


 2024-05-22
2024-05-22

目次

- 自作LLMモデル作ってみた。
- アーキテクチャ
- トークナイザクラス
- トークナイザの役割
- トークナイザクラスの構造
- トークン化プロセス
- 具体例
- まとめ
- マルチヘッドアテンション(Multi-Head Attention)クラスとヘッドクラス(HeadClass)
- イントロダクション
- マルチヘッドアテンション(Multi-Head Attention)の本質
- ヘッドクラスの構造
- ヘッドクラスの役割
- ヘッドクラスの重要性
- まとめ
- フィードフォワードクラス
- イントロダクション
- フィードフォワードクラスの役割
- フィードフォワードクラスの構造
- フィードフォワードクラスの構造
- フィードフォワードクラスの重要性
- まとめ
- ブロッククラス
- イントロダクション
- ブロッククラスの本質
- ブロッククラスのの構造
- ブロッククラスの操作
- ブロッククラスの重要性
- まとめ
- MyLanguageModelクラス
- MyLanguageModelクラスの概要
- MyLanguageModelクラスの構造
- MyLanguageModelクラスの機能
- MyLanguageModelクラスの重要性
- まとめ
- トレーニングと評価関数
- イントロダクション
- トレーニング関数の説明
- 評価関数
- GPTモデルにおける重要性
- まとめ
- 全体のまとめ
- おまけ
- 参考文献
自作LLMモデル作ってみた。
最近ChatGpt、GaiXerなどの生成AIを使った商品が有名になってきています。その裏で動いてるLLM(Large Language Model)を理解するために、また仕事でLLMを触れ初めて、何も知らなかった新人研修時代(気づいたら一年以上前に。。。)にLLMモデルの挙動を理解するために自作してみました。自分で作ったものを思い出す意味も含めて、今回のブログを書いてみました(書き始めたの、去年の8月くらい。。。)。
アーキテクチャ
今回作成したモデルはGPTと同じくdecoder-onlyモデルとなります。 Transformerのdecoderを参考に作っています。 Transformerの構造は以下の図のようになっています。
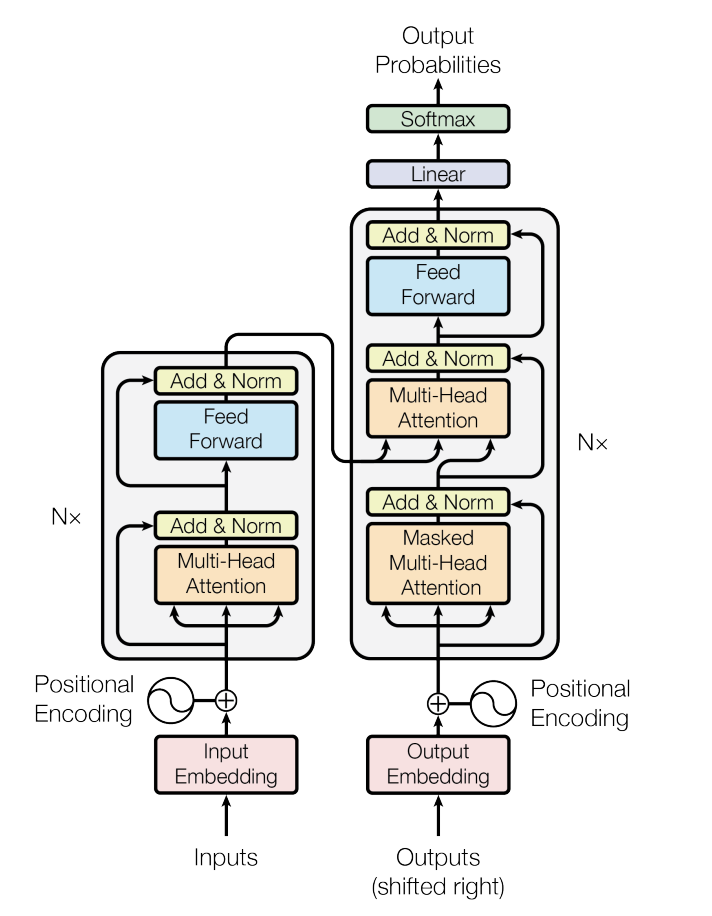
出典:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
ただし、これにはEncoderとDecoderの両方の構造が含まれています。ここから以下の図のようにDecoder部分を取り出し、その一部を変更してモデルを作成しています。
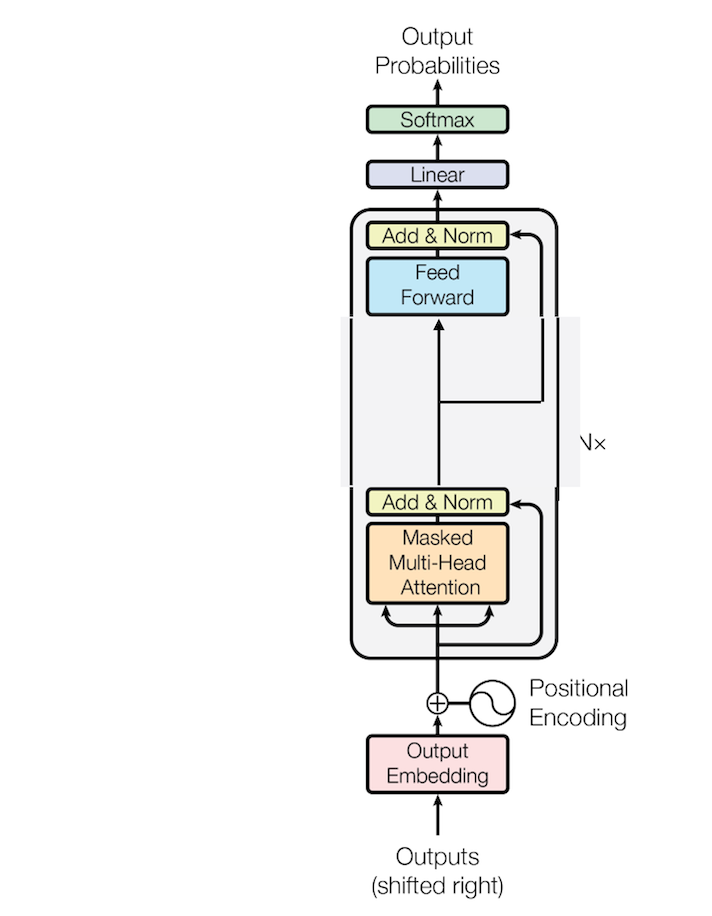
出典:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
トークナイザクラス
自然言語処理(NLP)の領域において、トークナイザは、人間の言語を機械が理解し処理できる形式に翻訳する基本的なステップとして機能します。今回の独自LLMモデルにおけるトークナイザクラスは、この重要な役割を果たし、テキストを数値トークンに変換し、その逆も行います。
トークナイザの役割
人間と機械の言語の架け橋: トークナイザは翻訳者として機能し、人間が読めるテキストをテキスト内の各文字や単語を表す整数(トークン)の連続に変換します。この変換は、GPTのようなニューラルネットワークが数値データのみを理解するため、不可欠です。
表現の一貫性: 固定された文字や単語の語彙を維持することにより、トークナイザはモデルが同じテキスト要素を毎回同じトークンで一貫して表現することを保証します。
処理の効率化: トークン化により、モデルはテキストをチャンク(トークン)として処理できます。これは、個々の文字や全文を扱うよりも効率的です。
トークナイザクラスの構造
コード
class Tokenizer():
def __init__(self, characters_list:list) -> None:
self.characters_list = characters_list
# 文字列を整数にマッピングする
def mapStringToInt(self):
self.MapStrToInt = {ch:i for i, ch in enumerate(self.characters_list)}
return self.MapStrToInt
# 整数から文字列へのマッピング
def mapIntToString(self):
self.MapIntToStr = {i:ch for i, ch in enumerate(self.characters_list)}
return self.MapIntToStr
# 文字列から整数への変換
def encoder(self, string:str):
CharMaps=self.MapStrToInt
return [CharMaps[c] for c in string]
# 整数から文字列への変換
def decoder(self, int_list:list):
CharMaps=self.MapIntToStr
return ''.join([CharMaps[i] for i in int_list])
変数
characters_list: トークン化に使用されるユニークな文字の包括的なリスト(モデルの語彙)。このリストは、エンコードとデコードの両プロセスの基盤を形成します。
MapStrToInt: characters_listの各文字をユニークな整数にマッピングする辞書。このマッピングは、テキストをトークンに変換するエンコードプロセスにとって基本的です。
MapIntToStr: 整数を文字に戻す対応する辞書。この逆マッピングは、トークンの連続を人間が読めるテキストに変換するデコードプロセスにとって重要です。
コアメソッド
mapStringToInt: このメソッドはMapStrToIntマッピングを作成します。これは、語彙内の各文字にユニークな整数を割り当てる一度きりの設定プロセスです。
mapIntToString: 同様に、このメソッドはMapIntToStrマッピングを設定します。モデルがその出力をテキストに戻すために不可欠です。
encoder: エンコーダメソッドは、文字のシーケンス(文字列)をMapStrToIntマッピングを使用して整数(トークン)のリストに変換します。この変換は、任意のテキストをモデルを通して処理する最初のステップです。
decoder: デコーダメソッドは、エンコーダの逆の操作を行います。トークン(整数)のシーケンスを取り、それをMapIntToStrマッピングを使用して文字列に戻します。このメソッドは、モデルの出力から人間が読めるテキストを生成するために重要です。
トークン化プロセス
GPTモデルにおけるトークン化のプロセスには、主に2つのステップが含まれます:
エンコード(トークン化): ここでは、encoderメソッドが入力テキストを取り、それをトークンの連続に変換します。このプロセスには、テキスト内の各文字をMapStrToInt辞書で検索し、それに対応する整数に置き換えることが含まれます。
デコード(デトークン化): モデルがトークン化されたテキストを処理した後、出力(トークンでも)をテキストに戻す必要があります。decoderメソッドはこれらのトークンを取り、MapIntToStr辞書で検索し、元のテキストまたはこれらのトークンに基づいて生成されたテキストを再構築します。
具体例
理解を深めるために、実践的な例を考えてみます。characters_listにはシンプルな文字セットが含まれていると仮定します:[a, b, c, ..., z]。そして、以下のマッピングがあります:
MapStrToInt = {'a': 1, 'b': 2, ..., 'z': 26}MapIntToStr = {1: 'a', 2: 'b', ..., 26: 'z'}
