






こんにちは。R&D Divisionの山本です。
みなさん、機械学習周りのコーディングは好きですか?
僕はあまり好きではないです。簡単な処理でさえよく書き方を忘れ、調べながら書くことが多いので時間を取られがちです。
コーディング好き嫌い以前に、したことがないという人も多数いると思います。そういう方々が、機械学習をするために1からPythonやRの環境準備から書き方を習得して---というのは中々にハードルが高いです。
なので、今回はノンコーディングで行う機械学習をして、予測モデルを作ってみたいと思います。
今回利用するのはAzure Machine Learning Serviceのデザイナーです。
デザイナーでは、機械学習に必要な様々な処理(例えば欠損値の補完やアルゴリズム)がモジュールとして用意されており、それらを繋げるだけで簡単に機械学習ができちゃいます。
今回はサンプルデータとしてUCI Machine Learning Repositoryで提供されているWine Qualityデータを用います。下記URLからwinequality-white.csvをダウンロードしてください。
https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/
winequality-white.csvには白ワインの情報と評価が4898件の情報が入っており、各項目の意味合いは以下になります。今回はquality: ワインの評価を予測します。
- fixed acidity: 酒石酸濃度
- volatile acidity: 酢酸濃度
- citric acid: クエン酸濃度
- residual sugar: 残留糖分濃度
- chlorides: 塩化ナトリウム濃度
- free sulfur dioxide: 遊離亜硫酸濃度
- total sulfur dioxide: 総亜硫酸濃度
- density: 密度
- pH: 水素イオン濃度
- sulphates: 硫酸カリウム濃度
- alcohol: アルコール度数
- quality: ワインの評価
リソースの作成
まずはAzure Machine Learning Serviceのリソースを作成します。
下記URLからAzure Portalに移動し、リソースの作成をクリックします。
https://portal.azure.com/
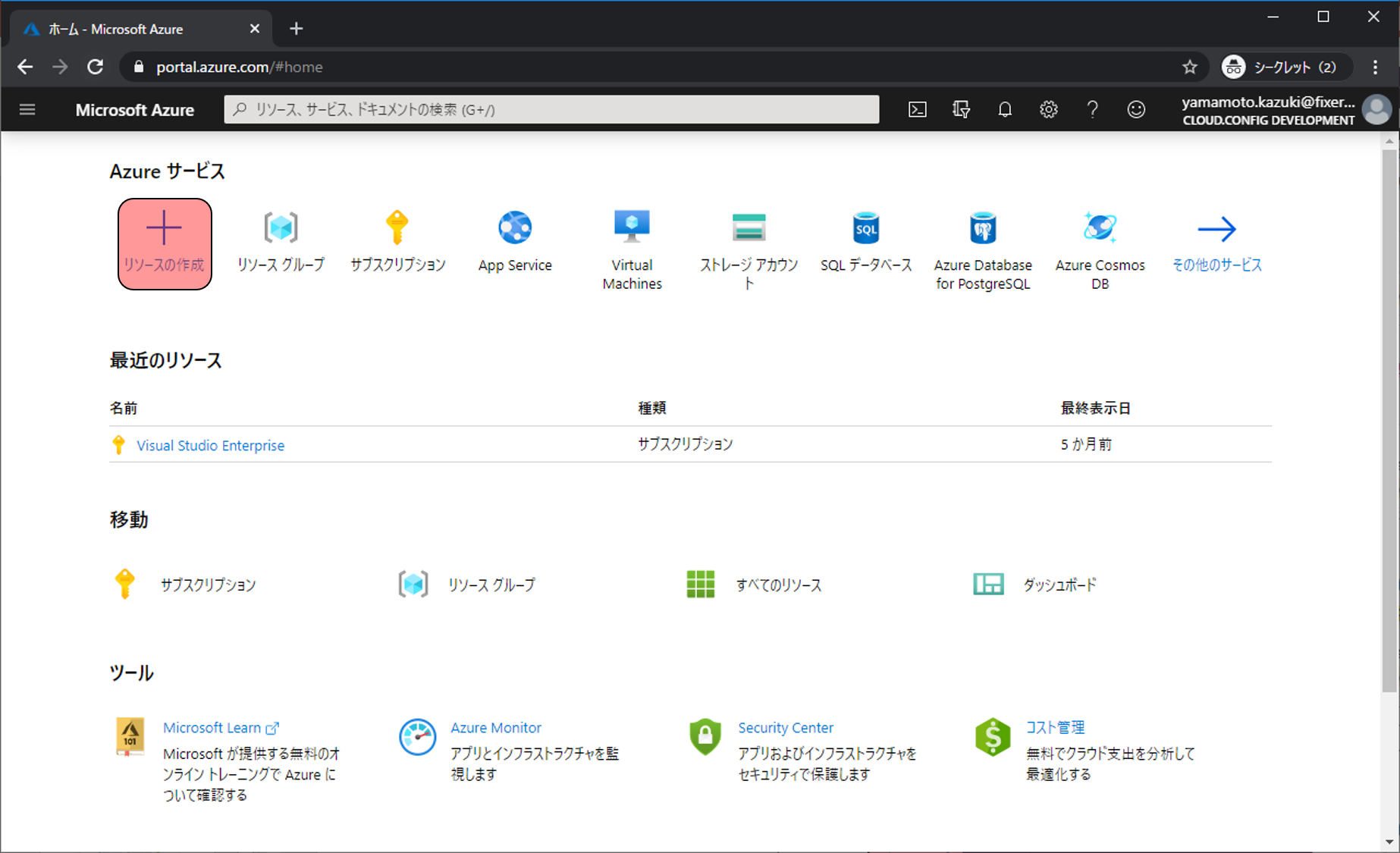
AI + Machine LearningのMachine Learningをクリックします。
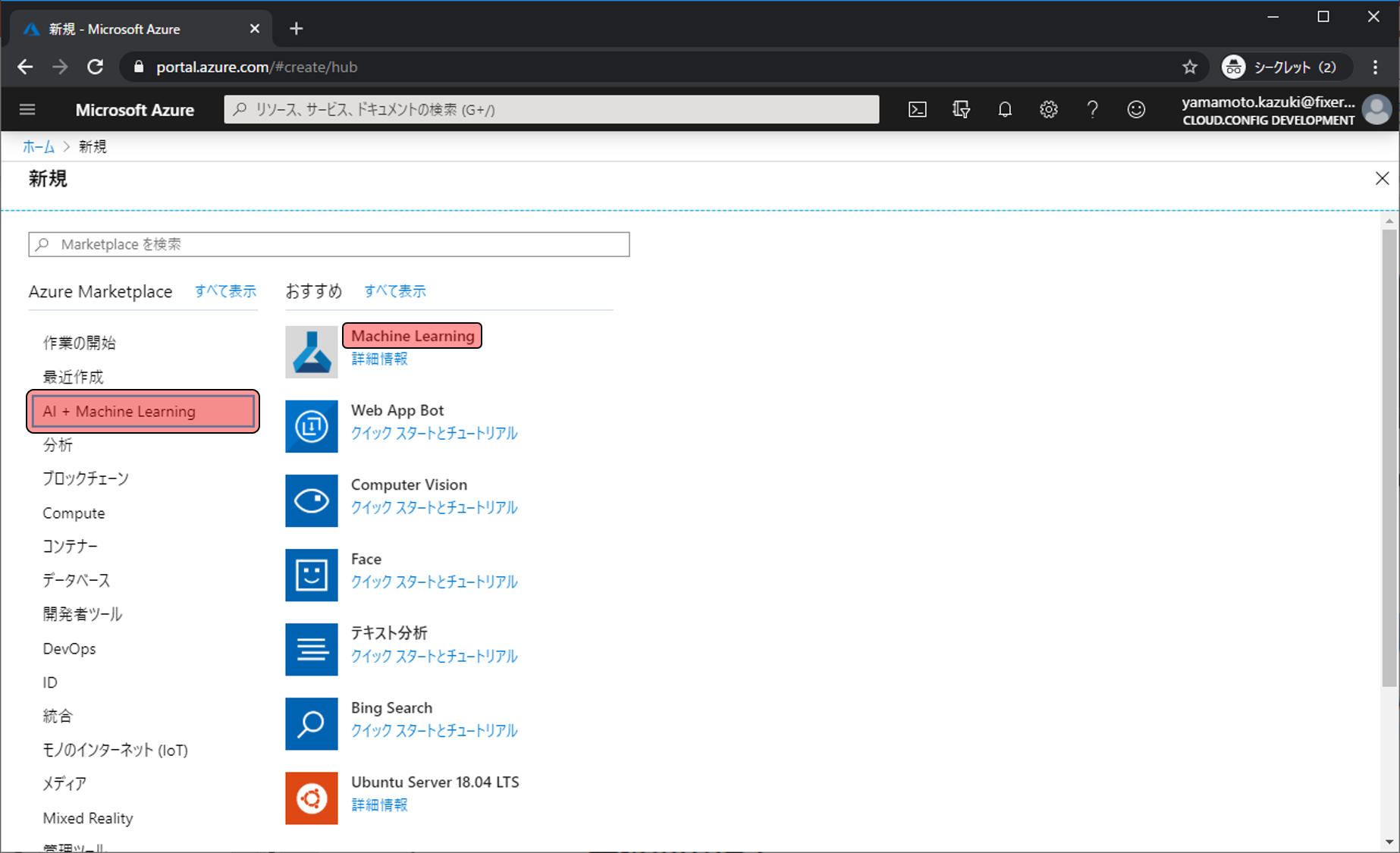
作成するリソースの名前等を決めます。各項目に入力・選択を行い、確認および作成をクリックします。
- ワークスペース名: 任意の文字列 → 作成するリソースに付ける名前
- サブスクリプション: 課金が紐づくサブスクリプションの選択
