






こんにちは。R&D Divisionの山本です。
本記事は予測モデル解釈の第三回目になります。これまでの記事は下記のリンクからどうぞ。
今回はPythonでコーディングを行い、Linear RegressionとDecision Treeでモデルの作成し、解釈を行います。
Linear RegressionとDecision Treeは予測のロジックがわかりやすいので実際にどのように予測結果を出しているのか見ていきたいと思います。
Pythonコーディング環境の準備
Pythonのコーディングと実行もAzure Machine Learning Service上で行います。そのためにVMを作成し、その上でPythonの開発環境であるJupyter Notebookを動かします。
まずは、Azure Machine Learning Service管理画面のトップページに移動し、ノートブックをクリックします。Azure Machine Learning Serviceの準備方法などについては、第二回の記事を参考にしてください。
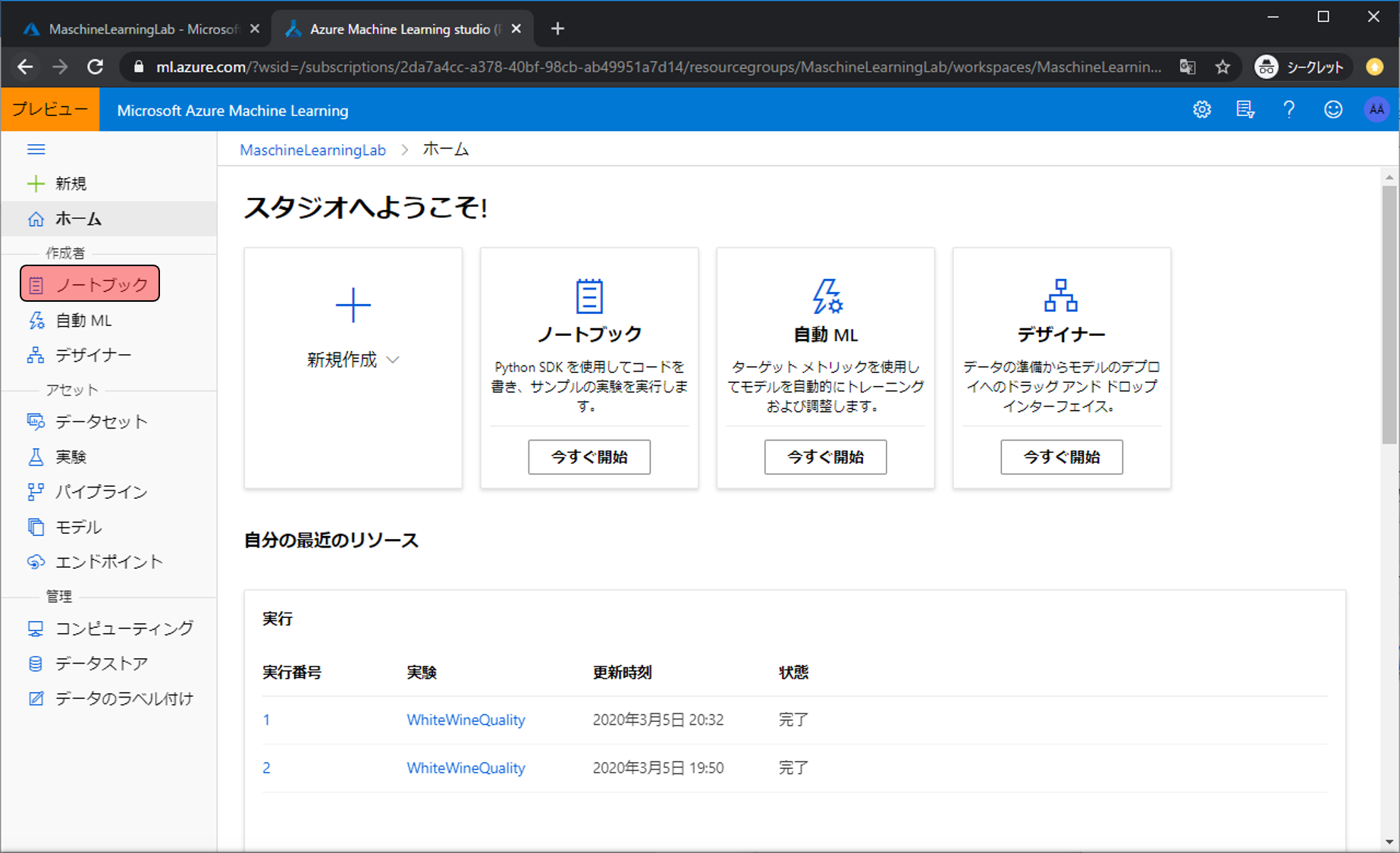
