


 2024-03-12
2024-03-12


日本初開催のMicrosoft AI Tour
いまから約1年前の2023年1月にChatGPTのアクティブユーザー数がリリースから約2ヶ月後に1億人を突破したニュースがありました。それまで生成AIという言葉を耳にしたことがない人が大半だったかと思います。そこから約1年後の今、機械に疎い自分の両親ですら知ってるくらいに生成AIが誰も予想できなかったスピードで世の中に普及しています。
そんな最中、2024年2月20日に日本で初めて開催されたMicrosoft AI Tourに参加してきました。今回のブログでは、AI Tourの中で自分が参加したセッションで印象に残った部分を紹介しながら、自分が感じたことを書いていきます。
冒頭で述べた通り、2023年は生成AIが世の中に大きく広まった年だったのは言うまでもないと思いますが、今回のAI Tourのメインともいえるキーノートセッションの中で日本マイクロソフト株式会社社長である津坂美樹さんが以下のように述べてたのがすごく印象的でした。
"2024年は生成AIを語る段階から、生成AIをさらにスケールさせ、フル活用する1年になる"

キーノートセッションのタイトルにもある通り、同セッションでは組織がいかにAI技術を取り入れビジネスを変革させるかに関して、AIに関するデータや実際にAIを導入している企業の具体的な取り組みなど紹介がありました。
同セッション内の中で個人的に印象深かった話として、本田技研工業株式会社の河合泰郎さんの生成AI活用には3つのレイヤーで切り分けて考えているという話がありましたのでご紹介します。3つのレイヤーとは以下です。
- インターネットなどにある一般常識を知能化するレイヤー
- 従業員の日々の業務で発生する情報や知識を知能化するレイヤー
- 専門家の知識を意図を持って知能化するレイヤー
1つ目に関しては、ある程度すでに身近な存在となっているかと思いますが、2つ目と3つ目のレイヤーに関してはまだ日常的に扱えてる方は少ないのではないでしょうか。今回のブログでは特に2つ目のレイヤーの話である従業員の日々の業務で発生する情報や知識を知能化するレイヤー、自分の言葉で置き換えて自社データを知能化(学習した)生成AIをメインテーマとして深堀りしていきたいと思います。
自社データを学習した生成AI
自社データを学習した生成AIがいるとどんなメリットがあるのでしょうか、これは実際に日々の業務を思い返しながらいくつか考えてみました。
過去のデータへのアクセスが簡単になる
