






この記事はなむゆの個人ブログにもマルチポストしています。
https://namyusql.hatenablog.com/entry/2021-02-15-azure-machine-learning…
はじめに
最近、再び機械学習熱が出てきたなむゆです。
AzureにはAzure Machine Learningという機械学習をローコードで行うサービスがあります。
これで久々に遊んでみようと思ったのですが、いつも頼りにしている Microsoft Learningのハンズオンを試していて日本語翻訳周りでかなり混乱した部分があったので、そのあたりを補完しながらリソース作成→回帰モデル生成までの流れをまとめてみたいと思います。
ただ、纏めていたら分量と画像の量が多くなってきたので、今回は内容を前後編に分け、前半ではサンプルデータの正規化まで行います。
下準備
まずはAzure ポータルから「Azure Machine Learning」のサービスを検索し、リソースを作成します。
リソースの名前とリージョン名だけ妥当な名前を入力し、作成を行います。
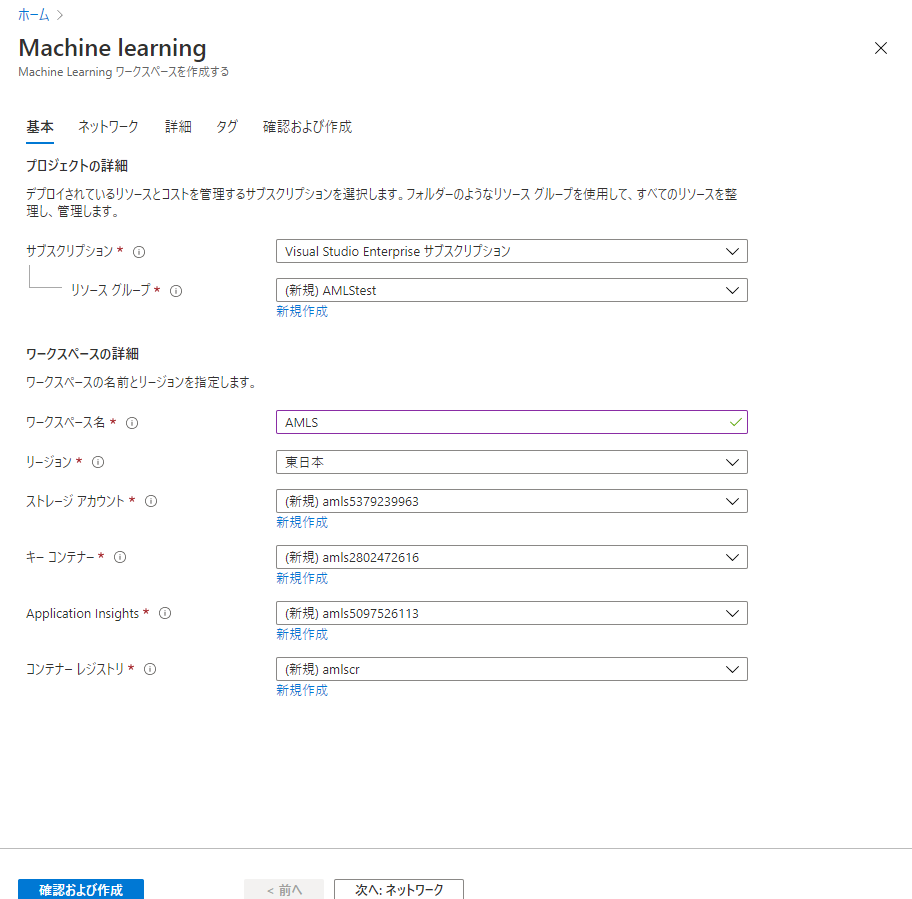
リソースが作成されたら、作成したAzure Machine Learningのリソースに移動し、「スタジオの起動」のボタンをクリックします。
すると、別タブでAzure Machine Learningの操作を行うスタジオのページが開きます。
