


 2025-12-07
2025-12-07
目次

- はじめに
- おことわり
- Day 1: まずは技術を知る — 技術調査フェーズ
- やったこと
- そもそもどうやって画像を生成してる?
- 既存の判定ツールを片っ端から試す
- 判定手法調査
- 判定手法の分類
- 1日目の学び/感想
- この後の予定立て
- Day2 : じっくり観察してどんな特徴があるかを見る
- AI絵の特徴
- 人間が描いた絵の特徴
- 2日目の学び/感想
- Day3 : 周波数解析に手を出してみる
- 画像と周波数解析って何の関係があるの
- Day3の学び/感想
- Day4 : ノイズ解析にチャレンジしてみる
- 1. ノイズ分布(右上)
- 2. 明るさ vs ノイズ(左下)
- 3. 局所ノイズマップ(中央下)
- 4. ELA(右下)
- 結論
- Day4の学び/感想
- Day5 : 機械学習(CNN)にチャレンジ
- そもそもCNNって何?
- 転移学習とは
- 実際にやってみた
- 準備したもの
- コードの流れ
- 結果
- CNNが見ている「特徴」って?
- Day5の学び/感想
- 5日間のまとめ
- 結論
- 参考サイト (外部のサイトへのリンクです。)
- 使用したソースコード (※AI生成品)
はじめに
AIが話題になってきている今、AI生成によるイラスト等の普及は良い/悪いなどで議論が繰り広げられています。(著作権が~などで話題になりましたね...)
素敵なイラスト・動画を見つけても「これ、AIが作ったんじゃないか?」と最初に疑いから入ることも多くなってきました。
「けど根拠なく疑うのもなぁ...技術的根拠を持って自信もってAIの特徴めっちゃあるじゃん!と言いたいなぁ」
そんな動機から、5日間でAI生成画像の生成からそれを判定アルゴリズムまでを実際に試して学んでみることにしてみました。
おことわり
AI生成した画像・動画等に対して優劣をつけたい/批判などを行いたい、という趣旨の記事ではありません。
あくまでどのような特徴があり、判別が難しい昨今の状況において付け焼き刃の知識でどれほどの精度で判定できるかをチャレンジするチャレンジ企画のようなものということを先に明記させていただきます。
判定アルゴリズムを1から組むのはきついので ソースコードについてはClaudeCodeに書かせてみました。
AIにAI生成画像か否かを判別させる AI vs AI という対立も少し見てみたかったという部分もあります。
また本記事は、生成AIに関する5日間のチャレンジ記録です。短期間・限定的な条件下での検証のため、用語の使い方や結果の解釈に誤りや偏りを含む可能性があることにご注意ください。
Day 1: まずは技術を知る — 技術調査フェーズ
やったこと
・AI画像生成の仕組みを調査
・既存の判定ツール・サービスを試す
・学術論文を調べる
そもそもどうやって画像を生成してる?
調べてみると、現在主流なのは拡散モデル(Diffusion Model)というアプローチ。
Stable Diffusionって聞いたことあるのでこれについてもう少しだけ調査してみましょう。
= アプローチ ・ 生成 ・ 学習方法 =
ノイズ画像 → [ノイズを少しずつ除去] → きれいな画像
学習時: きれいな画像にノイズを加えていく過程を学習
生成時: その逆をたどる
へー という感じですね。 生成モデルについても簡単に調べてみました。
= 主要なモデル =
・ Stable Diffusion — オープンソース、カスタマイズ性高い
・ Midjourney — 高品質、アート寄り
・ DALL-E — OpenAI製、プロンプト理解が優秀
・ Flux — 最新、高品質で検出が難しいらしい
↑こんな感じで各生成モデルでもかなりばらつきがありますね。
モデルの味というかモデル固有の癖が出る可能性がありそう...?
既存の判定ツールを片っ端から試す
まずは競合の判定力をみてみましょう。
| ツール名 | 方式 | 公称精度 | 実際に試した感想(ひとこと) |
| Hive Moderation | CNN分類器 | 99%+ | それなりではあるけど99%+は盛ってるかも |
| Illuminarty | アンサンブル | 94% | まぁ良い感じではあった |
| AI or Not | 独自モデル | 不明 | はっきり言って誤判定多い |
| Is It AI? | 周波数+CNN | 85% | 公称の%は正直すぎる 体感それぐらいだった |
試しに、友人に頼んで5枚のイラストを描いてもらい、AI生成した画像はAIそざいや (AIそざいや | AI素材 - 無料ai素材データダウンロードサイト)から5枚拝借しました。合計10枚ずつ各サービスに投げてみたけど、100%判別できますよ!はなかった。
(ちなみにこの10枚のほかに100%人間の手でトレスしたやつも投げてみましたがこれは全部誤判別でした。それはそうか...?と思いつつ完ぺきな判定をするのは難しそうですね...)
判定手法調査
AIの特徴をどうやって見破るかに関しては直接AI本人に聞くのが一番ですね 。
最近話題のClaude Codeに聞いてみました。
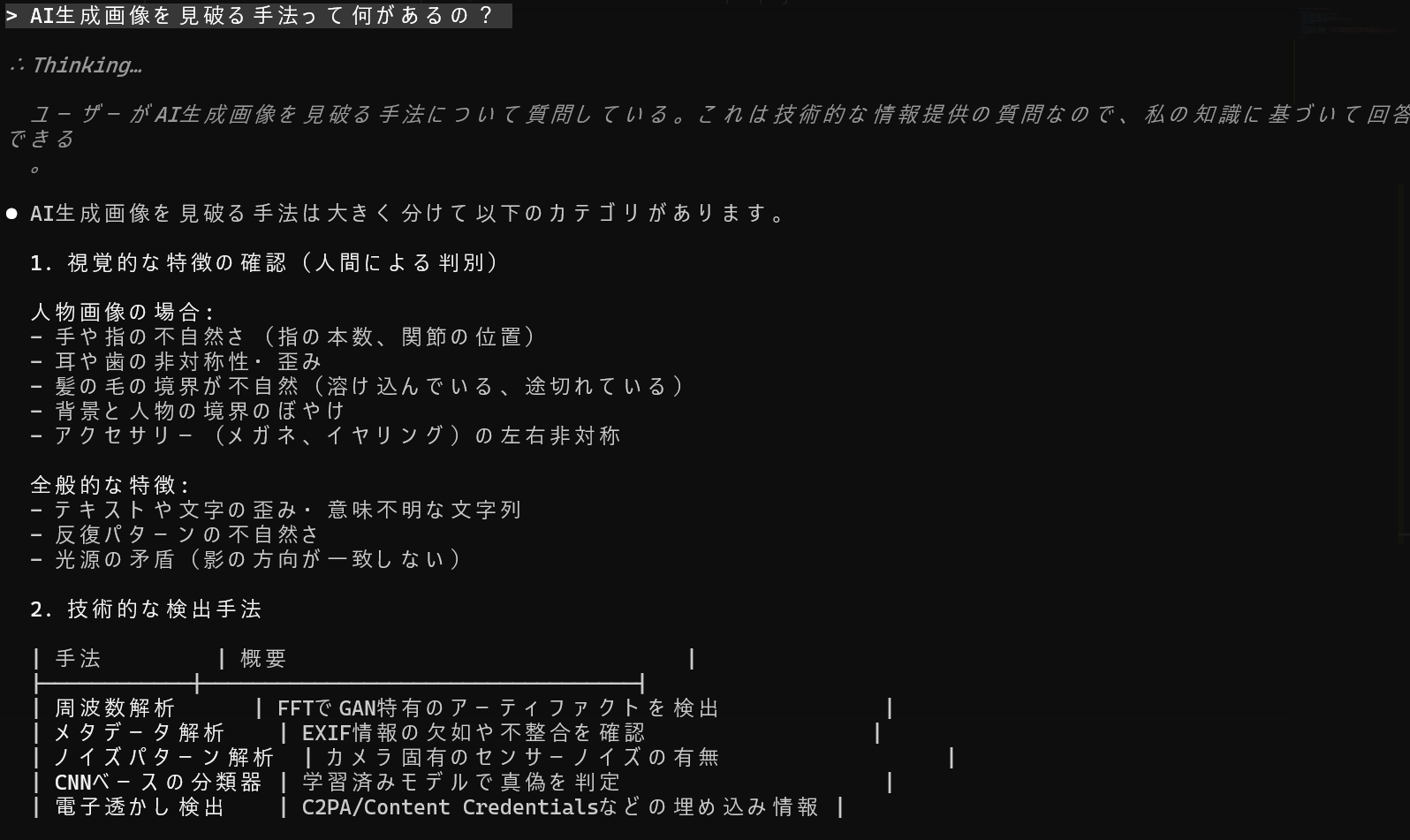
ふむふむ。
まとめると以下の通り。
判定手法の分類
周波数解析 - フーリエ変換でアーティファクトを検出
ノイズ解析系 - センサーノイズの有無を確認
CNN分類器 - AI生成した画像を大量に学習させて判別する
1日目の学び/感想
・既存ツールも完璧じゃない、というか限界はある → これらを5日という短い期間で超えるのは無理そうなので100%見破れるものを作るぜ!という考えは捨てる
・手法は「周波数」「ノイズ」「機械学習」の3系統
この後の予定立て
Day2はAI画像をゆっくり見て目視でも判別できる点がどうなのか を確認
Day3からは「周波数」-> Day4「ノイズ」 ->Day5「機械学習」の順で確認
Day2 : じっくり観察してどんな特徴があるかを見る
人によるとは思いますが、正直AIイラストをじっくりしっかりまじまじと見る機会はないですよね。「え~これーAIか~すげ~」ってなってスススッって次のイラスト等を見たりするのが普通だと思います。(少なくとも私がそうです。)
ただ今回はAI生成画像を見破るものを作るのでしっかり見ていきたいと思います。
AI絵の特徴
※ChatGptで生成した画像を利用しています。(Day1で使った画像ではありません)

おおーーーーーーーーーDay1の調べ通りノイズから作ったのか確かになんかザラザラとした質感の画像...