プロジェクトを進めていく中で、なんでこの設計ってこう決まったんだっけ?だったり、あの会議って結局どんな結論で終わったんだっけ?と思うことがしばしばあります。議事録を探すにもそれが1年以上前の会議であれば、議事録の場所を探すのに一苦労したり、当時いたメンバーがすでにプロジェクトから離れていてキャッチアップが困難で探すのを断念してしまった経験が皆さんの中にもあるのではないでしょうか。過去のやり取りを漁ったり議事録を一通り読み直したりする代わりにこれまでのやりとりを全て学習した生成AIに聞くことで、時空を超えて簡単にこれまでのやり取りの情報が手に入るかもしれません。
組織内の知識共有の幅が広がる
同じプロジェクト内でも、他のチームのやってることって案外わからなかったりしませんか?それが社内の他のプロジェクト、部門にまで広がると尚更かと思います。プロジェクトを進めていく中で壁にぶちあたったとき、社内の他のプロジェクトや部門でも似たような問題に対面したことはないか、その際どう対処してどんなアプローチが有効的だったのかわざわざ直接当事者に聞きに行くというシーンを見たことがあります。こんな時、1から10まで当事者から聞くのではなく自社データを学習した生成AIに素早く確認することによってプロジェクトや部門を跨いだ情報共有がスムーズに行われ、社内全体の問題解決の効率が飛躍的に向上するのではないかと思います。
よりパーソナライズされた出力結果を期待できる
現状生成AIの活用方法としては、アイデアを考えてくれたり文章を修正してくれたりするような用途が一般的なのではないかなと思っています。この用途も自社データを学習した生成AIを活用することによって、一般的な生成AIが提供する標準的な解決策やアイデアに留まらず、企業固有のニーズや文脈に沿った出力結果が期待できると思っています。たとえば、自社の過去の成功事例や失敗事例を基にしたアイデア生成、業界特有の用語を使用したり特定のスタイルに合わせた文章の修正といったことが自然と行えるようになるんじゃないかなと思っています。
まだ現実味に少し欠ける話かもしれませんが、これまでの生成AIの成長スピードに鑑みるに、そう遠くない未来には当たり前に変わってるかもしれないとAI Tourに参加して感じました。妄想に拍車がかかりますが、これらを実現させるには注意が必要であると気づかせてくれる面白いセッションがあったので共有します。それが以下のセッションでした。

" データは酸素である "
