


簡単な文かどうかの機械学習データを楽に作ってみた[Python]



はじめに
機械学習したい欲が増しているので、簡単な文かどうかを判断する機械学習データを作成するコードを書いたので紹介します。
利用させていただいたコーパスはSNOW T15:やさしい日本語コーパスです。
手法
1)ここからXLSXファイルをダウンロードし、csvファイルに保存しなおします。
データセットは以下の画像のようにID、日本語(原文)、やさしい日本語、英文となっています。
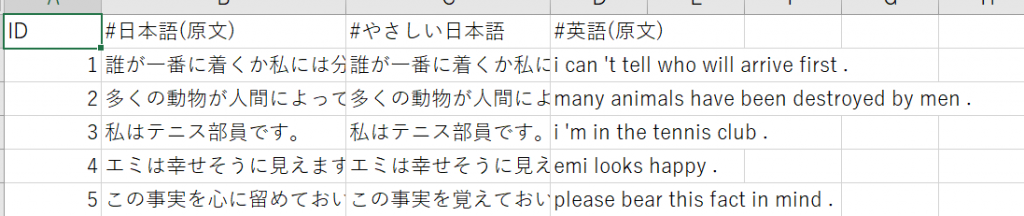
2)以下のPythonコードを実行します。
このデータには易しい文と難しい文が全く同じ場合があるので、その場合はデータから除外します。
import csv
with open("./T15-2018.2.28.csv", "r", encoding="ms932")as csv_file:
lines = csv.reader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True)
header = next(lines)
train_data = []
with open('train_data.csv', 'w') as f:
writer = csv.writer(f, lineterminator='\n')
for line in lines:
print(line)
if line[1] != line[2]:
writer.writerow([line[1],"難しい"])
writer.writerow([line[2],"易しい"])3)train_data.csvという名前の以下のような学習データができます。
この学習データは文、易しい/難しいのタグといった形式になっています。

おわりに
簡単な文かどうかを判断する機械学習データを作成するコードを書きました。
今週どこかで続きをあげられたらいいなと思います。








![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)