特に花の茎の部分とかノイズ乗ってるように見えますね。
あとは極端に髭の長さが違うような?

こちらもなんかザラザラした画像...
あとパスタってこんな太いっけ、、、と思ってたらなんか麺が一部つぶれてますね細かい描写は苦手にも見えます。
人間が描いた絵の特徴
※こちらは参考画像から全体で共通して言えそうなことをまとめます。(さすがに自分で書いてないイラストをブログに上げるわけにはいかないので...)
AI絵と比較すると当たり前ですがノイズはない+実際のモデルを参考にしながら描くことが大半なので関節があり得ない方向に曲がったりとかはしないですね。
あとなんというかAIは全体を描こうとしているけど人間の絵は部分部分で手が抜かれているような感じに見えました。
今日は少し忙しくてあんまり割けなかったのでここまで...
2日目の学び/感想
・ある程度なら人間の目で見分けることも可能
・Day1の調査知識と目視の直感が繋がってきた
・違和感がある部分は一日目で見た周波数解析とかでばっちり出てきそうだな...という所感
Day3 : 周波数解析に手を出してみる
画像と周波数解析って何の関係があるの
正直Day1でしらべた画像と周波数解析の関係性が全く分かりませんでした。
ということで「画像 周波数解析」で調べると以下のような記載がある記事を見つけました。
フーリエ変換は周波数解析ができる便利なデータ変換です。
画像に対しても利用できますが、周波数の考え方が通常の信号とは異なるので注意する必要があります。
- 通常の信号データ
- 周波数=単位時間内にどのくらい振動するか
- 画像データ
- 周波数=単位ピクセル内に画素値がどのくらい変化するか
よって、画像データの周波数は1[px]移動したときの画素値の変化が激しいほど高周波となります。画像処理でのフーリエ変換は「時間領域→周波数領域」ではなく「空間領域→空間周波数領域」となります。
*引用1
なるほど...?あー、確かにDay2のザラザラした画像なら高周波ではありそうだし見破る方法としては適切そうです。
そうとわかればエンジニアとしてはコード組んで確かめるほかありません。
…としたいところなのですが、昨今のAI情勢事情を顧みるとClaudeCodeに組んでもらうのも悪くはありません。(numpyやopencvのようなライブラリで一発でしょうし、お手並み拝見です)
決して楽をしたいわけじゃないですよ?お手並み拝見です。
というわけで生成...!
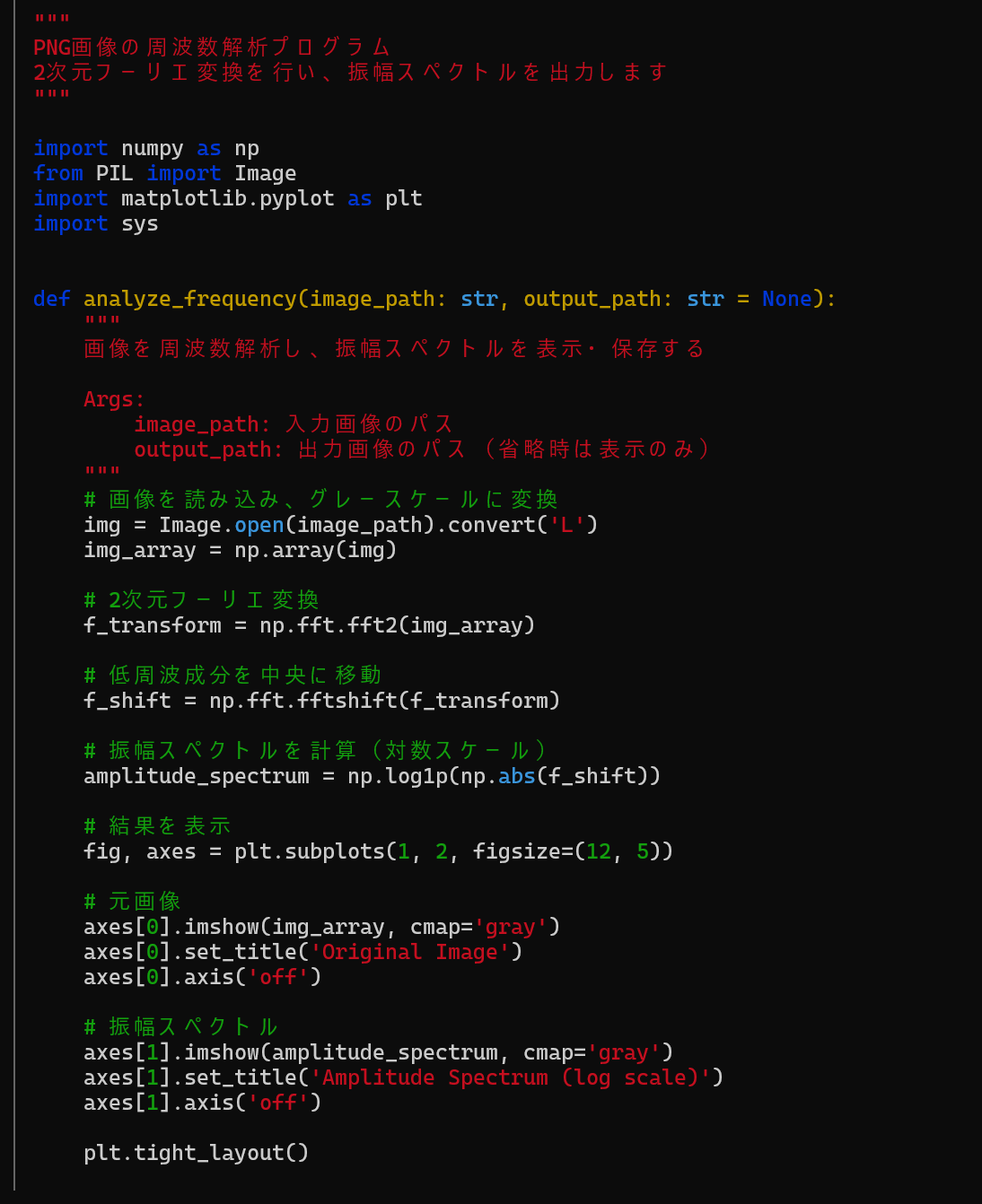
おお、すごい なんかそれっぽいですね。
ではこのプログラムを使ってDay2で示したような画像を早速入力として渡してみましょう。
全体が白ければ白っぽいほど高周波であるみたいなので全体的に明かるければAI生成画像である可能性が高いというわけですね。
まずはネコちゃんから

おおお...?
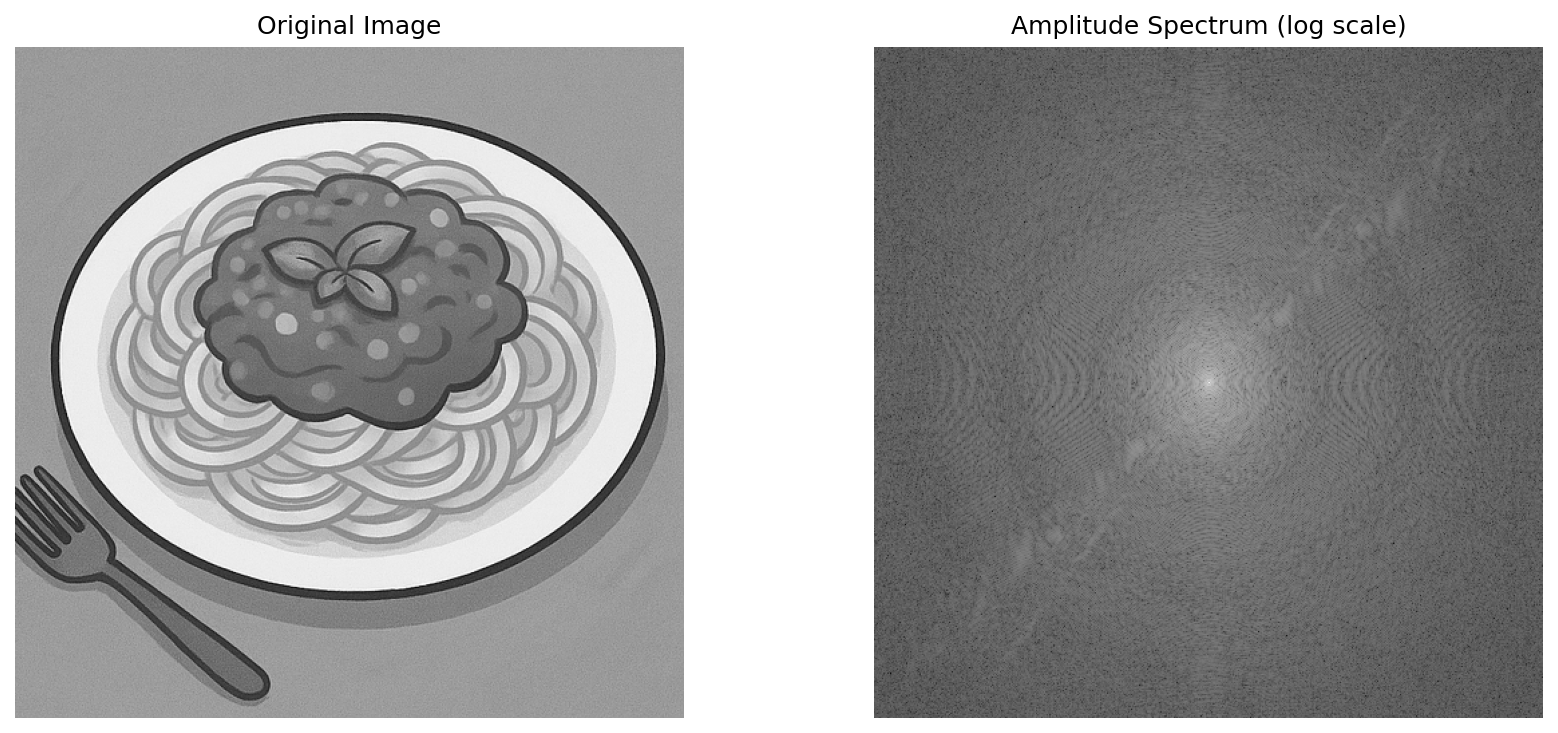
完全に周りも白いですね。
ではここで、私のGithubのアイコン画像(京都で撮影した写真)を入力として渡してAIではない以下のような画像だったらどういう結果なのかを確認して見ましょう


むむ、これも真ん中が白いですね... もしかして一概には言えない...?