というキャッチーなフレーズから始まるこのセッションの冒頭では、生成AIのクオリティは学習するデータによって大きく左右されるという話がありました。この言葉を踏まえて、セッションの中身に触れる前に、実際に自社データを学習した生成AIを活用するとなったときのそのクオリティについて自分なりに実際に使ってるところを想像しながら考えてみました。
実際問題、自社データを学習した生成AIが出力する結果に誤りがあったり、いわゆる「ハルシネーション」を引き起こす可能性は十分に考えられます。ハルシネーションを引き起こす原因はいくつかあるようですが、自分が調べた中には誤ったデータを学習させていることや学習データの不足が原因となり得るようです。では何が原因で誤ったデータを学習させたりデータが不足したりすることが起きるのか考えてみましょう。
例えば生成AIに対して
「最新のテスト仕様書の中身から○○の情報を抜き出してください」
と指示を出したいとします。その時テスト仕様書が以下画像のように管理されていたらどうでしょう。
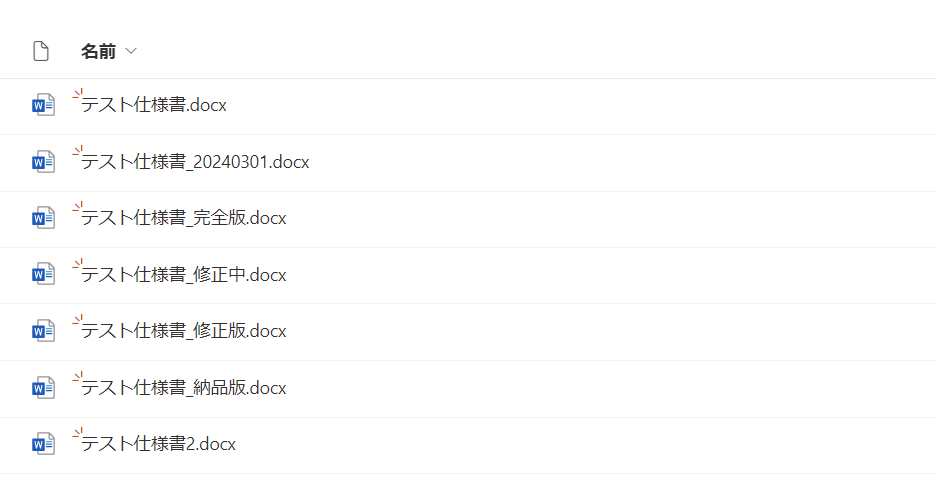
恐らく生成AIの出力結果はこうなるでしょう。
" あの。。。最新ってどれですか。。? "
っていうのは冗談ですが、現実的に考えられる回答としては画像の中のテスト仕様書のどれかを選択してその中から必要な情報を抜き出してくれるでしょう。しかし選択されたテスト仕様書は本来意図していたものとは違うものの可能性が大いにありえますし、そのせいで古いデータから参照してしまい、ハルシネーションを引き起こす原因になりえると思います。
上記例は極端ですが、社内のデータが杜撰に管理されていると精度の低い出力結果を招く要因になりえるかと思います。精度の高い出力を期待したいのであれば、常に社内のデータを最新に保つものや誤ったものがあるならば誤ったものであることがわかるように常に自社データの品質を保つ施策を考える必要があると思います。
また学習させたかったデータが実は学習されていなかった(学習データが不足していた)ケースもあるかと思います。どういった状況で起こりえるでしょうか。先ほどの例のような仕様書といったドキュメントはSharepointに、タスクやスケジュール管理はNotionで、ミーティングや普段のやりとりの情報はTeamsやSlack、他にもAWS上のS3やAuroraといったクラウドサービスでデータを管理するなど、管理するデータによって最適なプラットフォームを使い分けていおりデータが分散されて管理されているケースが1つ考えられるかと思います。
