


 2023-12-02
2023-12-02


こんにちは、FIXER Rookies Advent Calendar 2023 ~ルーキー編~ 2日目を担当する小野です。
今日はタイトルにもある通り、S3からAurora PostgreSQLに復元する 方法について書いていきます。
この記事の画像は執筆時点のものです。現在は異なります。
スナップショットについて
普通にスナップショットを取ると、RDSのページで左側のリストにある"スナップショット"から復元やコピー、共有を行うことができます。
これをS3にエクスポートした場合、Apache Parquetという形式に圧縮されて保存されます。
そして、この時大幅にサイズが縮小され、例として出すとエクスポートする前のサイズの表記が600GBだったスナップショットが、S3にエクスポートすると13GBとなりました。
しかし、このApache Parquetに圧縮されたデータはAmazon Athena、 Amazon EMR、および Amazon SageMaker などで分析するのが主な用途として想定されているようです。
一応、Aurora MySQL、MySQLであれば復元できるのですが残念ながらPostgreSQLではサポートされていません。
なので、自力で復元することにしました。
復元方法
復元にはAWS Glue(以下Glue)というサービスを使います。
Glueとは公式サイトによると
AWS Glue は、サーバーレスなデータ統合サービスで、分析、機械学習 (ML)、アプリケーション開発用に、複数のソースからデータを検出、準備、移動、統合することをより容易にします。
これでS3からAurora PostgreSQLにデータを移動(複製)させるわけですね。
事前準備
Glueを使うにはいくつか準備が必要です。
