




こんにちは。FIXER M&S 竹中です。 この連載も2本目ということでやっと本格的に分析工程に入っていきましょう。前回はセットアップ作業で終わってしまいましたからね。
1.本日のお題
さて、今回の分析のテーマは前回告知したように、Kaggleにおける入門編、「Titanic: Machine Learning from Disaster」のデータを利用しましょう。これはタイタニック号の乗客のリストと種々のパラメータから生存率を推定するもので、0か1かを分類するクラス分類問題のチュートリアルとして位置付けられています。ちなみにKaggleのコンペティションは難易度と性質に応じていくつかのカテゴリに分かれています。初心者はまずGetting Startedから始めるといいでしょう。上位のコンペでは賞金もつきますよ。
2.データを取り込んで眺めてみる
まずは生データを取り込んでとりあえず眺めてみましょう。いきなり作業に入る前になんとなくデータの分布や基本統計量を見て雰囲気を掴むことは案外大事です。このトライアルではライブラリとしてPandas、Numpy、Sklearnを主に利用します。
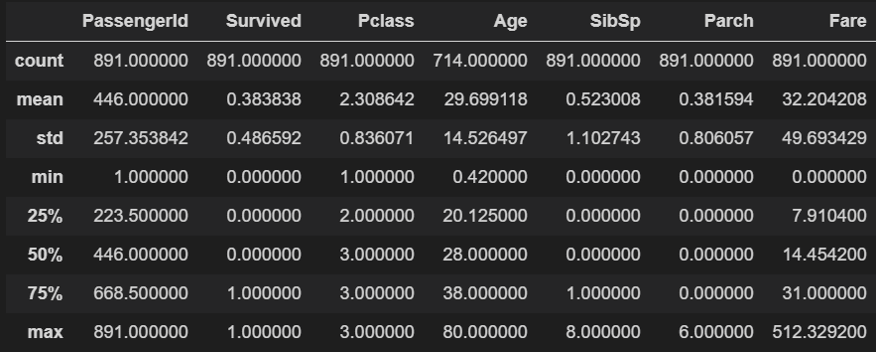
こちからが訓練データの基本統計量です。pandasのデータフレームパラメータcountの最大値が891なので全部で891名分のリストから成るデータということですね。Age(年齢)のカウントが714となっていますがこれは欠損値があるためです。また、基本統計量に出ない"Sex"、"Embarked"というパラメータがありますが、これは名義尺度のため統計が出ません。
さて、Ageに(と、実はEmbarkedにも)欠損がありますが、このままでは分析ができませんので欠損値を変換する必要があります。その前に訓練データにどのくらい欠損があるのか、見てみましょう。
import pandas as pd
null_val = df.isnull().sum()
percent = 100 * null_val/len(df)
Missing_table = pd.concat([null_val, percent], axis = 1)
missing_table_len = Missing_table.rename(
columns = {0:'欠損値', 1:'%'})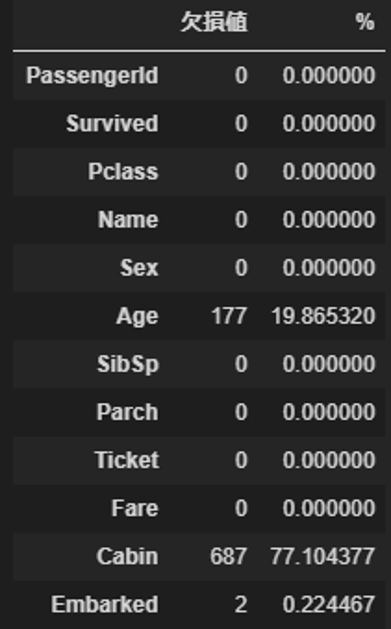
Age、Cabin、Embarkedにそれぞれ欠損がありますね。今回Cabinは使わないため、AgeとEmbarkedの欠損を埋めます。
train["Age"] = train["Age"].fillna(train["Age"].mean())
train["Embarked"] = train["Embarked"].fillna("S")Ageを欠損していないデータの平均値で、Embarkedを最頻値である"S"で埋めています。AgeについてはMedianで埋める方法や欠損値を落とす方法がありますが、今回は平均を採用します。欠損を埋めたところでAgeによるヒストグラムを見てみましょう。
