






こんにちは。R&D Divisionの山本です。
今回は予測モデル解釈の実践編1になります。実践編1では一切のコーディングを行わず、Azure Machine Learning Serviceが持つ、AutoML機能とモデル解釈機能で予測モデルの作成から解釈までを行います。
予測モデル解釈とはなんぞやを解説した前回の記事はこちらからどうぞ
では、早速実際に予測モデル解釈を始めます。
Azure Machine Learning Serviceの作成
まずはモデル解釈を行うための環境を準備します。今回はAzure Machine Learning Serviceを利用します。
Azure Machine Learning Service はモデルのトレーニング、デプロイ、自動化、管理、追跡に使用できるクラウドベースの環境であり、Azure上で機械学習を行うならまずはこれを利用するのがおすすめです。
下記URLからAzure Portalへ移動してリソースを作成を始めます。
Azure Portalへ移動したらリソースの作成をクリックします。
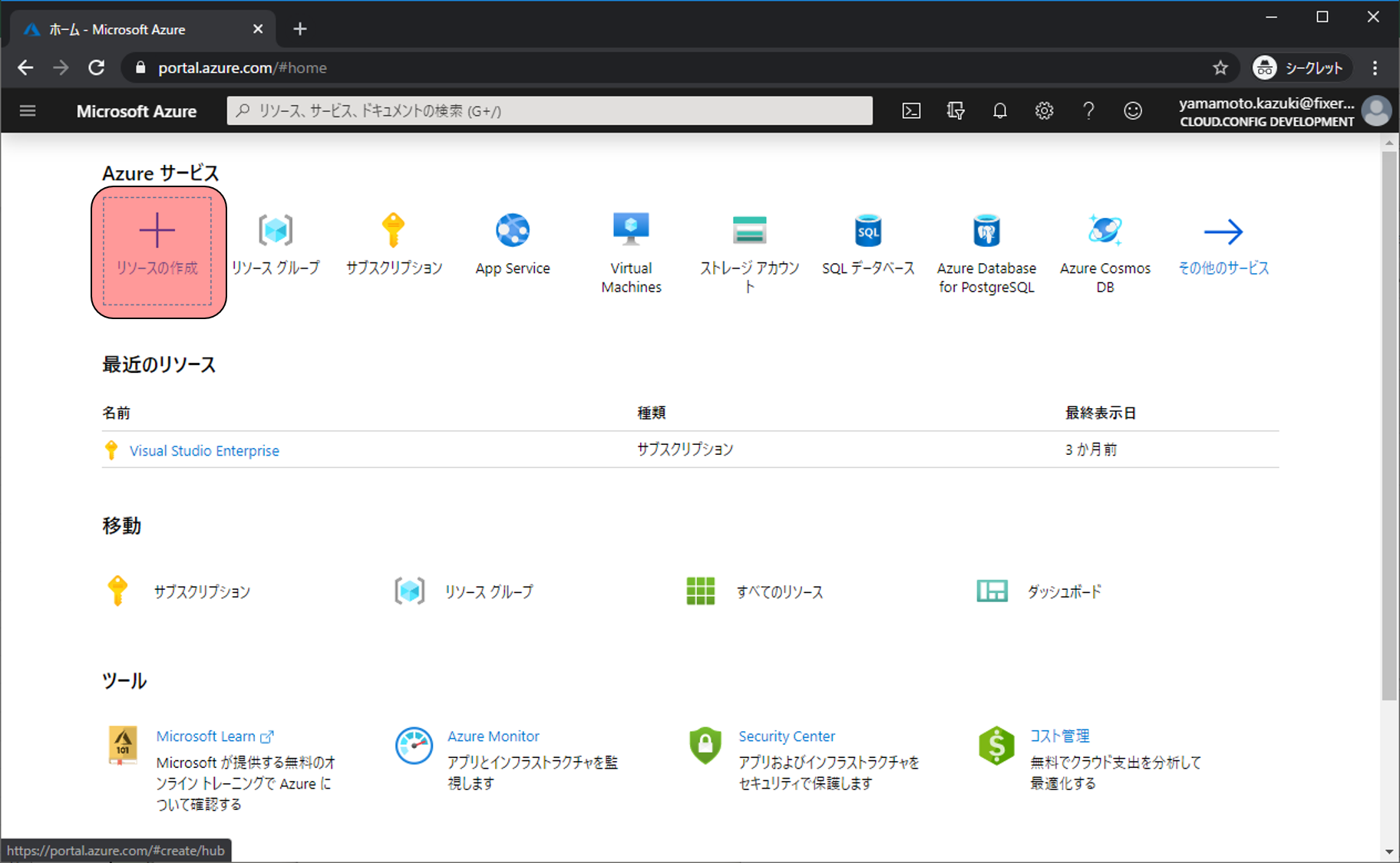
AI + Machine Learningをクリックし、Machine Learningをクリックします。
