


 2026-05-29
2026-05-29


はじめに
AIを使用しているアプリをテストする際、どのように書けばいいか悩んだことはありませんか?
プロンプトを少し変えただけで、別の質問に対する回答が崩れることがあります。Bedrockのモデルを変更したら微妙にトーンが変わったり、検索のtop-kを調整したら、以前は答えられていた質問の品質が落ちることもあります。
このような変更の影響を定量的に把握するのは悩みどころです。
ユニットテストで検証しようとしても、期待回答と完全一致する必要はなく、むしろ流暢に見えて質問に答えていない回答もあります。
社内ドキュメント検索RAGや問い合わせ対応チャットボットの場合、確認したい観点は以下の通りです。
- ユーザーの質問に答えているか
- 社内ドキュメントにない情報を述べていないか
- 必須の注意書きや制約を落としていないか
- 回答のトーンが業務用途として適切か
- 以前は答えられていた質問で品質が劣化していないか
これらは文字列の一致で判定できるものではなく、意味・内容レベルの評価が必要です。
そこで有効なのが、LLM-as-a-judgeというアプローチです。
あるLLMの出力を、別のLLM(または同じLLM)に評価させる手法で、関連性・期待回答との整合性・ハルシネーションの有無といった観点を人間のレビュアーと同じ要領で判定します。
スコアと判定理由を継続的に記録しておけば、プロンプトやモデル変更による品質劣化の検知にも活用できます。
本記事では、このアプローチを実践するOSSライブラリDeepEvalとAWS Bedrockを組み合わせ、Bedrock上のモデルを使ってLLMの回答品質を評価する構成を検証します。
DeepEvalとは
DeepEvalは、LLMアプリケーション向けの評価フレームワークです。
DeepEval by Confident AI - The LLM Evaluation Framework
pytestに近い感覚でテストケースを記述でき、出力に対してメトリクスを適用して品質を評価します。
基本単位は LLMTestCase で、ユーザー入力(input)・LLMの実際の出力(actual_output)・理想回答(expected_output)・検索コンテキストをひとつのオブジェクトにまとめます。
その上に評価メトリクスを組み合わせることで、RAG・チャットボット・エージェントなど幅広いユースケースに対応できます。
主な機能は以下のとおりです。
AnswerRelevancyMetricやFaithfulnessMetricなど、用途別の組み込みメトリクスGEvalによる独自評価基準の自然言語定義deepeval test runでのCI統合- スコアに加えて判定理由の取得
本記事では、このうち2つのメトリクスを使います。
AnswerRelevancyMetric で回答が質問に対して関連しているかを評価し、GEval で期待回答との一致度を独自基準で判定します。評価用LLMにはAWS Bedrock上のClaude Haiku 4.5を使用します。
セットアップ
仮想環境を作成し、依存パッケージをインストールします。また、環境変数ファイルのテンプレートをコピーしておきます。
python -m venv .venv
.\.venv\Scripts\python -m pip install -r requirements.txt
Copy-Item .env.example .env.local今回の検証で使った requirements.txt は以下です。
deepeval==3.9.9
aiobotocore==3.6.0
botocore==1.43.0
boto3==1.43.0
python-dotenv==1.2.2WindowsのPowerShellで実行する場合、DeepEvalの出力文字によってUTF-8エラーが発生することがあります。以下を事前に実行しておくと回避できます。
$env:PYTHONUTF8 = "1"環境変数の設定
.env.example にキーのテンプレートを定義しておき、.env.local に実際の値を記入します。Bedrockを呼び出すために最低限必要な設定は以下の2つです。
AWS_BEDROCK_REGION=ap-northeast-1
AWS_BEDROCK_MODEL_ID=jp.anthropic.claude-haiku-4-5-20251001-v1:0今回は東京リージョンで利用可能なClaude Haiku 4.5のJP inference profileを使用しました。
AWS認証情報(AWS_ACCESS_KEY_ID / AWS_SECRET_ACCESS_KEY)も .env.local に記載できますが、AWSプロファイルや実行ロールで解決できる環境であればそちらを推奨します。
DeepEvalの最小構造を確認する
