


 2019-06-05
2019-06-05

はじめに
5/30~6/2に開催されたNHK放送技術研究所の技研公開2019で見学した自然言語処理(NLP)に関する展示の紹介をこの記事で行います。
今回見学したのは
- 一緒にテレビを視聴して雑談してくれるロボット
- AIアナウンサー
- ニュースを対象とした日英翻訳システム
です。 上から1つずつ紹介していきます。
一緒にテレビを視聴して雑談してくれるロボット
今回展示されていた雑談ロボットは
- 番組の内容の認識に基づく発話文の自動生成
- ロボットの発話を起点とした音声対話
の2つで構成されていました。
番組の内容の認識に基づく発話文の自動生成
始めに番組の認識に基づく、発話文の自動生成について紹介します。 大まかな構成は以下のようになっています。
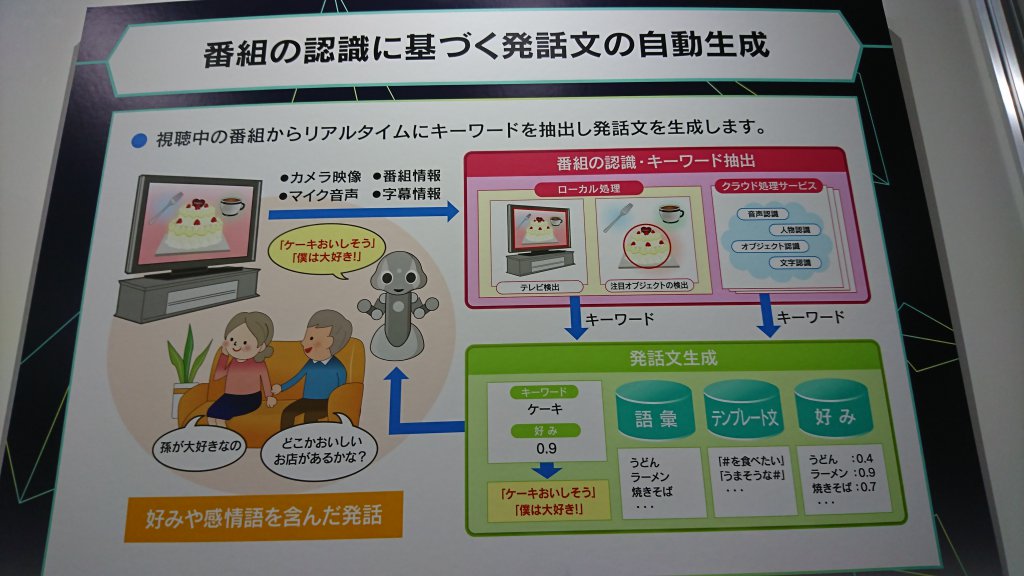
下の写真のディスプレイが実際に左側でテレビ画面を解析している様子になります。
流れとしては
- テレビ画面を検出
- 検出したテレビ画面を正面に補正し、オブジェクト検出(画面に何が映っているのか)と顕著性マップの作成(人間がどこに注目するのかをピクセル単位で表現)、文字検出(画面にどんな文字が表示されているか)を行う
となります。
特徴的なのは顕著性マップの作成です。
通常、オブジェクト検出は画面に映っているものをすべて検出します。
そのため、本来取得したい画面のシーンを象徴づけるものの単語以外もたくさん出力されます。
その象徴的でない単語に基づいて作成された文は、視聴者の想定するこのシーンを見たときの雑談とは全く異なり、会話に違和感を感じさせてしまいます。
例えば、下の画像では「木」、「人」、「自転車」、「バックパック」などが検出されていて、「木」を使った「木がたくさん生えていますね」といった文は視聴者に違和感を与えてしまいます。
それを防ぐために顕著性マップの作成を行い、視聴者の注目しているものの選択を行っているそうです(画像左下の赤い丸で囲まれた単語が注目しているものの単語)。