Azure Machine Learningの機械学習関連のタスクは主にここで行われます。
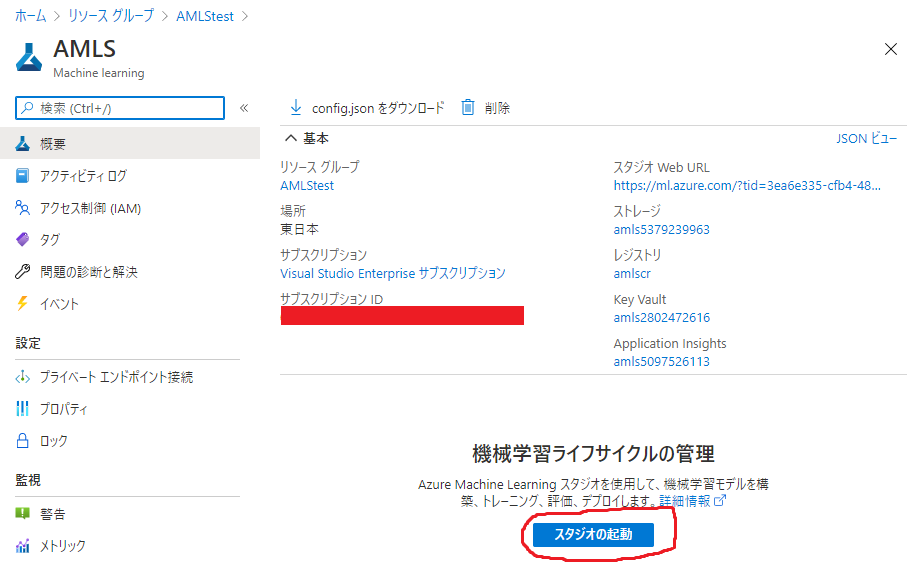
次は機械学習モデルのトレーニングに必要な「コンピューティングクラスター」を作成します。
Machine learningスタジオのホーム画面の左下の方にある「コンピューティング」ボタンを押します。
コンピューティングのページのタブを「コンピューティングクラスター」に切り替えます。
ここには作成したのコンピューティングクラスターの一覧が表示されますが現状は存在しないので「新規」ボタンから新規作成を行います。

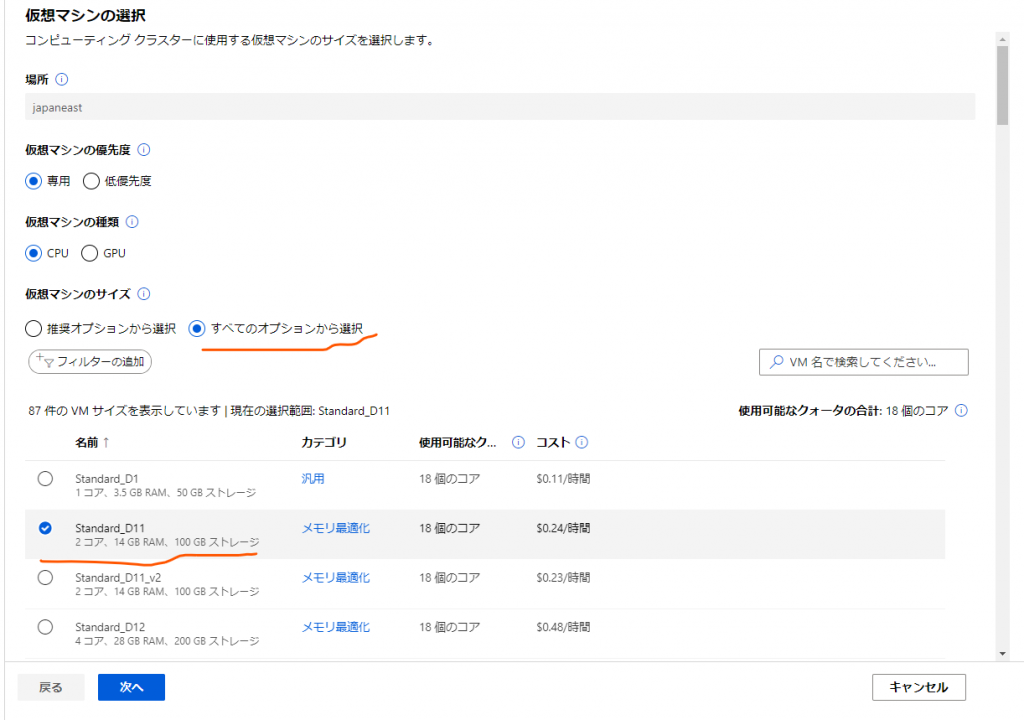
設定内容としてははLearnで解説されているとおり仮想マシンに「Standard_D11_v2」を選択したいのですが、初期状態では仮想マシンの選択肢にそのオプションが表示されていません。
なので、「仮想マシンのサイズ」の欄の「全てのオプションから選択」のラジオボタンを選択状態にしてそのオプションを表示させ、選択しておきます。
設定したら「次へ」ボタンを押します。
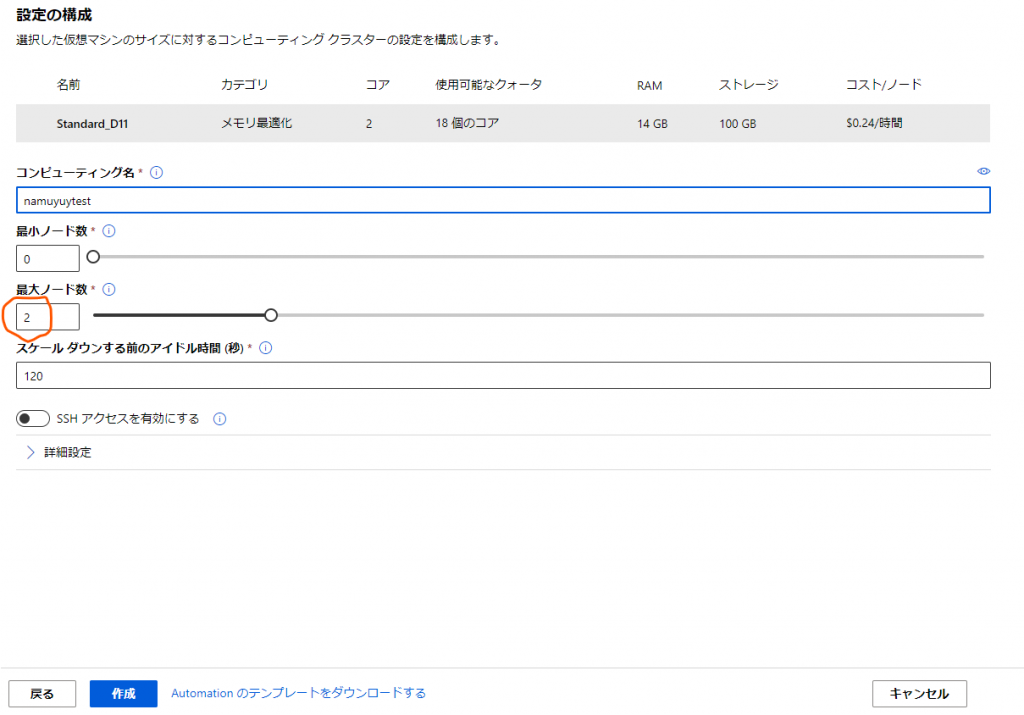
続いてクラスターのコンピューティング名などを設定します。
ここもLearnに合わせて最大ノード数を2に設定します。