Bedrockを呼ぶ前に、DeepEval単体の動作を確認します。ここではLLMもBedrockも使いません。
actual_output に固定値 "Tokyo" を入れ、期待値と一致するかをDeepEvalに判定させます。あわせて、正規表現で出力形式を確認する PatternMatchMetric のテストも同じファイルに含めています。
Pythonfrom deepeval import assert_test
from deepeval.metrics import ExactMatchMetric, PatternMatchMetric
from deepeval.test_case import LLMTestCase
def test_exact_match_metric_passes_without_llm_provider():
test_case = LLMTestCase(
input="What city is the capital of Japan?",
actual_output="Tokyo",
expected_output="Tokyo",
)
assert_test(test_case, [ExactMatchMetric()])
def test_pattern_metric_catches_output_contract_without_llm_provider():
test_case = LLMTestCase(
input="Return a support ticket id.",
actual_output="TICKET-12345",
)
assert_test(test_case, [PatternMatchMetric(pattern=r"^TICKET-\d{5}$")])各要素の役割は以下のとおりです。
| 要素 | 役割 |
|---|---|
input | ユーザーがLLMアプリに渡した入力 |
actual_output | LLMアプリが実際に返した回答 |
expected_output | 期待していた回答 |
ExactMatchMetric | actual_output と expected_output の完全一致を判定 |
PatternMatchMetric | actual_output が正規表現にマッチするかを判定 |
assert_test | メトリクスを適用し、しきい値を満たさなければテストを失敗させる |
以下のコマンドでテストを実行します。
$env:PYTHONUTF8 = "1"
.\.venv\Scripts\deepeval test run tests\test_local_deepeval.py実行結果は以下のとおりです。
2 passed in 1.47s
Test Results
Metric Score Status
Exact Match 1.0 PASSED
Pattern Match 1.0 PASSED
Pass Rate: 100.0% | Passed: 2 | Failed: 0DeepEvalのテストは、ざっくり次の3ステップで構成されます。
- LLMTestCase に入力、実際の出力、期待値を渡す
- 評価基準としてメトリクスを選ぶ
- assert_test でテストとして実行する
この型さえ掴めば、actual_output を実LLMアプリの回答に、メトリクスを AnswerRelevancyMetric や GEval に差し替えるだけで応用できます。
Bedrockを評価LLMとして使う
DeepEval側では AmazonBedrockModel を作り、メトリクスに渡します。複数のメトリクスから参照できるように、ヘルパー関数 _judge_model() としてまとめておきます。
Pythonimport os
from deepeval.models import AmazonBedrockModel
def _judge_model() -> AmazonBedrockModel:
model_id = os.getenv("AWS_JUDGE_MODEL_ID") or os.getenv("AWS_BEDROCK_MODEL_ID")
region = (
os.getenv("AWS_BEDROCK_REGION")
or os.getenv("AWS_REGION")
or os.getenv("AWS_DEFAULT_REGION")
)
if not model_id:
raise ValueError("Set AWS_JUDGE_MODEL_ID or AWS_BEDROCK_MODEL_ID.")
if not region:
raise ValueError("Set AWS_BEDROCK_REGION, AWS_REGION, or AWS_DEFAULT_REGION.")