先ほどの解析結果によって抽出された視聴者が注目しているキーワードのほかにテレビの情報や字幕情報を加えて取得したテレビ番組のキーワードは以下の画像の上半分のように出力されます。
その抽出したキーワードを使って作成した文が下半分の部分で表示されています。
「クラウドは質問を理解するのが苦手です」といったように少し違和感のある文が生成されています。
これには文の生成方法が関わっているそうです。
説明員の方によると、
- 動詞リストを用意しておき、キーワードとよく用いられる動詞を抽出
- 蓄積した字幕データなどの文から、その動詞を含む文を抽出
- 抽出した文の名詞をキーワードに置き換え
といったように文を自動生成しているそうです。
そのため、少し違和感のある文も生成されてしまうとのことです。

ロボットの発話を起点とした音声対話
先ほど生成した文をきっかけとして、視聴者と対話するシステムも公開されていました。
システムの概要は以下です。
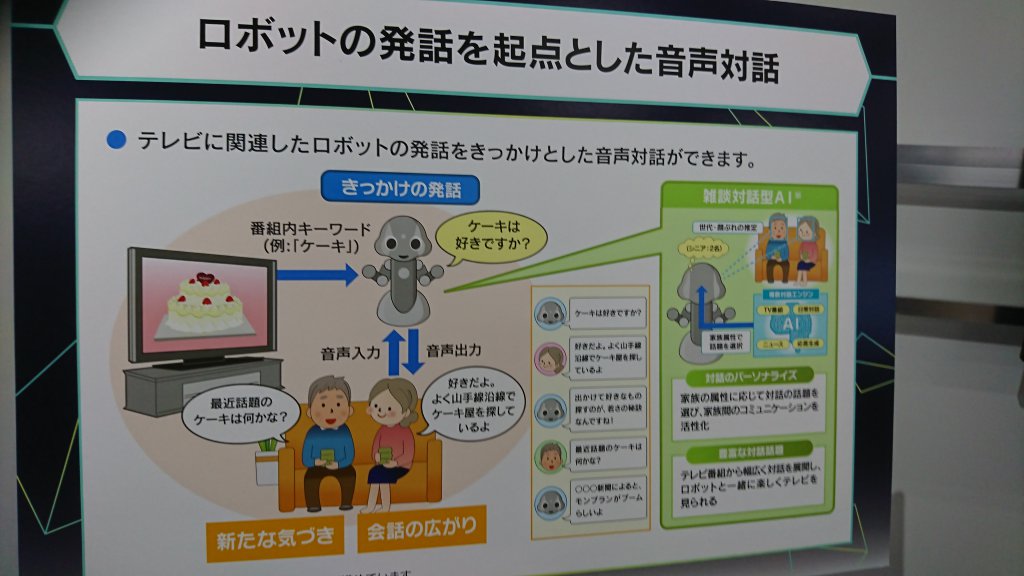
この下の写真のディスプレイのようにロボットの前に座った人の年齢などにより対話文を変化させているそうです。

AIアナウンサー
このブースでは自然で滑らかな合成音声で「関東地方は曇りのち晴れ」などのラジオの気象番組を読みあげるデモが行われていました。
どのくらい滑らかかというと展示の方に「合成音声です」といわれるまで気づかないレベルです・・・。本当にすごかった・・・。
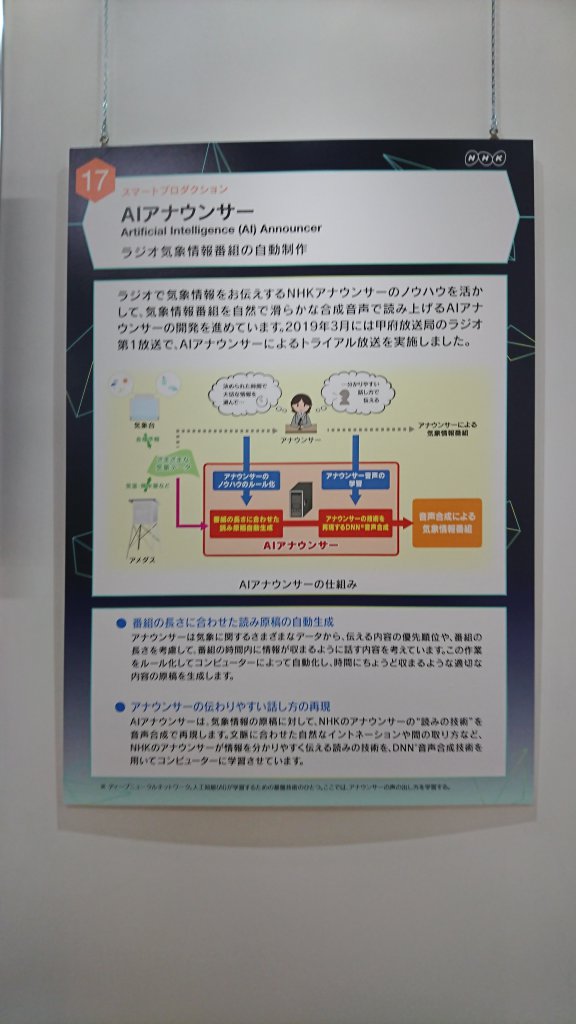
音声合成にはディープニューラルネットワークが用いられているそうです。詳しい仕組みなどは下の写真をご覧ください。
NHKならではと思った点は気象情報番組のセリフのデータセットやテンプレートを作成する際に本物のアナウンサーの方に協力していただいて作成したため、より自然な文になっている点です。
また、伝える気象情報のほかに制限時間を入力することで、より実用的になっているそうです。

