






こんにちは。R&D Divisionの山本です。
本記事は予測モデル解釈の第五回目になります。これまでの記事は下記のリンクからどうぞ。
- 第一回:予測モデル解釈とはなんぞやを解説した記事はこちら
- 第二回:Azure Machine Learningの機能を利用して、予測モデルの作成、モデル解釈を行った記事はこちら
- 第三回:線形回帰と決定木アルゴリズムを利用して、予測モデルの作成、モデル解釈を行った記事はこちら
- 第四回:LIMEを利用して高度なアルゴリズム作成した予測モデルの解釈を行った記事はこちら
今回は高度なアルゴリズムで作られた予測モデルを、SHAPというものを利用してモデル解釈していきます。
SHAPによるモデル解釈
ローカルなモデル解釈手法として前回はLIMEを紹介しましたが、もう一つ有名の手法としてSHAP(SHapley Additive exPlanations)と呼ばれるものがあります。
SHAPはゲーム理論のShapley valueを利用したモデルの解釈手法です。
Shapley valueとは、複数プレイヤーの協力で得た報酬を各プレイヤーの貢献度合いに合わせて分配するための計算手法であり、具体的な計算式などは難しいため、割愛しますが、Shapley valueで登場する「プレイヤー」を「特徴」に置き換え、結果求めるのに各特徴がどの程度貢献したのかを求めます。
実際にSHAPでの解釈を見ていきましょう。
今回もPythonで行っていくので、まずはノートブックの管理画面まで移動し、 新しいファイルの作成アイコンをクリックします。 ノートブック管理画面への移動やコンピューティングの設定方法がわからない場合は、第三回の記事を参考にしてください。
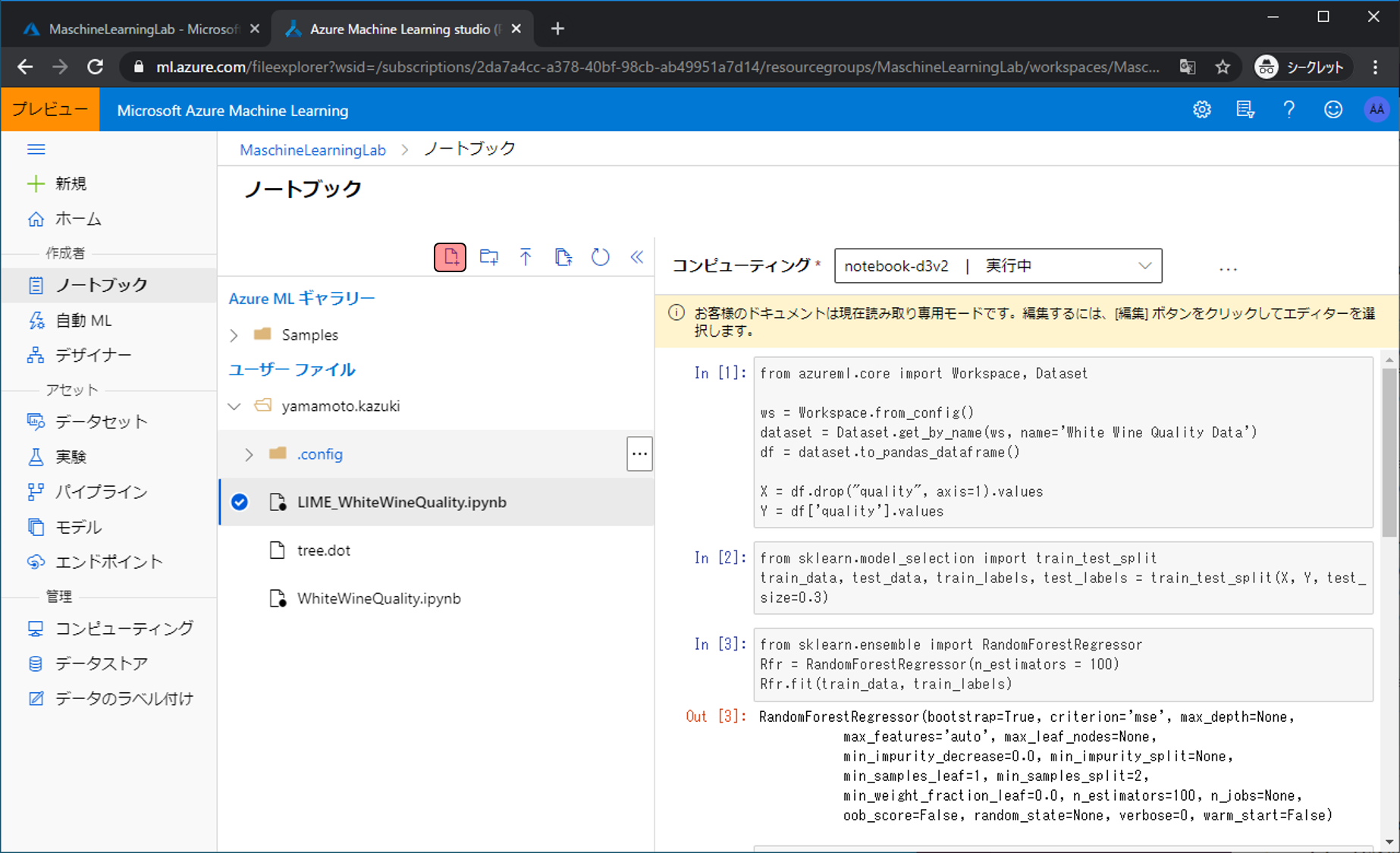
ファイル名をSHAP_WhiteWineQuality.ipynb、ファイルの種類をPython Notebookにし、作成をクリックします。
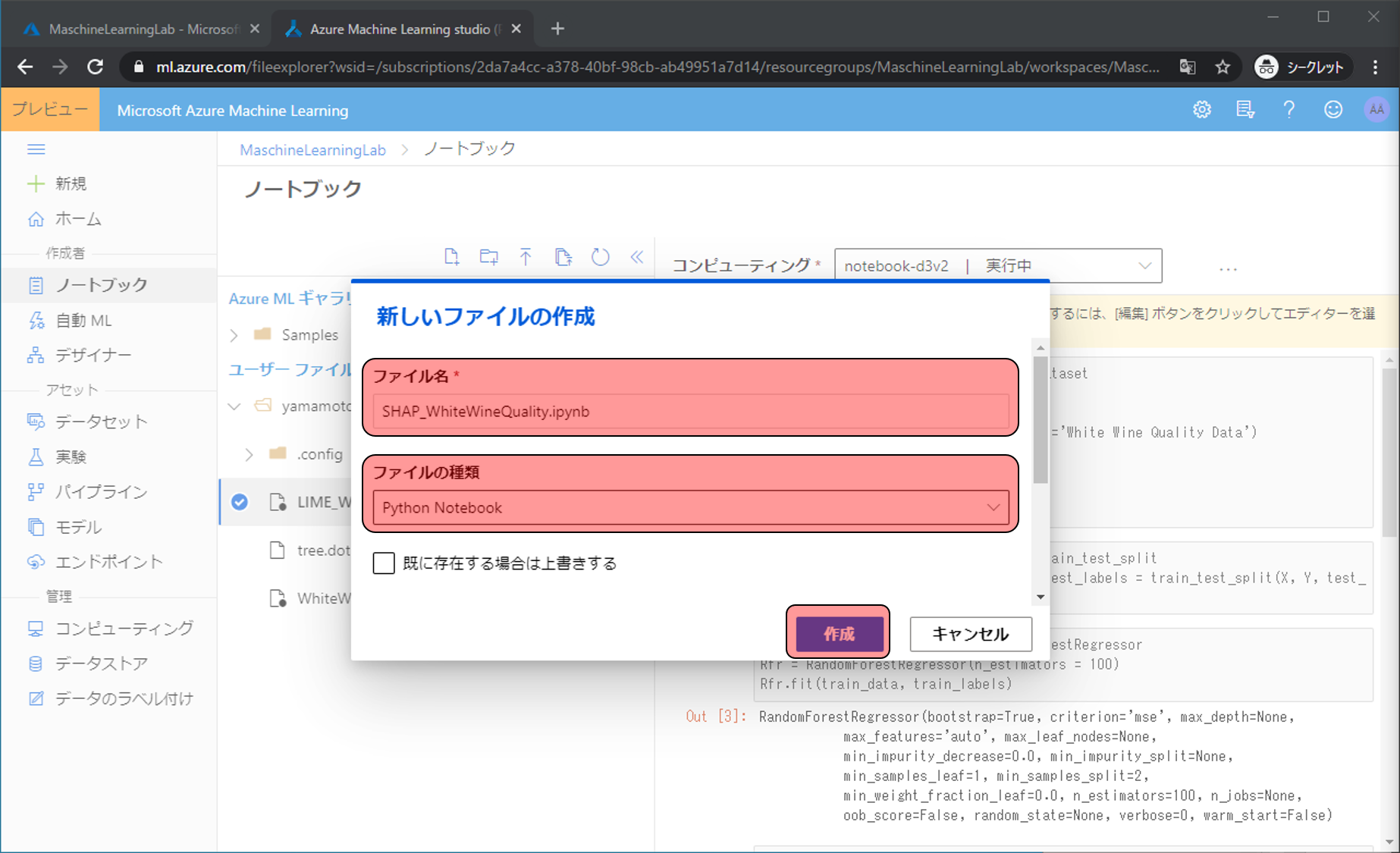
…をクリックし、編集をクリック、Jupyterで編集をクリックします。
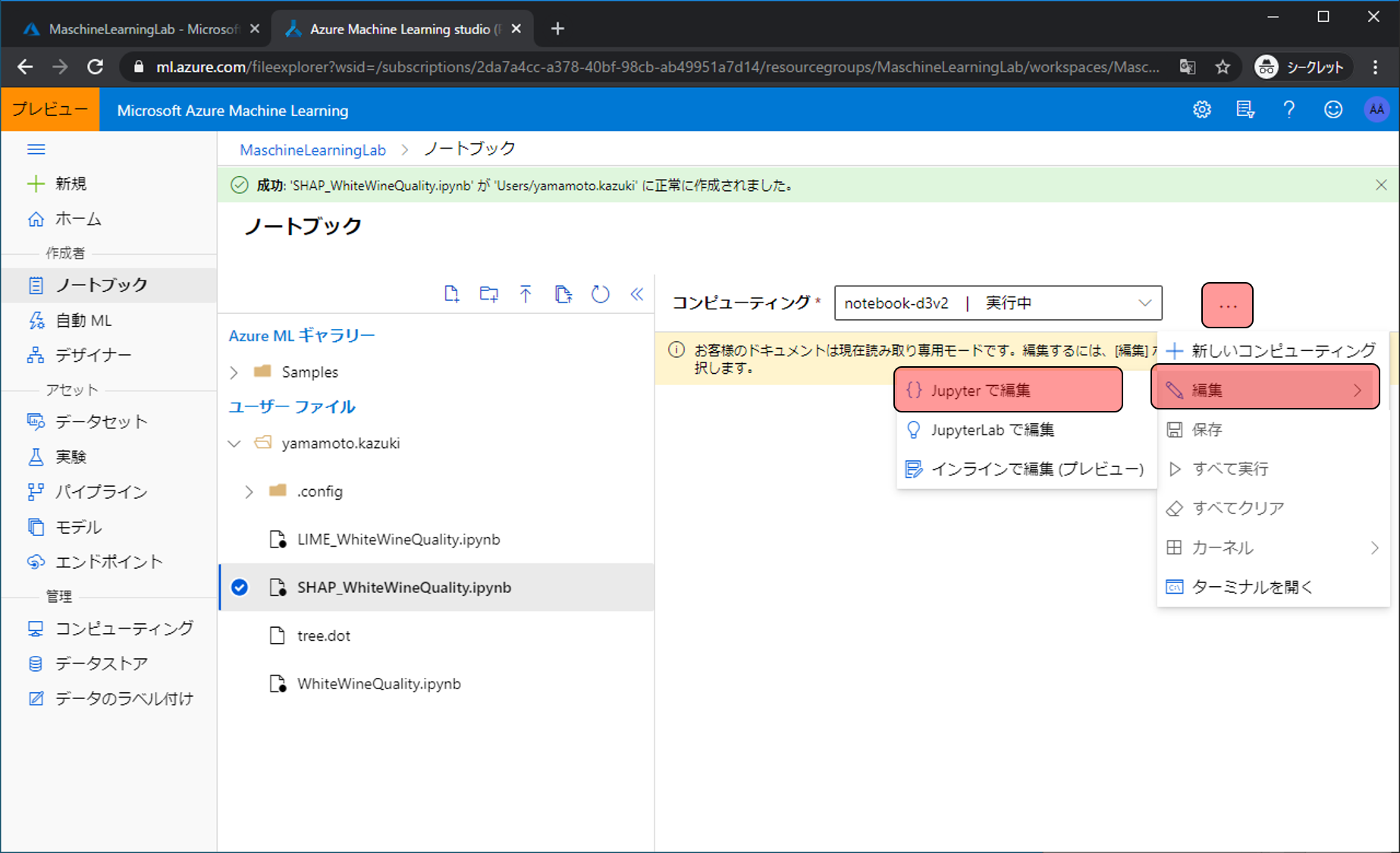
Jupyterの画面に移動しました。 引き続き、コードを書いていきます。