本記事で扱うETLジョブでは、具体的に以下の4つが必要になります。
- RDSと後述のコネクションに割り当てるセキュリティグループ
- S3とRDSに接続するコネクション
- コネクションが引き受けるIAMロール
- 実際に実行するジョブ
また今回はデータベースの復元を行うので、Secrets Managerに復元するRDSのusername、password、endpoint、dbnameを保存したシークレットが存在することも前提とします。
セキュリティグループを作成
セキュリティグループではタイプ"すべてのトラフィック"、ソースはカスタムで編集しているセキュリティグループ自身を許可します。
作成と同時に設定はできないので、一旦なにもインバウンドルールを許可しないセキュリティグループを作成し、その後に自分自身を許可してください。
作成、設定までできたら復元したいRDSにアタッチしてください。
コネクションを作成
Glueのページに移動し、左のハンバーガーメニューからData connectionsまたはConnections(緑丸)をクリックするとこの画面になります。
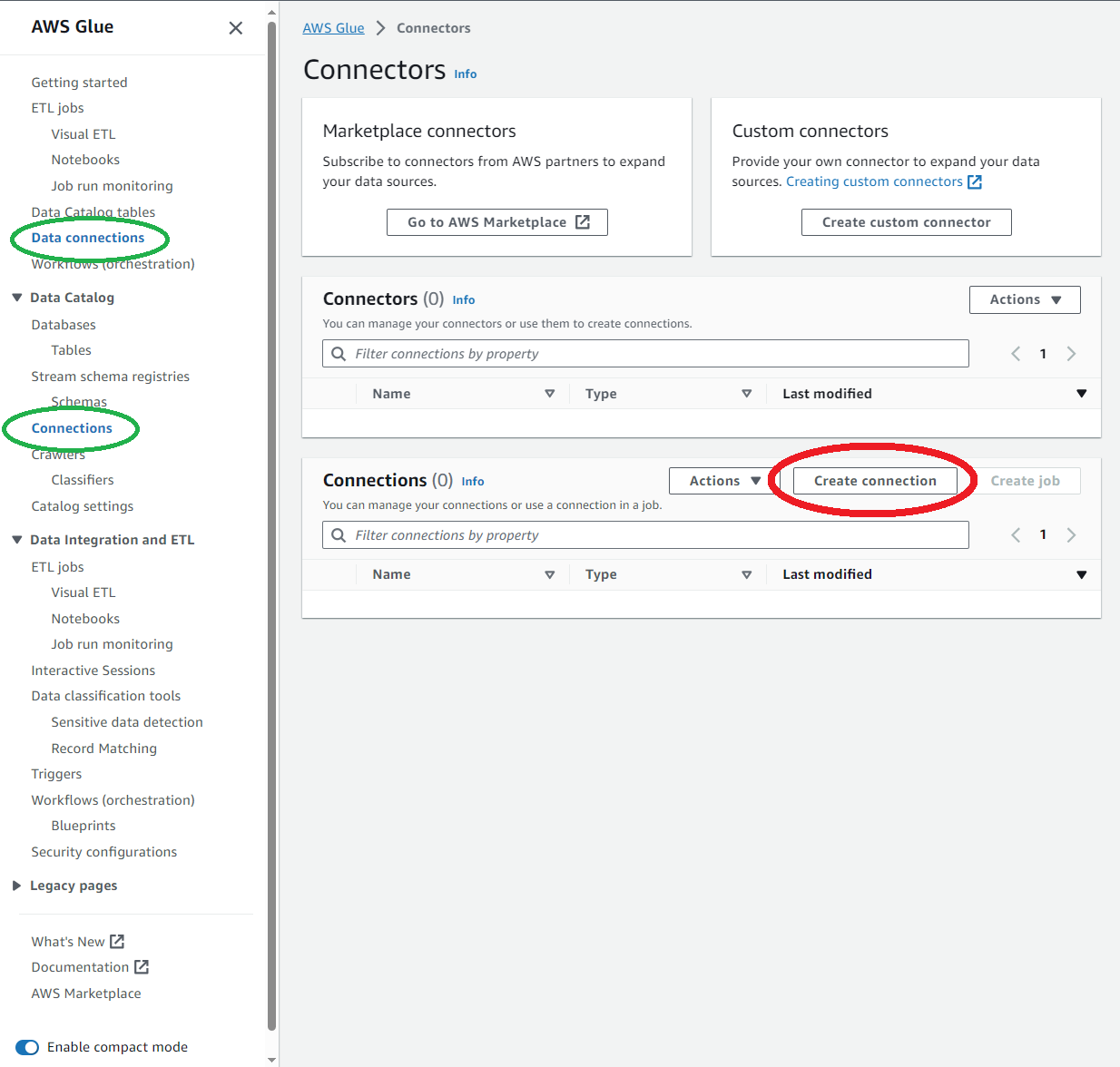
次に(赤丸)のCreate connectionをクリックします。
すると、このような画面になるのでJDBCをNetworkに変更します。
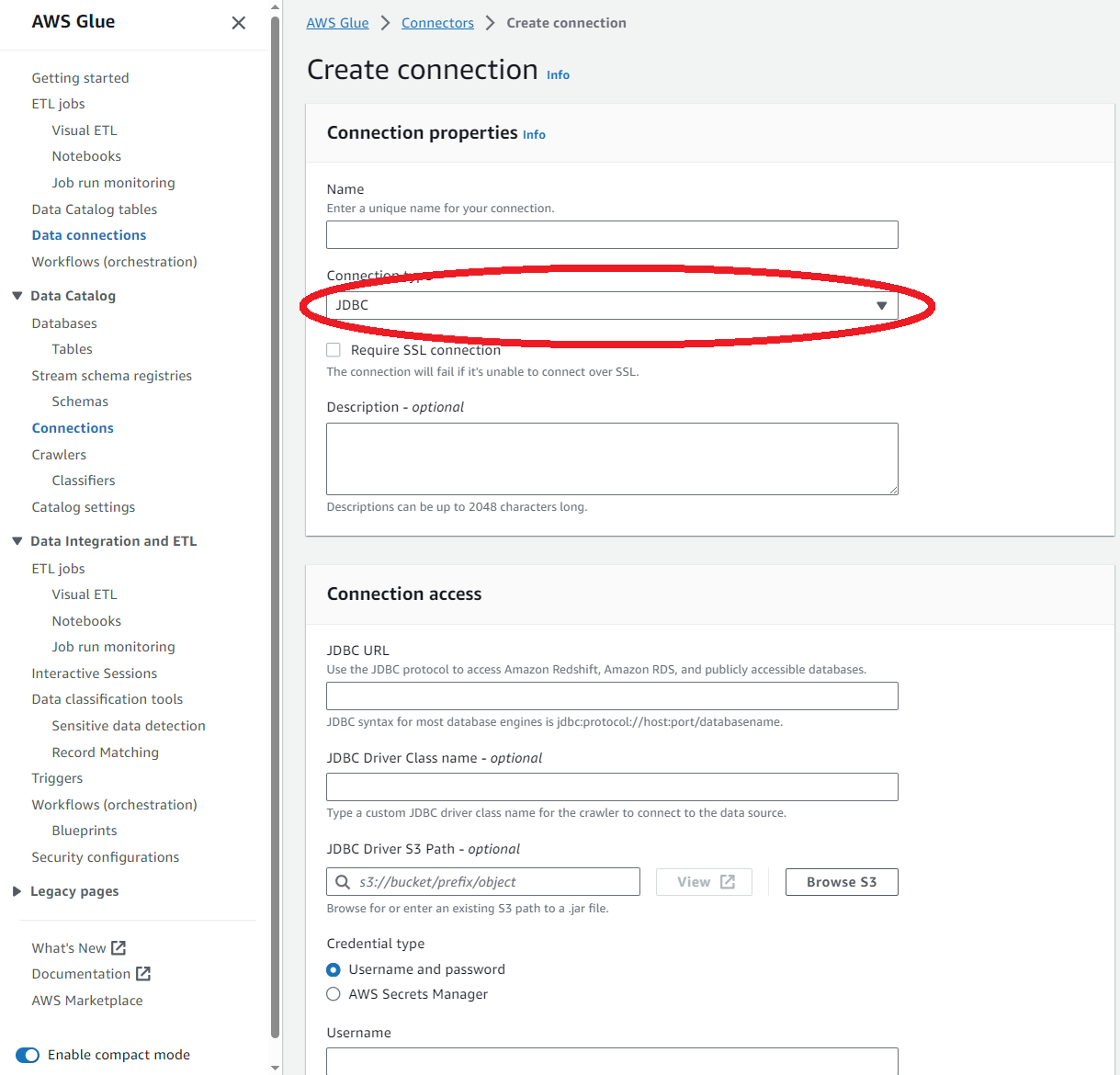
するとこのように、テキストボックスが一気に減るのでNameとDescriptionを適当に埋めます。
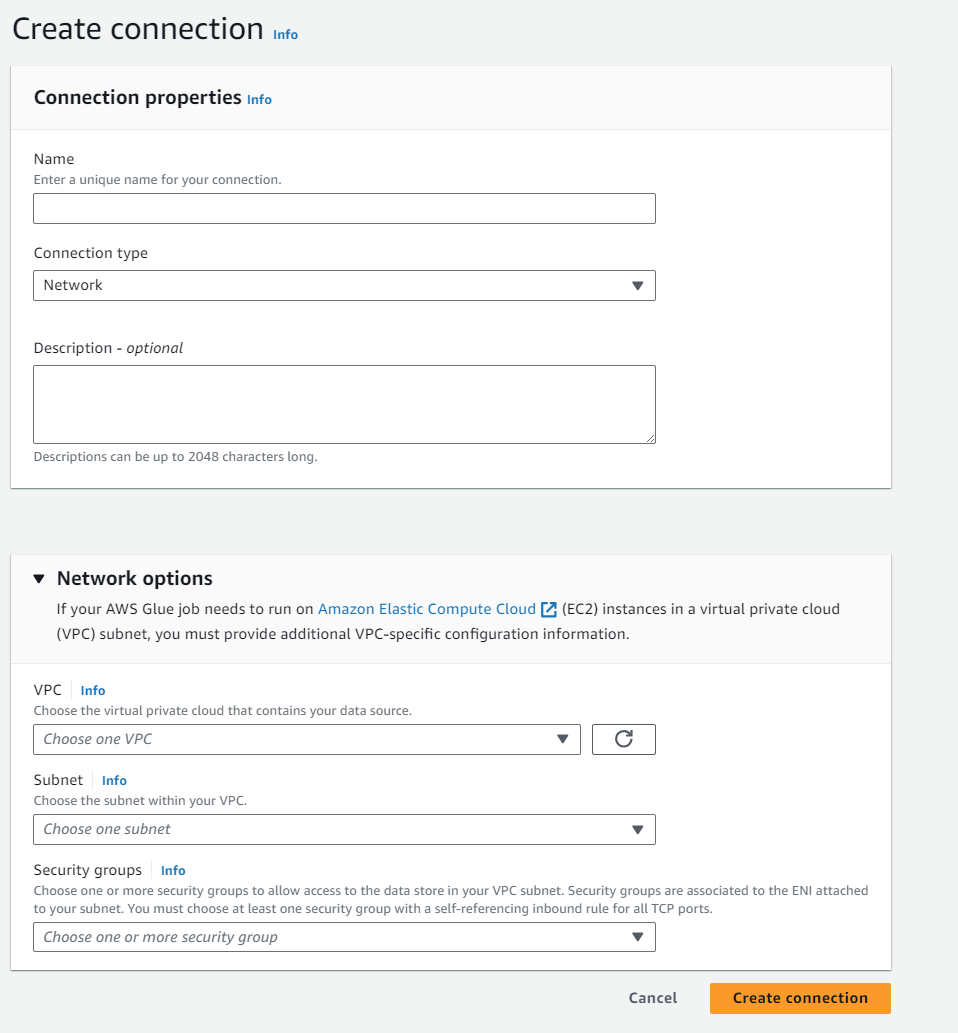