とおもったのですが、定義をよく考えてみると「画素値の変化が激しいほど高周波」なので物体とかが映り込んだりするとこうなりますね。
なのでこれだけで判別するのはむずかしそうです。
さて、本題のフーリエ変換でアーティファクトを検出というのをやってみましょう。
手法について調べたところ、以下3点の視点で見ればよいということが分かりました。
・高周波強調 : 中央をマスクして外側だけ表示
・放射状プロファイル : 中心からの距離ごとに平均
・角度分布 : 角度ごとに振幅を平均
これらを確認すべく、同じようにClaudeCodeに指示をして出されたプログラムを実行してみました。
まずはAI生成の画像
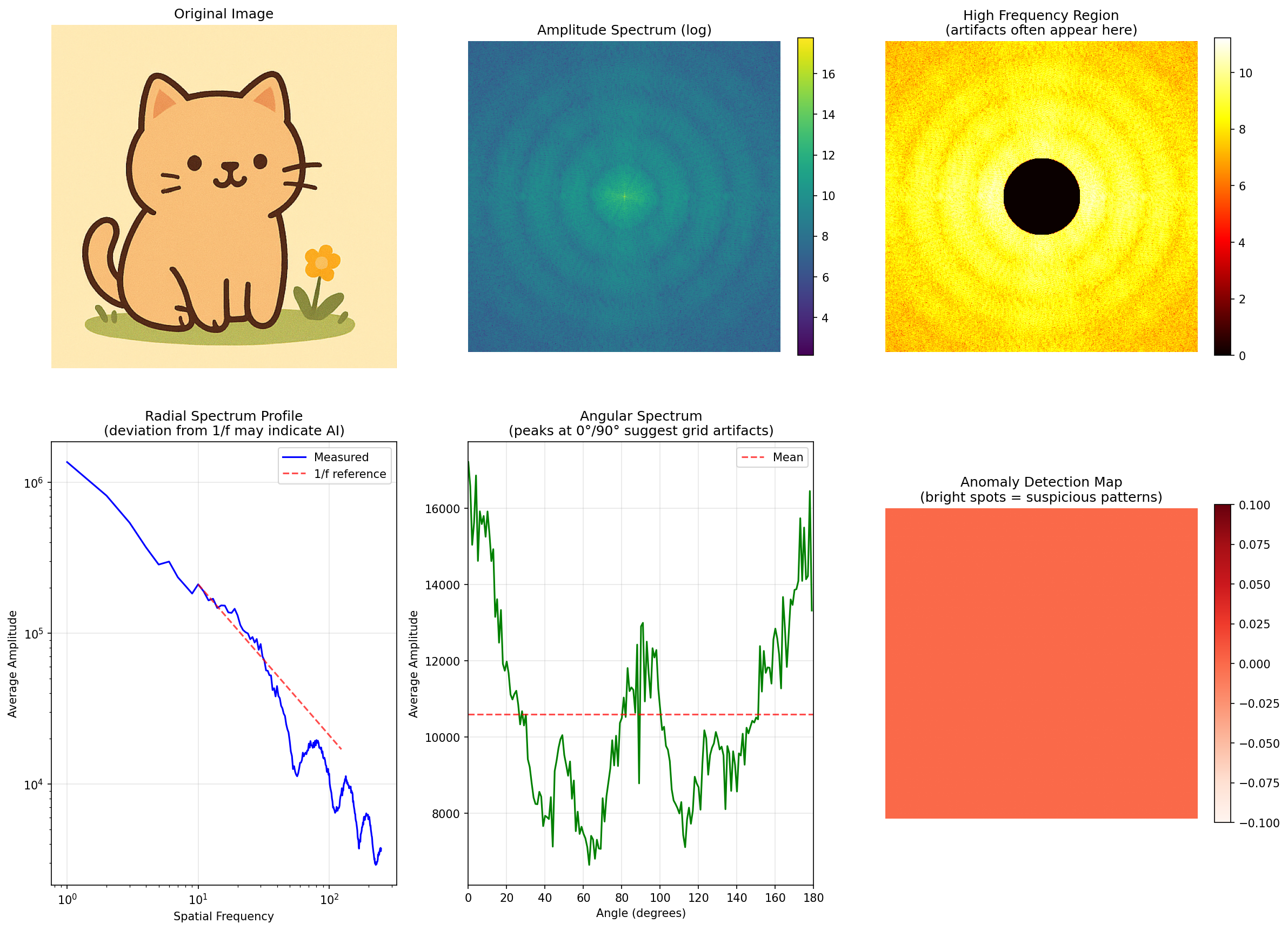
==================================================
AI Artifact Analysis Results
==================================================
High frequency energy ratio: 0.53% # >25% または <3% だとかなり怪しい
Angular spectrum variation: 67.06% # >15%(特定角度に集中)だとかなり怪しい
Deviation from 1/f law: 0.537 # >0.3だとかなり怪しい
==================================================お...おぉ...?
一番下の自然画像との乖離が0.537って出ると「おお、判別できてる」と思えますね。
では次はAI生成ではない画像を。
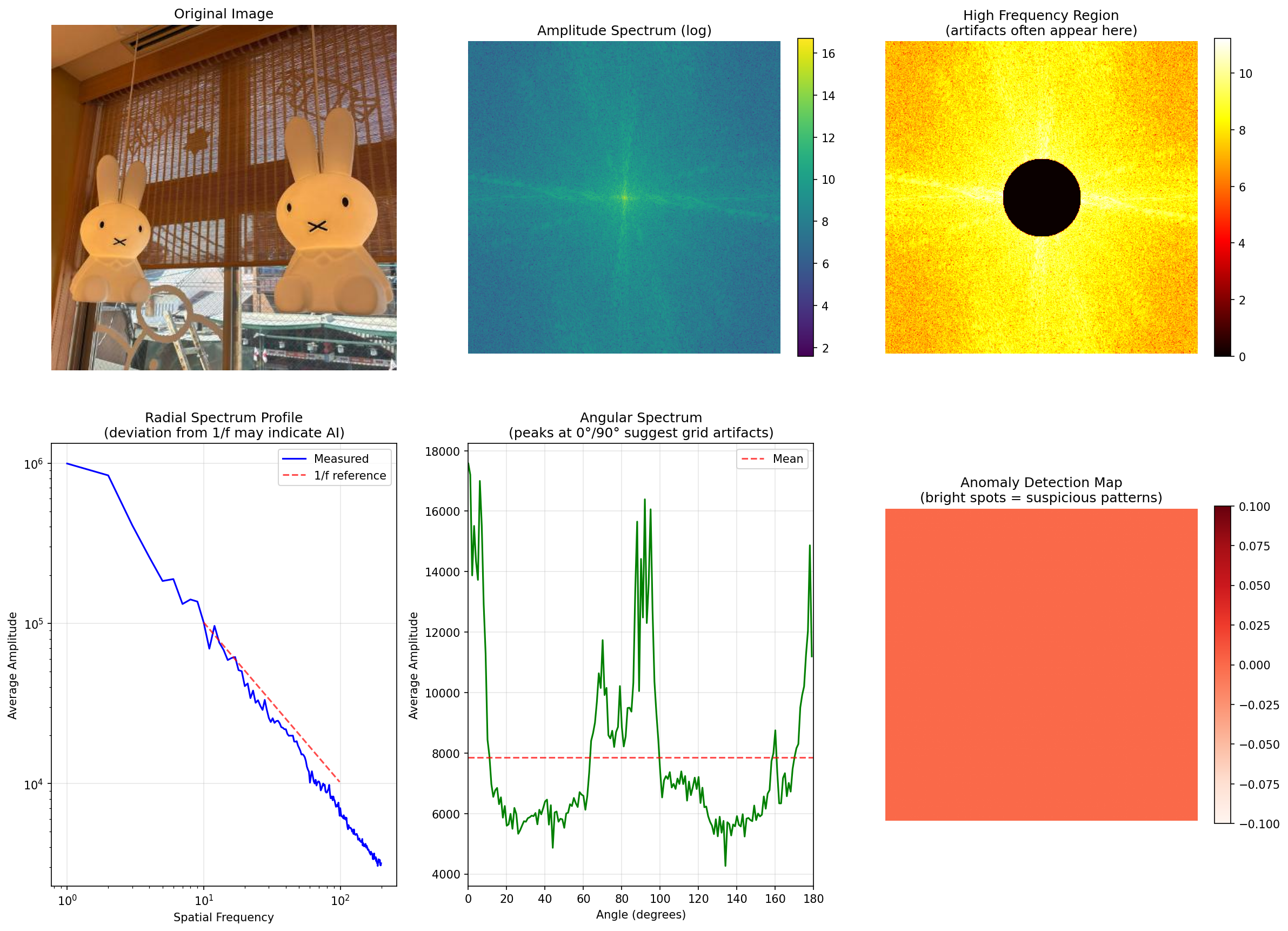
==================================================
AI Artifact Analysis Results
==================================================
High frequency energy ratio: 1.60% # >25% または <3% だとかなり怪しい
Angular spectrum variation: 36.09% # >15%(特定角度に集中)だとかなり怪しい
Deviation from 1/f law: 0.268 # >0.3だとかなり怪しい
==================================================変化が大きい画像なので上二つは怪しいラインですが、一番下の自然画像との乖離が基準値より下なのでギリギリ判別できていそうです
Day3の学び/感想
・周波数解析を行って画像を解析してみたところ、ギリギリAIだとわかる数値が出た (使用する生成サービスにもよると思うが...)