- リソースグループ: 新規作成、任意の文字列 → これから作成するリソース群を格納する場所の名前
- 場所: 任意のリージョン → リージョンによって料金が微妙に異なります。また、現在地から遠い場所を利用するとアクセスも遅くなるので注意。料金の詳細はこちら
- ワークスペースのエディション: Enterprise → BasicとEnterpriseを選べますが、エディションによって利用できる機能や料金が異なる。詳しい違いはこちら
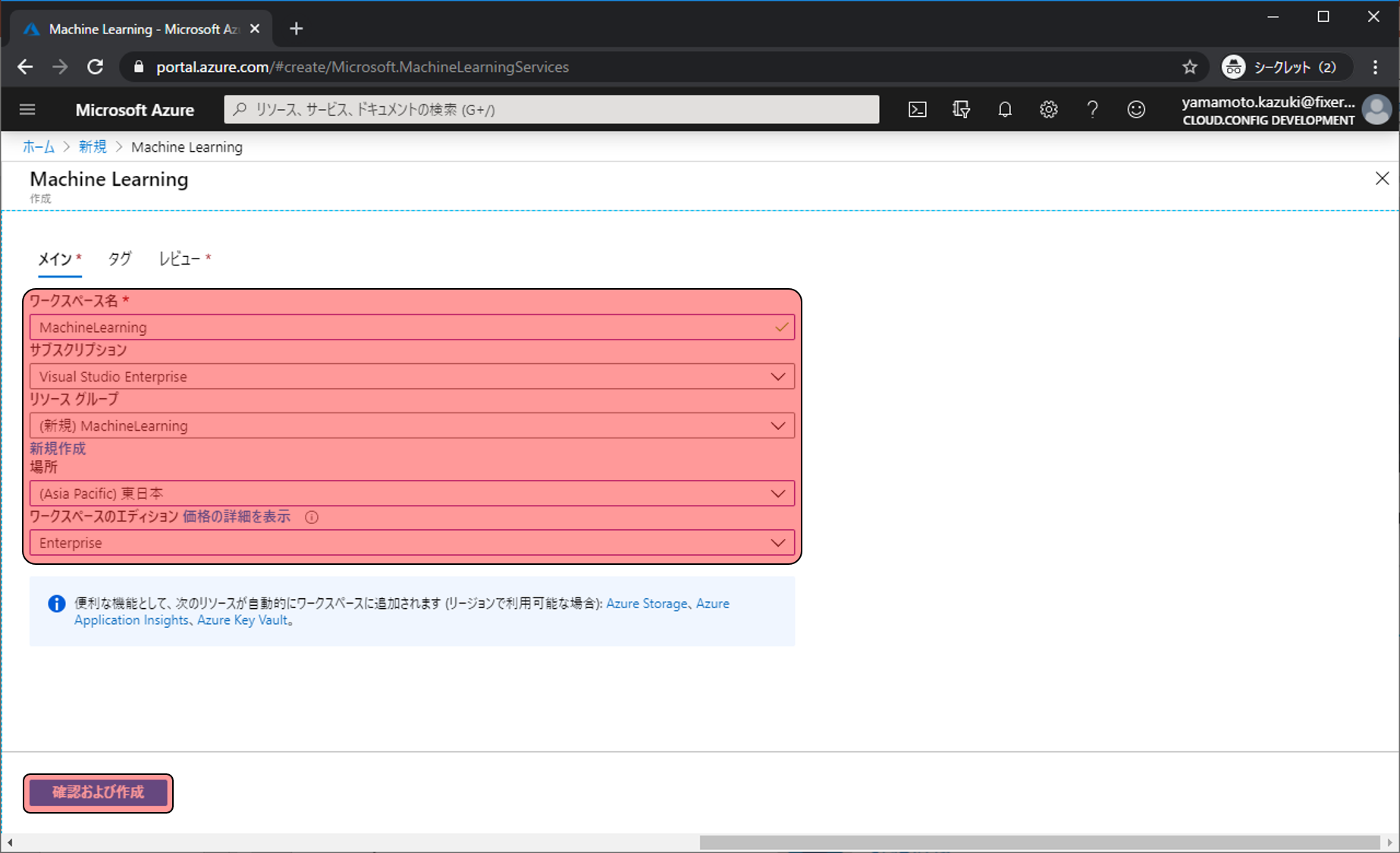
確認画面が表示されます。作成をクリックします。
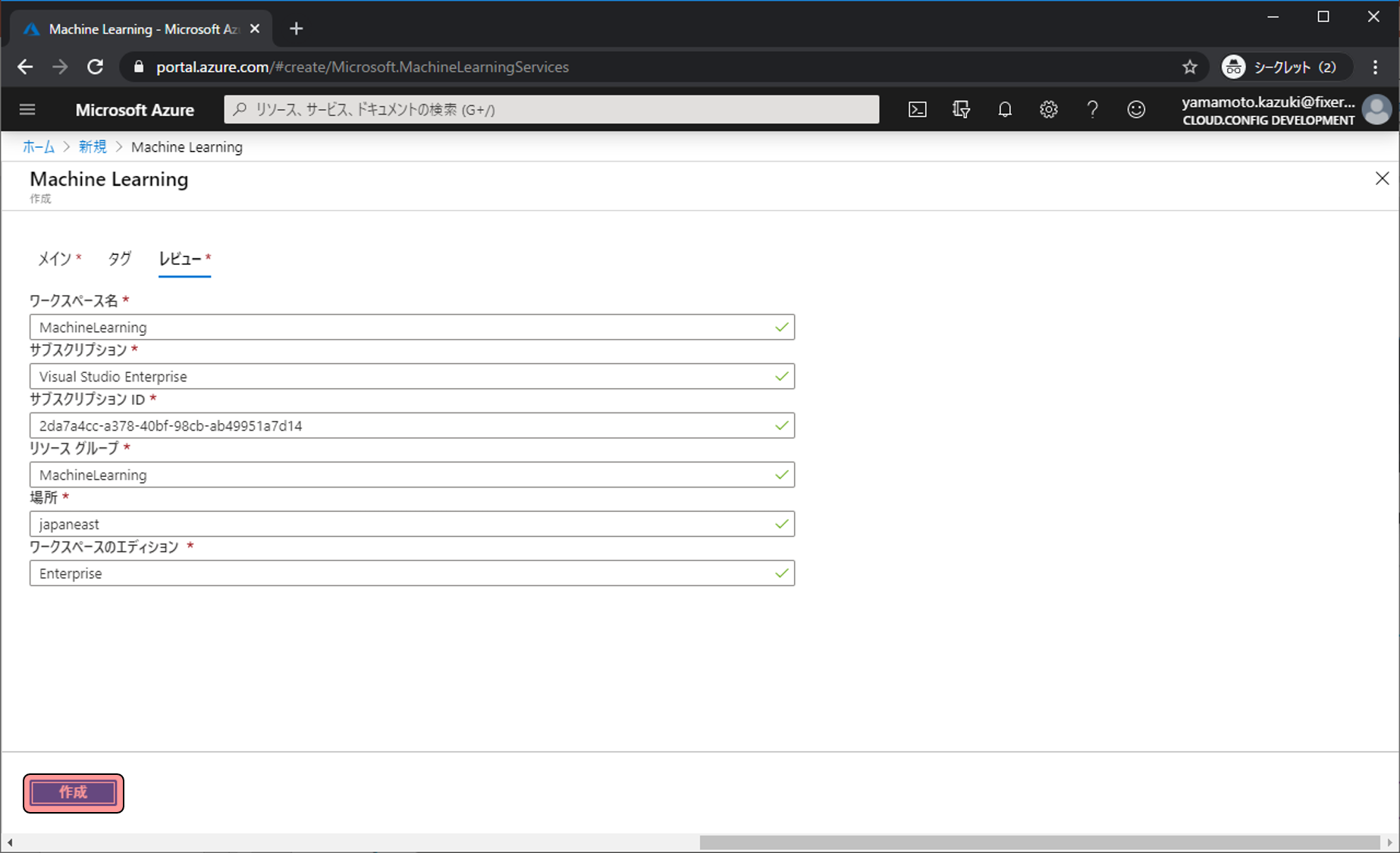
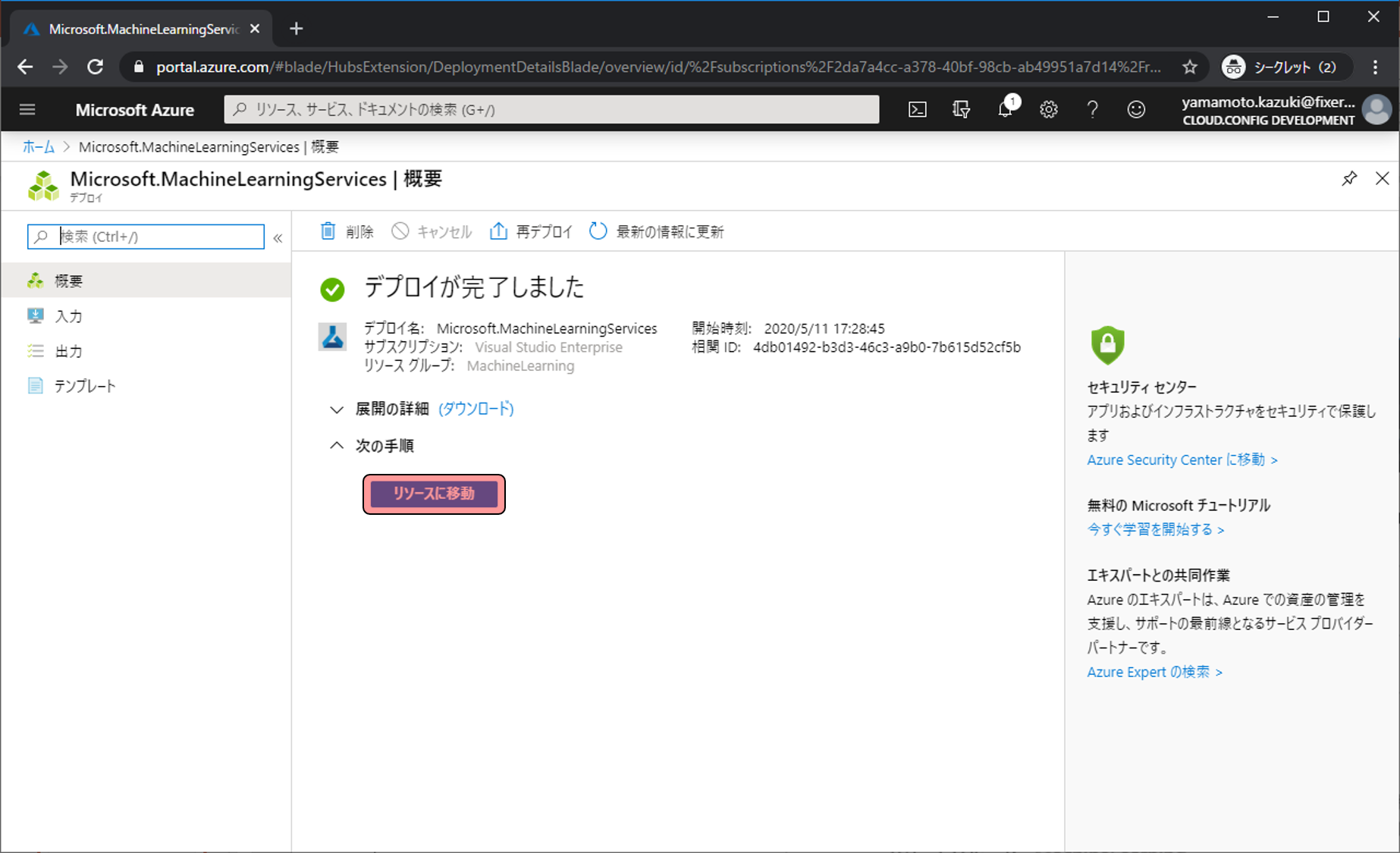
少しすると「デプロイが完了しました」と表示され、作成が完了します。作成したAzure Machine Learning Serviceを利用していくのでリソースに移動をクリックします、
学習させるデータの登録
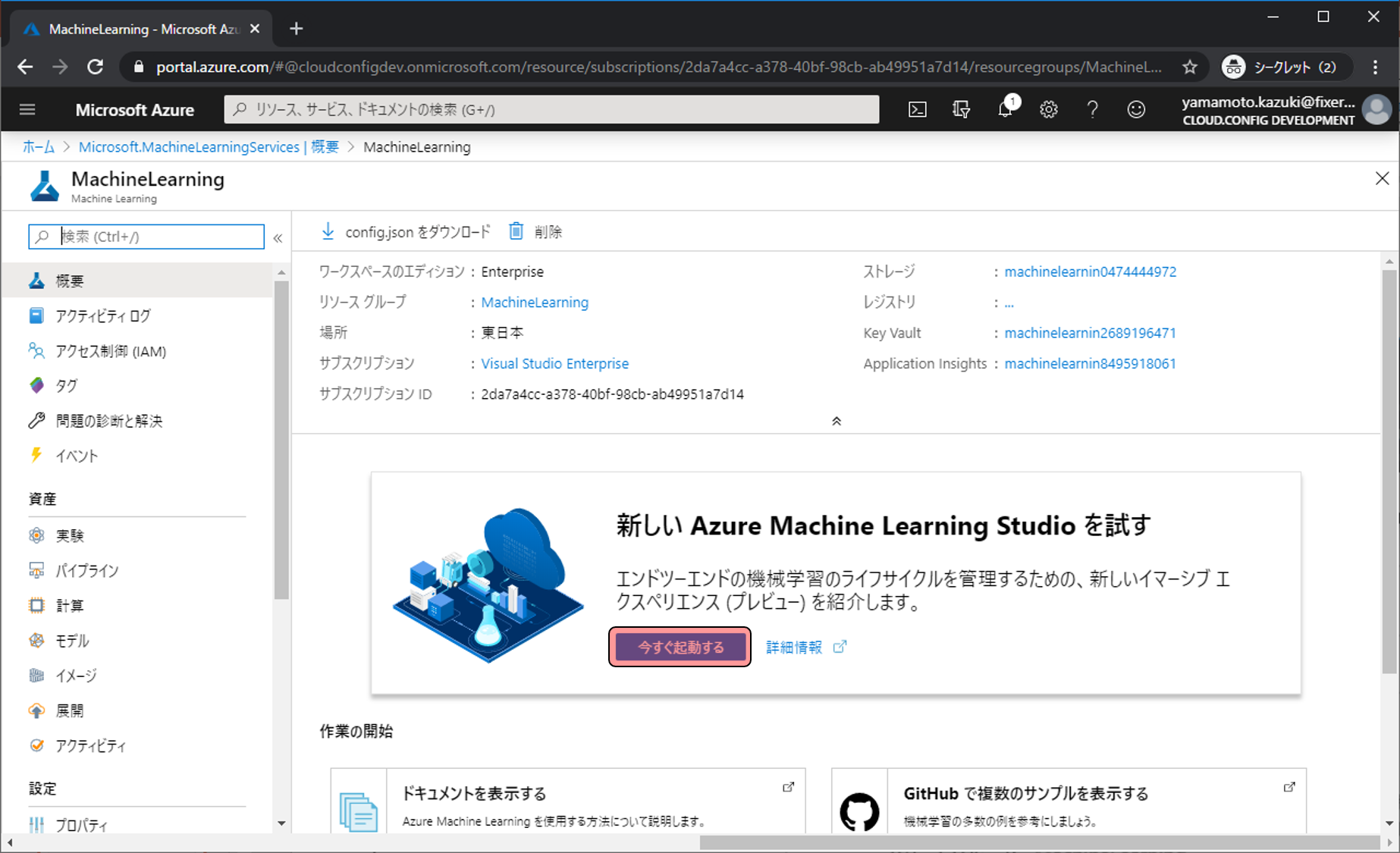
機械学習をしていくためにMachine Learning用のページへ移動します。今すぐ起動するをクリックします。
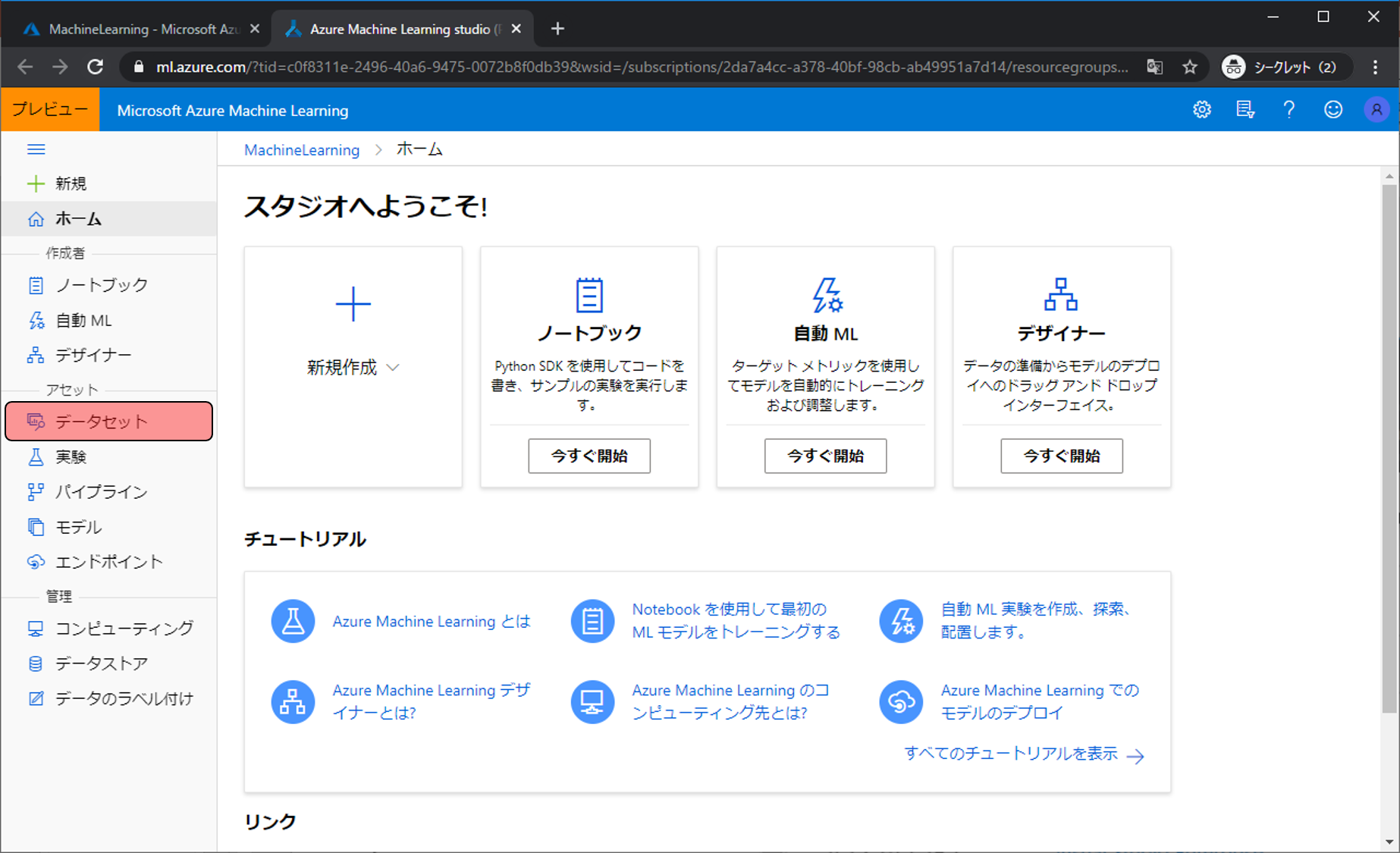
Machine Learning用ホーム画面に移動します。データを登録をするためにデータセットをクリックします。
