





自己紹介
閲覧していただいた皆様初めまして、私の名前は森川真伍です。
2000年8月10日に京都で生まれ、大学院生の頃までずっと京都で住んでいました。そのため、初めての一人暮らしをしている最中です。2025年の新卒社員で京都産業大学大学院 先端情報学研究科卒業です。大学院卒なので同期の人よりは年上ですが、年齢は気にしないで気軽に話しかけてください!
大学院での研究内容は“ウェーブレット変換を用いたAI生成画像と人が描いたイラスト画像の判別に関する研究”となっています(なぜか表紙が表示されていませんが)。触ってきた言語はC言語・Java・Pythonが主です。また、講義でSwiftやVelilog・C++・C#・HTML・CSS・go・ltsaなども触ってきましたがほとんど覚えていません…
趣味
趣味はゲームと実況動画視聴です。暇なときはいつもゲームかYouTubeでゲーム実況を見ています。ゲームは据え置き機だとNintendo Switchのポケモン等の任天堂系の作品やドラゴンクエストシリーズ、モンハンシリーズを多くプレイしています! ポケモンは厳選やネット対戦もしています(SVではしていませんが…)。マイナー厨なので好きなポケモンで勝つことを目指しています。ほかにはPCでモンハンワイルズやマインクラフト、Apex、SF6、などをしています(ApexとSF6は決して上手ではありませんが)。現在は家にPC環境がないため早くそろえるために給料を心待ちにしています。またソーシャルゲームはパズドラやモンスト、原神、ウマ娘をプレイしています。ソシャゲは無課金主義なので無課金でプレイしています。
基本的にゲームは強いキャラで楽々プレイするよりもマイナーキャラを使って頑張ってクリアするタイプの人間です。ゲームも理不尽はあまり好きではないですが簡単なゲームより難しいゲームのほうが好んでいます。
好きなIT技術:画像生成AI
好きなIT技術は画像生成AIです。これは大学院の研究テーマとして用いていました。画像生成AIというのは、従来の画像で表現できる撮影した写真画像や、パソコン等描画で描画ソフトを使って描いたアニメや漫画・ゲーム⾵の画像をAIで⽣成しているものです。有名なサービスとしては“StableDiffuion”や“NovelAI”・ "nijijourney"などがあります。
実はAI生成画像を見分けられる可能性がある方法があります(もちろん必ず見分けられるわけではなく、将来的にはこの方法も使えなくなると思います)。
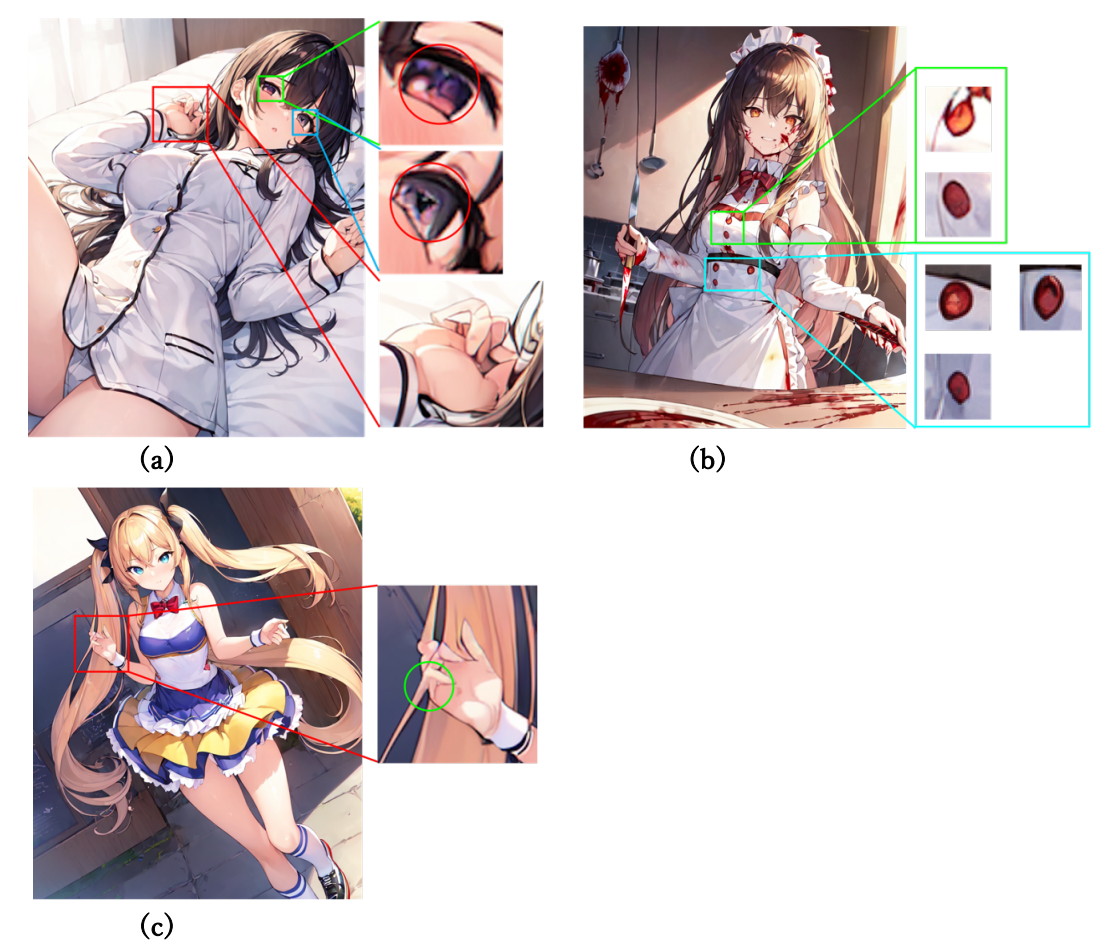
上記の画像はすべてStableDiffusionで生成した画像となっていますが、一部でおかしな出力がされています。左上の(a)の画像では両目の瞳の形が一貫していなかったり、指の形がおかしくなっています。右上の(b)の画像ではボタンの形が一貫していなかったり、下のボタンが左右対称じゃなかったりします(そういうデザインの可能性も微レ存ですが)。左下の(c)の画像では髪の毛と指が融合しています。
StableDiffusionは潜在拡散モデルという方法で画像生成しています。潜在拡散モデルをとても簡単に説明すると、学習データをもとにノイズを作成し、ノイズの除去を入力されたテキストを参照にしながら行うことで指定したような画像を生成する方法です。ここで説明したようにStableDiffusionはノイズから生成されています。
大学院の研究では、上記の画像で示した判断基準以外で画像を見分けようと頑張っていました。そこで、StableDiffusionは潜在拡散モデルを用いていることから、周囲のピクセルで違和感が発生するのではないかと考え、AI生成画像か判別するための研究を行っていました。判別する際に用いた方法はハールウェーブレット変換です。詳しく知りたい人は上記の論文で簡易的に説明しています。正直教授にもわかりにくいと言われたので決して素晴らしい文章ではございません…
最後に
研究ではAIかどうかを判別する研究をしていたため、AIの内部についてはあまり詳しくありませんが、AIを活用する仕事をFIXERではしていきたいと現在考えています。
長々と記述してきましたが、精いっぱい頑張っていきますので今後ともよろしくお願いいたします。是非ご飯に行ったり、一緒にゲームをしたりしましょう!











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
