


 2022-06-13
2022-06-13

はじめに
最近少し触っていたAzure Data Factory(以下、Data Factory)について、ハンズオン形式で簡単な紹介をしたいと思います。
この記事ではETLをしてみたい方、Data Factoryを触ったことがない方に向けて実際にData Factoryを動かすところまでを体験してみましょう。
Data Factoryとは
Data FactoryはAzureの中のETLツールと呼ばれる分類にあたる製品です。
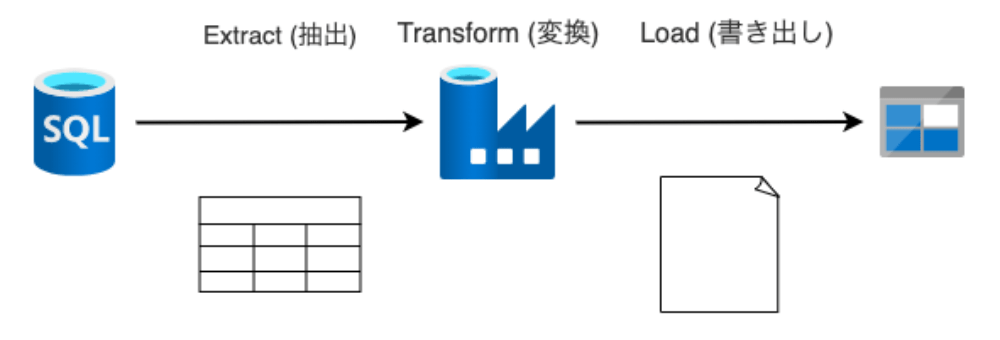
Azure Data Factory は、ETL (抽出 - 変換 - 読み込み)、ELT (抽出 - 読み込み - 変換)、データ統合という複雑なハイブリッド プロジェクト用に構築された、管理クラウド サービスです。
そもそもETLツールとは?という方はAzureのデータサービスの基礎についてまとめたこちらの記事を参考にしてみてください。
触ってみよう
ゴール
今回のゴールはこちらです。SQLデータベースのデータを抽出し、必要な変換を行ってBLOBストレージにファイルを出力します。
1.準備
1.1. サブスクリプションを用意
Azureのアカウントにサブスクリプションが紐づいていない方は準備しましょう。無料アカウントを用意する方法はこちらです。
1.2. 必要なリソースを作成
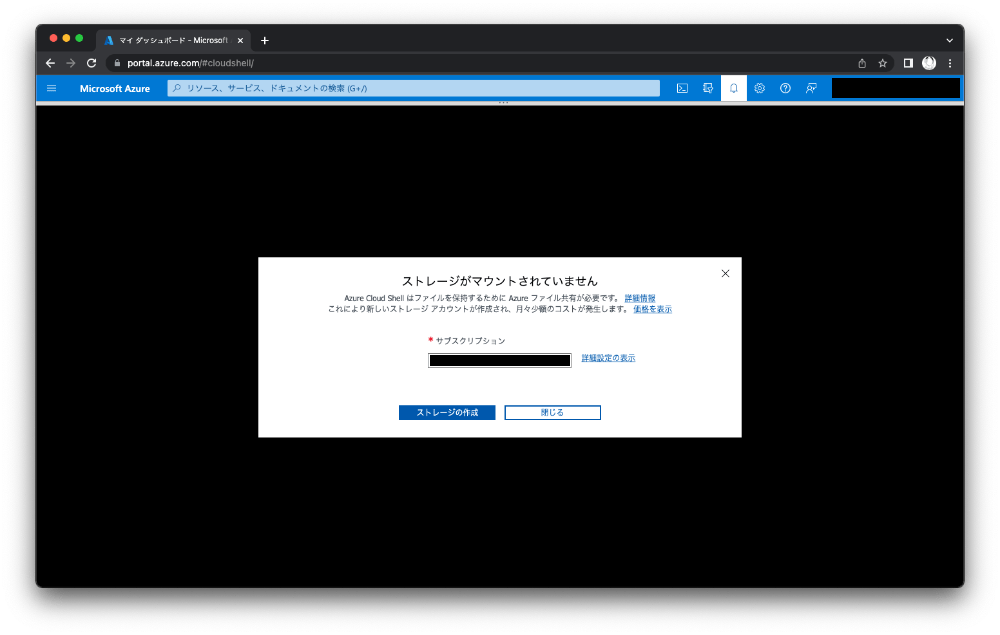
Data Factoryを触るまでの準備がたくさんあるので、Azure Cloud Shellを使ってサクッと作ってしまいましょう。初めてAzure Cloud Shellを使う方は先にストレージアカウントを作成してください。
準備ができたら、以下のPowerShellコマンドの適当な管理者名と適当なパスワードを書き換えてコピーして実行してください。コマンドの中身が気になる人は参考のリンクも併せてゆっくり読んでください!
