





こんにちは。 R&D Divisionの山本です。
最近のAIは当たり前にモノを識別しますよね。賢いAIに車の写真を渡したら、ちゃんと「車」だと識別しますし、写ってる人物が誰なのかを識別することだってできます。
ただ、なぜ「車」や「人」だと判断したのかは中々わかりません。誤った認識(例えば、人が写っていない画像を、人が写っていると判断)をしていた場合、なぜ間違ったのか気になると思います。
なので、今回はAIが画像のどこに着目して、判断をしているかを見ていこうと思います。
今回はAzure Maschine Learning Serviceに付随するJupyter Notebook上でAIがどこに着目しているのかを確認していきます。確認にはLIMEという手法を用います。
※LIMEについてLIMEを利用したモデル解釈の記事で解説しています
まずはノートブックの管理画面まで移動し、 新しいフォルダの作成アイコンをクリックします。 今から作成するフォルダに 分析対象の画像を格納します。ノートブック管理画面への移動やコンピューティングの設定方法がわからない場合は、過去に解説した記事があるので参考にしてください。
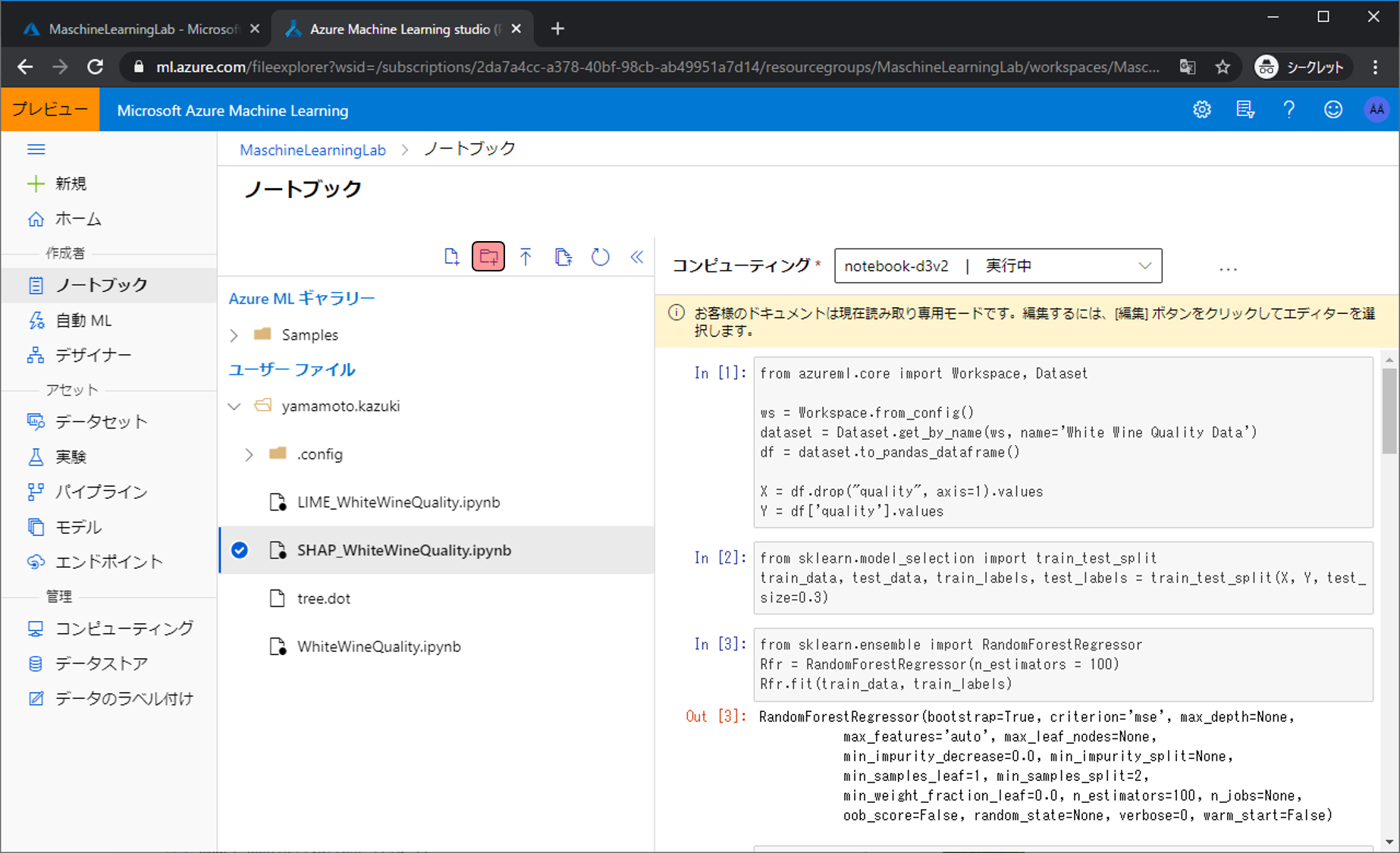
フォルダー名をimageにし、作成をクリックします。
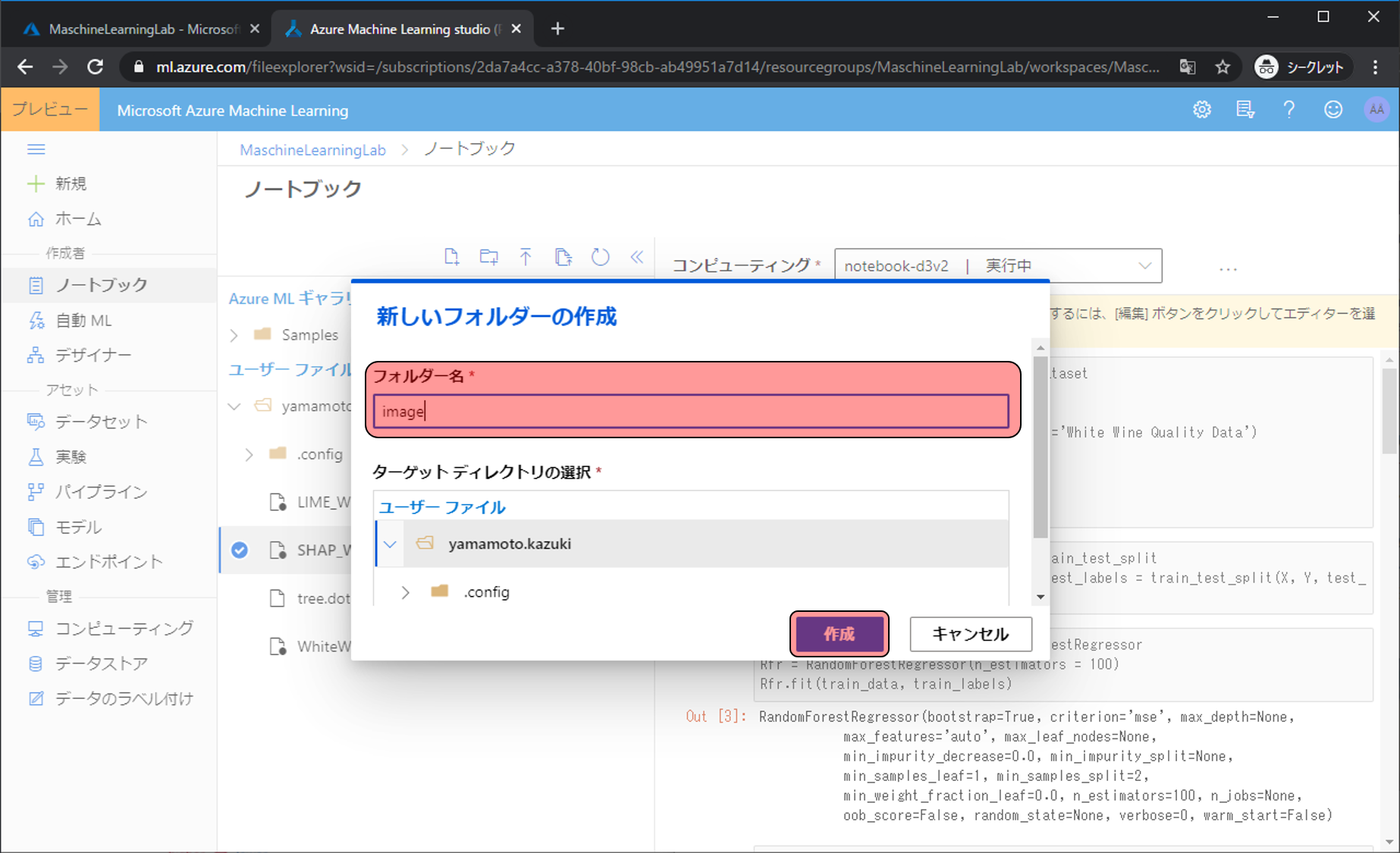
imageフォルダが作られます。続いて分析対象の画像をアップロードします。ファイルのアップロードアイコンをクリックします。
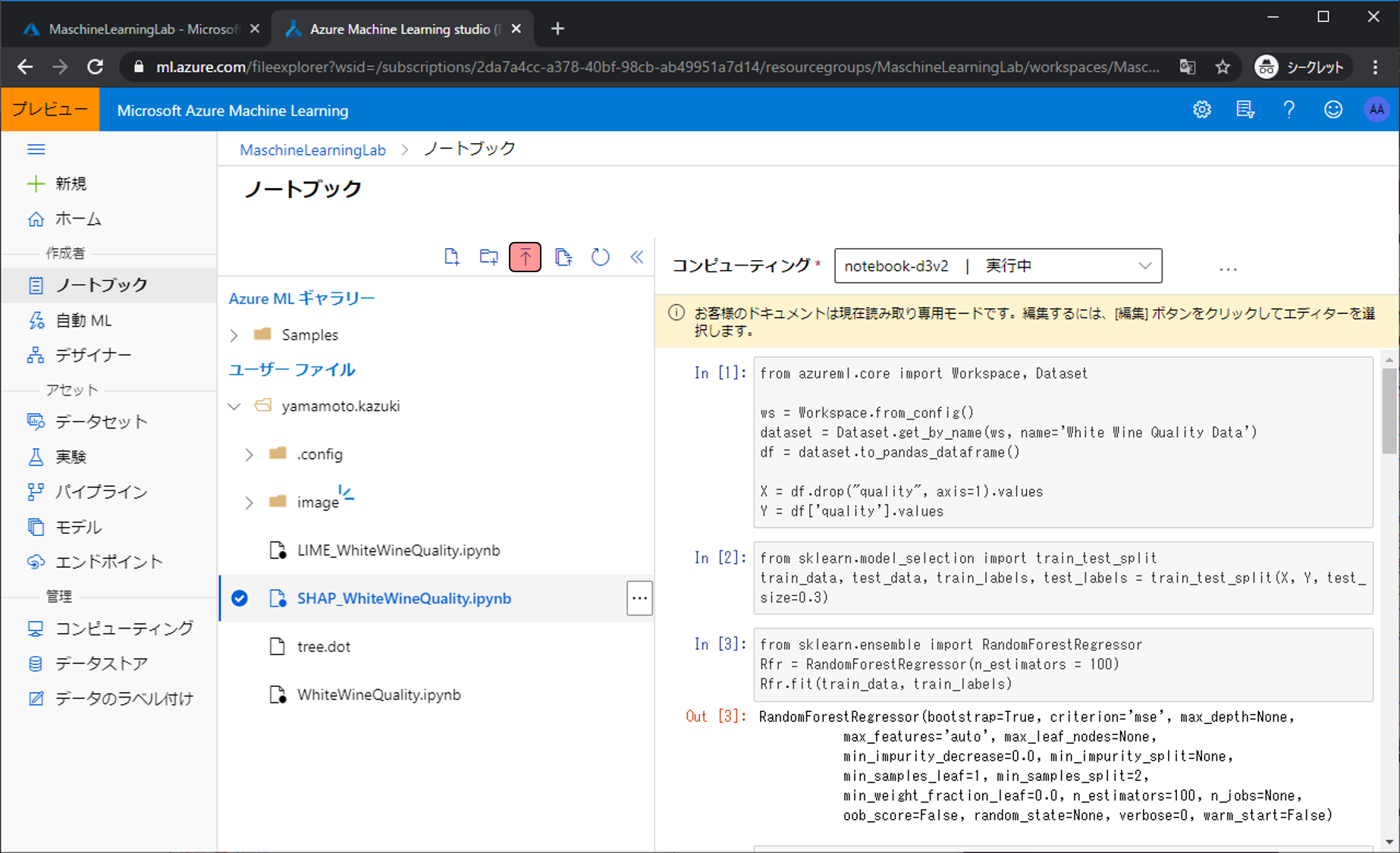
お持ちの好きな写真を選択し、ターゲットディレクトリの選択でimageを選び、アップロードをクリックします。
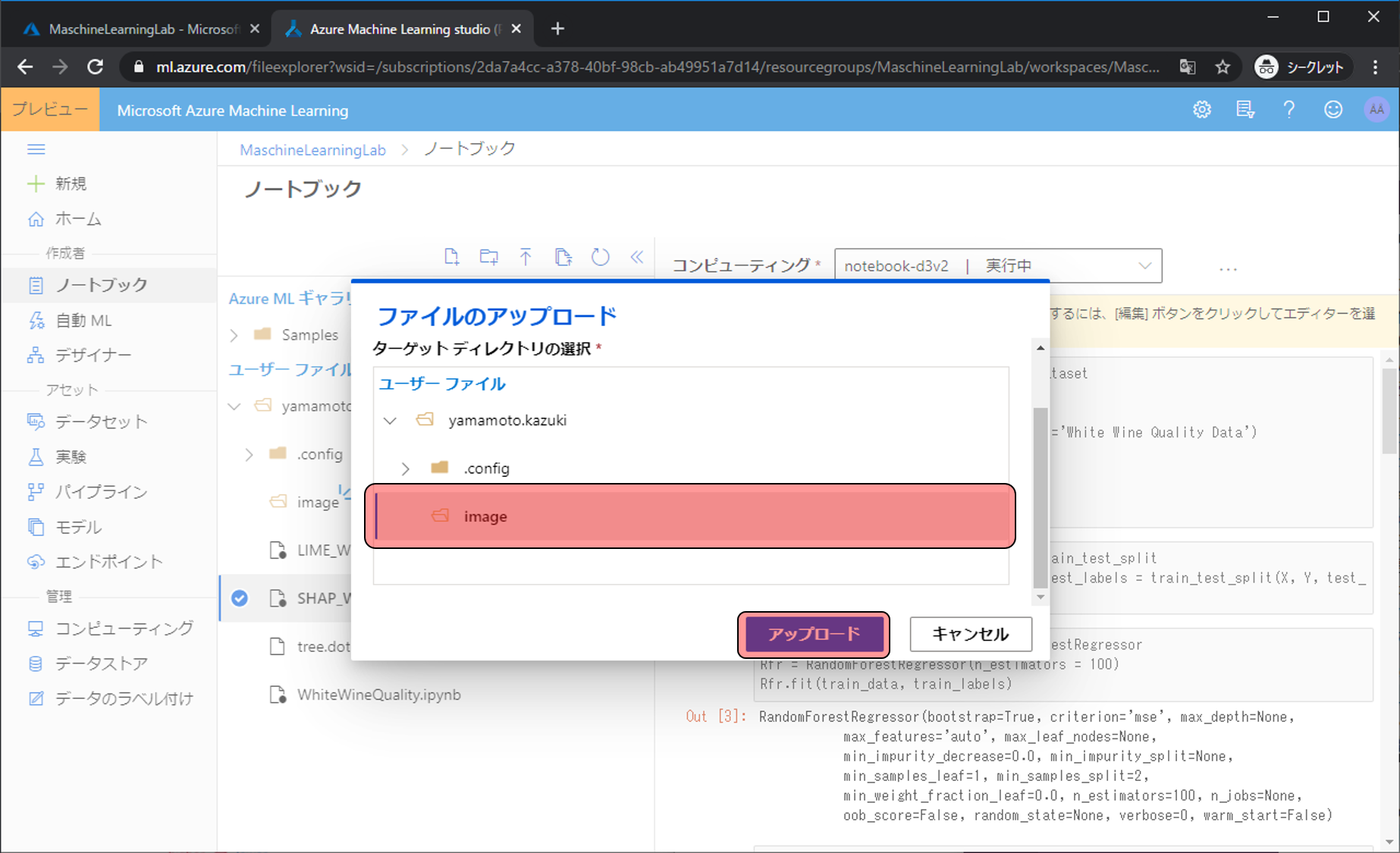
