





こんにちは。R&D Divisionの山本です。
前回、Azure Databricksを使ってBlob上のデータを分析する方法を解説しましが、せっかくAzure Databricksでデータの分析をしたのに、いざ機械学習で予測モデルを作成しようとしたら、別の環境に移ってなんやかんやするのは面倒くさいですよね。
そこで今回はAzure Databricks上でモデル開発し、その管理をAzure Machine Learning Serviceでしてみたいと思います。
今回は、前回作成・登録したAzure Databricksの環境やデータを使います。
(前回の記事はこちらから)
まずは、Azure Machine Learning Serviceのリソースを作成します。過去に作成手順を解説した記事を書いているので、今回は作成方法の解説しません。記事を参考に参考に作成してください。
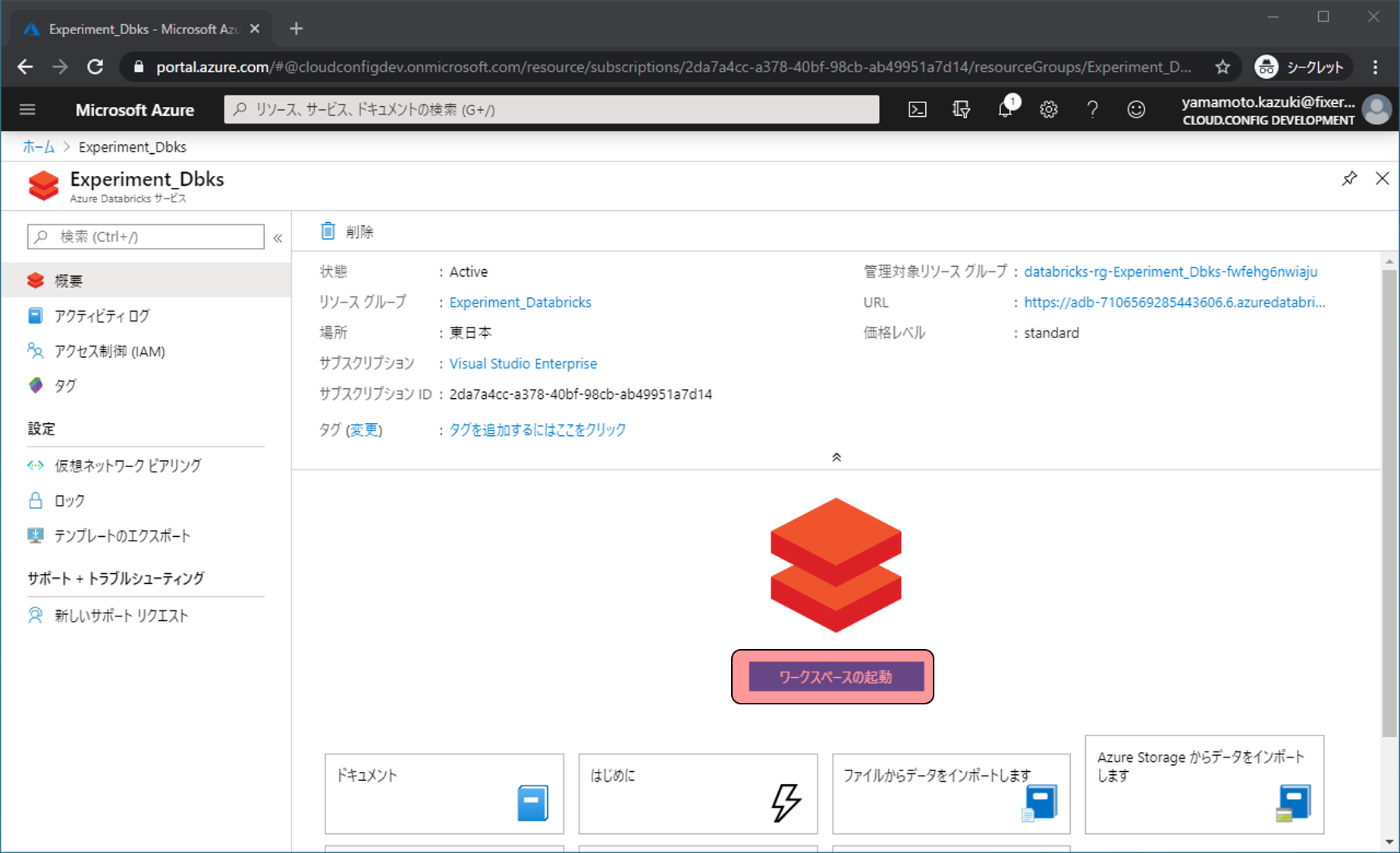
次にAzure Databricksの管理画面に移動し、ワークスペースの起動をクリックします。
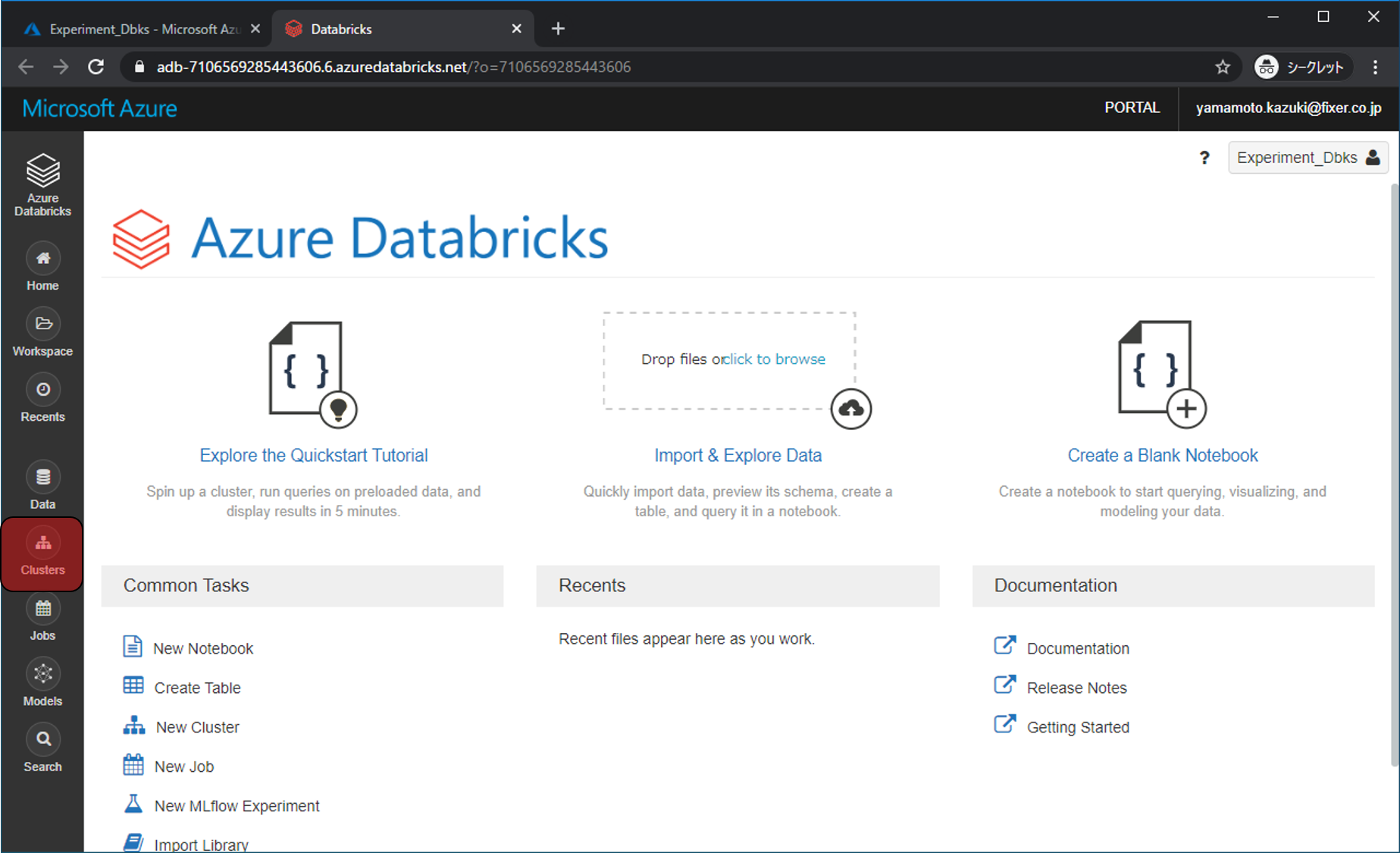
