






マイクロサービスアーキテクチャにおけるデータベース
昨今、マイクロサービスアーキテクチャというアプリケーションアーキテクチャのパターンへの関心が高まってきています。
サービス全体を複数のサービスに分割し、相互に通信を行って連携を行わせることで、それぞれのサービスを疎結合にし、サービスの間の依存関係を小さくすることで、それぞれのサービスを素早く開発したり、デプロイの単位を小さくしたり、サービスごとに別の技術を使用することができる、というのがこのアーキテクチャの特徴になります。
その中で、データベースをどうやって持たせるのかという疑問については、Database per serviceというパターンがその回答になります。
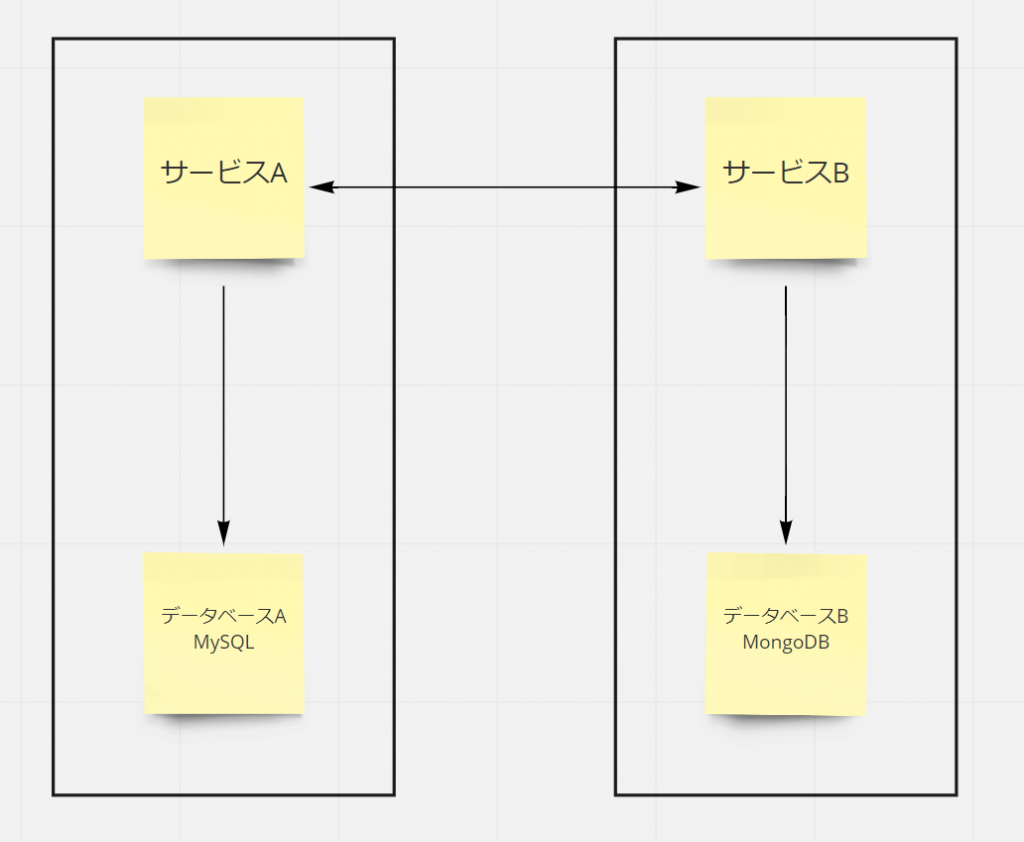
このパターンにおいては、例えば、サービスAはデータベースAと直接データのやり取りを行い、データベースBへの接続方法やスキーマについては関知しません。
サービスBも同様に、データベースAに依存しません。
つまり、データベースはそれを必要とするサービス毎に持たせようという考え方で、こうすることによってサービスはデータベースとセットになり、ほかのサービスとの間でデータベースも疎結合が維持されます。
Database per serviceパターンの問題点
このようにデータベースを分割してサービスに持たせる方法においては、いくつかの問題が発生します。
そしてその問題の中の一つに、整合性の問題があります。
例えば、RDBであれば、外部キーを用いてあるデータを別のデータと結び付け、参照先のデータが変更されれば、JOINを使うことで自動的に変更後のデータと結び付けてくれます。
しかし、Database per serviceパターンを用いる場合、データベースはサービスごとに持ち、同じデータが複数データベースに存在することを許容します。
この場合、片方のデータベースのデータを変更しても、もう片方のデータは自動的には変更されませんよね。
そうなると、使用するサービスによって、同じデータなのに値が異なるという事態が起きてしまいます。
これがDatabase per serviceパターンのデータの整合性の問題で、どうにかして片方のデータ変更をほかのデータに反映させる必要があります。
非同期イベントドリブン通信による解決方法
