






こんにちは、株式会社FIXER@東京の村上滉樹です!
AWS Summit New York 2024の基調講演で、生成AI技術に関するたくさんの発表がありました🎉 Amazon BedrockやAmazon Qの機能拡張に加え、自然言語によるアプリケーション開発を実現する「AWS App Studio」の登場などが紹介されましたね。
本ブログでは、これらの新機能の中から特に興味深い「Knowledge Bases for Amazon Bedrock」に焦点を当てます。講演の中で新たにデータコネクトとして追加された「Web Crawler」により、WEB上にあるコンテンツデータをRAG(Retrieval-Augmented Generation)に登録して、Amazon Bedrockで利用できます。
AWSマネジメントコンソールから実装方法と生成精度について書いていきます。
AWS News Blog|Knowledge Bases for Amazon Bedrock now supports additional data connectors (in preview)
■実装方法
1.ナレッジベースを作成する
Amazon Bedrock コンソールにアクセスして、「ナレッジベース」を押下します。
1-1.ナレッジベースの詳細を入力
| 項目 | 本ブログで紹介する設定値 |
| ナレッジベース名 | 適当な名前を付ける |
| IAM許可 | 「新しいサービスロールを作成して使用」を選択 |
| Choose data source | 「Web Crawler」を選択 |
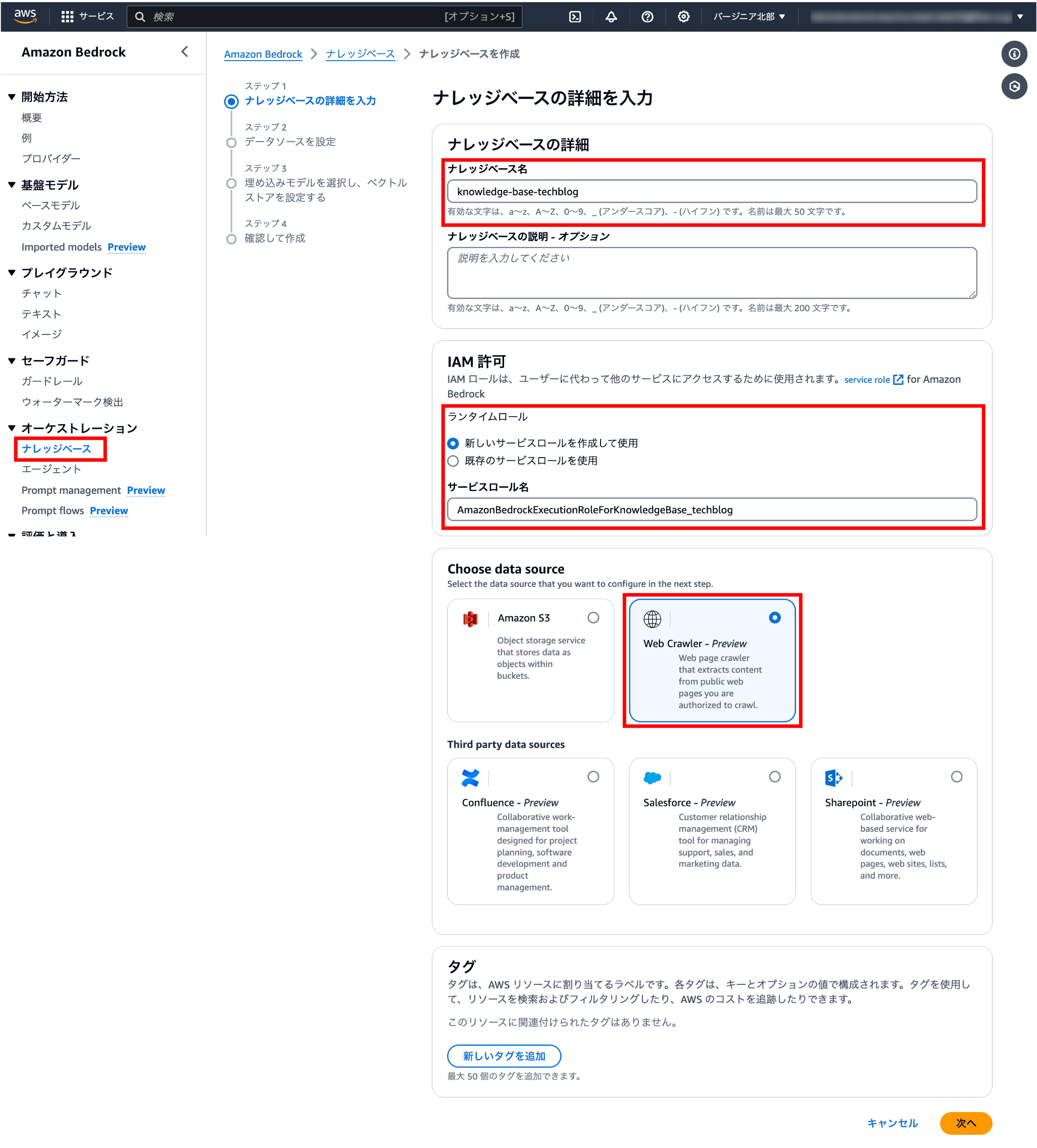
1-2.データソースを設定