-
Workspace.from_config()でAzure Machine Learning Service上の情報と接続 - 接続情報を元に、
Dataset.get_by_nameで前回データセットに登録した白ワインのデータを取得 - 取得した白ワインのデータをを扱いやすいように変換
- Xにワインデータのquality以外の情報を格納(学習データ)
- Yに ワインデータのqualityの情報を格納(予測対象データ)
from azureml.core import Workspace, Dataset
ws = Workspace.from_config()
dataset = Dataset.get_by_name(ws, name='White Wine Quality Data')
df = dataset.to_pandas_dataframe()
X = df.drop("quality", axis=1).values
Y = df['quality'].values- 白ワインデータを学習用と評価用に分割
from sklearn.model_selection import train_test_split
train_data, test_data, train_labels, test_labels = train_test_split(X, Y, test_size=0.1)- Random Forest RegressorのアルゴリズムをRfrに格納
- Random Forest Regressorでqualityを予測するモデルの作成
from sklearn.ensemble import RandomForestRegressor
Rfr = RandomForestRegressor(n_estimators = 100)
Rfr.fit(train_data, train_labels)- モデル解釈で利用するLIMEをインストール
pip install shap- 実行結果を表示させるためにjsをロード
- 各特徴の寄与度を表すshap_valuesの取得
import shap
shap.initjs()
explainer = shap.TreeExplainer(Rfr)
shap_values = explainer.shap_values(train_data)- 解釈結果の表示(1)