・数値としてみると「怪しいな...」と思ってたのが確信に変わりますね「見えない特徴」が可視化出来た気がします
Day4 : ノイズ解析にチャレンジしてみる
いよいよ終盤ですね。
まずはDay1で出てきたノイズに付いて調べてみました。
AI画像のノイズ特性:
1. ノイズの一貫性: 自然写真はセンサーノイズがあるが、AI画像は均一すぎるか不自然なノイズパターンを持つ
2. ノイズレベルの不均一性: 自然画像は明るさに応じてノイズレベルが変化するが、AI画像はそうでないことがある
3. ELA (Error Level Analysis): 再圧縮時のエラーパターンの違い
4. ノイズの周波数特性: センサーノイズは特定の特性を持つが、AI画像は異なる実装できる手法:
1. ノイズ抽出(高周波成分の分離)
2. ノイズレベルの空間的な分布
3. ノイズの統計的特性(分散、歪度、尖度)
4. ELA解析 (複数回保存された画像では精度が落ちることを利用した解析 もともと画像改ざんの発見に使われていた)
なるほど... 実装できる手法の中で4番が一番顕著に出そうですね。
早速試してみましょう。
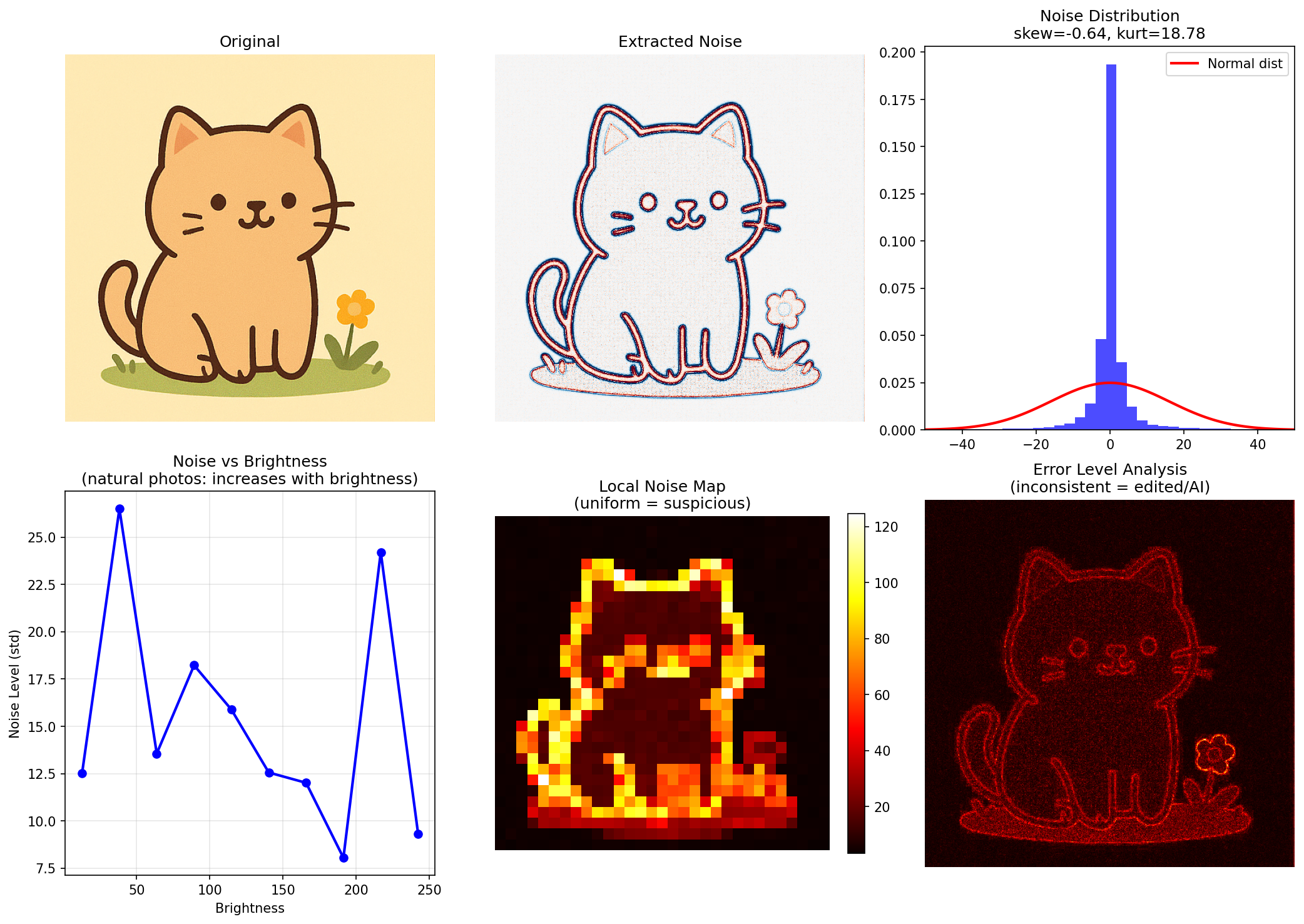
==================================================
Noise Analysis Results
==================================================
Noise std: 15.981
Skewness: -0.643 (0 = symmetric)
Kurtosis: 18.775 (0 = normal dist)
Brightness-Noise correlation: -0.285
(natural photos: positive correlation)
Noise uniformity: 1.206
(low = too uniform = suspicious)
==================================================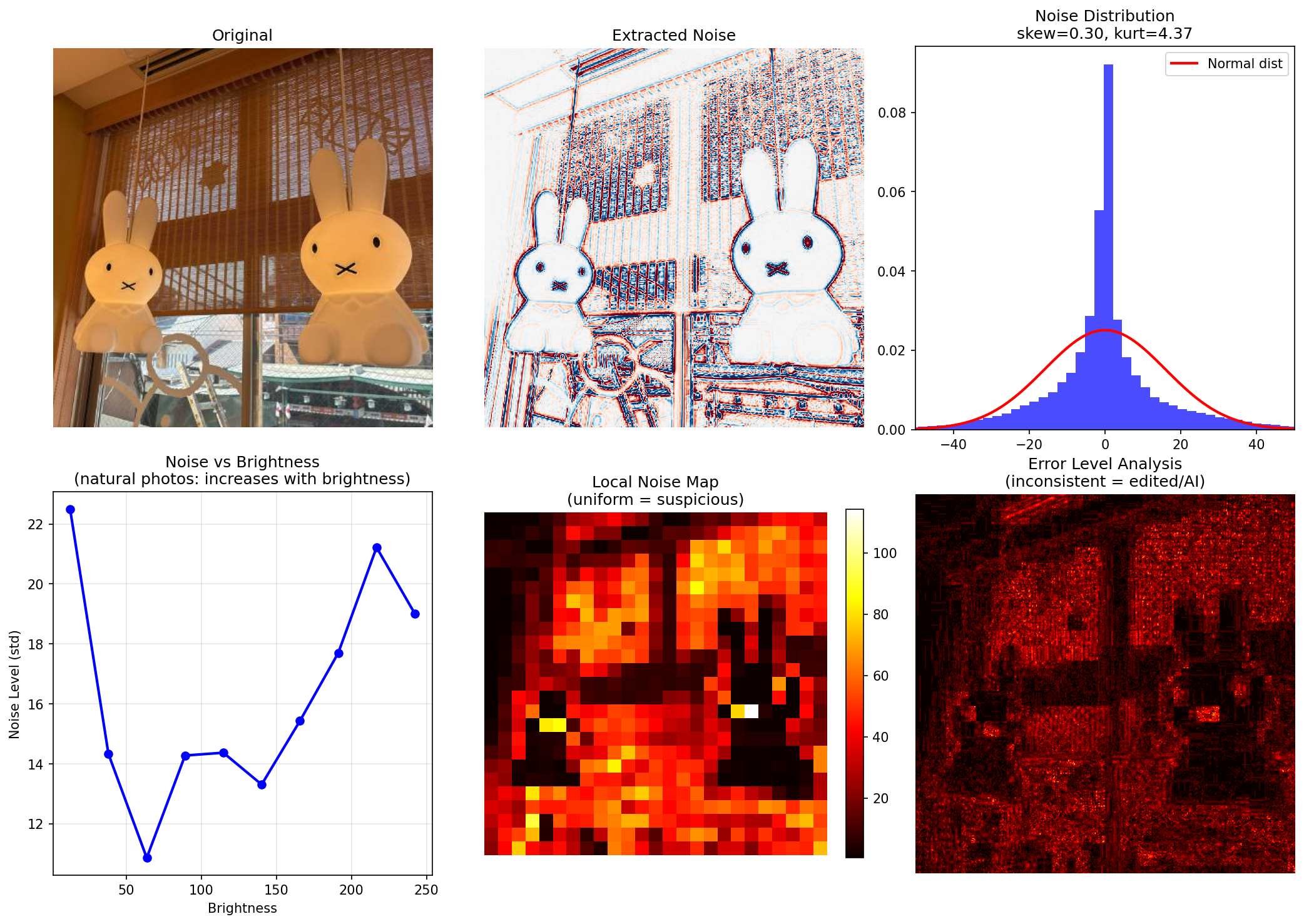
==================================================
Noise Analysis Results
==================================================
Noise std: 15.910
Skewness: 0.301 (0 = symmetric)
Kurtosis: 4.374 (0 = normal dist)
Brightness-Noise correlation: 0.266
(natural photos: positive correlation)
Noise uniformity: 0.731
(low = too uniform = suspicious)
==================================================...なるほど?数値で出されても今回は画像の専門用語ばかりにも見えるのでAIに解説を依頼してみました!