Network optionsを開いてVPCに復元したいRDSがあるVPCを、SubnetにRDSへのルートがある且つS3エンドポイントかNATゲートウェイへのルートがあるサブネットを、Security groupsに先ほど作成したセキュリティグループを設定してCreate connectionをクリックします。
サブネットは、可能であればNATゲートウェイへのルートがあるサブネットを推奨します。
IAMロールの作成
Glueでジョブを実行するロールには以下のような信頼関係が必要です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}また許可ポリシーは
- AWS管理ポリシーであるAWSGlueServiceRole
- 実行するスクリプトやスナップショットをS3から読み取るための"s3:Get*"、"s3:List*"
- スナップショットを復号するためのkms:Decrypt
- RDSへの認証情報を取得するためのsecretsmanager:GetSecretValue
を許可します。
Glueでジョブを実行するだけであれば1、2の許可があればOKですが、今回はスナップショットからRDSに復元を行うのでさらに3、4を許可しています。
ジョブの作成
作成したコネクションを選択してCreate jobを選択します。
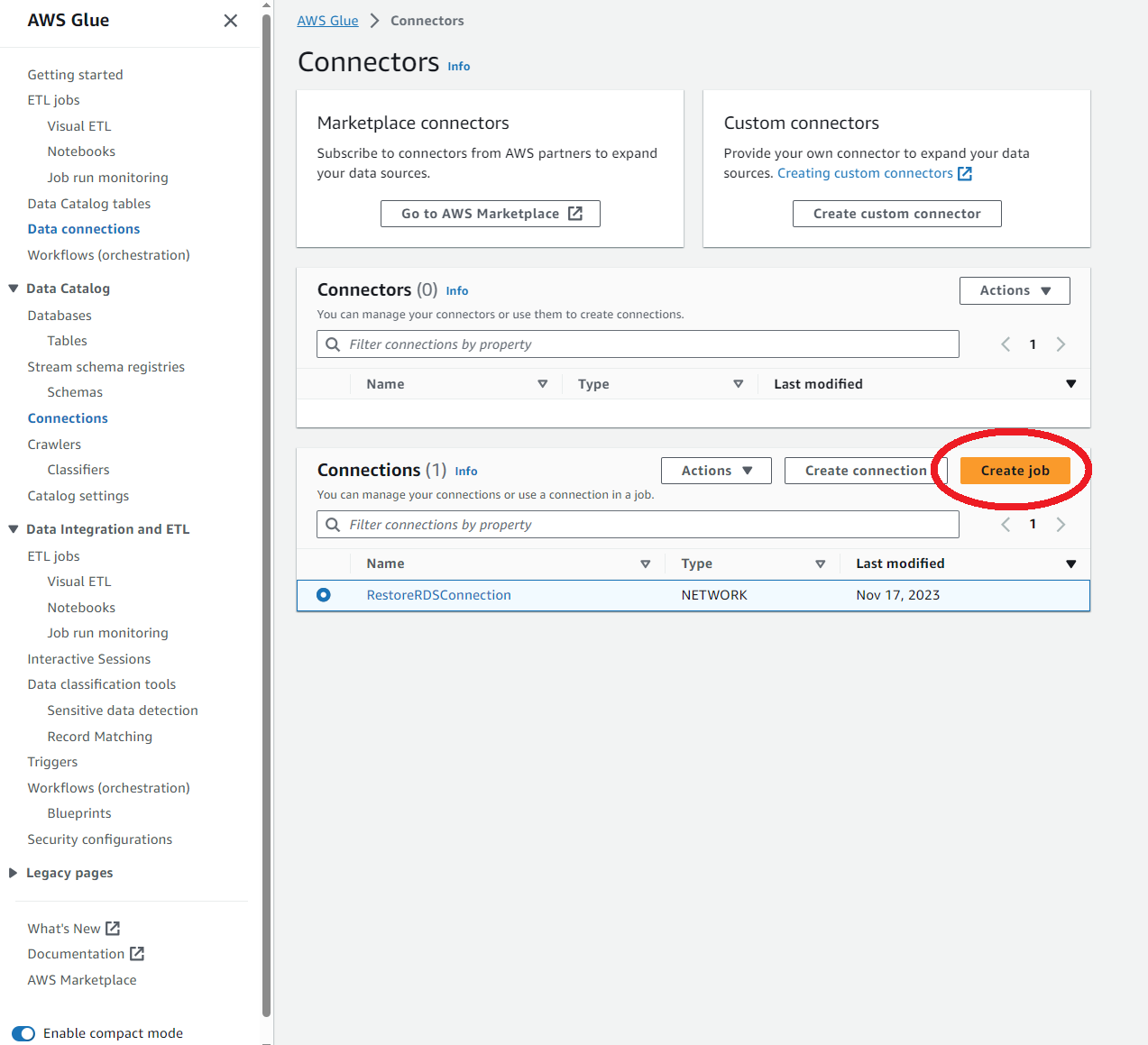
するとVisual Editorは使えないよ的な警告が出るので、もう一度Create jobをクリックします。
そしたら、このような編集画面が出てきます。
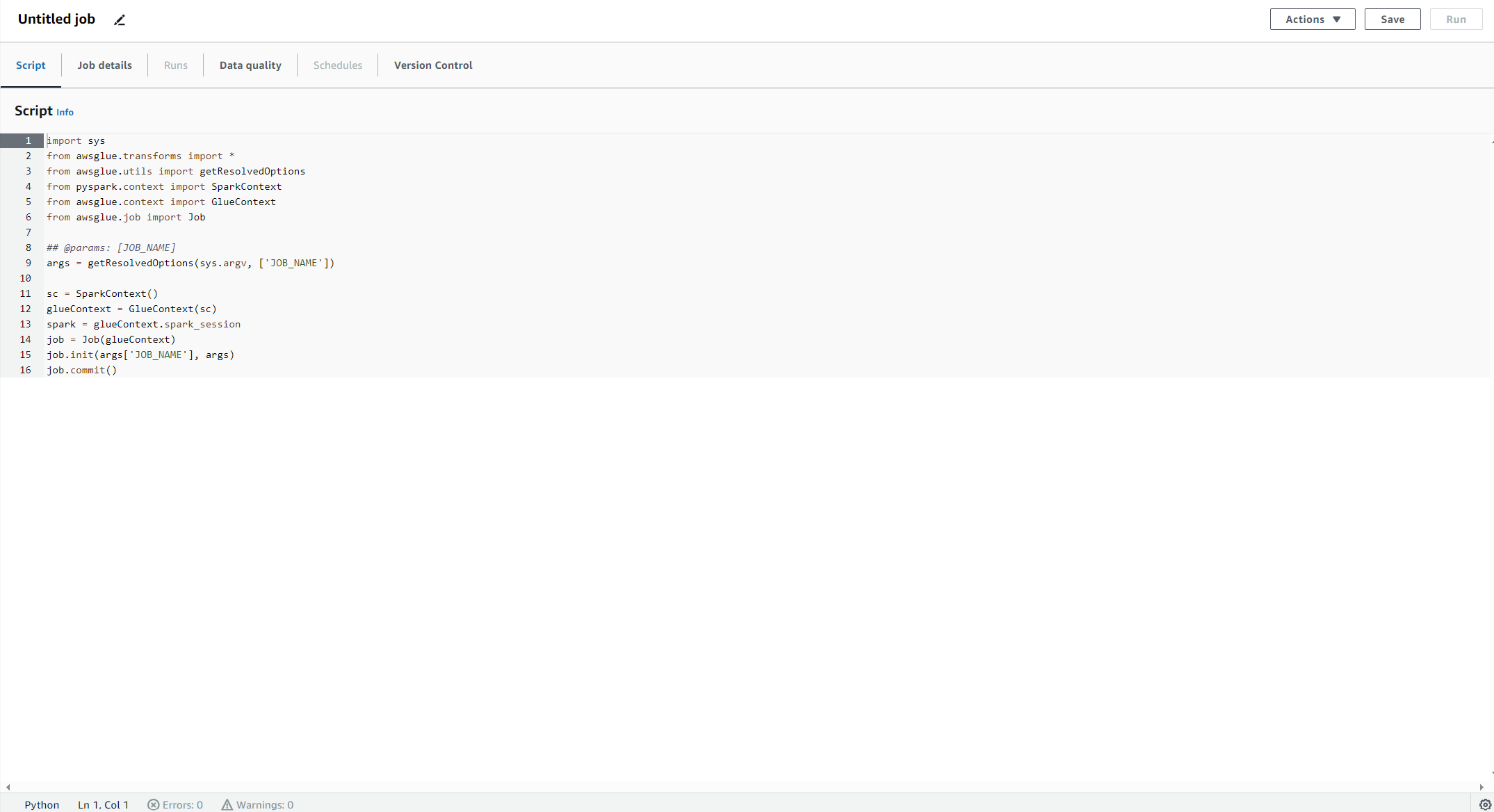
スクリプト作成
ここにPythonのスクリプトを書いていきます。
今回はこのようなスクリプトを書きました。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