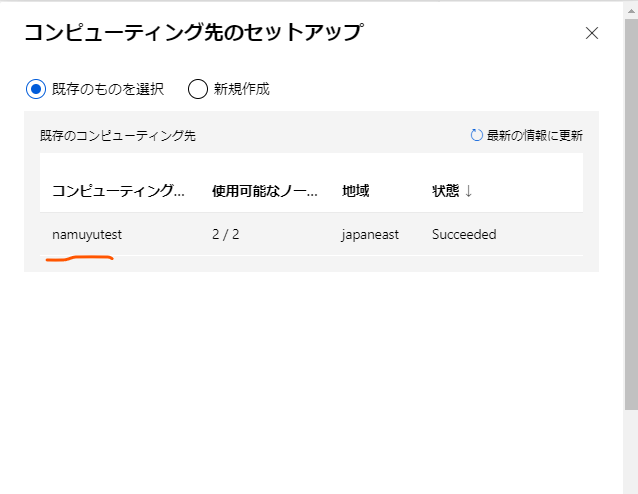
コンピューティング名は覚えられるもので設定しましょう。自分の場合は「namuyutest」としています。
設定できれば「作成」ボタンを押してクラスターの作成を開始します。
これで必要な下準備は完了です。続いて実際にモデルを作成していきましょう。
データの前処理を行う
今回はオーソドックスに回帰モデルを作っていくのですが、一般的に機械学習を行う時の流れとして「データを取ってくる」→「データの前処理を行う」→「モデルのトレーニングを行う」という手順を踏みます。
この処理をそれぞれ一つの塊として、モデル作成の手順を一続きにしてつなぎ合わせたものを「パイプライン」と呼びます。
Azure Machine Learningで機械学習を行う方法の一つとして、そのパイプラインを「デザイナー」という機能を使って行うものがあり、今回はそれを利用します。
まずはホーム画面から、再び左の法のアイコン一覧のうち今度は上の方の「デザイナー」のボタンをクリックします。
すると、これまでデザインしたパイプラインの一覧の画面に移るのですが今回はまだパイプラインを作成していないので上の方のプラスボタンを押して新規作成します。
デザイナーの画面にやってきました。
ここでまず行うのは、Learningと合わせてパイプラインの名称を変えることです。