# 各種変数
$resourceGroupName = "adfhandson-rg"
$sqlServerName = "adfhandson-sql"
$sqlDatabaseName = "adfhandson-sqldb"
$storageAccountName = "adfhandsonst"
$locationName = "japaneast"
$adminName = "{適当な管理者名}"
$password = "{適当なパスワード}"
$startIp = "0.0.0.0"
$endIp = "0.0.0.0"
# リソースグループを作成
$resourceGroup = New-AzResourceGroup -Name $resourceGroupName -Location $locationName
# SQLサーバーを作成
$sqlServer = New-AzSqlServer -ResourceGroupName $resourceGroupName `
-ServerName $sqlServerName `
-Location $locationName `
-SqlAdministratorCredentials $(New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $adminName, $(ConvertTo-SecureString -String $password -AsPlainText -Force))
# ファイアーウォールを設定
$firewallRule = New-AzSqlServerFirewallRule -ResourceGroupName $resourceGroupName `
-ServerName $sqlServerName `
-FirewallRuleName "AllowedIPs" -StartIpAddress $startIp -EndIpAddress $endIp
# S0のデータベースを作成
$sqlDatabase = New-AzSqlDatabase -ResourceGroupName $resourceGroupName `
-ServerName $sqlServerName `
-DatabaseName $sqlDatabaseName `
-RequestedServiceObjectiveName "S0" `
-SampleName "AdventureWorksLT"
# Standard 汎用 v2のストレージアカウントを作成
$storageAccount = New-AzStorageAccount -ResourceGroupName $resourceGroupName `