shap.summary_plot(shap_values, train_data, feature_names=df.drop("quality", axis=1).columns)- 解釈結果の表示(2)
shap.summary_plot(shap_values, train_data, feature_names=df.drop("quality", axis=1).columns, plot_type="bar")- 解釈結果の表示(3)
shap.force_plot(explainer.expected_value, shap_values[0,:], train_data[0,:], feature_names=df.drop("quality", axis=1).columns)- 解釈結果の表示(4)
shap.force_plot(explainer.expected_value, shap_values, train_data, feature_names=df.drop("quality", axis=1).columns)+をクリックすると、空のセルを追加することができるので、上記したコードを1セルに1つづつJupyterに貼り付けます。
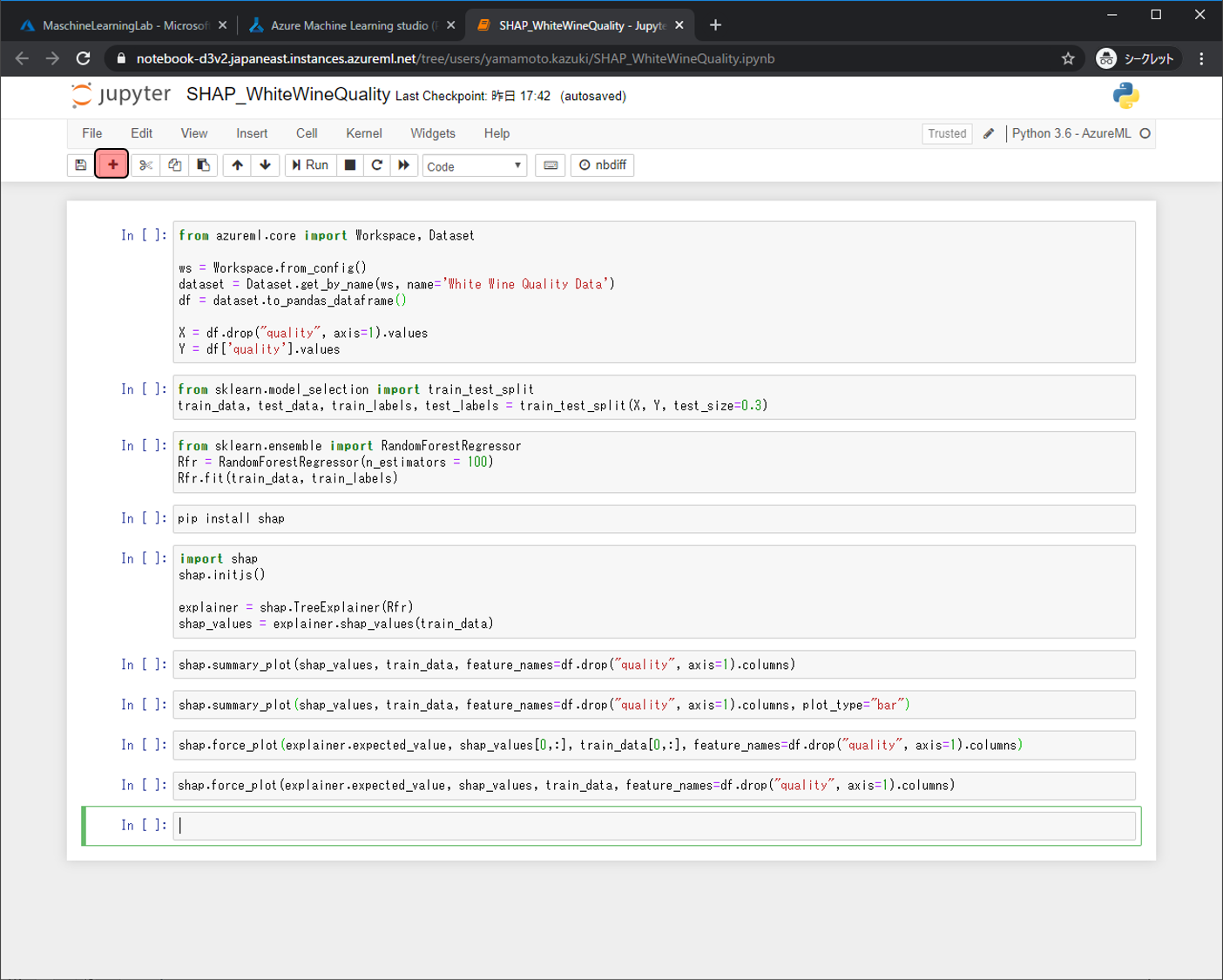
上から順にすべてのセルが実行完了になるまでRunします。(スクリーンショットに全実行結果が入り切らなかったので、重要な下部分だけ写しています)
これらがSHAPによる解釈内容になります。
上から順に見ていきましょう。
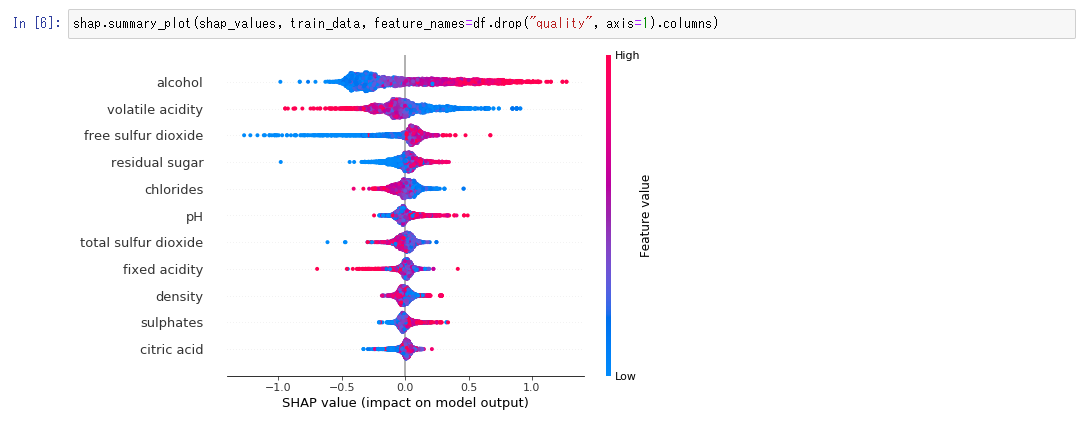
各ドットはデータ、横軸はSHAP値、色は特徴量の大きさを表しています。例えば、アルコール度数に着目すると、右になるにつれて赤くなっているので、アルコール度数が高くなると予測値が高くなることが確認できます。
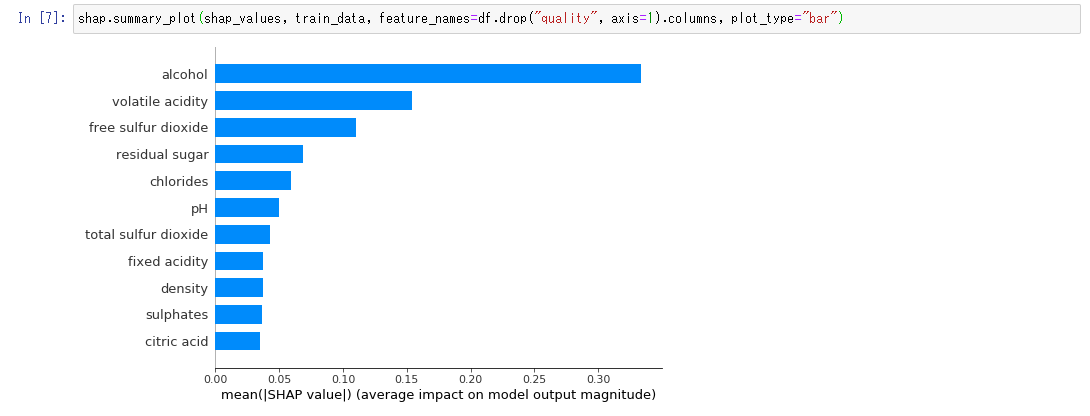
このグラフでは、SHAPの絶対値でどの特徴が予測結果に影響を与えているのかをみることができます。今までの傾向通り、アルコールの与える影響が大きいようです。

1つのデータだけに着目してみます。このデータではアルコール度数は9であり、予測値を下げる方向に影響していることが確認できます。