import boto3
import json
import pg8000
args = getResolvedOptions(sys.argv, ["JOB_NAME", "SNAPSHOT_IDENTIFIER", "TABLE"])
# DBへの接続情報取得
session = boto3.session.Session()
client = session.client(service_name='secretsmanager')
try:
response = client.get_secret_value(SecretId='シークレット名')
secret_data = response['SecretString']
except Exception as e:
print(f"Failed to retrieve secret: {str(e)}")
secret_data = json.loads(secret_data)
password = secret_data["password"]
database = secret_data["dbname"]
user = secret_data["username"]
endpoint = secret_data["endpoint"]
snapshot = args["SNAPSHOT_IDENTIFIER"]
table = args["TABLE"]
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
noException = True
# S3からデータ取得
S3bucket_node1 = glueContext.create_dynamic_frame.from_options(
format_options={},
connection_type="s3",
format="parquet",
connection_options={
"paths": [
f"s3://{"スナップショットを保存しているバケット名"}/{snapshot}/venhidbapne1/standard.{table}/"
],
"recurse": True,
},
transformation_ctx="S3bucket_node1",
)
mapping = []
try:
# 型変換
conn = pg8000.connect(host=endpoint, database=database, user=user, password=password)
cur = conn.cursor()
cur.execute(f"SELECT column_name, data_type FROM information_schema.columns WHERE table_name = '{table}' ORDER BY ordinal_position")
columns = cur.fetchall()
for column in columns:
mapping.append((column[0], 'String', column[0], column[1]))
cur.close()
# TRUNCATE実行
cur = conn.cursor()
cur.execute(f"TRUNCATE TABLE {table}")
conn.commit()
except:
noException = False
finally:
cur.close()
conn.close()
if noException:
mapped_frame = ApplyMapping.apply(frame = S3bucket_node1, mappings = mapping)