今、もし「cat」という単語をトークン化したい場合、encoderメソッドはそれを[3, 1, 20]に変換します。逆に、もしモデルがトークン[2, 1, 20]を出力した場合、decoderメソッドはこれを「bat」という単語に戻します。
まとめ
GPTのようなモデルの動作に深く潜るためには、トークナイザクラスを理解することが重要です。これは、これらのモデルがテキストをどのように処理するかの基盤を築くだけでなく、生のテキストから洞察に富んだ予測や生成への旅の最初のステップをも照らし出します。
マルチヘッドアテンション(Multi-Head Attention)クラスとヘッドクラス(HeadClass)
イントロダクション
GPTモデルの複雑さと、洗練された言語特徴を把握する能力は、革新的なマルチヘッドアテンション(Multi-Head Attention)メカニズム、そしてそれにおけるヘッドクラスの重要な役割によるものです。このメカニズムにより、モデルは入力テキストの異なる部分から情報を抽出し、それを統合することで、より複雑な文脈や関係性を理解することが可能になります。
マルチヘッドアテンション(Multi-Head Attention)の本質
ヘッドクラスを理解するには、まずマルチヘッドアテンション(Multi-Head Attention)のコンセプトを理解することから始めます。このメカニズムは、モデルが入力シーケンスの異なる部分を同時に処理することを可能にし、テキスト内のコンテキストと関係性を豊かに理解することを可能にします。このアプローチにより、モデルは複数の視点から入力データを分析し、異なるタイプの関係やパターンを識別できます。
ヘッドクラスの構造
コード
Python# Single Head
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embed, head_size, bias=False)
self.query = nn.Linear(n_embed, head_size, bias=False)
self.value = nn.Linear(n_embed, head_size, bias=False)
self.register_buffer("tril", torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def ScaledDotProductAttention(self, k, q, B, T, C):
# 行列の積 + スケール (MatMul + Scale)
weight = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, head_size) @ (B, head_size, T) --> (B, T, T)
# マスキング (Opt)
weight = weight.masked_fill(self.tril[:T,:T] == 0, float('-inf')) # (B, T, T) # 過去のトークンからの情報を集約しないようにするため、ゼロの部分を無限大に設定します
# SoftMax
weight = F.softmax(weight, dim = -1) # 重みを正規化
weight = self.dropout(weight)
# 値の重み付き集約を実行
v = self.value(x) # シングルヘッドの目的のために集約されるもの
weighted_values = weight @ v
return weighted_values
def forward(self, x):
B,T,C = x.shape
k = self.key(x) # (B, T, head_size)
q = self.query(x) # (B, T, head_size)
# アテンションスコアの計算 # スケールドドットプロダクトアテンション
weighted_values = self.ScaledDotProductAttention(k, q, B, T, C)
return weighted_values
# パラレルなセルフアテンションのマルチヘッド
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(n_embed, n_embed)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# スケールドドットプロダクトアテンションと連結
out = torch.cat([h(x) for h in self.heads], dim=-1)
# 最後の線形層
out = self.proj(out)
out = self.dropout(out)
return out
- 変換層 (key, query, value):
key: キーは、入力データ内の各トークンを表すベクトルです。これらのキーは、クエリと比較され、どのトークンが注目に値するかを判断するのに使用されます。query: クエリは、モデルが入力データのどの部分に注目するかを決定するための参照点です。各トークンに対して、関連する情報を検索するための基準を提供します。value: 値は、最終的にアテンションスコアに基づいて加重され、出力ベクトルの形成に寄与するトークンの情報を含んでいます。
- アテンションマスキング (mask): 特定の位置の予測がそれ以前の位置の既知の出力にのみ依存できるようにするためのメカニズムです。このマスキングにより、未来のトークンからの情報の漏洩を防ぎ、モデルが時系列データの順序を維持するのに役立ちます。具体的には、
weightテンソルの対角要素より上の部分を -inf に置き換えることで、上三角行列の部分を無視するようにしています。その結果、softmax 関数を適用した後の重みがほぼ 0 になります。これにより、自己注意メカニズムが入力シーケンスの過去のトークンのみを考慮するようになります。 それぞれの weight の結果の例は以下のようになっています。詳しくは下で説明します。
この例では、weight テンソルの要素がSoftMax関数を適用する前と後でどのように変化するかを示しています。マスキング操作により、上三角行列の要素が -inf(${-\infty}$) に置き換えられ、SoftMax関数を適用した後、これらの要素の重みがほぼ 0 になります。これにより、モデルが過去のトークンの情報のみを考慮するようになります。
- 正則化 (dropout): トレーニングプロセスにランダム性を導入することにより、過学習を防ぐためのコンポーネントです。これは、モデルが特定の入力特徴に過度に依存するのを防ぎ、汎用性のある特徴抽出を促進します。
B(Batch) はバッチサイズを表し、並列に処理されるシーケンスの数です。T(Time) はシーケンスの長さを表し、各シーケンス内のトークンの数です。C(Channel) は特徴の次元数を表し、入力トークンの埋め込みの次元数です。
これらの変数は、入力テンソルの形状を定義し、それに応じて操作を実行するために使用されます。これらの次元を正しく理解することは、テンソルの操作やアテンションメカニズムの計算を正確に行うために重要です。
Dropoutは「Dropout: A Simple Way to Prevent Neural Networks from Overfitting」で紹介された手法で、下の図のよう一部のニューロンをランダムに無効化しています。
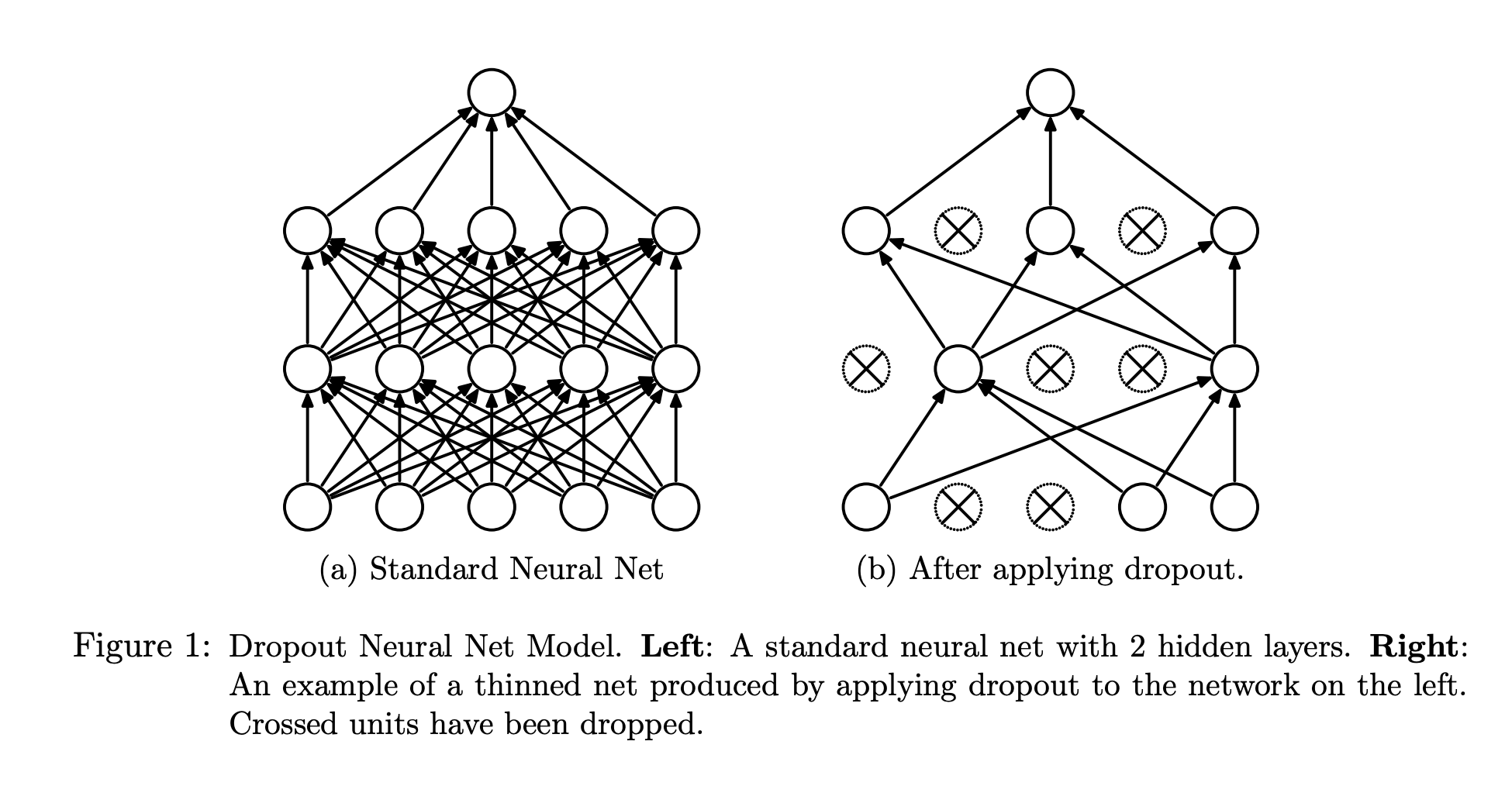
出典:Srivastava, Nitish, et al. "Dropout: a simple way to prevent neural networks from overfitting." The journal of machine learning research 15.1 (2014): 1929-1958.