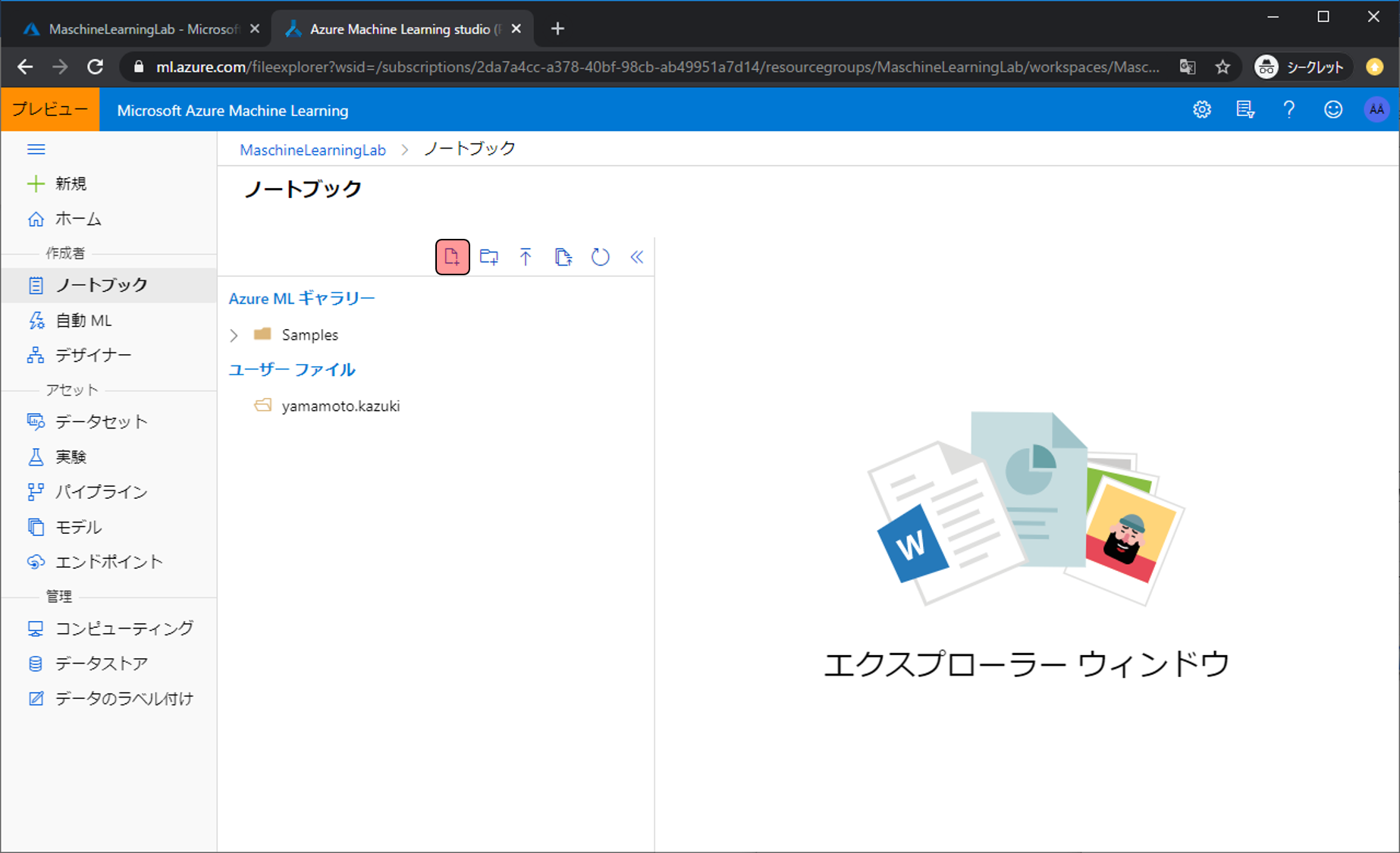
Pythonコードを書き込むファイルを用意します。新しいファイルの作成アイコンをクリックします。
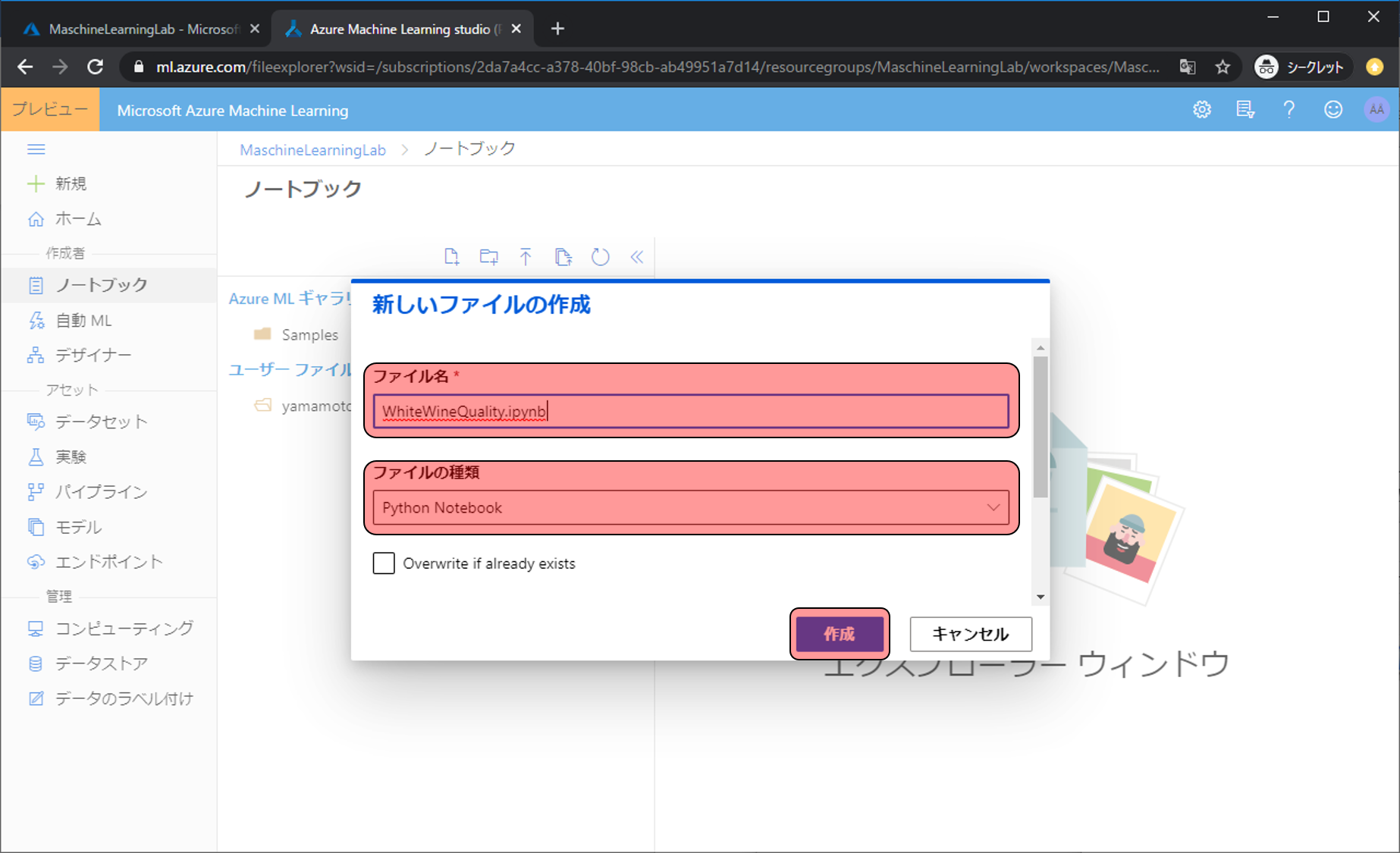
ファイル名をWhiteWineQuality.ipynb、ファイルの種類をPython Notebookにし、作成をクリックします。
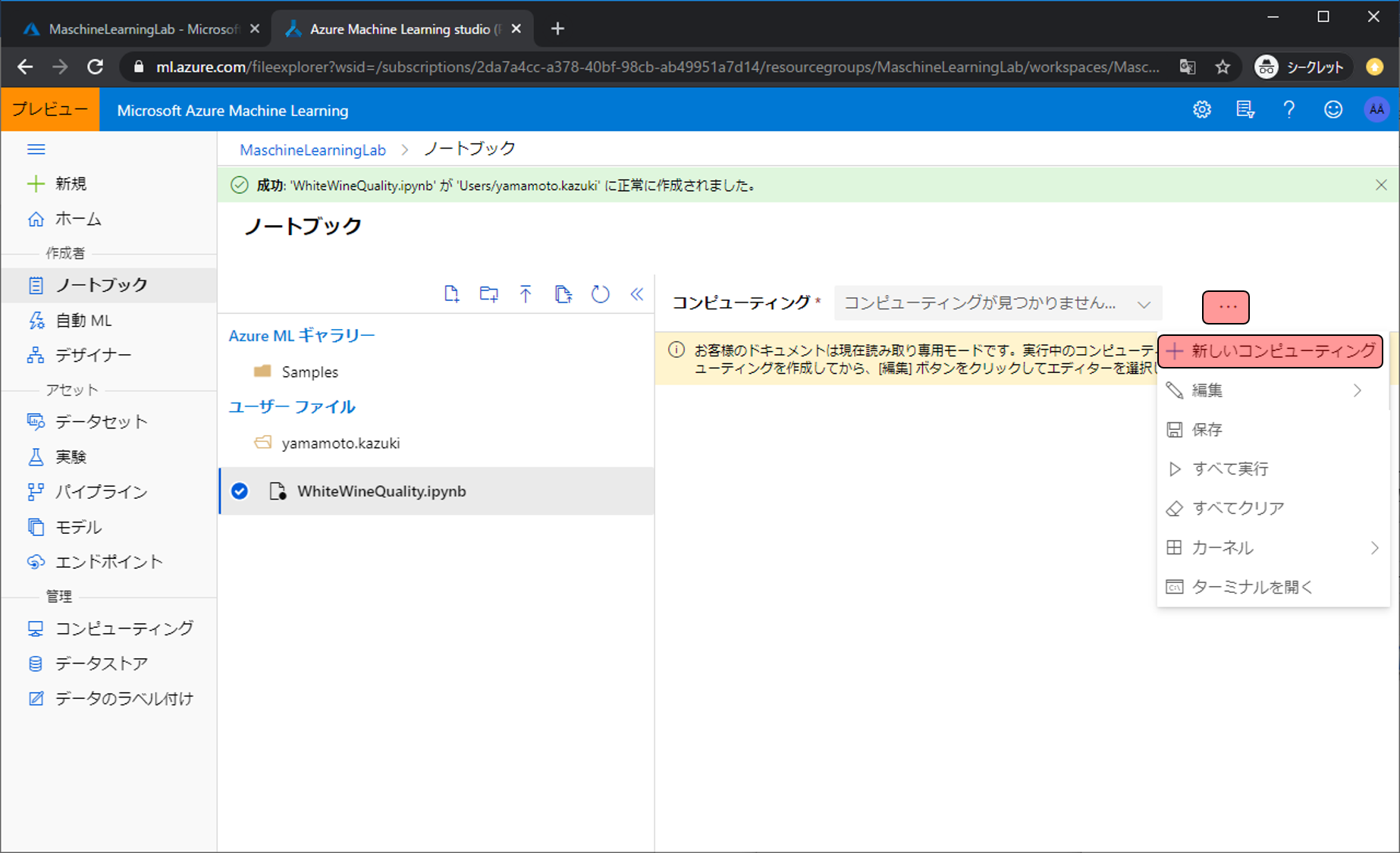
このままだとPythonを実行するコンピューティングリソースが用意されていないので、その環境(VM)を用意します。…をクリックし、新しいコンピューティングをクリックします。
作成するコンピューティングリソースに名前をつけ、作成をクリックします。今回は仮想マシンサイズの変更は行いません。
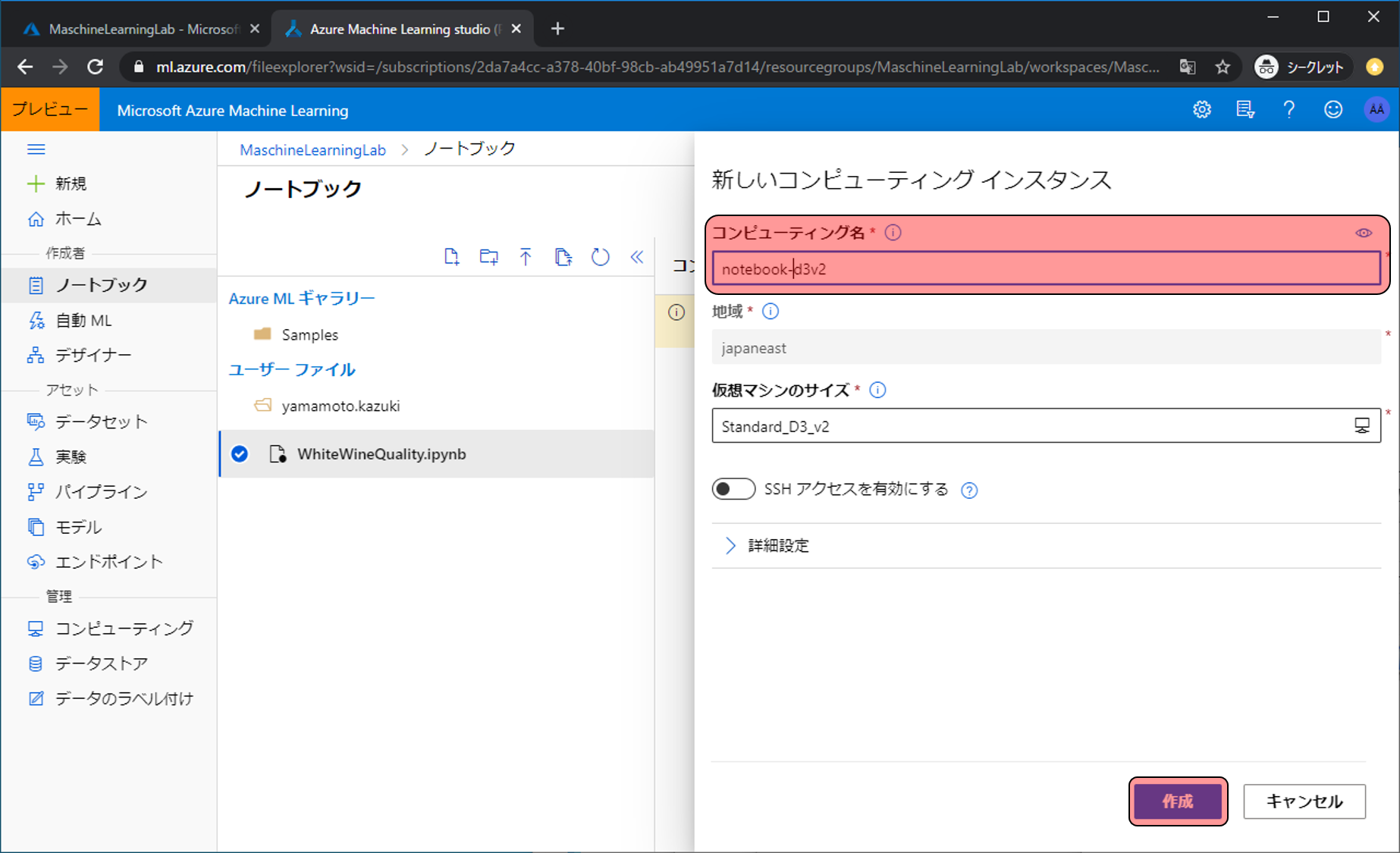
作成をクリック直後は作成中と表示されますが、完了すると実行中と表示されます。実行中になったら、…をクリックし、編集をクリック、Jupyterで編集をクリックします。
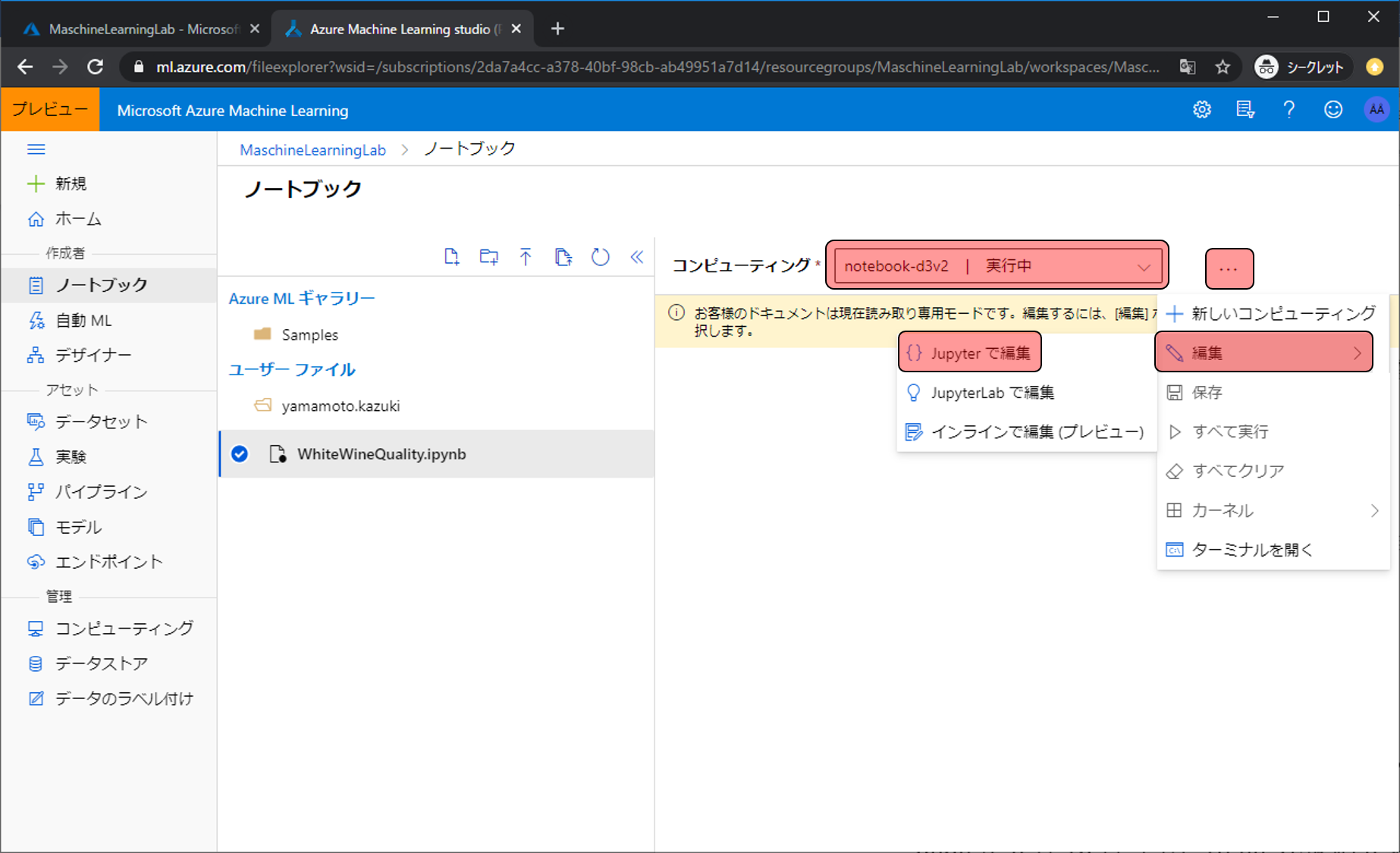
