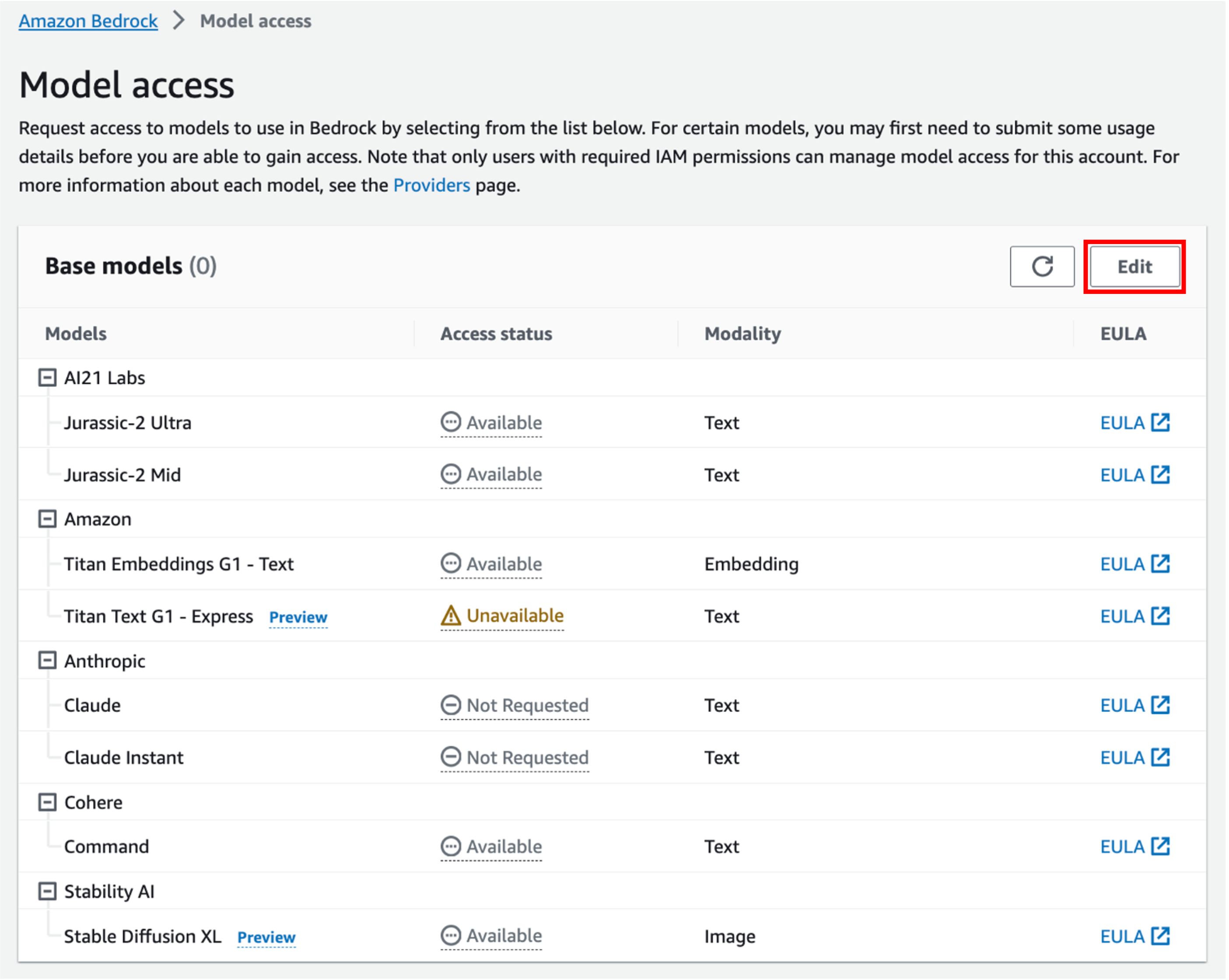
■ Amazon Bedrockの料金
- モデルインファレンス料金:
- On Demand: 使用したモデルインファレンスに対して、利用した分だけの料金が発生します。時間ベースの契約は不要です。
- Provisioned Throughput: アプリケーションのパフォーマンス要件を満たすために、十分なスループットを提供するための時間ベースの契約があります。
- カスタマイズ料金:
- Model customization (fine-tuning): カスタムモデルの作成や調整に関連する料金が発生します。
■ Titan Embeddings で埋め込みベクトルを生成してみた
本ブログのハンズオンではモデルID「amazon.titan-embed-text-v1」を利用して、埋め込みベクトルを生成してみます。
事前にいくつか環境設定が必要なので、紹介していきます。
1.環境設定
- AWSの認証情報をセットアップする
AWSアクセスキーとシークレットアクセスキーを取得します。
aws configure コマンド をターミナル等で実行します。
必要なパラメータは以下のとおりです。適宜、プロファイル名を調整します。
| AWS Access Key ID | 先ほど取得したアクセスキー |
| AWS Secret Access Key | 先ほど取得したシークレットアクセスキー |
| Default region name | 使用したいAWSリージョン(今回は us-east-1 を設定) |
| Default output format | 出力形式(今回は json を設定) |
ハンズオンで使用するGitHubリポジトリをクローンする
git clone https://github.com/aws-samples/amazon-bedrock-workshop.git cd amazon-bedrock-workshopPython 3バージョン系 をインストールする(pip もインストールください!)
