


 2019-12-06
2019-12-06

はじめに
12/5から開催されているMicrosoft Ignite The Tourの「これまでにない速さで機械学習モデルの構築を始めましょう」を聞いてきた聴講レポートです。
スライドはのちのち公開されるそうです。
ちなみにこのセッションは英語版のスライドがすでにこちらで公開されています。
また、プログラムのサンプルはこちらです。
想定されているユースケース
一番最初に紹介されていたのは機械学習を使うために想定されているユースケースでした。
具体的には店舗が2つあって、2店舗の在庫を漢字にに管理したいというニーズがあるTailwind Tradersという会社が想定されていました。

そもそもArtificial Intelligence、Machine Learning、Deep Learningって何?
このスライド取り忘れてしまったので英語版で失礼します。
ここでは機械学習の初心者向けに書く概念を説明していました。
- Artificial Intelligence(AI):コンピューターが彼の知性を模倣できるようにする手法
- Machine Learning(ML):AIの中に包含される。マシンが経験(具体的にはおそらくデータのこと)のあるタスクを改善できるようにする手法
- Deep Learning(DL):マシンが自分自身を学習できるようにするニューラルネットワーク

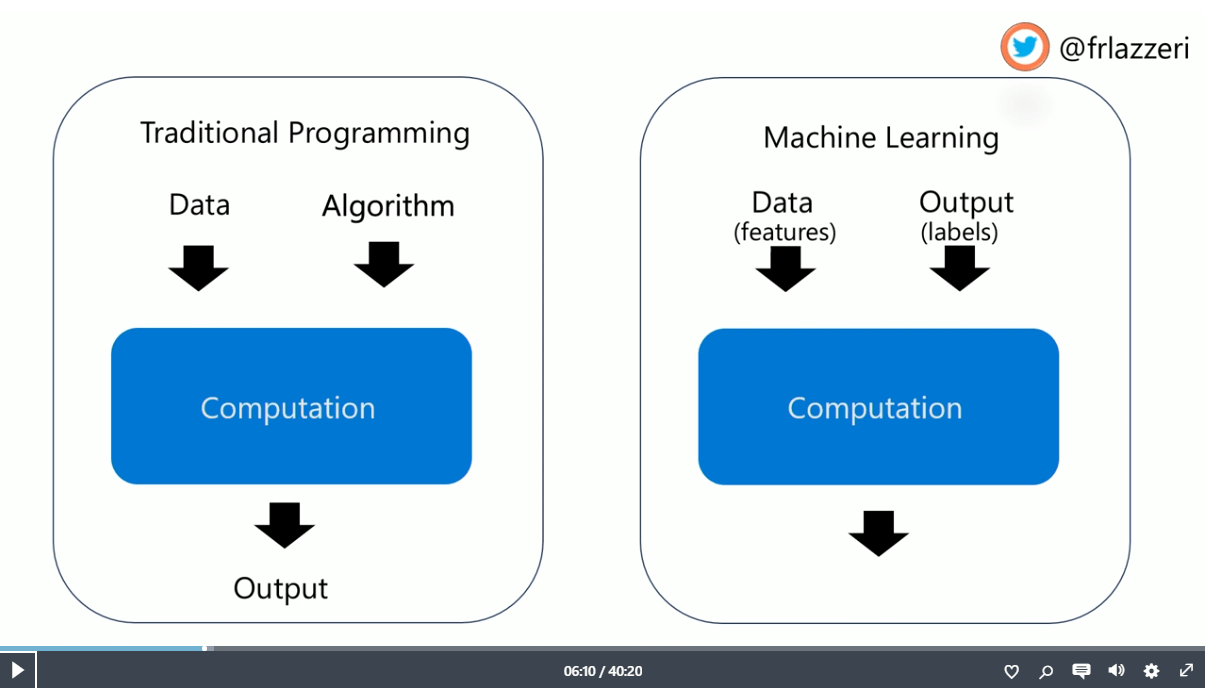
また、伝統的なプログラミングと機械学習のちがいについても紹介していました。
- 伝統的なプログラミング:入力はデータとアルゴリズム
- Machine Learning(ML):入力はデータ(特徴)とアウトプット(ラベル)
つまり、Machine Learning(ML)をするときはデータ(特徴)とアウトプット(ラベル)が対になっているものがある程度なければなりません。
どんなときに機械学習をしようすべきか
先ほども触れましたが、Machine Learning(ML)をするときはデータ(特徴)とアウトプット(ラベル)が対になっているものがある程度あることが前提となっています。
その前提を踏まえて、どんな時にどういうものを使うのかも紹介されていました。
- 教師あり学習:データ(特徴)とアウトプット(ラベル)が対になっているものが豊富
- 回帰:どれくらいの量・数になるか
- 分類:どのクラスに属しているか
- 教師なし学習:データ(特徴)だけで学習
- クラスタリング:どんなグループに分けることができるか
- 異常検知:異常かどうか
- レコメンデーション:おすすめは何か ・(強化学習):今回は省略
今回のユースケースでは回帰が最適だそうです。

モデルの構築プロセス
具体的なモデルの構築プロセスは以下だそうです。
- データを準備:データを探索・選択・作成、前処理を適用
- トレーニング:学習アルゴリズムを適用、モデルの候補を選択
- テスト:モデルにとって未知のデータでテスト、精度の高いモデルを選択 以上を回して精度の良いモデルを作成
- デプロイ:制度の良いモデルをデプロイして、アプリからアクセス。この後もデータを収集してモデルの改善をしていく