ニュースを対象とした日英翻訳システム
ITmedia NEWSでも取り上げられていた「手作業で作成した約50万対の翻訳データ」で学習した翻訳システムが展示されていました。
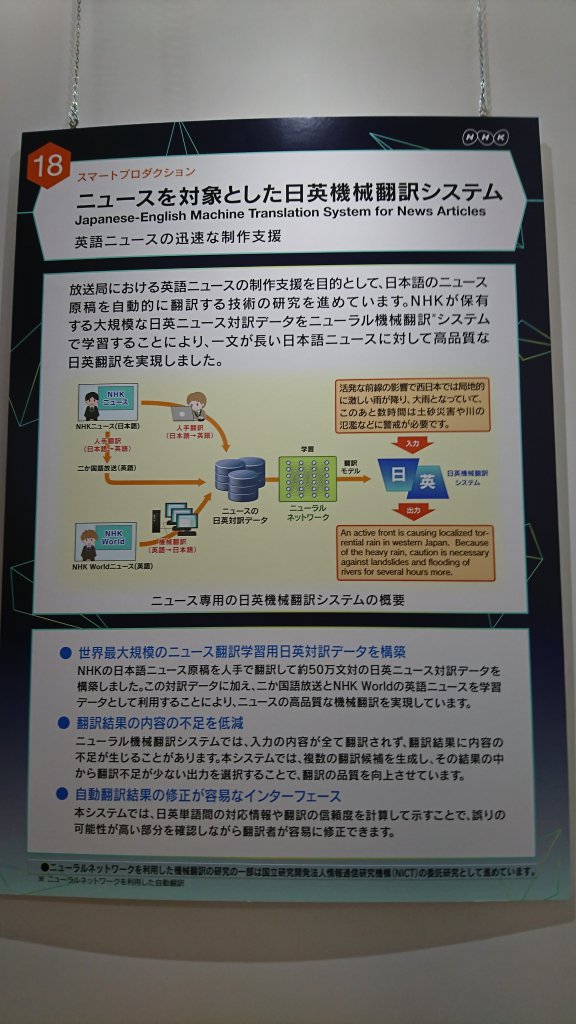
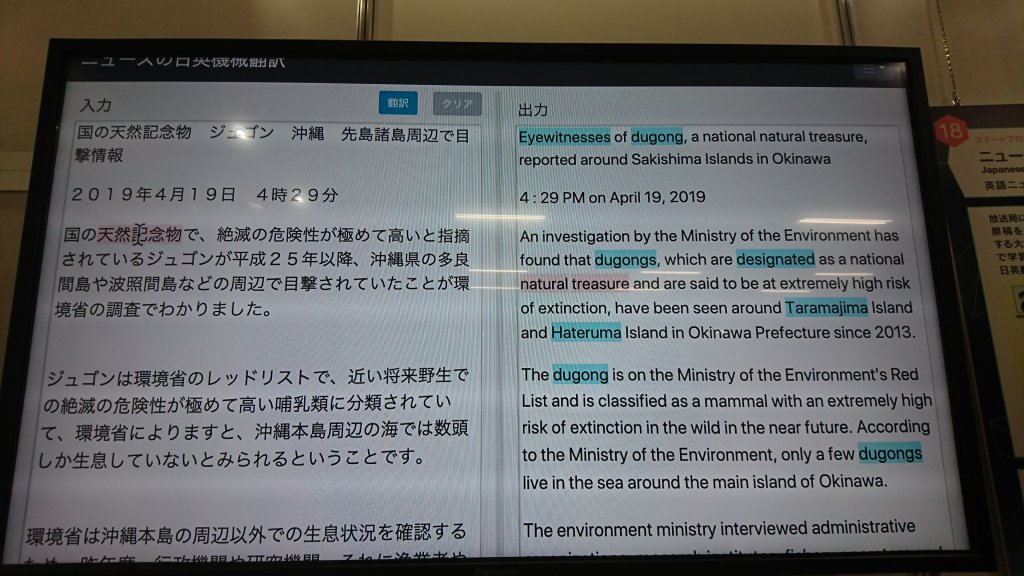
システムのデモは以下です。
赤のハイライトが対応が付いた単語で、青のハイライトが元の日本語文と対応付けがされず正しく翻訳されたかどうか怪しい単語を示しています。
すごい点としては
- 多良間島などの難しい固有名詞が翻訳されている
- 2段落目のように長すぎる日本語文は英訳されると、2文に分割される
というところです。
綺麗な翻訳対のデータで学習すると、やっぱりすごいですね・・・。
このデータは公開されないそうなので、手元で試せず悲しいです。
