


 2026-04-21
2026-04-21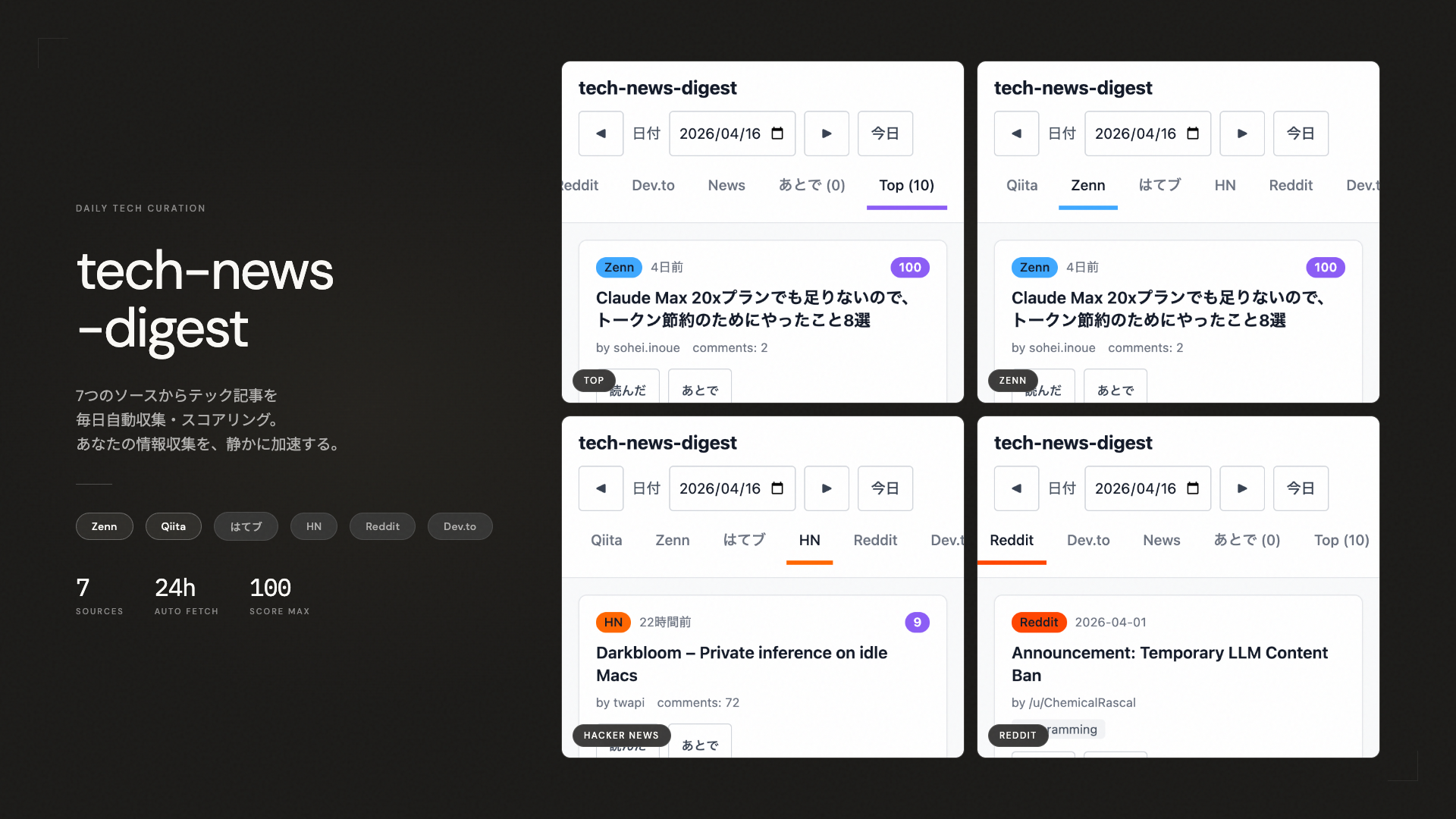

こんにちは、中島です。
こちらの記事(Claude Codeで自分好みの朝刊が届く仕組みを作った) で Claude Code + Python を使って毎朝の技術ニュースを自動収集する仕組みが紹介されていて、めちゃくちゃ良かったので自分でも作りました。
元記事は Markdown テーブルに出力する形でしたが、僕は朝の電車でスマホで読みたかったので Web アプリにして、さらにスコアリングや UI の設計書を書いてガチ作り込んだりもしました。
今回作ったもの
システム構成
| 層 | 技術 | 役割 |
| 収集 | Python 3 標準ライブラリのみ | 7 ソースから RSS / HTML を取得しパース |
| 保存 | git コミット済み static JSON | 日付単位 data/YYYY-MM-DD.json |
| 配信 | Vite 5 + React 18 + TypeScript + Tailwind 3 | SPA、`vite build` が 441 ms |
| スケジュール | GitHub Actions の schedule cron | 毎朝 6 時 JST に収集 |
| ホスト | Vercel 無料枠 | git push で自動デプロイ |
Python 側は外部ライブラリゼロで urllib と xml.etree.ElementTree だけです。
SPA 側も fetch 1 本で動くので、ルーティングも状態管理ライブラリも導入していません。
元記事をベースとした部分、変更点
元記事 の「ソースを Group A/B/C に分けてブロック対策する」構造や、Reddit / YouTube は Python スクリプトに逃がすアイデアはそのまま使わせてもらっています。
変えたのはこの辺です。
| 元記事 | 自分の実装 | 理由 |
| Markdown 出力 | JSON → React SPA | スマホで読みたかった |
| launchd で毎朝実行 | GitHub Actions cron | マシン起動に依存したくなかった |
| Claude Code の WebFetch で取得 | Python 標準ライブラリのみ | GHA で Claude Code は実行できない |
| 6 ソース | 7 ソース + Top 10 + あとで読む | Google News 追加、スコアリングで Top 抽出 |
Next.js は使っていません。更新は 1 日 1 回で動的コンテンツもないので、Vite の build で十分です。
テストは先に書いて、実装と分けた