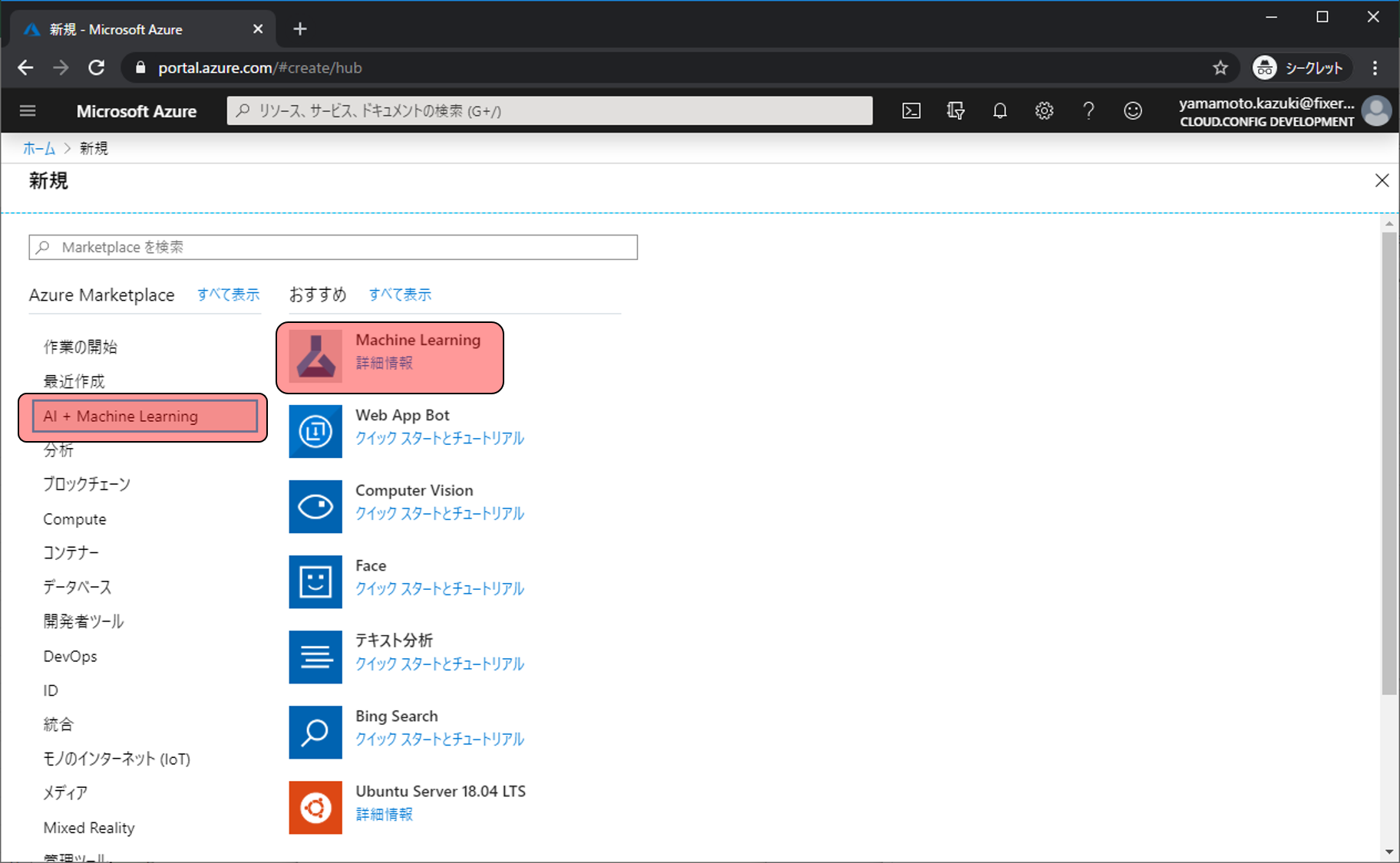
リソースを作成するに当たって、いくつか入力や選択する項目があるので、埋めて確認及び作成をクリックします。その後、確認画面が表示されるので作成をクリックします。
- ワークスペース名: 任意の文字列 → 作成するリソースに付ける名前
- サブスクリプション: 課金が紐づくサブスクリプションの選択
- リソースグループ: 任意の文字列 → これから作成していくリソース群を格納する場所の名前
- 場所: 任意のリージョン → リージョンによって料金が微妙に異なります。また、現在地から遠い場所を利用するとアクセスも遅くなるので注意。料金の詳細はこちら
- ワークスペースのエディション: Enterprise → BasicとEnterpriseを選べますが、エディションによって利用できる機能や料金が異なります。詳しい違いはこちら
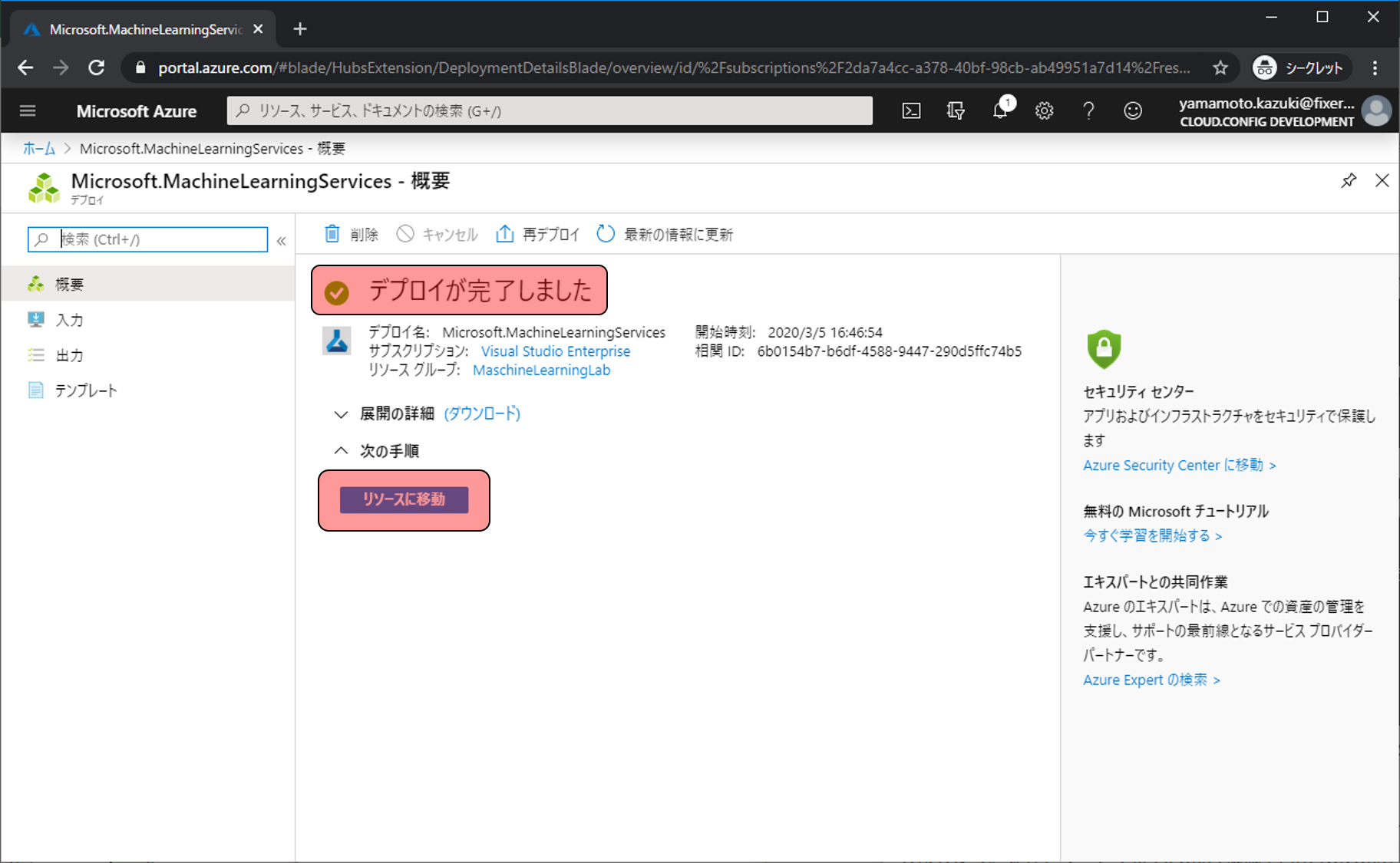
デプロイが始まるので3分程度待ちます。
デプロイが完了しましたと表示されたらリソースに移動をクリックします。これでAzure Machine Learning Serviceの作成は完了です。
予測モデルを作成する
次に解釈させる予測モデルを作成します。モデルの作成は Azure Machine Learning ServiceのAutoML機能で行います。
