


 2023-06-06
2023-06-06


Attentionってそもそもなに?
非常に端的に説明するならば、「2つの文章の単語の関連度や類似度を計算する機構」です。
例えば、Attentionに「これはペンです」という文章と「This is a pen」という2つの文章を入力として与えます。これらの文章を仮にA、Bとすると、Aの単語「これ」と、Bの単語「This」「is」「a」「pen」それぞれの関連度を計算してくます。この場合、「これ」というAの単語と関連度が高いBの単語は「This」と「pen」になるでしょう。
要は、Aの単語がBの文章のどの単語と深く関連しているかを数値化してくれる機構ということです。
NLPモデルの推移
Attentionが台頭して世代交代するまでのNLPモデルの推移をみていきます。Attentionがどのように活用されたか、またNLPモデルの基本的な構造がどのようなものか理解できれば良いと思います。
以下の順番でモデルを見ていきます。
- Attentionなし
- RNN(seq2seq以前)
- seq2seq
- Attentionあり
- seq2seq + Attention
- Transformer
Attentionなし
RNNモデル(seq2seq以前)
RNN(Recurrent Neural Network)は時系列データを処理するために設計されたモデルです。自己回帰を行う構造になっていて、時間tの情報をt+1に引き継ぐことで時系列データを処理します。
文章は、単語同士が密接につながってできています。特に、「これ」や「あれ」、「彼」や「彼女」のような代名詞のような言葉は文章の繋がりから理解するしかありません。なので、文章をシーケンシャルに処理する機構はとても重要でした。
文脈(単語の依存関係)の理解にはcontextという文脈のベクトル情報を用います。非常にシンプルな手法になっており、時刻tの単語をベクトル化するときに時刻t-1のcontextを加味して処理を行うだけです。この時ベクトル化した情報(隠れ状態)を時刻t-1のcontextと合わせて、時刻tのcontextとして次の時刻に渡します。
このように文脈情報を伝播させていくことで最終的なcontextから、文脈に沿った出力を行うことができます。
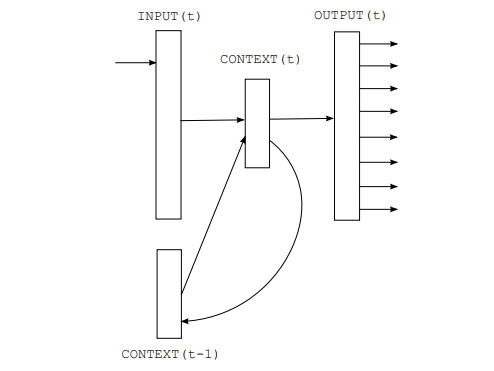
現時刻のINPUTと前時刻のCONTEXTを用いてCONTEXTを更新する処理を回帰的に行い1つの文脈ベクトルを生成する。
seq2seqモデル
sequence-to-sequenceという名前は、RNNを2つ利用した構造になっていることからそう呼ばれています。1つはcontextを作成するためのEncoder(データを計算機で処理できる形にする機構)、もう1つはcontextから文章を生成するためのDecoder(データを人間の処理できる形にする機構)として利用されています。
処理も簡単でcontextの作成はEncoderで行い、そのcontextを用いてDecoderで出力を行います。また、Decoder部分でもcontextを更新しながら文章生成を行っていくため、時刻t-1の出力を時刻tの入力として与えます。
seq2seqは異なる時系列データを扱うことができるモデルとなっていて、日本語の文章を英語に翻訳するといったことができます。その場合、日本語のcontextを用いて英語の文章が生成できるように学習させます。
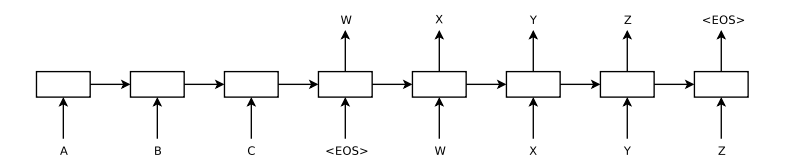
ABCを入力として受け取っているのがEncode、入力からcontextを作成する
与えられたcontextからWXYZを生成しているのがDecoder、入力には前の出力(Xから見たW)を与えてcontextと前の出力からその時間の出力を生成する
Attentionあり
seq2seq + Attention
ここからが、Attentionが組み込まれたモデルです。Attentionについて忘れているかもしれないので再確認すると、Attentionは「2つの文章の単語の関連度や類似度を計算する機構」です。
seq2seqの問題点として、contexを更新し続けると前の方にあった単語の情報が薄くなってしまうことが挙げられます。これは入力文章が長ければ長いほど顕著に表れる問題でした。そこで、Attentionを組み込んだ機構にすることでこの問題を克服し、さらに精度を向上させようと生まれたのがこのモデルです。
例えば上図において、入力「ABC W」から「X」を推論する場合、「A」「B」「C」と「W」をAttentionの入力にします。そして、このAttentionの値から次に来る確率が最も高い単語、今回は「X」を生成します。
最初は解説の簡単化のためにAttentionの入力を「A」「B」「C」「W」としていますが、実際は単語そのものではなく、隠れ状態を入力にします。つまり「Aのベクトル」「Aを加味したBのベクトル」「ABを加味したCのベクトル」「ABCを加味したWのベクトル」を入力します。これらを使って推論を行うため、contextというまとまった1つの文脈ベクトルが不要になりました。そして、問題の発端であったcontextが無くなったため、contexを更新し続けると前の方にあった単語の情報が薄くなってしまう問題が解消されました。