import matplotlib.pyplot as plt
plt.hist(train["Age"], bins=20)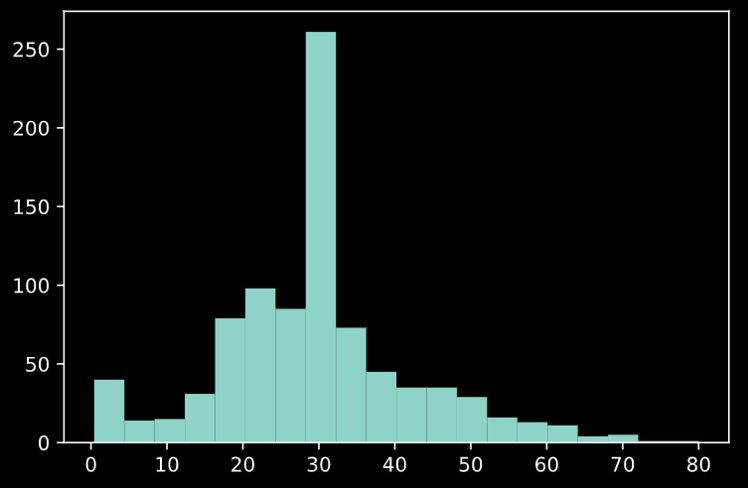
やはり欠損を平均で埋めてしまったため、30歳前後のサンプルに偏りが出てしまいましたね。これが分析結果にどう影響してくるか…。ちなみに中央値で埋めたパターンも試しましたが、25歳くらいにピークが移る結果になります。
このほかにもSex(性別)とEmbarked(出発港)はそれぞれ名義尺度がついていますので、分析時邪魔にならないよう数字に置き換えます。訓練データと同時にテストデータの変換もやりましょう。
# 名義尺度の置き換え
train["Sex"][train["Sex"] == "male"] = 0
train["Sex"][train["Sex"] == "female"] = 1
train["Embarked"][train["Embarked"] == "S" ] = 0
train["Embarked"][train["Embarked"] == "C" ] = 1
train["Embarked"][train["Embarked"] == "Q"] = 2
test["Age"] = test["Age"].fillna(test["Age"].mean())
test["Sex"][test["Sex"] == "male"] = 0
test["Sex"][test["Sex"] == "female"] = 1
test["Embarked"][test["Embarked"] == "S"] = 0
test["Embarked"][test["Embarked"] == "C"] = 1
test["Embarked"][test["Embarked"] == "Q"] = 2
test.Fare[152] = test.Fare.mean()ちなみに性別などは代表的な名義尺度(分類にのみ意味があり、順序に意味のない尺度)なので、上記のように男性を0、女性を1として扱うような処理は不適切です。ですが、アンケートなどの統計処理上はこういった変換を行うことはよくあることなので、本稿でも一先ずはこういった処理とさせて頂きたいと思います。もちろん、上手に特徴量にできれば精度の向上に貢献できるでしょう。
3.データを学習させる
さて、一応ひととおりの前処理が済みましたので学習させてみましょう。今回はアルゴリズムとしてランダムフォレストを利用します。ランダムフォレストとは決定木モデルを複数検討し、統合して結果の汎用性を高めるものです。今回はほかにサポートベクターマシンも検討しましたがこちらにもあるようにSVMはパラメータの調整が難しく、学習が非効率であるようなのでいったん中止しました(実はSVMの方が精度が良かったりしたので惜しい気持ちなのですが…)
