


 2026-03-30
2026-03-30

はじめに
Kiroを触り始めたきっかけは、AWSに関連するAIエージェントだったことです。AWSに関連する業務をここ数か月やっていたこともあり、自然と気になって触り始めました。
もともと、AIやAIエージェントを使う上で、設計の意図を持たせないと実務で使える出力になりにくいと感じていました。特にインフラは小さなミスでも大きな障害につながり得るため、コード生成そのものよりも、前提や設計との整合をどう持たせるかが重要です。
Kiroには、specやsteeringを通して設計やルールを前提として渡せる仕組みがあり、自分の業務とも相性が良さそうでした。これは単なる仕様整理というより、AIに設計意図や制約を持たせるためのハーネスを組む発想に近いと感じています。
この記事では、その中で意識していることや、ルール化したことを書いてみます。
AIに「設計の意図」を持たせる難しさ
AIコーディングツールに指示を投げて、出てきたものをそのまま使うケースがあります。小さいスクリプトならそれでも回りますが、チームで運用するコードだと話が変わってきます。
- 同じ指示を出しても、文脈が変わると出力が揺れる
- 設計書に書いてある前提条件が反映されない
- 「なぜこの実装にしたか」の根拠が残らない
たとえば、設計書に書かれていない値や構成前提をAIがそれらしく補完してしまい、見た目は自然なのに実際には採用できない出力になったことがありました。特にインフラでは、この「それっぽい誤り」が危険です。
spec/steeringで前提を渡す
Kiroにはspecとsteeringという仕組みがあります。
specは、requirements(要件)→ design(設計)→ tasks(タスク)の3段階で整理するものです。いきなりコードを書かせるのではなく、「何を作るか」「どう作るか」を先に明文化してからタスクに落とします。
steeringは、毎回必ず守らせたい最小限のガードレールを書く場所として使っています。たとえば命名規則、バージョン固定、推測禁止、必須タグのような「常に効いてほしい制約」です。適用範囲はfrontmatterで制御でき、特定のファイルパターンに応じた条件付き適用も可能です。
一方で、Terraform固有の詳細な設計ルールやレビュー観点はsteeringには載せず、skillとして分離しています。必要な場面で `/terraform-design` を呼び出して参照する運用にしています。
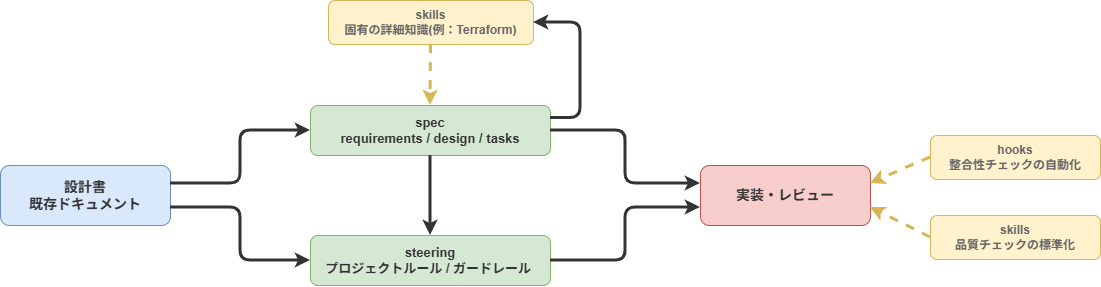
specとsteeringは、設計の意図をKiroに渡すための仕組みです。ただし、これだけで全部解決するわけではなく、使い方次第です。
実際の使い方とハマりどころ
自分の場合、既存の設計書(非機能設計書等)がすでにある状態でKiroを使い始めました。ここでは実際にやったことと、ハマったことを整理します。
まず全体の役割分担をざっくり言うと、次のようなイメージです。
- steering — 常時または条件付きで効かせる最小限のガードレール
- skills — 必要に応じて明示的に呼び出す、詳細な設計ルールやレビュー観点、再利用可能な作業手順
- hooks — IDEのイベントをきっかけに自動実行されるアクション
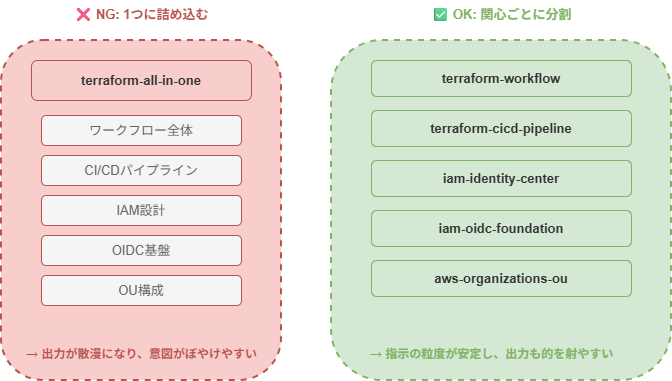
specは1機能1specに分ける
最初、関連する機能をまとめて1つのspecに書こうとしたら、設計が散漫になりました。Kiroが参照する情報量が多すぎて、出力がぼやけます。1機能1specに分けたら、指示の粒度が安定して、出力も的を射るようになりました。
