






はじめまして。9月1日付けでJOINした花野です。
「時間が7倍で流れる」と言われるくらい変化の激しいFIXERで日々刺激的に楽しく過ごしています。
そんな中、11月5日~7日に開催されたMicrosoft
TechSummit2018に行って来たので、面白かったセッションを紹介させていただきます。
Azureクラウドインフラストクチャで実現する高可用性アーキテクチャ

Azureのシステムを構築する際に、高可用性を実現するにはどうすればいいの?というお話です。システムを導入するにあたって重要となる話を分かりやすく解説いただいて、とても勉強になりました。
ご存知の方も多いかもしれませんが、Azureではまず大前提として主要なサービスにSLAが設定されています。これはAzureの特徴の一つで、この値をふまえた上で、ビジネス要件を鑑みて「冗長化が必要かどうか」を検討できます。
例えばバーチャルマシンの場合は、以下のような構成を選択できます。図の左から右に行くに従って可用性が高くなります。

図の一番左は、単純に何も考えずにバーチャルマシンを立てた場合です。プレミアムストレージで構成した場合に限りますが、ユーザーが特に意識しなくても、Azureの方で99.9%のSLAを実現してくれます。
これは心強いですね。
しかし冷静に考えてみてください。Azureと言えども、その基盤を動かしている実態はサーバです。サーバを運用している場合、定期的なメンテナンスの再起動や、突発的なシャットダウンは避けて通れません。
つまり我々がAzureサービスの高いSLAの恩恵を受けている裏には、涙ぐましいMicrosoftさんの努力があったのです!

Microsoftによるメンテナンスの手段は上記のチャートに沿って進みます。
まずはなるべく影響が少ないメンテナンス手段を選び、その方法が選択できない場合に限り、順繰りに影響の大きい手段へとエスカレーションして行くようです。メンテナンスの手法はユーザーでは選べません。
ここで我々が気にしないといけないことは、それぞれのメンテナンスにおいてバーチャルマシンにどんな影響があるかということです。

インプレースマイグレーションの場合は、バーチャルマシンのメモリが保持されたままの状態でホストのメンテナンスが実行されます。この際、30秒~数秒だけ、バーチャルマシンの一時停止が発生します。※シャットダウンはしません!
「あれ、一瞬意識飛んでた?」みたいな感じでしょうか。
つまりシステムを構築する際は「最大30秒程度、たまに意識が飛ぶかも」ということを知った上で設計しないといけないということです。
一方、ライブマイグレーションは、バーチャルマシンを別ホストへお引越しさせる手法です。
お引越しの際、パフォーマンスが低下する可能性があるそうです。
そして上記の手法が取れない場合は、やむを得ずバーチャルマシンの停止が必要な手法が採択されます。ただし、いきなり問答無用で停止させられるわけではなく、「セルフサービス期間」という、ユーザーが任意のタイミングでメンテナンス完了にできる期間が設けられます。
また、セルフサービス期間を過ぎて自動的にメンテナンスが開始される際は、15分前にその情報が「スケジュールされたイベント」としてREST
APIで取得できるので、その際の動きを予め設計しておいて組み込むこともできます。

上記までが、ユーザーで冗長化構成を組まずに単純にバーチャルマシンを利用した際の話です。以下からいよいよ冗長化を組む話になります。
普段オンプレミスで冗長化を組む際は、複数のマシンを立てて、ロードバランサなり、SQL
ServerのAlwaysOnなり、そのサーバの種類によって冗長化を実装するかと思います。
Azureでも基本的な考え方は変わりません。
しかし注意しないといけないのは、Azure上で何も考えずにバーチャルマシンを2台立ててしまうと、実は動いている基盤が共通で、ハード故障などの影響を一緒に受けてしまうかもしれないということです。
そんな時に使うのが可用性セットです。
可用性セットにより、基盤的に独立したバーチャルマシン同士になるので「お前が落ちても俺がやる!」という状況が実現できるわけです。
なお、注意点としては、可用性セットのバーチャルマシンは管理ディスク推奨ということです。管理ディスクにすることにより、ディスクが単一点障害にならないよう相互に十分に分離されるそうです。

さて、ここまでやってもデータセンタがまるごと落ちてしまっては残念ながら意味がありません。
そんな時に有効なのがAvailability
Zonesです。
これは1つのリージョン内で、電気系統などが物理的に独立したゾーンを3つ以上持つというものです。

残念ながら現在は対応リージョンおよびサービスに制限がありますが、Application Gatewayがプレビューで出たり、ゾーン冗長仮想ネットワークゲートウェイがGAで出たりしているので、これからが楽しみな機能です!
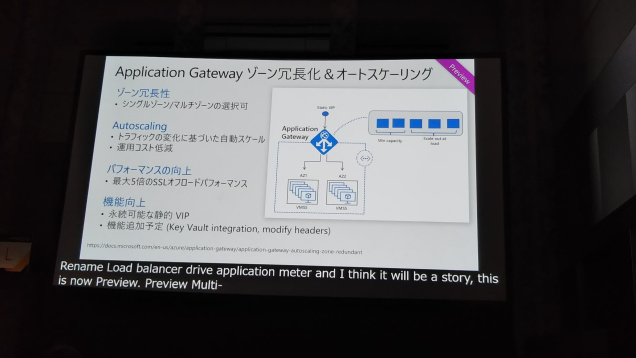
また、ロードバランサ、フロントエンドサーバ、SQL Databaseという構成なら、現状のAvailability Zonesでも十分に構成ができるそうです。

さらには、グローバルレベルのロードバランシングを実現する機能として、プレビューのFront
Doorが紹介されていました。
これは元々は一番速く繋げられるリージョンに繋ぐという、高速化のための機能でした。
つまり要は複数のリージョンに繋げられるサービスというわけで、冗長化にも使えるということです。このように、とある機能の本質を見ると実は他の機能にも使えるというのはエレガントでわくわくします。

他にも、ストレージ冗長オプションやAzure Service Health
Alertsが紹介されたりと盛りだくさんなセッションでした。
色々とご紹介したくて、エントリが長くなってしまいました。ここまで読んでくださってありがとうございます。
そして実はまだ紹介しきれなかったスライドがたくさんあります。そのうち公式にスライドが公開されると思うので、ぜひ見てみてくださいね。
まとめると
- ユーザーが意識しなくてもAzureの機能で高いSLAが実現されている
- 各種冗長構成を組むことでさらに高いSLAも実現できる
- 要件に合わせて選びましょう
でした。
他にも色々とセッションを聞いたので、また別エントリでご紹介させていただきます。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