ワークスペースに移動したら、まずはAzure Machine Learning Service と接続できるようにクラスターにSDKをインストールします。Clusterをクリックします。
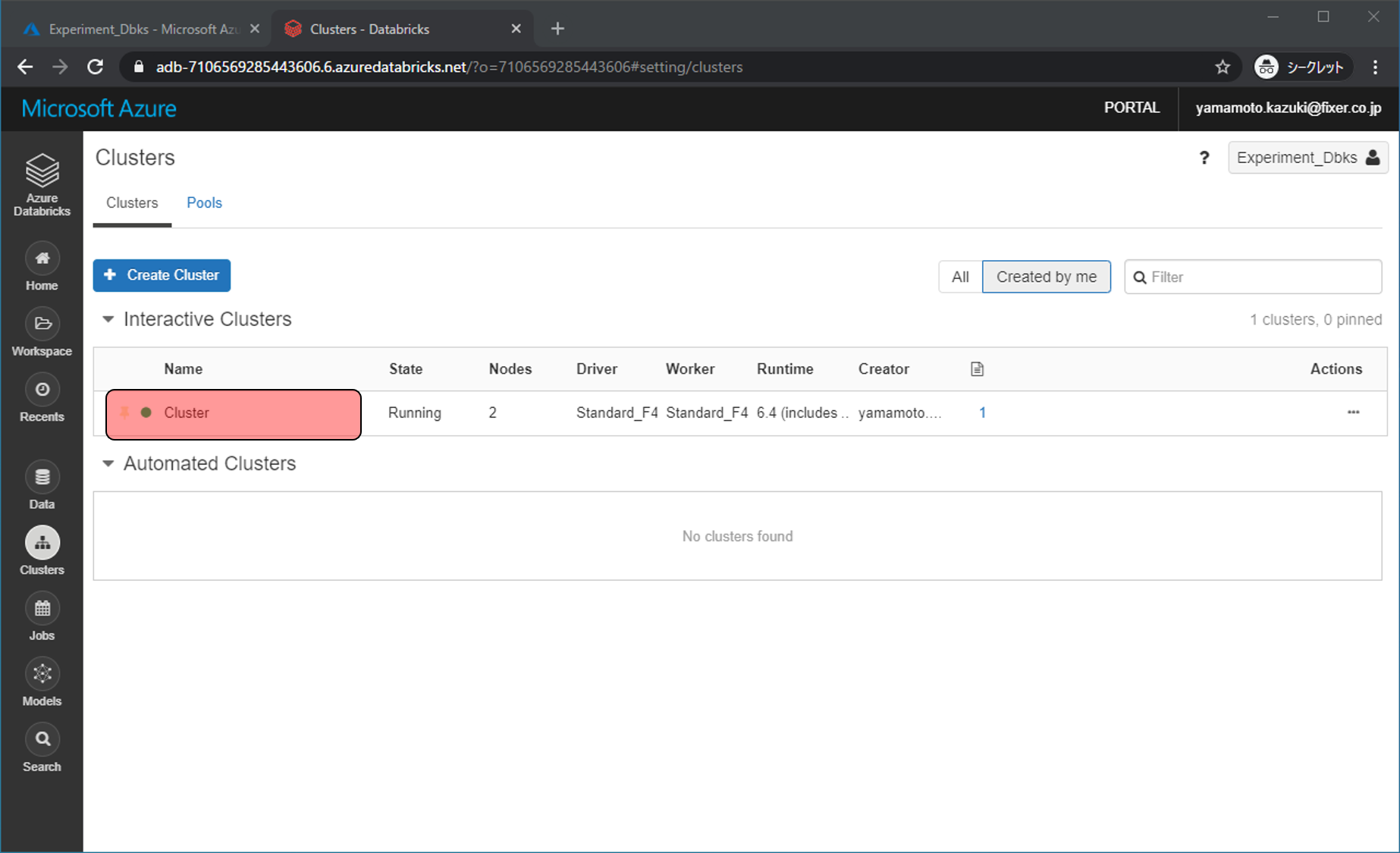
前回作成したクラスターをクリックします。
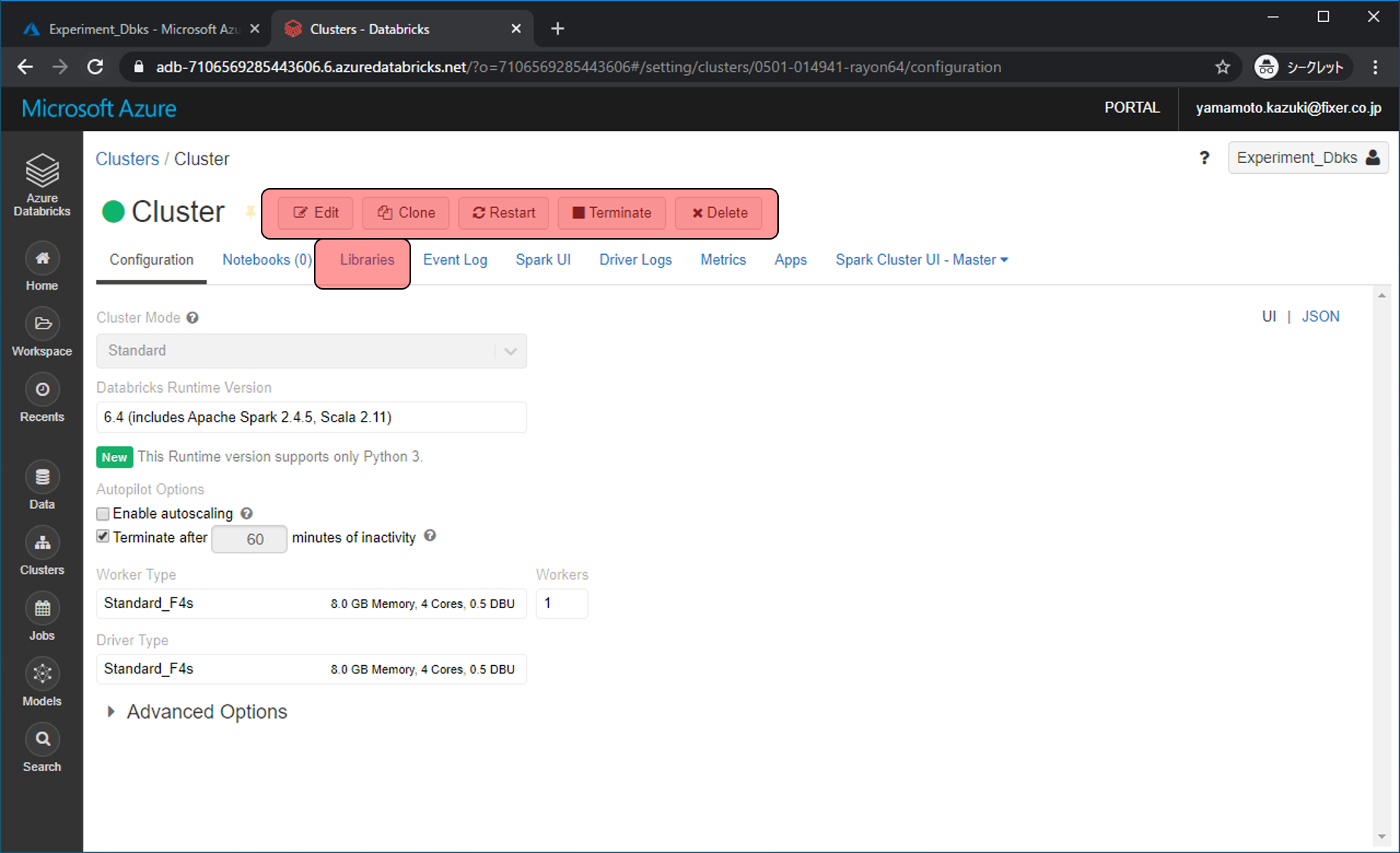
クラスターが起動していなかったらStartをクリックします(下の図では既に起動)。起動したらLibrariesをクリックします。
Install Newをクリックします。
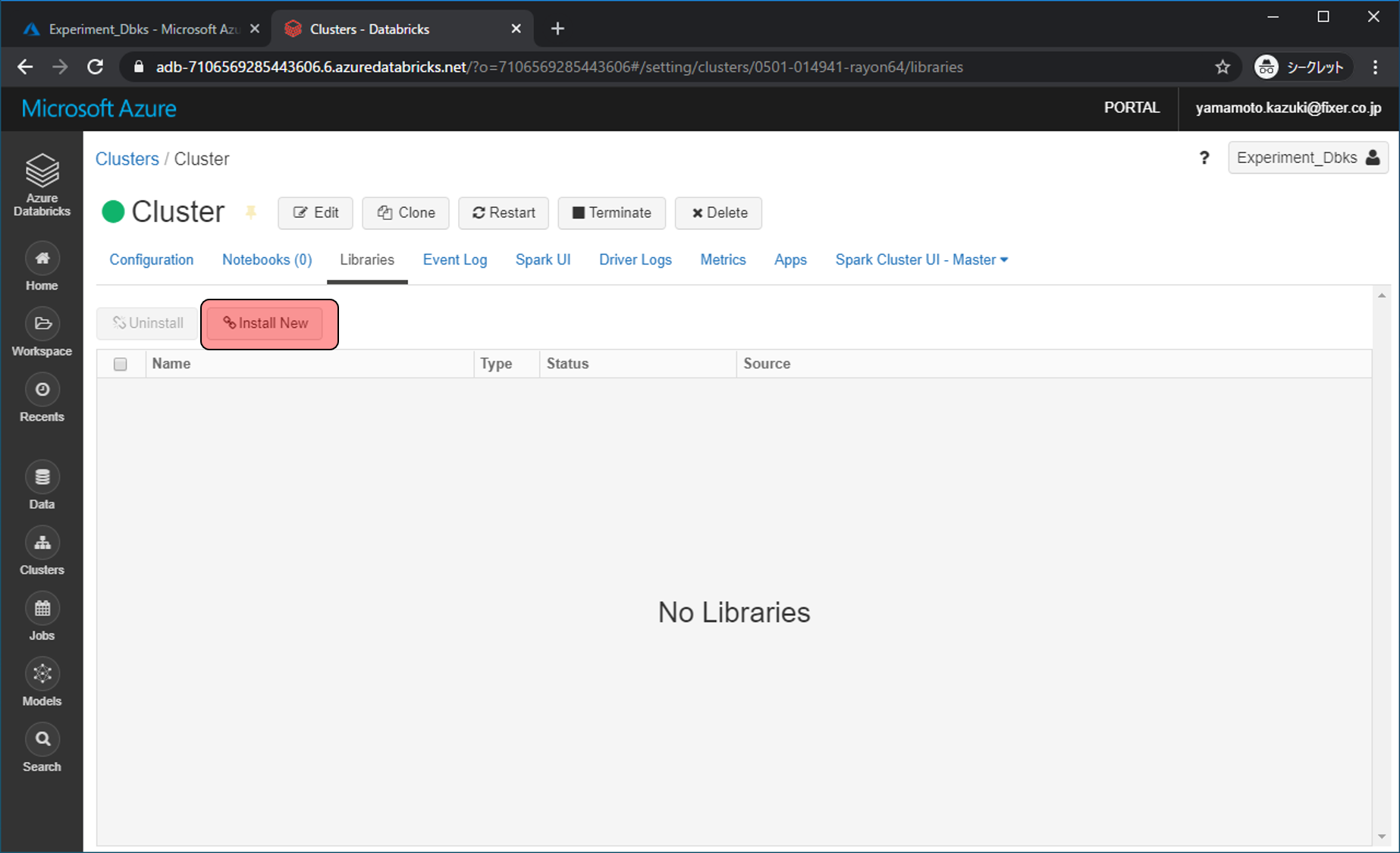
下記のように選択・入力し、Installをクリックします。
Library Source: Pypl
Package: azureml-sdk[databricks]
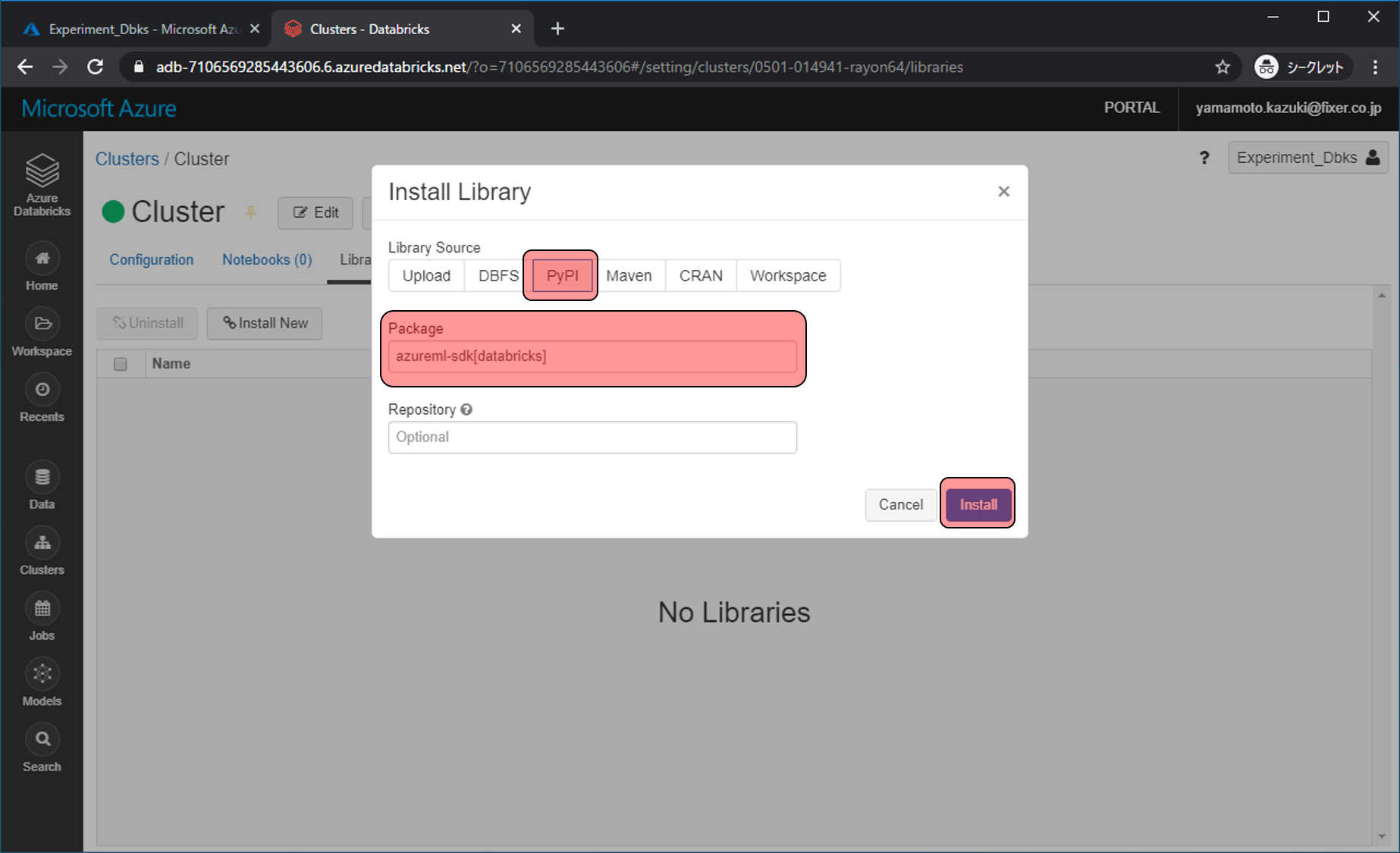
少しするとStatusがInstalledになります、これでAzure Machine Learning Serviceと接続するための準備は完了です。左上のAzure Databricksをクリックしてホーム画面に戻ります。