現在のパイプラインの名称をクリックすると名前を変更できるので、「Auto Price Training」に置き換えておきます。適当にどこか別のところをクリックすると自動でセーブされます。
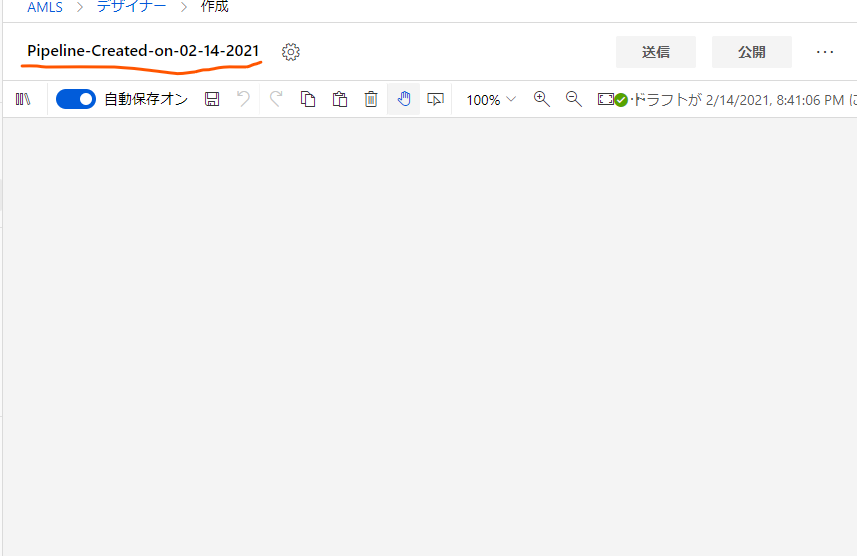
次に、その名前の横の歯車ボタンから、パイプラインの設定画面に入ります。
ここで、このパイプラインがモデルのトレーニングに使用するコンピューティング先(コンピューティングクラスター)を選択します。
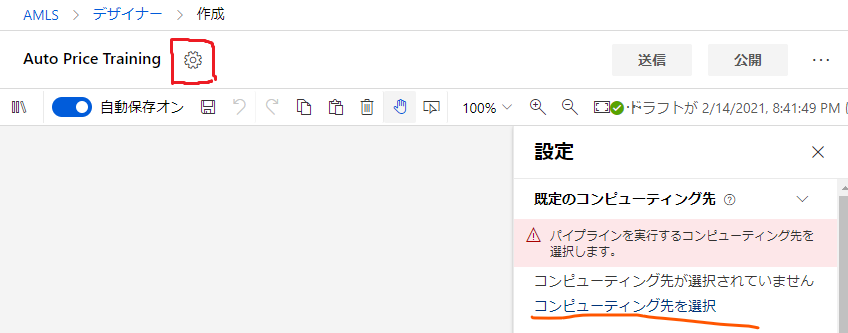
先程作成したコンピューティングクラスターを選択して確認ボタンを押します。
ちなみにその確認ボタンはモーダルの中の画面外の下の方にあるのでスクロールして探してください。
間の空白は一体。
設定を終えたら、パイプラインのデザインを行っていきます。
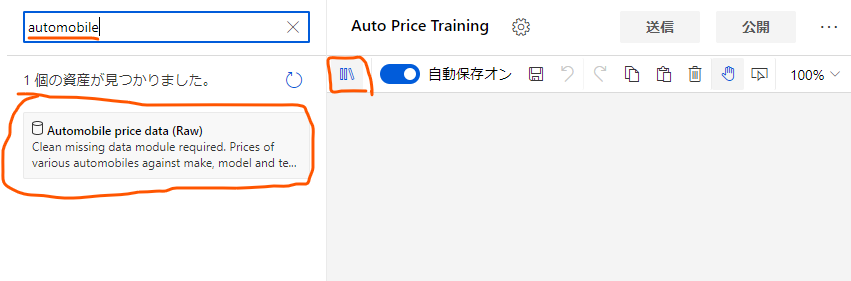
まずは、「データを取ってくる」の部分を作ります。デザイン画面右上の本棚のようなボタンを押し、出てくる検索窓に「automobile」あたりの文字を入力し、「Automobile price data (Raw)」を探します。
これが今回使用するサンプルデータです。
見つけられたら、これをデザイン画面内にドラッグアンドドロップします。
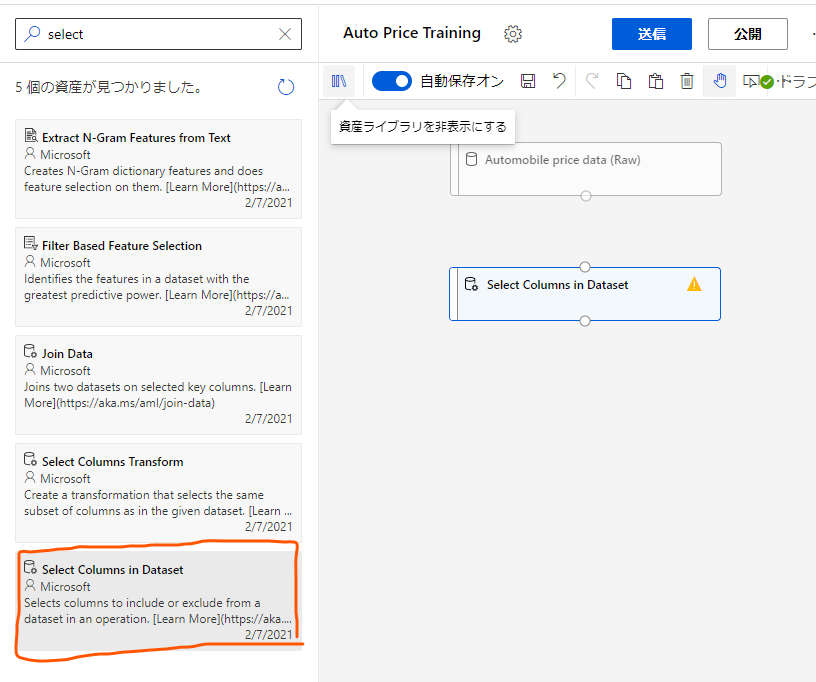