Sync scope では、登録したURLに対してどの階層まで深く読み込ませるか設定できます。特定のページやコンテンツを対象外にしたり、料金を最低限にしたりなどの要件がない限り、デフォルト値でもいいと思います。
| 項目 | 本ブログで紹介する設定値 |
Data source name | 適当な名前を付ける |
Source URLs | RAGに登録したいURLを入力 |
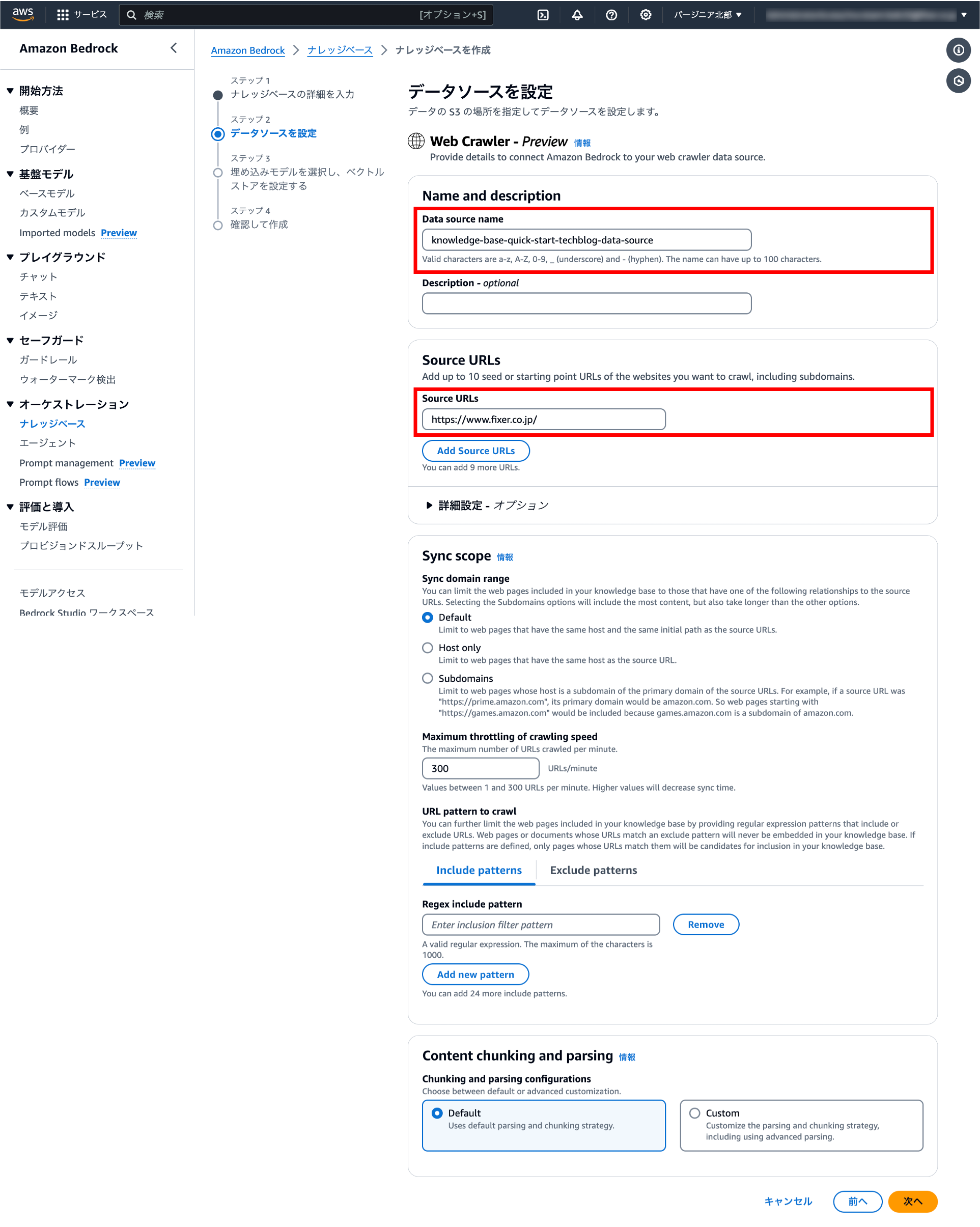
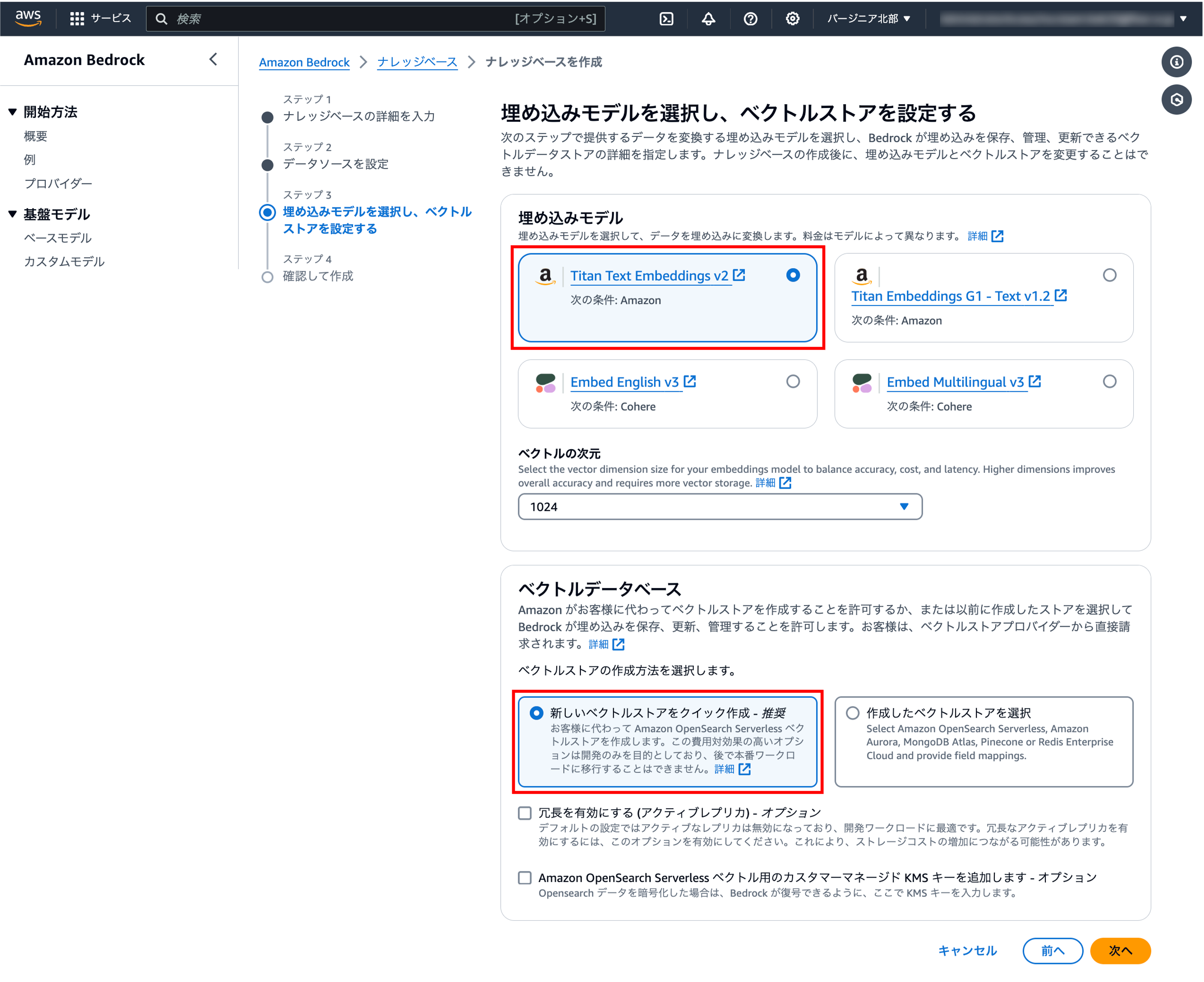
1-3.埋め込みモデルを選択し、ベクトルストアを設定する
ベクトル次元の数値を増やすことにより、より多くの情報をBedrockにインプットするが可能です。ただし、数値を大きくする分、計算処理に時間がかかります(高次元)。簡単なテキスト検索や分類処理ぐらいであれば「256」や「512」などの低次元が最適化されるケースもあります。用途に合わせてチューニングしましょう。
