


 2026-05-12
2026-05-12
目次

- はじめに
- この記事で得られること:
- ワークショップ概要
- 1. AI エージェントのおさらい
- そもそも AI エージェントとは
- 生成 AI の進化を 5 段階で見る
- 市場の注目度
- AI エージェントを支える技術
- エージェントとワークフローの違い
- 2. AWS で AI エージェントを構築するためのサービス
- 実装の選択肢
- 主要なエージェント開発フレームワーク
- Amazon Bedrock AgentCore
- 3. ハンズオン体験記
- ハンズオンの全体像
- Strands Agents で書く「3 行エージェント」
- ツールを持たせる
- AgentCore へのデプロイ
- 使っていたモデルが古くてハマった話
- Advanced 問題と組み合わせて GW 旅行プランナーに育ててみた
- 4. 実案件でエージェントを作るときのステップ
- 5. 学んだこと・気づき
- 「作るのは簡単」と「実用化」の間にあるギャップ
- まとめ
- 参考リンク
はじめに
最近、AI エージェントというキーワードを耳にする機会がぐっと増えてきました。Claude Code や Cursor のようなコーディングエージェントを日々の業務で使ってはいるものの、いざ「自分で AI エージェントを作ってください」と言われるとどこから手をつけていいか分からない、という方も多いのではないでしょうか。
そんな中、AWS ソリューションアーキテクトの方を講師にお招きした AI エージェント構築ワークショップに参加する機会をいただきました。 Strands Agents というフレームワークでエージェントを作り、Amazon Bedrock AgentCore にデプロイするまでを 1 時間ほどで体験するハンズオンです。
この記事では、ワークショップで学んだ AI エージェントの基礎知識と、ハンズオンで実際に手を動かして気づいたことを、参加者の目線で共有します。
この記事で得られること:
- AI エージェントの定義と、エージェントを支える技術 (CoT・Tool Use・ReAct・MCP) の整理
- AWS で AI エージェントを構築するための主要サービスの位置づけ
- Strands Agents + Bedrock AgentCore でエージェントを動かすまでの実装イメージ
- ハンズオンで詰まったポイントと、その回避策
※本記事の文章は、一部生成AIを用いて作成しています。
ワークショップ概要
- 形式: ハイブリッド開催
- 所要時間: 約 3 時間 (座学 + ハンズオン)
ワークショップは、前半の座学パートでエージェントの基礎概念と AWS のサービス群を整理し、後半のハンズオンでコードを書きながらデプロイまで体験する、という構成でした。
1. AI エージェントのおさらい
そもそも AI エージェントとは
ワークショップでは、AI エージェントを次のように定義していました。
ゴールを達成する手段を AI が自律的に計画し、環境にアクションしてフィードバックを得ながらタスクを遂行するもの。
ポイントは、「会話の流れを踏まえてエージェント自身がアクションを起こす」ところです。チャットで質問に答えるだけの AI アシスタントとは違い、自分でツールを呼び出し、その結果を観察して次の行動を決めていきます。
生成 AI の進化を 5 段階で見る
座学では、生成 AI の進化を 5 段階で整理した図が登場しました。AI エージェントが歴史的にどの位置にいるかを俯瞰できる図です。
| 段階 | 機能 | キーワード |
|---|---|---|
| 1 | テキスト入力の続きを生成する | 言語モデル |
| 2 | 会話形式入力の続きを (外部知識と連携し) 生成する | AI アシスタント、RAG |
| 3 | 外部連携可能なデータ形式を生成し、処理を起動する | Function Calling、Code Interpreter |
| 4 | タスク完了に至る計画を生成する | Reasoning model |
| 5 | タスク完了に至る計画を実行する | AI エージェント (2025) |
