





こんにちは。FIXER M&S 竹中です。社内での反響がすこぶる聞こえないこのシリーズも第4弾になりました。もしかして社員全員逐電した??
先日社内の懇親会にて社長に「Kaggle楽しすぎて仕事しないでずっとこっちやっていたいくらいです」と言ったところ(率直すぎてウケるな)、突き抜けてくれとのオーダーを貰ったので引き続き本業の傍ら頑張っていきます。
第一回→①環境設定篇
第二回→②クラス分類入門篇
第三回→③回帰分析入門篇
1.今回のお題
今回は「Restaurant Revenue Prediction」というコンペのデータを使っていきましょう。前回の住宅価格と同じく、連続値を推定する回帰モデルになります。ちなみに今回のは前2回とはとは異なりFeatured、つまり過去実際に競争が行われて賞金が出たコンペです。もう期間は終わっているのでランキングは変動しませんが、スコアそのものは出るのでトレーニングにはなるという寸法です。
2.まずはデータを見てみよう
いつも通りデータを見てみましょう。今回のデータは欠損が無い(珍しい!)ので、変数名とデータ型をとります。ちなみに今回のデータ、訓練データが137件に対しテストデータが100,000件あります。訓練データの不足は典型的な過学習のもとなのでこれをうまくさばくことが必要になりそうです。
# サンプルからデータ型を調べる関数
def Datatype_table(df):
list_type = df.dtypes #データ型
Datatype_table = pd.concat([list_type], axis = 1)
Datatype_table_len = Datatype_table.rename(columns = {0:'データ型'})
return Datatype_table_len
Datatype_table(train)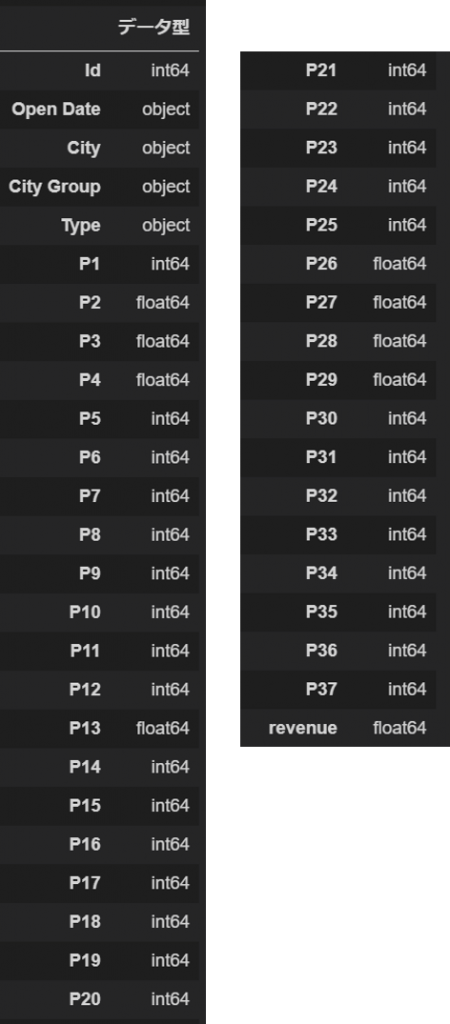
IDとRevenueはそれぞれキーと目的変数なので除外します。P1~P37は店舗の立地や人口動態とのことです。個々に意味を推測することは難しいのでいったん放置で。City、City Group、Typeは店舗のある町、町の大小、フランチャイズ等の経営形態です。今回はダミー変数に置き換えましょう。
Open Dateはお店が開いた日時ですが、このままでは文字列扱いなので日付データに置き換えましょう。また、ここでひと工夫して、日付データから現在までの営業日数を特徴量に加え入れます。また、この時点で訓練データとテストデータをラベルしてマージしておきます。
train['WhatIsData'] = 'Train'
test['WhatIsData'] = 'Test'
test['revenue'] = 9999999999
alldata = pd.concat([train,test],axis=0).reset_index(drop=True)
alldata["Open Date"] = pd.to_datetime(alldata["Open Date"])
alldata["Year"] = alldata["Open Date"].apply(lambda x:x.year)
alldata["Month"] = alldata["Open Date"].apply(lambda x:x.month)
alldata["Day"] = alldata["Open Date"].apply(lambda x:x.day)
alldata["kijun"] = "2015-04-27"
alldata["kijun"] = pd.to_datetime(alldata["kijun"])
alldata["BusinessPeriod"] = (alldata["kijun"] - alldata["Open Date"]).apply(lambda x: x.days)
alldata = alldata.drop('Open Date', axis=1)
alldata = alldata.drop('kijun', axis=1)基準日は明示されていなかったため、Kaggleコンペに登録された日を仮に入れてあります。変換した後のOpen Dateと基準日はノイズになるので削除しておきましょう。
3.モデルにフィッティングしてみる
さて、前処理を終えましたのでフィッティングしてみます。今回は回帰モデルのため、①RandomForestRegresser、②Lasso回帰、③ElasticNet ④ElasticNetでグリッドサーチとクロスバリデーション、の4種類を試してみましょう。なかなか特徴的な結果になりましたので、それぞれのスコアを取得して表示もしてみましょう。
acc_dic = {}
X_train, X_test, y_train, y_test = train_test_split(
