




こんにちは。FIXER M&S 竹中です。 また新たなシリーズを始めさせて頂きたいと思います。書き溜めはないので不定期掲載になるかと思いますが、少しでも楽しんでいただければ幸いです。
さて、私はかつてこんな連載をしておりました。読んで字のごとく2019年2月~5月にかけて120時間ほどをPyQというWebサービスを自腹で使ってPythonを習っておりました(ちなみにPyQは3,000円/月程度のコストなので自腹というほどでもない)。このシリーズにおいて自分的に楽しめた分野がデータマイニングでしたので、目標を作る意味でもデータサイエンスの梁山泊ことKaggle(読みは「カグル」)に挑戦したいと思います。
1.まずは開発環境を整えよう
カグりに行く前にまずは言語と開発環境を選びましょう。私は言語は当然Pythonです。そしてピュアPythonで全開発をすることは不可能なのでデータサイエンスに必要なライブラリも入れておきましょう。Pythonのライブラリは多種類かつ強力なので助かります。ライブラリもpipというコマンドで一つ一つ入れることもできますが、今のデファクトはAnacondaを使うことです。Anacondaはデータサイエンス用の基本的なライブラリの詰め合わせで、かつ専用のコマンドでライブラリを追加することもできます。ライブラリの管理も容易になりますので、特に宗教上の理由でもない限りお勧めします。
また、環境を清浄に保つためにローカルのDockerを導入してからAnacondaを入れる方法もありますが、めんどくさかったので諸般の事情で割愛しました。普通にローカルに入れております。
コマンドプロンプト -> conda list でライブラリ一覧を見たところ。特に追加していないのに大量のライブラリが一発で!
2.エディタを選ぼう
さて、Anacondaの導入が終わったら次はエディタを選びましょう。私はMicrosoftのVisual Studio Code(以下、VSCode)を選びました。VSCodeは取り回しが軽くシンプルで、同じマイクロソフト製品のAzureやGitとも高相性な素晴らしいIDEです!(熱いステマ)
「なんだかんだで利用者多いですし、実際便利ですよ」と信頼する後輩から言われたので信じて使っています。今のところ快調です。MSさんありがとう。
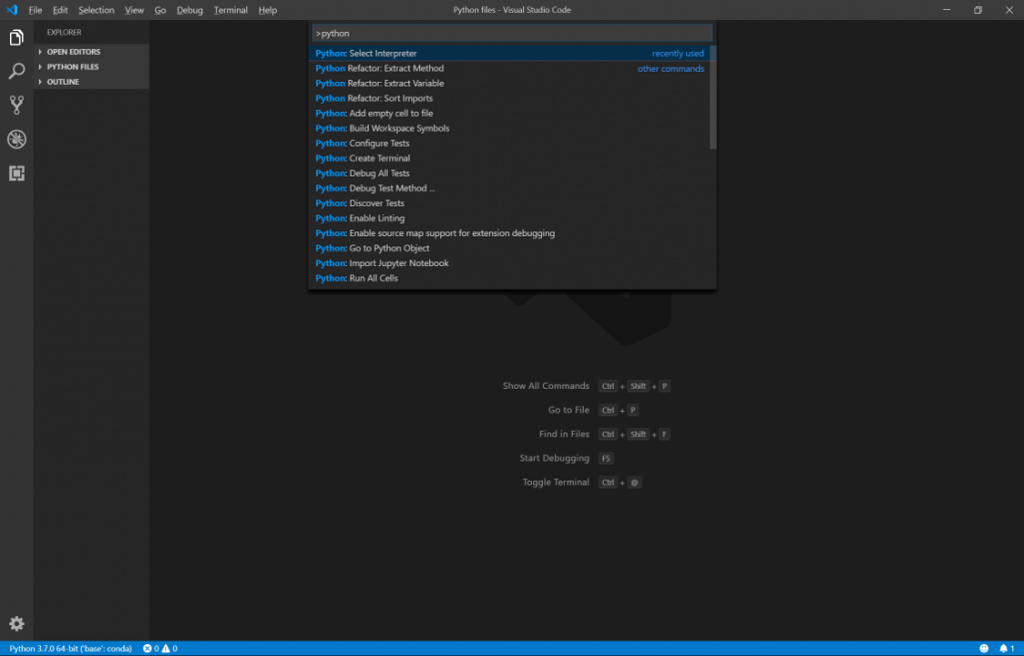
VSCode画面。F1 -> 検索窓で"Python: Select Interpriter" -> Anacondaを導入したディレクトリを指定することでVSCodeからAnaconda内のライブラリを利用することができます。忘れずにインタープリタは通しておきましょう。
3.Kaggleに登録してデータを取得しよう
準備が整ったらKaggleにユーザ登録してサンプルデータを取得しましょう。
ユーザ登録についてはごく一般的なサービスなのでここでは割愛します。さて、登録が済んだらここにアクセスしてみましょう。ZipでデータセットがDLできると思います。中に"train.csv"と"test.csv"という2つのCSVファイルがあります。2つのデータ構造は同じで、タイタニック号の顧客リストになっており、事件で亡くなった方と生き残った方のフラグが立っています。他のパラメータからこの乗客の生死を推定する精度を競うもので、trainでの学習結果からtestを予測し、その結果をアップロードすることでスコアを算出してくれます。
ここまでで長くなってしまったので、このデータでの実施結果はまた後日まとめたいと思います。
お読みいただきありがとうございました。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