実際のディレクトリ構成はこんな感じです。
.kiro/specs/
├── terraform-workflow/
├── terraform-cicd-pipeline/
├── iam-identity-center/
├── iam-oidc-foundation/
├── aws-organizations-ou/
└── ...まず既存の方式設計を元に全体ルール(terraform-workflow)を作り、そのうえで詳細設計を個別のspecに分けて詰めていくイメージです。たとえば「認証基盤」と「CI/CDパイプライン」のように、関心事が違うものは分けた方が出力が安定します。
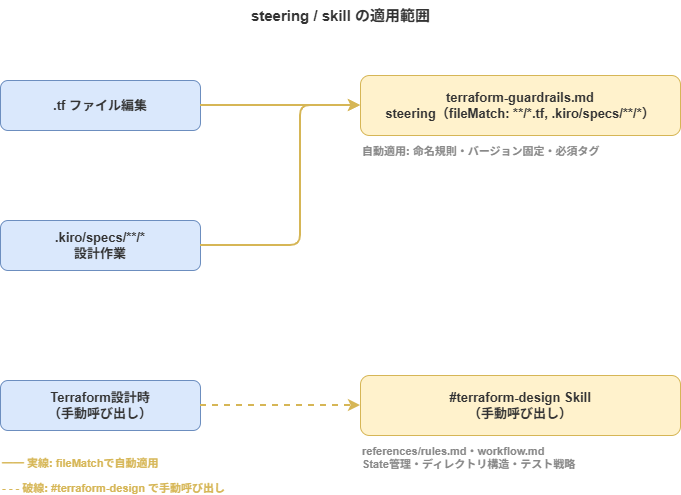
steeringはファイルパターンで適用範囲を絞る
steeringは全部常に読み込ませるのではなく、frontmatterの `fileMatch` で適用範囲を制御しています。
たとえばガードレール(最小限ルール)はこう書いています。
---
inclusion: fileMatch
fileMatchPattern: "**/*.tf,.kiro/specs/**/*"
---`.tf`ファイルを編集するときだけでなく、`.kiro/specs/**/*` 配下でSpecを作成・編集するときにも読み込まれます。ここで扱うのは、命名規則、バージョン固定、必須タグ、推測禁止のような最低限のガードレールだけです。
以前はState管理、ディレクトリ構造、テスト戦略などの詳細ルールもsteeringで扱っていましたが、現在はその部分をskillsへ移しています。
Terraform設計を深掘りしながらSpecを作るときは、必要に応じて /terraform-desigin を呼び出します。これにより、常時読み込む情報は最小限に抑えつつ、必要な場面だけ詳細な設計ルールを参照できるようになりました。
PowersでTerraform Registry情報を補完する
Kiro Powerの「Deploy infrastructure with Terraform」を有効にすると、Terraform Registryの情報を参照しながら出力できるため、プロジェクト固有ルールを記載したsteeringと組み合わせやすいです。
また、PowerにはSteeringがセットで付いています。つまり、Terraformのコーディング規約などをルールとしてマネージドに利かせることができます。
一方で、常に意図したタイミングで参照されるわけではなかったため、「どの作業で何を優先して参照させるか」は別途ルール化が必要だと感じました。
hooksで整合性チェックを自動化する
hooksは、整合性チェックのような毎回やる確認を自動化する仕組みとして使っています。
specとsteeringの同期チェックや、ドキュメント全体の整合性チェックをhooksで仕組み化しています。手動で毎回確認したり、その都度チャットでプロンプトを考えてAIと対話するのは現実的ではないので、ボタン一つで実行できるようにしました。
たとえばSpec-Steering同期チェックのhookはこんな定義です。
{
"name": "Spec-Steering同期",
"when": { "type": "userTriggered" },
"then": {
"type": "askAgent",
"prompt": "design.md(正本)とsteering(ルールブック)を比較し、不整合があれば同期修正を提案..."