AutoMLは予測させたいデータを与えるだけでアルゴリズムの選択やハイパーパラメータの調整などを自動で行い、高精度なモデルを作成してくれるというとても便利な機能です。
今回はサンプルデータとしてUCI Machine Learning Repositoryで提供されているWine Qualityデータを用います。下記URLからwinequality-white.csvをダウンロードしてください。
https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/
winequality-white.csvの各項目の意味合いは以下になります。ワインについて全く詳しくないので、各項目が味にどのような影響を与えるのかわかりませんが、今回はquality: ワインの評価を予測対象とします。
- fixed acidity: 酒石酸濃度
- volatile acidity: 酢酸濃度
- citric acid: クエン酸濃度
- residual sugar: 残留糖分濃度
- chlorides: 塩化ナトリウム濃度
- free sulfur dioxide: 遊離亜硫酸濃度
- total sulfur dioxide: 総亜硫酸濃度
- density: 密度
- pH: 水素イオン濃度
- sulphates: 硫酸カリウム濃度
- alcohol: アルコール度数
- quality: ワインの評価
Azure Machine Learning Serviceの管理画面に移動したら今すぐ起動するをクリックします。
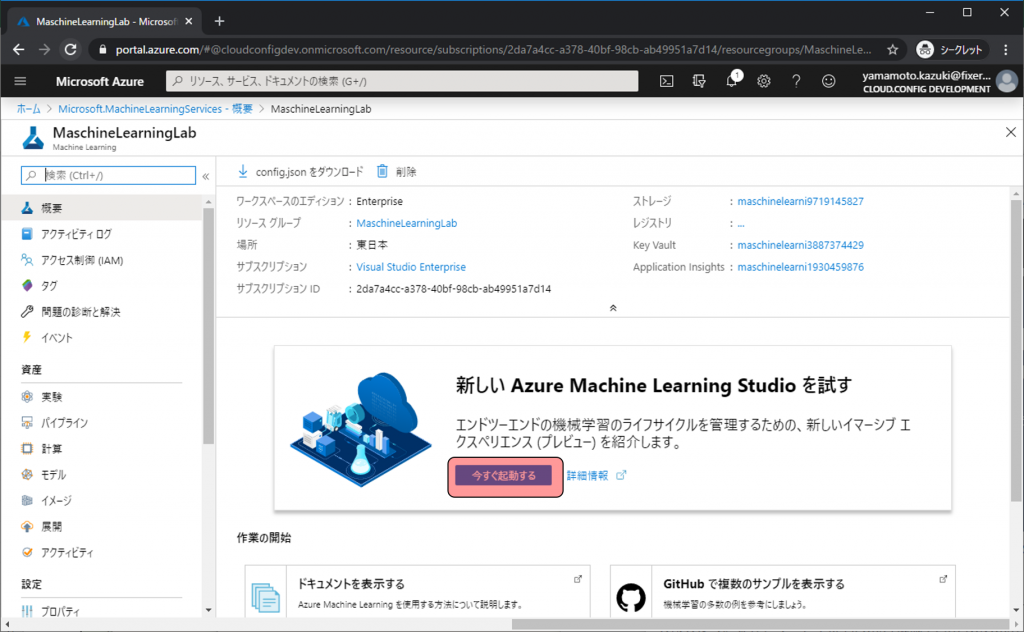
Azure Machine Learning Service専用の管理画面に移動します。ここで学習データやコンピューティングリソース、デプロイしたモデルなど機械学習に纏わるすべてを管理します。
モデルを作成する準備を進めます。自動MLをクリックします。
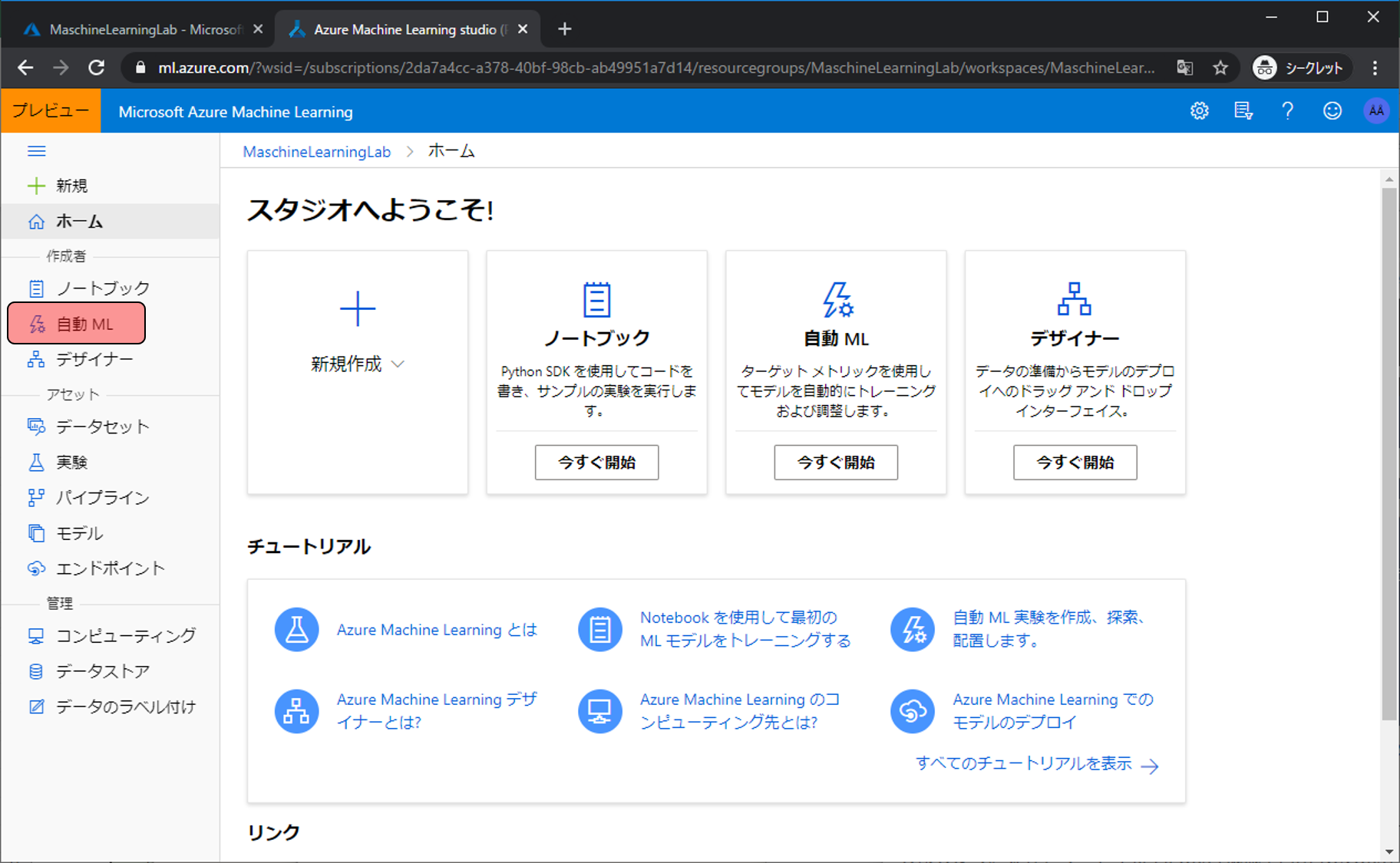
新しい自動MLの実行をクリックします。
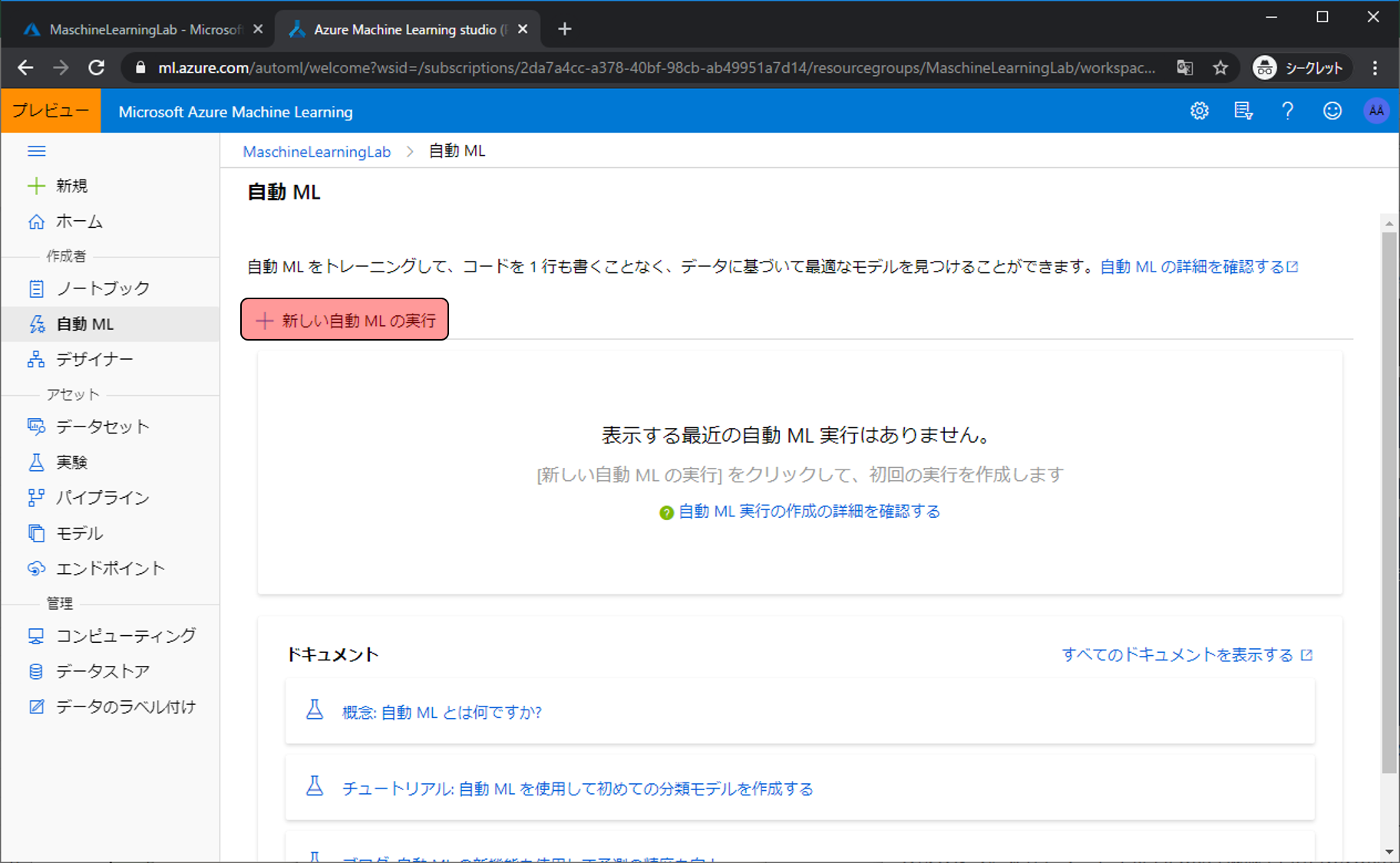
モデル作成に利用する学習データをアップロードします。データセットの作成をクリックし、ローカルファイルからをクリックします。
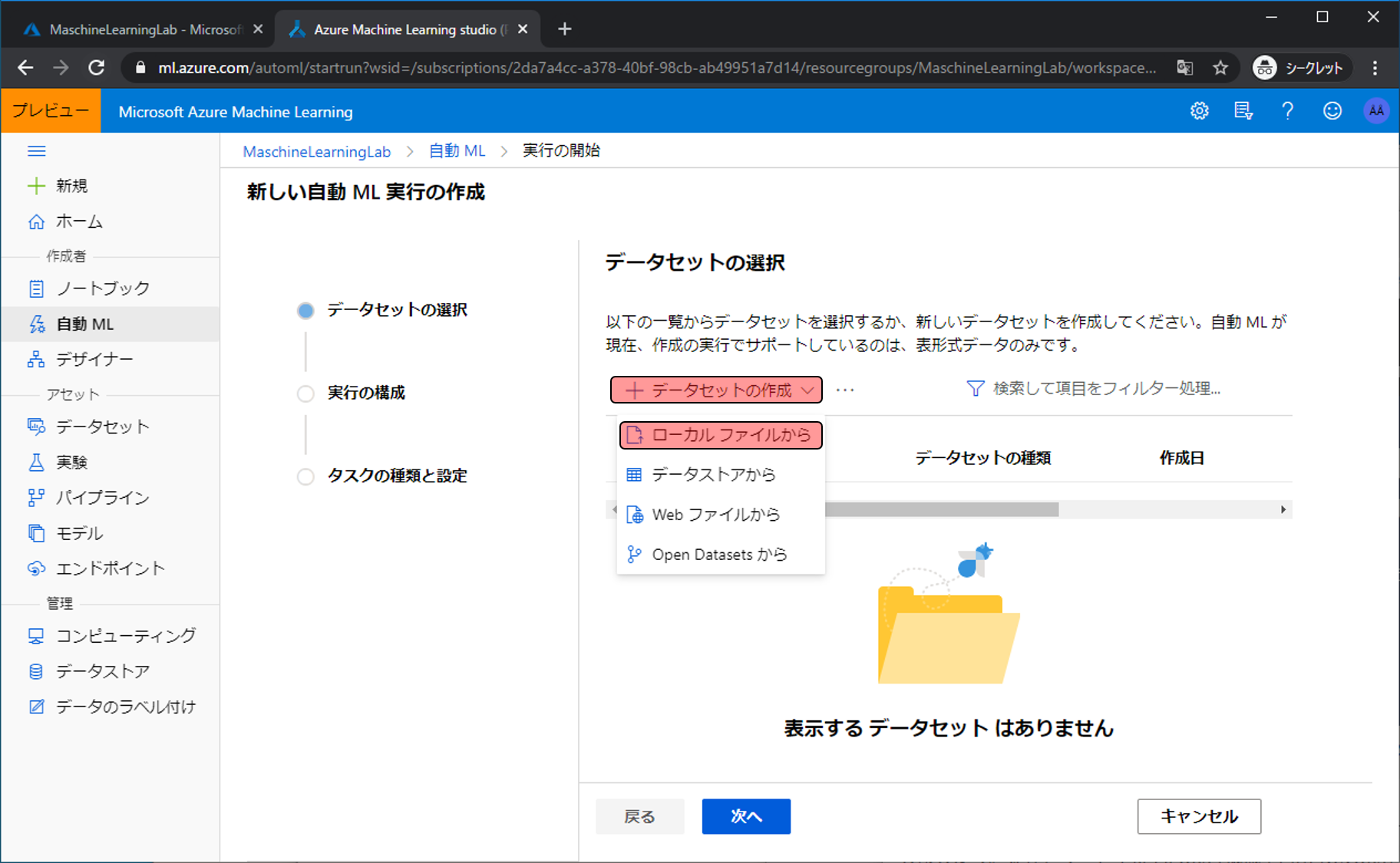
名前にWhite Wine Quality Dataと入力し、次へをクリックします。
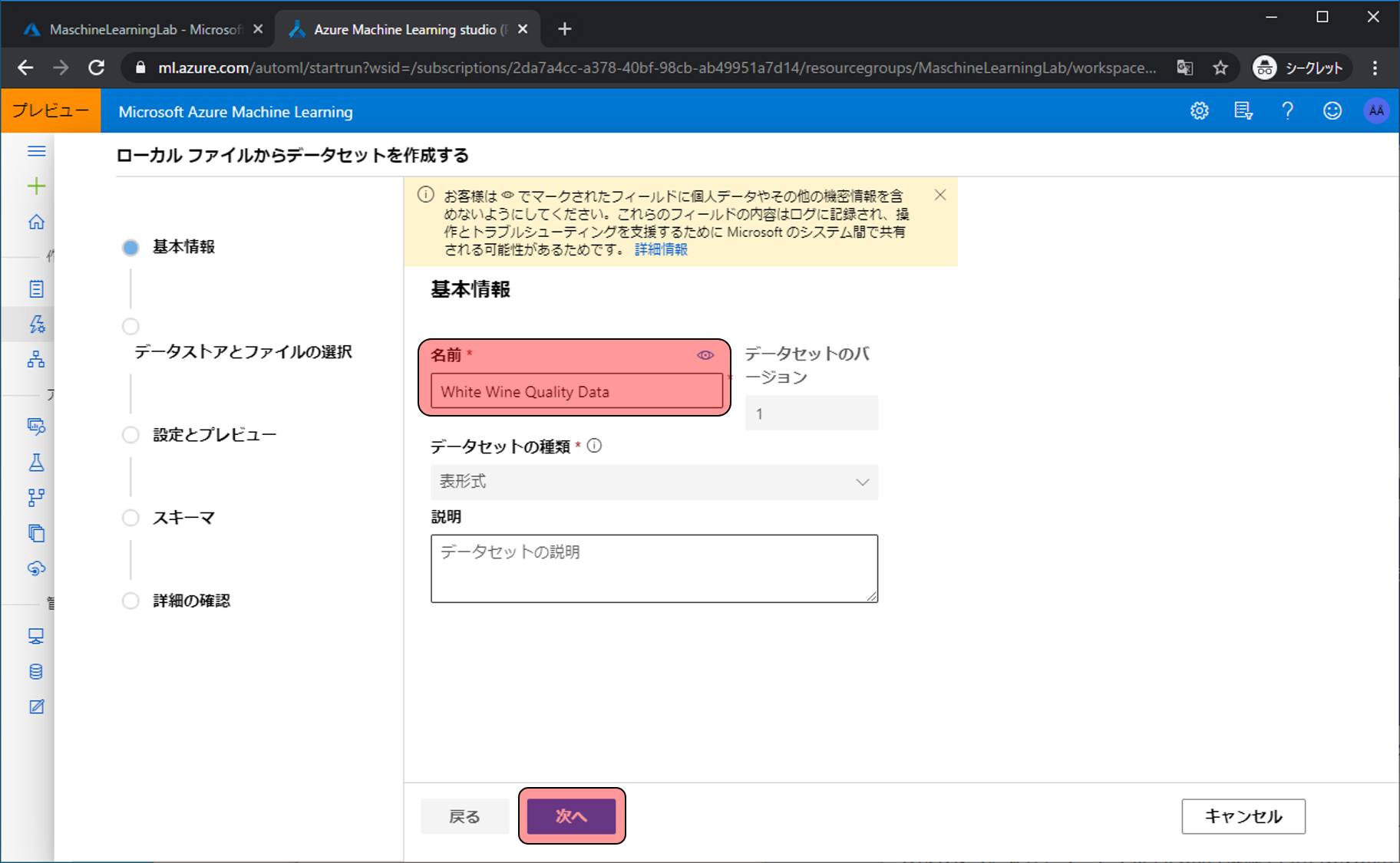