| 項目 | 本ブログで紹介する設定値 |
埋め込みモデル | 好きなLLMを選択 |
ベクトルデータベース | 「新しいベクトルストアをクイック作成」を選択 |
またベクトルDBでは、Amazon OpenSearchが構築されます。高性能インスタンスが複数台起動するため、料金には注意しましょう。サーバレスモデルなので検証目的ぐらいであれば安価ではありますが・・・
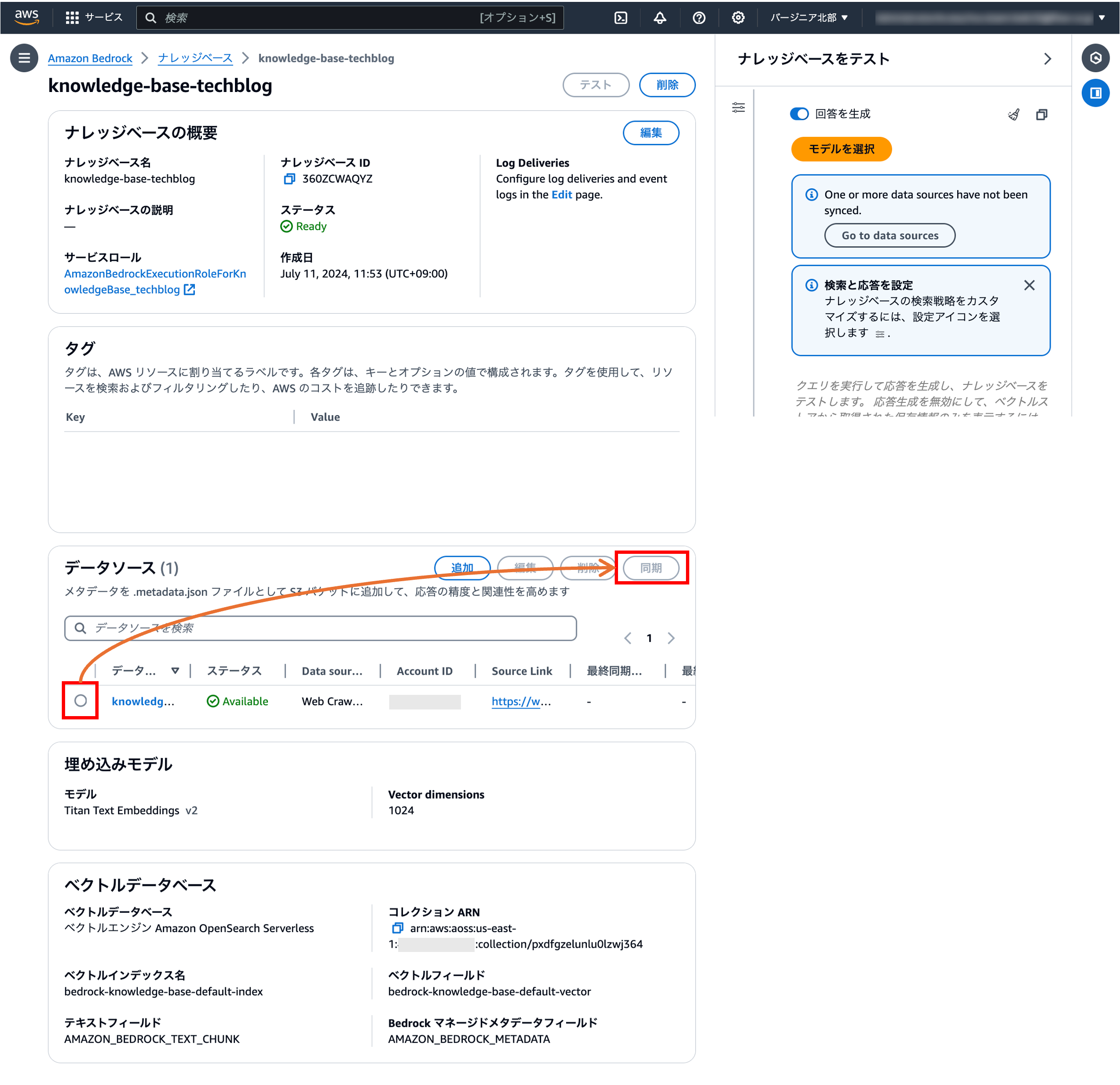
2.データソースを同期する
2-1.データソースをナレッジベースのワークスペースに同期する
明示的にデータソースを同期する必要があります。
(スクショの撮りミスで同期ボタンが非活性化になっていますが、ラジオボタンを選択すると活性化します)
