


 2022-07-08
2022-07-08


こんにちは、あおいです。
最近、弊社でAWS資格取得カーニバルが開催されそうなので、AWS認定資格のAssociateを勉強します。
さて、DBのパフォーマンスチューニングでインデックスの作成は非常に重要です。
とは言え、自分も最初はインデックスの構造について深く理解していなかったので、改めて調査と実践を繰り返しました。
そこで、今回はSQL Serverのインデックスの仕組みについて紹介しようと思います。
インデックスとは
テーブルへの検索処理を高速化するための索引です。
国語辞典で例えると、五十音索引を使って特定のページに載っている単語を探します。
しかし、一定の規則に沿った索引がなければ全ページを順番に調べる必要があるので、検索に非常に時間がかかります。
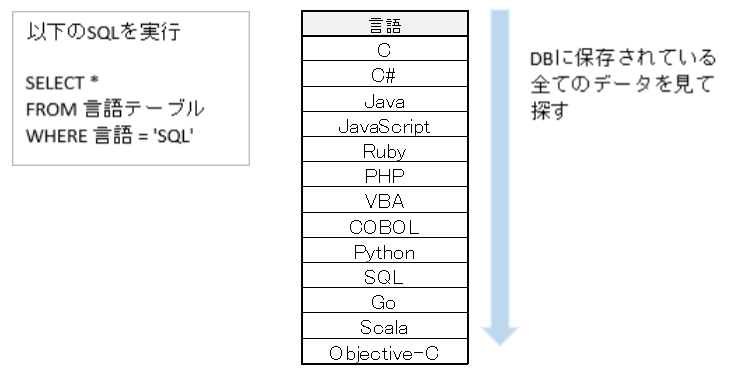
インデックスを使用しない検索
大量のデータを順番に検索して、該当のデータを探します。
線形探索で計算量はO(n)となるので、最悪、最大値まで繰り返します。
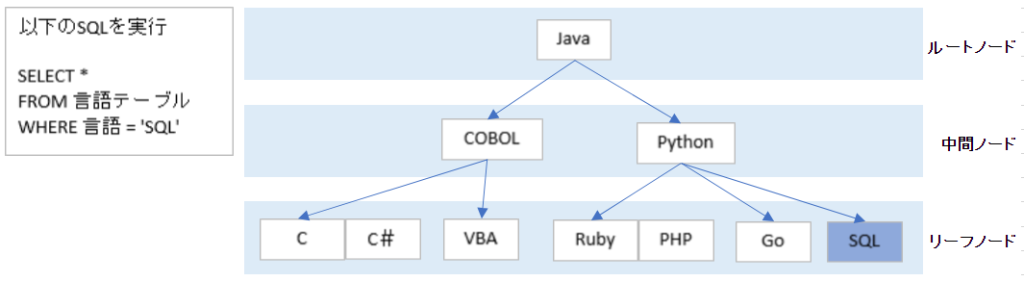
インデックスのB-Tree構造
SQL ServerのインデックスはB-Treeと呼ばれる二分探索の構造になっています。
各ノードがルールを持った階層構造を作ります。ノードの階層が全ての要素において同じで、計算量が変わりません。計算量はO(log n)となります。
インデックスには大きく分けて「クラスター化インデックス」「非クラスター化インデックス」の2種類があります。この2種類の内部構造をきちんと理解しておくことが非常に大事です。
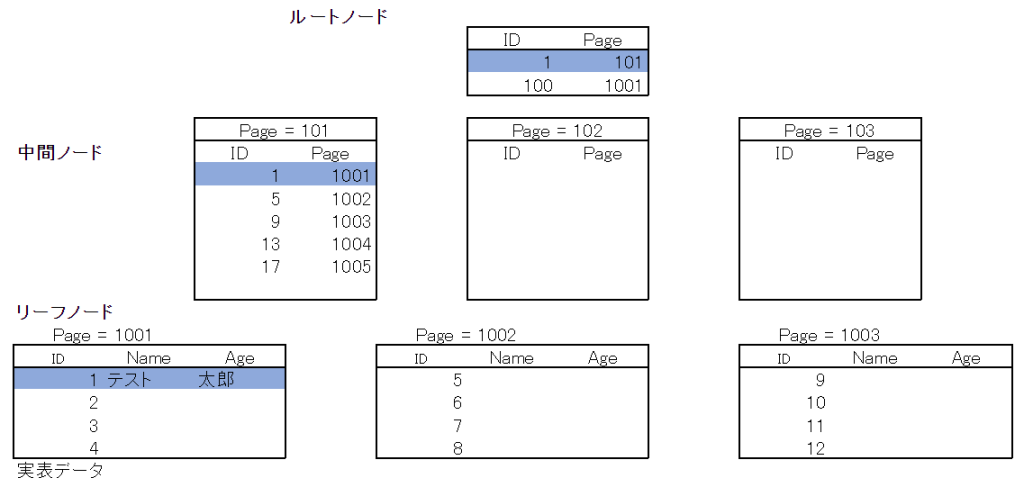
クラスター化インデックス
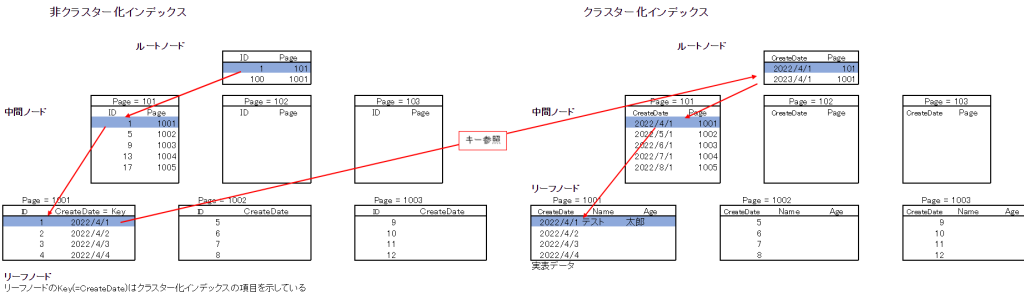
終端のリーフノードに実表データが存在します。また、インデックスに指定したキー値によって並び替えがされて、B-Treeのリーフノードに実表データが格納されます。後述で説明しますが、非クラスター化インデックスのようなキー参照やRID Lookupが発生しないので、クラスター化インデックスは最速の検索方法になります。
ただし、クラスター化インデックスはテーブルに1つしか作成できない制約があるので、よく考えて作成する必要があります。意味のない連番にするのはやめましょう。