# 復元
PostgreSQLtable_node2 = glueContext.write_dynamic_frame.from_options(
frame=mapped_frame,
connection_type="postgresql",
connection_options={
"url": f"jdbc:postgresql://{endpoint}:5432/{database}?currentSchema=standard",
"dbtable": table,
"user": user,
"password": password,
"bulkSize": 100,
},
transformation_ctx="PostgreSQLtable_node1",
format_options={
"useGlueParquetWriter": True,
},
)
job.commit()
注意すべき点として、
- write_dynamic_frameは上書きではなく追加
- スナップショットから直接エクスポートした場合型がすべてStringになる。
があります。
なので、pg8000を使って事前にTRUNCATEし、型情報を取り出して復元前にApplyMapping.applyで変換をかけています。
しかしpg8000はインストールされていないので、用意してやる必要があります。
それについては後述します。
ジョブの詳細設定
Job detailsを選択するとこのような画面になります。
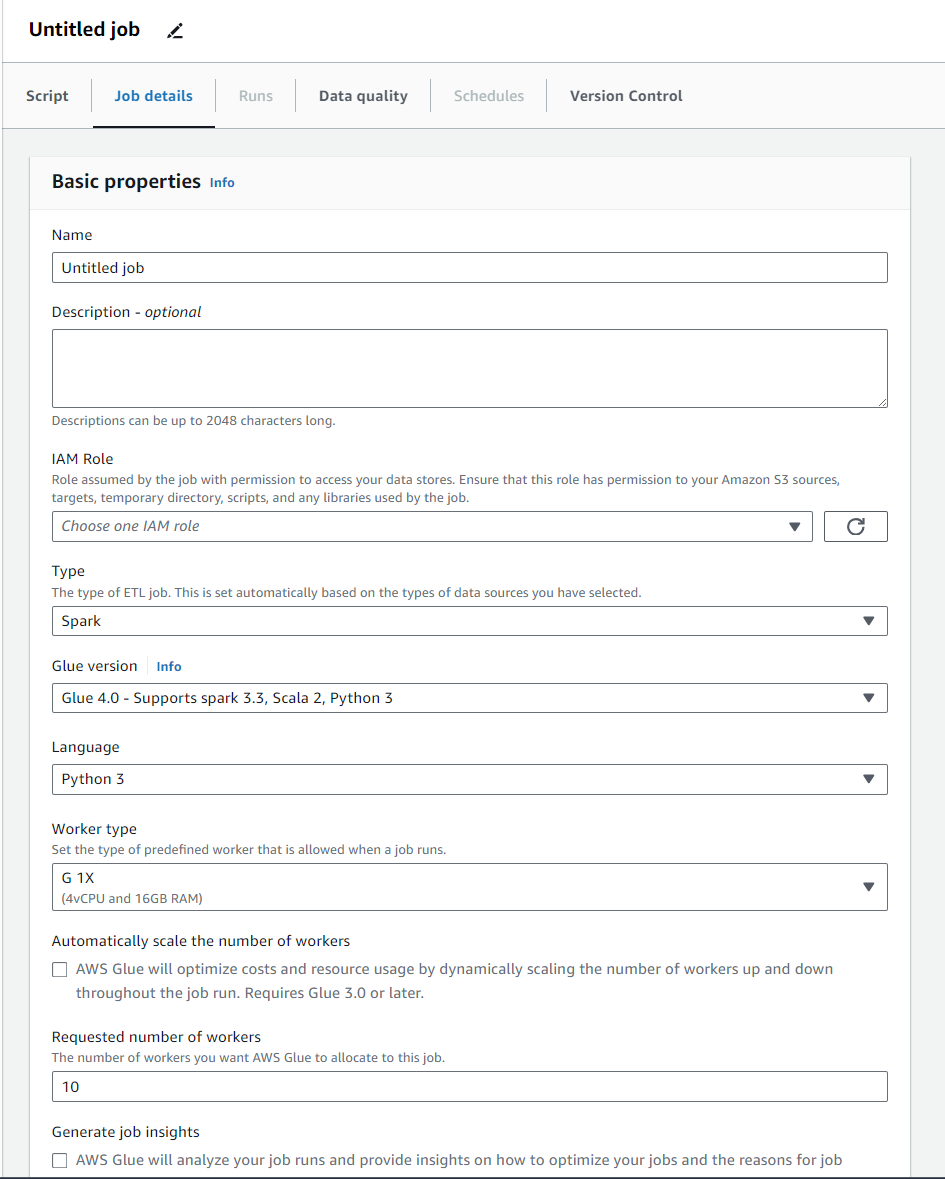
Nameにはジョブの名前、IAM Roleには作成したIAMロールを入れます。
そのほかのBasic propertiesは一旦そのままで問題ありません。