また、コンテンツのデータ量にもよりますが、同期にかかる時間は少し長いです。本ブログでは弊社の公式HPを登録したのですが、10分ほどかかりました。
2-2.LLMを指定する
本ブログでは、Claude 3 Sonnnet を利用します。
■RAGありとRAGなしで実検証してみた
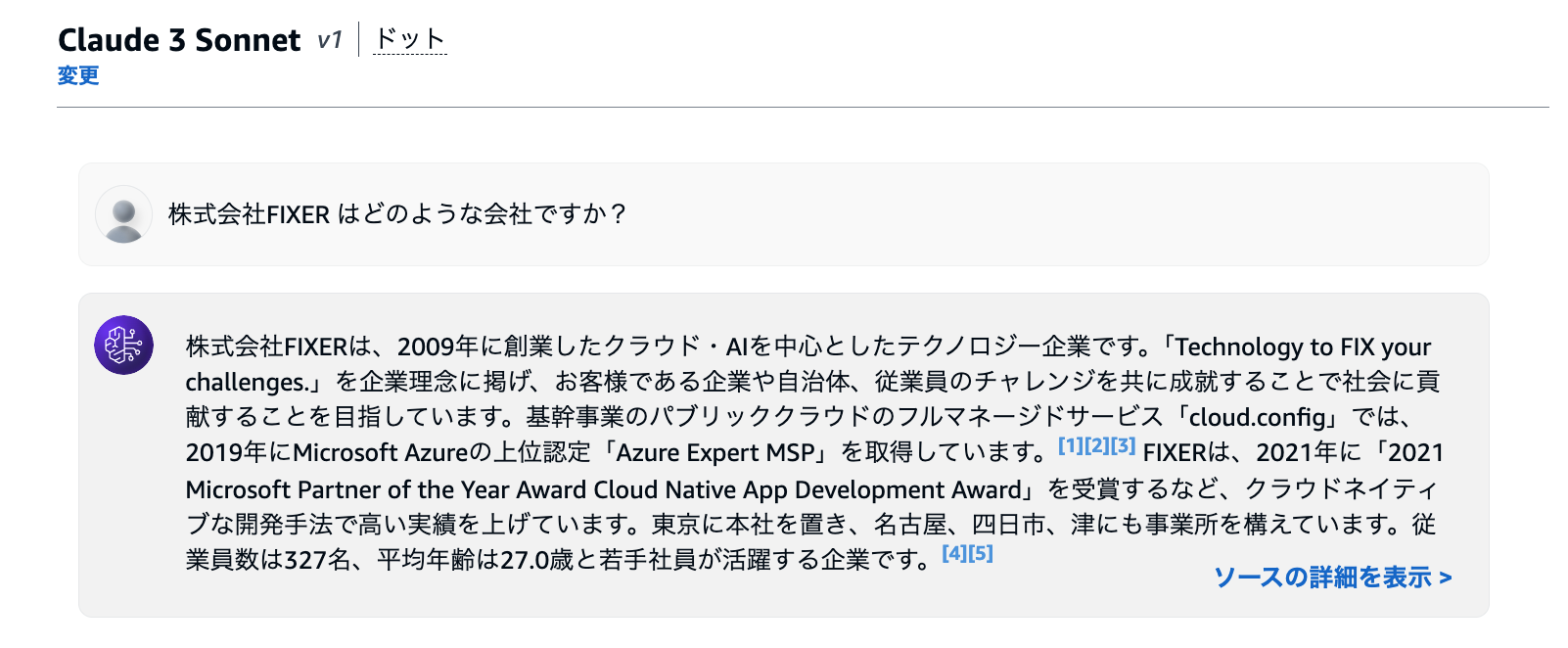
Q. 株式会社FIXER はどのような会社ですか?