1. ノイズ分布(右上)
| AI生成 | 写真 | |
| skew(歪度) | -0.64 | 0.30 |
| kurtosis(尖度) | 18.78 | 4.37 |
AI生成 : 尖度が異常に高い(18.78)→ ノイズが均一すぎる
写真 : 尖度が低め(4.37)→ 自然なばらつき
2. 明るさ vs ノイズ(左下)
| AI生成 | 写真 | |
| パターン | 不規則・下降傾向 | 右肩上がり |
AI生成 : 相関がない・むしろ逆 → AI的
写真 : 明るいほどノイズ増加 → カメラセンサーの特性そのもの
3. 局所ノイズマップ(中央下)
AI生成 : エッジ部分だけ高い、他は均一 → 人工的
写真 : 全体的にばらつきあり → 自然
4. ELA(右下)
AI生成 : 輪郭がくっきり検出 → イラスト特有
写真 : 全体的にざらついた反応 → 写真の圧縮ノイズ
結論
| AI生成 | 写真 | |
| 判定 | AI生成の可能性高 | 実写真 |
| 根拠 | 尖度18.78、明るさ相関なし | 尖度4.37、明るさ相関あり |
おぉ.....予想通り右下で結構判別できそうですね (左下の図などからも判別ができたみたいですが、ぱっと見でわかりそうなのは右下という印象がありました)
Day4の学び/感想
・ノイズ解析を行ったところ、周波数解析とはまた違った部分で画像を見ることができた。
・周波数解析のみだとギリギリ判別できるか否かであったが、ノイズ解析の場合は比べてはっきりと出ることが分かった。
Day5 : 機械学習(CNN)にチャレンジ
機械学習...1日でモデルを1から作るのは時間的にも無理がありそうです...
ということで今回は転移学習という手法を使って、既存のモデルをベースにサクッと試してみることにしました。
そもそもCNNって何?
CNN(Convolutional Neural Network / 畳み込みニューラルネットワーク)は画像認識に特化したニューラルネットワークです。
ざっくり言うと:
画像 → [特徴を自動抽出] → [判定] → AI生成か否か
という流れで、AIが「この画像のどこを見れば判別できるか」を大量の画像から自動で学習してくれます。(すごい)
Day3・Day4では人間が「ここを見ればいい」と決めた特徴(周波数、ノイズ)を使いましたが、CNNは「どこを見るか」も含めて自分で学習するのがポイントみたいです。
転移学習とは
1からモデルを学習させるには大量のデータと時間が必要ですが、転移学習を使えばかなりショートカットできるらしい...
通常の学習:
ゼロから学習 → 数十万枚の画像 + 数日〜数週間
転移学習:
ImageNet学習済みモデル → 少しだけ追加学習 → 数百〜数千枚 + 数時間ImageNetで「猫」「犬」「車」などを見分けるために学習したモデルは、画像の基本的な特徴(エッジ、テクスチャ、形状など)を既に理解していて、これを流用して「AI生成か否か」の判別に使おうというわけです。
実際にやってみた
PyTorchとEfficientNetを使って、最小限のコードで試してみました。(もちろんClaudeCodeにつくってもらいましたが...)
準備したもの
・Real画像: 500枚
・Fake画像: 500枚
合計1000枚という少なさですが、転移学習なのでなんとかなる...はず
github(引用*2)にて公開されていた画像を利用しています。
コードの流れ
Python# ざっくりした流れ
1. EfficientNet(学習済みモデル)を読み込む
2. 最後の分類層だけを「2クラス分類」に差し替え
3. Real/Fake画像で追加学習(10エポック程度)
4. 新しい画像で判定!ClaudeCodeに実装してもらったコードで学習を回してみます...
結果
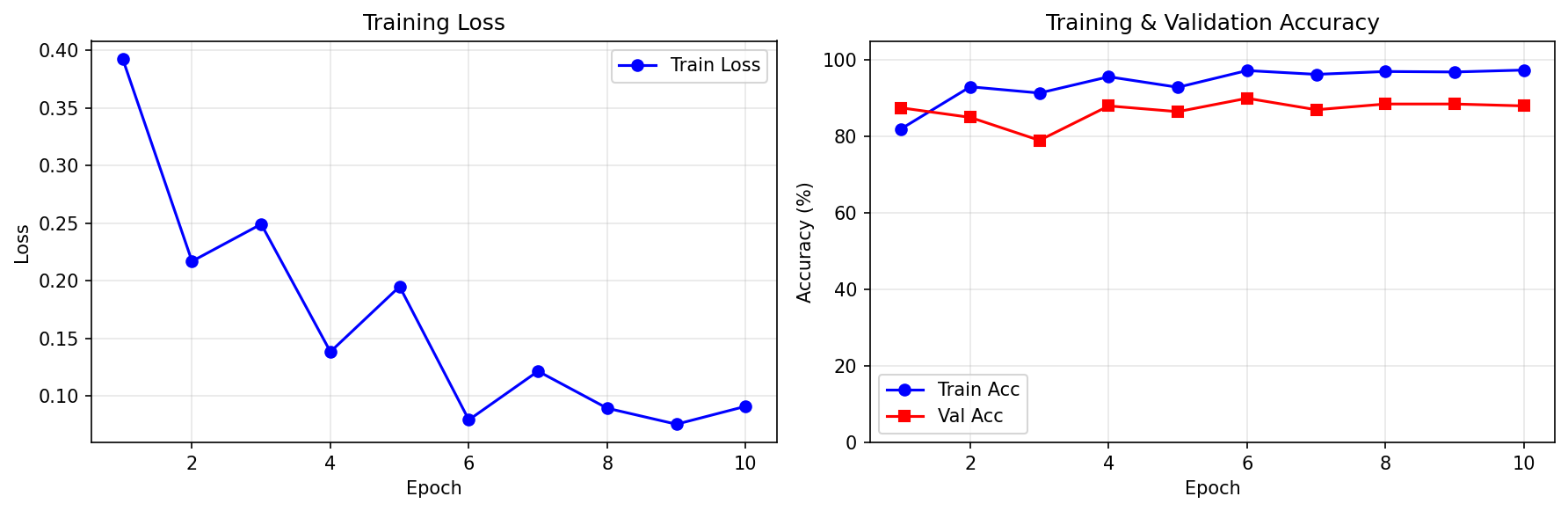
| 指標 | 結果 |
| 学習時間 | 約20分 |
| 訓練精度 | 約95% |
| テスト精度 | 約85% |
おお!1000枚という少ないデータでも、それなりに判別できるようになりました。
機械学習ってすごいですね... ちなみにAI生成の訓練画像見ましたがほぼわかりませんでした....くやしい...
CNNが見ている「特徴」って?
せっかくなので、モデルが画像のどこを見て判定しているのかを可視化してみました。Grad-CAMという手法でみれるらしいです。
Grad-CAM: モデルが「判定に重要だと思った部分」をヒートマップで表示する手法こちらも参考としてAI生成したもので見てみました。
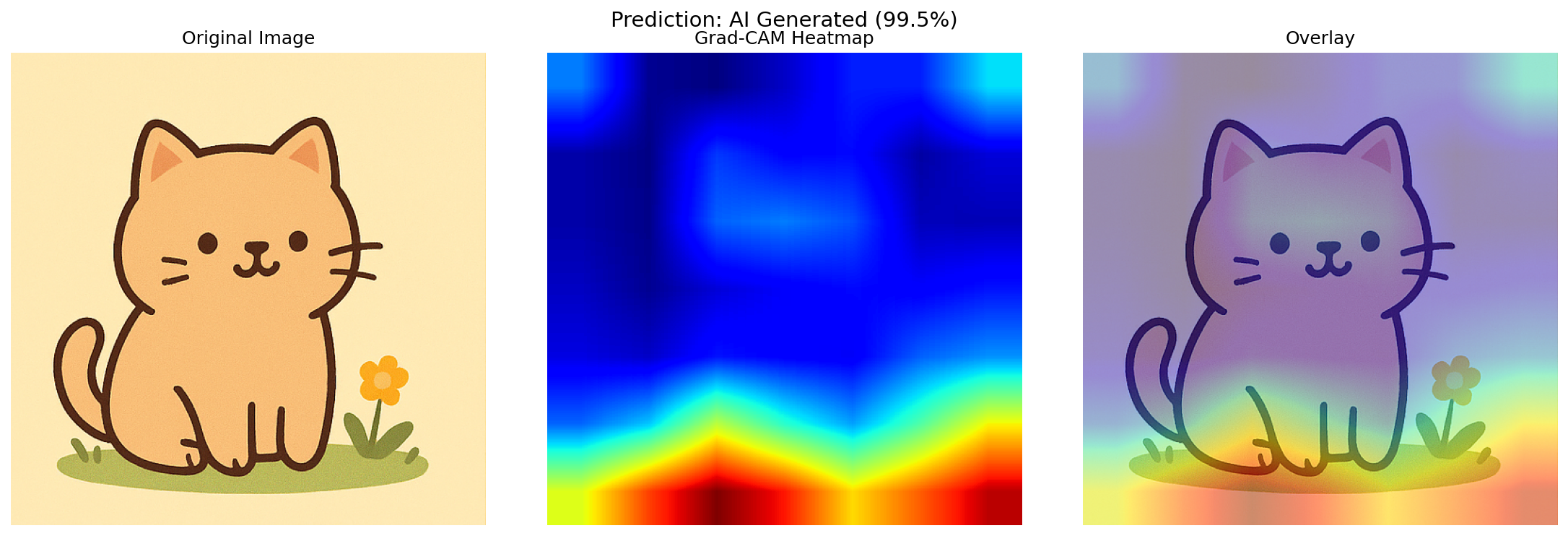
赤色の部分が着目している部分みたいなのですが、草木のザラザラしている部分に着目しているんですかね...?