次はこのデータに前処理をかける部分を作成していきます。
再び本棚のアイコンをクリックし、今度は「Select Columns in Dataset」をドラッグアンドドロップします。
これはこのモジュールにやってきたデータから必要な列だけを選択する部分になります。
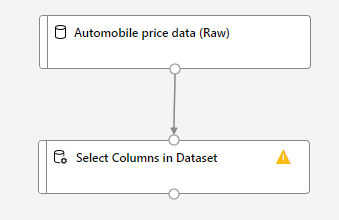
ドラッグアンドドロップ出来たら、これまで持ってきたモジュールをつなぎ合わせます。「Automobile price data (Raw)」の下の〇から「Select Columns in Dataset」の上の〇までドラッグします。
これによって、生のデータから列を選択することができるようになります。
次はその列選択の設定を行います。
列選択のモジュールをクリックし、右に出てくる設定画面から「列の編集」をクリックします。
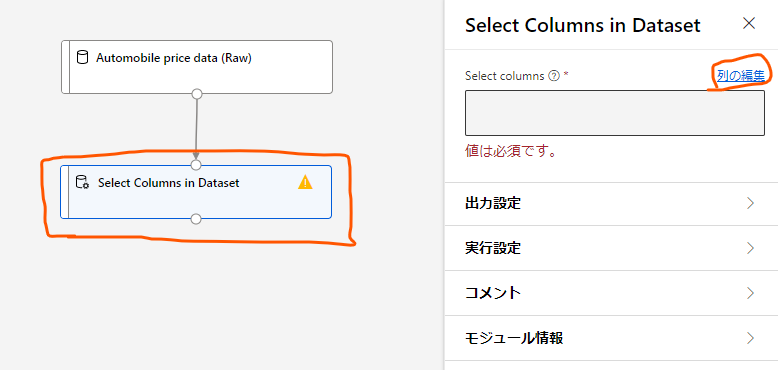
すると、このモジュールにやってくるデータの中のどの列を使用するかを選べます。
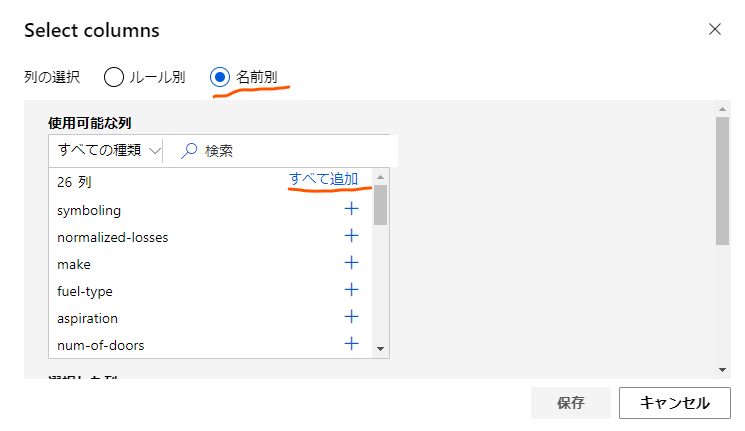
ここでは「名前別」のラジオボタンをクリックし、使用する列を選択します。
今回は「normalized-losses」以外の列を全部使用するので、列を全部追加した後で「normalized-losses」だけを削除する形で設定しました。