コアメソッド
- ComputeAttentionScore: 異なるトークンの影響をバランスよく取るために、ComputeAttentionScoreを使用してアテンションスコア(weight)を計算します。このメカニズムにより、モデルはシーケンス内の各トークンが他のトークンとどのように関連しているかを評価し、関連性の高いトークンに重みを置きます。
- フォワードパス (forward): ヘッドを通るデータの流れを定義し、キー、クエリ、値の変換を組み合わせ、アテンションスコアを計算します。このプロセスは、モデルが入力データをどのように処理し、関連情報を集約するかを決定します。
ヘッドクラスの役割
入力の変換: 最初に、入力トークンはキー、クエリ、および値のベクトルに変換されます。このステップは、トークンを注意メカニズムの準備をします。
アテンションスコアの計算: 次に、ヘッドはアテンションスコアを計算し、入力の異なる部分にどれだけの焦点を当てるかを決定します。
マスキングとドロップアウトの適用: マスキングはシーケンシャルデータの整合性を保証し、ドロップアウトは正則化を追加します。
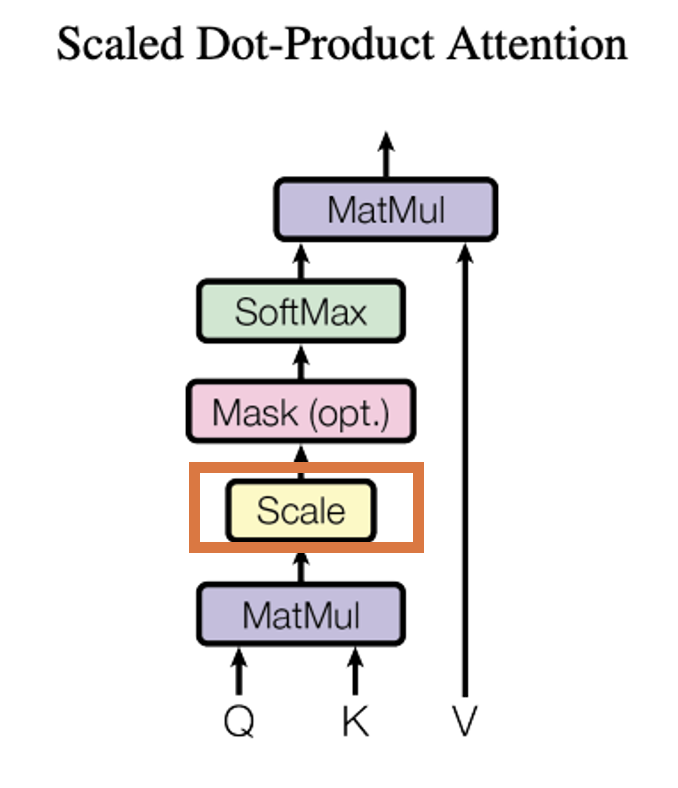
Headの考え方 Headの考え方はScale Dot-Product Attentionをもとに作っています。以下の図が「Transformerの論文に描かれている図です。
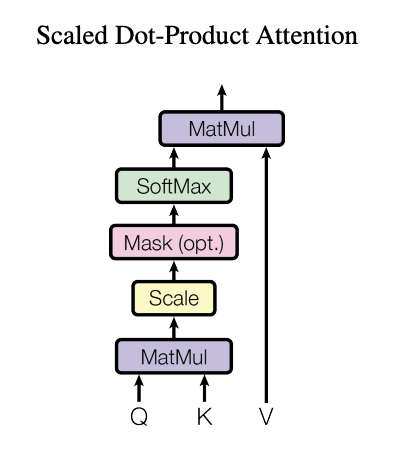
出典:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
Scaled Dot-Product Attention を簡単に説明すると入力に基づいて重みを変えられるニューラルネットワークです。QueryとKeyを入力として受けてsoftmaxを適用するまでのパスで行列(Attention Matrix)が計算されます。そして、Attention MatrixとValueの内積処理(MutMul)は、線形層(=活性化関数が恒等関数のニューラルネットワーク)の処理を行っているのと同義です。つまり、Valueを入力とし、Attention Matrixを重み行列とするニューラルネットワークと見なすことができます。Attention Matrixは入力に応じて変化するので、これを重み行列とするニューラルネットワークは、入力に応じてネットワークの特性を変えることができます。この自在に形を変えれる性質のため、「文脈理解」、「効率的な処理」、「学習の柔軟性」を持つことができるようになっています。
それぞれのMatMul, Scale, Mask, SoftMax, Matmulで行っていることを詳しくみていきましょう。
例えば、以下のように「I Work At FIXER Inc.!」をベクトル化すると以下のようになったとします。
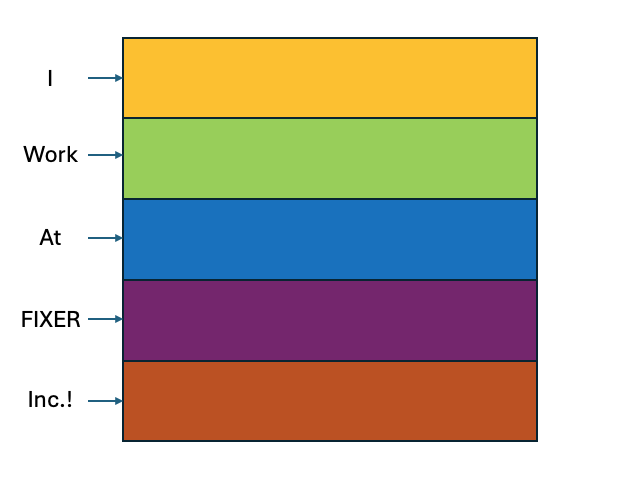
すると、$Q$, $V$, $K^T$ ($K$の転置行列) は以下のようになります。
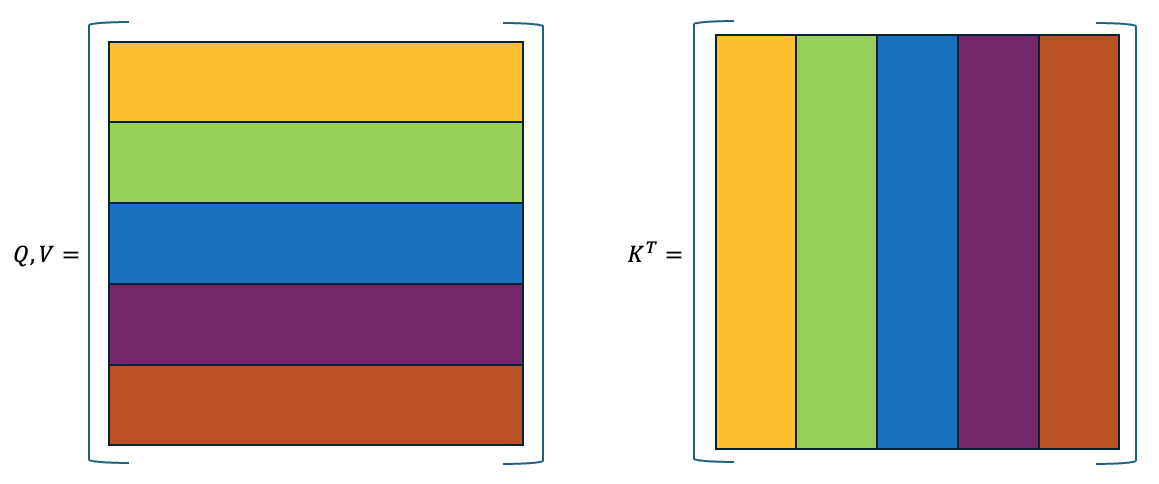
今回、Q, V, K が同じなのはSelf-Attentionすなわち、自分自身を見るような処理になっているからです。
最初のMatMul(内積処理)層
論文のScaled Dot-Product Attentionの図、では以下のオレンジので囲っている部分が表しています。
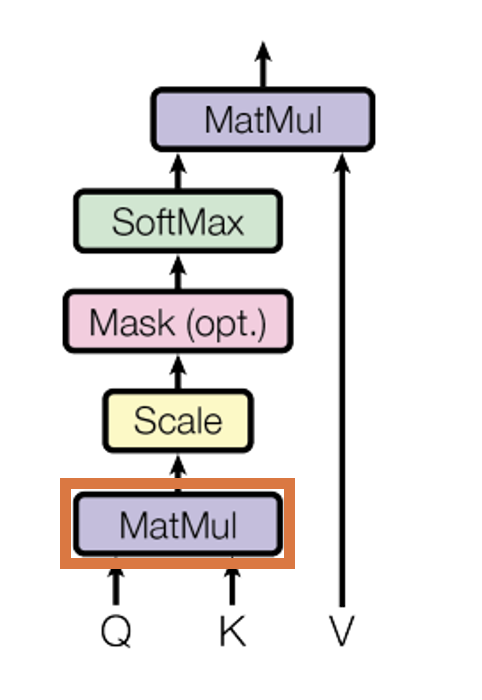
出典:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
論文の数式では以下のオレンジの部分です。
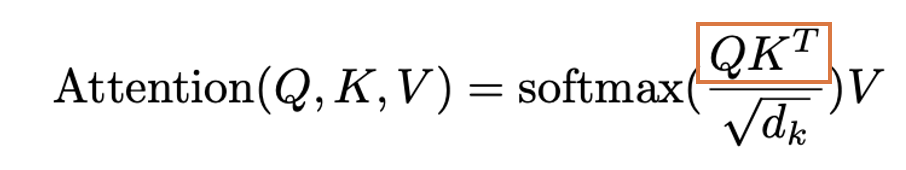
出典:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
$Q*K^T$ の計算は以下のようになります。
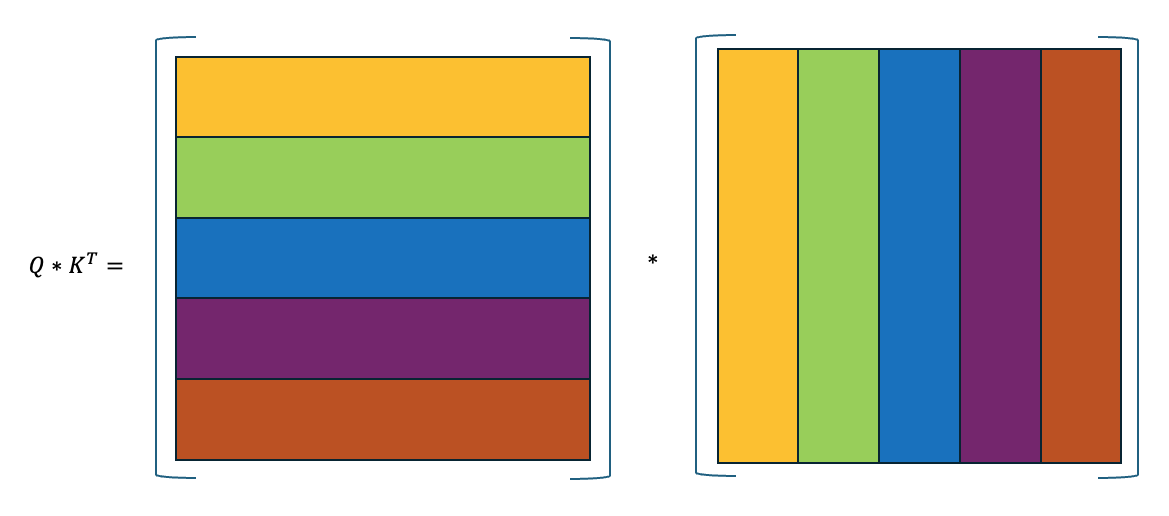
これを分かりやすく理解するために、$Q$の最初の行($q_1$とする)でみていくと以下のようになります。
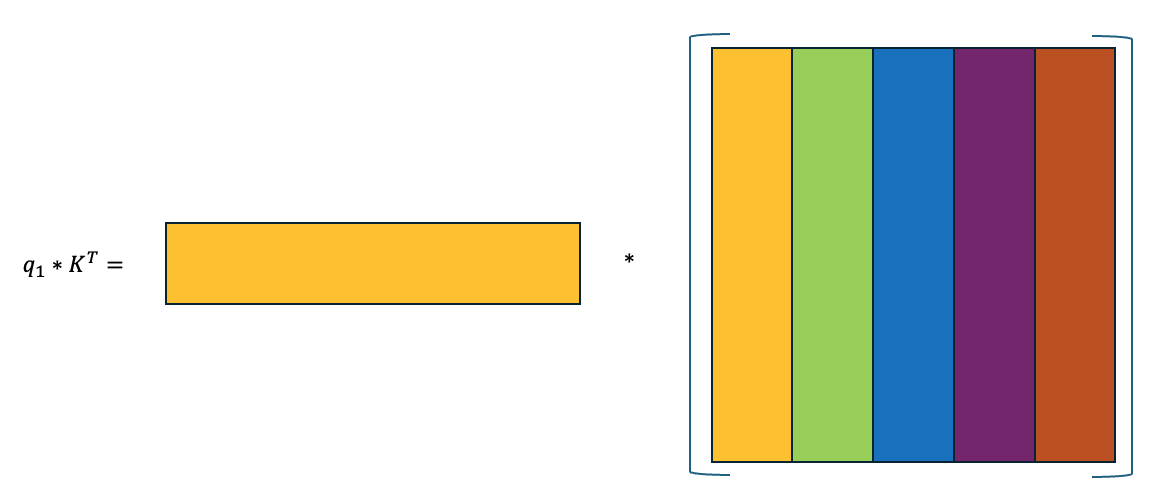
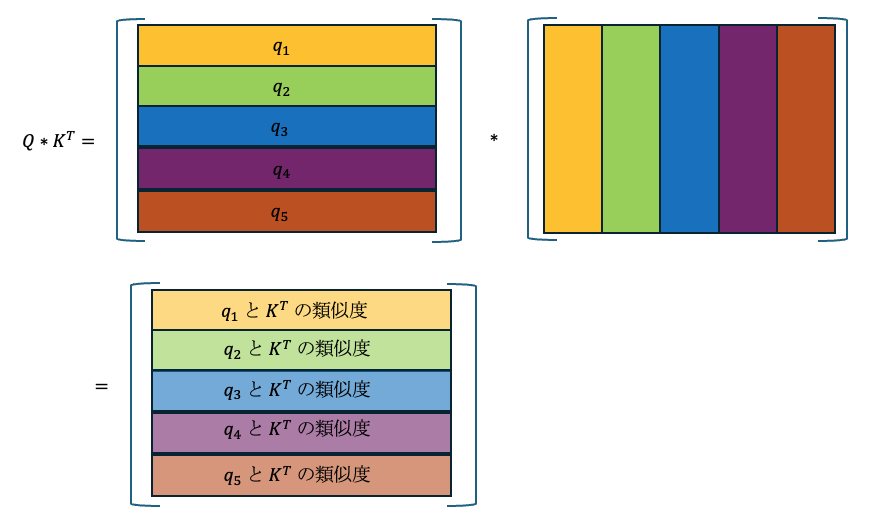
これは$q_1$と$K^T$の類似度を計算しているのと同じことです。 つまり、$Q*K^T$ は $Q$のそれぞれの行と$K^T$の類似度を計算していることになります。
これはすなわち、それぞれの文字と文章の関係を表していると言えます。
Scaled層
論文のScaled Dot-Product Attentionの図では以下のオレンジので囲っている部分です。
出典:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
論文の数式では以下のオレンジの部分です。
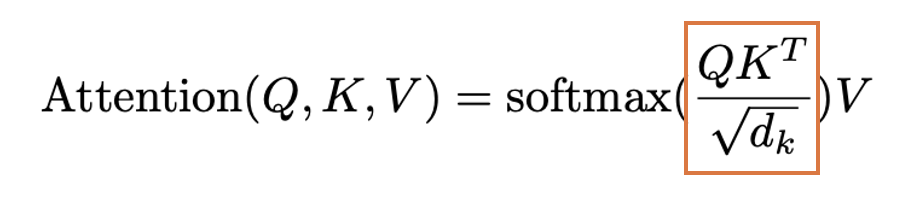
出典:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
これはすなわち、先ほどのMatMul層で計算した $QK^T$を $\sqrt{d_k}$ (Kのベクトルの次元数)で割ることで正規化していることがわかります。
これをなぜ行なっているのかを論文から読み解いてみます。

出典:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
つまり、ドット積($QK^T$)が大きな値を取り、ソフトマックス関数が非常に小さな勾配を持つ領域に押し込まれるかもしれないため$\frac{1}{d_k}$で正規化しているとのこと。
正直文章だけだとわかりづらいと思うので、正規化した状態としない状態でどうなるか簡単な実験をしてみましょう。