Day3・Day4で「怪しい」と思った部分と、CNNが注目する部分が結構重なっていて面白いですね。
Day5の学び/感想
・転移学習を使えば、少ないデータ・短時間でもそれなりのモデルが作れる
・ただし「汎化性能」(未知の生成モデルへの対応)は課題
・CNNが見ている特徴を可視化すると、Day3・4の知見と繋がって理解が深まる
・本気でやるなら数万枚規模のデータセット+複数の生成モデルで学習が必要そう
5日間のまとめ
| Day | やったこと | 得られた知見 |
| 1 | 技術調査 | 既存ツールも完璧じゃない、手法は3系統 |
| 2 | 目視観察 | ノイズ感、不自然な部分は目でも分かる |
| 3 | 周波数解析 | 1/fからの乖離でギリギリ判別可能 |
| 4 | ノイズ解析 | ELA・尖度でかなり明確に差が出る |
| 5 | CNN分類器 | 転移学習で手軽に85%程度の精度 |
結論
「付け焼き刃の知識でどれほど判別できるか」という当初の問いに対する答えは...
→ 複数手法を組み合わせれば、それなりに根拠を持って「怪しい」と言えるようになる!
ただし、最新の生成モデルは本当に精度が高く、これらの手法でも見破れないケースが増えているのも事実です。
今後はC2PA(電子透かし)のような「生成時に証明を埋め込む」アプローチが主流になっていくかもしれませんね。
今後の生成AIはいつか見破れないほど精巧なものになっていくのでしょうか...(もうなっている気もしますが。)
それでは、ありがとうございました。
参考サイト (外部のサイトへのリンクです。)
*引用1【画像処理】フーリエ変換の原理・実装例 | 数理超入門部
使用したソースコード (※AI生成品)
Day3 : 振幅スペクトル分析
Python"""
PNG画像の周波数解析プログラム
2次元フーリエ変換を行い、振幅スペクトルを出力します
"""
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import sys
def analyze_frequency(image_path: str, output_path: str = None):
"""
画像を周波数解析し、振幅スペクトルを表示・保存する
Args:
image_path: 入力画像のパス
output_path: 出力画像のパス(省略時は表示のみ)
"""
# 画像を読み込み、グレースケールに変換
img = Image.open(image_path).convert('L')
img_array = np.array(img)
# 2次元フーリエ変換
f_transform = np.fft.fft2(img_array)
# 低周波成分を中央に移動
f_shift = np.fft.fftshift(f_transform)
# 振幅スペクトルを計算(対数スケール)
amplitude_spectrum = np.log1p(np.abs(f_shift))
# 結果を表示
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 元画像
axes[0].imshow(img_array, cmap='gray')
axes[0].set_title('Original Image')
axes[0].axis('off')
# 振幅スペクトル
axes[1].imshow(amplitude_spectrum, cmap='gray')
axes[1].set_title('Amplitude Spectrum (log scale)')
axes[1].axis('off')
plt.tight_layout()
if output_path:
plt.savefig(output_path, dpi=150, bbox_inches='tight')
print(f"保存しました: {output_path}")
plt.show()
if __name__ == "__main__":
if len(sys.argv) < 2:
print("使い方: python frequency_analysis.py <画像パス> [出力パス]")
print("例: python frequency_analysis.py input.png spectrum.png")
sys.exit(1)
image_path = sys.argv[1]
output_path = sys.argv[2] if len(sys.argv) > 2 else None
analyze_frequency(image_path, output_path)Day3 : アーティファクト分析
Python"""
AI生成画像のアーティファクト検出プログラム
フーリエ変換を用いてAI画像特有のパターンを可視化・分析します
検出できる主なアーティファクト:
1. 周期的なグリッドパターン(GANのアップサンプリング由来)
2. 特定周波数のスパイク
3. 放射状スペクトルの異常(自然画像は1/fに従う傾向)
"""
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
import sys
def compute_spectrum(img_array: np.ndarray) -> tuple:
"""2次元FFTと振幅スペクトルを計算"""
f_transform = np.fft.fft2(img_array)
f_shift = np.fft.fftshift(f_transform)
amplitude = np.abs(f_shift)
return f_shift, amplitude
def compute_radial_profile(amplitude: np.ndarray) -> tuple:
"""
放射状平均スペクトルを計算
自然画像は1/f(ピンクノイズ)パターンに従う傾向がある
"""
center_y, center_x = amplitude.shape[0] // 2, amplitude.shape[1] // 2
y, x = np.ogrid[:amplitude.shape[0], :amplitude.shape[1]]
r = np.sqrt((x - center_x)**2 + (y - center_y)**2).astype(int)
max_r = min(center_x, center_y)
radial_sum = np.bincount(r.ravel(), amplitude.ravel())
radial_count = np.bincount(r.ravel())
radial_mean = radial_sum / np.maximum(radial_count, 1)
return np.arange(len(radial_mean))[:max_r], radial_mean[:max_r]
def detect_periodic_artifacts(amplitude: np.ndarray, threshold_factor: float = 3.0) -> np.ndarray:
"""
周期的アーティファクト(スパイク)を検出
局所的な平均から大きく外れる点を検出
"""
# 対数スケールで処理
log_amp = np.log1p(amplitude)
# 局所平均を計算(ガウシアンブラー的な処理)
from scipy.ndimage import uniform_filter
local_mean = uniform_filter(log_amp, size=15)
local_std = np.sqrt(uniform_filter((log_amp - local_mean)**2, size=15))
# 異常値検出(中心のDC成分は除外)
center_y, center_x = amplitude.shape[0] // 2, amplitude.shape[1] // 2
mask = np.ones_like(amplitude, dtype=bool)
mask[center_y-5:center_y+5, center_x-5:center_x+5] = False
anomaly_map = np.zeros_like(amplitude)
anomaly_map[mask] = np.maximum(0, (log_amp[mask] - local_mean[mask]) / (local_std[mask] + 1e-10) - threshold_factor)
return anomaly_map
def compute_angular_spectrum(amplitude: np.ndarray, num_angles: int = 180) -> np.ndarray:
"""
角度ごとのスペクトル強度を計算
周期的なグリッドパターンは特定角度(0°, 90°など)に集中
"""
center_y, center_x = amplitude.shape[0] // 2, amplitude.shape[1] // 2
y, x = np.ogrid[:amplitude.shape[0], :amplitude.shape[1]]
# 中心からの距離と角度を計算
dist = np.sqrt((x - center_x)**2 + (y - center_y)**2)
angles = np.arctan2(y - center_y, x - center_x)
angles_deg = np.degrees(angles) % 180 # 0-180度に正規化
# 中心付近(低周波)と外側すぎる部分を除外
min_dist = min(center_x, center_y) * 0.1
max_dist = min(center_x, center_y) * 0.8
dist_mask = (dist > min_dist) & (dist < max_dist)
# 角度ビンごとに平均
bins = np.linspace(0, 180, num_angles + 1)
angular_profile = np.zeros(num_angles)
for i in range(num_angles):
mask = (angles_deg >= bins[i]) & (angles_deg < bins[i+1]) & dist_mask
if np.any(mask):
angular_profile[i] = np.mean(amplitude[mask])
return bins[:-1], angular_profile
def analyze_ai_artifacts(image_path: str, output_path: str = None):
"""
AI画像のアーティファクトを総合的に分析
"""
# 画像読み込み
img = Image.open(image_path)
original_mode = img.mode
# RGB画像として保持(表示用)
if original_mode in ['RGB', 'RGBA', 'P']:
img_rgb = np.array(img.convert('RGB'))
else:
img_rgb = None
# グレースケールに変換(解析用)
img_gray = img.convert('L')
img_array = np.array(img_gray)
# スペクトル計算
f_shift, amplitude = compute_spectrum(img_array)
# 放射状プロファイル
radii, radial_profile = compute_radial_profile(amplitude)
# アーティファクト検出
try:
anomaly_map = detect_periodic_artifacts(amplitude)
has_scipy = True
except ImportError:
anomaly_map = None
has_scipy = False
# 角度スペクトル
angle_bins, angular_profile = compute_angular_spectrum(amplitude)
# 可視化
fig = plt.figure(figsize=(16, 12))
# 1. 元画像
ax1 = fig.add_subplot(2, 3, 1)
if img_rgb is not None:
ax1.imshow(img_rgb)
else:
ax1.imshow(img_array, cmap='gray')
ax1.set_title('Original Image')
ax1.axis('off')
# 2. 振幅スペクトル(対数スケール)
ax2 = fig.add_subplot(2, 3, 2)
im2 = ax2.imshow(np.log1p(amplitude), cmap='viridis')
ax2.set_title('Amplitude Spectrum (log)')
ax2.axis('off')
plt.colorbar(im2, ax=ax2, fraction=0.046)
# 3. 高周波領域の強調表示
ax3 = fig.add_subplot(2, 3, 3)
# 中心部分をマスクして高周波を強調
high_freq_amp = amplitude.copy()
center_y, center_x = amplitude.shape[0] // 2, amplitude.shape[1] // 2
mask_size = min(center_x, center_y) // 4
y, x = np.ogrid[:amplitude.shape[0], :amplitude.shape[1]]
center_mask = (x - center_x)**2 + (y - center_y)**2 < mask_size**2
high_freq_amp[center_mask] = 0
im3 = ax3.imshow(np.log1p(high_freq_amp), cmap='hot')
ax3.set_title('High Frequency Region\n(artifacts often appear here)')
ax3.axis('off')
plt.colorbar(im3, ax=ax3, fraction=0.046)
# 4. 放射状プロファイル
ax4 = fig.add_subplot(2, 3, 4)
ax4.loglog(radii[1:], radial_profile[1:], 'b-', linewidth=1.5, label='Measured')
# 1/f参照線
if len(radii) > 10:
ref_freq = radii[10:len(radii)//2]
ref_amp = radial_profile[10] * (ref_freq[0] / ref_freq)
ax4.loglog(ref_freq, ref_amp, 'r--', alpha=0.7, label='1/f reference')
ax4.set_xlabel('Spatial Frequency')
ax4.set_ylabel('Average Amplitude')
ax4.set_title('Radial Spectrum Profile\n(deviation from 1/f may indicate AI)')
ax4.legend()
ax4.grid(True, alpha=0.3)
# 5. 角度分布
ax5 = fig.add_subplot(2, 3, 5)
ax5.plot(angle_bins, angular_profile, 'g-', linewidth=1.5)
ax5.axhline(np.mean(angular_profile), color='r', linestyle='--', alpha=0.7, label='Mean')
ax5.set_xlabel('Angle (degrees)')
ax5.set_ylabel('Average Amplitude')
ax5.set_title('Angular Spectrum\n(peaks at 0°/90° suggest grid artifacts)')
ax5.set_xlim(0, 180)
ax5.legend()
ax5.grid(True, alpha=0.3)
# 6. 異常検出マップ
ax6 = fig.add_subplot(2, 3, 6)
if has_scipy and anomaly_map is not None:
im6 = ax6.imshow(anomaly_map, cmap='Reds')
ax6.set_title('Anomaly Detection Map\n(bright spots = suspicious patterns)')
plt.colorbar(im6, ax=ax6, fraction=0.046)
else:
ax6.text(0.5, 0.5, 'scipy required\npip install scipy',
ha='center', va='center', transform=ax6.transAxes)
ax6.set_title('Anomaly Detection\n(requires scipy)')
ax6.axis('off')
plt.tight_layout()
# 統計情報を表示
print("\n" + "="*50)
print("AI Artifact Analysis Results")
print("="*50)
# 高周波エネルギー比率
total_energy = np.sum(amplitude**2)
high_freq_energy = np.sum(high_freq_amp**2)
hf_ratio = high_freq_energy / total_energy * 100
print(f"High frequency energy ratio: {hf_ratio:.2f}%")
# 角度分布の偏り
angular_std = np.std(angular_profile)
angular_mean = np.mean(angular_profile)
angular_cv = angular_std / angular_mean * 100
print(f"Angular spectrum variation: {angular_cv:.2f}%")
# 放射状プロファイルの1/fからの乖離
if len(radii) > 20:
measured = radial_profile[10:len(radii)//2]
expected = radial_profile[10] * (radii[10] / radii[10:len(radii)//2])
deviation = np.mean(np.abs(np.log(measured + 1) - np.log(expected + 1)))
print(f"Deviation from 1/f law: {deviation:.3f}")
if has_scipy and anomaly_map is not None:
anomaly_score = np.sum(anomaly_map > 0.5) / anomaly_map.size * 100
print(f"Anomaly pixel ratio: {anomaly_score:.3f}%")
print("="*50)
print("Note: These metrics are indicators, not definitive proof.")