x_, y_, random_state=0, train_size=0.7,shuffle=False)
# RandomForestRegressorによる予測
forest = RandomForestRegressor().fit(X_train, y_train)
prediction_rf = np.exp(forest.predict(test_feature))
acc_forest = forest.score(X_train, y_train)
acc_dic.update(model_forest = round(acc_forest,3))
# lasso回帰による予測
lasso = Lasso().fit(X_train, y_train)
prediction_lasso = np.exp(lasso.predict(test_feature))
acc_lasso = lasso.score(X_train, y_train)
acc_dic.update(model_lasso = round(acc_lasso,3))
# ElasticNetによる予測
En = ElasticNet().fit(X_train, y_train)
prediction_en = np.exp(En.predict(test_feature))
acc_ElasticNet = En.score(X_train, y_train)
acc_dic.update(model_ElasticNet = round(acc_ElasticNet,3))
# ElasticNetによるパラメータチューニング
parameters = {
'alpha' : [0.001, 0.01, 0.1, 1, 10, 100],
'l1_ratio' : [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9],
}
En2 = GridSearchCV(ElasticNet(), parameters)
En2.fit(X_train, y_train)
prediction_en2 = np.exp(En.predict(test_feature))
acc_ElasticNet_Gs = En2.score(X_train, y_train)
acc_dic.update(model_ElasticNet_Gs = round(acc_ElasticNet_Gs,3))
# 各モデルの訓練データに対する精度をDataFrame化
Acc = pd.DataFrame([], columns=acc_dic.keys())
dict_array = []
for i in acc_dic.items():
dict_array.append(acc_dic)
Acc = pd.concat([Acc, pd.DataFrame.from_dict(dict_array)]).T
Acc[0]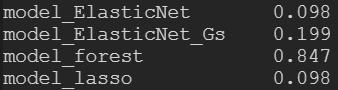
分割した訓練データに対する精度がこちらになります。ランダムフォレスト以外極めて悪いですね。ランダムフォレストはもともと弱い学習機によるアンサンブル学習なのでノイズや過学習に強い傾向があります。しかしながら、ランダムフォレストでも精度は0.85程度と、高スコアを狙うには心もとないですね。なので、今回はまた別のモデルを試してみましょう。
4.lightGBMを使ってみよう
さて、ここで今日の本題。lightGBMというモデルを使ってみましょう。 lightGBMは2017年にMicrosoftから発表されたフレームワークで、Gradient Boostingという手法を採用しています。GBMはGradient Boosting Methodの略称ですね。詳しくは原著に譲りますが、ランダムフォレストのようなアンサンブル学習モデルの一種で、学習のたびに二乗誤差を最小化する処理が入るため非常に強力なモデルになっています。Kaggle MasterのBen Gorman氏は投稿でこんな風に述べられています(訳は竹中)
線形回帰モデルがトヨタのカムリだとしたら、Gradient BoostingはUH-60 ブラックホーク戦闘ヘリでしょう
https://www.gormanalysis.com/blog/gradient-boosting-explained/
突然のトヨタへの流れ弾がアツいですね。
そんな lightGBMですがインストールはとても簡単です。例によりAnacondaのコマンドを使っていきます。
conda install -c conda-forge lightgbm通常のconda install lightgbmですと上手くいかない場合がありますので上記方法推奨です。さて、先ほどのデータをlightGBMで学習してみましょう!