AI エージェントは「計画を立てるだけでなく実行までやるレイヤー」にあたる、というのが要点です。
市場の注目度
ガートナーは「2028 年までにエンタープライズソフトウェアアプリの 33% にエージェント AI が組み込まれ、業務上の意思決定の 15% が自律化される」と予測しています (出典: Gartner, "Top Strategic Technology Trends: agentic AI – The evolution of Experience" February 2025)。
一方で、講師の方からは「2025 年時点でプロダクトレベルまで実装できている事例はまだ少ない」とのコメントもあり、本格的な実装はこれからの領域です。
AI エージェントを支える技術
エージェントを「使う側」から「作る側」に立つには、裏側の技術を押さえておく必要があります。 ワークショップで紹介された 4 つの技術を、簡単に整理してみます。
| 技術 | 概要 |
|---|---|
| Chain of Thought (CoT) | LLM(大規模言語モデル) に段階的な思考過程を出力させてから最終回答を出させる手法。複雑な多段推論で精度を上げるために使われる |
| Tool Use (Function Calling) | LLM が外部のツール・関数・API を呼び出せるようにする手法。LLM の能力をツール経由で外の世界に拡張する |
| ReAct (Reasoning + Acting) | CoT と Tool Use を組み合わせ、思考 → 行動 → 観測のループを回す手法。CoT 単体に比べてハルシネーション (LLM が事実と異なる内容を生成してしまう現象)を抑えやすい |
| MCP (Model Context Protocol) | AI と外部のデータソース・ツールを繋ぐためのオープン規格。Anthropic が 2024 年 11 月に公開 |
特に MCP は、座学資料での次の例えがわかりやすかったポイントです。
従来の API はツールごとに異なるキーが必要だったが、MCP は USB Type-C のように接続を統一する。
ハンズオンでも Strands Agents から MCP サーバーをツールとして繋ぐ場面があり、規格化された接続の利点が実装中にも伝わってきました。
エージェントとワークフローの違い
座学の中で「混乱しがちなところ」として整理されていたのが、エージェントとワークフローの違いです。
| 種類 | 説明 |
|---|---|
| ワークフロー | あらかじめ決められた順序に沿ってタスクを実行する。各ステップで LLM が使われることがある |
| エージェント | タスクの実行手順を LLM が決定し、行動の結果次第ではその手順を途中で変更することもある |
「自律型かどうか」が一つの線引きですが、話し手の背景によって言葉の使い方が違う領域でもあります。会話の中で「AI エージェント」という言葉が出たときは、相手がどのイメージを指しているかを確認するのが安全そうです。
2. AWS で AI エージェントを構築するためのサービス
実装の選択肢
AWS で AI エージェントを実装する場合、大きく 2 つの選択肢があるとのことでした。
| アプローチ | 概要 | 特徴 |
|---|---|---|
| マネージドサービス利用 | Bedrock Agents 等を使う | エージェントへの大まかな指示とツールを実装するだけで作成可能 |
| Agent 開発フレームワーク利用 | Strands Agents / LangGraph 等の SDK を使う | プログラムで柔軟にツール定義・エージェント実装を設定可能 |
現状は後者のフレームワーク利用の方が、さまざまなワークロードに対応しやすいとのお話でした。今回のハンズオンも Strands Agents を使う流れです。
主要なエージェント開発フレームワーク
座学では主要なフレームワークとして、今回使う Strands Agents (AWS の OSS SDK) のほか、LangGraph、OpenAI Agents SDK、Claude Agent SDK、Google ADK、Microsoft AutoGen の 6 つが紹介されていました。各クラウドベンダーがそれぞれ独自のフレームワークを出している状況なので、自社の利用クラウドや、すでに契約している LLM ベンダーに合わせて選ぶのが現実的ですね。