Pythonコードを書いていくファイルを準備します。新しいファイルの作成アイコンをクリックします。
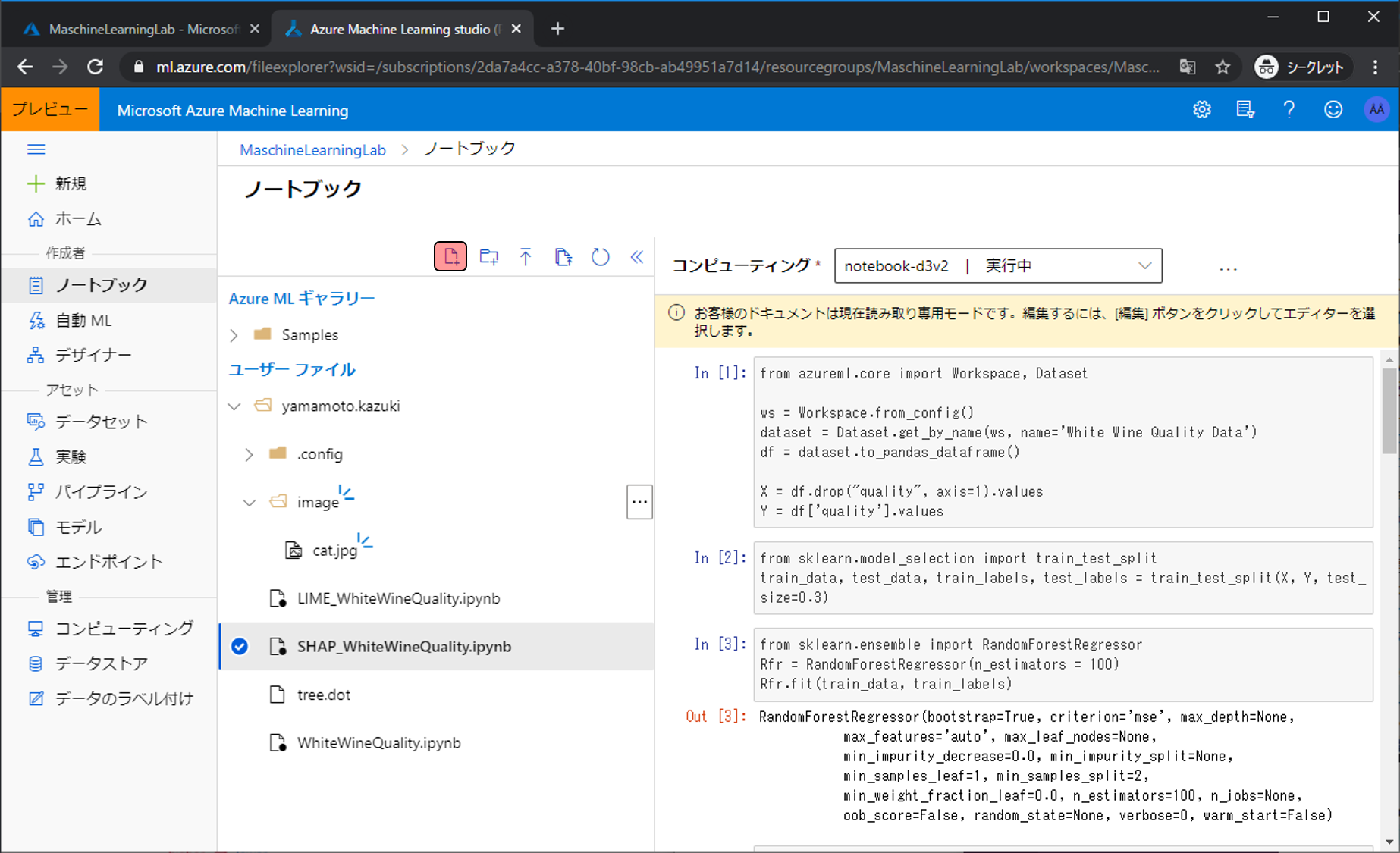
ファイル名をLIME_Image.ipynb、ファイルの種類をPython Notebookにし、作成をクリックします。
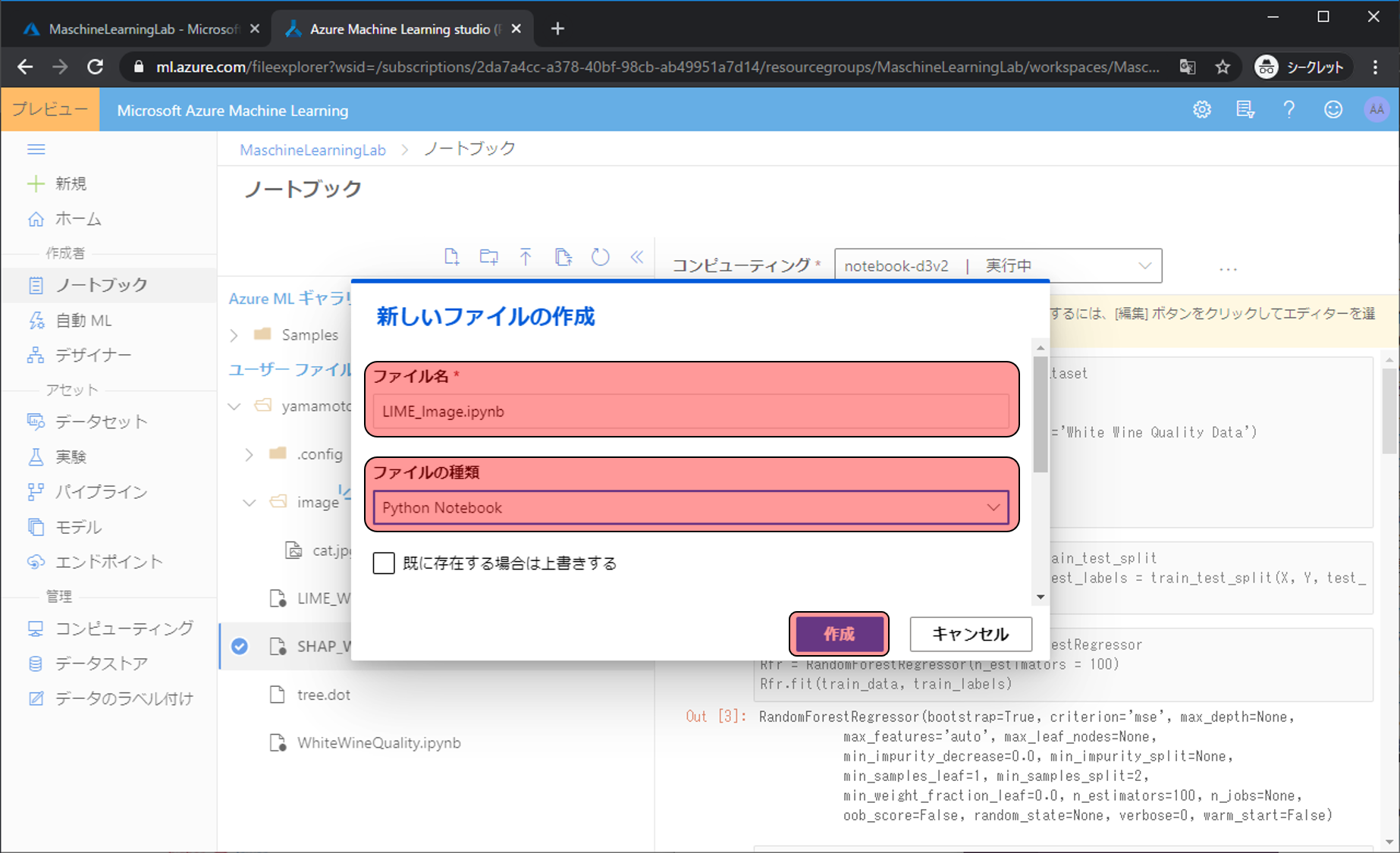
Jupyterが開けたらプログラムを書いていきます。下記は完成状態です。
今回は学習済みの画像認識モデル「InceptionV3」を利用するので、呼び出します。
from keras.applications import inception_v3 as inc_net
inet_model = inc_net.InceptionV3()画像を整形するための関数です。
from keras.preprocessing import image