本ブログでは、python@3.11/3.11.5 をインストールしています。
https://www.python.org/downloads/AWS SDK for Python(Boto3)をインストールする
本ブログでは、AWS SDK(Boto3)は 1.28.57 をインストールしています。1.28.57 以上のバージョンが必要です。
pip install -q -U boto3言語モデルを利用したアプリケーションを開発するためのフレームワーク(LangChain)をインストールする
pip install --quiet langchain==0.0.304「Titan Embeddings G1 - Text」の利用申請を行う
モデルアクセス の画面から「Titan Embeddings G1 - Text」をリクエストします。
「Edit」からTitan Embeddings G1 - Textを申請ください。
利用可能になると Access status が「Access granted」に更新されます。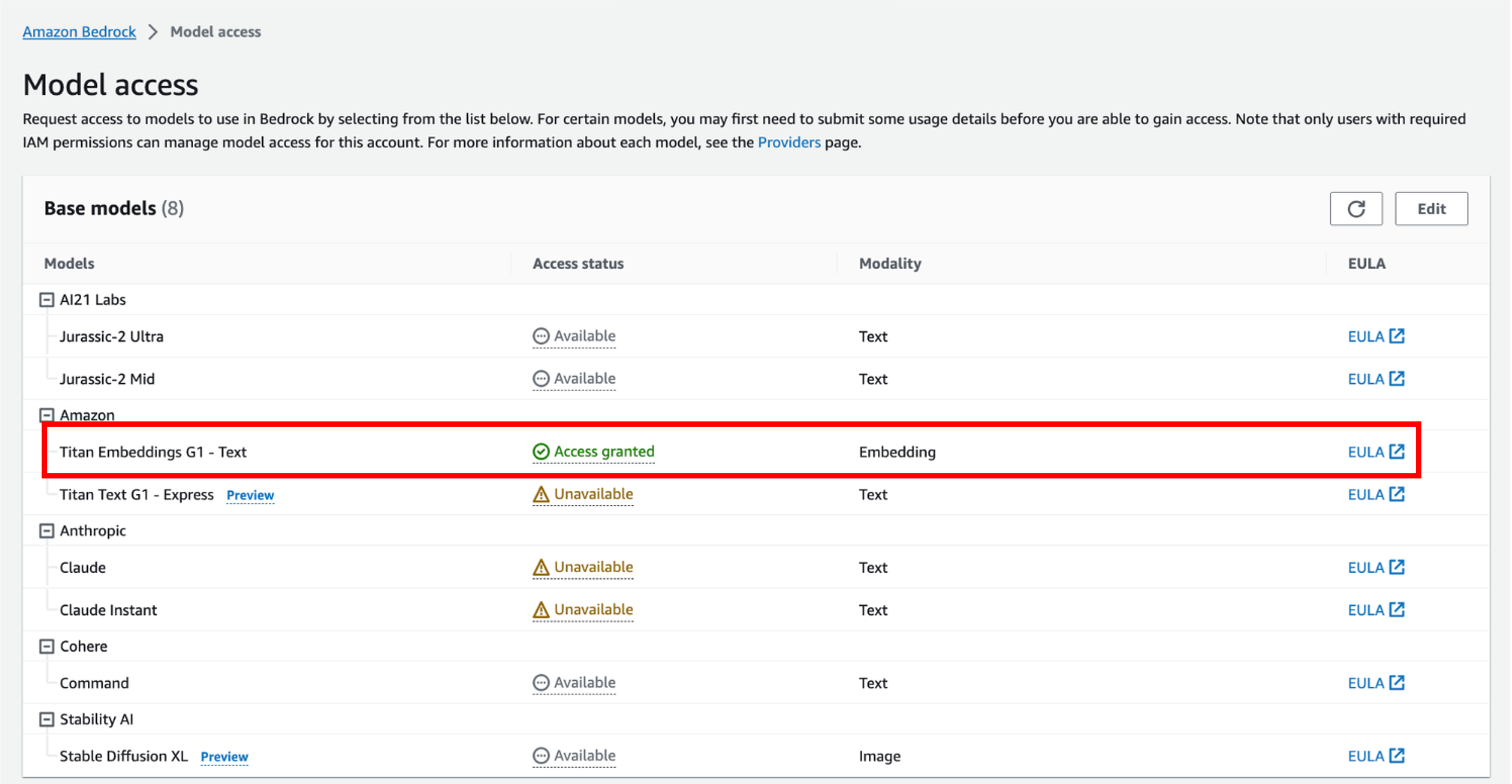
2.いよいよ実践
クローンしたリポジトリの直下にpythonファイルを配置します。コードは以下のとおりです。
本プログでは bedrock_api_request.py というファイルを配置しました。
import json import os import sys module_path = "./utils" sys.path.append(os.path.abspath(module_path)) from utils import bedrock, print_ww bedrock_runtime = bedrock.get_bedrock_client( assumed_role=os.environ.get("BEDROCK_ASSUME_ROLE", None), region=os.environ.get("AWS_DEFAULT_REGION", None) ) prompt_data = """ Command: We are the world's most cloud-native IT vendor. """ response = bedrock_runtime.invoke_model( body=json.dumps({ "inputText": prompt_data }).encode(), modelId="amazon.titan-embed-text-v1", accept="application/json", contentType="application/json" ) response_body = json.loads(response.get('body').read()) embedding = response_body.get('embedding') print_ww(embedding)実行してみました。
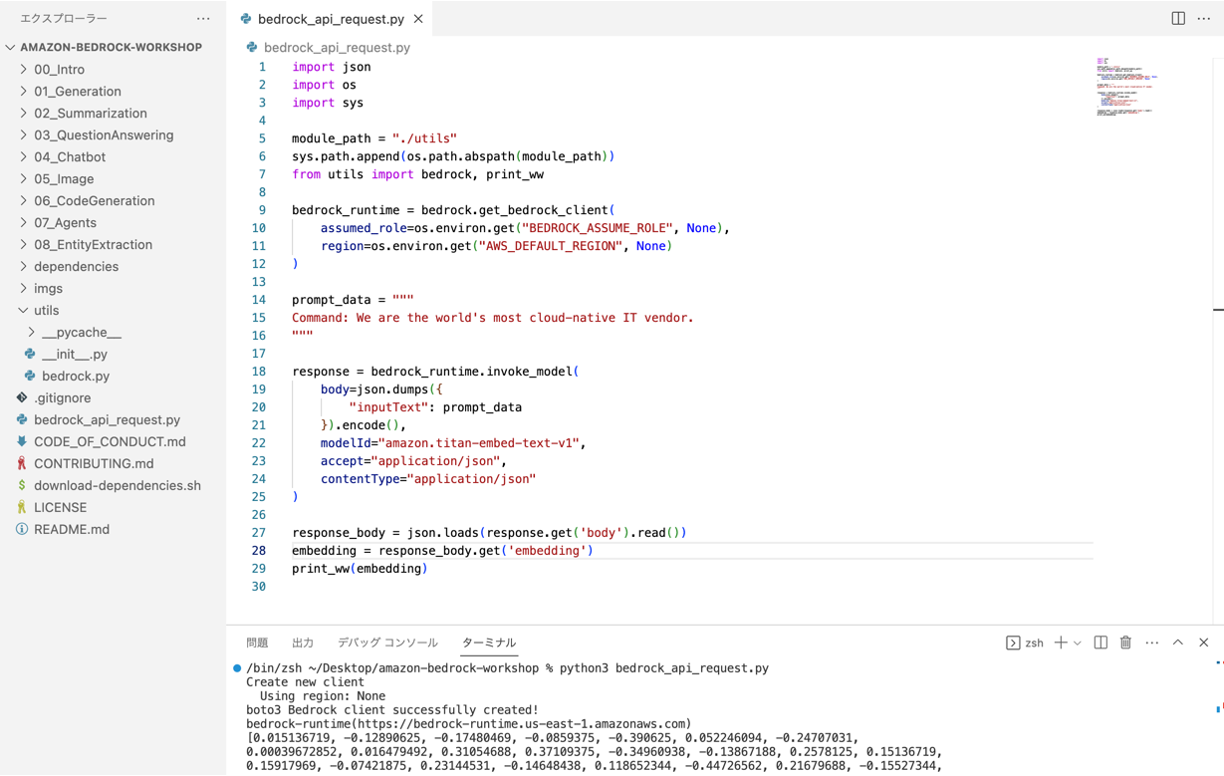
[0.015136719, -0.12890625, -0.17480469, -0.0859375, -0.390625, 0.052246094, ..., 0.109375]
と埋め込みベクトルが表示されました。私は見てもよく分かりませんが、生成できたので良しとします。
■ さいごに
Amazon Bedrockが公開されたことで、国内の生成型AIをビジネスに取り入れるシーンが増加する可能性が高まっていますね!
今後来るであろうVPCエンドポイントへの対応をしてもらえれば、閉域網の実現ができて、今後が楽しみですね!!
■ 参考サイト
Amazon Bedrock API Reference
Amazon BedrockのAPIをPythonアプリから呼んでみよう。LangChainにも挑戦!
Amazon BedrockをBoto3から使ってみた











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
