


M2DetのDemoを改良してみた[TensorBoard/tensorboardX]



はじめに
白石君がこの記事で設置してくれたM2Detを弄らせてくれました。
M2Detのdemo.pyは実際に解析した結果がムービーのように表示されるため、リモートデスクトップなど画像が表示できる環境で実行しなければならないというのが面倒なので、以下の部分を改良しました。
- コマンドラインで実行可能
- 解析結果を保存用ディレクトリに保存
- TensorBoardで表示
コード
早速、コードを表示します。
import os
import cv2
import numpy as np
import time
from torch.multiprocessing import Pool
from utils.nms_wrapper import nms
from utils.timer import Timer
from configs.CC import Config
import argparse
from layers.functions import Detect, PriorBox
from m2det import build_net
from data import BaseTransform
from utils.core import *
from utils.pycocotools.coco import COCO
import tensorboardX
from collections import Counter
import os
import tensorflow as tf
parser = argparse.ArgumentParser(description='M2Det Testing')
parser.add_argument('-c', '--config', default='configs/m2det320_vgg.py', type=str)
parser.add_argument('-f', '--directory', default='imgs/', help='the path to demo images')
parser.add_argument('-m', '--trained_model', default=None, type=str, help='Trained state_dict file path to open')
parser.add_argument('--video', default=False, type=bool, help='videofile mode')
parser.add_argument('--cam', default=-1, type=int, help='camera device id')
parser.add_argument('--show', action='store_true', help='Whether to display the images')
args = parser.parse_args()
print_info(' ----------------------------------------------------------------------\n'
'| M2Det Demo Program |\n'
' ----------------------------------------------------------------------', ['yellow','bold'])
global cfg
writer = tensorboardX.SummaryWriter()
cfg = Config.fromfile(args.config)
anchor_config = anchors(cfg)
print_info('The Anchor info: \n{}'.format(anchor_config))
priorbox = PriorBox(anchor_config)
net = build_net('test',
size = cfg.model.input_size,
config = cfg.model.m2det_config)
init_net(net, cfg, args.trained_model)
print_info('===> Finished constructing and loading model',['yellow','bold'])
net.eval()
with torch.no_grad():
priors = priorbox.forward()
if cfg.test_cfg.cuda:
net = net.cuda()
priors = priors.cuda()
cudnn.benchmark = True
else:
net = net.cpu()
_preprocess = BaseTransform(cfg.model.input_size, cfg.model.rgb_means, (2, 0, 1))
detector = Detect(cfg.model.m2det_config.num_classes, cfg.loss.bkg_label, anchor_config)
def _to_color(indx, base):
""" return (b, r, g) tuple"""
base2 = base * base
b = 2 - indx / base2
r = 2 - (indx % base2) / base
g = 2 - (indx % base2) % base
return b * 127, r * 127, g * 127
base = int(np.ceil(pow(cfg.model.m2det_config.num_classes, 1. / 3)))
colors = [_to_color(x, base) for x in range(cfg.model.m2det_config.num_classes)]
cats = [_.strip().split(',')[-1] for _ in open('data/coco_labels.txt','r').readlines()]
labels = tuple(['__background__'] + cats)
def draw_detection(im, bboxes, scores, cls_inds, fps, thr=0.2):
imgcv = np.copy(im)
h, w, _ = imgcv.shape
for i, box in enumerate(bboxes):
if scores[i] < thr:
continue
cls_indx = int(cls_inds[i])
box = [int(_) for _ in box]
thick = int((h + w) / 300)
cv2.rectangle(imgcv,
(box[0], box[1]), (box[2], box[3]),
colors[cls_indx], thick)
mess = '%s: %.3f' % (labels[cls_indx], scores[i])
cv2.putText(imgcv, mess, (box[0], box[1] - 7),
0, 1e-3 * h, colors[cls_indx], thick // 3)
if fps >= 0:
cv2.putText(imgcv, '%.2f' % fps + ' fps', (w - 160, h - 15), 0, 2e-3 * h, (255, 255, 255), thick // 2)
return imgcv
im_path = args.directory
im_result_path = im_path + "_result"
if not os.path.exists(im_result_path):
os.mkdir(im_result_path)
cam = args.cam
video = args.video
if cam >= 0:
capture = cv2.VideoCapture(cam)
video_path = './cam'
if video:
while True:
video_path = input('Please enter video path: ')
capture = cv2.VideoCapture(video_path)
if capture.isOpened():
break
else:
print('No file!')