また、少しでも精度を高めるためにパラメータのグリッドサーチを試してみましょう。これは簡単に言うと複数のパラメータの組み合わせを全通り実施するというもので、決め打ちするよりも高い精度が望めます。ただしトレードオフとして組み合わせの数だけ学習に時間がかかってしまうため、あまり手軽には試せないというデメリットがあります。
この処理は下記のとおりです。
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# Random Forestによる予測
x2_ = train["Survived"].values
y2_ = train[["Pclass", "Age", "Sex", "Fare", "SibSp", "Parch", "Embarked"]].values
parameters = {
'n_estimators' : [10,25,50,75,100],
'random_state' : [0],
'n_jobs' : [4],
'min_samples_split' : [5,10, 15, 20,25, 30],
'max_depth' : [5, 10, 15,20,25,30]
}
clf = GridSearchCV(RandomForestClassifier(), parameters)
clf.fit(y2_, x2_)
feature = test[["Pclass", "Age", "Sex", "Fare", "SibSp", "Parch", "Embarked"]].values
prediction = clf.predict(feature)これで訓練データからの学習と、テストデータへのフィッティングが完了しました。結果を出力してみましょう。
# 予測データとPassengerIdをCSVへ書き出す
import numpy as np
PassengerId = np.array(test["PassengerId"]).astype(int)
result = pd.DataFrame(prediction, PassengerId, columns = ["Survived"])
result.to_csv("prediction_forest.csv", index_label = ["PassengerId"])このprediction_forest.csvをkaggleのコンペサイトにアップロードすると結果と順位とを算出してくれます。
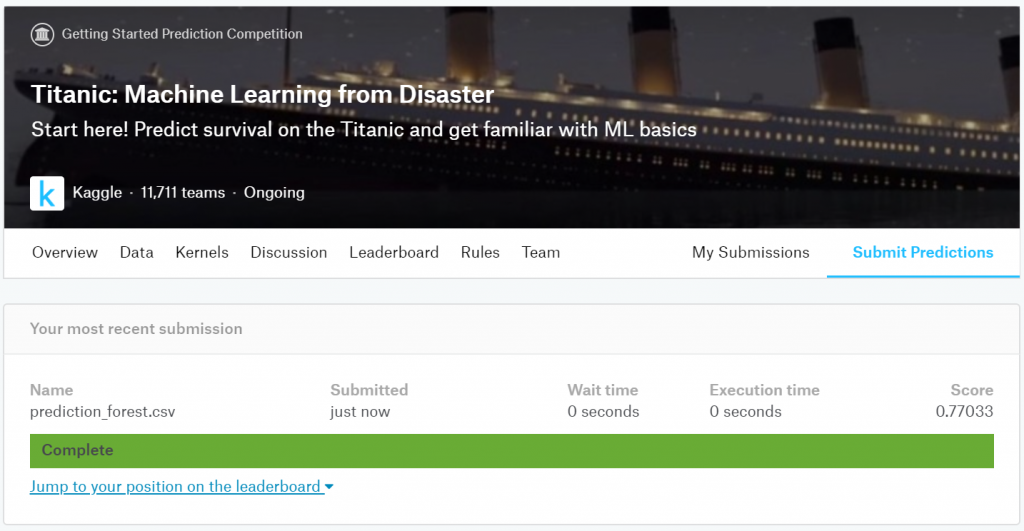
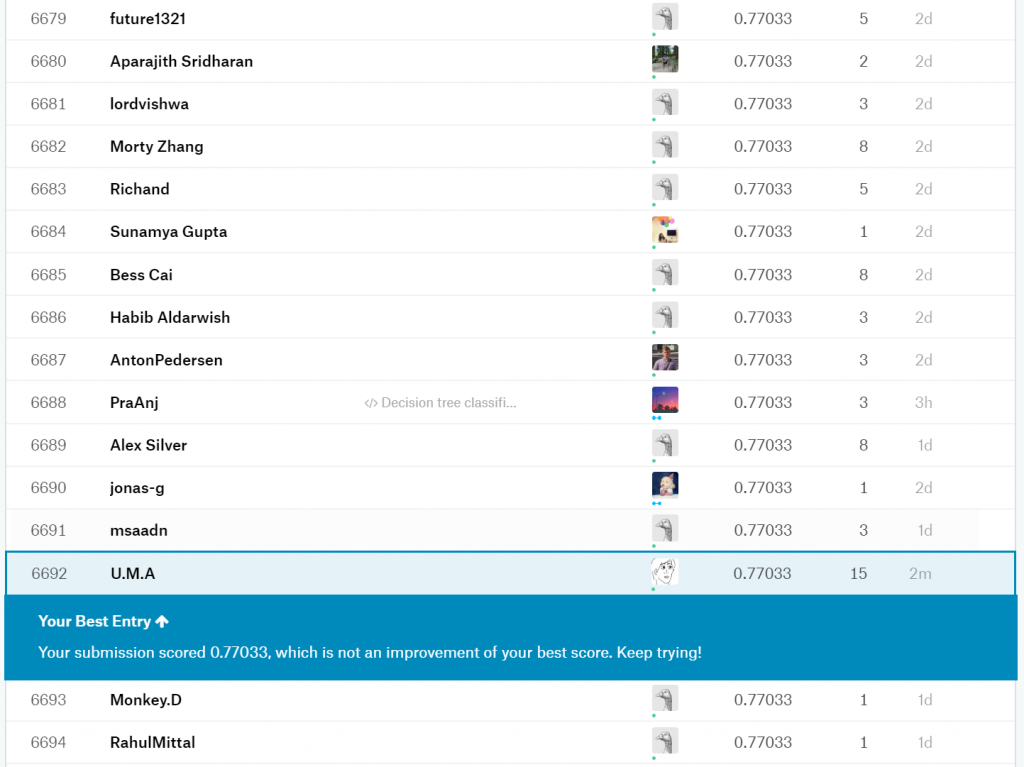
精度は0.77033(77%)で順位は6,692/11,712でした。半分以下ですね…笑
今回はひとまずKaggleコンペティションの一通りを経験できたということでOKとしたいと思います。必ずしも勝つことがすべてじゃないっていうね。
ん…??
あっ…!!
6,693位の海賊王(Monkey.D)に勝ってる…!!!
今回は以上になります。お読みいただきありがとうございました。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