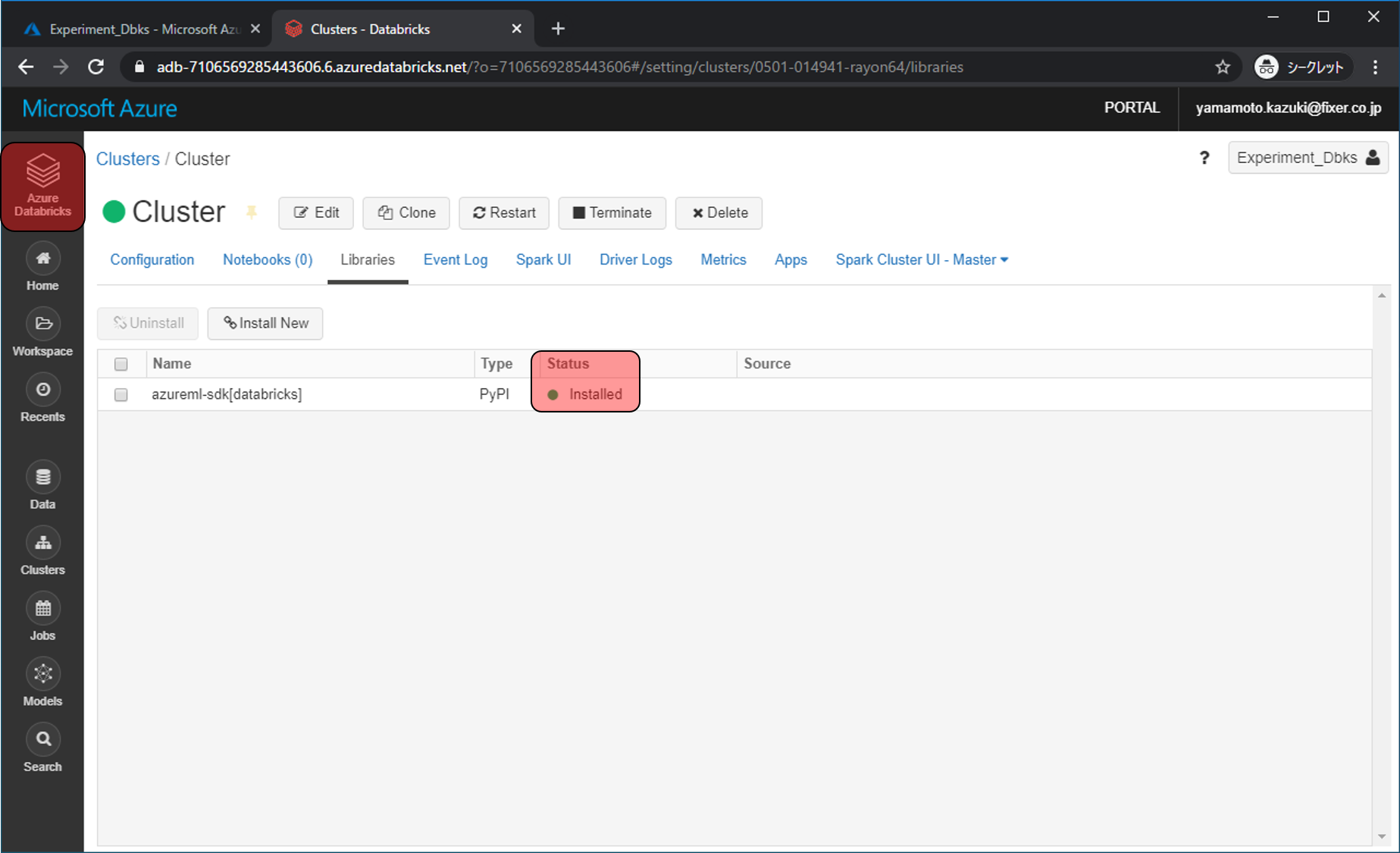
Pythonで予測モデルを作り始めます。New Notebookをクリックします。
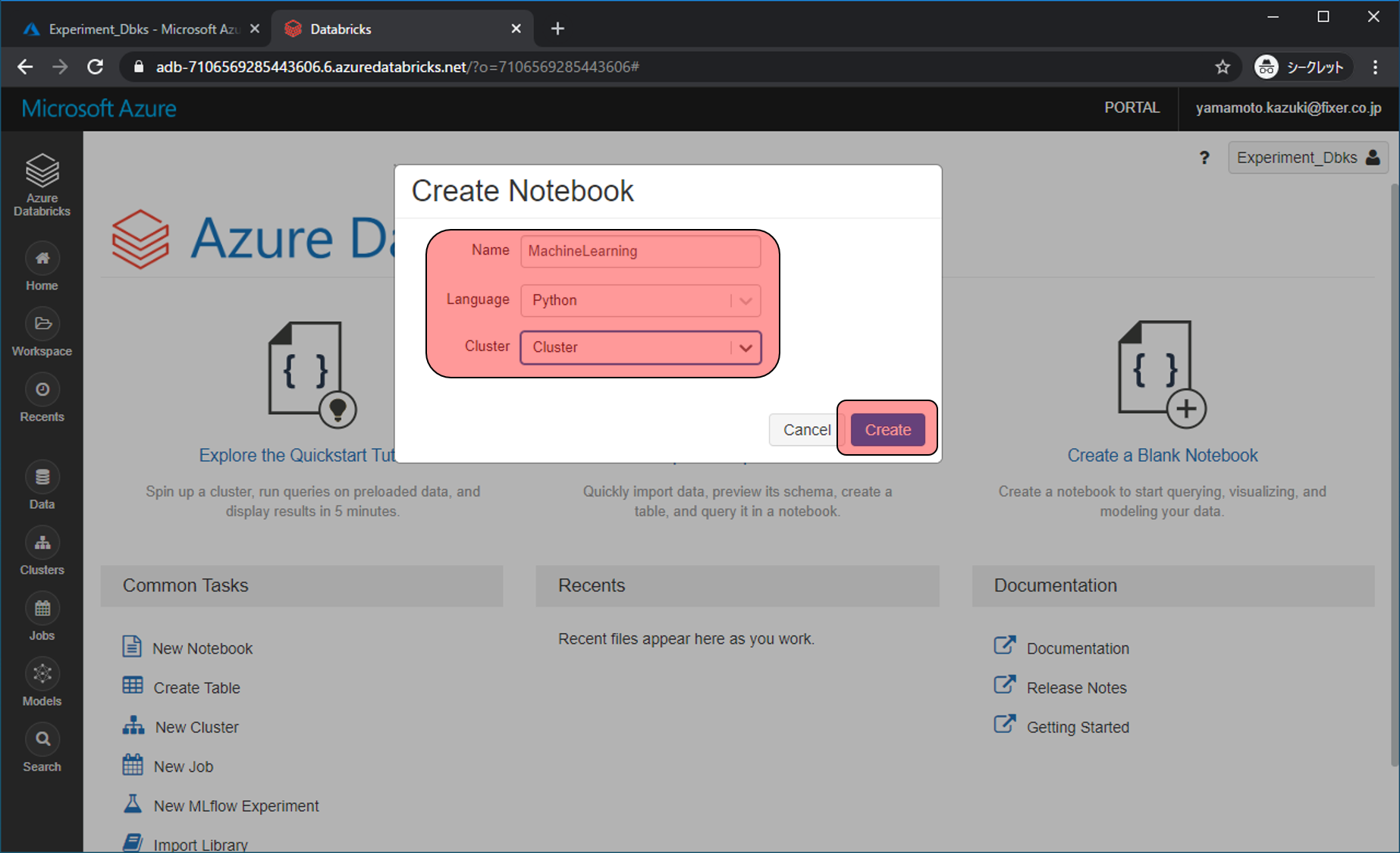
Notebookの名前や、言語、どのClusterで利用するかを選び、Createをクリックします。
- Name: 任意の文字列
- Language: Python
- Cluster: 先程作成したクラスター
Notebookが開けました。ここにコードを書いていきます。
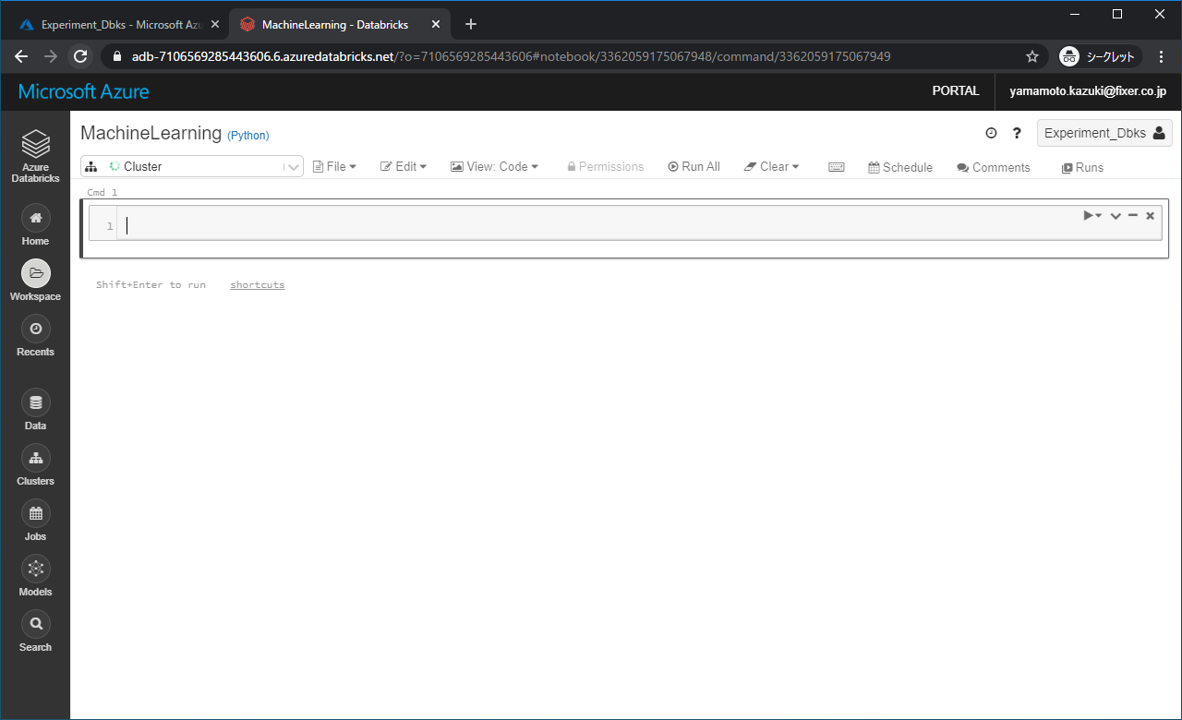
各コードは大きく分け下記の5つです。
- Blobのマウント
- マウントしたデータを使いやすい形式に変更
- Azure Machine Learning Serviceと接続
- 予測モデルの作成
- 作成した予測モデルの登録
まずはBlobのマウントをします。必要な情報の取得方法は前回の記事を確認してください。
- 任意のマウント先ディレクトリ名: mldata