Jupyterの画面に移動しました。これでPythonのコードを作成する準備は完了です。
TIPS
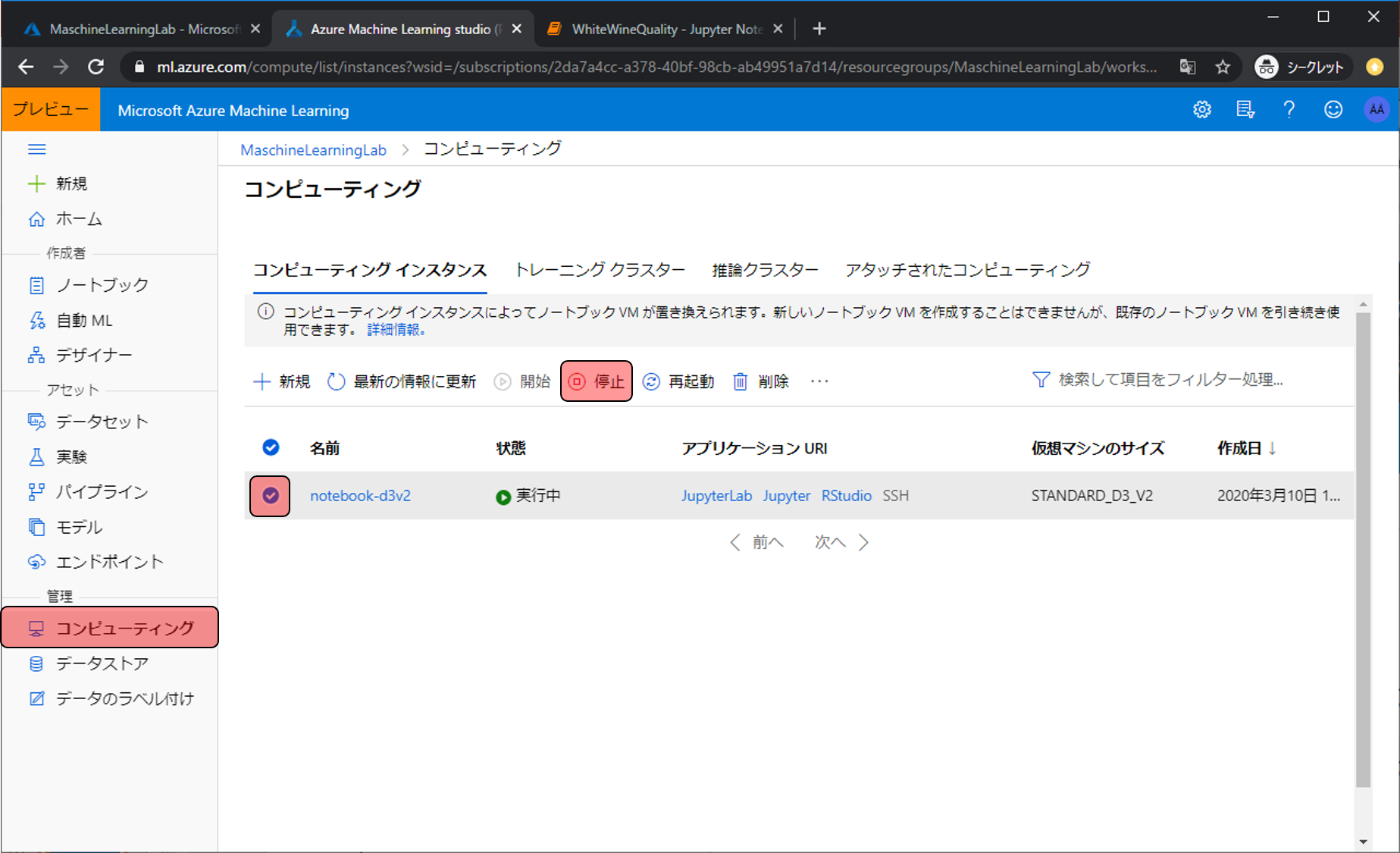
コンピューティングが実行中である間は1時間に数十円のVMの利用料金が発生し続けます。料金の発生を止めるにはVMを停止する必要があります。
VMを停止するには、まずコンピューティングに移動し、止めたい対象を選択、停止をクリックする必要があります。
再度VMを利用する際には、またコンピューティングに移動し、動かしたい対象を選択して、開始をクリックします。
Linear Regressionで予測モデル作成と解釈
Pythonを実行する環境が整ったので、早速予測モデルを作成します。 まずはLinear Regressionでモデル作成し、解釈を行います。
実行させるPythonコードの解説を書いていきます。
Workspace.from_config()でAzure Machine Learning Service上の情報と接続- 接続情報を元に、
Dataset.get_by_nameで前回データセットに登録した白ワインのデータを取得 - 取得した白ワインのデータをを扱いやすいように変換