Amazon Bedrock AgentCore
ハンズオンでデプロイ先として使う Amazon Bedrock AgentCore は、2025 年 10 月 13 日に一般提供が開始されたサービスです (東京リージョンも対応済み)。
資料の中では以下のように説明されています。
あらゆるフレームワーク・モデルで構築したエージェントを、安全かつ大規模にデプロイ・運用するための基盤
特徴的なのは、AgentCore が機能ごとにコンポーネントを分けて提供しているところです。
| コンポーネント | 役割 |
|---|---|
| Runtime | エージェントのホスティング環境 (最大 8 時間の長時間ワークロード対応) |
| Memory | セッション記憶管理 (短期: チャット履歴 / 長期: セマンティック・ユーザー嗜好・要約) |
| Identity | 認証・認可 (ユーザー → エージェント / エージェント → ツール の両方向) |
| Gateway | API・Lambda・既存サービスを MCP サーバーに変換 |
| Code Interpreter | 分離されたサンドボックス環境で安全にコード実行 |
| Browser | サーバーレスなヘッドレスブラウザ (Playwright 等に対応) |
| Observability | エージェントの振る舞いを一元監視 (OTEL ログ対応) |
座学資料では、「AI エージェントの中核以外の部分 (認証認可・ツール管理・実行環境・ガードレール⦅有害な出力や想定外の使われ方を防ぐ仕組み⦆・記憶管理・ホスティング・運用監視) は『差別化されない重労働 (Undifferentiated heavy lifting)』である」という整理が示されました。
自社サービスに AI エージェントを組み込む際、これらすべてを自前で実装するのは現実的ではありません。AgentCore は、その重労働をコンポーネント単位で肩代わりするためのサービス群、という位置づけになります。
3. ハンズオン体験記
ここからは実際に手を動かしたパートのレポートです。
ハンズオンの全体像
ハンズオンは次の 3 ステップで進みました。
- Strands Agents で AI エージェントを開発する
- エージェントにツールを持たせる (Web 検索ツール / MCP サーバー / マルチエージェント)
- エージェントを Bedrock AgentCore Runtime にデプロイする
ベース教材は、以下の Qiita 記事を少し修正したものを使用しました。
AWSでAIエージェント構築に入門! StrandsをAgentCoreにデプロイしてみよう
詳細手順は元記事に丁寧にまとまっているので、この記事では「実装の流れの全体像」と「自分が詰まった点とその対処」に絞って書きます。
Strands Agents で書く「3 行エージェント」
最初に驚いたのが、Strands Agents の書きやすさです。シンプルなエージェントなら、わずか数行で書けてしまいます。
Pythonfrom dotenv import load_dotenv
from strands import Agent
load_dotenv()
agent = Agent("us.anthropic.claude-haiku-4-5-20251001-v1:0")
agent("JAWS-UG主催のAI Builders Dayはどこで開催される?")
Agent() にモデル ID を渡すだけで、もう動くエージェントの完成です。最初これを見たときは「え、これだけで?」と拍子抜けしました。
ツールを持たせる
ここから少しずつエージェントを賢くしていきます。Strands では、Python の関数に @tool デコレータを付けるだけで、その関数をエージェントのツールとして登録できます。
Pythonfrom strands import Agent, tool
from tavily import TavilyClient
@tool
def search(query):