また社内の中でもプロジェクトによって、使用するプラットフォームが異なることもありえると思います。それによって、このプロジェクトのドキュメントは学習させられているが他のプロジェクトのドキュメントは学習させられておらず、前述したような他プロジェクト間での情報共有のスムーズさを向上させられるようなメリットが受けにくくなるといったことが考えられます。
というように自社データの品質が悪い場合や多種多様な管理により適切なデータを生成AIに学習させられず、生成AIの魅力を感じにくい結果を生みかねないのではないでしょうか。
ここでセッションの冒頭の話に戻りますが、生成AIのクオリティを高めるには学習させるデータの質を上げる必要がある。
つまり自社データを学習した生成AIのクオリティを高めるには自社データの質を高める必要がある。
これが今回のブログで最も伝えたいテーマです。
では自社データの質を高めるにはどうしたらいいでしょうか。
先ほど例として、データが分散されて管理されているためすべてのデータを生成AIに学習させることは難しいという課題をあげましたが、同セッションの中でこの課題を解決できるかもしれない面白いものが紹介されていました。
それがOneLakeです。
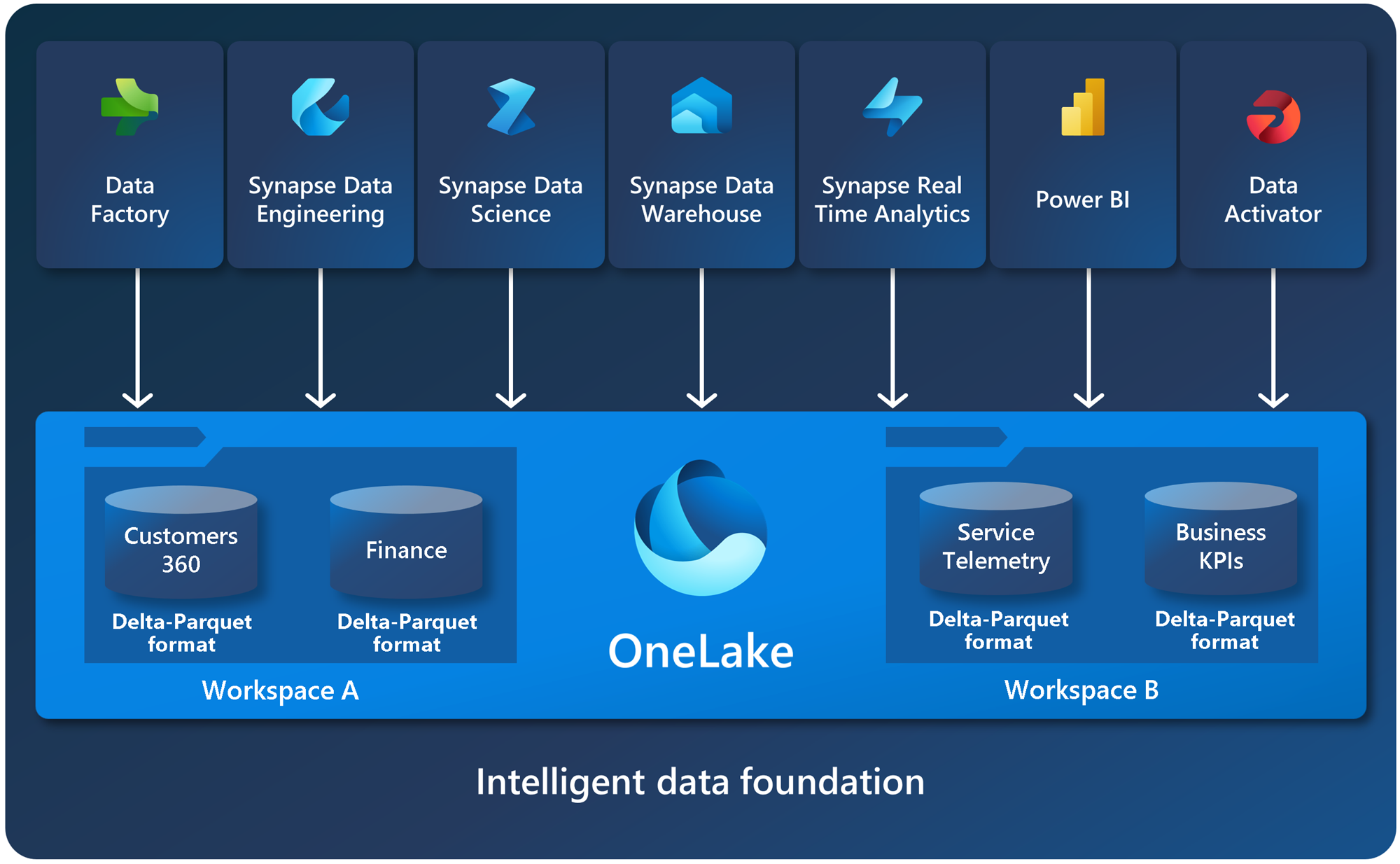
OneLake は、組織全体で 1 つに統合された論理データ レイクです。 OneDrive と同様、OneLake はすべての Microsoft Fabric テナントに付属し、すべての分析データの単一の場所になるように設計されています。
OneLake 内のすべてのデータには、データ項目経由でアクセスできます。 Office が OneDrive に Word、Excel、PowerPoint の各ファイルを格納するのと同様に、Fabric はレイクハウス、ウェアハウス、およびその他のアイテムを OneLake に格納します。
本来OneLakeはMicrosoft Fablicというデータ分析ソリューションの1つの機能みたいな位置付けなのですが、上記引用文の通りOneLakeを使うことで社内のデータをOneLakeに集約させることができるらしいです。またショートカット機能を使うとAWSのS3やDataverseといった外部のサービスにもOneLake上からアクセスすることがすでに可能のようです。
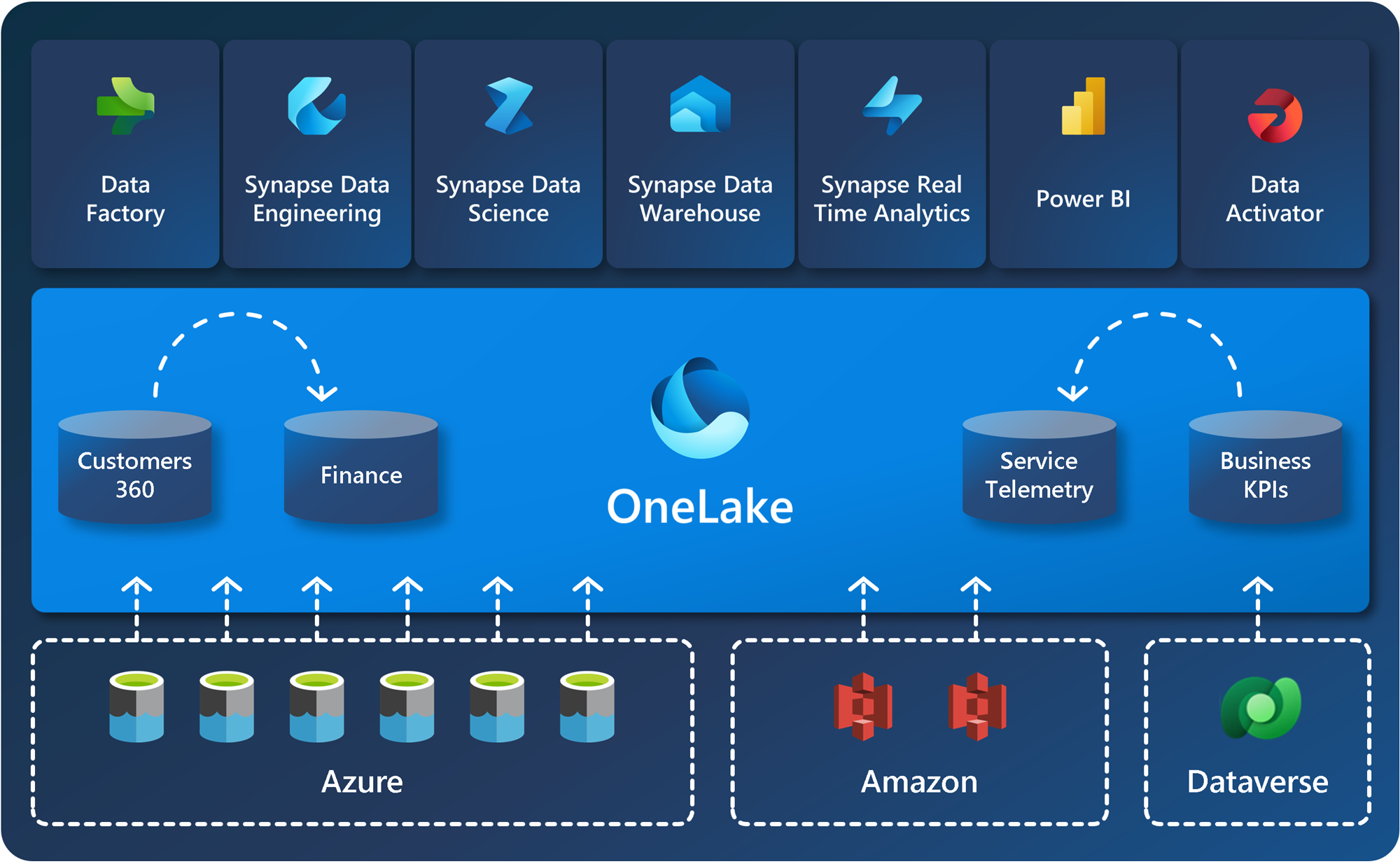
今後アクセス可能なサービスがより増えれば、分散して管理していたデータがすべてOneLake上からアクセス可能になるかもしれないですし、生成AIとOneLakeをつなぐことができればすべての自社データを学習させることができるようになるかと思います。