import numpy as np
def transform_img_fn(path_list):
out = []
for img_path in path_list:
img = image.load_img(img_path, target_size=(299, 299))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = inc_net.preprocess_input(x)
out.append(x)
return np.vstack(out)先程アップロードした画像を呼び出して、関数に渡します。
images = transform_img_fn([os.path.join('image','cat.jpg')])画像に写っているモノをなにと予測したのかの情報と、整形後の画像表示します。
import matplotlib.pyplot as plt
from keras.applications.imagenet_utils import decode_predictions
plt.imshow(images[0] / 2 + 0.5)
preds = inet_model.predict(images)
for x in decode_predictions(preds)[0]:
print(x)分析に必要なLIMEをインストールします。
pip install limeLIMEによる分析の下準備をします。
import lime
from lime import lime_image
explainer = lime_image.LimeImageExplainer()
explanation = explainer.explain_instance(images[0], inet_model.predict, top_labels=5, hide_color=0, num_samples=1000)判断結果の決め手になった箇所だけ表示します。
from skimage.segmentation import mark_boundaries
temp, mask = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=True, num_features=5, hide_rest=True)
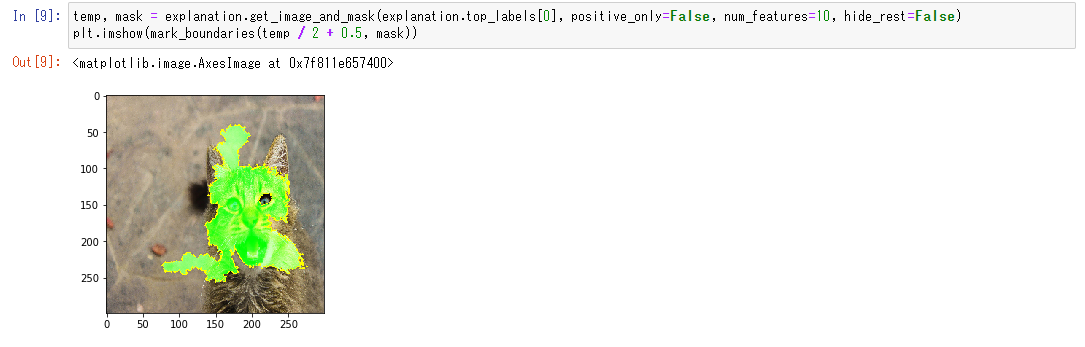
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))判断結果を求めるのに有益だった箇所を緑色で表しています。今回はありませんが、不益(判断するのに邪魔だった箇所)は赤色で表示されます。