特徴量エンジニアリング
特徴量を見つけたり、データを加工したりするうえで重要なのは以下だそうです。
- 使用できる十分なデータがあるかどうか
- 外部データを収集してモデルの精度の向上
- 機械学習は正規化したほうが予測がよくなる場合があるため、精度をよくするために、データを正規化してみるのはあり

今回のユースケースでは以下のように特徴量を作成していったそうです。

また、よく機械学習詳しい人にデータを持ってきて質問する人もいらっしゃるらしいですが、機械学習はインプット次第なところが多く、やってみないとわからないため、考えるよりも試すのが一番だそうです。
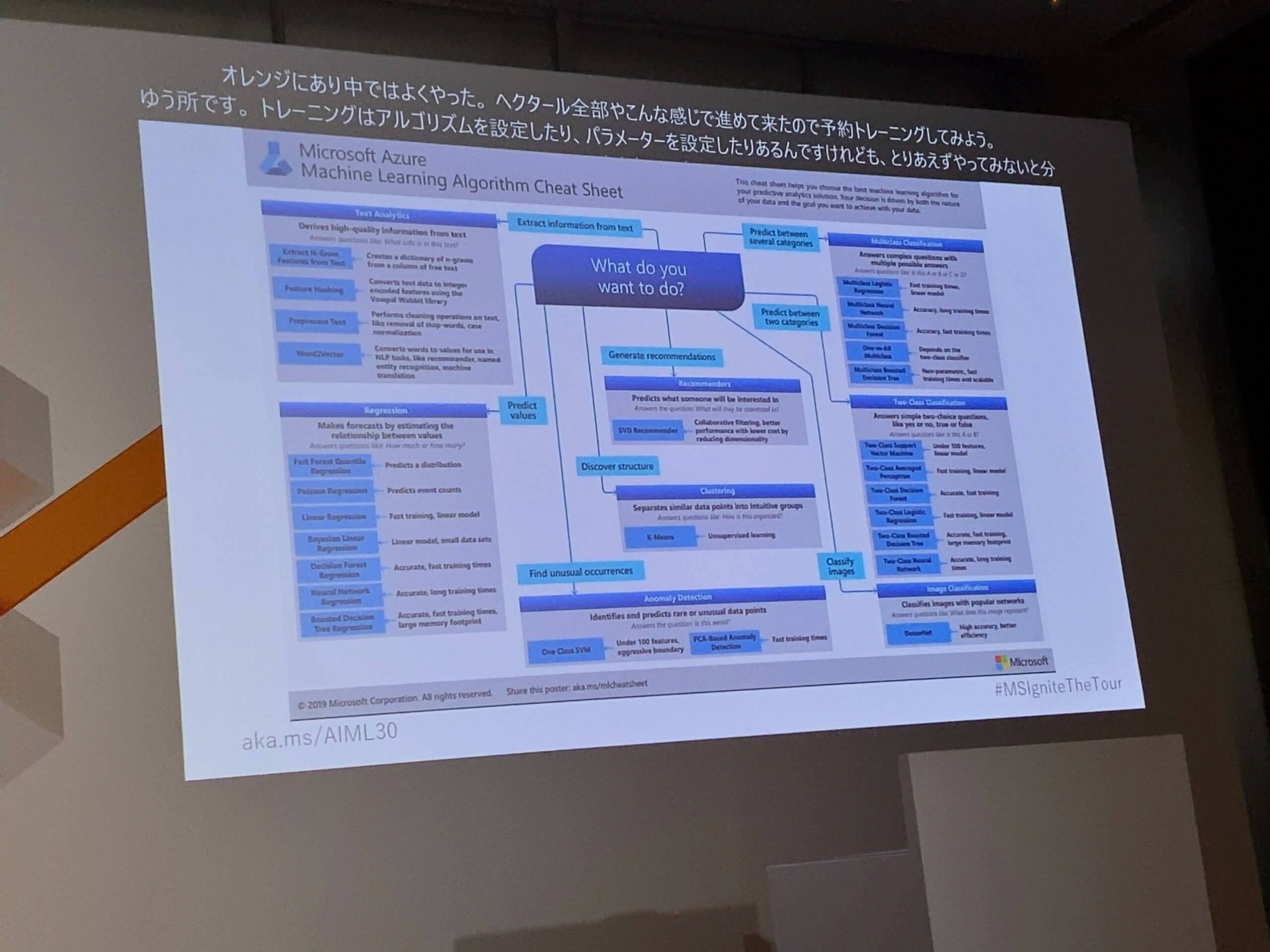
そのとっかかりとして、MSが公開している機械学習アルゴリズムチートシートを見てみることも紹介されていました。
最後にAzure Machine Learning Studioでのデモがされていました。
また、英語版でこちらにデモの様子が掲載されていて、プログラムのサンプルはこちらです。
デモの内容に関しては省略させていただきます。
おわりに
12/5から開催されているMicrosoft Ignite The Tourの「これまでにない速さで機械学習モデルの構築を始めましょう」を聞いてきた聴講してきました。
全体的な感想としては機械学習の基礎からしっかりめに解説してくれたので、初心者でもすぐにAzure Machine Learning Studioを利用できそうだと思いました。
機械学習が手軽にできるAzure Machine Learning Studio、活用していきたいですね。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