Claude Code に実装を任せるときに怖いのは、テストを通すためだけの嘘実装ができてしまうことです。
ダミーデータで埋めたり、assert を弱めたり、skip を入れたりするパターン。
対策として、テスト設計と実装担当を物理的に分けて、最後にクロスレビューするフローにしています。
- テスト設計担当がテストとスケルトンを先に書く
- 僕がテスト観点をレビュー
- 実装担当がテスト全 PASS するまで書く。テストファイルには触らない
- テスト設計担当がクロスレビュー。テストファイルの mtime が自分の作業時刻で止まっているかを確認する
Python 側 99 テスト、Web 側 35 テスト、合計 134 テストで固めました。
mtime ベースの検証は地味ですが、テスト詐欺の検出にはこれで十分です。
業務でレビューが形式的になりやすい体制でも、テストを書く人と実装する人を分けるだけで品質が変わると思います。
つまずいた箇所 3 点
1つ目:YouTube の channel ID が本番で 404
元記事にもあった YouTube RSS フィードの収集で、ハードコードした channel ID が 404 を返してきました。
最初は 1 channel 失敗でソース全体が死ぬ構造だったので、channel 単位で try/except を貼って、失敗したら stderr にログ吐いて次へ進む形に直しました。
外部 API や外部 feed は単品で死ぬ前提で設計するのが鉄則です。
2つ目:JST の日付が 1 日ずれた
getTimezoneOffset()で日付を組み立てたところ JST ブラウザで 1 日ずれました。
Intl.DateTimeFormat('en-CA', { timeZone: 'Asia/Tokyo' }) に差し替えて解消しました。
toISOString().slice(0, 10) は UTC 基準なので 23 時台に前日を拾ってしまいます。
業務コードでも「今日の YYYY-MM-DD が欲しい」ときは Intl.DateTimeFormatを第一候補にしておくと安全です。
3つ目:Vercel のモノレポ対応
リポジトリルートに Python、web/ に Vite プロジェクトという構成だと Vercel のデフォルト検出で build が落ちます。
vercel.json で installCommand と buildCommand を cd web && ... にして、outputDirectory を web/dist に指定するだけで直りました。
ここから拡張:スコアリングと UI をガチで作り込んでみた
毎朝使い始めて、7 ソース 200 件超の記事が並ぶと『全部見る気にならないこと』に気づきました。