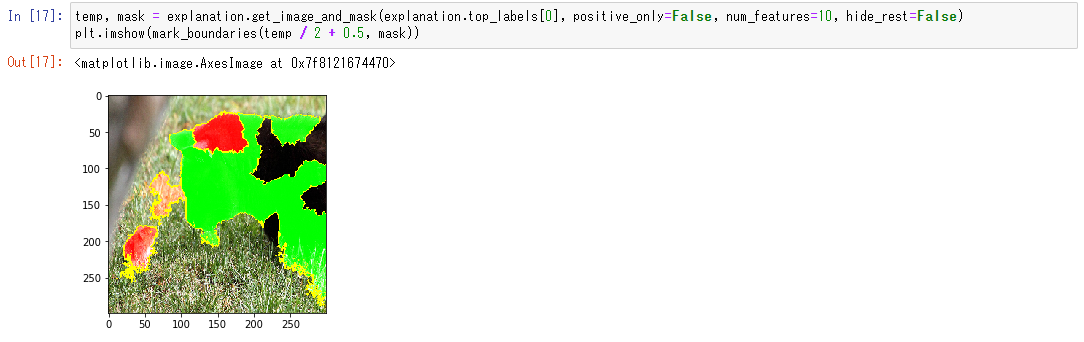
temp, mask = explanation.get_image_and_mask(explanation.top_labels[0], positive_only=False, num_features=10, hide_rest=False)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))コードをコピペしたら、上から順に実行します。
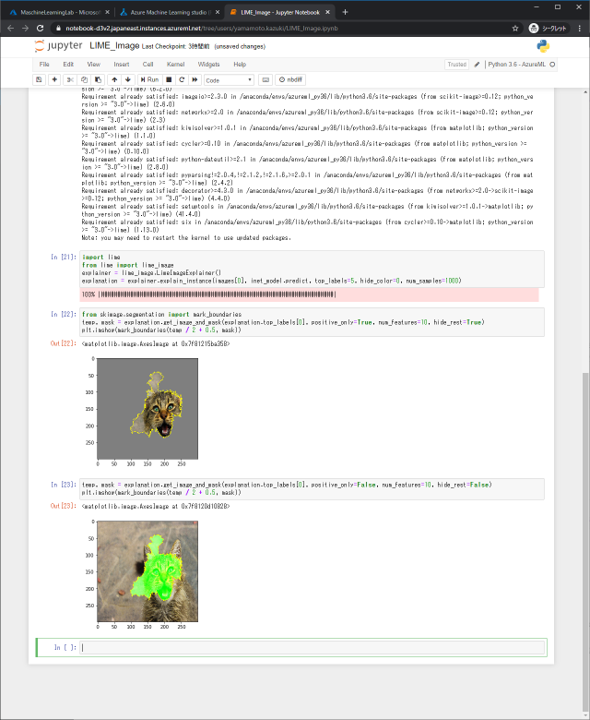
まずは予測結果を見てみましょう。今回の画像では写っているものはtiger_catだと予測していました。合っていそうですね。
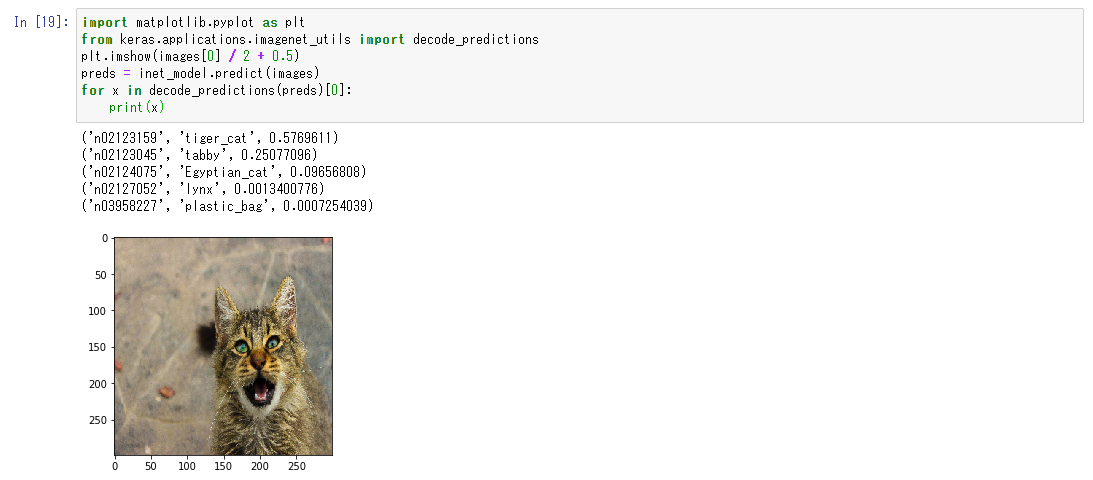
次に着目したポイントを確認しましょう。画像が出ている場所が着目したポイントです。顔に着目していたようですが、左目と耳にはあまり着目していないようですね。