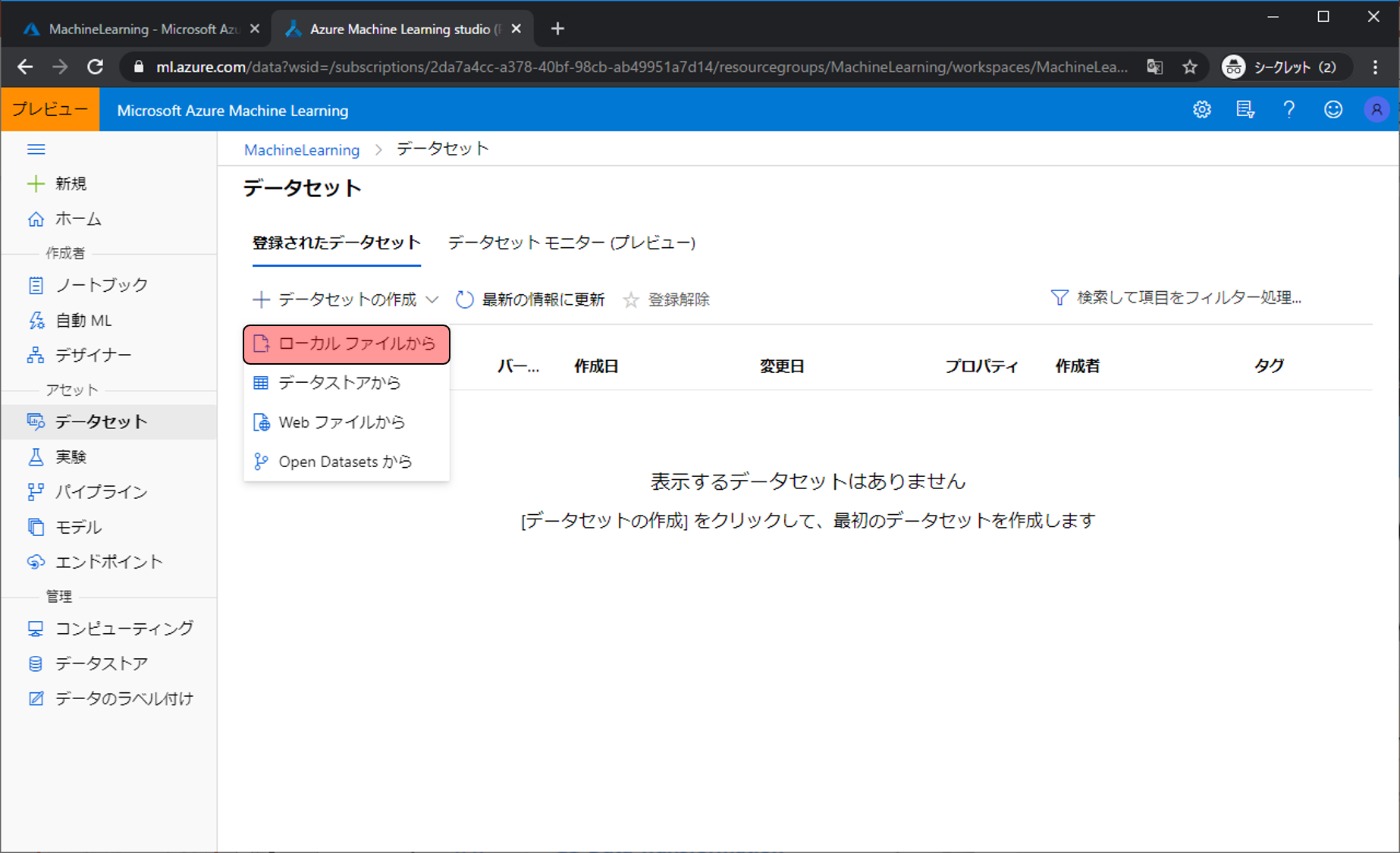
データセットの作成のローカルファイルからをクリックします。
データセットの名前を決めます。名前をWhiteWineにして次へをクリックします。
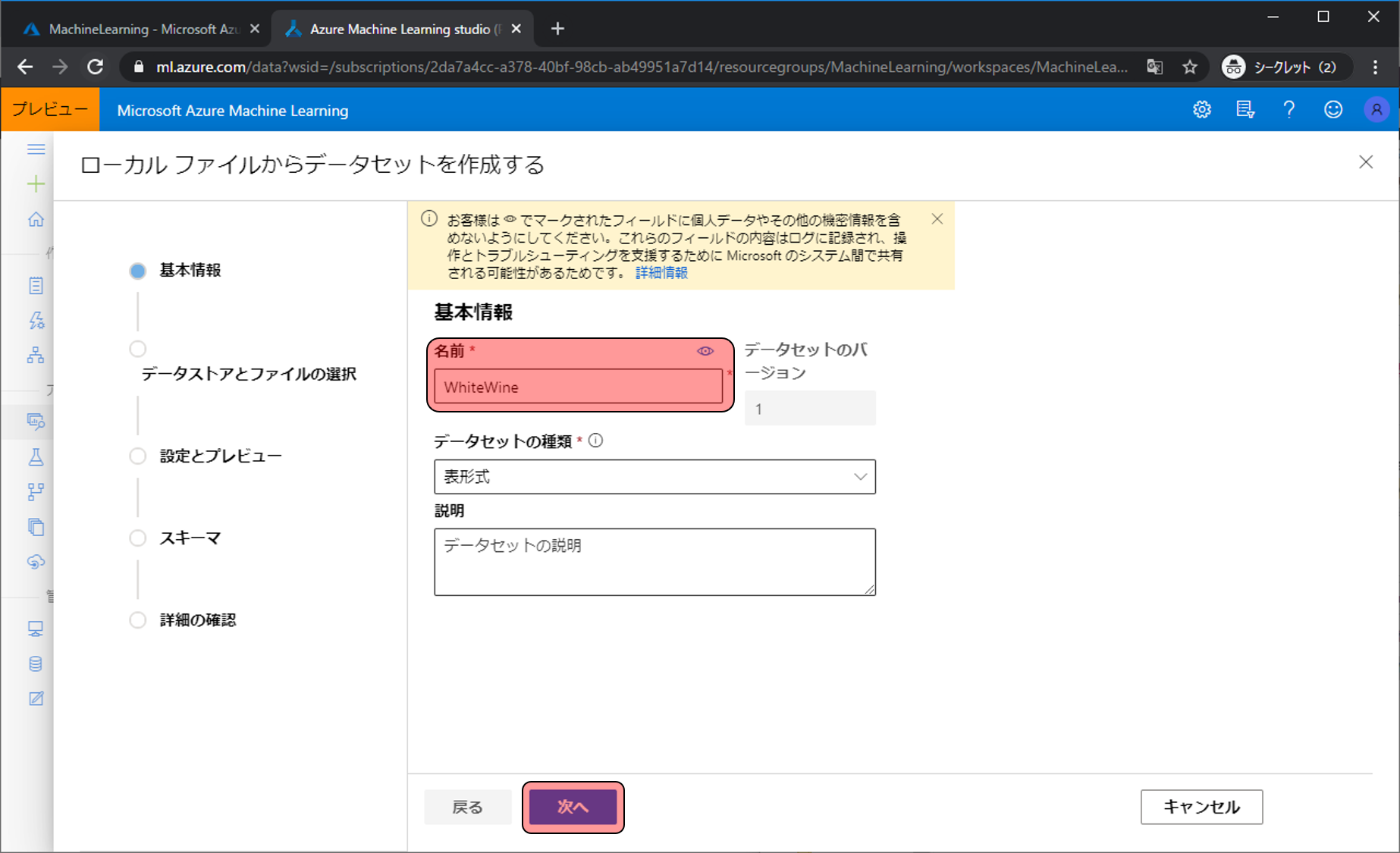
参照をクリックし、最初にダウンロードしたwinequality-white.csvを選択します。その後次へをクリックします。
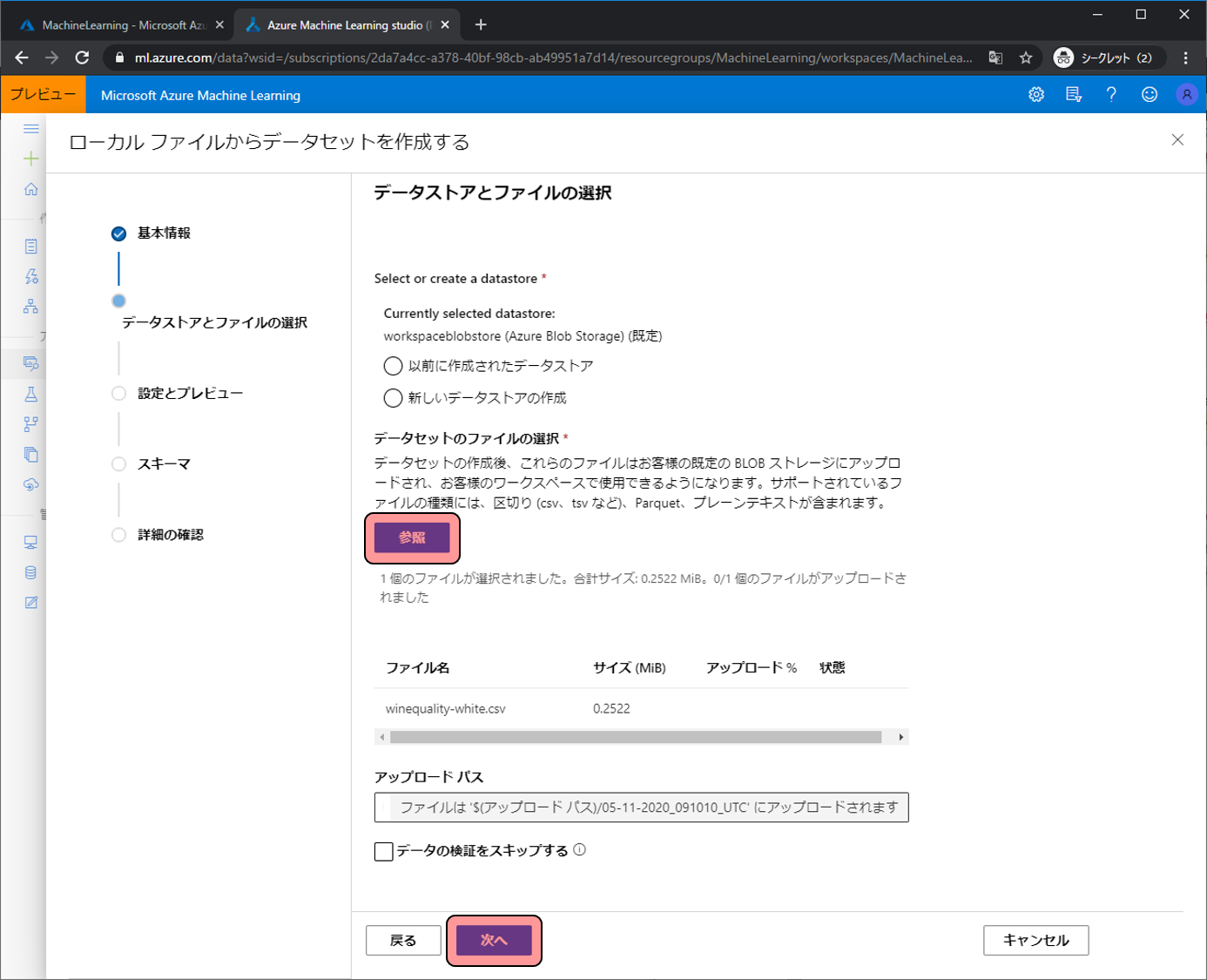
読み取り方法の設定をします。列見出しを最初のファイルのヘッダーを使用するに変更し次へをクリックします。
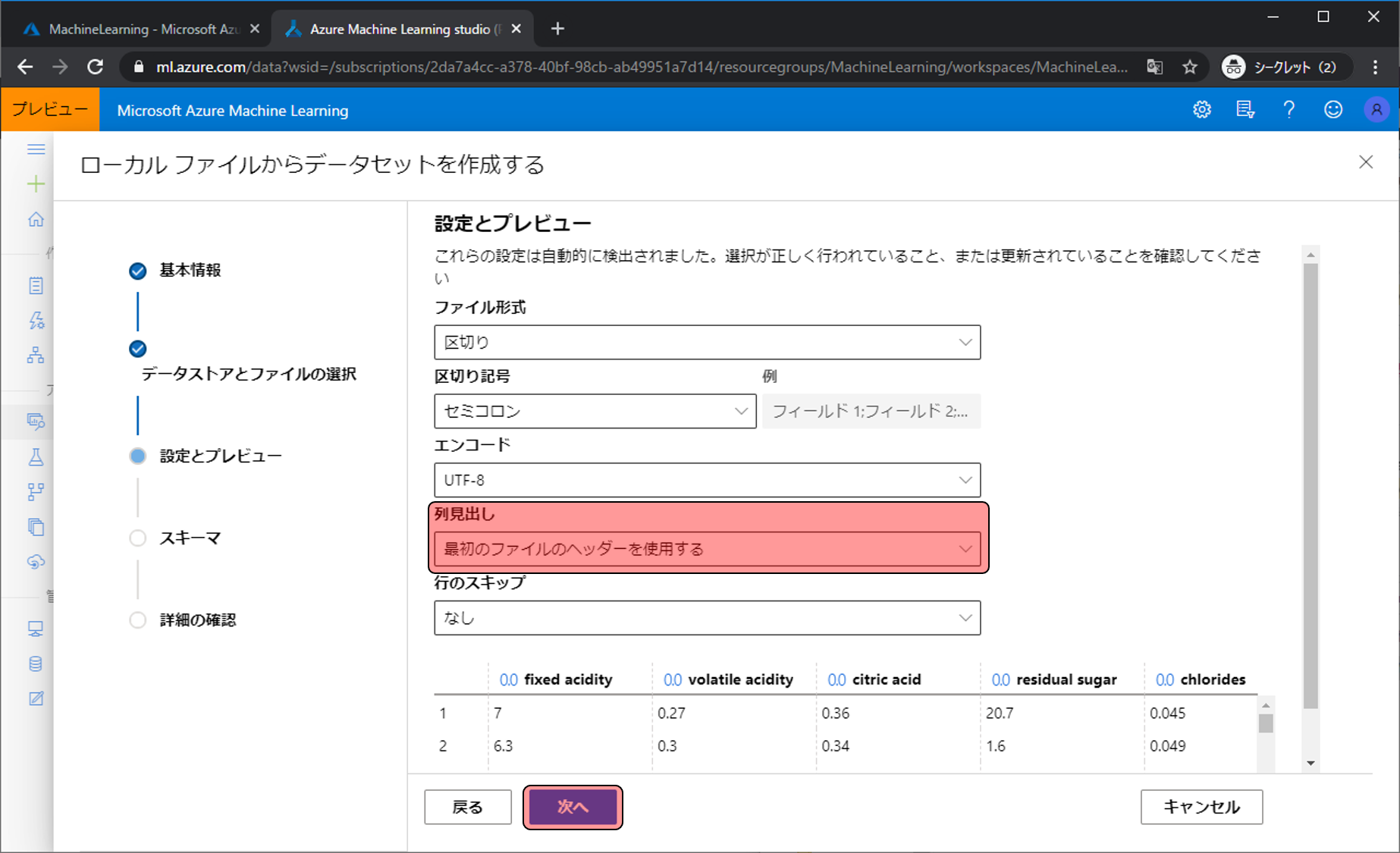
スキーマの設定画面が表示されますが、変更する項目はないのでそのまま次へをクリックします。
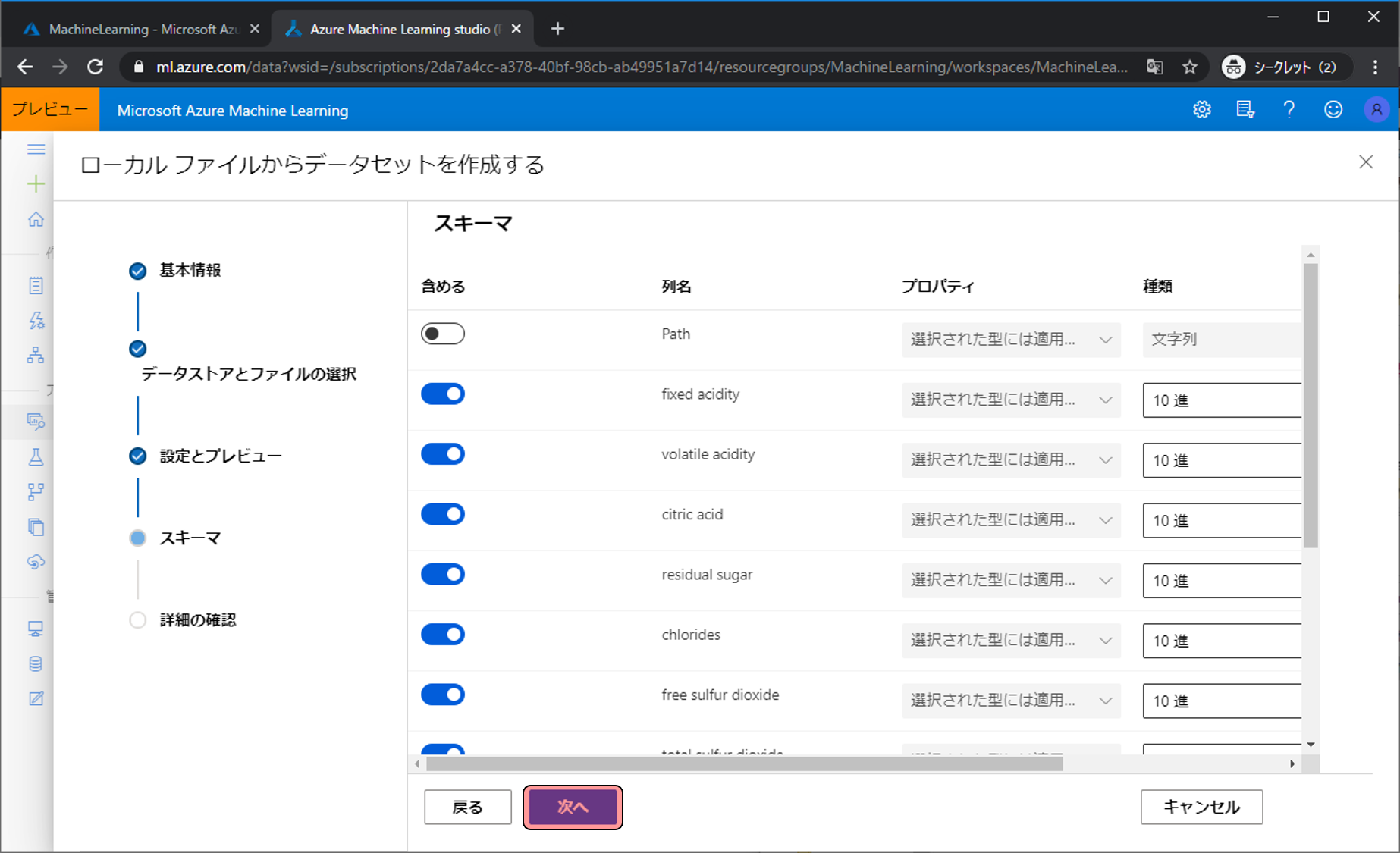
確認画面が表示されます。作成をクリックします。
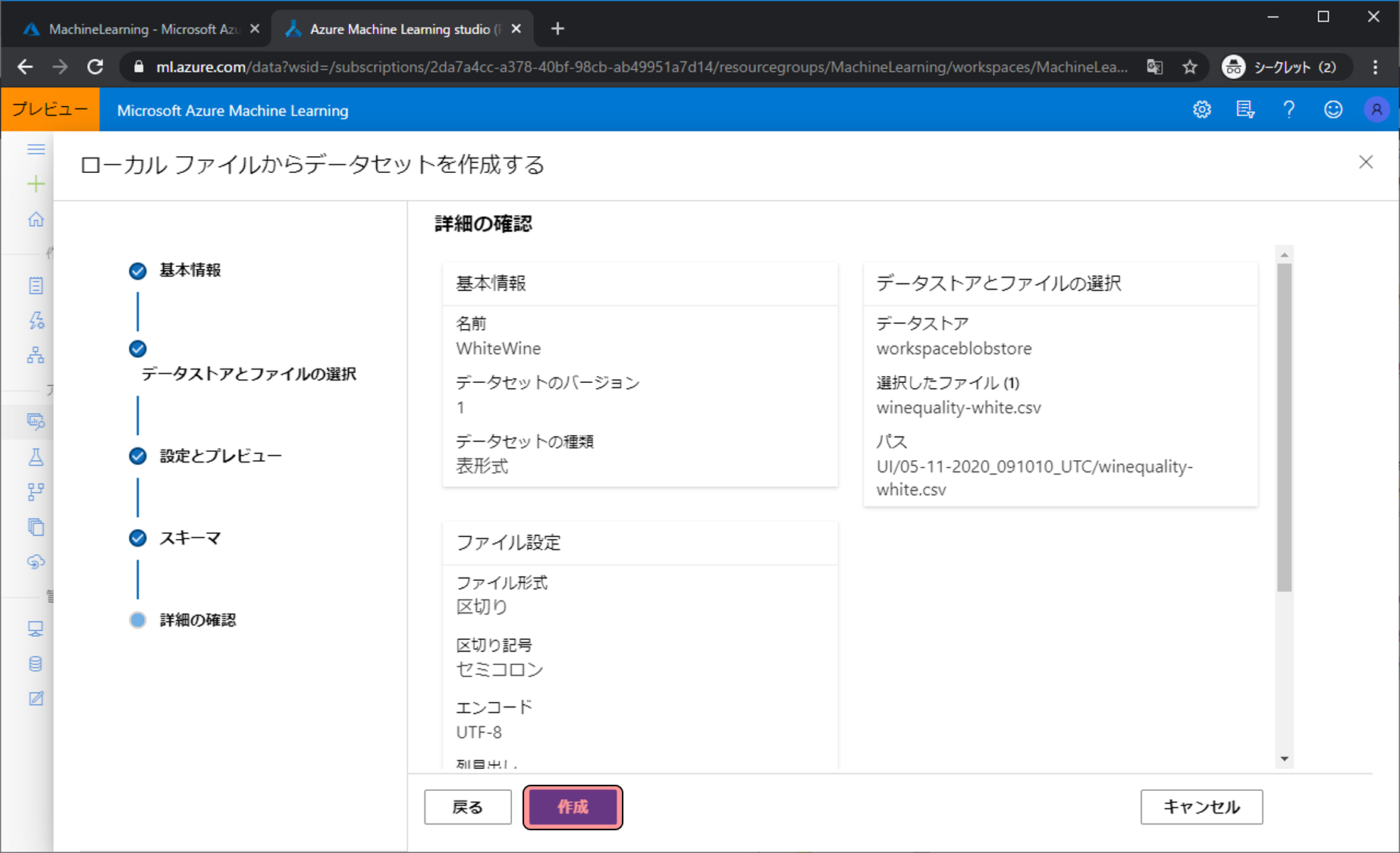
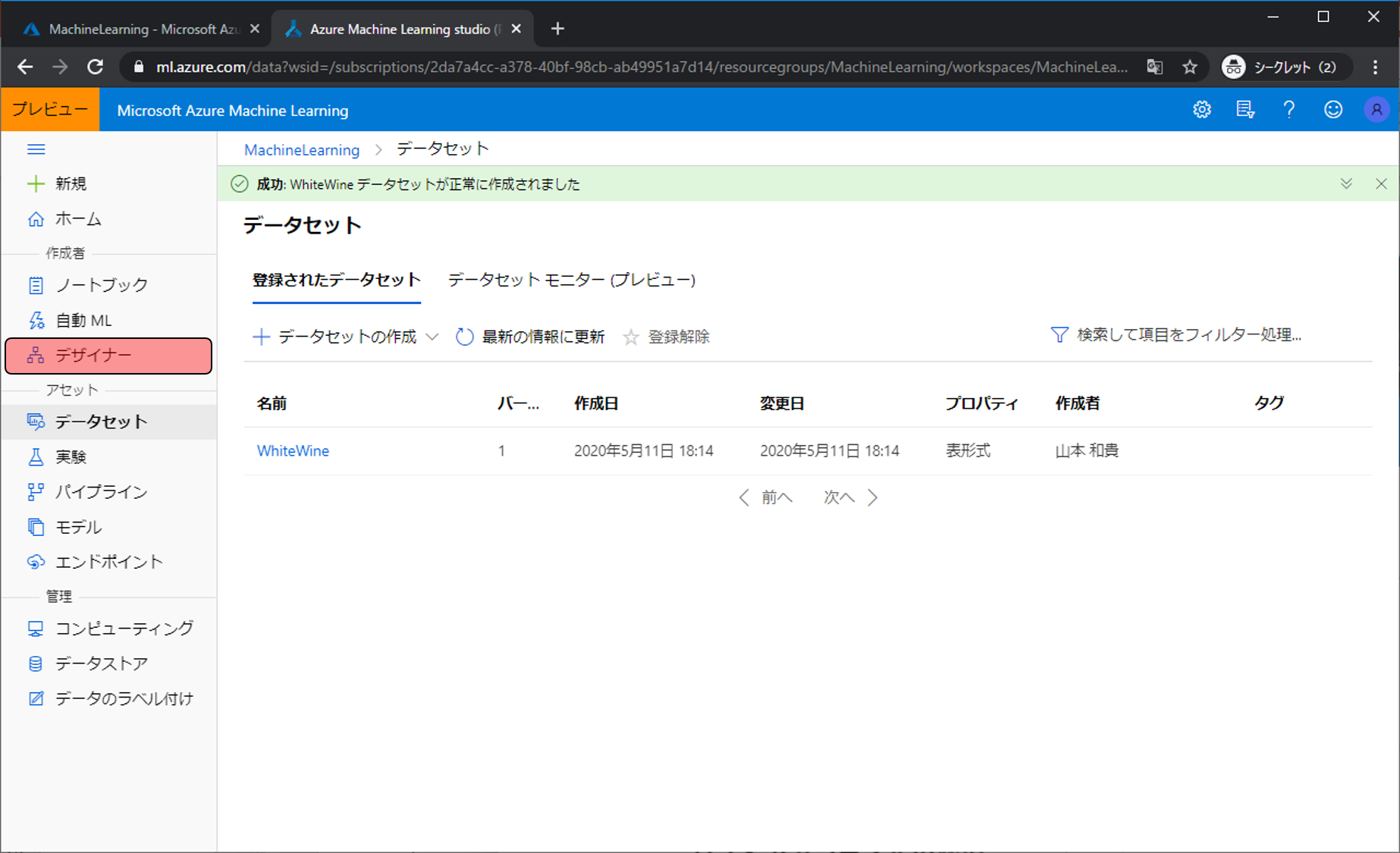
データの登録が完了しました。次は登録したデータをつかって機械学習をしていくためデザイナーをクリックします。
機械学習の実施
ここからはデザイナーでモジュールを組み合わせて機械学習を実際に行っていきます。事細かな説明をするとあまりに長くなってしまうので、今回はどうやって組み立てるのかについての解説を重点的に行い、次回以降細な解説をしていきます。