データストアの選択は以前に作成されたデータストアを選択し、参照から先程ダウンロードしたwinequality-white.csvを選択して次へをクリックします。
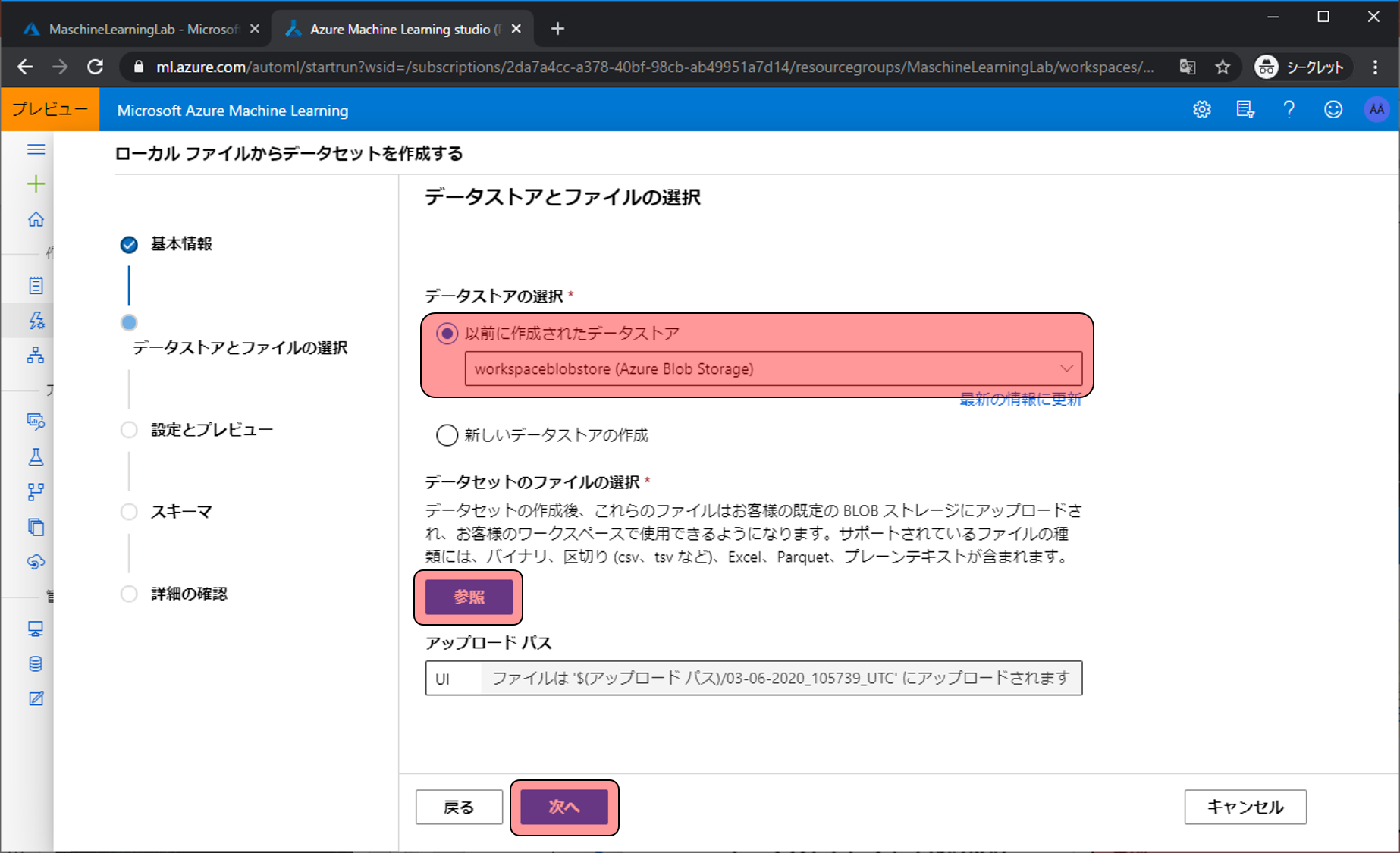
入力したデータがちゃんと区切られているかなどを確認することができます。今回のデータでは、一行目がヘッダー情報になっています。これを反映させるため、列見出しを最初のファイルヘッダーを使用するを選択し、次へをクリックします。
利用するデータの選択や、型の指定を行えます。今回は特に変更箇所はないので、そのまま次へをクリックします。
作成をクリックします。
アップロードしたWhite Wine Quality Dataを選択して次へをクリックします。
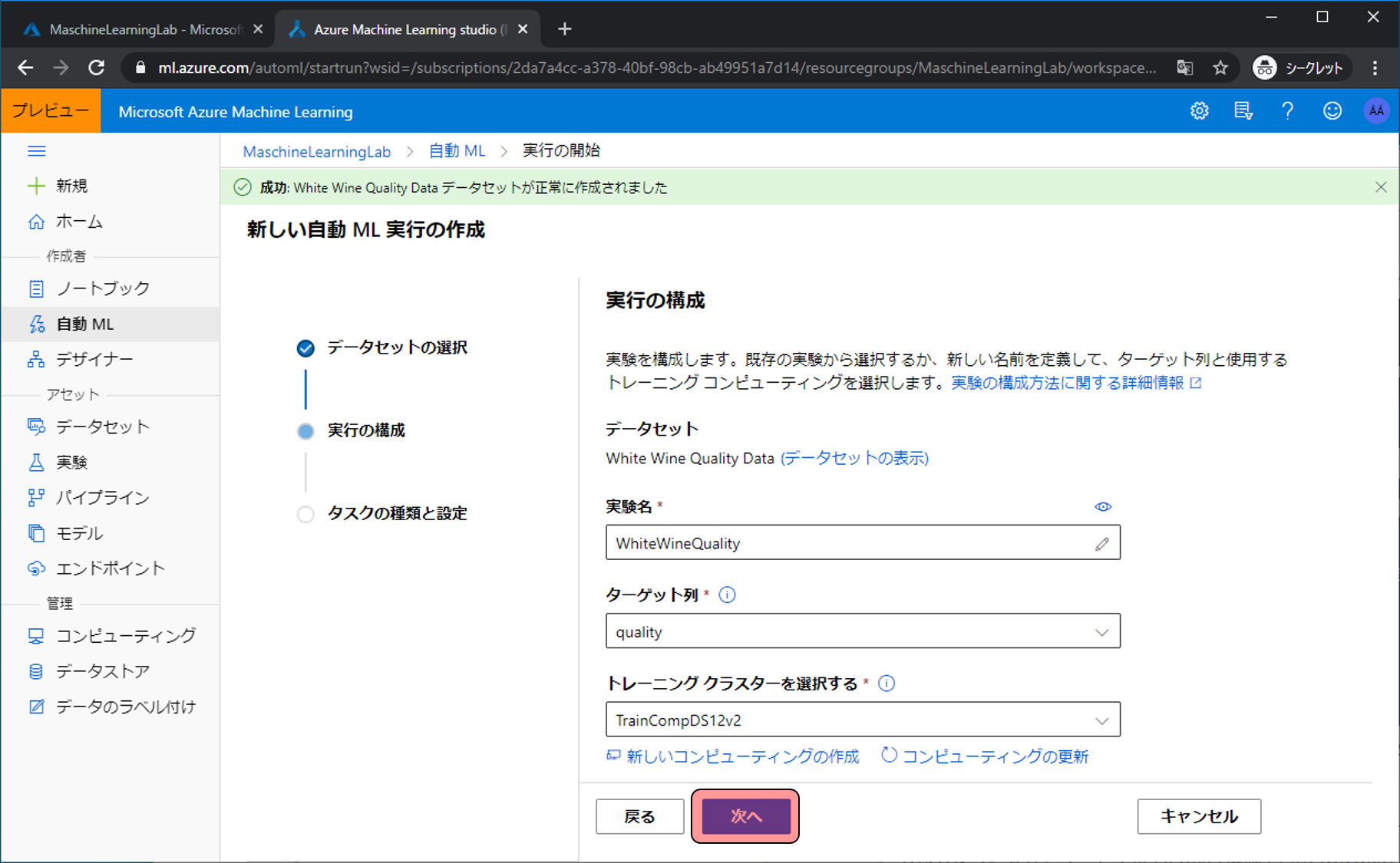
入力や選択する項目があるので、設定しトレーニングクラスタを選択するをクリックします。
- 実験名: 任意の文字列 → 予測するモデルを作成しているのか分かる名前
- ターゲット列: 予測したい対象の列名
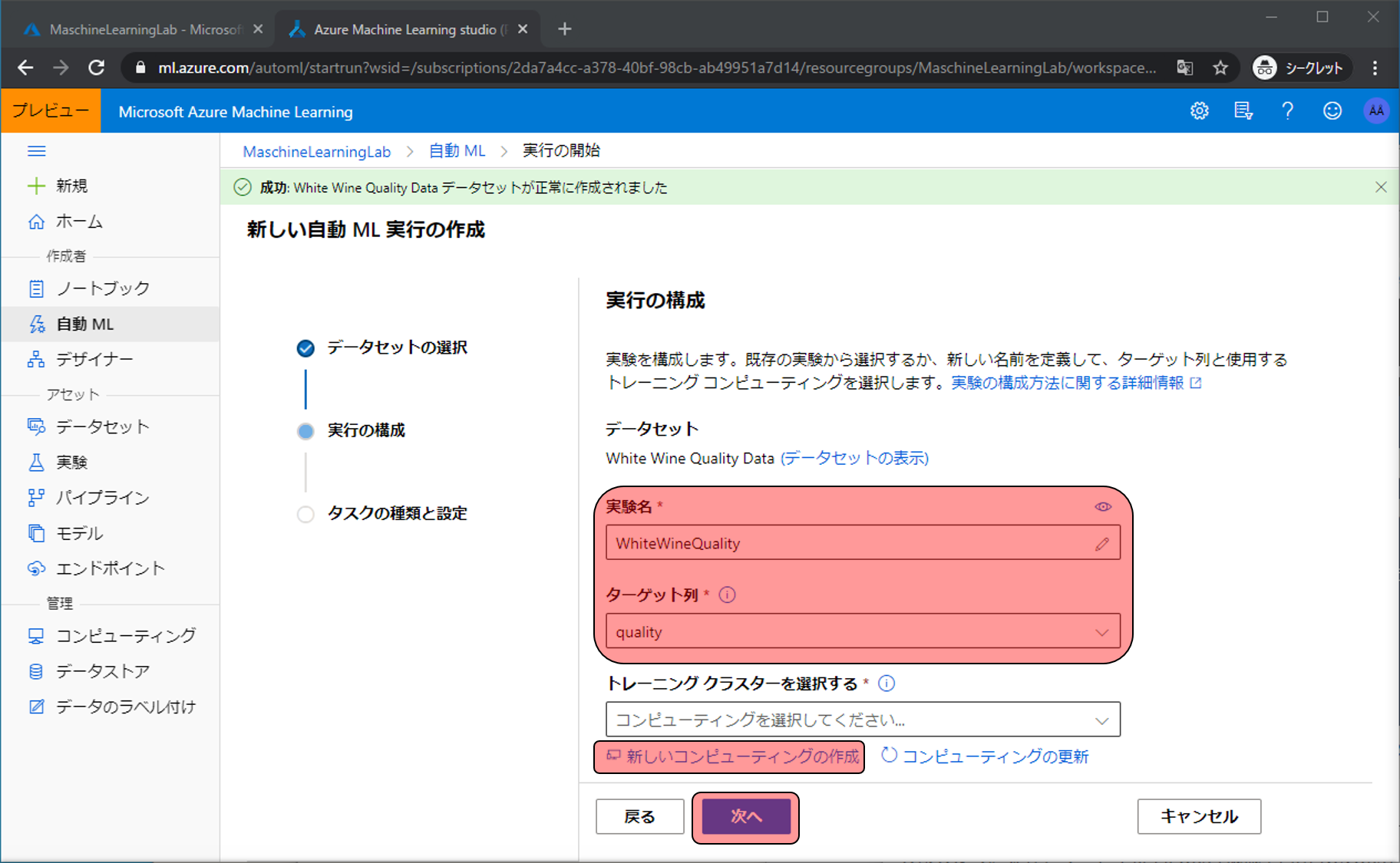
ここでは機械学習で利用するコンピュータリソースを作成します。特に初期値から変更はせず、コンピューティング名だけ設定して作成をクリックします。
