






この記事はなむゆの個人ブログにもマルチポストしています。
続きまして
この記事は前回の「久々に機械学習に触りたくなって。Azure Machine Learningで回帰モデルを作る・前編」から引き続いての後編になります。
今回は前回作った「データ投入」「前処理」の部分に続き、「モデルトレーニング」の部分を作っていきます。
モデルのトレーニングを行う
まずは回帰モデルをトレーニングする部分のパイプラインを作成します。
「Normalize Data」の下に続けて画像のようにモジュールを探してきて配置します。配置したら、矢印をつなぎ合わせます。
モジュールの配置と接続ができたら、それぞれの設定を行っていきます。
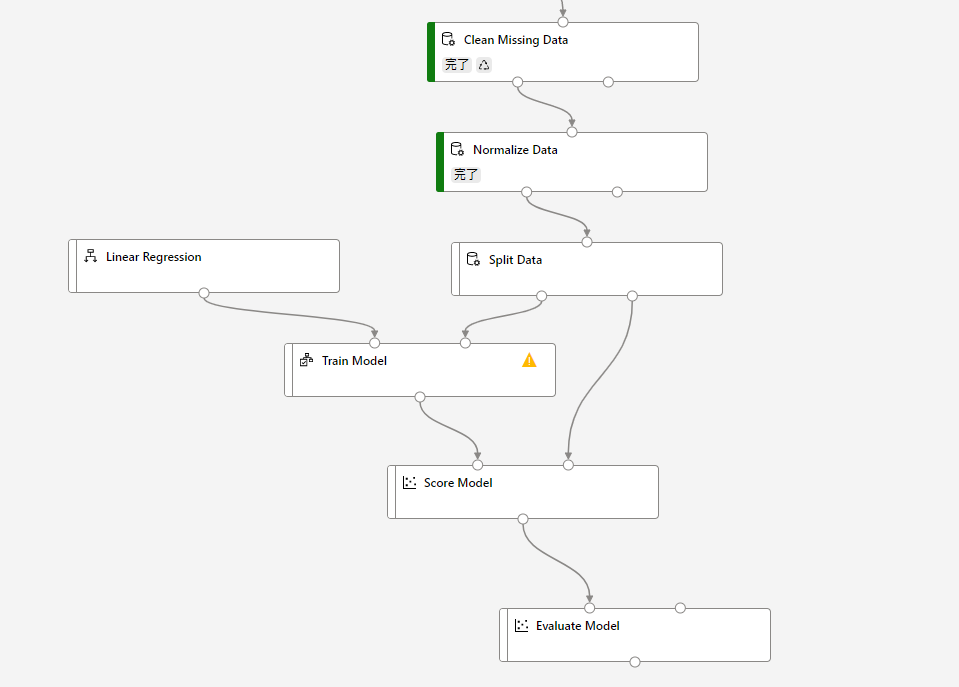
まずは「Split Data」の設定を開きます。
「Fraction of rows~」とある部分を0.7、Random seedはLearnと合わせて123にします。
「Fraction of rows~」は、下に伸びているパイプの左側に送るデータと右側に送るデータを分ける割合になります。
回帰モデルを作るのにあたって、モデルをトレーニングするのに使うデータとそのデータの評価をするのに使うデータを分けるために設定しています。
「Random seed」は、その割合でランダムに振り分けるときに使うシード値です。
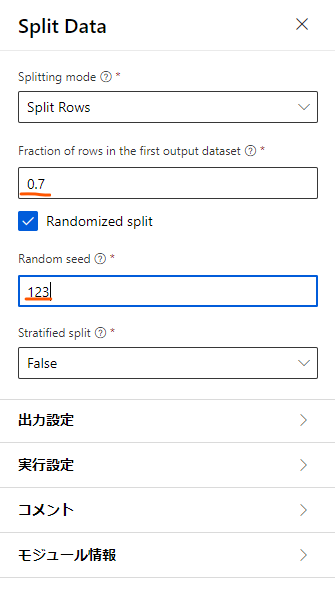
続いて、「Train model」を設定します。
ここでは回帰モデルで予測する対象の値を決めます。
今回の分析では、車の各種情報から自動車の価格を予測しようとしているので、「列の編集」ボタンから、予測の対象である価格を選択しておきます。
これでパイプラインの設定は完了です。