Pythonimport numpy as np
import matplotlib.pyplot as plt
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=-1, keepdims=True)
def compute_attention(Q, K, scaling=True):
d_k = Q.shape[-1]
scores = np.dot(Q, K.T)
if scaling:
scores /= np.sqrt(d_k)
return softmax(scores)
# Define sample query and key vectors
np.random.seed(0)
Q = np.random.rand(1, 5) # 1 query vector of dimension 5
K = np.random.rand(10, 5) # 10 key vectors of dimension 5
# Compute attention scores with and without scaling
attention_with_scaling = compute_attention(Q, K, scaling=True)
attention_without_scaling = compute_attention(Q, K, scaling=False)
# Plot the results
x = np.arange(attention_with_scaling.shape[1])
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.bar(x, attention_with_scaling[0], color='blue')
plt.title('With Scaling')
plt.xlabel('Keys')
plt.ylabel('Attention Score')
plt.subplot(1, 2, 2)
plt.bar(x, attention_without_scaling[0], color='red')
plt.title('Without Scaling')
plt.xlabel('Keys')
plt.ylabel('Attention Score')
plt.tight_layout()
plt.show()
このコードでは Qを1行5列の行列、Kを10行5列の行列をそれぞれ定義して、MatMulを計算したのち、正規化した場合としない場合でそれぞれSoftMax関数に入れることでどうなるのかが視覚化しています。今回$\sqrt{d_k}$は$\sqrt{5}$になり、この数字で割っています。
結果は以下のとおりです。 左が正規化する場合、右が正規化しない場合です。
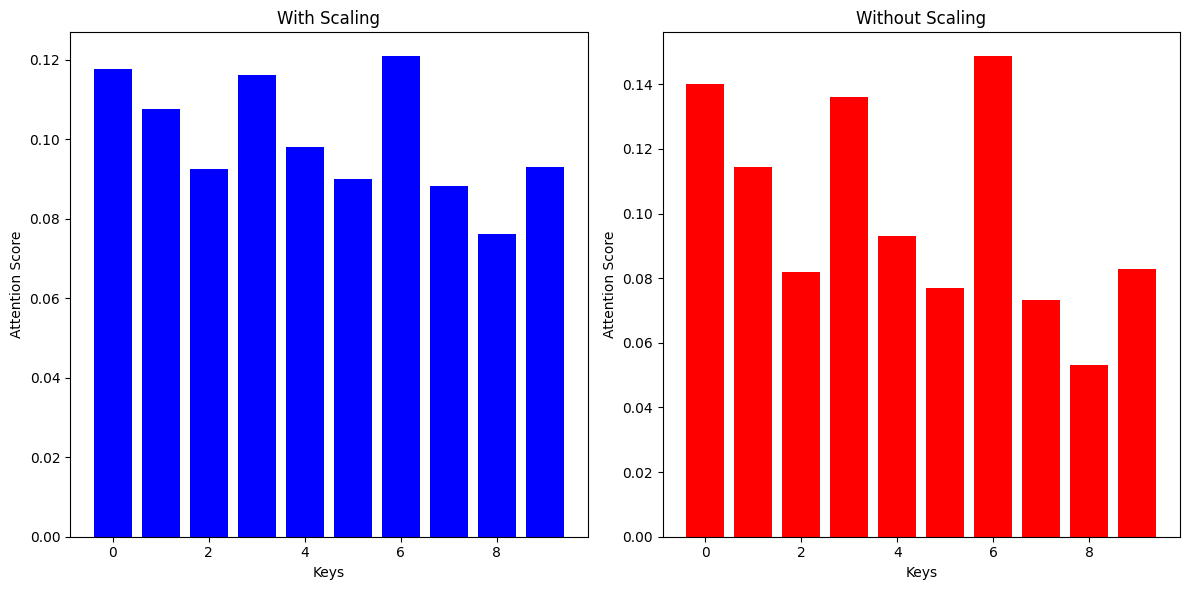
上の結果から、正規化する場合の方が、正規化しない場合に比べて、バランスが取れていることがわかります。逆に正規化しない場合は極端になっています。これを専門的に言うと「勾配情報が消失している」や「loss of gradient information」と表現したりすることもあります。これにより効率的に学習しやすくなります。
Mask(opt.)層
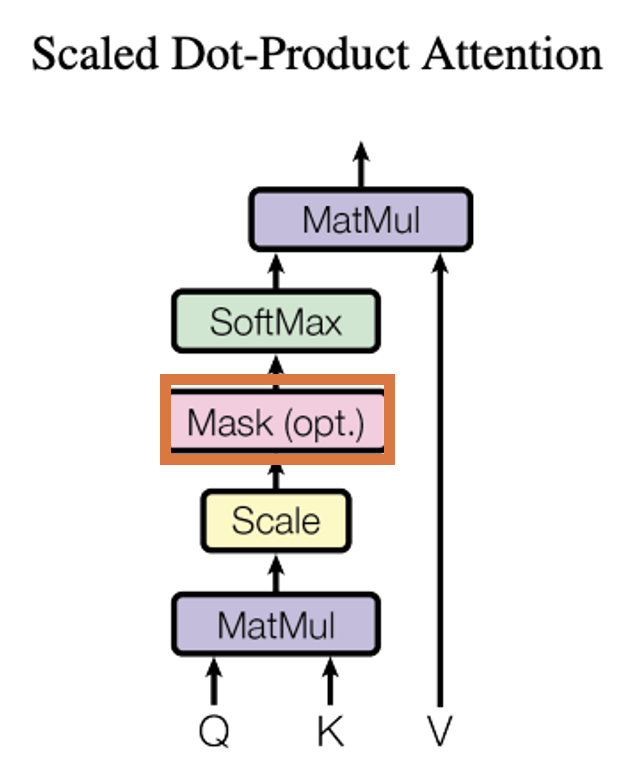
出典:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
以下は実際の最初のMatMul(内積処理)層とMask(opt.)層の結果です。 最初のMatMul(内積処理)層の結果に対して、三角行列になるように-inf($-\infty$)を入れていく形になっています。 これを行うことで、未来のトークンが見えないようになっています。今回は入れるこむような計算にしていますが、行列同士の掛け算で結果的にマスク処理を行うようにしたりすることもあるようです。
Python# 最初のMatMul(内積処理)層
# weight = q @ k.transpose(-2,-1) * C**-0.5
tensor([[
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]]])
# Mask(opt.)層
# weight = weight.masked_fill(self.tril[:T,:T] == 0, float('-inf'))
tensor([[
[0., -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf],
[0., 0., 0., -inf, -inf],
[0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0.]]])
実際にI WORK AT FIXER INC!を当てはめると以下のようなイメージです。
Python# 最初のMatMul(内積処理)層
# weight = q @ k.transpose(-2,-1) * C**-0.5
tensor([[
[I, WORK, AT, FIXER, INC!],
[I, WORK, AT, FIXER, INC!],
[I, WORK, AT, FIXER, INC!],
[I, WORK, AT, FIXER, INC!],
[I, WORK, AT, FIXER, INC!]]])
# Mask(opt.)層
# weight = weight.masked_fill(self.tril[:T,:T] == 0, float('-inf'))
tensor([[
[I, -inf, -inf, -inf, -inf],
[I., WORK, -inf, -inf, -inf],
[I., WORK, AT, -inf, -inf],
[I., WORK, AT, FIXER, -inf],