使いやすい事前登録済みモジュールをクリックします。
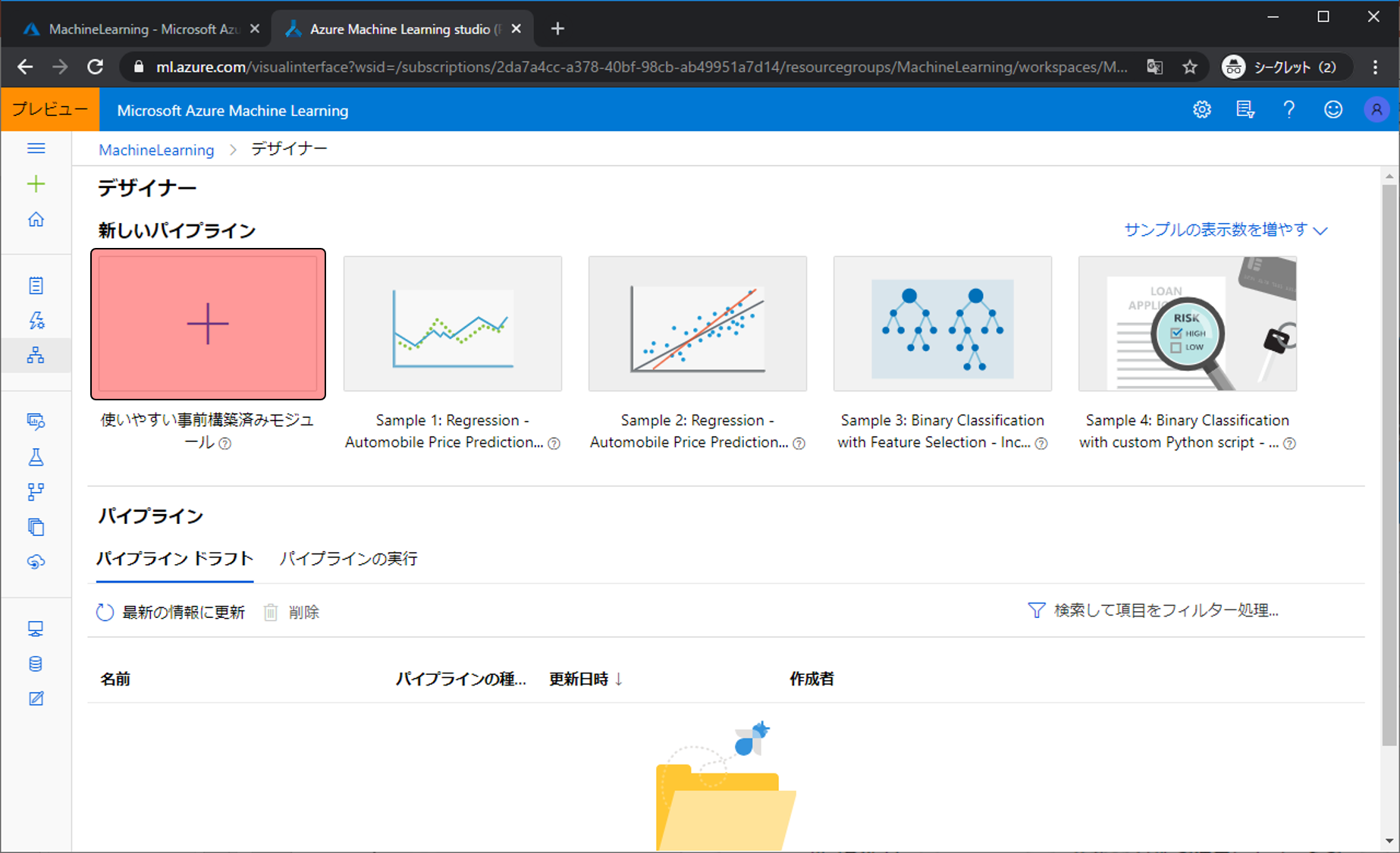
実際に機械学習の処理をするためVMを用意します。コンピューティング先を選択をクリックします。
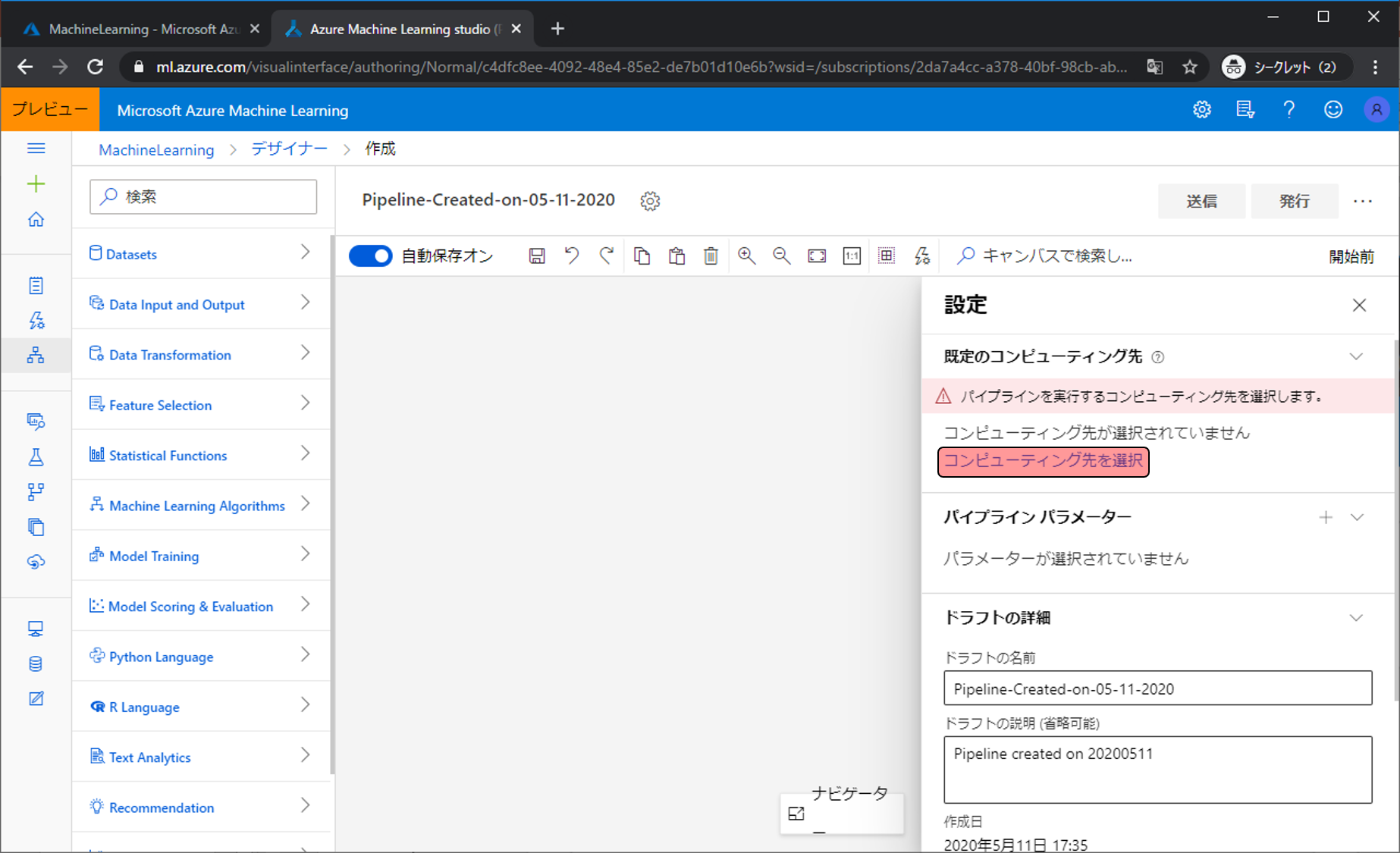
新規作成をクリックして、新しいコンピューティング先の名前にわかりやすい名前(今回はDesignerVM)を入力し、保存をクリックします。
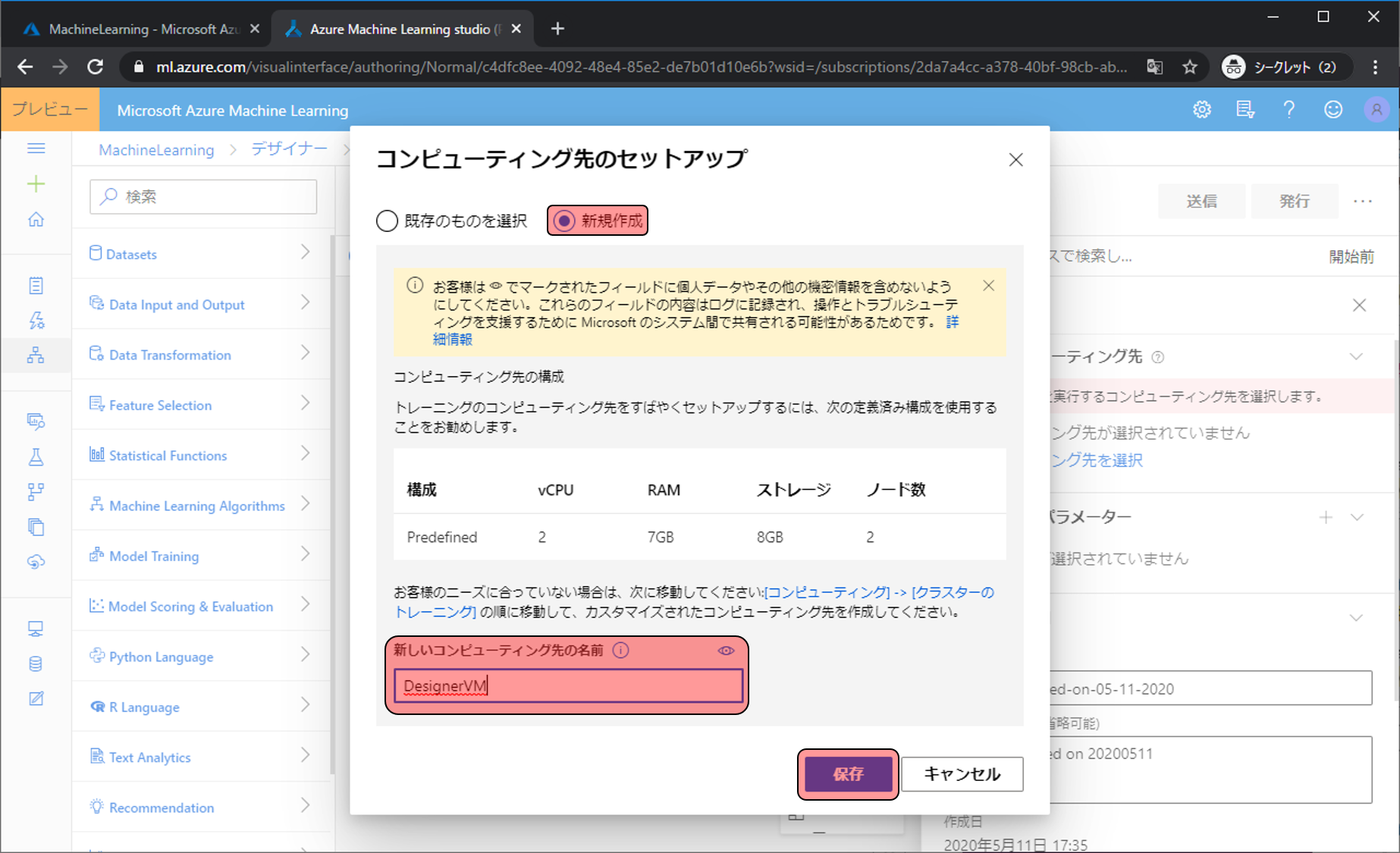
作成したVMを選択し、保存をクリックします。
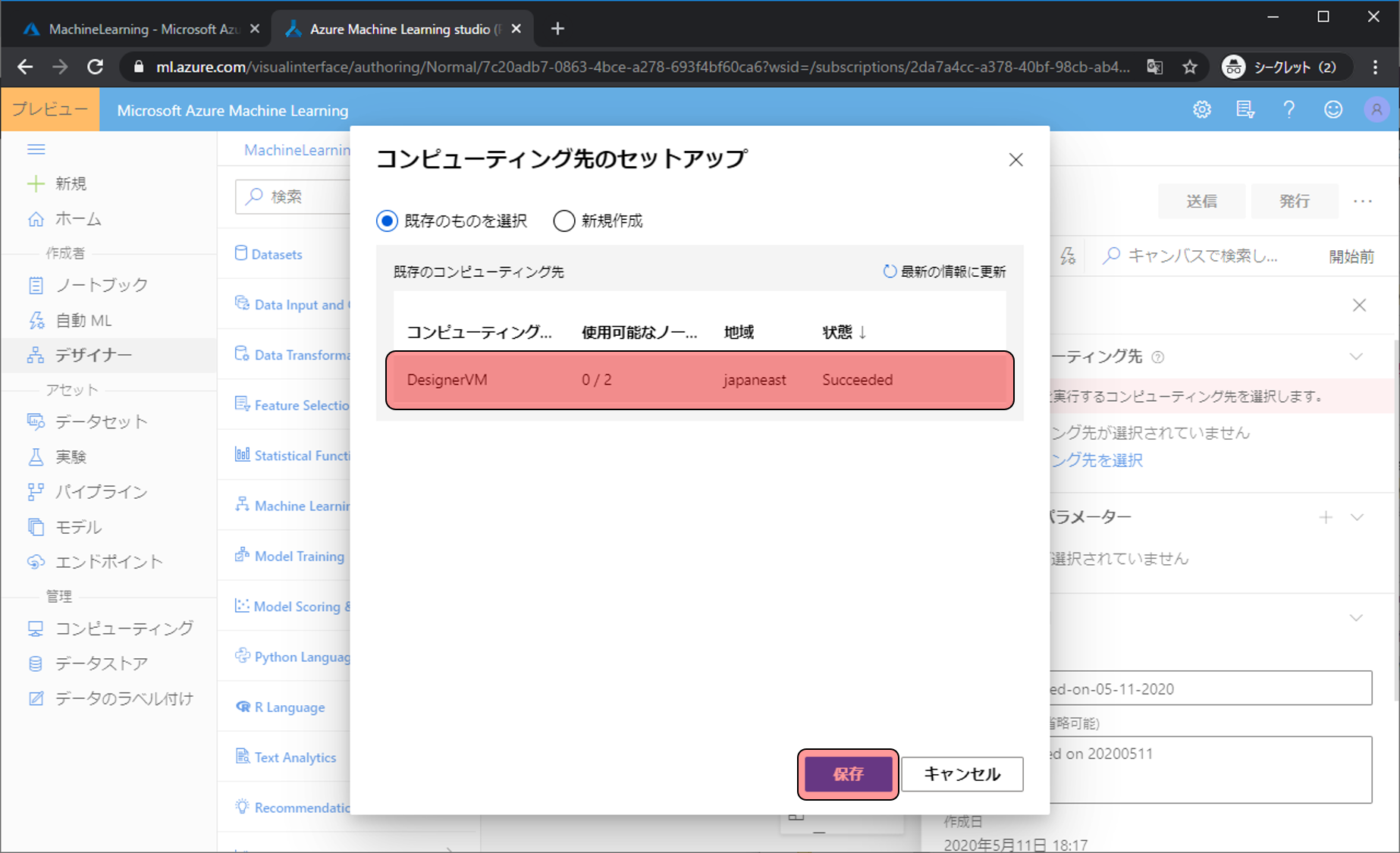
VMを設定できたので×をクリックします。
では、モジュールを配置していきます。
まずは学習するデータを配置します。Datasetsをクリックすると先程アップロードしたWhiteWineがあるので、それをドラックアンドドロップして真ん中のスペースに置きます。
各モジュールには下や上、または両方にポッチが付いており、下側のポッチは出力、上側のポッチは入力となります。WhiteWineモジュールは下にポッチがあり、WhiteWineの4898件のデータを出力しています。
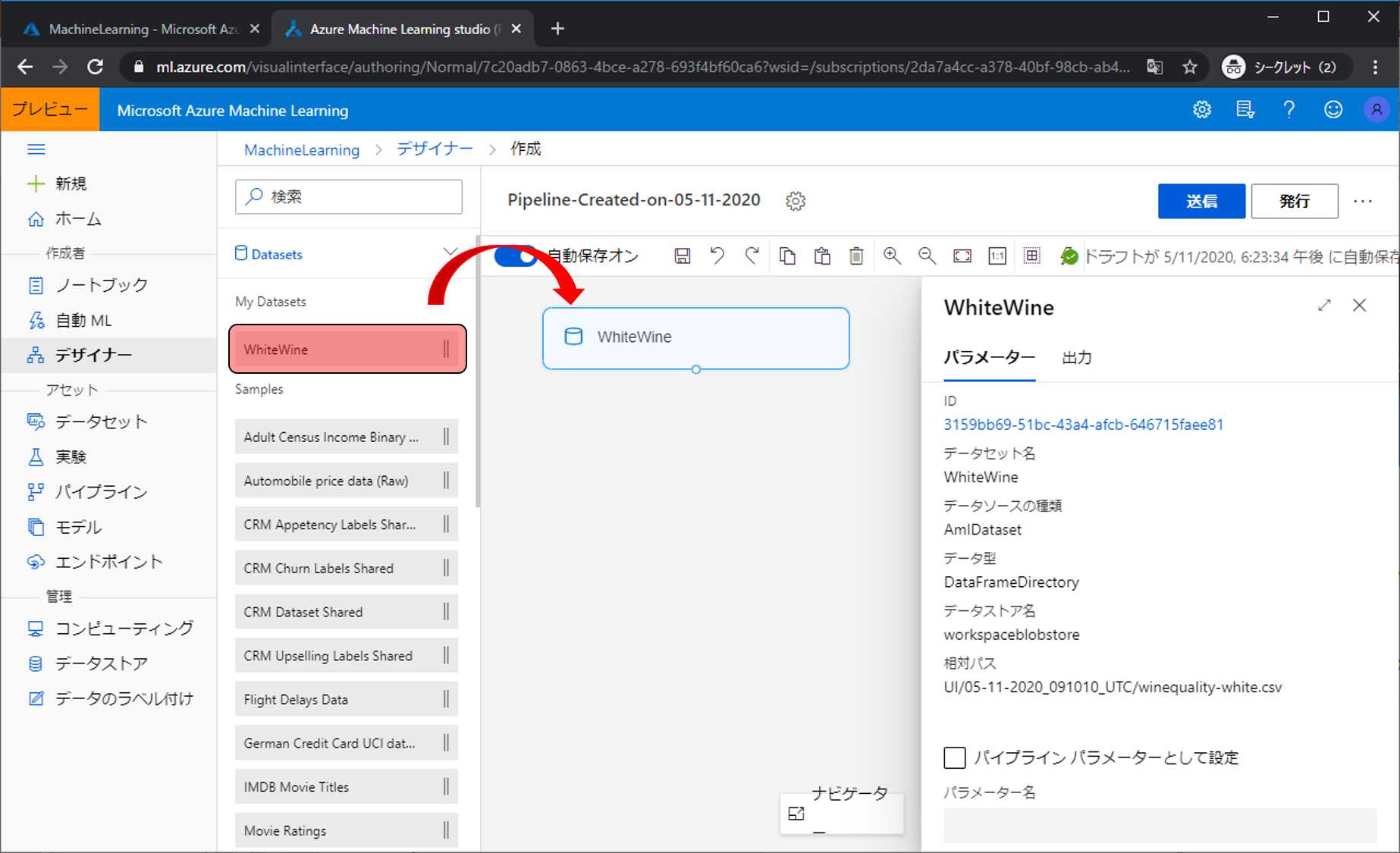