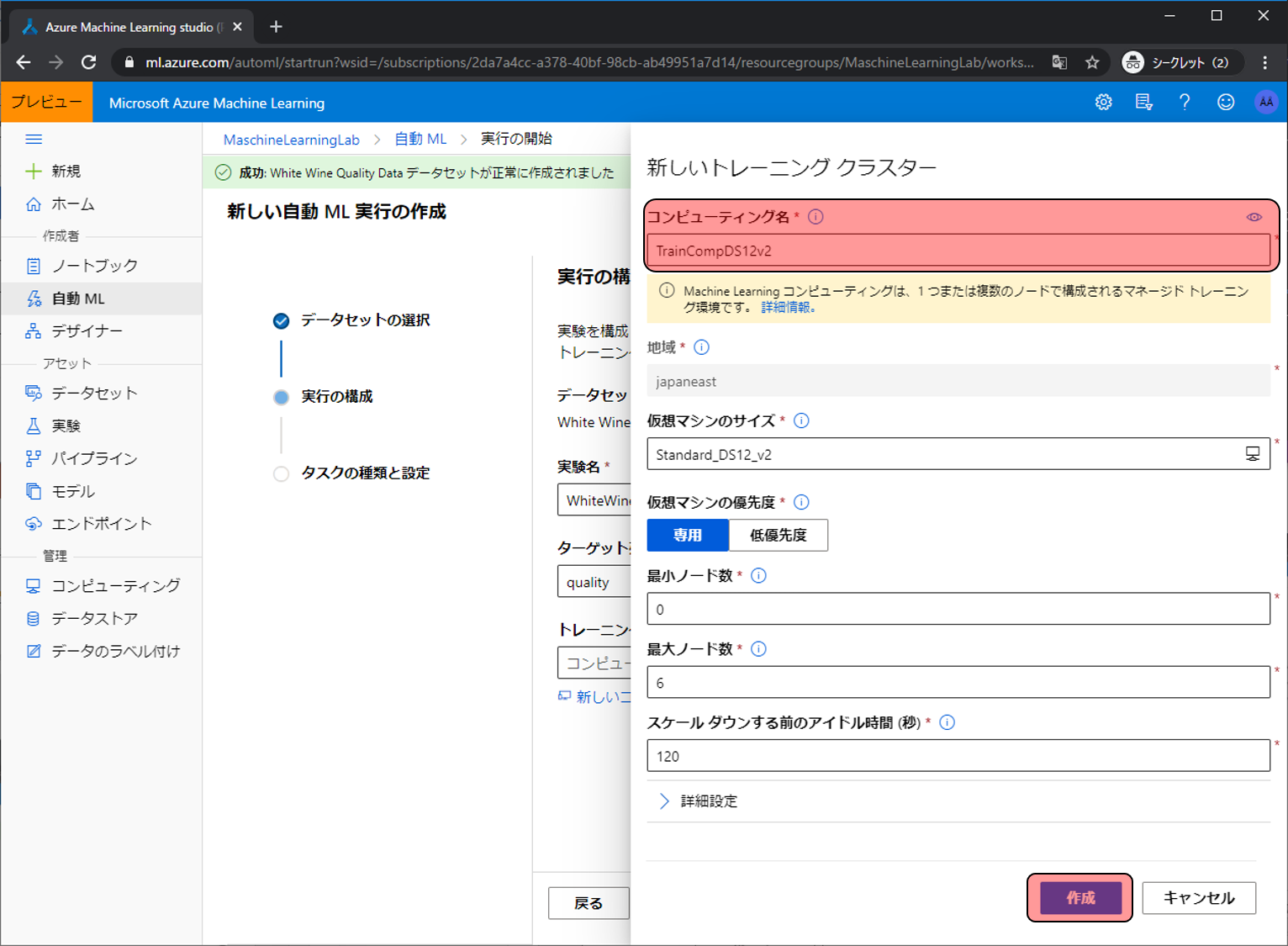
次へをクリックします。
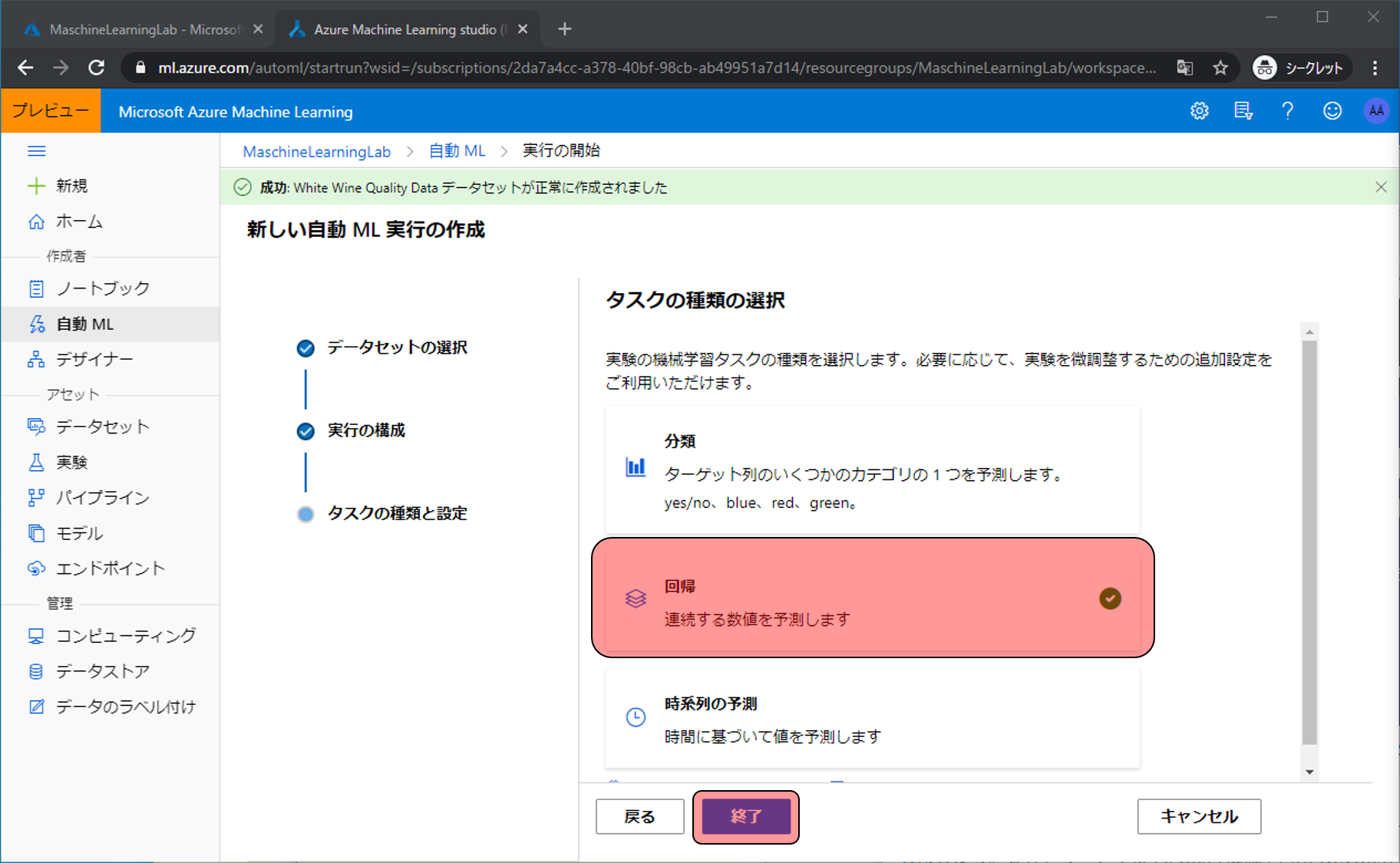
どんな予測を行うか設定します。今回はワインの評価(値)を予測するので回帰を選択して終了をクリックします。
学習が始まります。今回の場合では、モデルの完成まで40分程度かかります。AutoMLでは40分掛けて1つのモデルを作るのではなく、何十個もモデルを作成します。何十と作成した中で最も良かったモデルを今回は解釈します。
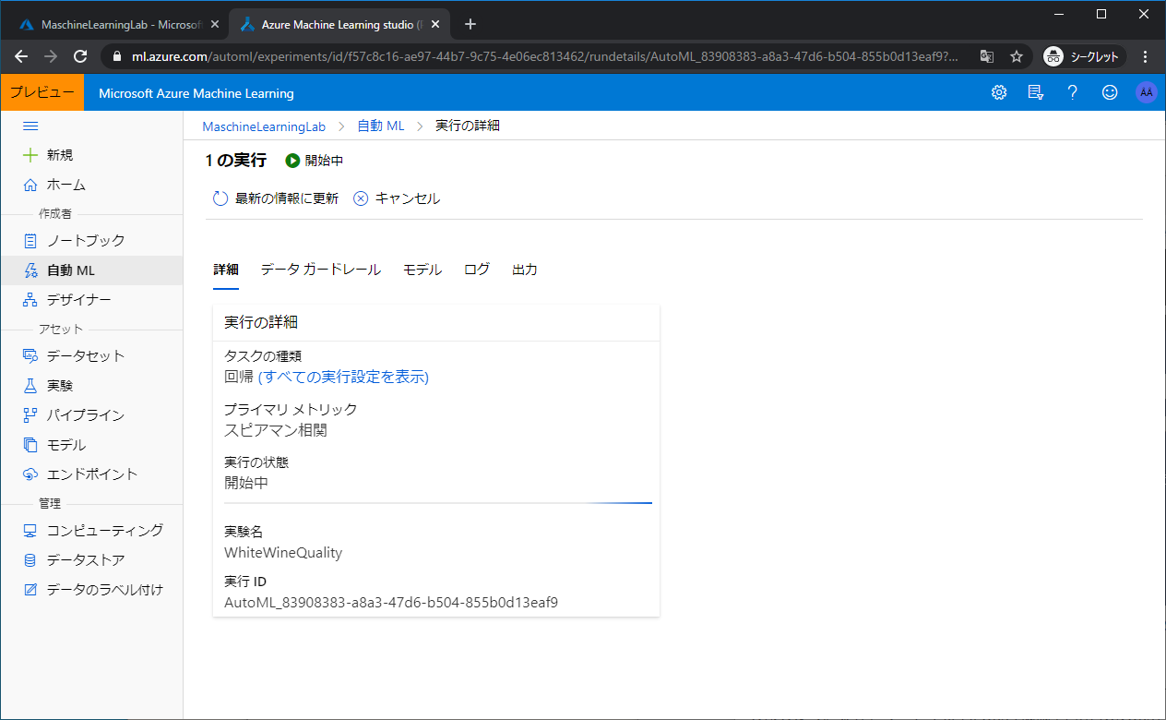
完了と表示されたらモデルの詳細表示をクリックします。これで予測モデルの作成は完了です。
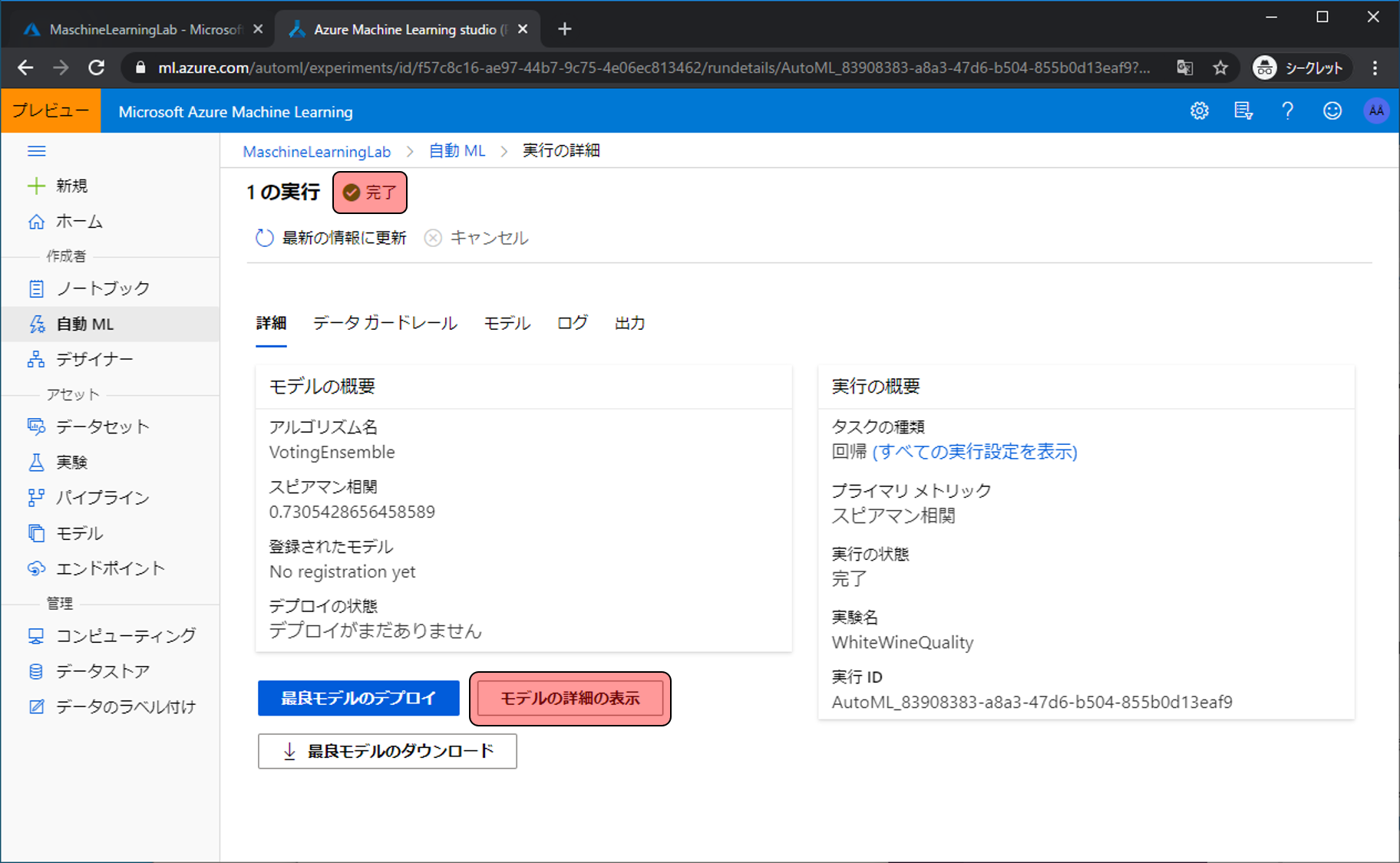
モデルを解釈する
メトリック情報にこのモデルの統計情報が記載されます。今回は解釈をすることが優先なので各パラメータの解説は割愛します。視覚エフェクトをクリックします。
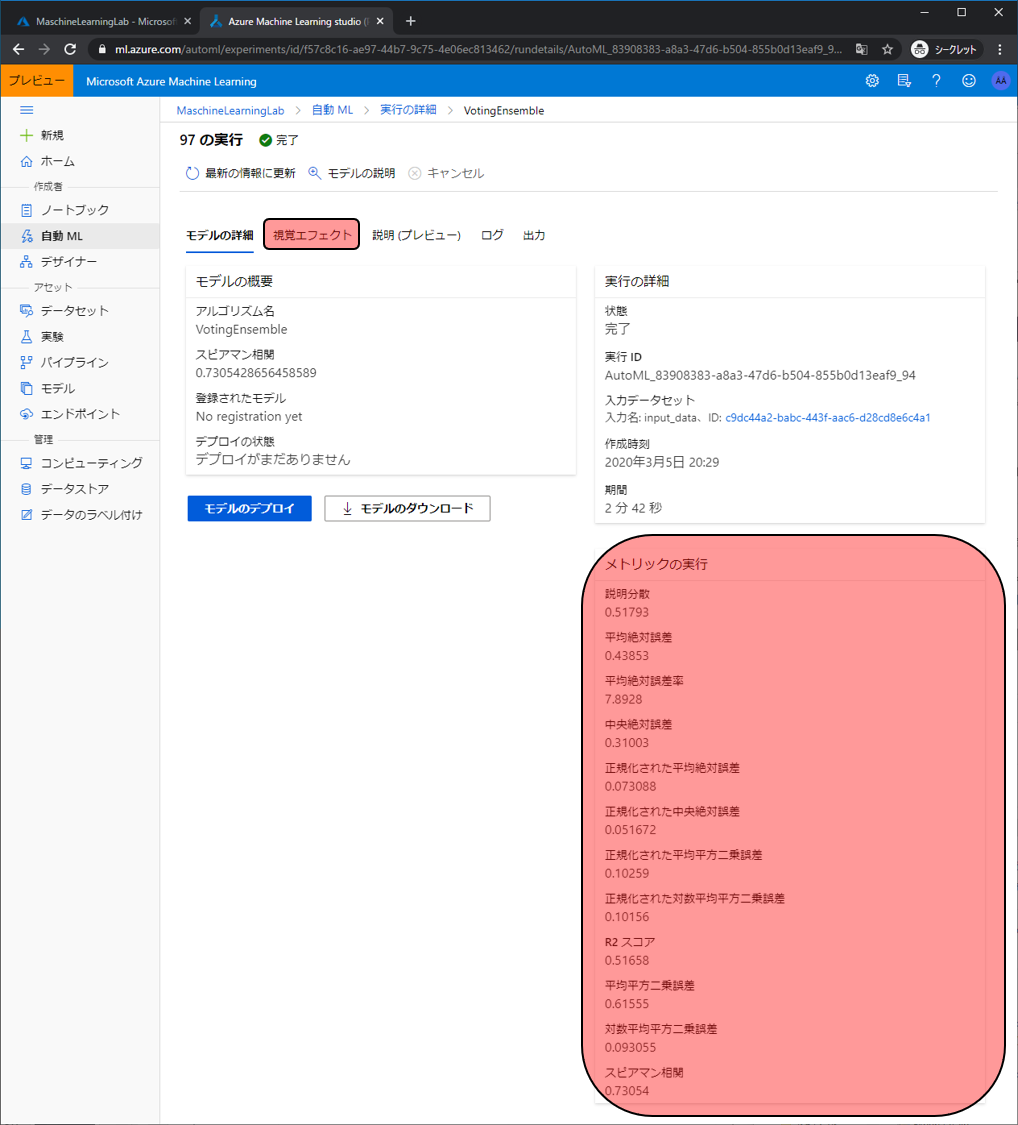
視覚エフェクトではこのモデルの予測精度をグラフィカルな情報で確認することができます。