ちなみに今後のOneLakeの開発ロードマップが公式で発表されているので確認してみてください。
Microsoft Fabric の OneLake の新機能と計画内容 - Microsoft Fabric | Microsoft Learn
また同セッションの中で実際にOneLakeを導入し使ってみた感想を株式会社集英社の須藤明洋さんが登壇されて紹介いただきました。
同社では社内の一部をOneLakeに移行して運用しているそうなのですが、実際に使って便利に感じる点としてプラットフォーム間でのコピー作業が極端に減ったということを挙げられてました。
この話を聞いて自分自身のプロジェクトでもSharepointにある100GB以上のcsvファイルをOracleDBに取り込む必要があったときのことを思い出しました。そのときはSharepoint→ローカルPC→データロード用サーバ→OracleDBと合計3回も100GB越えのデータをコピーする必要がありすごく時間かかった苦い思い出があります。一部をOneLakeに変えてデータを集約するだけでもそういったデータのコピーの時間を減らすことができ、よりやりたいことに時間が割くことができそうですね。
余談ですが、この方の話し方や雰囲気含め個人的にすごい好きでAI Tour全体で見ても色濃く記憶に残ってます。
道のりは果てしないがやる価値あり
ということで、このブログでは自社データを学習させた生成AIの活用に伴って自社データの質を高めようという話をしました。とはいえ自社データの質を高めるといっても今回紹介したOneLakeのように異なるリソースからデータを集約すること以外にも、テスト仕様書の例で出したようなデータの品質を保つ施策やデータを安全に利用してもらうセキュリティ面なども考慮しなければいけません。
調べれば調べるほど気の遠くなるような話がたくさんありました。
とはいえ、現状そんなに困ってないからそのままでいいと胡坐をかいてしまう側と、これからを考え今からでも行動に移す側では数年後の差がとんでもないことになってしまうのではないかと自分は思います。
生成AIと自社データを適切に組み合わせることができれば、これまでの仕事のあり方が一新されるほどの影響力が考えられると思うので、今のうち社内のデータ戦略を考え実行に移しましょう!
というのがAI Tourに参加して思ったことでした。では!











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