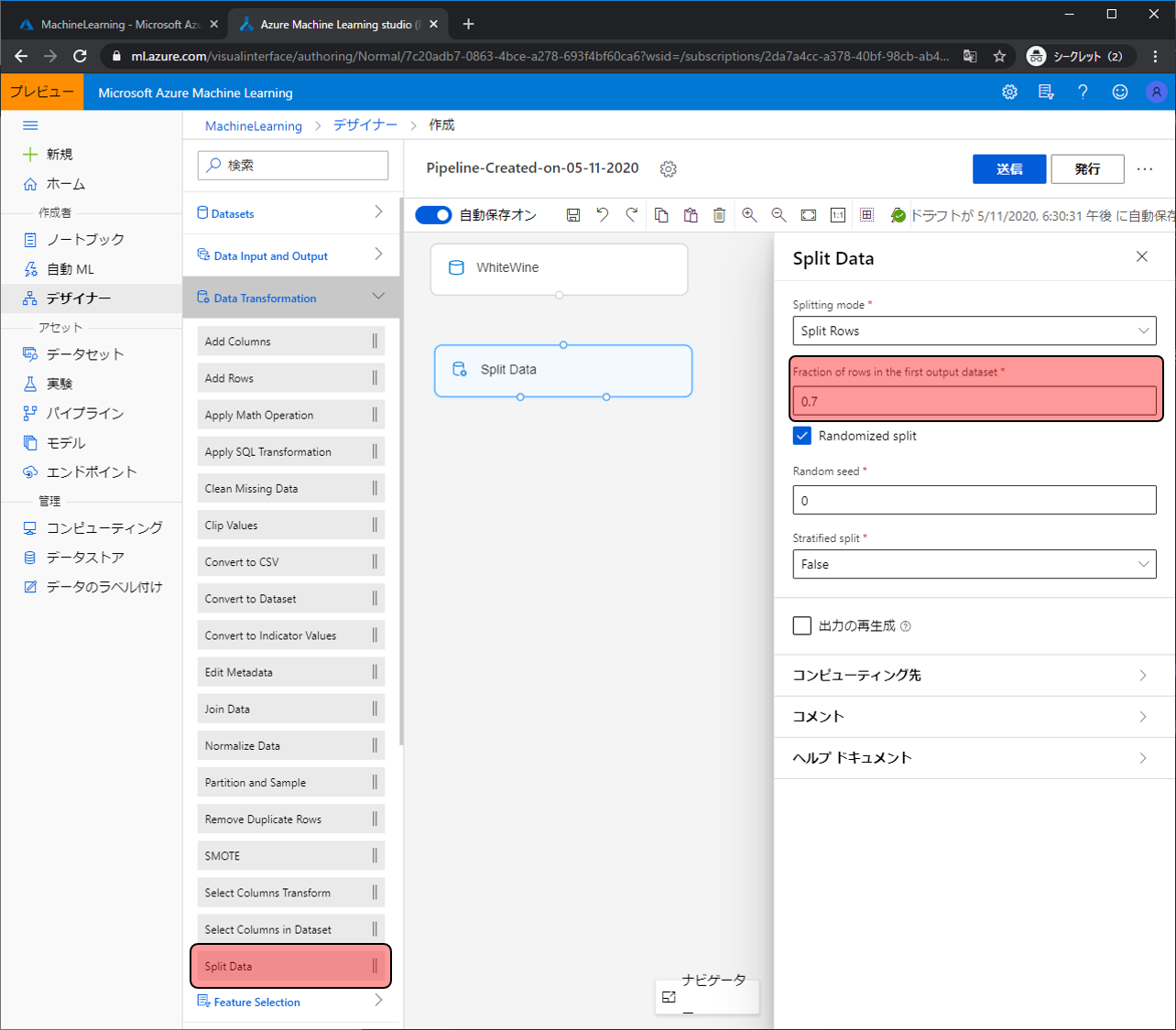
WhiteWineの4898件のデータを学習用データと評価用データに分割するモジュールを配置します。Data Transformationをクリックし、Split Dataを配置します。配置すると右側に設定ができる項目が表示されます。モジュールによって様々な設定できるのですが、今回は分割する割合だけを変更します。Fraction of rows in the first output datasetを0.7にします。
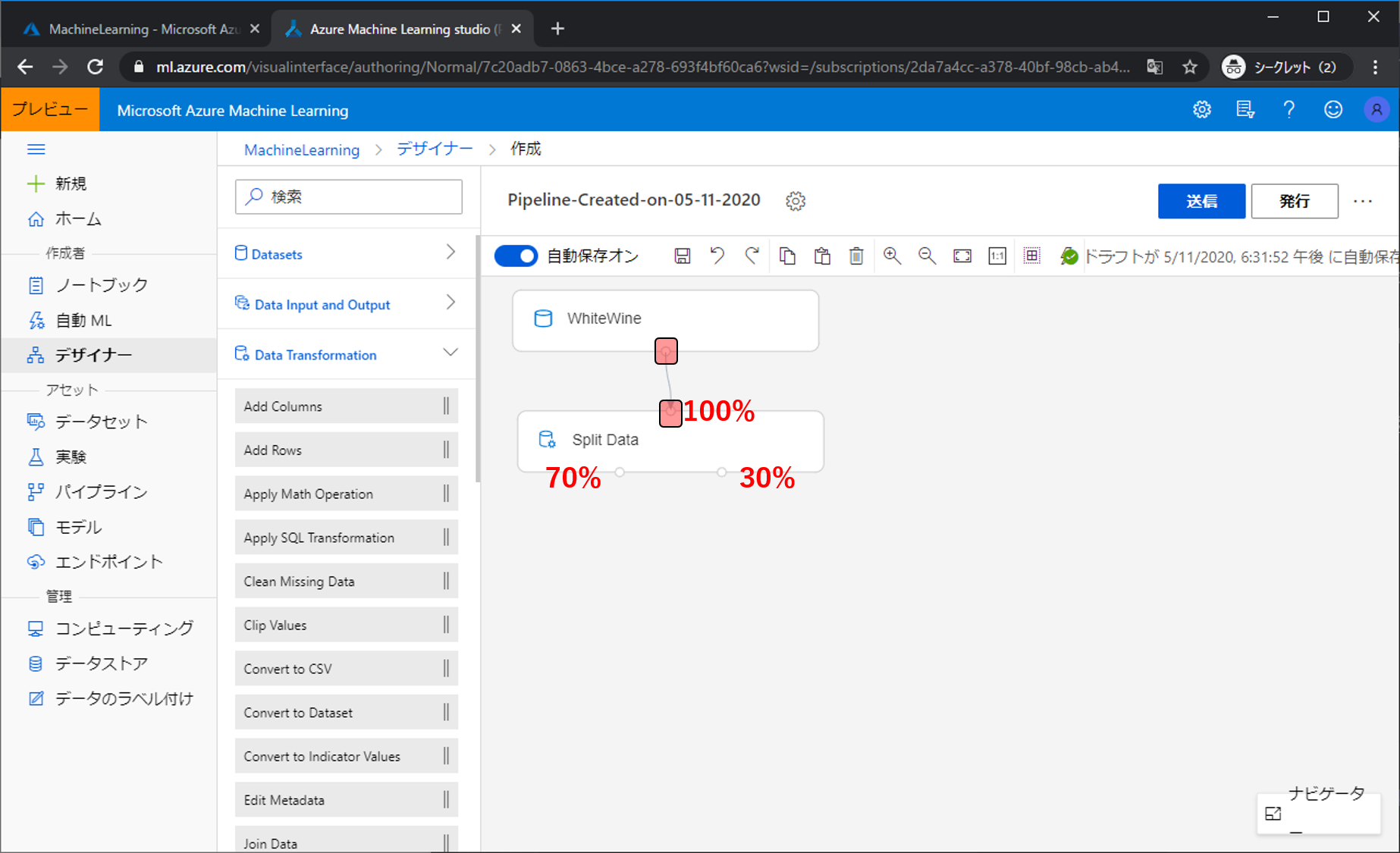
WhiteWineモジュールの出力をSplit Dataの入力に入れます。WhiteWineモジュールの下の出力ポッチをクリックしたままSplit Dataの上の入力ポッチに繋げます。すると、WhiteWineのデータがSplit Dataモジュールに流れ、WhiteWineのデータ(4898件)のうち、Split Dataモジュールの左下ポッチから70%(3429件)、右下ポッチから30%(1469件)に分けたWhiteWineのデータが出力されます。
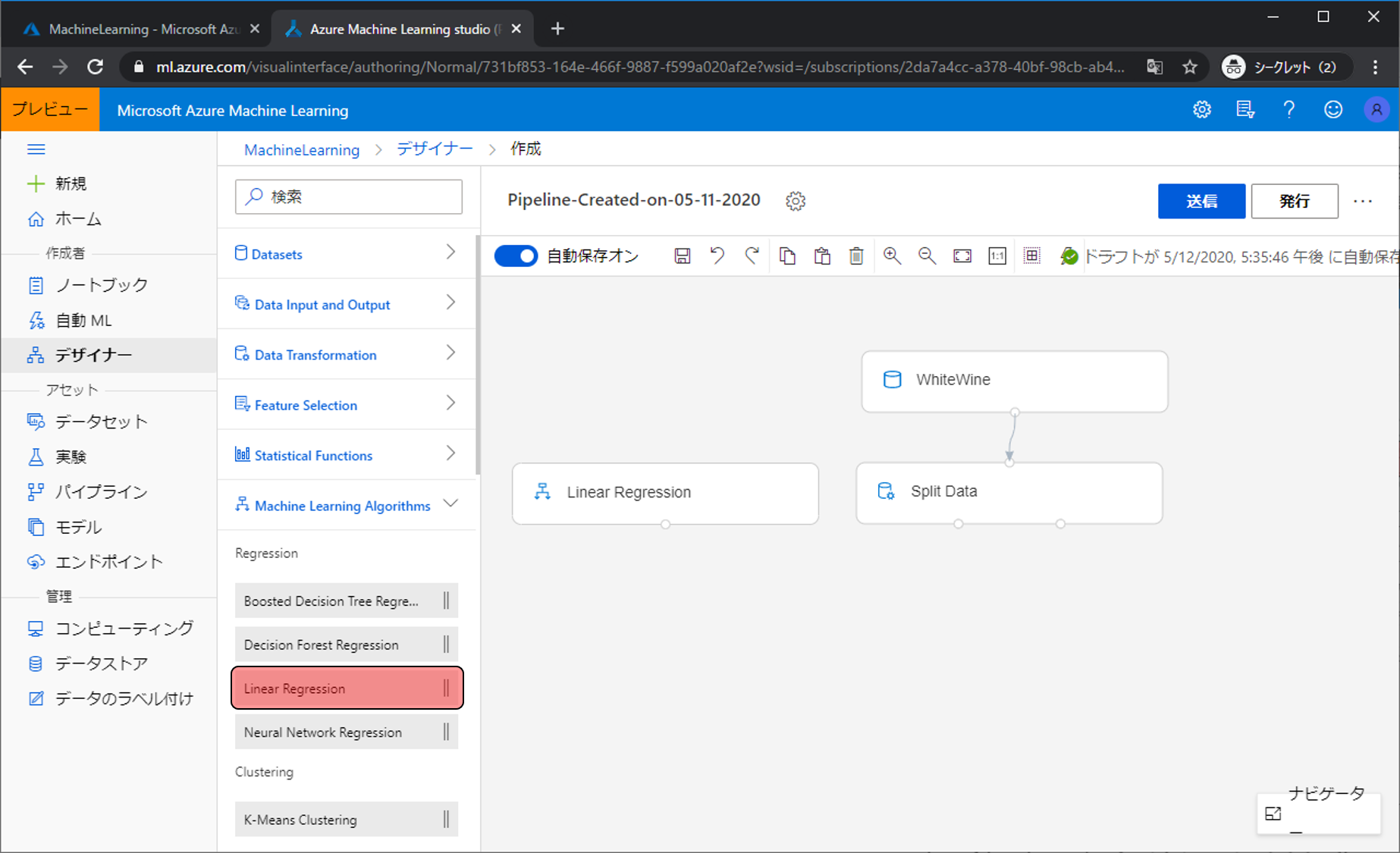
次にアルゴリズムを決めます。今回は評価の数値を予測するので、わかりやすい線形回帰を利用します。Machine Learning Algorithmsをクリックし、Linear Regressionを配置します。