print("AI detection requires comprehensive analysis.")
print("="*50 + "\n")
if output_path:
plt.savefig(output_path, dpi=150, bbox_inches='tight')
print(f"Saved: {output_path}")
plt.show()
if __name__ == "__main__":
if len(sys.argv) < 2:
print("使い方: python ai_artifact_detector.py <画像パス> [出力パス]")
print("例: python ai_artifact_detector.py ai_image.png result.png")
sys.exit(1)
image_path = sys.argv[1]
output_path = sys.argv[2] if len(sys.argv) > 2 else None
analyze_ai_artifacts(image_path, output_path)Day4 : ノイズ解析
Python"""
AI画像のノイズ解析プログラム
検出原理:
- 自然写真: カメラセンサー由来のノイズがある(明るさに依存)
- AI画像: ノイズが均一すぎる or 不自然なパターン
"""
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from scipy import ndimage
import sys
def extract_noise(img_array: np.ndarray, method: str = 'highpass') -> np.ndarray:
"""ノイズ成分を抽出"""
if method == 'highpass':
# ガウシアンぼかしで低周波を除去
blurred = ndimage.gaussian_filter(img_array.astype(float), sigma=2)
noise = img_array.astype(float) - blurred
elif method == 'median':
# メディアンフィルタで構造を除去
filtered = ndimage.median_filter(img_array, size=3)
noise = img_array.astype(float) - filtered.astype(float)
return noise
def analyze_noise_by_brightness(img_array: np.ndarray, noise: np.ndarray, bins: int = 10):
"""明るさ別のノイズレベルを分析(自然画像は明るさに応じてノイズが変化)"""
brightness_bins = np.linspace(0, 255, bins + 1)
noise_levels = []
bin_centers = []
for i in range(bins):
mask = (img_array >= brightness_bins[i]) & (img_array < brightness_bins[i + 1])
if np.sum(mask) > 100:
noise_levels.append(np.std(noise[mask]))
bin_centers.append((brightness_bins[i] + brightness_bins[i + 1]) / 2)
return np.array(bin_centers), np.array(noise_levels)
def compute_noise_statistics(noise: np.ndarray) -> dict:
"""ノイズの統計量を計算"""
from scipy import stats
flat = noise.flatten()
return {
'std': np.std(flat),
'skewness': stats.skew(flat), # 歪度(0に近いほど対称)
'kurtosis': stats.kurtosis(flat), # 尖度(0=正規分布)
}
def compute_local_noise_map(img_array: np.ndarray, window: int = 16) -> np.ndarray:
"""局所的なノイズレベルのマップを作成"""
h, w = img_array.shape
noise_map = np.zeros((h // window, w // window))
for i in range(noise_map.shape[0]):
for j in range(noise_map.shape[1]):
block = img_array[i*window:(i+1)*window, j*window:(j+1)*window]
# ラプラシアンで高周波成分を検出
laplacian = ndimage.laplace(block.astype(float))
noise_map[i, j] = np.std(laplacian)
return noise_map
def ela_analysis(image_path: str, quality: int = 90) -> np.ndarray:
"""Error Level Analysis - 再圧縮時の誤差を検出"""
import io
img = Image.open(image_path).convert('RGB')
# JPEG再圧縮
buffer = io.BytesIO()
img.save(buffer, format='JPEG', quality=quality)
buffer.seek(0)
recompressed = Image.open(buffer)
# 差分を計算・強調
diff = np.abs(np.array(img).astype(float) - np.array(recompressed).astype(float))
ela = np.mean(diff, axis=2) # RGB平均
ela = (ela / ela.max() * 255).astype(np.uint8)
return ela
def analyze_noise(image_path: str, output_path: str = None):
"""ノイズ解析のメイン関数"""
# 画像読み込み
img = Image.open(image_path)
img_rgb = np.array(img.convert('RGB'))
img_gray = np.array(img.convert('L'))
# ノイズ抽出
noise = extract_noise(img_gray, method='highpass')
# 各種分析
brightness, noise_by_bright = analyze_noise_by_brightness(img_gray, noise)
stats = compute_noise_statistics(noise)
noise_map = compute_local_noise_map(img_gray)
ela = ela_analysis(image_path)
# 可視化
fig = plt.figure(figsize=(14, 10))
# 1. 元画像
ax1 = fig.add_subplot(2, 3, 1)
ax1.imshow(img_rgb)
ax1.set_title('Original')
ax1.axis('off')
# 2. 抽出したノイズ
ax2 = fig.add_subplot(2, 3, 2)
ax2.imshow(noise, cmap='RdBu', vmin=-30, vmax=30)
ax2.set_title('Extracted Noise')
ax2.axis('off')
# 3. ノイズのヒストグラム
ax3 = fig.add_subplot(2, 3, 3)
ax3.hist(noise.flatten(), bins=100, density=True, alpha=0.7, color='blue')
# 正規分布を重ねる
x = np.linspace(-50, 50, 100)
normal = np.exp(-x**2 / (2 * stats['std']**2)) / (stats['std'] * np.sqrt(2 * np.pi))
ax3.plot(x, normal, 'r-', linewidth=2, label='Normal dist')
ax3.set_title(f"Noise Distribution\nskew={stats['skewness']:.2f}, kurt={stats['kurtosis']:.2f}")
ax3.set_xlim(-50, 50)
ax3.legend()
# 4. 明るさ別ノイズレベル
ax4 = fig.add_subplot(2, 3, 4)
ax4.plot(brightness, noise_by_bright, 'bo-', linewidth=2)
ax4.set_xlabel('Brightness')
ax4.set_ylabel('Noise Level (std)')
ax4.set_title('Noise vs Brightness\n(natural photos: increases with brightness)')
ax4.grid(True, alpha=0.3)
# 5. 局所ノイズマップ
ax5 = fig.add_subplot(2, 3, 5)
im5 = ax5.imshow(noise_map, cmap='hot')
ax5.set_title('Local Noise Map\n(uniform = suspicious)')
ax5.axis('off')
plt.colorbar(im5, ax=ax5, fraction=0.046)
# 6. ELA
ax6 = fig.add_subplot(2, 3, 6)
ax6.imshow(ela, cmap='hot')
ax6.set_title('Error Level Analysis\n(inconsistent = edited/AI)')
ax6.axis('off')
plt.tight_layout()
# 統計情報
print("\n" + "=" * 50)
print("Noise Analysis Results")
print("=" * 50)
print(f"Noise std: {stats['std']:.3f}")
print(f"Skewness: {stats['skewness']:.3f} (0 = symmetric)")
print(f"Kurtosis: {stats['kurtosis']:.3f} (0 = normal dist)")
# 明るさ-ノイズ相関
if len(brightness) > 2:
correlation = np.corrcoef(brightness, noise_by_bright)[0, 1]
print(f"Brightness-Noise correlation: {correlation:.3f}")
print(" (natural photos: positive correlation)")
# ノイズマップの均一性
noise_uniformity = np.std(noise_map) / np.mean(noise_map)
print(f"Noise uniformity: {noise_uniformity:.3f}")
print(" (low = too uniform = suspicious)")
print("=" * 50)
if output_path:
plt.savefig(output_path, dpi=150, bbox_inches='tight')
print(f"Saved: {output_path}")
plt.show()
if __name__ == "__main__":
if len(sys.argv) < 2:
print("使い方: python noise_analyzer.py <画像パス> [出力パス]")
sys.exit(1)
analyze_noise(sys.argv[1], sys.argv[2] if len(sys.argv) > 2 else None)Day5 : 転移学習
Python"""
AI生成画像検出 - 最小限のCNN分類器
転移学習(EfficientNet)を使ったシンプルな実装
使い方:
学習: python cnn_detector.py train --real ./real --fake ./fake
判定: python cnn_detector.py predict image.png
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import os
import argparse
# ========== データセット ==========
class AIDetectionDataset(Dataset):
def __init__(self, real_dir, fake_dir, transform=None):
self.samples = []
self.transform = transform
# Real画像 (ラベル: 0)
if os.path.exists(real_dir):
for f in os.listdir(real_dir):
if f.lower().endswith(('.png', '.jpg', '.jpeg')):
self.samples.append((os.path.join(real_dir, f), 0))
# Fake画像 (ラベル: 1)
if os.path.exists(fake_dir):
for f in os.listdir(fake_dir):
if f.lower().endswith(('.png', '.jpg', '.jpeg')):
self.samples.append((os.path.join(fake_dir, f), 1))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
path, label = self.samples[idx]
image = Image.open(path).convert('RGB')
if self.transform:
image = self.transform(image)
return image, label
# ========== モデル ==========
class Detector(nn.Module):
def __init__(self):
super().__init__()
# EfficientNet-B0を使用(軽量で高性能)
self.backbone = models.efficientnet_b0(weights='IMAGENET1K_V1')
# 最終層を2クラス分類に変更
num_features = self.backbone.classifier[1].in_features
self.backbone.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(num_features, 2)
)
def forward(self, x):
return self.backbone(x)
# ========== 前処理 ==========
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# ========== 学習 ==========
def train(real_dir, fake_dir, epochs=10, save_path='detector.pth', graph_path='training_curve.png'):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Device: {device}")
# データ準備
dataset = AIDetectionDataset(real_dir, fake_dir, transform)
print(f"データ数: {len(dataset)} 枚")