- ストレージアカウント名: dbksblob
- コンテナー名: data
- ストレージアカウントアクセスキー: (シークレット)
mount_name= "(任意のマウント先ディレクトリ名)"
storage_account_name = "(ストレージアカウント名)"
container_name = "(コンテナー名)"
storage_account_access_key = "(ストレージアカウントアクセスキー)"
mount_point = "/mnt/" + mount_name
source = "wasbs://" + container_name + "@" + storage_account_name + ".blob.core.windows.net"
conf_key = "fs.azure.account.key." + storage_account_name + ".blob.core.windows.net"
mounted = dbutils.fs.mount(
source=source,
mount_point = mount_point,
extra_configs = {conf_key: storage_account_access_key}マウントしたBlobからcsvファイルを読み取り、読み取ったデータを扱いやすいpandas.DataFrameに変換しておきます。
pyspark_df = spark.read.option("header","true").option("delimiter", ";").csv("mnt/mldata/winequality-white.csv")
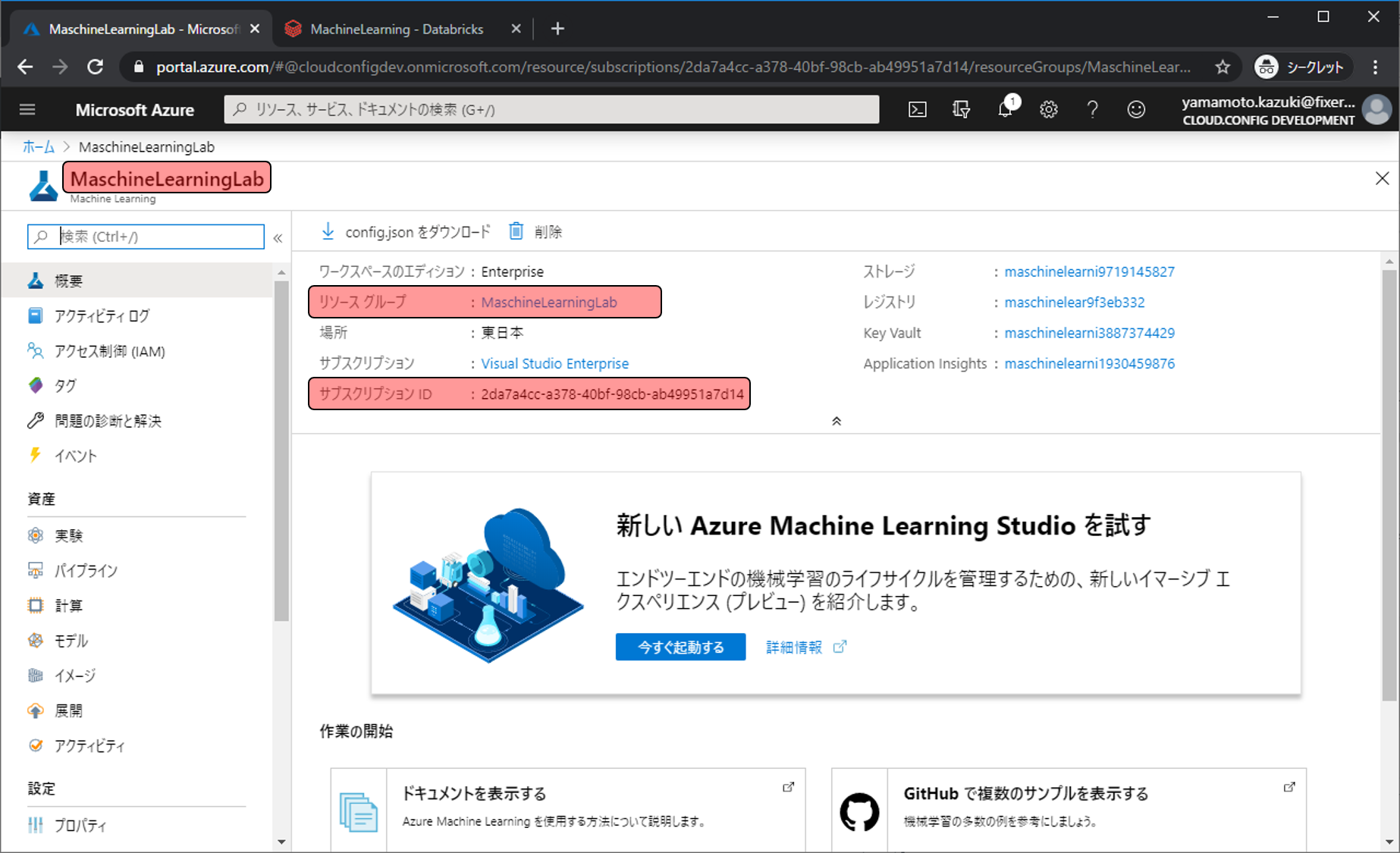
pandas_df = pyspark_df.toPandas()Azure Machine Learning Serviceと接続を確保します。接続には下記の3つが必要となるため、管理画面にアクセスして取得します。
- サブスクリプションID
- リソースグループID
- ワークスペース名
from azureml.core import Workspace
subscription_id = '(サブスクリプションID)'
resource_group = '(リソースグループ名)'
workspace_name = '(ワークスペース名)'