return AmazonBedrockModel(
model=model_id,
region=region,
generation_kwargs={"temperature": 0, "maxTokens": 1024},
)※generation_kwargs の maxTokens は、DeepEval の AmazonBedrockModel が Bedrock Runtime の Converse API に inferenceConfig として渡すため、この表記にしています。
Anthropic の Messages API のリクエストボディでは max_tokens を使う場面がありますが、Converse API の inferenceConfig では maxTokens です。
モデルIDとリージョンはそれぞれ複数の環境変数をフォールバックとして参照しています。評価専用モデルを分けたい場合は AWS_JUDGE_MODEL_ID を、Lambda等の実行ロールで動かす場合は AWS_REGION や AWS_DEFAULT_REGION を使うことができます。
このヘルパーをメトリクスに渡すと、Bedrockを評価LLMとして使用できます。
Pythonfrom deepeval.metrics import AnswerRelevancyMetric
metric = AnswerRelevancyMetric(model=_judge_model(), threshold=0.7)AnswerRelevancyMetric は回答が入力に関連しているかを評価します。RAGの正確性まで確認したい場合は、retrieval_context を渡せる FaithfulnessMetric や ContextualRelevancyMetric も候補になります。
Bedrockを使った評価テストの中身
今回はLLMアプリから以下の回答が返ってきた、という前提で評価します。
actual_output = (
"DeepEvalをCIで使うメリットは、LLMアプリの品質劣化を自動検知できることと、"
"プロンプトやモデル変更時の回帰テストとして使えることです。"
)実運用では、RAG、チャットボット、エージェントなどの呼び出し結果を actual_output に渡します。
本記事では評価部分にフォーカスするため、固定文字列を評価対象にしています。
確認したいのは2点です。
1. 回答が質問に答えているか
AnswerRelevancyMetric は、回答が質問の趣旨に答えているかを評価します。
今回であれば「CIでDeepEvalを使うメリットを2つ」という問いに回答が直接答えているかどうかを判定します。文字列の一致は見ません。
Pythonfrom deepeval import assert_test
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
def test_bedrock_answer_is_relevant():
question = "DeepEvalをCIで使うメリットを2つ、日本語で短く教えて。"
actual_output = (
"DeepEvalをCIで使うメリットは、LLMアプリの品質劣化を自動検知できることと、"
"プロンプトやモデル変更時の回帰テストとして使えることです。"
)
test_case = LLMTestCase(input=question, actual_output=actual_output)
assert_test(
test_case,
[AnswerRelevancyMetric(model=_judge_model(), threshold=0.7)],
)2. 期待する要点を含んでいるか
GEval は独自の評価基準を evaluation_steps に自然言語で記述できるメトリクスです。完全一致ではなく「この観点が含まれているか」「矛盾していないか」といった意味レベルの判定に向いています。
Pythonfrom deepeval import assert_test
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase, SingleTurnParams
def test_bedrock_answer_matches_expected_points():
question = "DeepEvalとは何かを、テストケースとメトリクスという語を含めて日本語で1文で説明して。"
actual_output = (