※今回なぜか回帰にも関わらず二値分類モデルの方でいいスコアが出てしまいました…。なんでだろう…。。
# lightGBMによる予測
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# LightGBM parameters
params = {
'task' : 'train',
'boosting_type' : 'gbdt',
'objective' : 'regression',
'metric' : {'l2'},
'num_leaves' : 31,
'learning_rate' : 0.1,
'feature_fraction' : 0.9,
'bagging_fraction' : 0.8,
'bagging_freq': 5,
'verbose' : 0,
'n_jobs': 2
}
gbm = lgb.train(params,
lgb_train,
num_boost_round=100,
valid_sets=lgb_eval,
early_stopping_rounds=10)
prediction_lgb = np.exp(gbm.predict(test_feature))コードも簡単ですね。lightGBMはPythonによるデータ分析のデファクトスタンダードであるScikit learnとの互換や文法の類似を考慮されていますのでとても書きやすいです。
さて、この結果をKaggleにアップロードしてスコアと(期間中と仮定した)順位を見てみましょう。
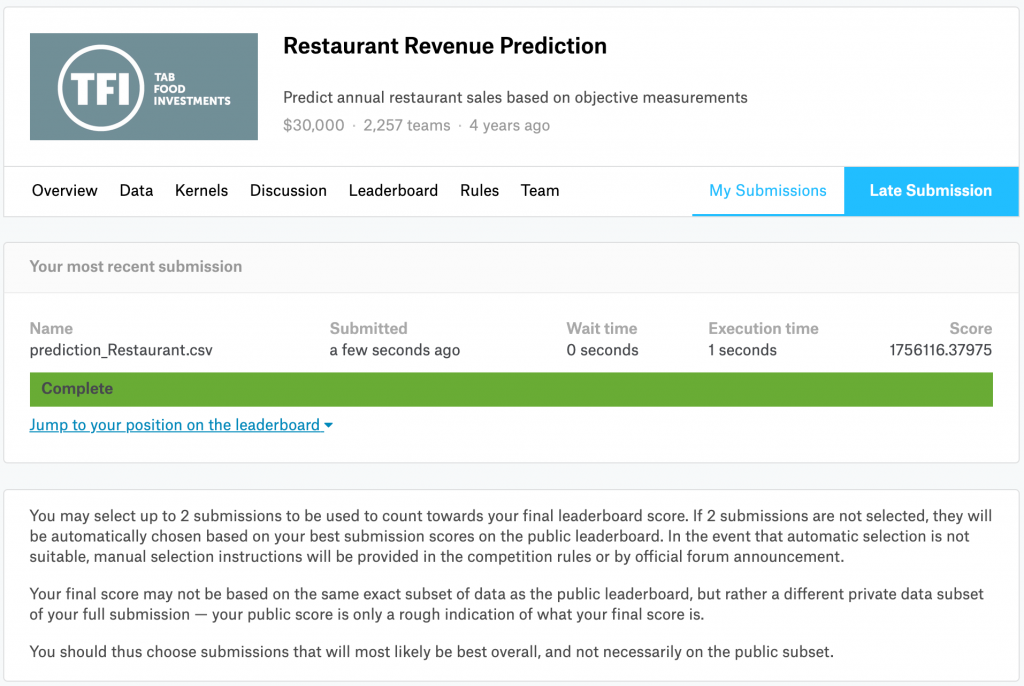
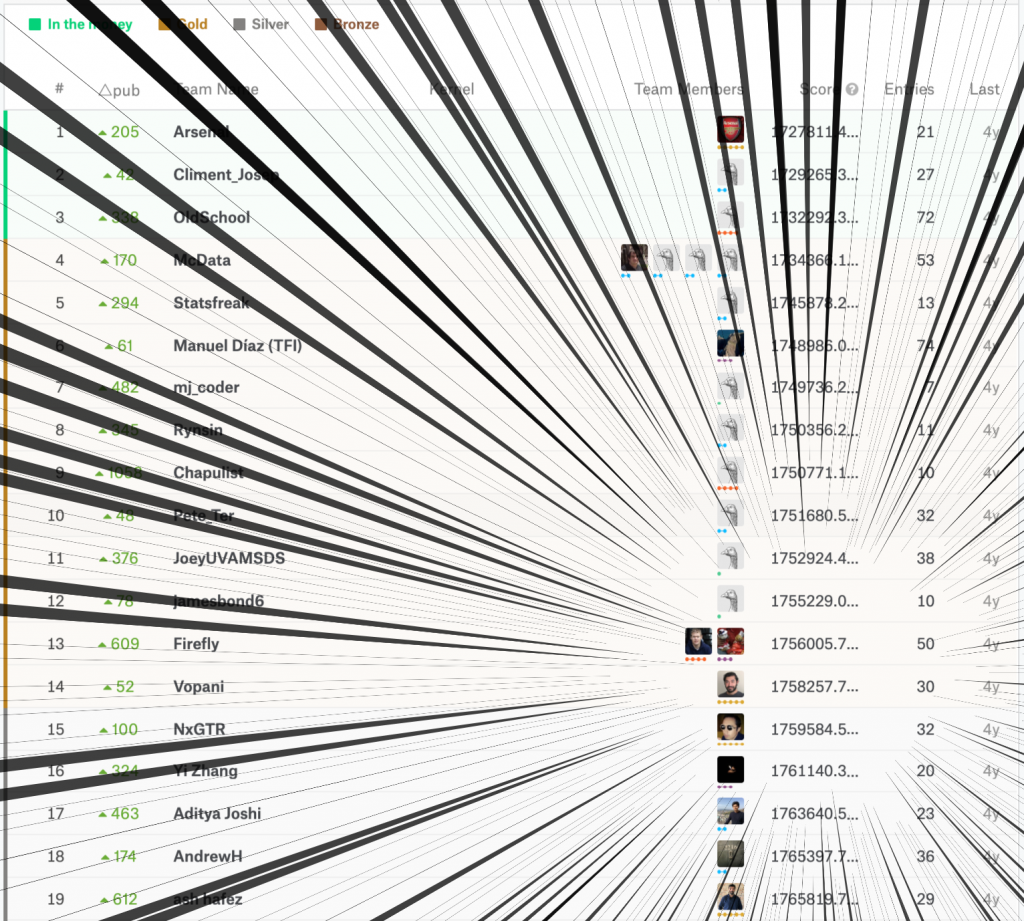
激アツやん
なんと本戦中であれば13位/2,257チームの好成績が出てしまいました。ぎりぎりゴールドメダル対象ですね。エントリ期間中だったらよかったのに…
そろそろ色々なことができるようになってきたでしょうか。
皆さんも是非Kaggle、やろう!
今回は以上になります。お読みいただきありがとうございました。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