続いてAdvanced propertiesを開きます。
ここでデフォルトで使えるライブラリ以外のライブラリ(今回はpg8000)をジョブの中で使えるようにしていきます。
コネクションがNATゲートウェイへのルートがある(インターネットに出ることができる)かどうかで方法が異なるのでそれぞれ説明します
NATゲートウェイへのルートが無い場合
インターネットに出られない場合は、自分でPYPIからダウンロードしてきたtar.gzファイルを、展開後にzipに圧縮し直してS3にアップロードする必要があります。
このとき依存ライブラリがある場合はそれも同様にダウンロード→展開、zip圧縮→S3にアップロードを行わなければなりません。
pg8000を例に挙げると、pg8000のほかにscramp、asn1cryptoの2つもzipをアップロードする必要があります。
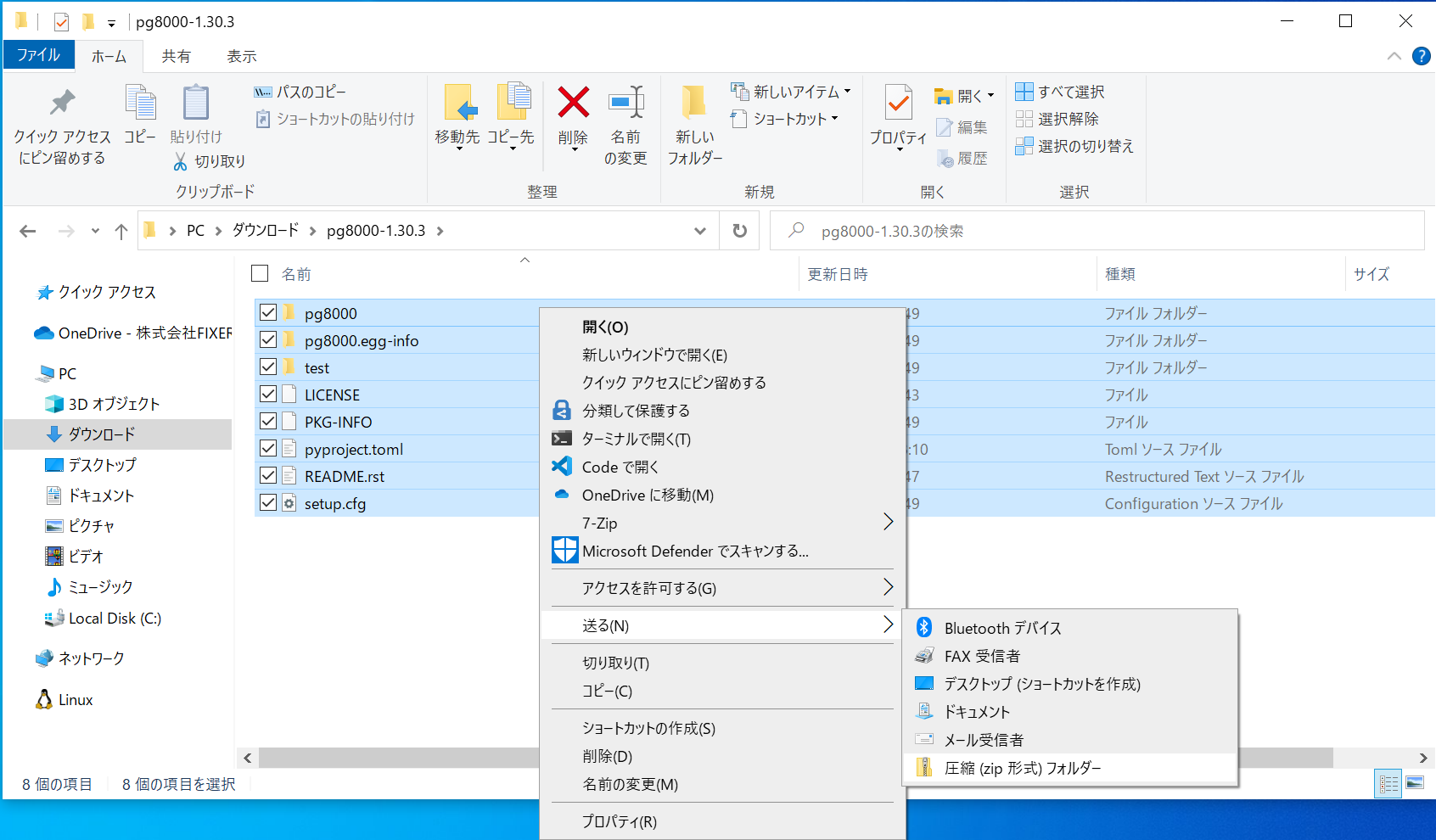
またzip圧縮する際に注意点があり、setup.cfgやpyproject.tomlなどを選択した状態で圧縮しなければなりません。
下の画像での、pg8000-1.30.3フォルダを選択して圧縮しても意味がないので気をつけてください。
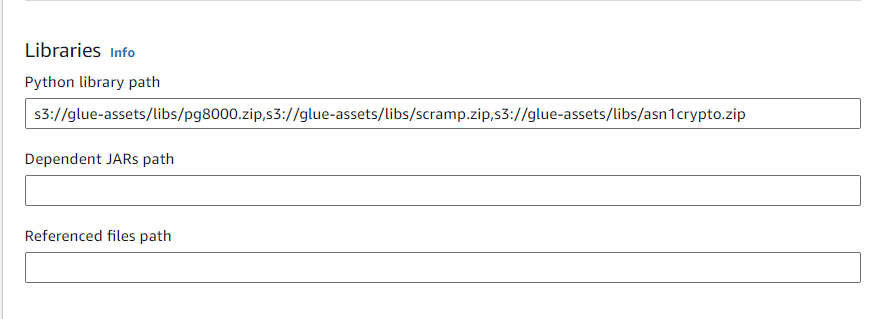
S3にzipをアップロードしたら、Glueで使えるように場所を教えてやります。
LibrariesのPython library pathにzipのS3URIを入れます。
複数のzipがある場合は","で区切り、間にスペースを入れてはいけません。
これでライブラリが使えるようになりました。
NATゲートウェイへのルートがある場合
インターネットに出られる場合はもう少し楽になります。