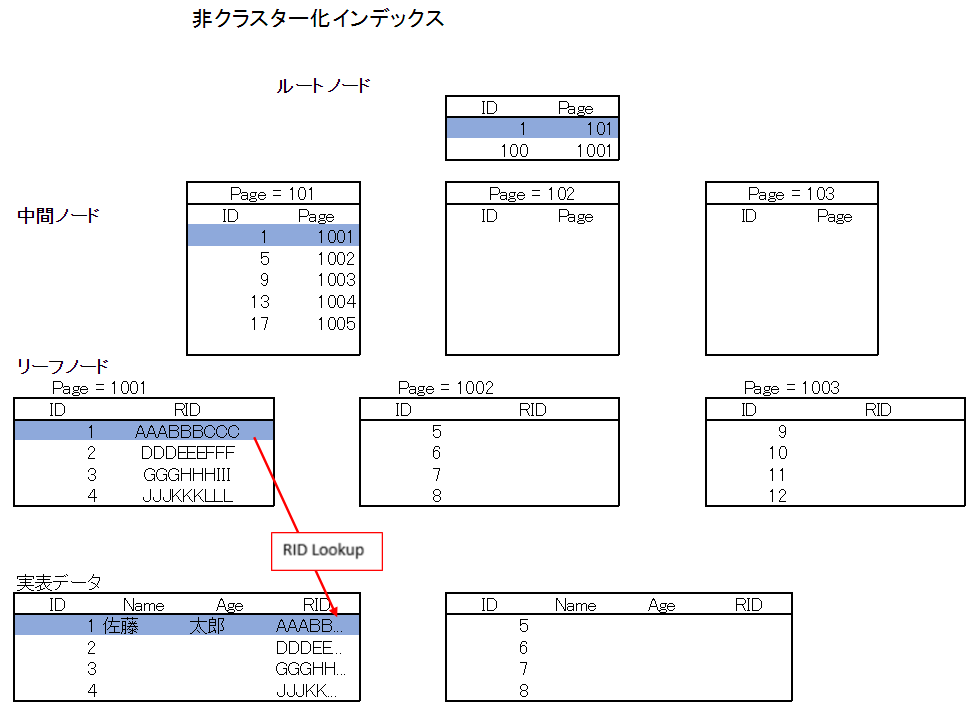
非クラスター化インデックス
クラスター化インデックスが存在しない場合
終端のリーフノードにインデックス項目とRIDが存在します。RIDは実表データの行情報です。
もし、非クラスター化インデックスの項目以外の情報を抽出したい場合、RIDを参照して実表データの所在を特定してデータを取得します。このRIDを参照して必要なデータを取得することをRID Lookupと呼びます。
クラスター化インデックスが存在する場合
終端のリーフノードにインデックス項目とクラスター化インデックスのキー列が含まれています。そこから、クラスター化インデックスのキー参照で実表データを検索する2段階検索になります。インデックスにない項目の取得は、キー参照が発生する2段階検索になるので処理が遅くなります。
ただし、リーフノードのインデックス項目とキー列のみで検索する場合は、リーフノードの読み込みで完結するので、キー参照は発生せず高速に検索できます。
基本的に、上記2種類のインデックスを使用しますが、どうしてもパフォーマンス改善が見込まれない場合、付加列インデックスを使用します。
付加列インデックス
終端のリーフノードに列を追加して、キー参照を回避します。
検索速度の高速化が見込めますが、あまり安易に多用してはいけません。内部構造的にデータの2重持ちになり、データ容量を圧迫します。

今回はSQL Serverのインデックスの仕組みについて紹介させていただきました。
次回の記事では、実際にインデックスを作成して検索を高速化する方法について紹介します。
SQL Serverのインデックスを作成して検索を高速化する | cloud.config Tech Blog
参考記事
SQL ServerとAzure SQLのインデックスアーキテクチャとデザインガイド | Microsoft Docs
ページとエクステントのアーキテクチャ | Microsoft Docs
クラスター化インデックスと非クラスター化インデックスの概念 | Microsoft Docs
SQL Serverのインデックスの理解を深める | Qiita
【SQL Server】クラスター化インデックスと非クラスター化インデックス | Hatena Blog











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