[I., WORK, AT, FIXER, INC!]]])
ヘッドクラスの重要性
文脈理解: 各ヘッドは入力のユニークな側面を捉え、モデルの文脈理解に貢献します。これにより、モデルはより複雑な文脈や意図を解釈できるようになります。
効率的な処理: 複数のヘッドでの並行処理により、より効率的かつ効果的なアテンションメカニズムが可能になります。これは、モデルが大規模なデータセットをより迅速に処理するのに役立ちます。
学習の柔軟性: 異なるヘッドが入力の異なる側面に焦点を当てることで、モデルは柔軟性を達成し、学習能力を高めます。これにより、モデルは様々なタイプのデータやタスクに適応しやすくなります。
まとめ
マルチヘッドアテンション(Multi-Head Attention)内のヘッドクラスは、言語を処理し、解釈するGPTモデルの高度な能力の証です。入力データのさまざまな側面を捉えるその役割は、モデルの文脈理解と柔軟性にとって不可欠です。ヘッドクラスの革新的な設計は、モデルの洗練さを理解するための基盤となります。
フィードフォワードクラス
イントロダクション
GPTモデルにおける複雑なアテンションメカニズムに続いて、フィードフォワードクラスは情報のさらなる処理と洗練において重要な役割を果たします。このクラスは、アテンション層の出力をさらに処理し、モデルの精度と表現力を高めます。
フィードフォワードクラスの役割
Transformer Block内に組み込まれたフィードフォワードクラスは、追加の処理層として機能し、モデルのデータ理解に複雑さと深さを加えます。このクラスは、入力データに対する高次元の変換を行い、特徴のより高度な表現を生成します。
フィードフォワードクラスの構造
コード
Python# 線形層に続く非線形活性化関数
class FeedForward(nn.Module):
def __init__(self, n_embed):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embed, 4 * n_embed),
nn.ReLU(),
nn.Linear(4 * n_embed, n_embed),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
ネットワーク層 (net): ネットワーク層は、ReLUのような非線形活性化関数と交互に配置された線形層で構成されており、単純な線形変換では捉えきれない複雑なデータパターンを捉えるために不可欠です。この設計により、フィードフォワードクラスは、モデルの非線形表現能力を強化します。
今回 nn.Linear(n_embed, 4 * n_embed) nn.Linear(4 * n_embed, n_embed) で途中のレイヤーを入出力の次元数の4倍にしているのは下の画像のように「Attention Is All You Need」(https://arxiv.org/pdf/1706.03762.pdf) の3.3章のPosition-wise Feed-Forward Networks にて、入出力の次元数が512で、途中の次元数が2048のされていたためです。

出典:Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
主要なメソッド
データ処理 (forward): forward メソッドは、ネットワークを通るデータの経路を定義し、連続した変換を適用します。このメソッドにより、モデルは入力データを複数の処理層を通じて洗練し、最終的な出力を生成します。
フィードフォワードクラスの構造
最初の線形変換: 入力は最初に線形変換(nn.Linear(n_embed, 4 * n_embed))を受け、次元性を増加させ、特徴をより広範なスペースで表現します。このステップは、特徴空間を広げ、データの潜在的な表現を拡張することを可能にします。
非線形活性化: ReLU活性化は非線形性を導入し、モデルがデータの複雑な関係やパターンを捉えることを可能にします。非線形活性化関数は、モデルがよりリッチな特徴表現を学習するのに役立ちます。
さらなる線形変換とドロップアウト: 後続の線形変換は、データを元の次元性に戻し、次の処理段階に備えます。また、ドロップアウトはモデルの正則化を提供し、過学習を防ぐ役割を果たします。
フィードフォワードクラスの重要性
複雑なパターン認識: クラスの非線形変換により、モデルは線形変換だけでは達成できない複雑なデータパターンを学習することができます。これにより、モデルはより複雑なデータ構造を解釈し、予測する能力を持ちます。
アテンションメカニズムの補完: フィードフォワードクラスは、アテンションメカニズムに対する重要な補完として機能し、アテンションで重み付けされた情報をさらに洗練し処理します。この層により、モデルは細部の特徴をより詳細に捉えることができます。
モデルの深化: 各フィードフォワード層はモデルに深みを加え、異なる抽象レベルでの特徴の豊かな階層を学習することを可能にします。これにより、モデルはより複雑なタスクに対応する能力を持ちます。
まとめ
フィードフォワードクラスは、GPTモデルの基本的な要素であり、言語を処理し解釈する能力を高めています。アテンションメカニズムを補完し、モデルの深さを豊かにすることで、GPTアーキテクチャにおける重要なプレーヤーとなっています。その役割と操作を理解することは、GPTモデルの全体的な洗練さと機能性を理解する上で不可欠です。
ブロッククラス
イントロダクション
GPTモデルのアーキテクチャの中心にはブロッククラスがあります。このクラスは、トランスフォーマーの主要な機能を包括する基本的な単位であり、モデルの全体的な能力の基盤です。このブロックの考え方は画像認識のモデルのResNetで使われはじめており、層を深くさせることによって起こる劣化問題(Degradation problem)の発生を防ぐために考案されました。
ブロッククラスの本質