"DeepEvalは、LLMアプリケーションの出力品質をテストケースとメトリクスで評価するための"
"Pythonフレームワークです。"
)
test_case = LLMTestCase(
input=question,
actual_output=actual_output,
expected_output="DeepEvalはLLMアプリケーションの出力品質をテストケースとメトリクスで継続評価するためのフレームワークです。",
)
correctness = GEval(
name="Correctness",
evaluation_steps=[
"actual outputがDeepEvalをLLMアプリケーション評価のフレームワークとして説明しているか確認する。",
"テストケースやメトリクスによる品質評価という要点が含まれているか確認する。",
"expected outputと矛盾する説明があれば大きく減点する。",
"判定理由は日本語で簡潔に説明する。",
],
evaluation_params=[
SingleTurnParams.ACTUAL_OUTPUT,
SingleTurnParams.EXPECTED_OUTPUT,
],
model=_judge_model(),
threshold=0.7,
)
assert_test(test_case, [correctness])このテストで見たいポイントは次の3つです。
- DeepEvalをLLMアプリケーション評価のフレームワークとして説明しているか
- テストケースとメトリクスによる品質評価という要点が入っているか
- 期待回答と矛盾していないか
つまり、Bedrockを使った評価テストは「評価対象の回答をDeepEvalに渡し、BedrockのClaude Haiku 4.5をjudgeとして採点させる」構成です。
生成側の実装に依存しないので、actual_output さえ用意できれば同じ形で評価できます。
実行
Bedrock用の環境変数を設定したら、以下のコマンドでテストを実行します。
$env:PYTHONUTF8 = "1"
.\.venv\Scripts\deepeval test run tests\test_bedrock_deepeval.py実行結果は以下のとおりです。
2 passed in 8.39s
Test Results
Metric Score Status
Answer Relevancy 1.0 PASSED
Correctness [GEval] 0.9 PASSED
Pass Rate: 100.0% | Passed: 2 | Failed: 0AnswerRelevancyMetric はスコア 1.0 で通過しました。質問で求められた「メリット2つ」に直接答えているため、関連性が高いと判定されています。
GEvalのスコアは0.9でした。DeepEvalをLLMアプリケーション評価のフレームワークとして説明できている点は評価された一方、期待回答にあった「継続評価」のニュアンスが実際の回答では弱く、その分が減点されています。
評価レポートを自作する
deepeval test run の出力だけでも便利ですが、CIやチーム共有を考えると、独自の形式でレポートを残したくなります。たとえば以下のようなMarkdownを生成しておけば、PRに貼ったりCIのartifactとして保存できます。
# DeepEval Evaluation Report
- Total: 2
- Passed: 2
- Failed: 0
| Test | Score | Threshold | Status |
| --- | ---: | ---: | --- |
| Answer relevancy | 1.0 | 0.7 | PASS |
| Correctness | 0.9 | 0.7 | PASS |実装方針は単純です。assert_test ではなくメトリクスの measure() を直接呼び、score・threshold・reason を取り出してMarkdownに整形します。
Pythonmetric = AnswerRelevancyMetric(model=judge_model, threshold=0.7)
metric.measure(test_case)
result = {
"score": metric.score,
"threshold": metric.threshold,
"success": metric.is_successful(),
"reason": metric.reason,