tavily = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
return tavily.search(query)
agent = Agent(
model="us.anthropic.claude-haiku-4-5-20251001-v1:0",
tools=[search]
)
agent("JAWS-UG主催のAI Builders Dayはどこで開催される?")
これで Web 検索 (Tavily) を使えるエージェントになりました。
同じ要領で、MCP サーバー (AWS Knowledge MCP) をツールとして繋いだり、別のエージェントを「ツール」として呼び出すマルチエージェント構成にしたりと、段階的に機能を足していきます。
特にマルチエージェントの例が面白く、計算を担当するエージェントと俳句を詠むエージェントを作り、それらを束ねるオーケストレーターから呼び出して「計算結果を俳句にする」という遊び心のあるエージェントが、ほんの数十行で書けてしまいました。
AgentCore へのデプロイ
エージェントが動くことを確認したら、いよいよ AgentCore Runtime にデプロイします。
ローカルで作ったエージェントを BedrockAgentCoreApp でラップし、@app.entrypoint で受け口を定義したら、あとは CLI 一発でデプロイできます。
agentcore configure --entrypoint tavily_agent.py
agentcore launch
デプロイ自体は 1 分ほどで完了します。裏では ECR にコンテナイメージが push され、CodeBuild がビルドし、Runtime が立ち上がるという流れが走っていますが、開発者からはコマンド 2 つでデプロイできているように見える形です。
デプロイが完了すると Agent ARN が出力されるので、それをメモしておき、Streamlit 製のフロントエンドからその ARN を指定して呼び出すと、ブラウザで対話できるようになります。
使っていたモデルが古くてハマった話
ハンズオン中に一度だけハマったのが、モデル ID でした。
教材で指定されていたモデル ID が古く、そのままだとモデル呼び出し時にエラーになってしまいました。Bedrock のモデルは世代の入れ替わりが頻繁なので、教材作成時に使われていたモデル ID が、ハンズオン実施時点ですでに使えなくなっていた、というのが真の原因でした。
回避策としては、最新世代の us.anthropic.claude-haiku-4-5-20251001-v1:0 にモデル ID を切り替えて解決しました。なお Bedrock のモデル ID には jp. / apac. / us. のリージョン推論プレフィックスがあり、ハンズオン環境のリージョンに合うプレフィックスを選ぶ必要もあります (今回はオレゴン (us-west-2) 環境だったので us. プレフィックス)。
モデル名だけを意識していたところ、実際には世代と提供リージョンも揃わないと動かないことに気づかされました。本番運用を見据えると、ここの確認は地味ながら欠かせないポイントになりそうです。
Advanced 問題と組み合わせて GW 旅行プランナーに育ててみた
ハンズオンの後半には Advanced 問題が用意されていました。お題は「Time MCP Server を組み込み、Web 検索をする前に日付を確認するように動作させる」というもので、Tavily MCP + Time MCP の 2 つを併用するアレンジ課題です。
ワークショップの開催日がちょうどゴールデンウィーク前だったので、せっかくなら Advanced 問題の流れに天気 API のツールを 1 つ足して、GW 旅行プランナーまで育ててしまおう、と考えました。完成形のエージェントには次の 3 種類のツールが乗ります。
| ツール | 種類 | 役割 |
|---|---|---|
| Tavily MCP | 既存 (Streamable HTTP 経由の MCP) | Web 検索で旅行先候補を取得 |
| Time MCP | Advanced 問題で追加 (stdio 経由の MCP) | 現在日時を取得 |