1つ目の図では、このモデルが予測した値と実際の値の関係がグラフで表示されます。縦軸が予測した値、横軸が実際の値になり、緑の点線が理想の状態で、青の線が実際です。青い線は緩やかですが右肩上がりになっているため、良くはないですがなんとなく傾向が取れているようです。
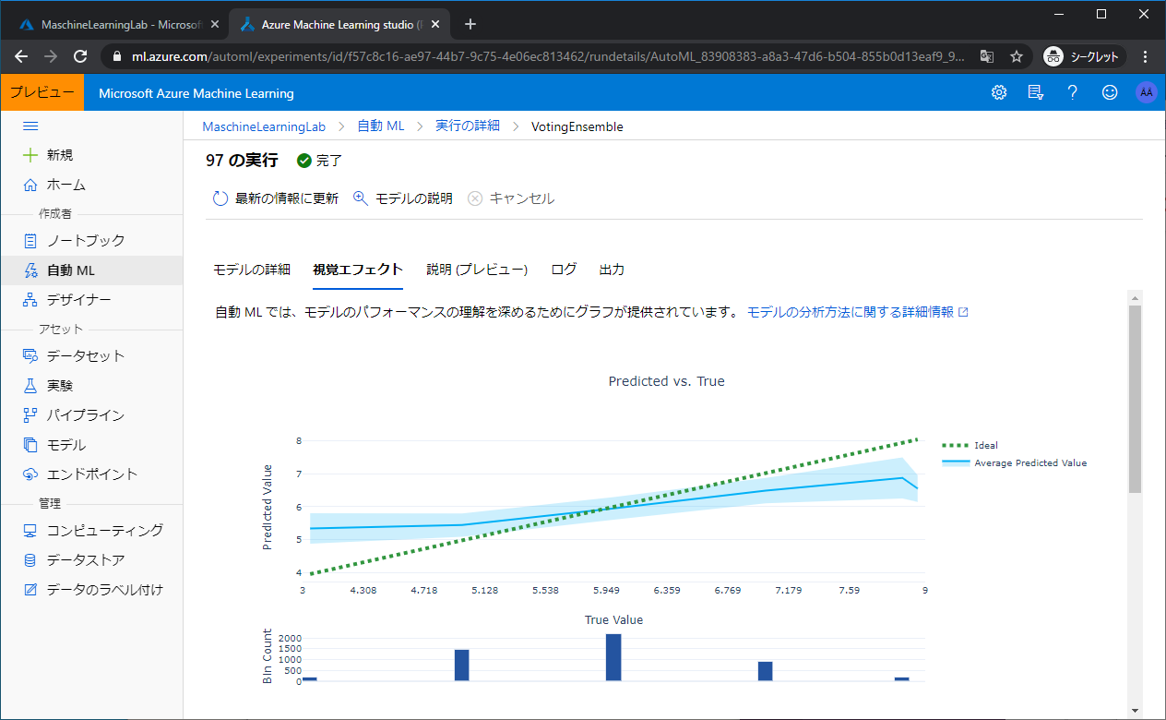
下にスクロールすると予測した値と実際の値の差の分布が確認できます。正規分布っぽくなっていると良い感じなので、おおむね問題ないようです。
次に本題のモデル解釈の結果を確認します。説明(プレビュー)をクリックします。
Data Explorationでは、データ同士の関連性を確認できます。
X valueをPredictedY(予測値)、Y valueをalcohol_MeanImputerとすると、アルコール度数が高いものを高評価と予測する傾向が確認できます。選択するパラメータを変更することで、他のデータとの関係性も確認できます。
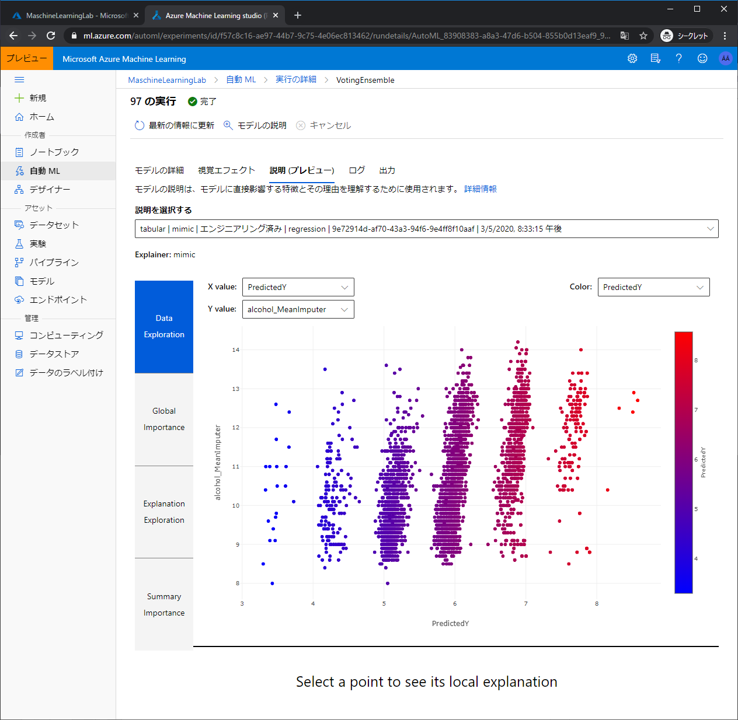
Global Importanceではグローバルなモデル解釈の際に重要視される要素が確認できます。ここでもアルコール度数がワインの評価への影響が大きいことが伺えます。
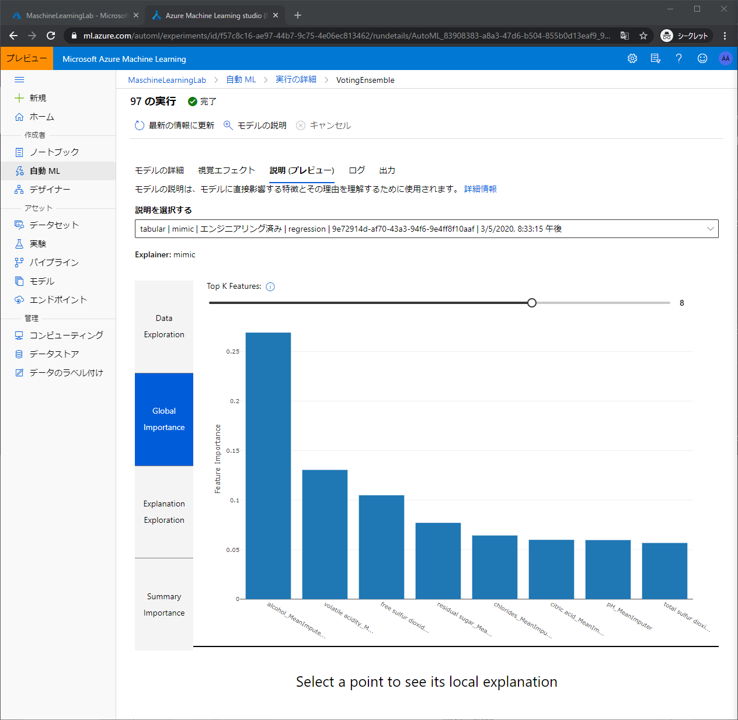