ブロッククラスの各インスタンスは、GPTモデル内の単一のTransformer Blockを表します。Self-Attentionとフィードフォワードネットワークの融合を体現し、入力の処理と高度な特徴の抽出に不可欠です。この組み合わせにより、ブロックは入力データのさまざまな側面を捉え、それを統合してより豊かな表現を生成します。
ブロッククラスのの構造
コード
Python
# Transformer Block
class Block(nn.Module):
def __init__(self, n_embed, n_head):
# n_embed: 埋め込み次元,
# n_head: ヘッドの数
super().__init__()
head_size = n_embed // n_head
self.sa = MultiHeadAttention(num_heads=n_head, head_size=head_size)
self.ffwd = FeedForward(n_embed)
self.ln1 = nn.LayerNorm(n_embed)
self.ln2 = nn.LayerNorm(n_embed)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x
Self-Attention (sa): マルチヘッドアテンション(Multi-Head Attention)クラスのインスタンスであり、Self-Attentionメカニズムを担当します。このメカニズムにより、モデルは入力シーケンス内の各トークン間の関係を分析し、重要な情報に焦点を当てます。
フィードフォワードネットワーク (ffwd): このフィードフォワードコンポーネントは、線形および非線形変換を順次適用し、モデルがより複雑なデータ関係を捉えるのを助けます。
レイヤーノーマライゼーション(Layer Normalization) (ln1, ln2): Layer Normalizationは2016年に論文で発表されました。自然言語処理などの可変長なデータに対して行いやすいようにBatch Normalization(バッチ正規化)を改良したものです。 Layer Normalizationを行っているln1層とln2層は、Self-Attentionとフィードフォワードネットワークの前後でデータを正規化し、トレーニングの効率を高めています。正規化をすることにより、異なるレイヤー間でのデータの分散と平均を一定に保ち、学習を安定させることができます。
Layer NormalizationとBatch Normalizationの違いはを画像にするとわかりやすいかもしれません。 以下はGroup Normalizationの論文に描かれている図です。
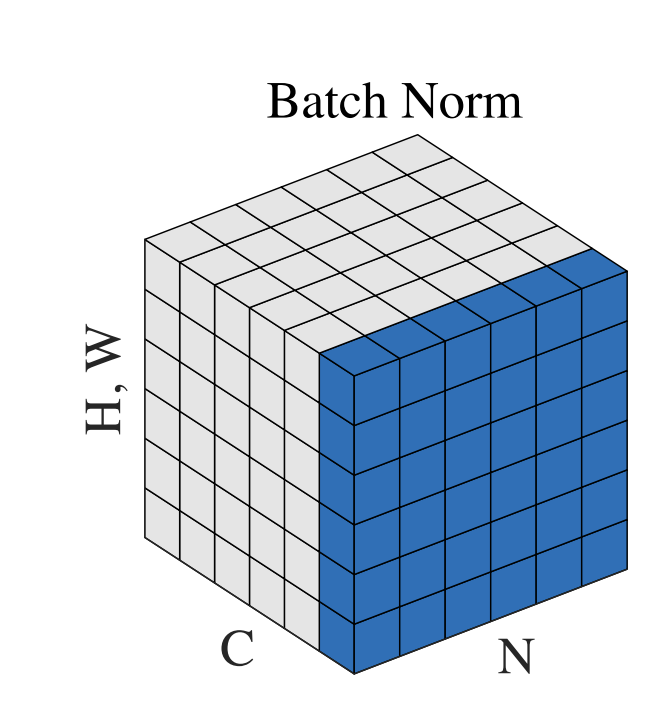
出典: Wu, Yuxin, and Kaiming He. "Group normalization." Proceedings of the European conference on computer vision (ECCV). 2018.
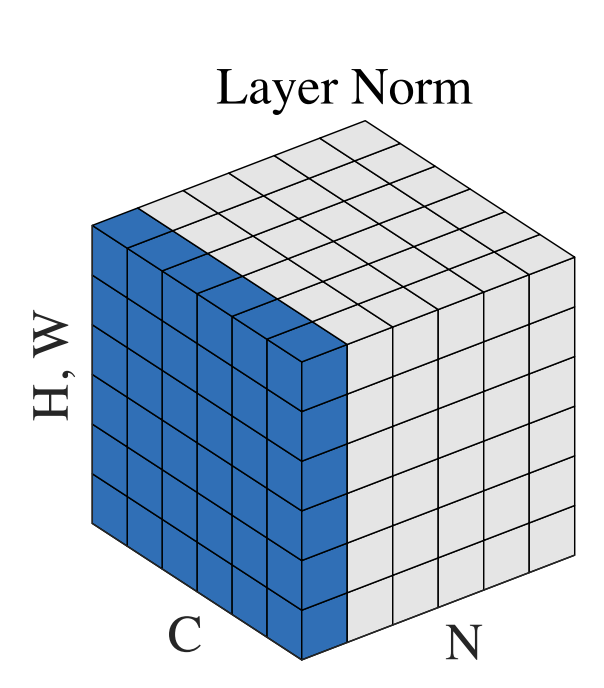
出典: Wu, Yuxin, and Kaiming He. "Group normalization." Proceedings of the European conference on computer vision (ECCV). 2018.
Nをバッチ軸、Cをチャンネル軸、(H, W)を空間軸とする特徴マップテンソルを示しています。青色のピクセルは、これらのピクセルの値を集約して計算された同じ平均と分散で正規化されます。Batch Normalizationでは、各サンプルの各チャンネルとバッチ全体にわたった平均と分散が計算されるため、青色のピクセルは同じチャンネル内の異なるサンプルの値に対して正規化が行われます。一方、Layer Normalizationでは、各サンプルの各チャンネルに沿った平均と分散が計算されるため、青色のピクセルは同じサンプル内の異なるチャンネルの値に対して正規化が行われます。
このように、Layer NormalizationとBatch Normalizationは、どの軸に沿って平均と分散を計算するかが異なります。この違いによって、Layer Normalizationは可変長のデータに対しても適用しやすくなっています。
コアメソッド
フォワードパス (forward): このメソッドは、Transformer Blockを通るデータの流れを調整し、Self-Attention、Layer Normalization、およびFeedForwardを順番に適用します。この一連の操作により、ブロックは入力データをより効果的に処理し、洗練された特徴を生成します。 今回の順番は"Attention Is All You Need" 論文とは異なります。トランスフォーマーの論文では、Norm層はマルチヘッドアテンション(Multi-Head Attention)の後に配置されますが、今回はマルチヘッドアテンション(Multi-Head Attention)の前に配置しました。これは 「On Layer Normalization in the Transformer Architecture」 という論文で提案された手法です。下の図はその論文から参照している図です。左が「Attention Is All You Need」で提案されたdecoderの構造で、右がこの論文で提案された手法です。
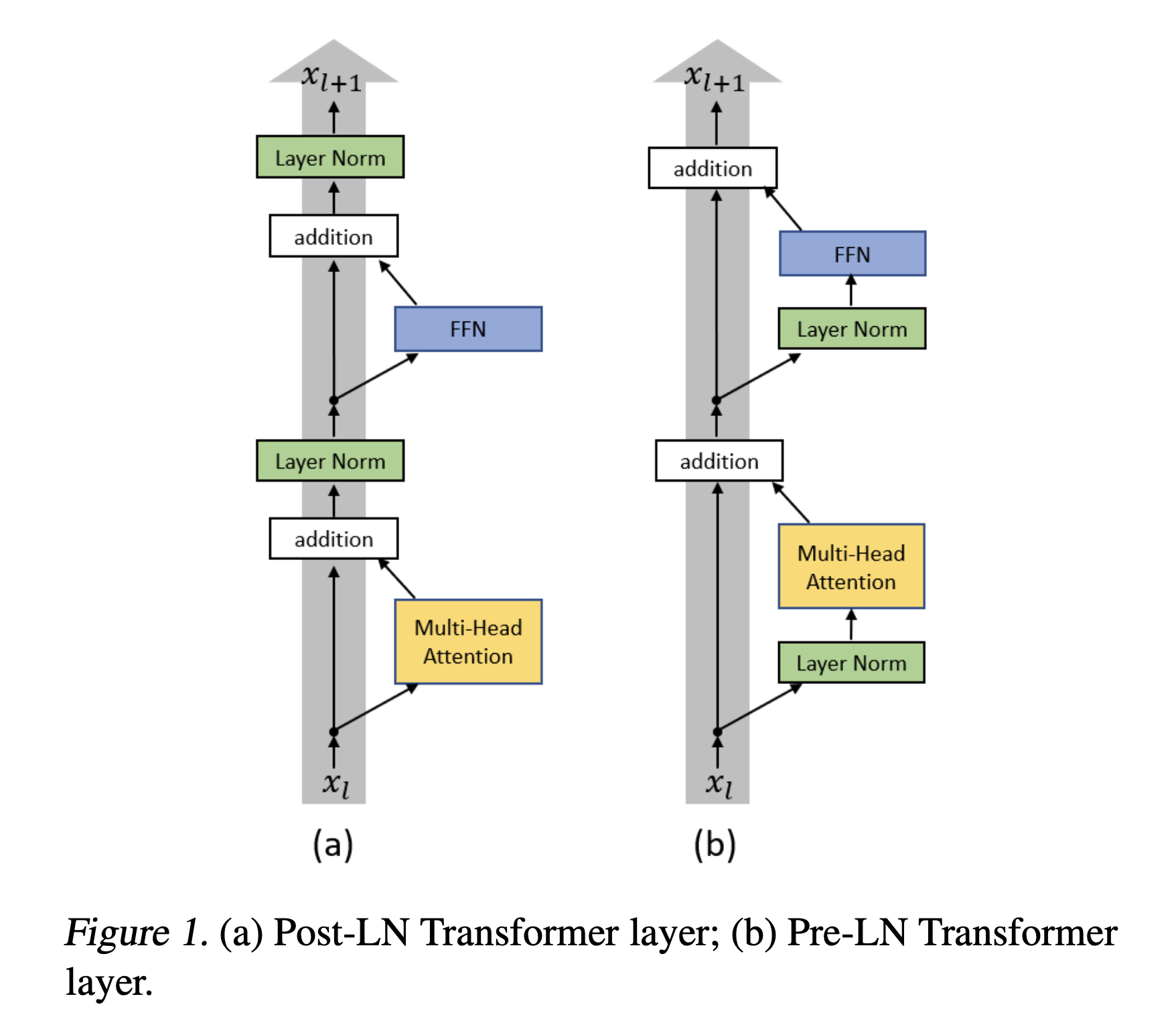
出典:Xiong, Ruibin, et al. "On layer normalization in the transformer architecture." International Conference on Machine Learning. PMLR, 2020.