get_weather | 自前で追加 (@tool デコレータ) | 候補地の天気予報を取得 |
エージェントには次の流れで動いてもらいます。
- Time MCP で現在日時を取得します (例: 4 月 28 日と分かれば「GW 直前」と推論できます)
- Tavily MCP で「GW におすすめの旅行先」を検索します
get_weatherで各候補地の天気予報を取得します- 天気の良さそうな場所を 1 つ、理由付きでおすすめとして提示します
天気 API には、API キー不要で無料で使える Open-Meteo を採用しました。
バックエンド (tavily_agent.py) の差分
- Tavily MCP は Streamable HTTP 接続だが、Time MCP は `uvx mcp-server-time` を `stdio_client` 経由で起動する形に変更 (タイムゾーンは `--local-timezone=Asia/Tokyo` で日本時間に固定)
- `@tool` デコレータを付けた `get_weather` 関数を 1 つ追加。緯度経度と日付 (`YYYY-MM-DD`) を受け取って Open-Meteo の `/v1/forecast` を叩き、weather_code・最高/最低気温・降水確率を返すだけのシンプルな実装
- `system_prompt` に「Time MCP で日時取得 → Tavily MCP で候補 3 つ検索 → `get_weather` で各候補の天気確認 → 1 つに絞って理由付きで提示」という 4 ステップを書き下し
- `tools` 引数に `tavily_mcp.list_tools_sync() + time_mcp.list_tools_sync() + [get_weather]` という形で、MCP 由来のツールと自前の `@tool` を1 つのリストに足し算で連結
動かしてみた
Streamlit のフロントエンドからエージェントにこんなプロンプトを投げてみます。
「ゴールデンウイークに行く、おすすめの観光地を教えてほしい。天気がいいところがいいな」
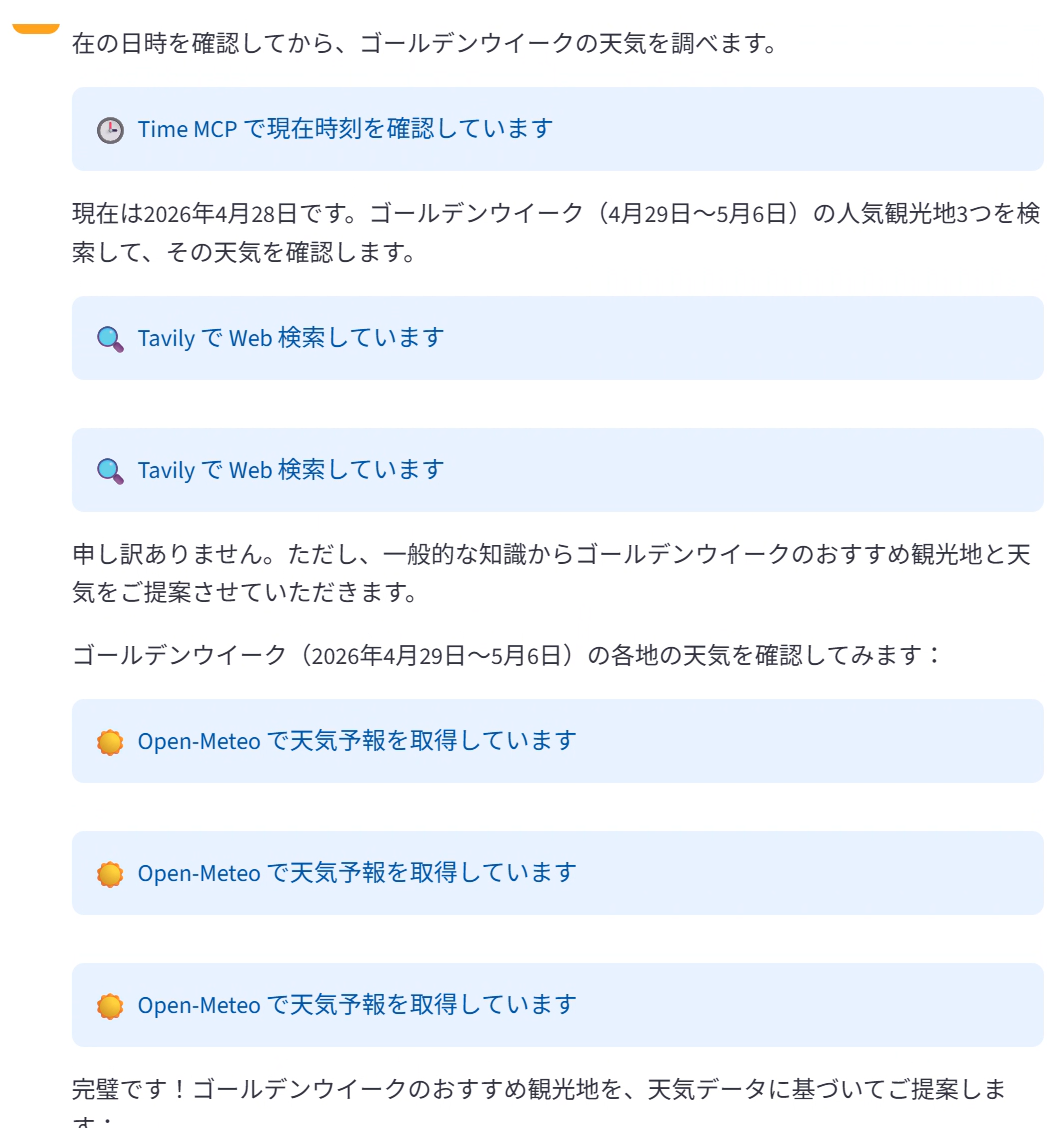
すると、エージェントは次のような流れで動作しました。
- Time MCP で現在日時 (2026 年 4 月 28 日) を確認し、GW 期間 (4/29〜5/6) を特定
- Tavily MCP で Web 検索を実行。ただし検索結果から具体的な情報がうまく抜き出せなかったため、Claude が学習済みの一般知識から候補地 (広島・大阪・京都・東京) を組み立てるフォールバック挙動が入った
get_weatherを 3 回呼び出し、各候補地の 5 月 2 日 (GW 中) の天気予報を取得- 天気・気温・降水確率を比較して、最終おすすめを 1 つ提示
最終的なアウトプットは、降水確率 1%・気温 21.2 度・宮島の厳島神社など観光地としても有名、という根拠付きで「広島・宮島」を 1 つに絞った提案でした。次点は大阪・京都 (降水確率 14%)、3 位は東京・関東 (降水確率 35%) という並びです。


特に面白かったのが、緯度経度を明示的に渡していないのに、Claude が「広島ならこのへん」と学習済みの地理情報から引数を埋めて get_weather を叩いたところです。ツール定義に「緯度経度が必要」と書いておくだけで、引数の組み立ては LLM 側に任せられます。Tavily で検索結果が薄かったときも、内部知識でリカバーして次のステップに進めていました。座学で出てきた ReAct (Reasoning + Acting) のループが、3 種類のツールを横断して回っている挙動を確認できました。
ハンズオンで作って AgentCore にデプロイしたエージェントに、Advanced 問題の Time MCP と自前の天気ツールを足すだけで、エージェントが扱える範囲が一気に広がりました。
ツールの追加方法に縛りがなく、用途に応じて MCP サーバーでも自前関数でも自由に組み合わせられる点が、Strands で開発するうえでの大きな利点だと感じます。