# 訓練/検証に分割 (8:2)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_set, val_set = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_set, batch_size=16, shuffle=True)
val_loader = DataLoader(val_set, batch_size=16)
# モデル・損失関数・最適化
model = Detector().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 記録用リスト
history = {
'train_loss': [],
'train_acc': [],
'val_acc': []
}
# 学習ループ
for epoch in range(epochs):
# 訓練
model.train()
train_loss, train_correct = 0, 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_correct += (outputs.argmax(1) == labels).sum().item()
# 検証
model.eval()
val_correct = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
val_correct += (outputs.argmax(1) == labels).sum().item()
# 記録
avg_loss = train_loss / len(train_loader)
train_acc = 100 * train_correct / len(train_set)
val_acc = 100 * val_correct / len(val_set) if len(val_set) > 0 else 0
history['train_loss'].append(avg_loss)
history['train_acc'].append(train_acc)
history['val_acc'].append(val_acc)
print(f"Epoch {epoch+1}/{epochs} | "
f"Loss: {avg_loss:.4f} | "
f"Train Acc: {train_acc:.1f}% | Val Acc: {val_acc:.1f}%")
# 保存
torch.save(model.state_dict(), save_path)
print(f"\nモデル保存: {save_path}")
# グラフ作成
plot_training_curve(history, epochs, graph_path)
def plot_training_curve(history, epochs, save_path='training_curve.png'):
"""学習曲線をプロットして保存"""
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
x = range(1, epochs + 1)
# Loss
ax1.plot(x, history['train_loss'], 'b-', marker='o', label='Train Loss')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss')
ax1.set_title('Training Loss')
ax1.legend()
ax1.grid(True, alpha=0.3)
# Accuracy
ax2.plot(x, history['train_acc'], 'b-', marker='o', label='Train Acc')
ax2.plot(x, history['val_acc'], 'r-', marker='s', label='Val Acc')
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Accuracy (%)')
ax2.set_title('Training & Validation Accuracy')
ax2.legend()
ax2.grid(True, alpha=0.3)
ax2.set_ylim(0, 105)
plt.tight_layout()
plt.savefig(save_path, dpi=150, bbox_inches='tight')
print(f"学習曲線保存: {save_path}")
plt.show()
# ========== 判定 ==========
def predict(image_path, model_path='detector.pth'):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# モデル読み込み
model = Detector()
model.load_state_dict(torch.load(model_path, map_location=device))
model.to(device)
model.eval()
# 画像読み込み・前処理
image = Image.open(image_path).convert('RGB')
input_tensor = transform(image).unsqueeze(0).to(device)
# 推論
with torch.no_grad():
output = model(input_tensor)
probs = torch.softmax(output, dim=1)[0]
real_prob = probs[0].item()
fake_prob = probs[1].item()
print("\n" + "="*40)
print(f"判定結果: {image_path}")
print("="*40)
print(f"Real確率: {real_prob*100:.1f}%")
print(f"Fake確率: {fake_prob*100:.1f}%")
print("-"*40)
if fake_prob > 0.5:
print(f"→ AI生成の可能性が高い ({fake_prob*100:.1f}%)")
else:
print(f"→ 実写の可能性が高い ({real_prob*100:.1f}%)")
print("="*40)
# ========== Grad-CAM ==========
class GradCAM:
"""Grad-CAMでモデルの注目領域を可視化"""
def __init__(self, model, target_layer):
self.model = model
self.target_layer = target_layer
self.gradients = None
self.activations = None
# フック登録
target_layer.register_forward_hook(self._save_activation)
target_layer.register_full_backward_hook(self._save_gradient)
def _save_activation(self, module, input, output):
self.activations = output.detach()
def _save_gradient(self, module, grad_input, grad_output):
self.gradients = grad_output[0].detach()
def generate(self, input_tensor, target_class=None):
# 順伝播
output = self.model(input_tensor)
if target_class is None:
target_class = output.argmax(dim=1).item()
# 逆伝播
self.model.zero_grad()
one_hot = torch.zeros_like(output)
one_hot[0, target_class] = 1
output.backward(gradient=one_hot)
# Grad-CAM計算
weights = self.gradients.mean(dim=(2, 3), keepdim=True)
cam = (weights * self.activations).sum(dim=1, keepdim=True)
cam = F.relu(cam)
# 正規化
cam = cam - cam.min()
cam = cam / (cam.max() + 1e-8)
return cam.squeeze().cpu().numpy()
def gradcam(image_path, model_path='detector.pth', save_path='gradcam_result.png'):
"""Grad-CAMで判定根拠を可視化"""
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# モデル読み込み
model = Detector()
model.load_state_dict(torch.load(model_path, map_location=device))
model.to(device)
model.eval()
# EfficientNetの最終畳み込み層を取得
target_layer = model.backbone.features[-1]
# Grad-CAM初期化
cam = GradCAM(model, target_layer)
# 画像読み込み
original_image = Image.open(image_path).convert('RGB')
input_tensor = transform(original_image).unsqueeze(0).to(device)
# 推論
with torch.enable_grad():
output = model(input_tensor)
probs = torch.softmax(output, dim=1)[0]
pred_class = output.argmax(dim=1).item()
# Grad-CAM生成
heatmap = cam.generate(input_tensor, target_class=pred_class)
# ヒートマップをリサイズ
heatmap_resized = np.array(Image.fromarray(
(heatmap * 255).astype(np.uint8)
).resize(original_image.size, Image.BILINEAR)) / 255.0
# 可視化
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# 元画像
axes[0].imshow(original_image)
axes[0].set_title('Original Image')
axes[0].axis('off')
# ヒートマップ
axes[1].imshow(heatmap_resized, cmap='jet')
axes[1].set_title('Grad-CAM Heatmap')
axes[1].axis('off')
# オーバーレイ
overlay = np.array(original_image) / 255.0
heatmap_color = plt.cm.jet(heatmap_resized)[:, :, :3]
blended = 0.6 * overlay + 0.4 * heatmap_color
blended = np.clip(blended, 0, 1)
axes[2].imshow(blended)
axes[2].set_title('Overlay')
axes[2].axis('off')
# 判定結果をタイトルに
real_prob = probs[0].item()
fake_prob = probs[1].item()
result = "AI Generated" if pred_class == 1 else "Real"
confidence = fake_prob if pred_class == 1 else real_prob
fig.suptitle(f'Prediction: {result} ({confidence*100:.1f}%)', fontsize=14)
plt.tight_layout()
plt.savefig(save_path, dpi=150, bbox_inches='tight')
print(f"\nGrad-CAM保存: {save_path}")
plt.show()
print("\n" + "="*40)
print(f"判定: {result}")
print(f"Real確率: {real_prob*100:.1f}%")
print(f"Fake確率: {fake_prob*100:.1f}%")
print("="*40)
print("赤い部分 = モデルが注目している領域")
print("="*40)
# ========== メイン ==========
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='AI生成画像検出器')
subparsers = parser.add_subparsers(dest='command')
# train コマンド
train_parser = subparsers.add_parser('train', help='モデルを学習')
train_parser.add_argument('--real', required=True, help='Real画像のフォルダ')
train_parser.add_argument('--fake', required=True, help='Fake画像のフォルダ')
train_parser.add_argument('--epochs', type=int, default=10, help='エポック数')
train_parser.add_argument('--output', default='detector.pth', help='モデル保存先')
train_parser.add_argument('--graph', default='training_curve.png', help='学習曲線の保存先')
# predict コマンド
pred_parser = subparsers.add_parser('predict', help='画像を判定')
pred_parser.add_argument('image', help='判定する画像パス')
pred_parser.add_argument('--model', default='detector.pth', help='モデルパス')
# gradcam コマンド
cam_parser = subparsers.add_parser('gradcam', help='Grad-CAMで可視化')
cam_parser.add_argument('image', help='判定する画像パス')
cam_parser.add_argument('--model', default='detector.pth', help='モデルパス')
cam_parser.add_argument('--output', default='gradcam_result.png', help='保存先')
args = parser.parse_args()
if args.command == 'train':
train(args.real, args.fake, args.epochs, args.output, args.graph)
elif args.command == 'predict':
predict(args.image, args.model)
elif args.command == 'gradcam':
gradcam(args.image, args.model, args.output)
else:
parser.print_help()










![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