アルゴリズムと学習用データを混ぜて予測モデルを作ります。Model TrainingをクリックしTrain Modelを配置、アルゴリズムを右上の入力ポッチに学習用データを左上の入力ポッチに繋げます。その後、予測モデルでなにを予測させるのか設定するためにLabel columnの列の編集をクリックします。
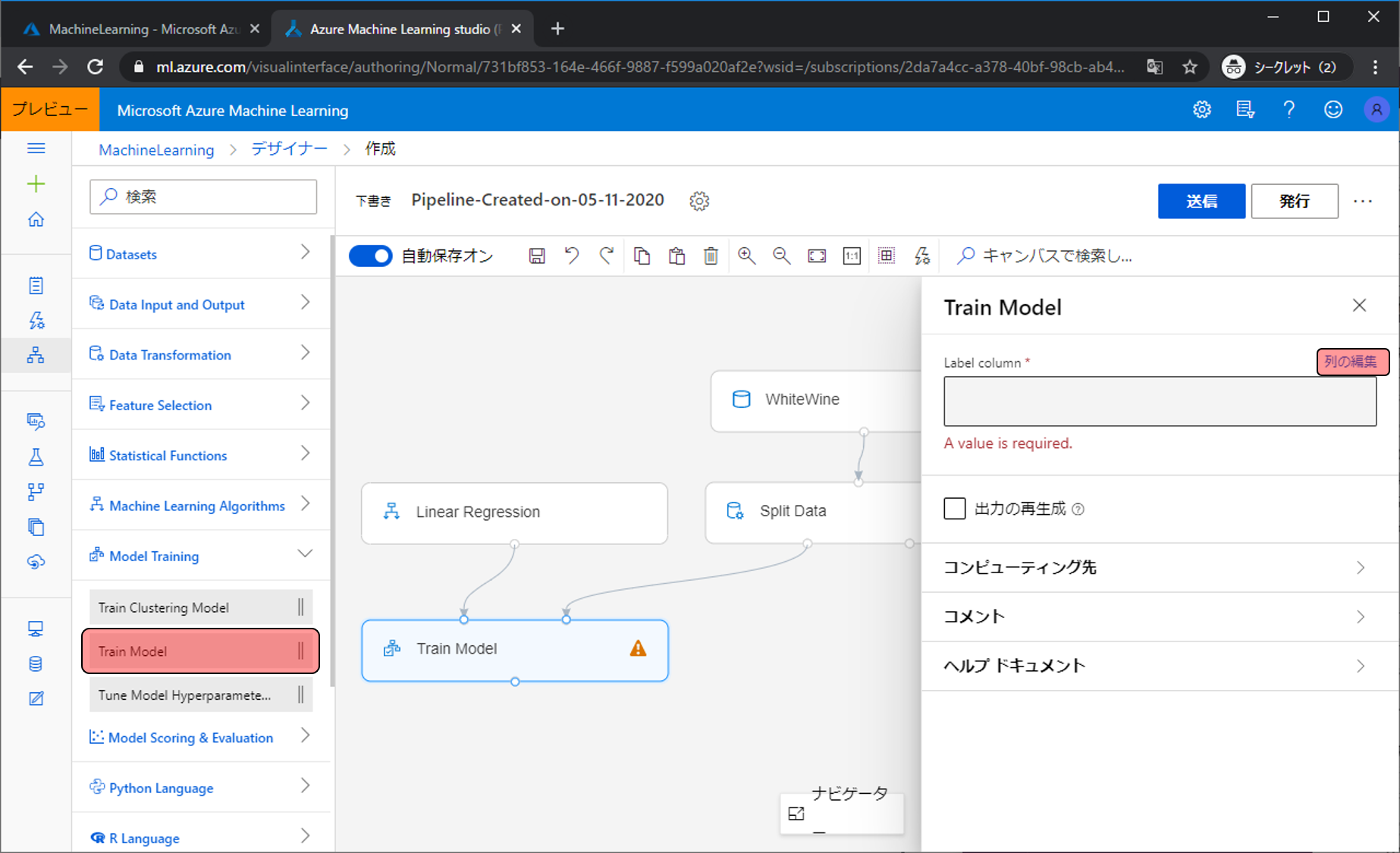
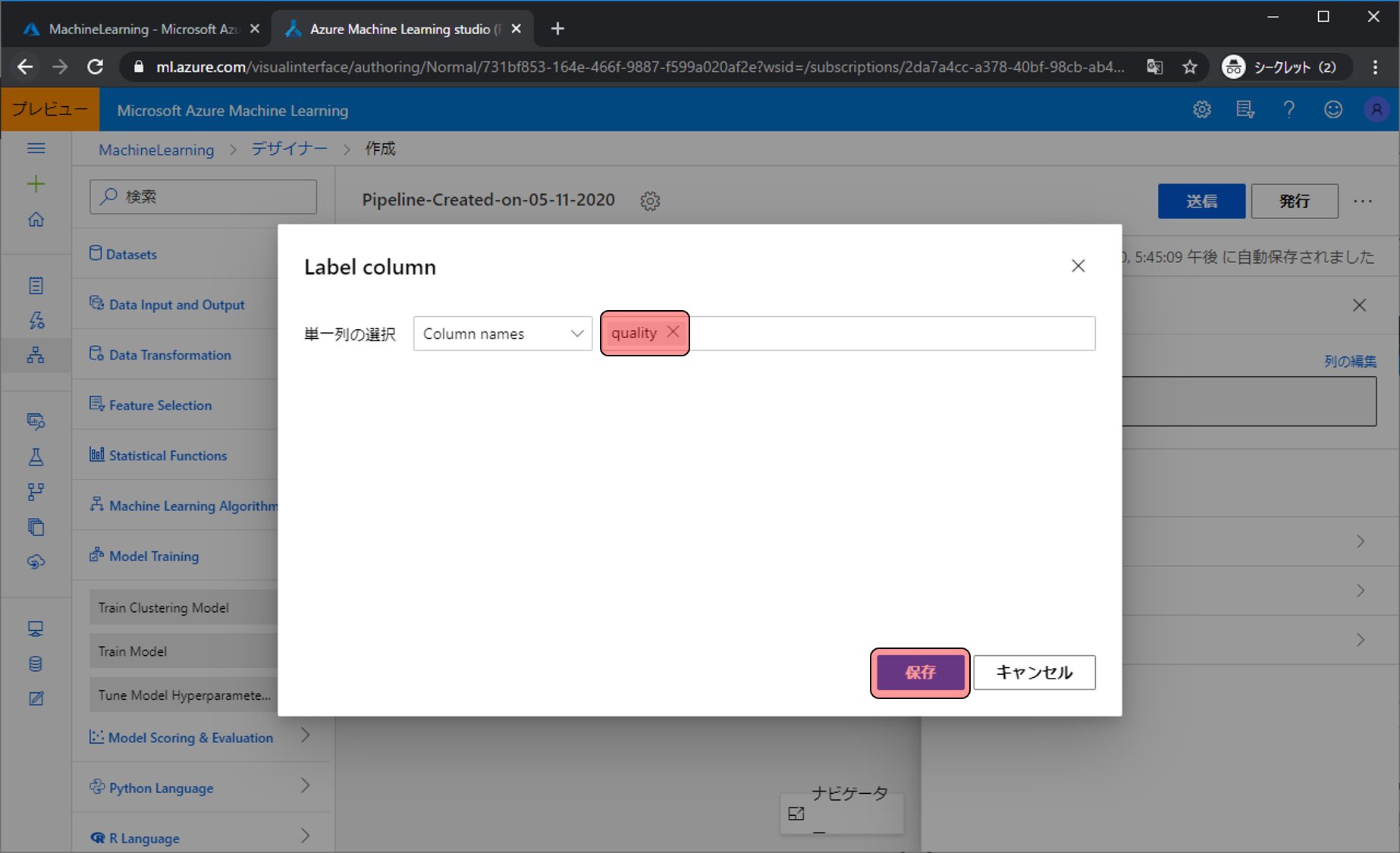
今回の予測対象はqualityなので、入力欄にqualityとし保存をクリックします。
ここまでで予測モデルを作成できる状態になりました。
予測モデルができるようになったので、作成した予測モデルを評価できるようにしていきます。評価には評価用データ(Split Dataの使っていない出力)を利用し。Score Model で行います
。Model Scoring & Evaluationをクリックし、Score Modelを配置し、Score Modelの右上の入力ポッチは予測モデルを入れるためのものなので、Train Modelの下の出力ポッチを繋げます。Score Modelの右上の入力ポッチは予測モデルで予測したい対象のデータを入れるのでSplit Modelの左下の出力ポッチを繋げます。
これで、評価用データに対して予測値が出る状態になったので、Evaluation Modelで精度を評価します。