Job parametersのKeyに--additional-python-modules、Valueにインストールしたいライブラリ名(今回はpg8000)を入れることでpip3を使ったインストールを行うことができます。
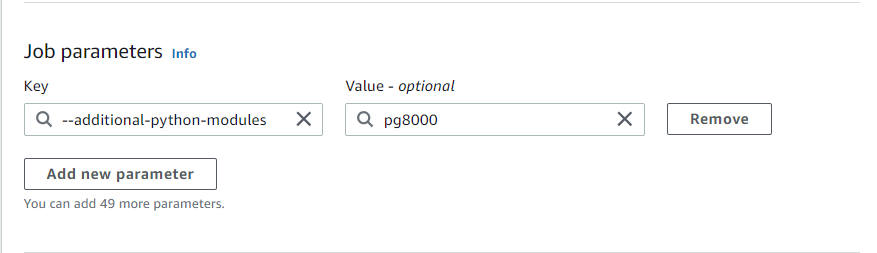
これでライブラリが使えるようになりました。
もちろん、NATゲートウェイへのルートが無い場合の方法を使うこともできます。
どちらの場合でも最後に右上のSaveをクリックするのを忘れないようにしてください。
復元実行
それでは復元を実行してみましょう。
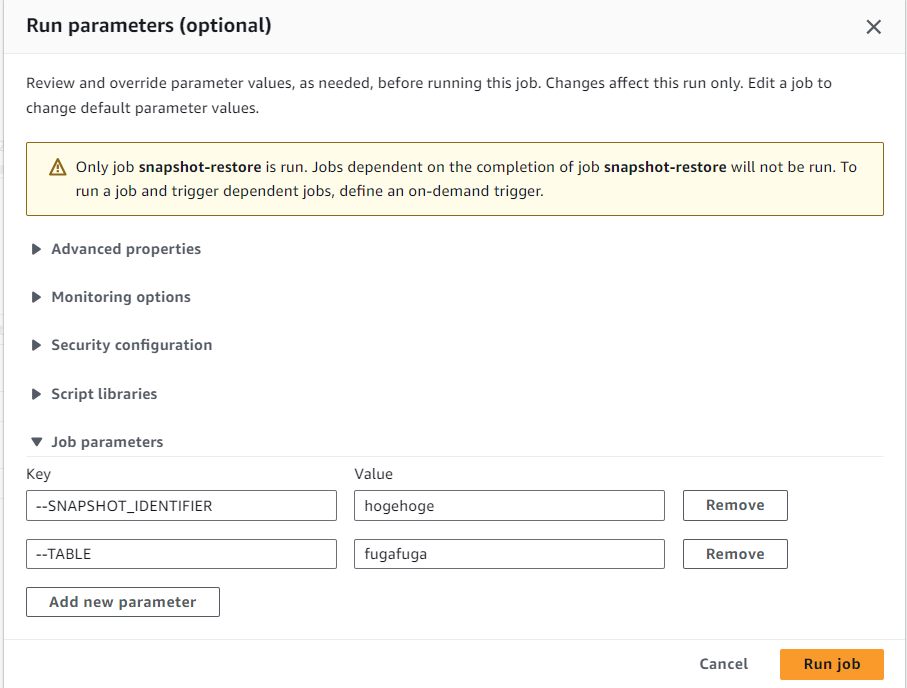
左上のActionsからRun with parametersを選択し、Job parametersを開きます。
Add new parameterを2回クリックし、Keyに--SNAPSHOT_IDENTIFIERと--TABLE、Valueにスナップショットの識別子とテーブル名を入れてRun jobをクリックします。
Runsタブに新しく追加されるのでRun statusがSucceededになれば完了です。

最後に
これでApache Parquetに圧縮されたデータからAurora PostgreSQLに復元することができました。
ここで作成したPythonスクリプトはデフォルトだと
s3://aws-glue-assets-アカウントID-リージョン名/scripts/に保存されます。またJob parameterも平文で見ることができるのでクレデンシャル情報はベタ書きや引数で渡したりせずに、今回のようにSecrets Managerのシークレット経由で取得するようにしましょう。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