ブロッククラスの操作
Self-Attention処理: 入力はまずSelf-Attentionを受け、モデルが入力の異なる部分を相互に関連付けることを可能にします。このプロセスにより、各トークンは文脈内の他のトークンとの関係を理解します。
一つ目の正規化と残差接続(residual connection): Self-Attentionの後、レイヤーノーマライゼーション(Layer Normalization)は出力を安定化させ、残差接続(residual connection)は元の入力を加え戻し、レイヤー間の情報を保持します。このステップは、深いネットワークの訓練を容易にし、情報の喪失を防ぎます。残差接続(residual connection)とは前述通り、画像認識のモデルのResNetで提案された手法です。
これは以下の疑問のもとに提案された手法です。
Is learning better networks as easy as stacking more layers?
より良いネットワークを学ぶのは、より多くのレイヤーを積み重ねるのと同じくらい簡単なことなのだろうか?
すなわち、良いモデルを構築するには層をただただ増やせばいいのではという疑問です。実際にResNetが提案される前は層を深くしていくことで精度を上げられると考えるのが一般的でした。ですが、それと同時に深くしていくほど、損失問題が顕著に表れていきました。
そこで提案された手法は以下のようなものでした。
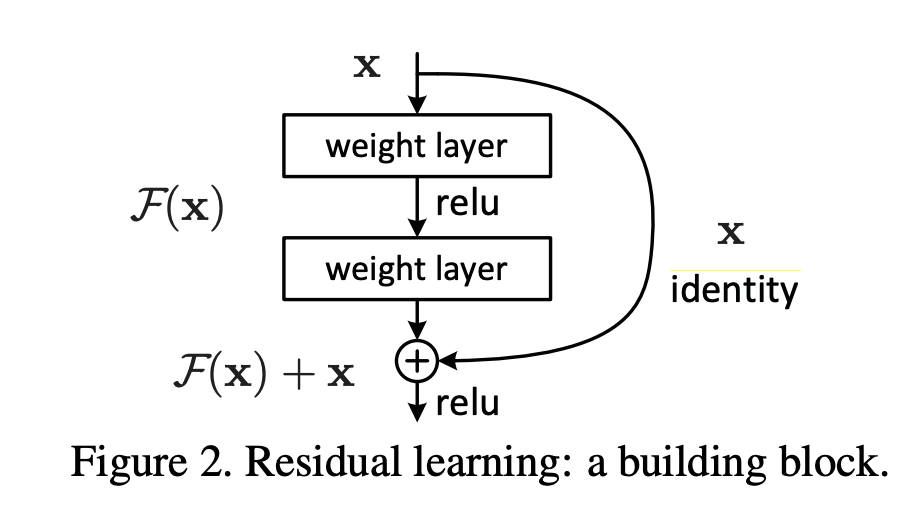
出典:He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
従来のものを図として表すと、
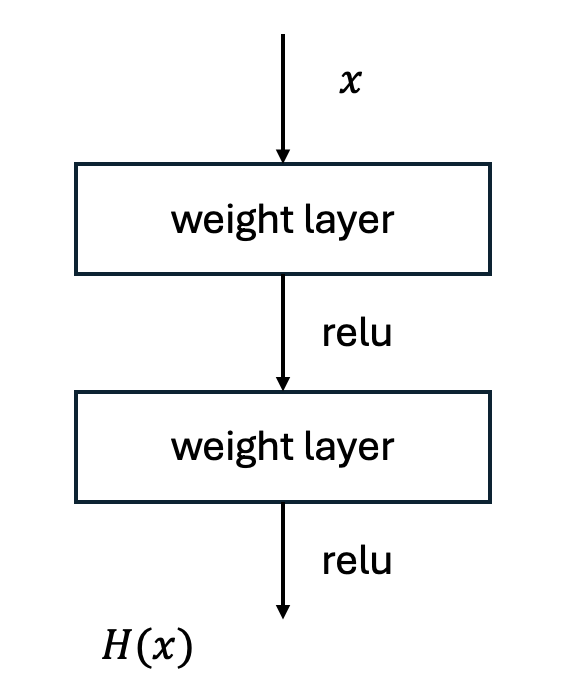
つまり、図のように従来のニューラルネットワークレイヤーに直接入力(図の$x$)を加えことで、残差ブロック内の写像$F(x)$は,$x$に対する変化分である「非常に小さな変換」だけを担当できるようになりました。
これにより、
勾配消失問題の軽減: 勾配が逆伝播する際に直接の経路が確保されるため、勾配消失問題が軽減されるようになり、非常に深いネットワークでも効果的に学習ができるようになりました。
効率的な学習: 入力から生成された残差に制限することで、学習に必要なパラメータの数を減らすことができるため、効率的な学習が可能となりました。
コード上では
Python def forward(self, x):
x = x + self.sa(self.ln1(x)) <= 最初の残差接続
x = x + self.ffwd(self.ln2(x)) <= 二つ目の残差接続
の部分で行なっています。コードからも入力値を入れていることがわかると思います。
フィードフォワード処理: フィードフォワードネットワークはさらにデータを処理し、特徴抽出に複雑さを加えます。この段階では、ネットワークは非線形変換を行い、より高度な特徴表現を生成します。
二つ目の正規化と残差接続(residual connection): 2つ目のレイヤーノーマライゼーション(Layer Normalization)が続き、別の残差接続(residual connection)がSelf-Attention層の出力を加え戻し、堅牢な特徴表現を確保します。この連続する正規化と残差接続は、ブロックの各コンポーネント間でデータの一貫性と効果的な伝達を保証します。
ブロッククラスの重要性
特徴抽出: ブロッククラスにより、モデルは多様な特徴セットを抽出することが可能となり、言語理解を強化します。これにより、モデルはより複雑な言語パターンと文脈を捉えることができます。
安定した学習ダイナミクス: レイヤーノーマライゼーション(Layer Normalization)と残差接続(residual connection)は、安定した学習プロセスに貢献し、逆伝播中の勾配の流れを改善します。これにより、モデルはより深いレイヤー構造を持つことができ、複雑なタスクを効果的に学習します。
拡張性とモジュール性: ブロッククラスの設計により、モデルアーキテクチャの拡張が可能となり、複数のブロックを積み重ねることで学習容量を増やすことができます。これにより、モデルは様々なサイズと複雑さのデータセットに対応することができます。
まとめ
ブロッククラスは、GPTモデルに不可欠なコンポーネントであり、トランスフォーマーアーキテクチャの要素を包括しています。その機能は、モデルが言語を効果的に処理し、文脈を理解し、文脈に関連する出力を生成する能力の中心です。ブロッククラスを理解することは、GPTモデルの全体的な構造と能力を理解する上で鍵となります。
MyLanguageModelクラス
今まで作ってきた部品を一つにまとめているクラスです。
MyLanguageModelクラスの概要
MyLanguageModelクラスは、埋め込み層、複数のTransformer Block、最終的な線形層を統合し、洗練されたテキスト処理が可能な一貫した言語モデルを構築します。
MyLanguageModelクラスの構造
コード
Pythonclass MyLanguageModel(nn.Module):
def __init__(self, vocab_size, n_embed) -> None:
super().__init__()
# 各トークンは、次のトークンのロジットをルックアップテーブルから直接読み取ります
self.token_embedding_table = nn.Embedding(vocab_size, n_embed)
self.position_embedding_table = nn.Embedding(block_size, n_embed) # トークンの位置のための埋め込みテーブル
self.blocks = nn.Sequential(*[Block(n_embed, n_head=n_head) for _ in range(n_layer)])
self.lm_head = nn.Linear(n_embed, vocab_size)
self.ln_f = nn.LayerNorm(n_embed)
def forward(self, idx, targets=None):
B, T = idx.shape
# idxとtargetsはどちらもテンソルです
tok_emb = self.token_embedding_table(idx) # (B バッチ(batch size), T 時間(ブロックサイズ), C チャネル(埋め込み))
pos_emb = self.position_embedding_table(torch.arange(T,device=device)) # (T,C) 0〜T-1の整数
x = tok_emb + pos_emb # (B,T,C)
x = self.blocks(x) # Self-Attentionの1つのヘッドを適用 (B,T,C)
x = self.ln_f(x) # (B,T,C)
logits = self.lm_head(x) # (バッチ(batch size), 時間(ブロックサイズ), 語彙サイズ)
if targets is None:
loss = None
else:
B, T, C = logits.shape # (バッチ(batch size), 時間(ブロックサイズ), チャネル(埋め込み))
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
# idxは現在のコンテキストのインデックスの(B,T)配列です
for _ in range(max_new_tokens):
# 最後のブロックサイズのトークンにidxを切り取る # ブロックサイズ以上は持つことはできません
idx_cond = idx[:,-block_size:]
# 予測を取得する
logits, loss = self(idx_cond)
# 最後のステップにのみ焦点を当てる
logits = logits[:, -1, :]
# 確率にsoftmaxを適用する
probs = F.softmax(logits, dim =-1) #(B,C)
# 分布からサンプリングする
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# サンプルされたインデックスを実行中のシーケンスに追加する
idx = torch.cat((idx, idx_next), dim = 1)
return idx
主要な変数
トークン埋め込み (token_embedding_table): 入力トークンを密なベクトル表現に変換し、意味情報を捉えます。
位置埋め込み (position_embedding_table): これらの埋め込みは、トークンの順序を理解するためにモデルに位置的なコンテキストを提供します。
Transformer Block (blocks): 一連のブロッククラスのインスタンスで、それぞれがモデルの処理と理解能力を向上させます。
言語モデリングヘッド (lm_head): シーケンス内の次のトークンに対する予測を生成する線形層です。
最終レイヤーノーマライゼーション(Layer Normalization) (ln_f): 最後のTransformer Blockからの出力を安定化させ、それを言語モデリングヘッドにフィードする前のステップです。