RAGあり(Web Crawler)in Claude 3 Sonnet
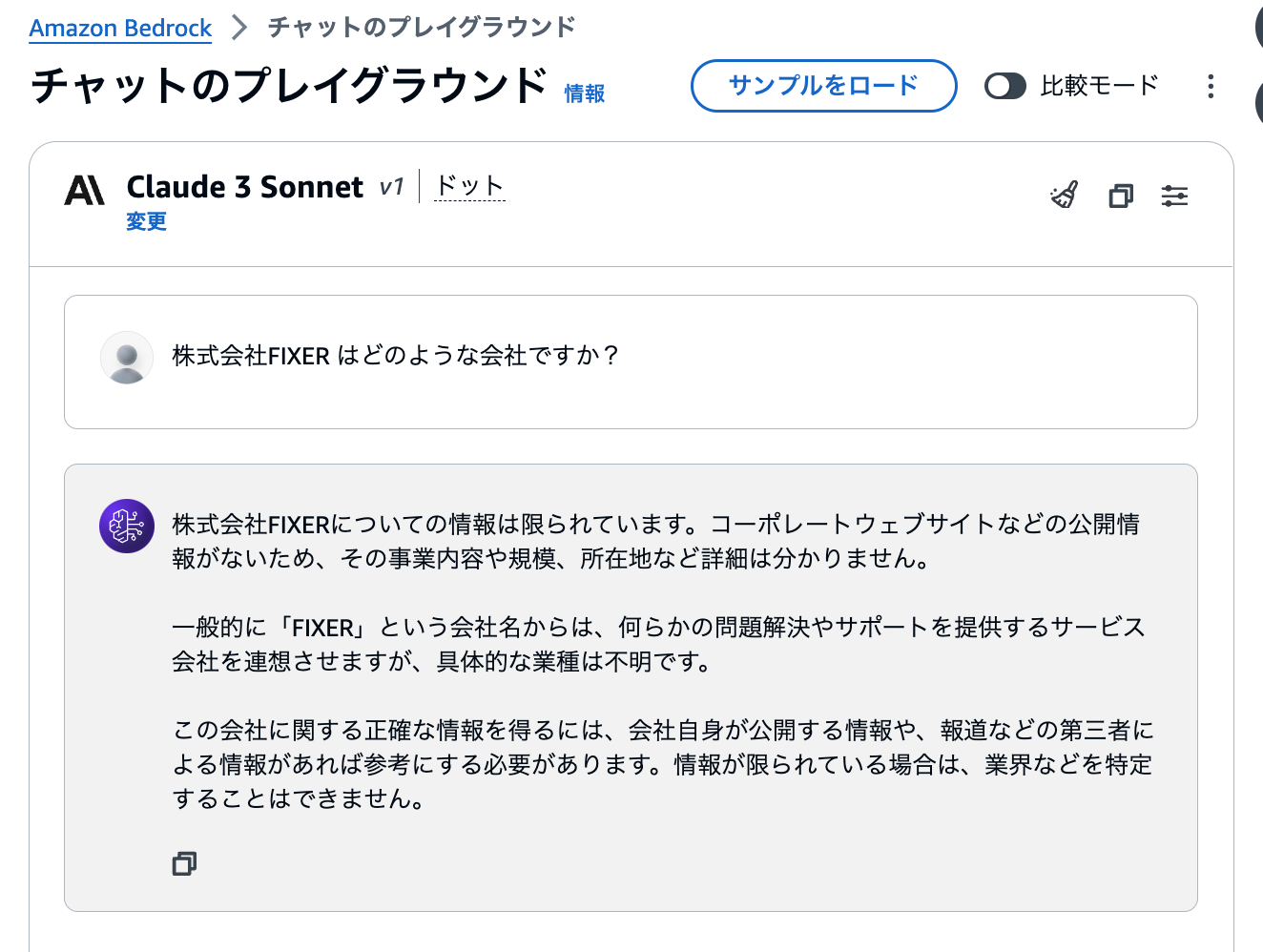
RAGなし in Claude 3 Sonnet
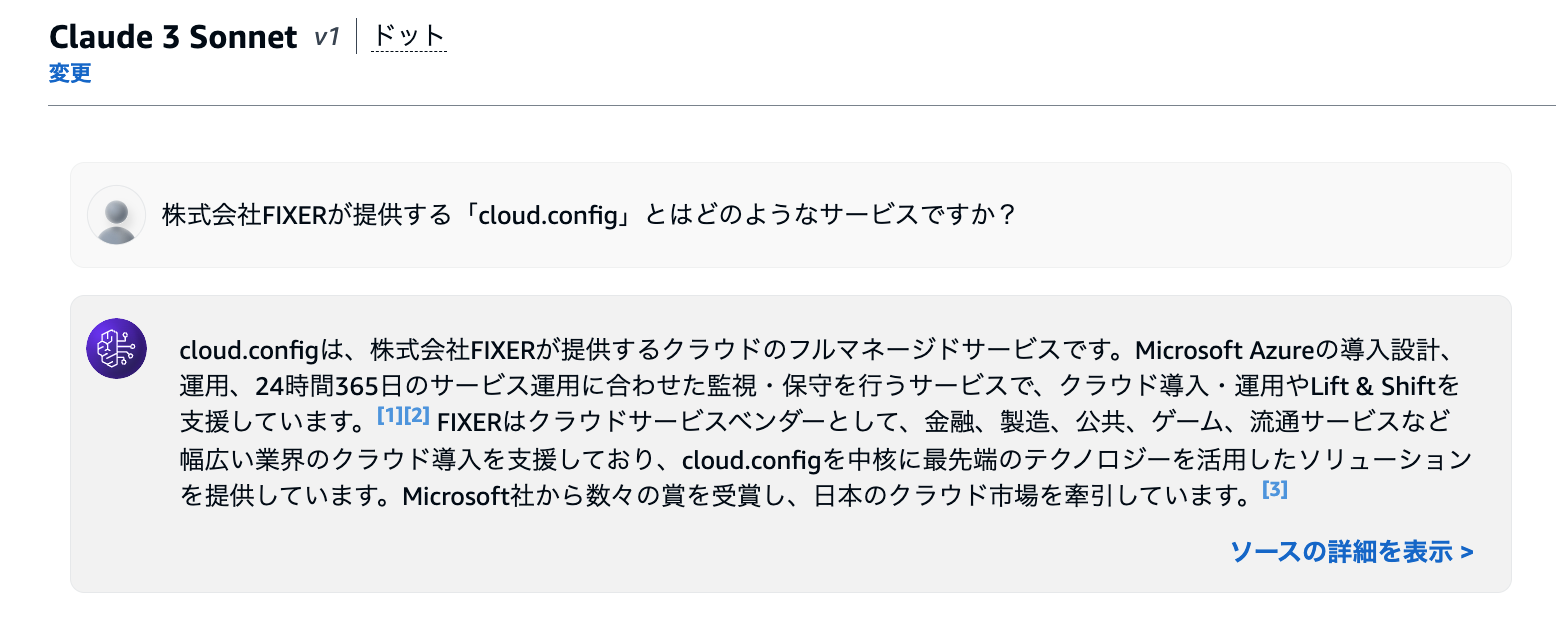
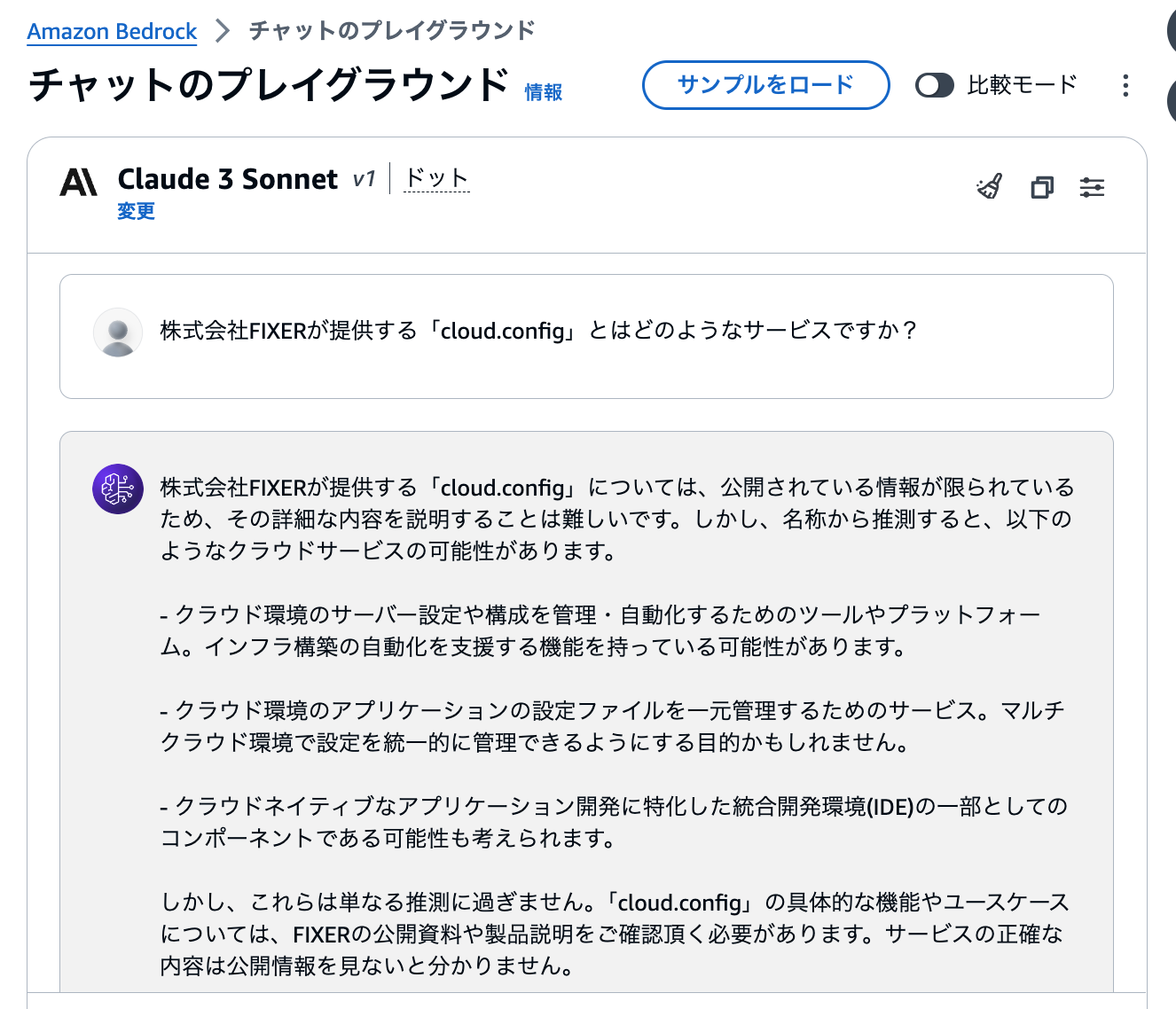
Q. 株式会社FIXERが提供する「cloud.config」とはどのようなサービスですか?
RAGあり(Web Crawler)in Claude 3 Sonnet
RAGなし in Claude 3 Sonnet
■最後に
最後まで読んでいただき大変ありがとうございます。
RAGいいですね〜 クラウドサービスを自分で育てている実感があるので私は好きです。
従来ではS3バケットにCSVやPDFをアップロードして、OpenSeatch などでデータ分析するしか方法はなかったですが、今回のアップデートでWeb URLだけで登録できるようになりました。
他にもSharePointやSalesforceなどの有名なSaaSのコンテンツデータも登録できるため、ご利用を検討くださいませ!











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