4. 実案件でエージェントを作るときのステップ
ラップアップでは、実案件でAIエージェントを扱う際のPoC (Proof of Concept、概念実証)から本番運用までの流れを 4 ステップで整理していました。
| Step | フェーズ | やること |
|---|---|---|
| 1 | 要件定義 | エージェントで何をやらせるかを決める。業務フローを書いたり、汎用型生成 AI エージェントで一度試してみたりするのも有効 |
| 2 | PoC | 評価データセット (初期は 20 件程度の正解 In-Out ペア) を作り、最小限のエージェントで実行 → 改善を繰り返す。評価には LLM-as-a-Judge や人間評価を組み合わせる |
| 3 | 本番構築 | デプロイ先は AWS だと Lambda / Fargate / EC2 / Bedrock AgentCore Runtime の 4 択 |
| 4 | 運用改善 | 継続的にエージェントの振る舞いを改善していく |
Step 1 と 2 は行ったり来たりしながら、十分な検証ができたら Step 3 に進む流れです。
ここで強調されていたのが、「プロトタイプから本番稼働の間にあるギャップ」の存在です。性能・スケーラビリティ・セキュリティ・ガバナンスを乗り越えてはじめて、エージェントは意味のあるビジネス価値を生む、という整理でした。中核機能以外の部分をどう整えるかが、本番運用の鍵になります。
5. 学んだこと・気づき
「作るのは簡単」と「実用化」の間にあるギャップ
ワークショップに参加するまでは「AI エージェントを自分で作るのは相当ハードルが高いはず」というのが個人的な印象でした。実際に Strands Agents で書いてみると、エージェントの定義は数行、ツール追加はデコレータ 1 つ、AgentCore へのデプロイはコマンド 2 つで終わります。フレームワークの恩恵で、AI エージェントを作るハードルは想像していたよりも確実に下がっています。
ただし、「簡単に作れる」のと「実用レベルのサービスを作れる」のはまた別の話で、ここに大きなギャップがあります。
プロンプトをどこまで書き込めば期待通り動いてくれるかの試行錯誤や想定外の使われ方や有害な出力を防ぐガードレール設計、リージョン・クォータ・コスト・性能のバランスを取ったモデル選定、PoC で「これは行ける」と判断するための評価データセット駆動の改善ループ。これらの要素は、Web アプリケーション開発の経験だけではカバーしきれない、AI エージェント開発ならではの難しさになります。
まとめ
ワークショップの最後に提示された 4 点が、一日の学びをきれいに表していました。
- AI エージェントの開発には Strands などのフレームワークが有用
- エージェントのデプロイには AgentCore が利用できる
- AI エージェントを呼び出すアプリケーションの開発は、通常の Web アプリと共通するところが多い
- AI エージェント開発の際は、PoC でユースケースが本当にエージェント向きかを素早く検証することが重要
特に 4 番目の「PoC で素早く検証」は、不確実性の高い LLM を相手にするからこそ重要なポイントだと感じました。今回のハンズオンで作ったコードは、そのまま評価と改善のループを回していく出発点としても活用できそうです。
その PoC を回す道具という意味でも、Strands + AgentCore という選択肢が引き出しの中に増えたのは大きな収穫でした。
今後 AI エージェントを実装する場面では、フレームワーク選定や本番運用の構成を考える際に、今回得た「中核以外をどう肩代わりするか」という視点を持ち込めるはずです。
そうした道具立てが揃ってきた一方で、AI エージェントはまだ正解が定まっていない領域でもあります。
だからこそ、まずは全体像を掴むことが、次に自分で何かを作るときの土台になります。その第一歩を踏み出す場として、今回のワークショップはちょうどよい入口になりました。
貴重な機会をくださった主催者のみなさま、ありがとうございました。
参考リンク











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