Explanation Explorationは特徴が予測値の変化にどのような影響を与えるのかを確認できます。
例えば、Data: alcohol_MeanImputer と Importance: alcohol_MeanImputer で表示させると、アルコール度数が高い場合は アルコール度数の値を参考にしてワインの評価を予測できるが、アルコール度数が低いときは 予測をするときにアルコール度数の値を参考にできないということがわかります。
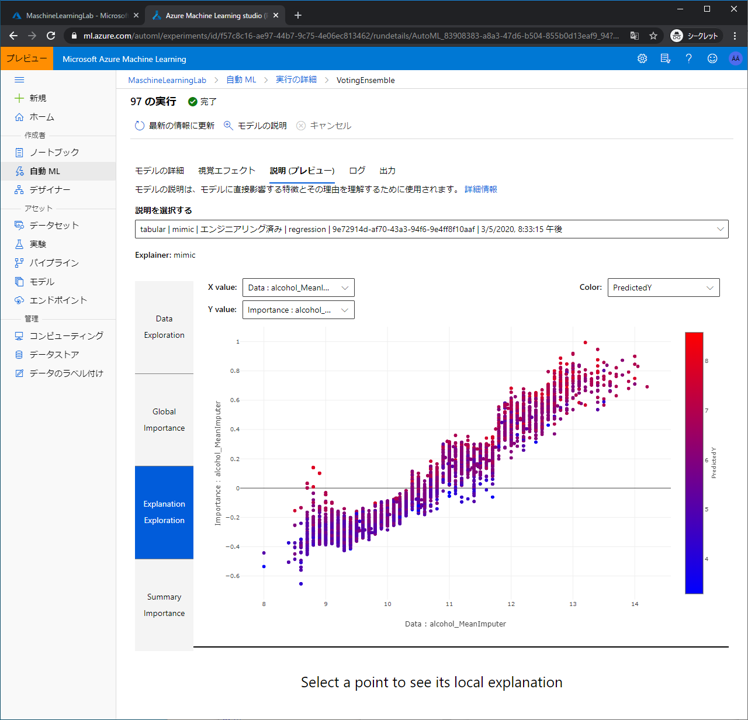
Summary Importance は各特徴が予測値に与える影響の分布を表示します。
(このデータはどう使うべきか正直良くわかりません……)
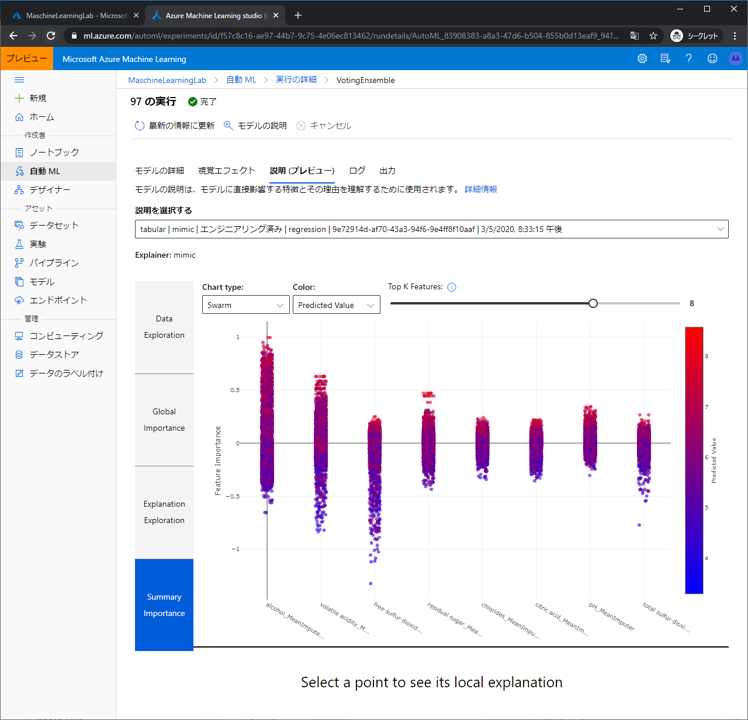
上記説明に存在する点の一つをクリックすると、そのデータのときのローカルなモデル解釈を確認することができます。
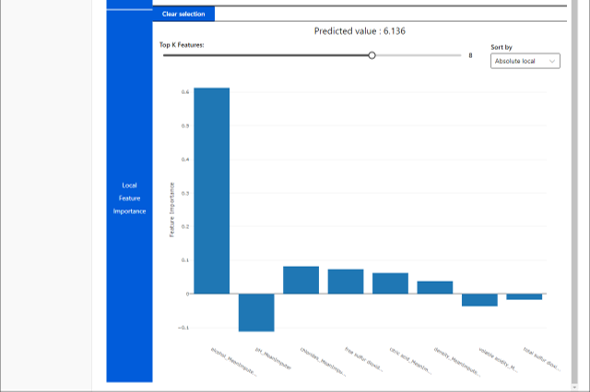
これで、AutoMLで確認することができるモデル解釈の内容をです。
次回はpythonコードでモデル解釈を行ってみます。










![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