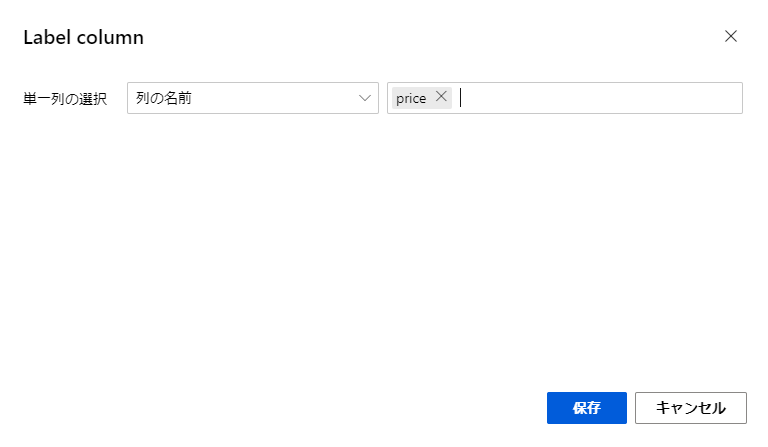
前回と同様にデザイナー画面上部の「送信」ボタンを押してモデルのパイプラインを実行します。
今回は、前回正規化まで行った実験があるので、それを選択します。
これによって、処理を途中まで行った結果を用いてそれ以降の処理を行うことができます。
「送信」ボタンを押して処理を実行します。
しばらくして処理がすべて完了したら結果を見てみましょう。
「Score Model」の「出力とログ」タブを開き、「Scored dataset」から視覚化のアイコンをクリックします。
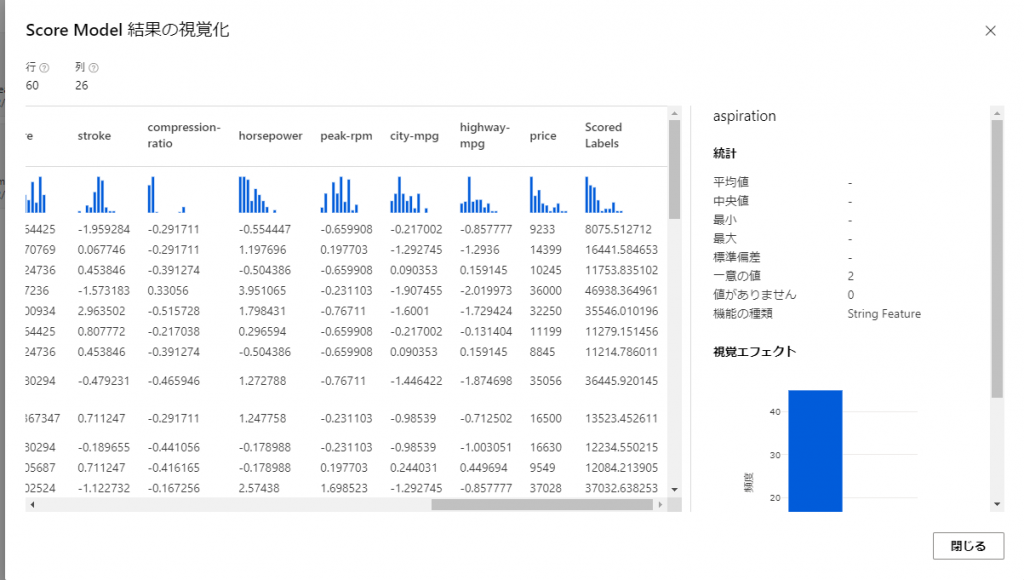
すると、このようなモデルのスコア付の結果が出力しています。
特に注目したいのが、「price」と「Scored Labels」の列です。
price はその車の実際の価格で、その隣のScored Labelsは今回トレーニングした回帰モデルを使って予測された価格です。
実際の価格より高かったり安かったりしますが、ある程度近い値が産出されているように見えるかと思います。
おわりに
今回は久々にAzure Machine Learningを利用して機械学習の実装を試してみました。
個人的には以前に書籍を読みながらいろいろ試したり学生時代からっきしだった数学にまた取り組んでみたりして打ち込んだ当時の情熱が思い起こされて何かしら懐かしい気分になりました。
Azure Machine Learningというサービスとしては触るたびに見た目が変わっていて、当時感じた技術やサービスの進歩の速さを今回も感じられました。
また定期的に触っていこうかと思います。
参考








![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)