from azureml.core import Workspace, Dataset
ws = Workspace.from_config()
dataset = Dataset.get_by_name(ws, name='White Wine Quality Data')
df = dataset.to_pandas_dataframe()- Linear RegressionのアルゴリズムをLrに格納
- Xにワインデータのquality以外の情報を格納(学習データ)
- Yに ワインデータのqualityの情報を格納(予測対象データ)
- Linear Regressionでqualityを予測するモデルの作成
from sklearn.linear_model import LinearRegression
Lr = LinearRegression()
X = df.drop("quality", axis=1).values
Y = df['quality'].values
Lr.fit(X, Y)ほとんど正しい予測はできないので、予測精度の確認は割愛します。
- 作成した予測モデルで各カラムの偏回帰係数の表示
- 切片の表示
import pandas as pd
print(pd.DataFrame({"Name":df.drop("quality", axis=1).columns, "Coefficients":Lr.coef_}).sort_values(by='Coefficients'))
print("intercept: " + str(Lr.intercept_))+をクリックすると、空のセルを追加することができるので、上記したコードを1セルに1つづつJupyterに貼り付けます。
貼り付けたら、一番上のセルを選択してRunをクリックします。
Runをすると底に書かれているPythonコードが実行され、実行が完了するとIn[ ]がIn[(数字)]になります。1つ目のセルの実行が完了したら2つ目のセルを選択してRunをクリックします。これをすべてのセルが実行完了になるまで繰り返してください。
すべてのセルの実行が完了すると最後のセルに各カラムの偏回帰係数と切片の情報が表示されます。これがモデルが判断するときの数式になります。
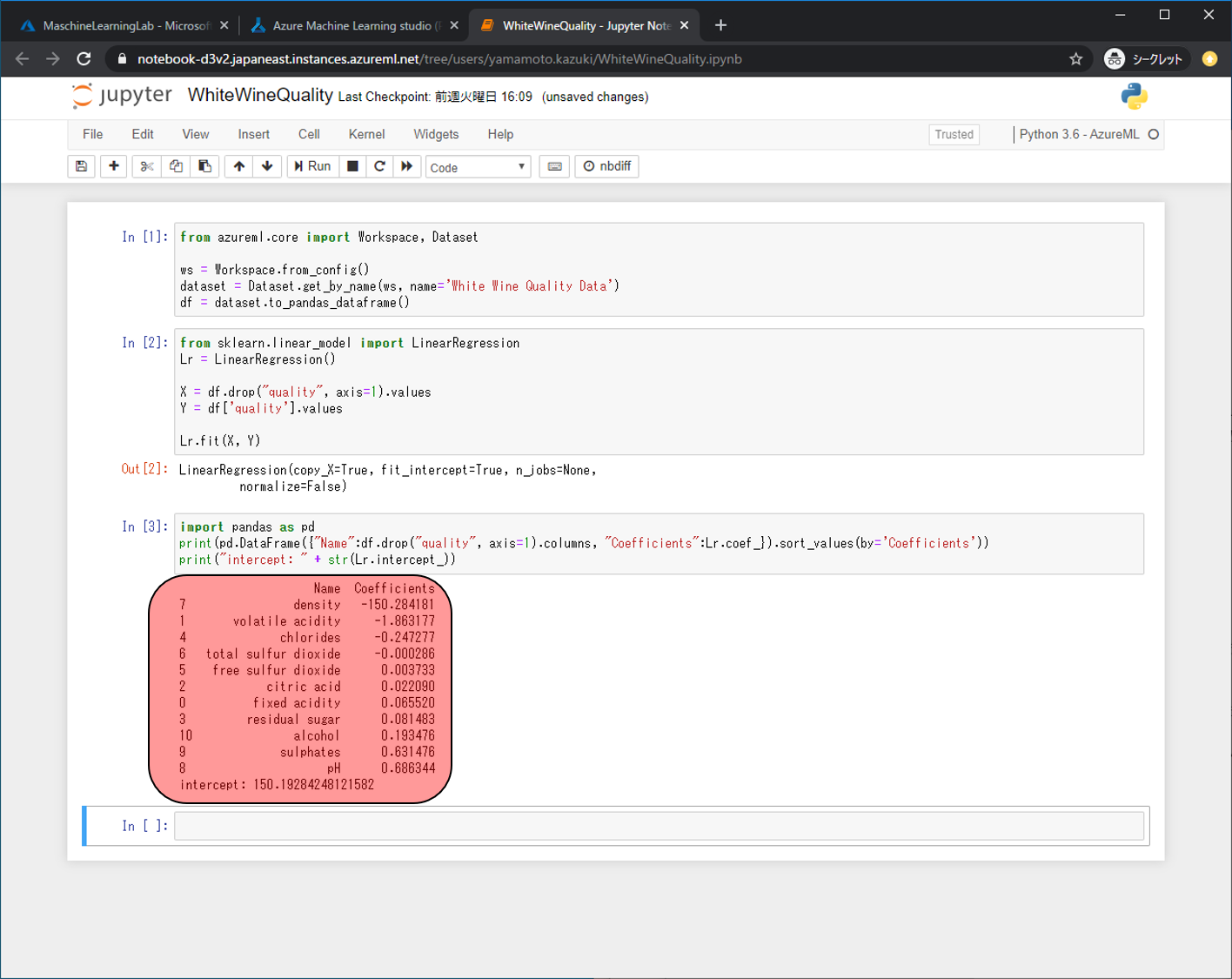
