






この記事は FIXER Advent Calendar 2023 - Adventar 23日目の記事です。
はじめに
こんにちは、毛利です。この記事では趣味用の自作PCにGPUを2枚挿してサイズが13BのLLMを動かす話をします。
LLMのパラメータ数と推論に必要なメモリ量について
まず初めに、LLMのパラメータ数に対して、推論に使う場合にどれぐらいのメモリが必要なのかを話します。ここで言うパラメータ数は7B(70億)、13B(130億)、70B(700億)といったものです。
精度によっても変わってくるのですが、配布されるモデルの精度としてはbfloat16であることが多いです。この場合は、1パラメータあたり2byteになるので、~Bの部分を2倍したGBが要求されると考えればよいです。例えば、7BのLLMであれば14GB、13BのLLMであれば26GBなどとなります。逆に4bit量子化等が行われている場合は1/2倍から1倍程度になるようです。
GPUを2枚挿すことにした経緯
さて、13Bぐらいまでのサイズのモデルはよく公開されるのですが、bfloat16のサイズで動かそうと思うと必要メモリ量が26GBとなります。生成速度を考えるとGPUに乗せ切りたいですが、一般向けのGPUとしてはGeforceのRTX 3090やRTX 4090でもVRAMが24GBとなっており、1枚では乗せ切ることができません。
新しく出たモデルを気軽に試せないのは悲しいので、16GBのGPUを2枚積んで、合計32GBにすることで13Bのモデルを動かせるようにしました。また、LLMに限らずGPGPUのコードを書きたいのもあるので、マルチGPU環境を持っててもいいかなぁというのもありました。
結果
選択したGPUですが、RTX A4000 (Ampere)にしました。Quadroシリーズの後継ですね。1スロットサイズで補助電源も6pin一つなので、複数枚挿すのにちょうど良くこれにしました。
で挿すとこうなりました。配線がやばい。

LLMを動かしてみたときの結果とnvidia-smiの結果は以下のようになりました。ちょうど最近出た東工大のSwallowの13Bモデルを動かしてみました。(説明文のコードの7bの部分を13bに変更して実行)
複数枚のGPUメモリの使い方ですが、transformers の AutoModelForCausalLM であれば device_map="auto" にすれば複数GPUでもいい感じに使ってくれるようです。Swallowの説明文のコードで言うとそのままで大丈夫です。

このときのnvidia-smiの状態は以下のようになりました。ちゃんと2つとも13GBほど使ってくれてますね。(実行後の図なのでGPU使用率は0%)
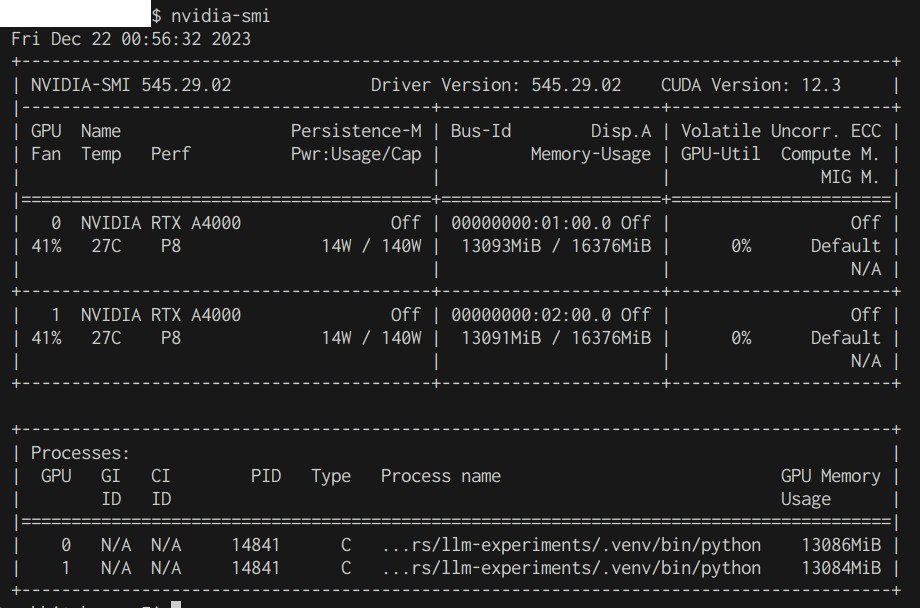
というわけでVRAMに乗り切りました。やったね。
ちなみにですが、3枚挿すと48GBになって70Bの4bit量子化が乗りそうなのですが、AMDの(Threadripperでない)マザボの場合は、空きスペースや補強されてないPCIeスロットの下側に補強用の支えを置く場所が少しつらいです。縦置きにするならIntelの3枚挿しても支えを置きやすいマザーボードを選ぶのが良さそうです。
おわりに
7950X+メモリ128GBマシンに挿したのでこのPC50万円ぐらいかかってない...?まぁCPUもメモリもGPUもあるだけうれしいのでまぁ良いとしよう。。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