}今回の検証では scripts/generate_eval_report.py としてレポート生成スクリプトを用意しました。
$env:PYTHONUTF8 = "1"
.\.venv\Scripts\python scripts\generate_eval_report.py出力先は以下の2つです。
- reports/evaluation_report.md
- reports/evaluation_report.html
各テストの入力、評価対象の回答、期待回答、スコア、判定理由を含めています。
HTML版には、次の情報を入れました。
- total / passed / failed / average score のサマリー
- メトリクスごとのスコア棒グラフ
- score、threshold、status の一覧表
- 各テストの input、actual_output、expected_output、reason
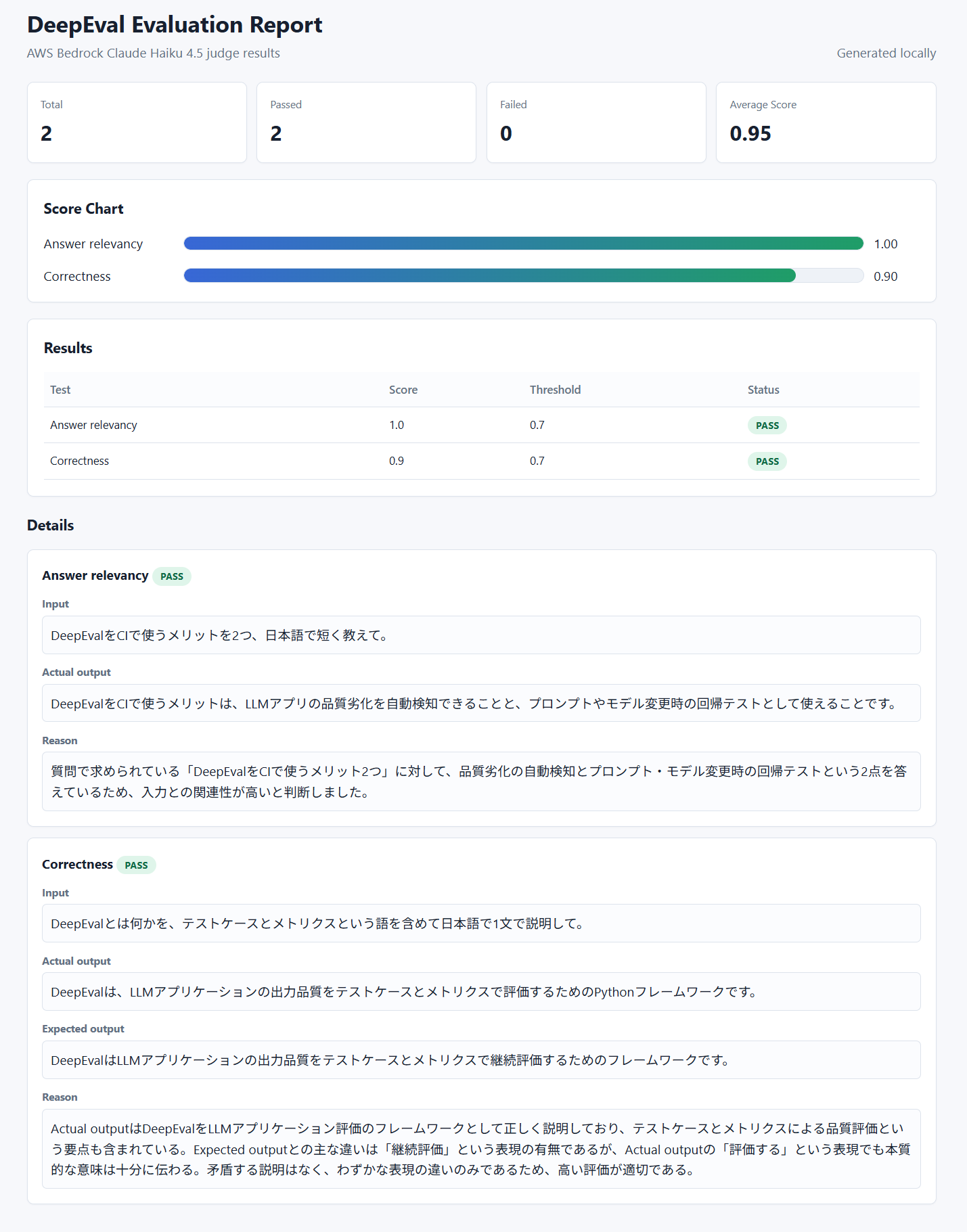
外部JavaScriptライブラリは使わず、単体のHTMLファイルとして出力します。CIのartifactに保存しておけば、あとからブラウザで評価結果を確認できます。
GEval の判定理由もレポートに記録できます。今回はレポートで読みやすいように、理由を日本語で出すようにしました。
Actual outputはDeepEvalをLLMアプリケーション評価のフレームワークとして
正しく説明しており、テストケースとメトリクスによる品質評価という要点も
含まれている。Expected outputとの主な違いは「継続評価」という表現の有無である。なお、AnswerRelevancyMetric の組み込みreasonは英語になりやすかったため、今回の自作レポートでは日本語の要約理由に置き換えています。運用では、チームが読みやすい形にreasonを整形して保存するのがよさそうです。
単に「0.9だった」という結果だけでなく、「なぜ満点ではなかったのか」を後から追跡できます。LLM評価をCIに組み込む場合、スコアだけでなくreasonの保存も重要だと感じました。
おわりに
今回の検証ではLLM評価を「なんとなく良さそう」から一段具体に落とせたと思います。
GEval の結果はスコア 0.9と、回答の方向性は正しいが「継続評価」のニュアンスが弱い、という判定でした。これは人間レビュアーが書くコメントとほぼ一致する内容で、reason をそのままプロンプト修正の根拠として使える形になっていました。pass/failだけでなく差分が言語化されることが、LLM-as-a-judgeを実用的にしている核心だと感じます。
一方で、DeepEvalを入れたからといって、評価設計まで自動化されるわけではありません。何を「良い回答」とするかはユースケース次第で、GEval の evaluation_steps に書く評価基準が曖昧であれば判定も曖昧になります。メトリクスは評価の実行を担いますが、評価設計そのものは依然として人間の仕事です。
実運用に乗せる前に意識しておきたい点が3つあります。
自己評価バイアス
生成側とjudge側が同系統のモデル(たとえば両方Claude)だと、judgeが甘めに評価する傾向が出る可能性があります。
可能であればモデルの系統を分けるか、人手レビューと突き合わせて判定の傾向を事前に確認しておくことを推奨します。
コストとレイテンシ
judgeにBedrockを使うと、テストケースが増えるほどAPI料金とCI実行時間が線形に伸びます。
今回は2テストで約10秒でしたが、100テスト規模ではCIで数分単位になります。ローカルLLMを使用する、代表質問セットを定期実行する運用と、PRごとに走らせる最小セットを分けるなど、段階を分けた設計が現実的です。
CIへの組み込み方
最初から全テストをブロッカーにするのは現実的ではありません。
まずレポートを保存してスコアの傾向を眺め、納得できるしきい値を見極めてから段階的にゲートに昇格させる進め方が扱いやすいです。
HTMLレポートを自作した理由もここにあります。スコアだけではLLM評価の妥当性は判断できません。入力・実際の回答・期待回答・reason を並べて読んで初めて、「この判定は信頼できる」「評価基準を直したほうがいい」が分かります。DeepEvalは評価の実行を担い、レポートは自分たちの運用に合わせて作るといった分担が、長期的に運用を続けるうえで最も現実的な形だと考えています。
参考










![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