設定ができたら、「保存」ボタンをクリックして閉じます。
次は、「Clean Missing Data」と「Normalize Data」のモジュールを同じく本棚のメニューから探して持ってきて、画像のようにつなぎ合わせます。
これらは、それぞれデータの入っていない列のあるデータの削除を行ったり、データの正規化(それぞれのデータの値が取る値の範囲を扱い範囲に収まるよう変形する)を行ったりするのに使います。
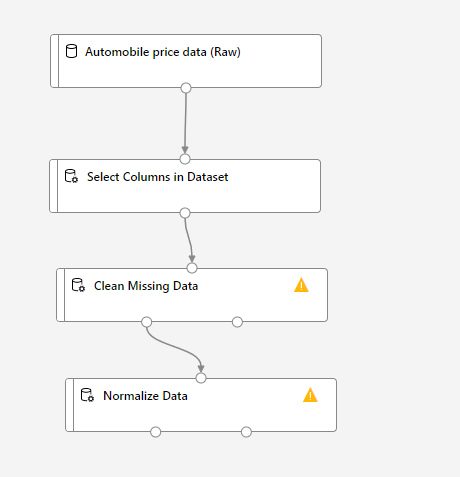
これらの設定を行っていきましょう。
まずは「Clean Missing Data」の設定から始めます。
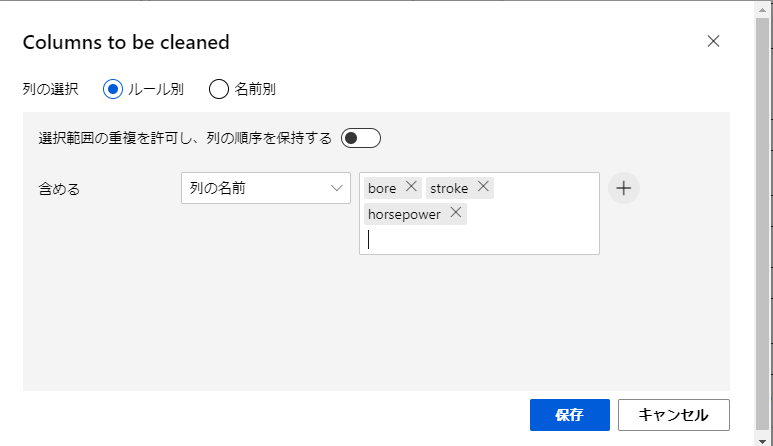
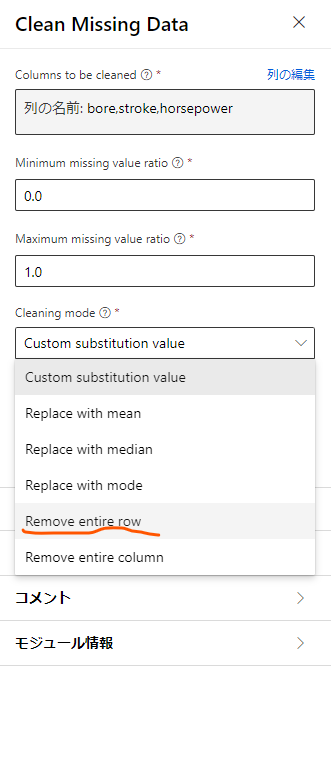
ここでは、特定の列に足りないデータがある際の動作を設定するのですが、まずは「列の選択」をクリックして足りないデータがあるかチェックする列を指定します。
今回は「bore」「stroke」「horseposer」の3つを設定して保存します。
続いて、設定画面の下の方の「Cleaning mode」から、先程選択した列の値が存在しなかった場合の振る舞いを設定します。
今回は、それらの値が存在しなかった場合はそのデータがある行を丸々サンプルから排除することにするため、「Romove entire row」を選択します。