ws = Workspace(subscription_id, resource_group, workspace_name)Azure Machine Learning Serviceにモデルを作成する実験を登録します。これで、Azure Machine Learning Serviceのワークスペースからこのモデル作成の状況を確認することができます。
from azureml.core import Experiment
experiment = Experiment(workspace=ws, name="dbks-experiment")予測モデルを作成するために、データを加工して学習用データと評価用データの準備します。
from sklearn.model_selection import train_test_split
X = pandas_df.drop("quality", axis=1).values
Y = pandas_df['quality'].values
train_data, test_data, train_labels, test_labels = train_test_split(X, Y, test_size=0.1)ランダムフォレストで予測モデルを作成します。
from sklearn.ensemble import RandomForestRegressor
run = experiment.start_logging()
Rfr = RandomForestRegressor(n_estimators = 100)
Rfr.fit(train_data, train_labels)作成した予測モデルをAzure Machine Learning Serviceに登録します。
from sklearn.externals import joblib
model_name = "model_dbks.pkl"
joblib.dump(Rfr, "model_dbks.pkl")
run.upload_file(name=model_name, path_or_stream="model_dbks.pkl")
run.register_model(model_name=model_name, model_path="model_dbks.pkl")
run.complete()これらのコードを実行が完了するとAzure Machine Learning Serviceのワークスペースに結果が反映されます。ワークスペースに移動するため、Azure Machine Learning Serviceの管理画面に移動し、ワークスペースの起動をクリックします。
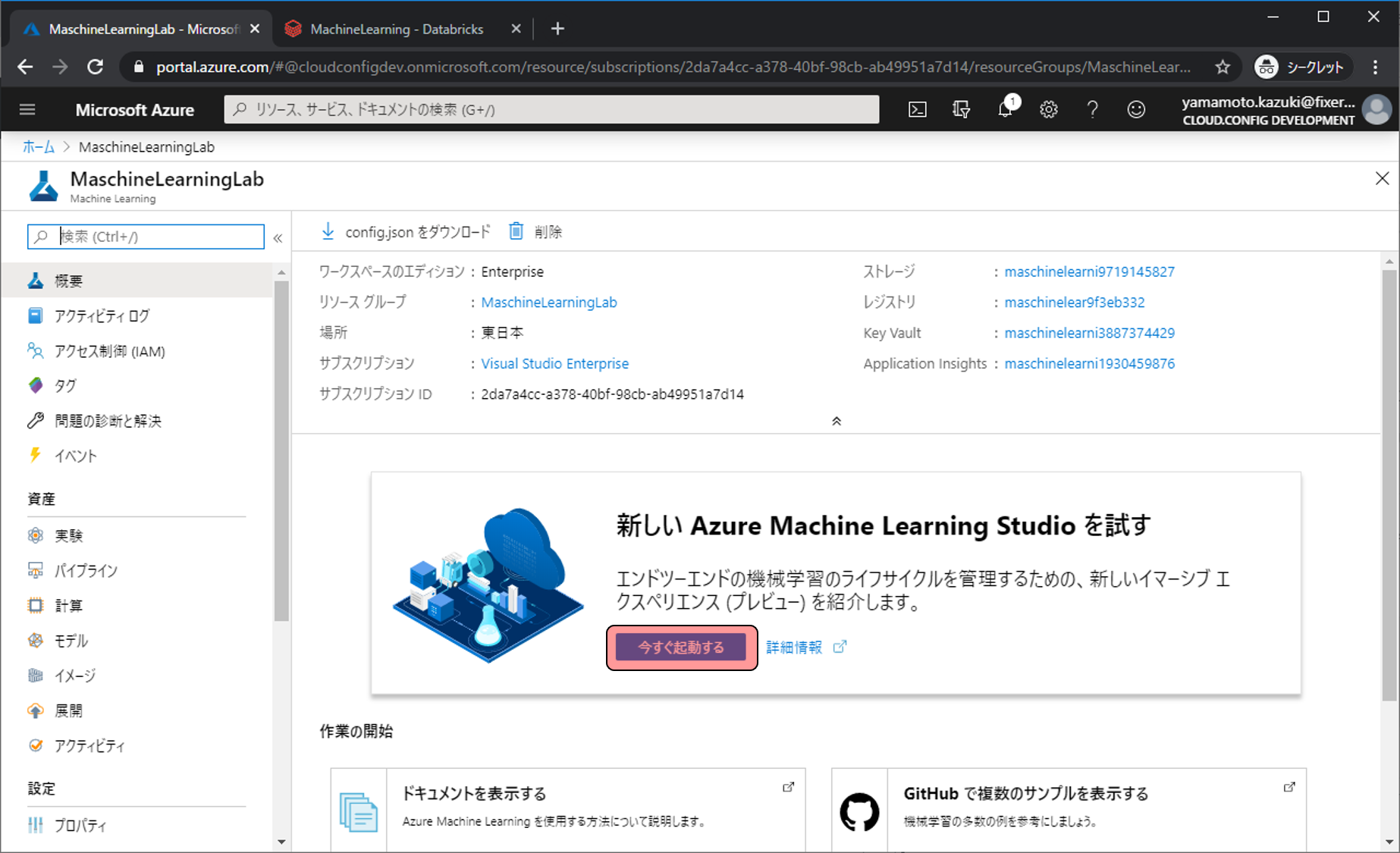
実行状態は実験から確認できます。pythonコードに内にログ出力等も書いておくことでより有効的に実験を扱うことができます。
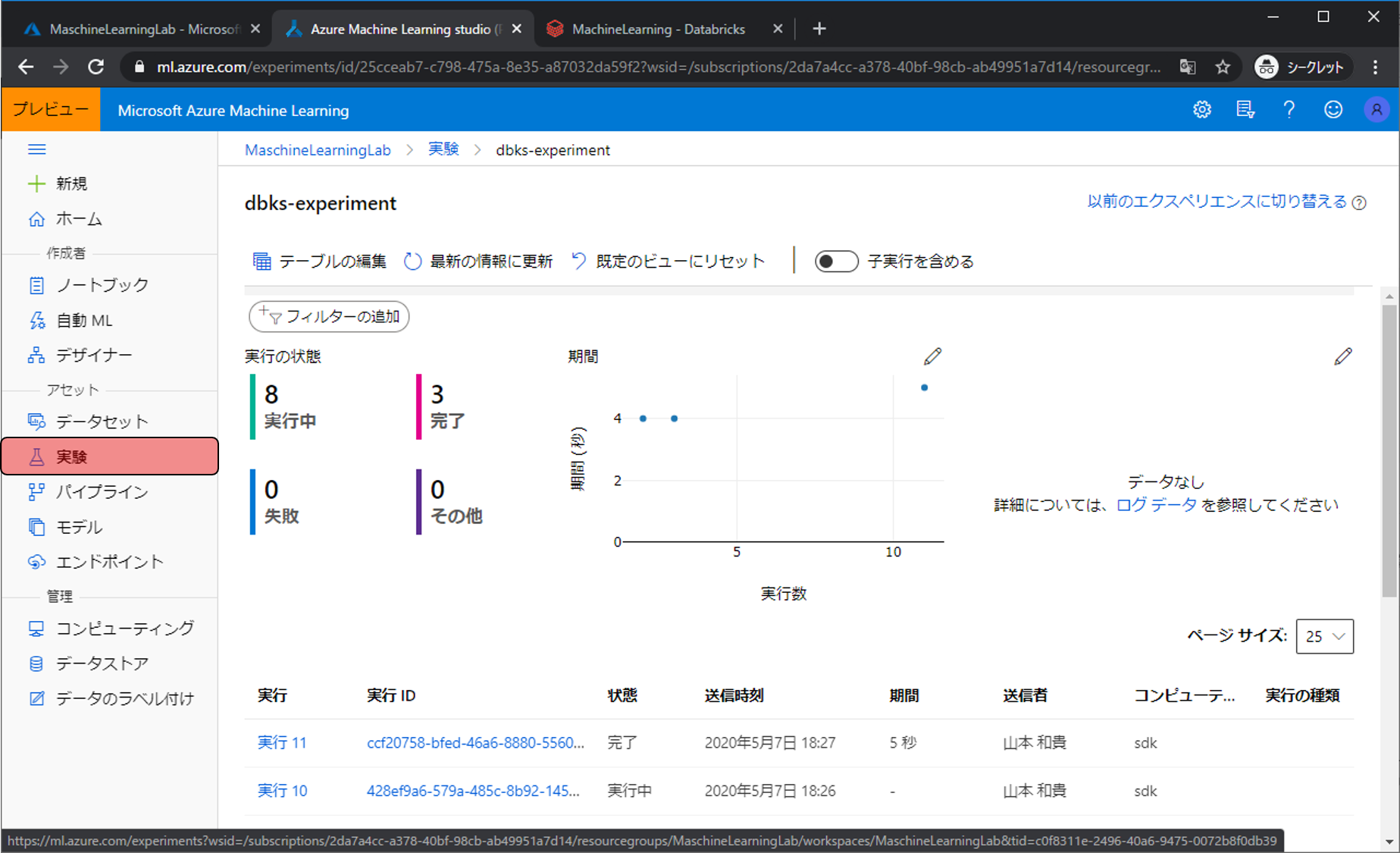
作成した予測モデルはモデルから確認できます。
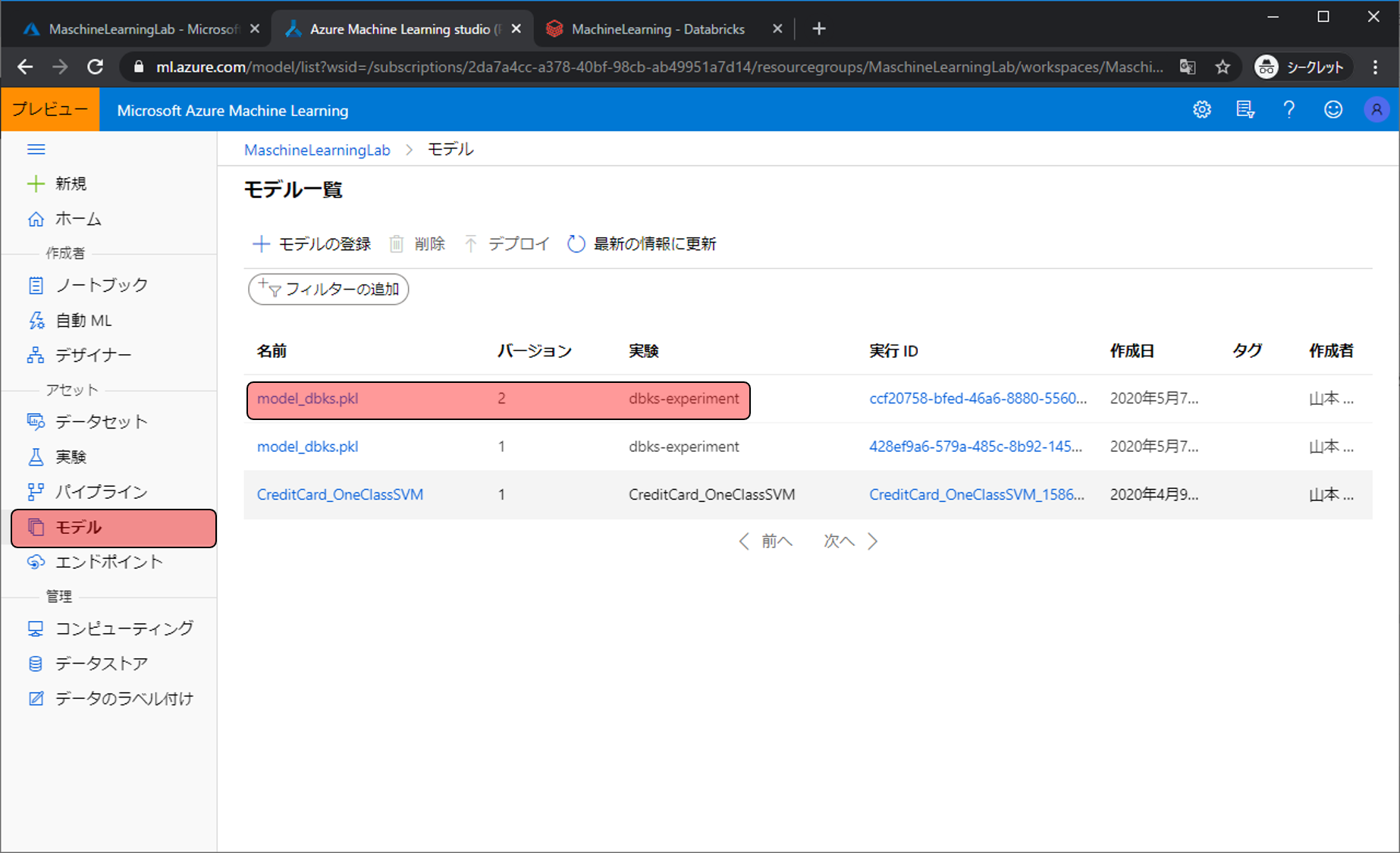
これでAzure Databricksを使った予測モデル開発は完了です。Azure Databricksだけでは作成したモデルの管理などが難しいので、ぜひAzure Machine Learning Serviceを一緒に使ってよい予測モデル開発ライフをお送りください!








![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)