コアメソッド
フォワードパス (forward): 入力をモデルを通して移動させる過程を調整し、埋め込み層、Transformer Block、言語モデリングヘッドを含みます。
テキスト生成 (generate): モデルが予測に基づいてテキストを生成することを可能にし、ビームサーチやトップkサンプリングなどの技術を使用して一貫性と関連性を確保します。
MyLanguageModelクラスの機能
埋め込みと入力の処理: クラスは入力トークンの埋め込みから始まり、意味的および位置的情報を加えます。埋め込まれたトークンは、それぞれのTransformer Blockを通して処理され、文脈理解が強化されます。
最終変換とテキスト生成: 最後のレイヤーノーマライゼーション(Layer Normalization)の後、データは言語モデリングヘッドを通して渡り、テキスト生成のための予測を生成します。
MyLanguageModelクラスの重要性
包括的な言語理解: クラスは、埋め込み、Transformer Block、および言語モデリングを統合することにより、微妙な理解を可能にします。
生成能力: そのテキスト生成能力は、チャットボットやコンテンツ作成などの分野でのモデルの実用的な応用を示しています。
拡張可能なアーキテクチャ: クラスのモジュール性により、言語タスクの複雑さに基づいてTransformer Blockの数を調整することができます。
まとめ
MyLanguageModelクラスは、GPTモデルの基盤となるもので、言語処理と生成の能力を体現しています。このクラスを理解することは、入力データの処理から人間のようなテキストの生成に至るまで、モデルの全範囲を把握するために重要です。そのコンポーネントの洗練された統合により、自然言語処理における強力なツールとなっています。
トレーニングと評価関数
イントロダクション
GPTのようなモデルの有効性は、そのアーキテクチャだけでなく、どのようにトレーニングされ、評価されるかにも依存します。トレーニングと評価関数は、GPTモデルの原始的な潜在能力を言語処理のための精巧な楽器に変える歯車です。
トレーニング関数の説明
コード
Python@torch.no_grad()
def estimate_loss(model):
out = {}
model.eval()
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = dataLoader.get_batch(split)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out
def train_model():
model = MyLanguageModel(vocab_size = vocab_size, n_embed=n_embed)
model.to(device)
# モデルのパラメータ数を表示する
print(sum(p.numel() for p in model.parameters())/1e6, 'M parameters')
# PyTorchのオプティマイザーを作成する
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
for iter in range(max_iters):
# 一定間隔でトレーニングセットとバリデーションセットの損失を評価する
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss(model)
print(f"ステップ {iter}: トレーニング損失 {losses['train']:.4f}, バリデーション損失 {losses['val']:.4f}")
# データのバッチをサンプリングする
xb, yb = dataLoader.get_batch('train')
# 損失を評価する
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
torch.save({
'epoch' : max_iters,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': losses['train']
}, f"{model_path}/{max_iters}")
# モデルから生成する
context = torch.zeros((1, 1), dtype=torch.long, device=device)
print(tokenizer.decoder(model.generate(context, max_new_tokens=2000)[0].tolist()))
損失見積もり (estimate_loss): この関数は、クロスエントロピーのような選択された損失関数を使用して、モデルの予測が実際のターゲットからどれだけ離れているかを計算します。
最適化関数 (optimizer): 例えばAdamWのようなメカニズムで、計算された損失に基づいてモデルの重みを更新し、モデルのパフォーマンス向上に導きます。
損失追跡 (losses): 反復ごとの平均損失を記録し計算する方法で、モデルの学習進行状況を監視するために重要です。
トレーニングプロセス
モデル処理 (順伝搬): 入力はモデルを通してフィードされ、予測を生成します。
損失計算: モデルの予測は実際のターゲットと比較され、損失が計算されます。
逆伝播: 損失は勾配を計算するために使用され、これらはモデルを通して逆伝播されて重みを更新します。
重みの更新: オプティマイザーはモデルの重みを調整し、将来の反復での損失を減少させることを目指します。
評価関数
ロジット計算: モデルの生の出力は、評価中に損失を計算するために使用されます。
評価損失: 評価中に計算される損失で、モデルの未確認データに対するパフォーマンスの洞察を提供します。
評価プロセス
モデル推論: 重みを更新せずにモデルを別のデータセット(検証セットまたはテストセット)で実行します。
パフォーマンス評価: このデータセットで損失を計算し、モデルが新しいデータに対してどれだけうまく機能するかを評価します。
追加のメトリクス: 手がかりの性質に応じて、精度、適合率、再現率などの他のパフォーマンス指標も計算されます。
GPTモデルにおける重要性
最適化と学習: トレーニング関数は、モデルが指定されたタスクを効果的に実行するためのパラメーターを洗練するために不可欠です。
モデル評価: これらは、モデルの一般化能力と実世界のアプリケーションへの準備状況を評価するための枠組みを提供します。
反復的改善: トレーニングと評価からの洞察は、モデルの能力をさらに向上させるための改善に導きます。
まとめ
トレーニングと評価関数は、GPTモデルのライフサイクルに不可欠です。これらは、モデルの学習旅路を指示し、その有効性を評価する枠組みを提供します。これらの機能を徹底的に理解することは、さまざまなアプリケーションで堅牢で効果的なGPTモデルを開発し、展開し、維持することを目指すすべての人にとって重要です。
全体のまとめ
今回、Large Language Model(LLM)の基盤を理解するために自らモデルを構築してみました。しかし、単にモデルを学習させたところで、我々が日常的に利用しているGaiXerやChatGPTのようなモデルが出来上がるわけではありません。そこから更にInstruction tuningを施すことで、単なるnext-word predictionモデルが対話を行えるようなモデルへとチューニングされていきます。また、今回はPyTorchのembedding機能を使用し、一定の辞書とサイズを持つシンプルなルックアップテーブルとしてのエンベッディングを実装しました。エンベッディングの世界は深く、その精度がモデルの文章の意味理解能力にも大きく影響します。時間がある時に、ちゃんとしたモデルを作ってまたこれについてブログ記事を書きたい思います。
おまけ
時間とお金のリソースを気にすることなくモデル作って学習できる環境が欲しいな〜
参考文献
- https://github.com/karpathy/ng-video-lecture
- https://arxiv.org/abs/1706.03762
- https://arxiv.org/pdf/2002.04745.pdf
- https://zenn.dev/yuto_mo/articles/72c07b702c50df
- https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf
- https://arxiv.org/abs/1512.03385
- https://theaisummer.com/attention/
- https://qiita.com/kenmaro/items/d096909311aa3b29a31a
- https://blog.roboflow.com/what-is-resnet-50/
- https://moritake04.hatenablog.com/entry/2023/06/04/232615
- https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