以下は、seq2seqとseq2seq + Attentionの翻訳精度と入力文章の長さの関係を表した表です。RNNsearchがseq2seq + Attentionを表していて、-(ハイフン)以後は学習データの文章の単語数です。評価基準にしているBLEUスコアは文章の意味の正しさよりも、正解データとどのくらい似ているかで評価されますが、それでもRNNsearch-50は入力が長文の時、目に見えて精度が向上しています。
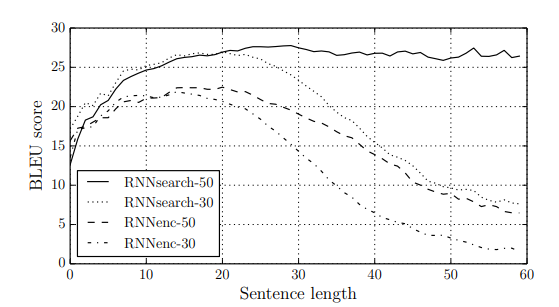
RNNsearchがAttentionを組み込んだseq2seq、RNNenc通常のseq2seq
-(ハイフン)以後は学習用データの文章の単語数
Transformer
そして最後にTransformerです。TransformerはGPTやBERTのベースになっているモデルです。その最大の特徴はRNNを取り払い、Attentionのみで構成しているという点です。RNNが無くなったため、回帰的な処理から解放され並列処理を行うことで処理の高速化を行うことができました。
TransformerはEncoder-Decoderモデルである点は変わらず入力や出力、セクション間の受け渡しデータはseq2seqに非常に似ています。しかし、内部処理にはRNNが使われておらず3つのAttention機構を主とした構成になっています。
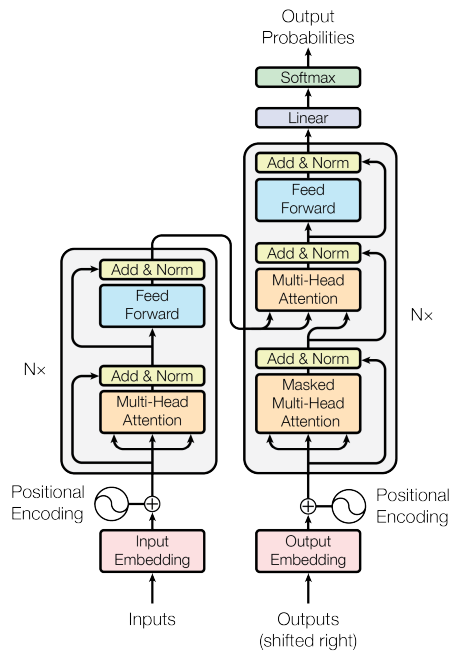
左側がEncoder、右側がDecoderとなっている
Attentionの何がよかったの?
NLPモデルの推移はこんな感じです。
RNN => seq2seq(RNN×2) => seq2seq(RNN×2) + Attention => Transformer(Attention×3)
順当にAttentionが浸透しているのがよくわかりますね。
世代交代のポイントは大きく分けて2つあり
- 長期記憶が可能だった
- 並列処理が可能だった
という点です。言い換えれば学習精度と速度が向上したということです。特に並列処理が可能だった部分が大きく、Transformerは推論時のDecoder部分以外すべての計算を並列で行えるため、非常に高速でした。
最初は、AttentionでRNNをサポートすれば、より良いNLPモデルが作れると、seq2seq + Attentionなどが生まれましたが結局「Attentionだけでいいじゃん」となりAttentionのみで構成されたTransformerが生まれているあたり、Attention機構がいかに優れていたか伝わってきますね。
おわりに
本記事を読んで、NLPを学んで行くうえでAttentionを知っておくことがいかに重要か理解していただけたら幸いです。
Transformerでも触れましたが、AttentionはChatGPTやBERTの基礎の基礎となっている機構なので、NLPを学ぶ上で避けて通れないものだと思います。
今回は難しい話を全てすっ飛ばして、誰にでも伝わるような記事を目指してみました。いきなり中身の話をしすぎると、とっつきにくいですし私自身NLPは初学者ですのでなるべく簡単にしたいという思いもありました。
今後はAttentionの詳細やTransformerについての記事などを細かく分けて書いていこうと考えています。
参考論文
Mikolov, Tomas, et al. "Recurrent neural network based language model." Interspeech. Vol. 2. No. 3. 2010.
http://www.fit.vutbr.cz/research/groups/speech/servite/2010/rnnlm_mikolov.pdf
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. "Sequence to sequence learning with neural networks." Advances in neural information processing systems 27 (2014).
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. "Neural machine translation by jointly learning to align and translate." arXiv preprint arXiv:1409.0473 (2014).
https://arxiv.org/abs/1409.0473
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