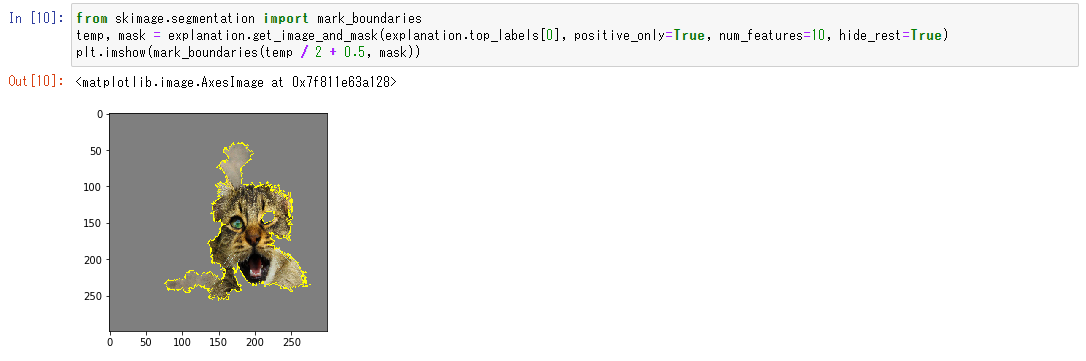
参考にした箇所を緑しました。tiger_catと判断するのに邪魔な要素があれば赤色で表示されますが、今回はありませんでした。
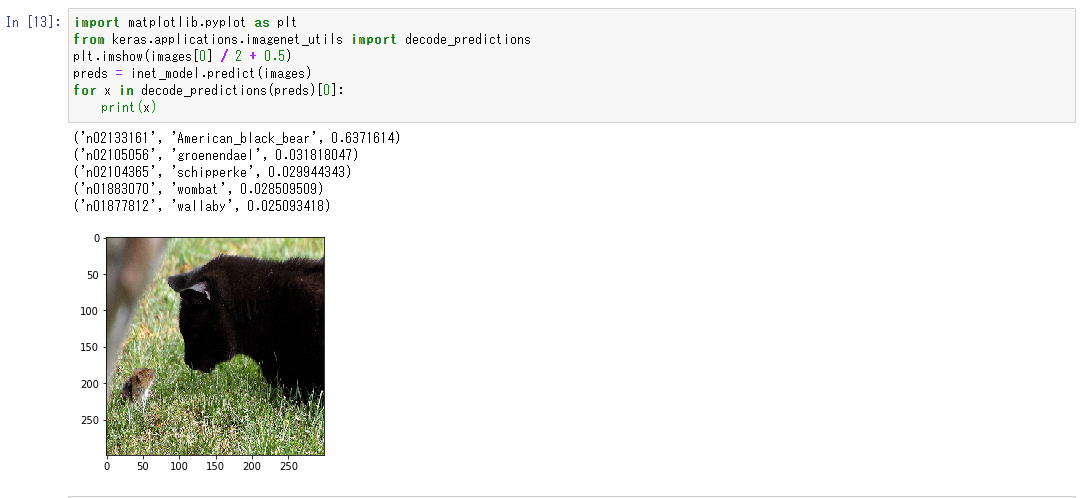
赤いのが表示される例です。この画像では、ネズミが判断の邪魔になっているようですね。ネズミがいなければもっとスコア高く予測されていました。
これで画像認識AIがどの箇所に着目して判断しているかわかりました。
画像識別をするときは、どこに着目しているかも調べてみると開発がスムーズに進みますので、ぜひやってみてください。








![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)