次に「Normalize Data」をクリックしてデータの正規化の設定を行います。
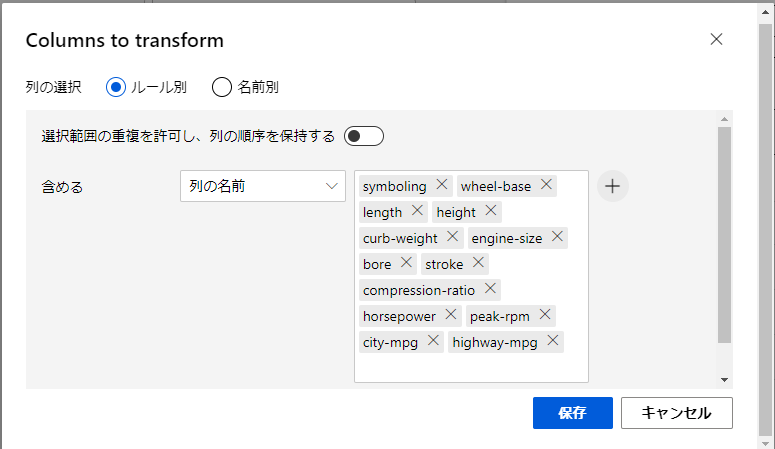
今回は、正規化の処理を行う列を選択するため、再び「列の選択」をクリックして設定モーダルを開きます。
ここでは、以下の画像に示している列の名前をルールに追加しておきます。
これによって、追加した名前の列のデータに対して正規化を書けることができます。設定できたら保存ボタンを押して戻ります。
ここまででサンプルデータの前処理のパイプラインを組むことができたので、これを実行してみましょう。
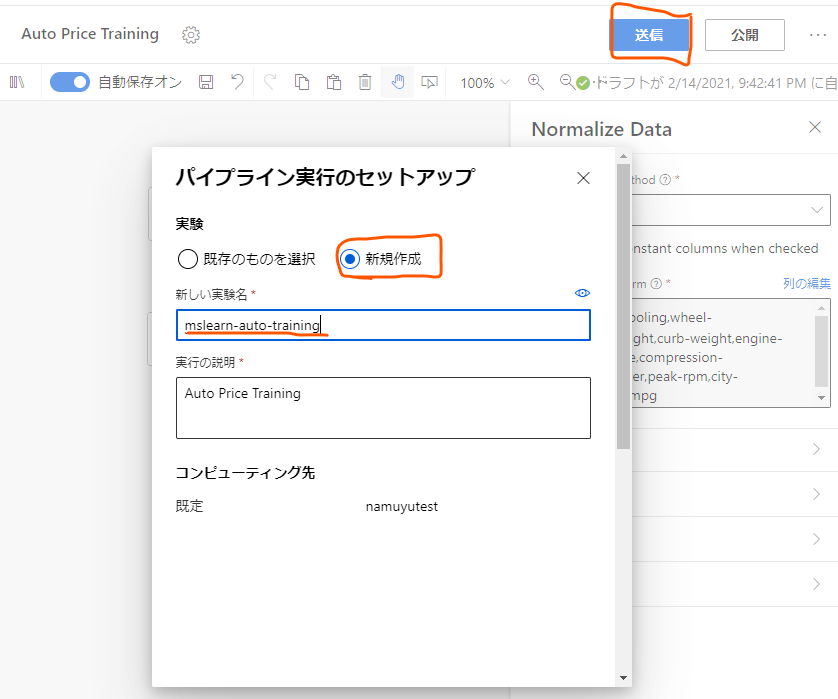
デザイナー画面上部の「送信」ボタンを押し、パイプライン実行のセットアップのモーダルを呼び出します。
新しい実行を行うので、「新規作成」のラジオボタンを選択し、新しい実験名として「mslearn-auto-training」を入力します。
設定ができたら下部の「送信」ボタンを押してこのパイプラインの処理をコンピューティングクラスターに送信します。
これで実験が始まるのでしばらく待ちましょう。
実験が進むと各モジュールの横に「完了」と表示され、全部のモジュールの処理が完了すればパイプライン全体の処理が完了となります。
処理の完了したモジュールは、その処理の終了時点での出力を確認することができます。