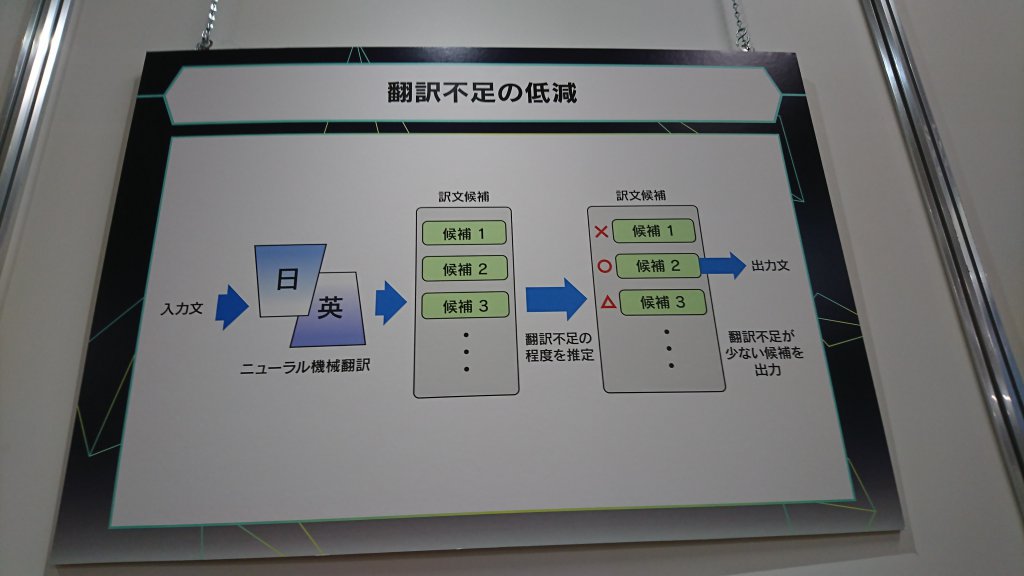
以下の画像のように
- 約50万文の翻訳対で学習したニューラル機械翻訳器に日本語文を入力して訳文候補を複数出力
- 統計的機械翻訳(SMT)で日本語の単語と英単語を対応付けさせ、対応がつく単語の多い英文を「翻訳不足が少ない文」として捉えて出力
といった仕組みになっているそうです。
まとめ
NHK放送技術研究所の技研公開2019で見学した自然言語処理(NLP)に関する展示を紹介しました。 AI対話ロボットや自動でラジオの気象番組を作成して読み上げてくれるシステム、より正しく翻訳されるニュースの日英翻訳など今後が楽しみなものが多いですね。








![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)