}
}ボタンを押すと、Kiroがdesign.md(正本)とsteering(ルールブック)を比較して、差分があれば修正案を出してくれます。
skillsで品質チェックを標準化する
skillsは、レビュー観点やチェック手順を再利用可能な作業手順としてまとめておくために使っています。Kiro上ではskillディレクトリに定義を置き、チャットから呼び出す形で使います。
たとえばspecの品質チェックをskillとして定義しておくと、必要なタイミングで呼び出して、対象ディレクトリに対して同じ観点で確認できます。`/spec-quality-check` のように呼び出して、対象を指定するだけです。
実際のディレクトリ構成はこんな感じです。
.kiro/skills/spec-quality-check/
├── SKILL.md # スキル定義(トリガー条件、実行手順)
└── references/
└── checklist.md # チェック観点の一覧`SKILL.md` にスキルの説明やトリガー条件を書き、`references/` 配下にチェック観点などの参照資料を置いています。
チェック項目は標準化していて、たとえば以下のようなものがあります。
- シークレット(パスワード、APIキー、秘密鍵等)がハードコードされていないか
- 各設計判断に参照ファイル名+章が明記されているか
- スコープ/スコープ外が明記されているか
設計書の内容をspecに落とし込む
既存の設計書からspecを作るときは、該当章を参照しながらrequirementsを書き、そこからdesign、tasksの順に落とします。設計書に書いてある内容はそのまま使い、未記載の部分はToBeとして残します。
- 設計ファーストの機能がKiroにはあります。つまりdesign ⇒ requirements ⇒ tasksの順です。設計書が既に存在している場合や、そもそもインフラと相性が良いと聞いたので、実務や家で今度試してみたいと思います。
ハマりどころ: 情報が曖昧だとそれっぽい出力になる
steeringやspecに曖昧な記述があると、Kiroはそれっぽく補完してきます。特にCIDRやアカウントIDのような固有値は、推測で埋められると気づきにくいです。間違っていても一見それらしく見えてしまうので、レビューで見落とすリスクがあります。
対策として、steeringに「推測禁止」を明記し、未確定事項はToBeとして残す運用にしています。設計書にない内容を推測で埋めないことが、最も重要な前提です。
さらに、品質チェックのskillでも固有値やシークレットのパターンを検出するようにしています。推測誤りの防止と秘密情報の混入防止は別の問題ですが、どちらも「意図しない値が紛れ込む」という点では共通しているため、同じチェックフローに載せています。
<シークレット検出パターン>
以下のパターンを「シークレットのハードコード」違反として検出する:
- パスワード: `(?i)[a-z0-9_-]*(password|passwd|pwd|secret)[a-z0-9_-]*\s*[:=]\s*("[^"]*"|'[^']*')`
~~
<検出対象外(許容)>
- IPアドレス/CIDR(ネットワーク設計値)
~~ToBeセクション内での確定値記載は例外として許容しつつ、それ以外で出てきたら警告する仕組みです。
まとめ
実務では、AIの出力精度そのものよりも、どの前提を与えるか、どこまで推測を許さないか、どうレビュー可能な形で残すかの方が重要です。AIには整理、ドラフト、整合チェックに加えてレビューまで含めて担ってもらう方が、全体の速度は出しやすいと感じています。たとえば、specとsteeringの同期確認やチェックリストベースの品質チェックをAIに任せることで、人はレビュー結果の判断に集中できます。ただし、セキュリティやIAM、データ削除・移行、インフラの公開設定のような高リスク変更だけは、人が明示的に確認するようにしています。
公式ドキュメントや公式ブログで体系的に学習もしてみたいです。
なお、この記事の構成整理や叩き台づくりにはKiroやChatGPTを一部活用していますが、内容そのものは実際に試した結果と手元のメモをもとに見直しています。
※本記事は、著者が過去に公開した内容をもとに、会社技術ブログ向けに再構成したものです。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