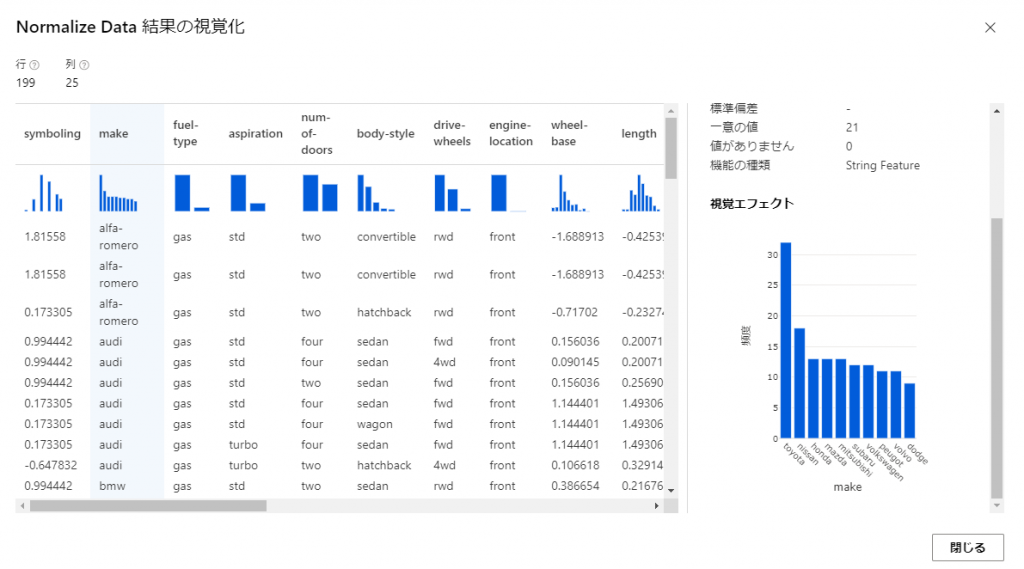
例えば、「Normalize Data」の出力を確認してみます。
Normalize Dataのモジュールを開き、「出力とログ」のタブを開きます。
上の方の「データ出力」の欄の「Transformed dataset」の棒グラフのアイコンをクリックすると出力されたデータが確認できます。
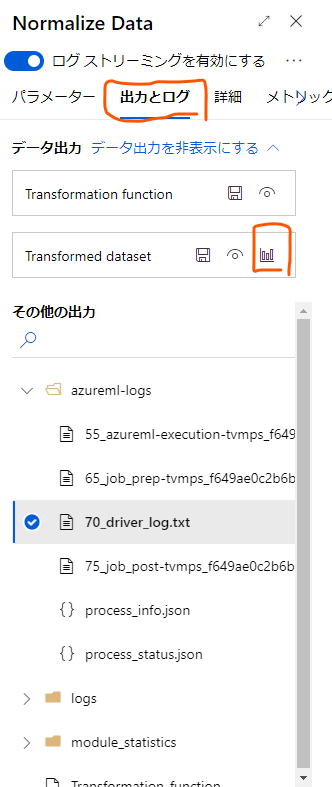
ここで各種データの値と、列ごとに集計された棒グラフが確認できます。
棒グラフからはデータの全体的な分布を把握することもできます。
この図とパイプラインの視点になる生データのモジュールの出力を見比べると前処理として削除されたデータや列があったり、正規化されてデータの値が大体-1から1の間に変換されている列があることが分かるはずです。
おわりに
今回はAzure Machine Learningのデザイナーを使用して機械学習のパイプラインをデータの正規化をするところまで作成しました。
Learnを見ながらやると途中で表示内容が違っていて詰まることが多かったので、その部分が補完できているとうれしいです。
続きはまた完成し次第リンクを張ろうと思います。
参考








![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)