この問題の解決法としては、同じデータを持つデータベースの一つに変更が加えられた際にその変更をほかのデータベースにイベントとして伝えてデータベースごとに変更を行ってもらう方法があり、これを非同期イベントドリブン通信といいます。
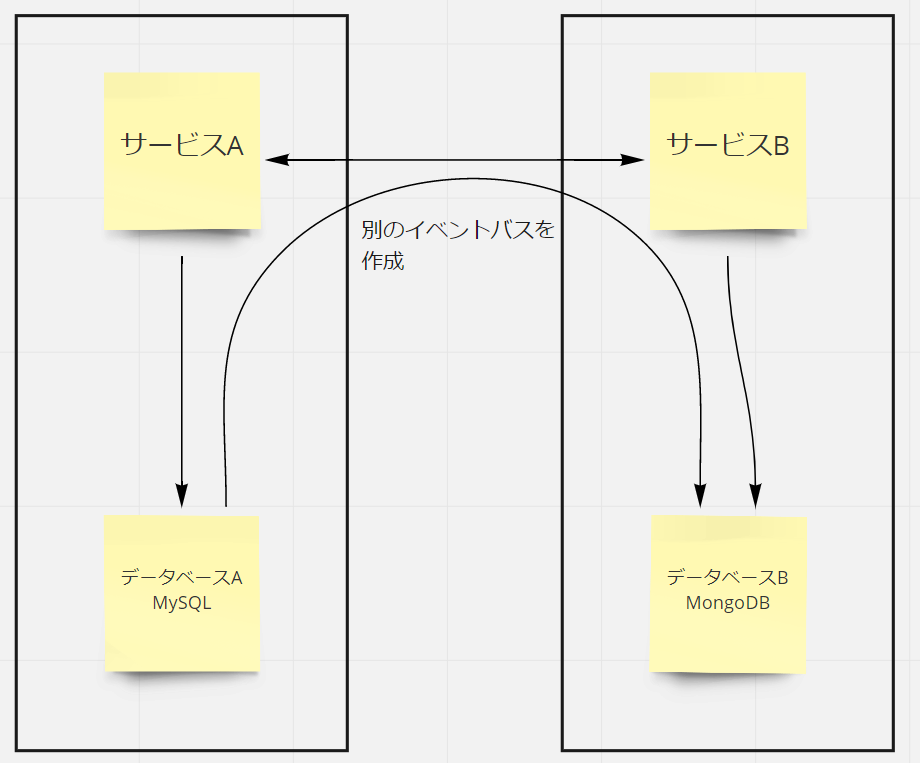
データの変更を伝えるイベントを通すイベントバスを作成し、同じデータを持つそれぞれのサービスがそれをサブスクライブします。
バスを通してデータ変更のイベントを受け取ったら、そのサービスが持つデータベースにも同様の変更を加えることで、全部のデータベースでデータの値を同じにし、整合性を保つことができます。
これを、結果整合性と言ったり最終的整合性と言ったりしますが、どちらも同じことを指しています。
つまり、同じデータを持つ複数の分散しているデータベースのデータのうち一つのデータの値が変更された際に、すぐにはほかののデータベースの値が同じにならなくても、結果的に/最終的に同じになることで整合性がとられるということを示しています。
ただし、その言葉通り、すぐには整合性をとることができません。
どうしても発生するデータベースの整合性がとられるまでのラグをどこまで許容できるのか、どこまで小さくできるのかは別に考える必要があります。
まとめ
本稿では、マイクロサービスアーキテクチャにおけるデータベースの特徴と、その問題の一つであるデータの整合性の問題とその解決法について説明しました。
マイクロサービスアーキテクチャにおけるデータベースの問題としては、ほかにもトランザクションをどうやって実現するのかなどのほかの問題もあるのですが、それについてもまた別の記事で纏めたいと思っていますので、お楽しみに!
マイクロサービスアーキテクチャ自体も「銀の弾丸ではない」といわれるとおり、メリットだけでなくデメリットもあります。
また、どのような場面で使うべきかという議論があり、作ろうとするシステムごとにマイクロサービスで作るべきかといった判断もしなければなりませんが、デメリットとなっていることについてどのような解決方法があるかを知ることも重要だと考えます。
アーキテクチャについて詳しく知り、取ることのできる選択肢を増やしていきましょう!











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