Model Scoring & Evaluationをクリックし、Score Model とEvaluation Modelを配置します。
その後、送信をクリックして今まで配置してきたモジュールを動かします。
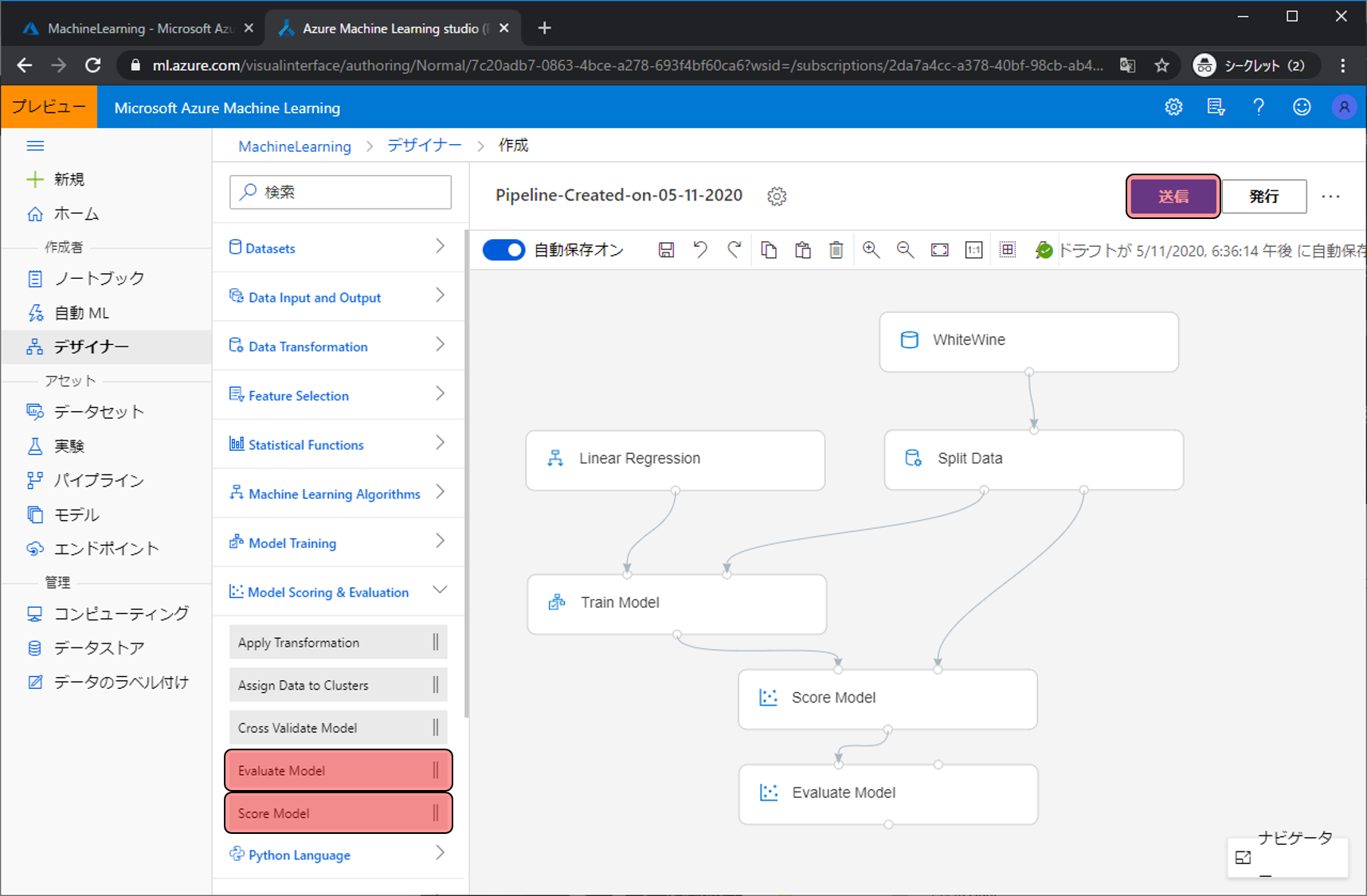
実行しようとすると実験名などを決めるようになるので、なにかわかりやすい名前を決め、送信をクリックします。
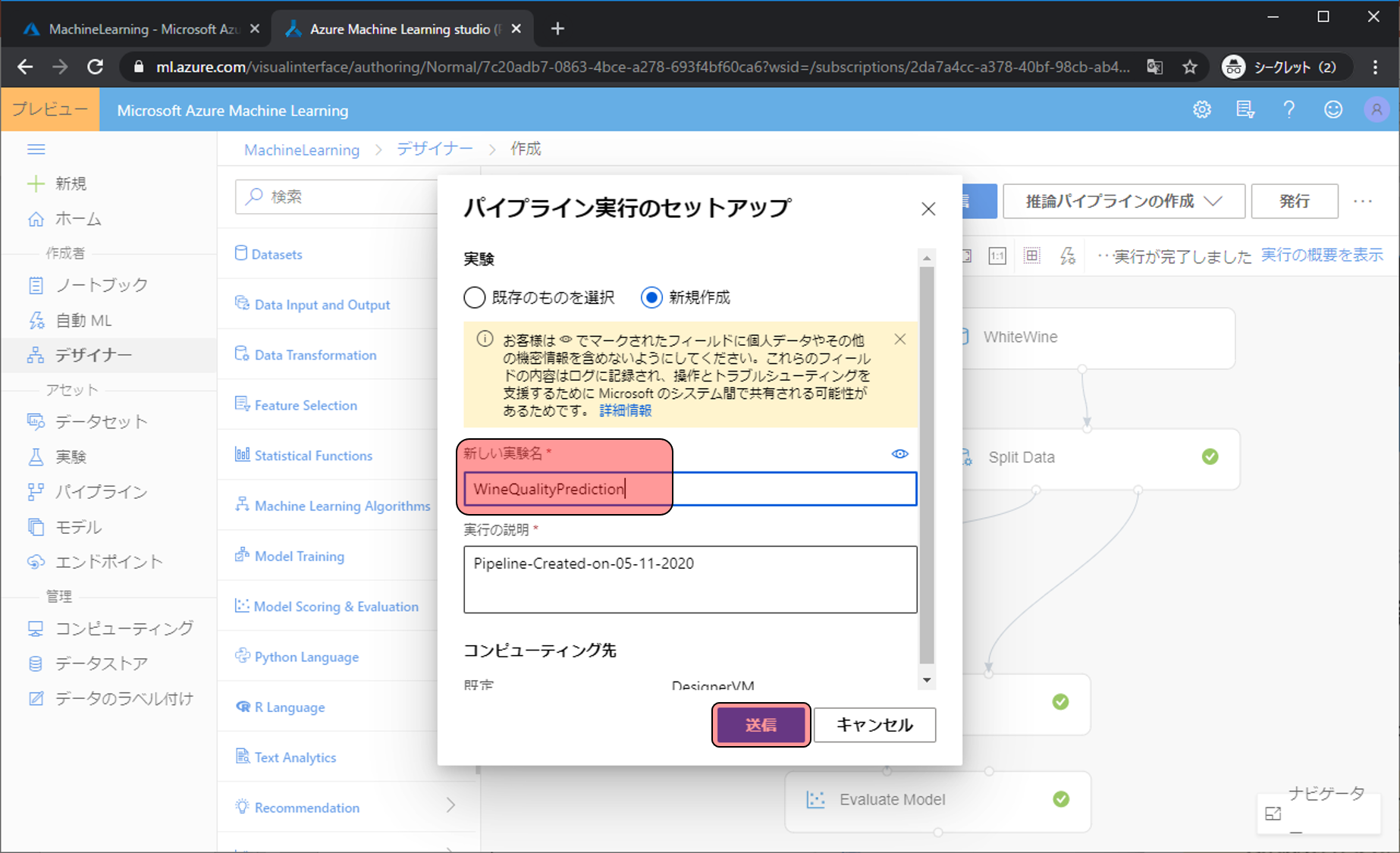
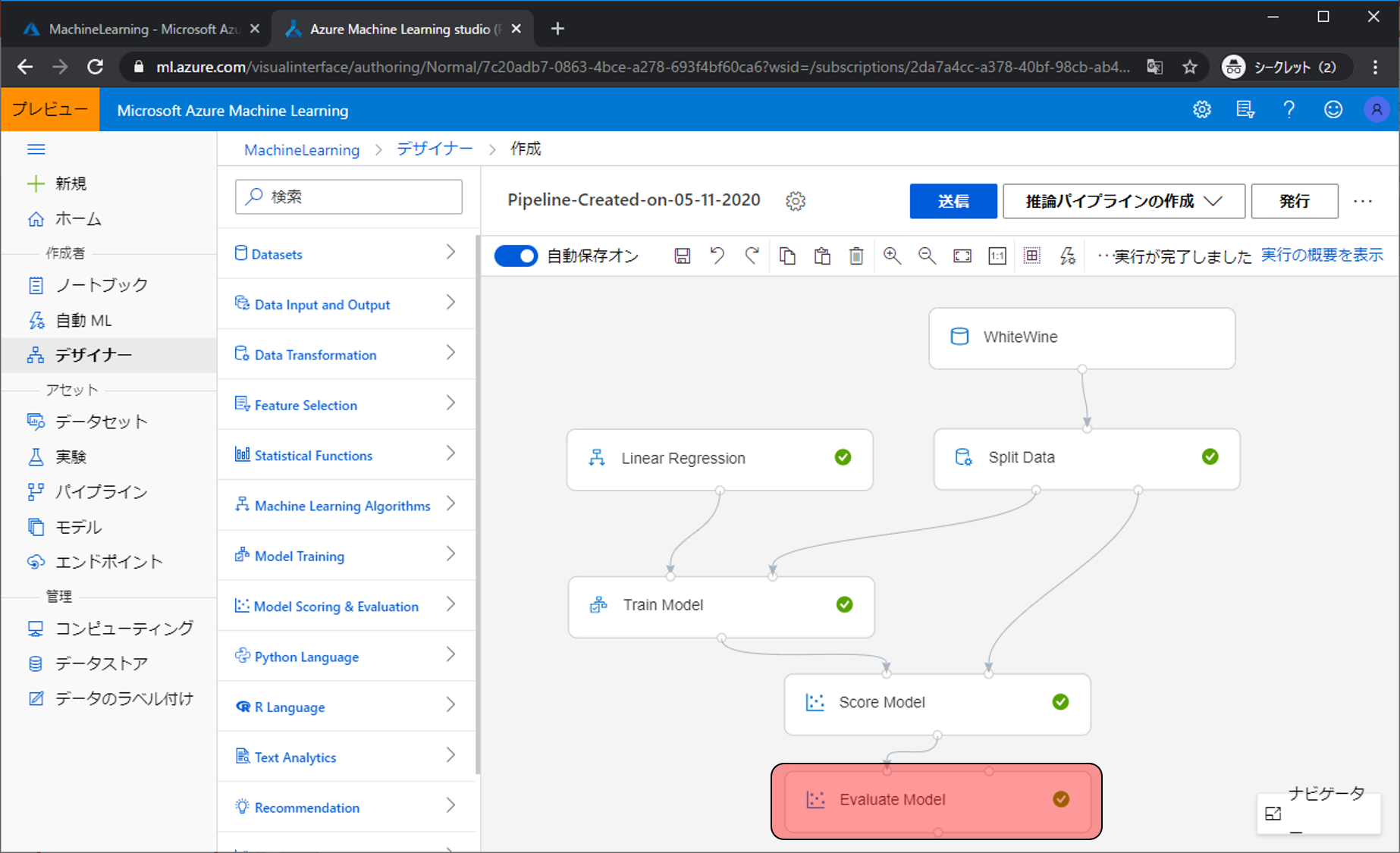
実行してから少しするとすべてのモジュールに緑のチェックマークがついて実行完了となります。予測モデルの評価を確認するためにEvaluation Modelをクリックします。
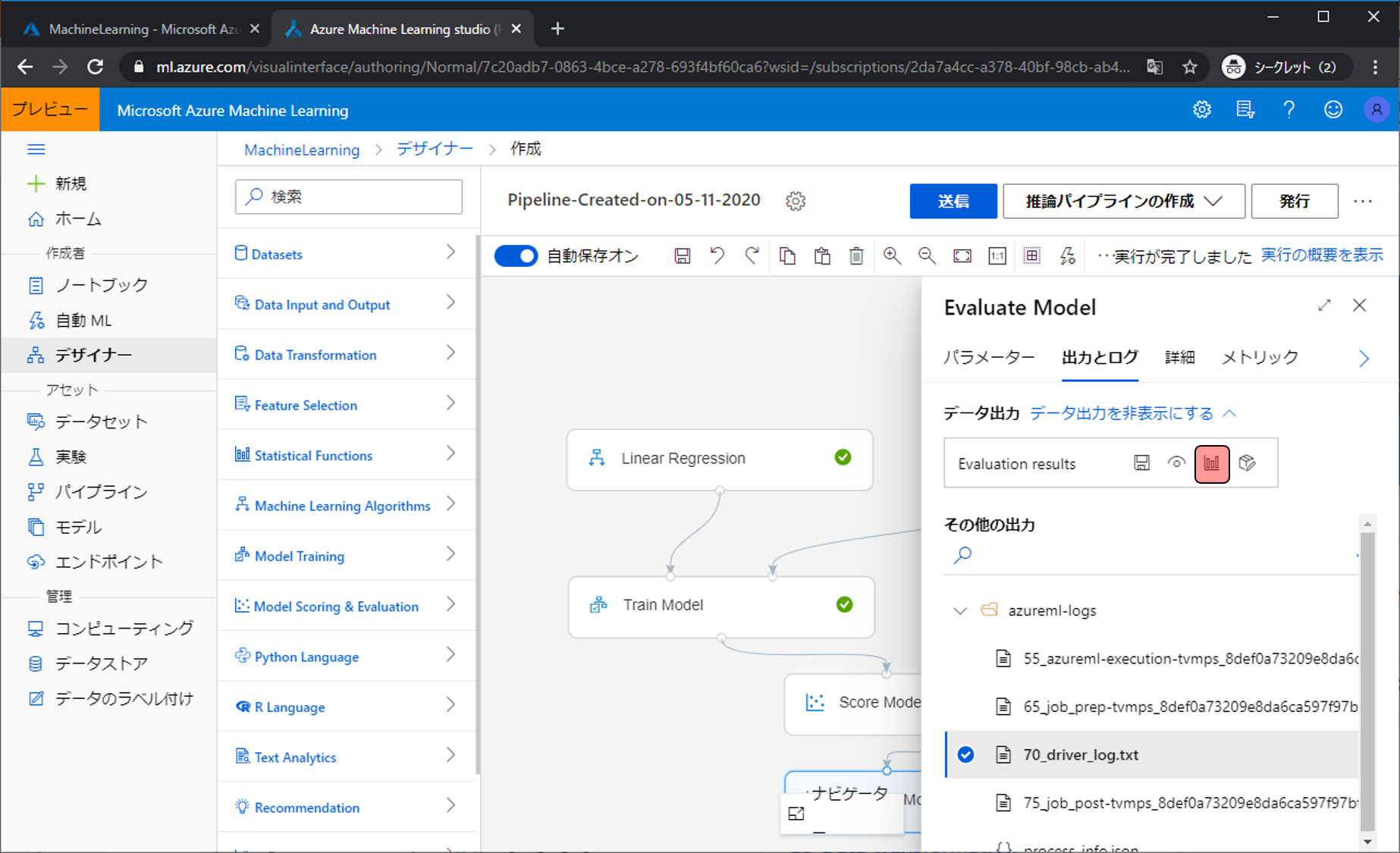
視覚化(グラフのような見た目のボタン)をクリックします。
すると、このモデルの評価が表示されます。これらの見方について次回解説します。
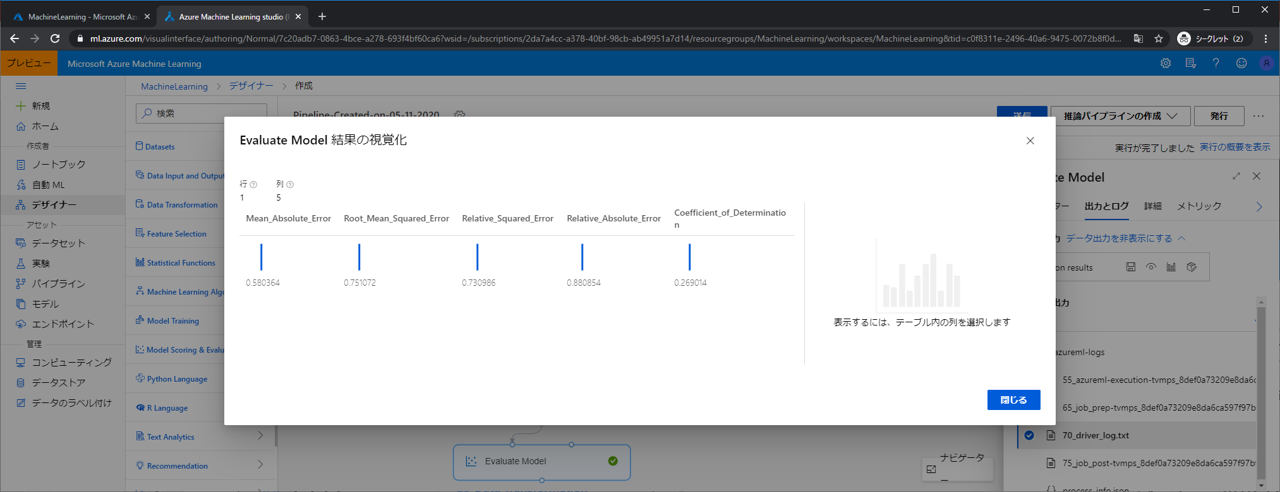
ここまでで一旦モデル作成の流れは全てできました。
記事が長くなりすぎてしまうため端折った箇所が多々あるので、次回さらに詳しく解説していきます。








![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)