「自分に関係ある記事だけ見たい」ので拡張を入れました。
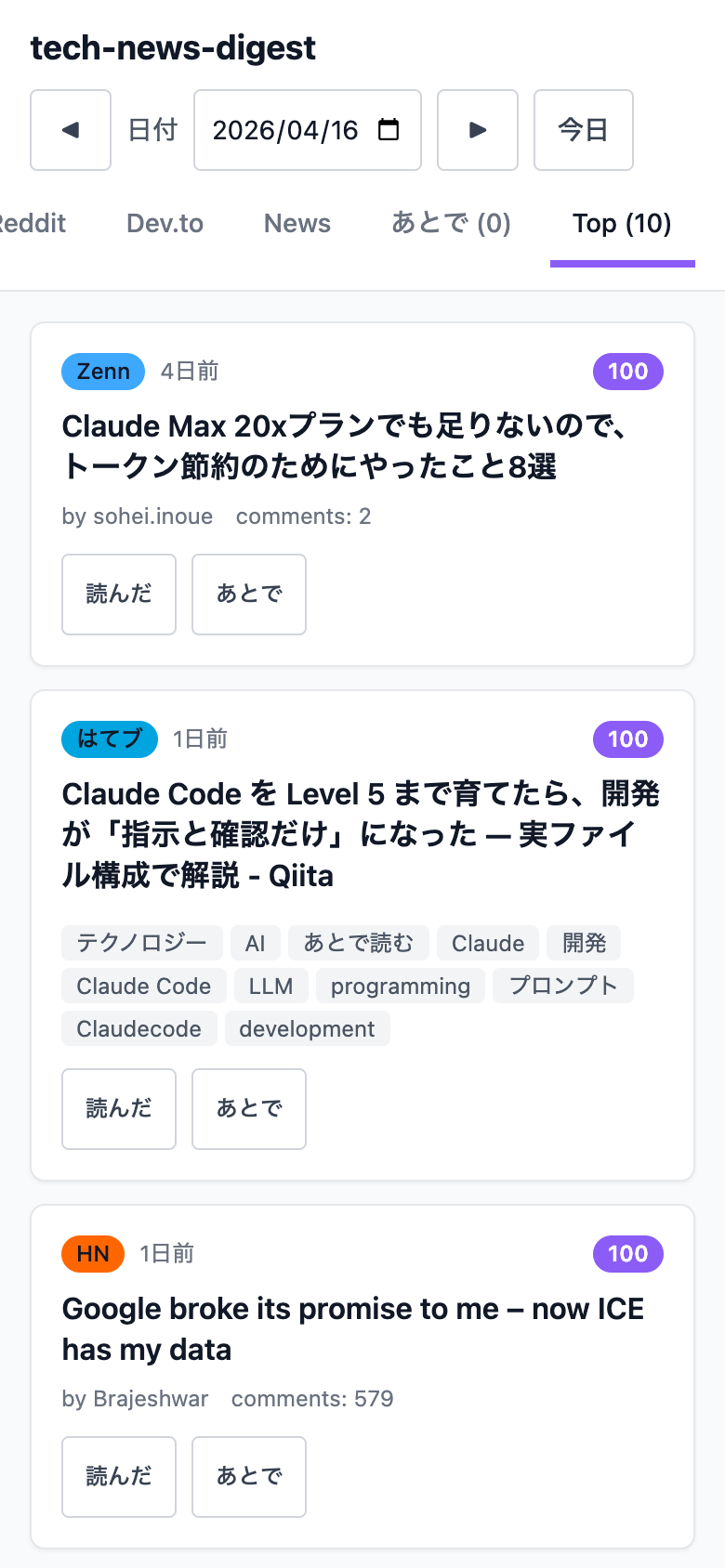
作り込みポイント①:スコアリング + Top 10
各ソースのスコア(Qiita の likes_count、HN の points、はてブの bookmark 数)をソースごとに min-max 正規化して 0-100 に揃え、全ソース横断で Top 10 を抽出。
UI には Top タブとスコアバッジを追加しました。
作り込みポイント②:興味キーワードブースト
自分の興味あるキーワード(Claude Code, React, AI, LLM, TypeScript など 18 語)にマッチしたらスコアに +15。
Top 10 のうち 6 件が自分の興味にマッチするようになりました。
作り込みポイント③:設計書を書いてからリデザイン
800 行の docs/design.md を書いて、Google News / Zenn / Daily.dev / Hacker News の 4 サイトを分析してからリデザインしました。
カラーシステム・タイポグラフィ・a11y・ダークモード方針を決めてから実装に入る形です。
設計書を書くのは楽しかったんですが、「書いた通りになっているか」を Puppeteer で検証するのが一番しんどかったです。
作り込みポイント④:「あとで読む」
朝の電車で気になる記事を localStorage にマークしておく機能。全ソース横断で「あとで」タブに集約されます。
業務でも使えそうなポイント
- 動的コンテンツが不要なら、静的 JSON + SPA で十分か検討する
- 収集層と配信層を分離しておくと差し替えやすい
- テスト設計と実装担当を分けるだけでテスト詐欺対策になる
- 外部 API / feed は単品で死ぬ前提で try/except を入れる
- デプロイが「git push で 1 発」になる構成を選ぶ
まとめ
元記事の「自分好みの朝刊」というコンセプトをもらって、スマホで読める Web アプリにして、スコアリングで情報量を絞って、設計書書いて UI をちゃんと作りました。
200 件の記事を全部並べても誰も読まないので、Top 10 + 興味ブーストで「自分に関係ある 10 件」に絞って、それをスマホで気持ちよく読める UI にする。ここまでやって初めて毎朝開くサイトになった感覚があります。
テストは最終的に 85 件まで増えて全 PASS。Claude Code にテスト設計と実装を分けて書かせるフローは、業務のプロトタイピングでも使えると思います。
参考サイト:











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