今回の場合は下記の式でqualityを求めています。
quality = density * (-150.284181) +
volatile acidity * (-1.863177) +
chlorides * (-0.247277) +
total sulfur dioxide * (-0.000286) +
free sulfur dioxide * 0.003733 +
citric acid * 0.022090 +
fixed acidity * 0.065520 +
residual sugar * 0.081483 +
alcohol * 0.193476 +
sulphates * 0.631476 +
pH * 0.686344 +
150.19284248121582Decision Treeで予測モデル作成と解釈
次にDecision Treeでモデル作成し、解釈を行います。
Linear Regressionのモデル解釈で使っていたファイルにソースコードを追記して行います。 実行させるPythonコードの解説を書いていきます。
- DecisionTreeのアルゴリズムをDtに格納、このときにツリーの深さを3までに制限
- Linear Regressionで利用したX(学習データ)とY(予測対象データ)を利用してDecisionTreeのアルゴリズムで予測モデルを作成
from sklearn import tree
Dt = tree.DecisionTreeClassifier(max_depth = 3)
Dt.fit(X, Y)- モデル解釈に利用するツリー図をtree.dotというファイル名で出力
tree.export_graphviz(Dt, out_file="tree.dot",
feature_names=df.drop("quality", axis=1).columns,
class_names=["3","4","5","6","7","8","9"],
filled=True, rounded=True)今回のモデルも予測精度は低いと思われるので、確認は割愛します。
Linear Regressionのときと同様に上記したコードを1セルに1つづつJupyterに貼り付けます。
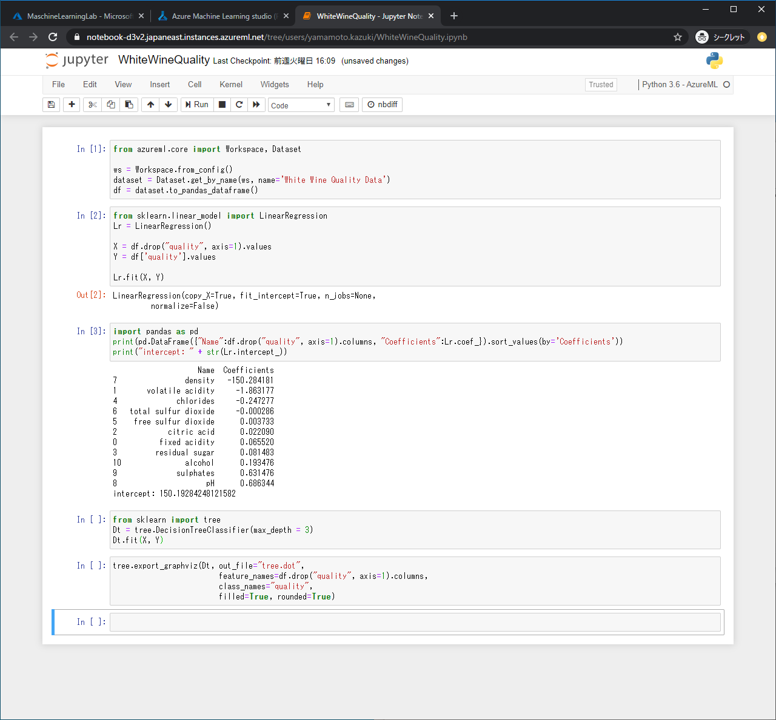
すべてのセルが実行完了になるまでRunします。実行が完了したら ブラウザのタブを切り替えて、ノートブックの管理画面に移動します。