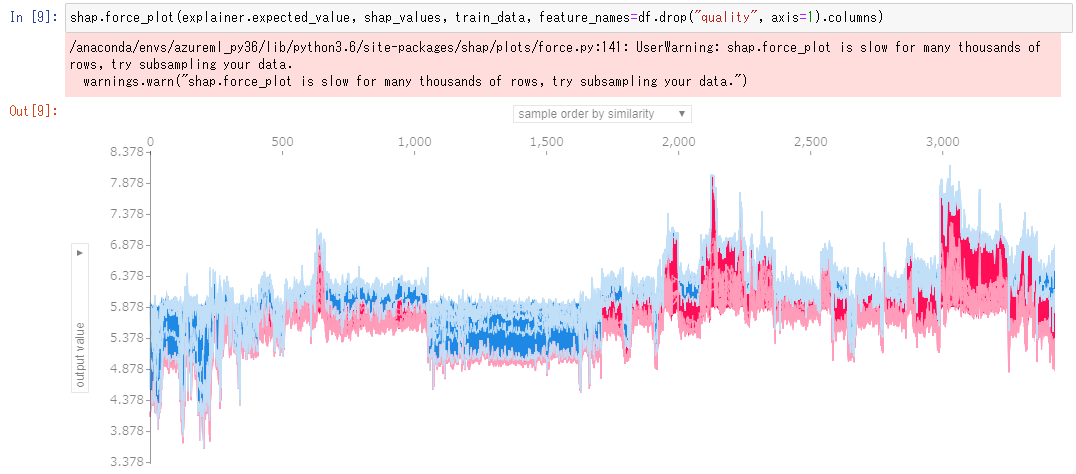
全データを入れた際の傾向も確認できます。 縦軸は予測値、横軸は各データが並んでおり、オンマウスするとそのときの各特徴の値が表示され、どの特徴が予測値に影響を与えたのかを確認できます。
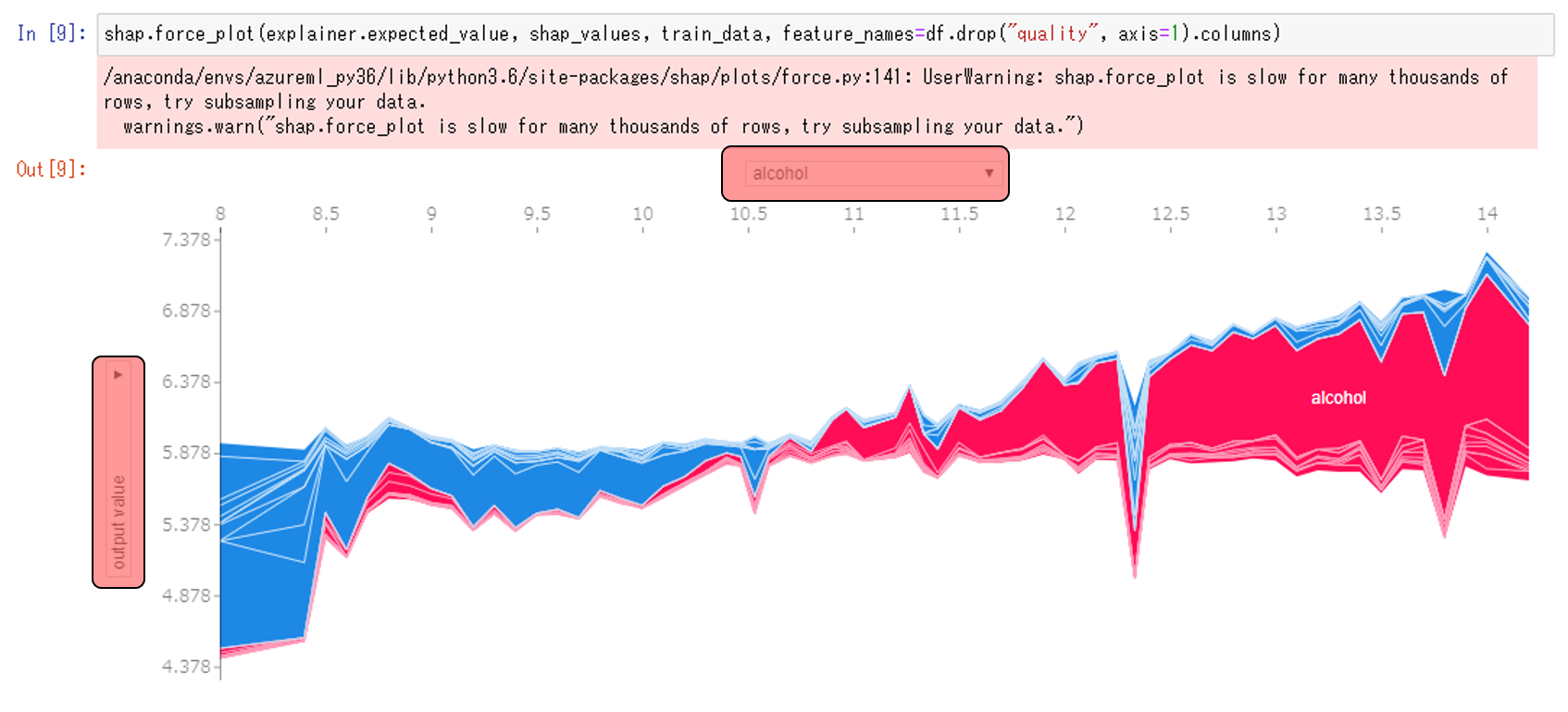
縦軸を予測値、横軸にアルコール度数の値を表示させると、やはりアルコール度数が高くなると予測値が高くなる傾向が確認できます。このへんのUIはAutoMLで確認したときのものと似ていますね。
これでSHAPによるモデル解釈は完了です。SHAPはLIMEと比べると、1つづつのデータでなく、全てのデータで傾向を確認できるのが優れてますね。
これで予測モデル解釈の解説は一通り終わったのですが、次回、予測モデル解釈シリーズ(?)の最後に画像データの解釈を行いたいと思います。なので、もう少しだけお付き合い頂ければ幸いです。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