if cam >= 0 or video:
video_name = os.path.splitext(video_path)
fourcc = cv2.VideoWriter_fourcc('m','p','4','v')
out_video = cv2.VideoWriter(video_name[0] + '_m2det.mp4', fourcc, capture.get(cv2.CAP_PROP_FPS), (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)), int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))))
im_fnames = sorted((fname for fname in os.listdir(im_path) if os.path.splitext(fname)[-1] == '.jpg'))
im_fnames = (os.path.join(im_path, fname) for fname in im_fnames)
im_iter = iter(im_fnames)
while True:
if cam < 0 and not video:
try:
fname = next(im_iter)
except StopIteration:
break
if 'm2det' in fname: continue # ignore the detected images
image = cv2.imread(fname, cv2.IMREAD_COLOR)
else:
ret, image = capture.read()
if not ret:
cv2.destroyAllWindows()
capture.release()
break
loop_start = time.time()
w,h = image.shape[1],image.shape[0]
img = _preprocess(image).unsqueeze(0)
if cfg.test_cfg.cuda:
img = img.cuda()
scale = torch.Tensor([w,h,w,h])
out = net(img)
boxes, scores = detector.forward(out, priors)
boxes = (boxes[0]*scale).cpu().numpy()
scores = scores[0].cpu().numpy()
allboxes = []
for j in range(1, cfg.model.m2det_config.num_classes):
inds = np.where(scores[:,j] > cfg.test_cfg.score_threshold)[0]
if len(inds) == 0:
continue
c_bboxes = boxes[inds]
c_scores = scores[inds, j]
c_dets = np.hstack((c_bboxes, c_scores[:, np.newaxis])).astype(np.float32, copy=False)
soft_nms = cfg.test_cfg.soft_nms
keep = nms(c_dets, cfg.test_cfg.iou, force_cpu = soft_nms) #min_thresh, device_id=0 if cfg.test_cfg.cuda else None)
keep = keep[:cfg.test_cfg.keep_per_class]
c_dets = c_dets[keep, :]
allboxes.extend([_.tolist()+[j] for _ in c_dets])
loop_time = time.time() - loop_start
allboxes = np.array(allboxes)
boxes = allboxes[:,:4]
scores = allboxes[:,4]
cls_inds = allboxes[:,5]
cls_count_list = []
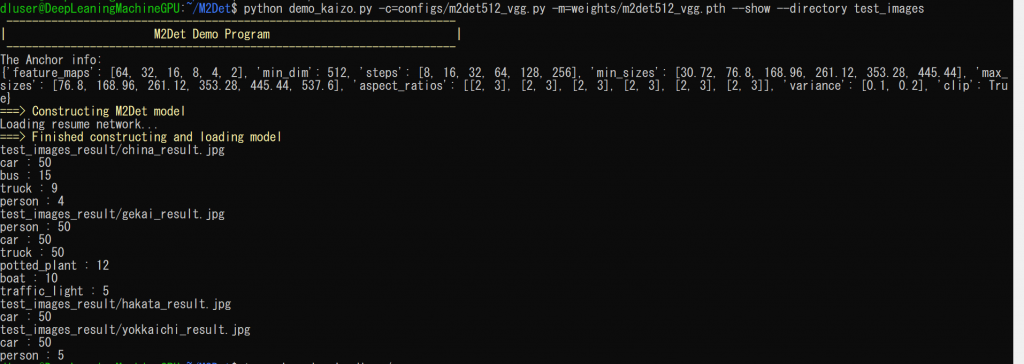
print(fname.replace(".jpg","_result.jpg").replace(im_path, im_result_path.replace("/", "")))
for cls_num in cls_inds:
cls_count_list.append(labels[int(cls_num)])
cls_count = Counter(cls_count_list)
for c, num in cls_count.most_common():
print(c, ":", num)
fps = 1.0 / float(loop_time) if cam >= 0 or video else -1
im2show = draw_detection(image, boxes, scores, cls_inds, fps)
cv2.imwrite(fname.replace(".jpg","_result.jpg").replace(im_path, im_result_path.replace("/","")), im2show)
im2show = cv2.cvtColor(im2show, cv2.COLOR_BGR2RGB)
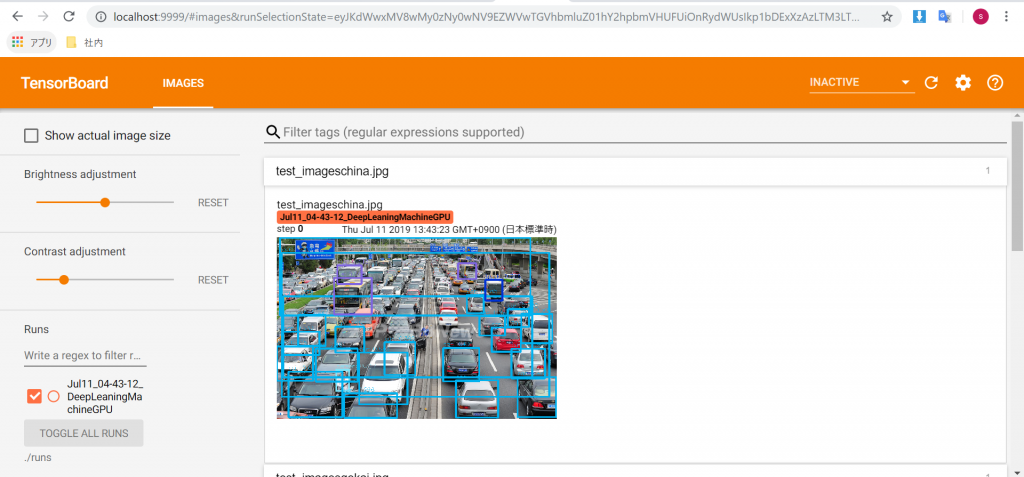
writer.add_image(fname.replace("/", ""),im2show,0, dataformats='HWC')
writer.close()苦労したところはim2showの配列のshapeがtensorboardXのadd_imageのデフォルトのdataformatsにでないのに気付くところと、RGBの順番が違うということに気づくところです・・・。
このプログラムをdemo.pyと同じ階層に入れて、以下のように実行します。
python demo_kaizo.py -c=configs/m2det512_vgg.py -m=weights/m2det512_vgg.pth --show --directory <実行したい画像が入っているフォルダまでのPath>以下のような結果とともに<実行したい画像が入っているフォルダまでのPath>_resultフォルダに解析結果の画像が保存されます。
ローカルのブラウザからTensorBoardにアクセスする方法はこの記事を参考にしてください。
おわりに
M2Detのdemo.pyを改良しました。
Python久々だったので手間取りました。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