リロードボタンをクリックします。
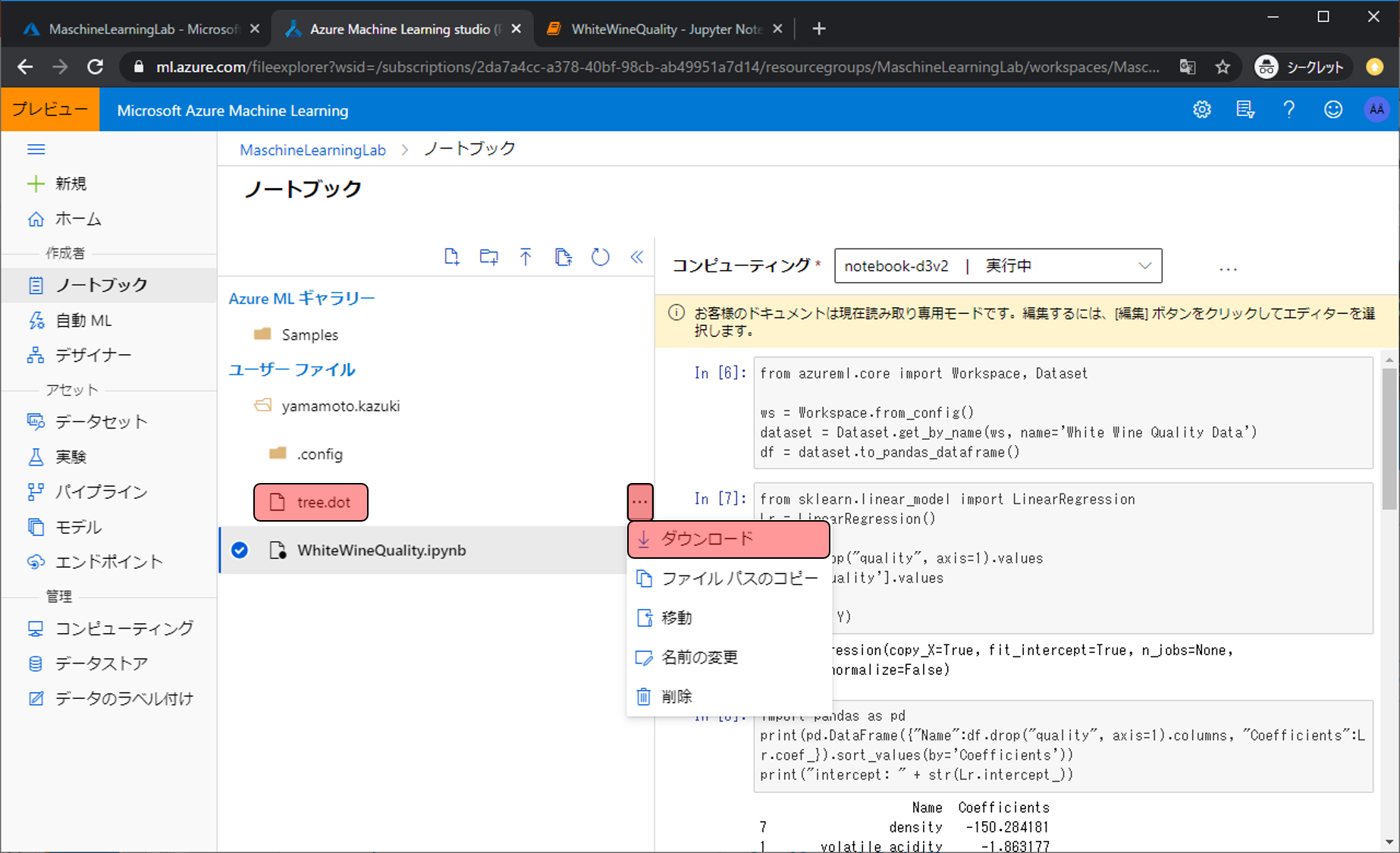
すると、先ほど作成したPythonで作成したtree.dotが作られているので、…をクリックし、ダウンロードをクリックします。
ダウンロードしたtree.dotはGraphvizで描写することができます。実際に開いてみると下記のようなツリー図が確認できます。
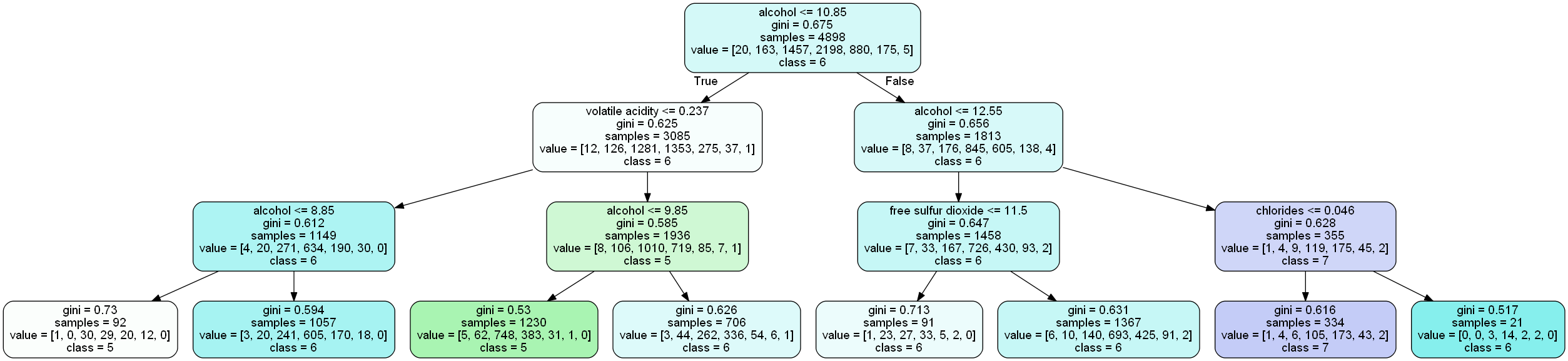
アルコール度数などを基準に分岐していることが確認できます。各項目の説明をざっくりと行います
- gini: ジニジニ不純度を表しており、ターゲットがどれくらい分類できていないかの値
- sample: ノードにあるデータの総件数
- value: ノードに属する各分類のデータの件数
- class: 分類結果
これでツリー図によるモデル解釈もできました。
次回はPythonを利用して高度なアルゴリズムで作成されたモデルの解釈を行います。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