-Name $storageAccountName `
-Location $locationName `
-SkuName Standard_RAGRS `
-Kind StorageV2実は上のコマンドではコンテナーストレージとData Factoryの作成が含まれていません。これらはAzure Portalで作成していきましょう。
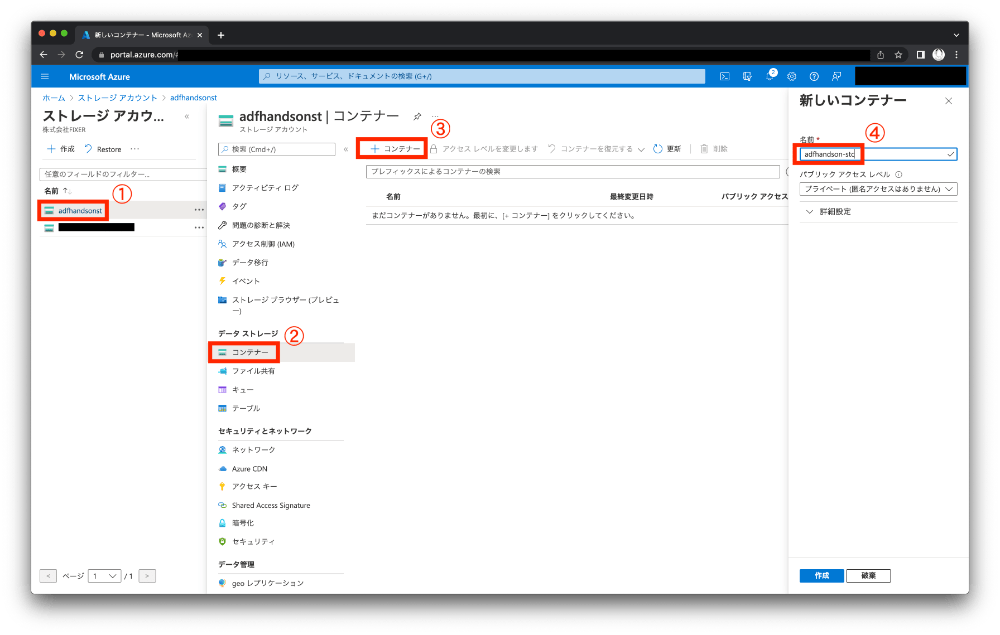
Azure Portalを開き、先ほど作成したストレージアカウントadfhandsonstから「新しいコンテナー」でadfhandson-stcを作成しましょう。
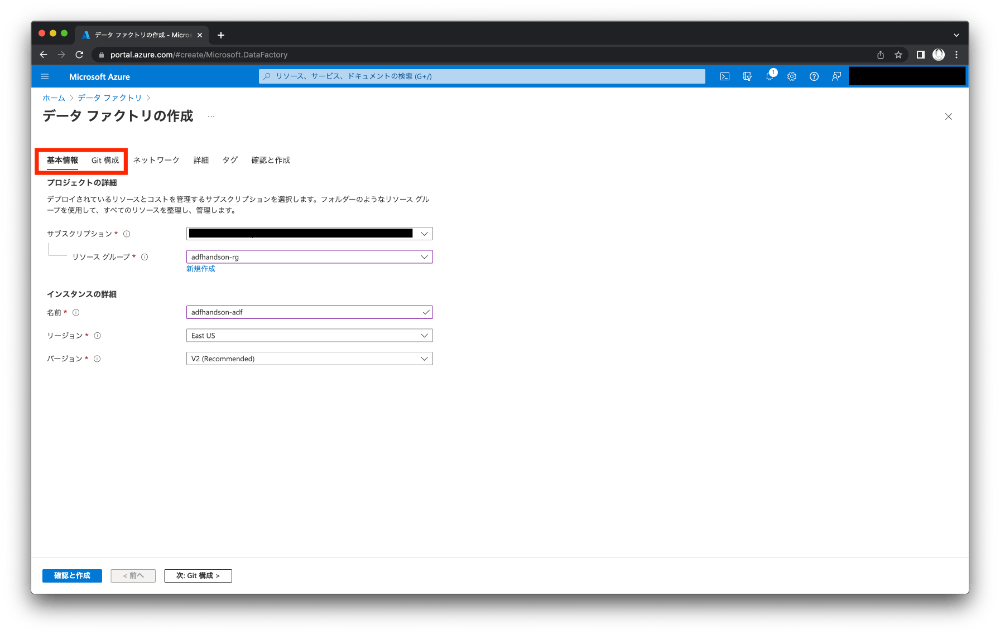
出来たら次はリソースの検索からデータファクトリを作成します。「基本情報」で必要な情報を入力し、「Git 構成」では[後で Git を構成する]を選択したら作成します。
これで必要なリソースも揃いました。
1.3. テストデータを作成
次はテストデータを作成します。SQLデータベースadfhandson-sqldbの「クエリエディター(プレビュー)」で以下のクエリを実行してテストデータを作りましょう。
CREATE TABLE Student (
Name VARCHAR(20) PRIMARY KEY,
Japanese INT,
Math INT,
English INT
)
INSERT INTO [dbo].[Student]
([Name],[Japanese], [Math], [English])
VALUES
('Nobita', CONVERT(int,RAND() * 100), CONVERT(int,RAND() * 100), CONVERT(int,RAND() * 100)),
('Suneo', CONVERT(int,RAND() * 100), CONVERT(int,RAND() * 100), CONVERT(int,RAND() * 100)),
('Taleshi', CONVERT(int,RAND() * 100), CONVERT(int,RAND() * 100), CONVERT(int,RAND() * 100)),
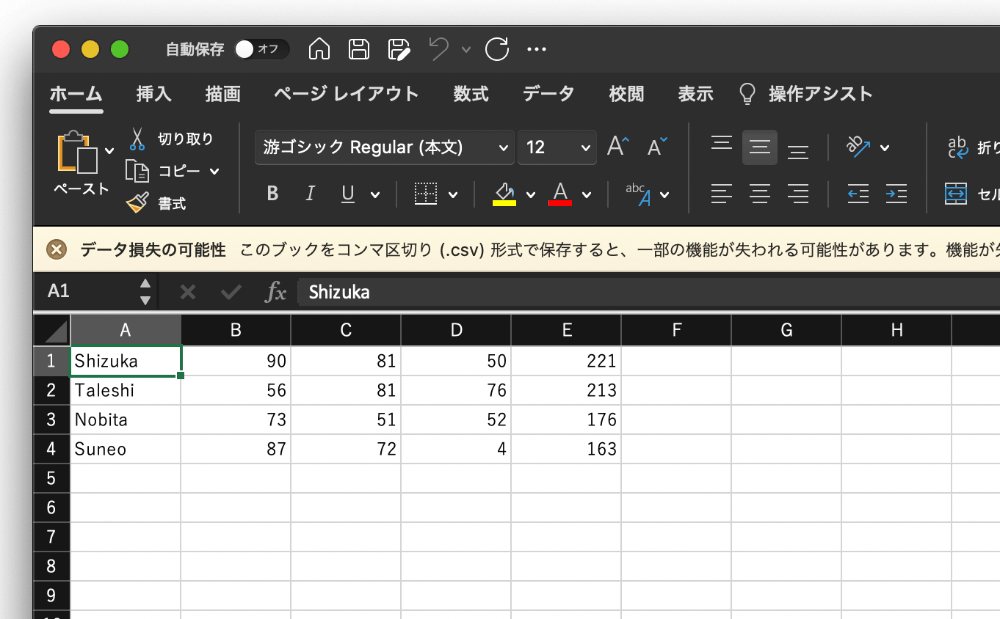
('Shizuka', CONVERT(int,RAND() * 100), CONVERT(int,RAND() * 100), CONVERT(int,RAND() * 100))実行すると以下のような生徒と3教科の点数のデータができました。

2.Data Factoryを触る
Data Factoryはデータセット、データ フロー、パイプラインという3つの要素から構成されます。
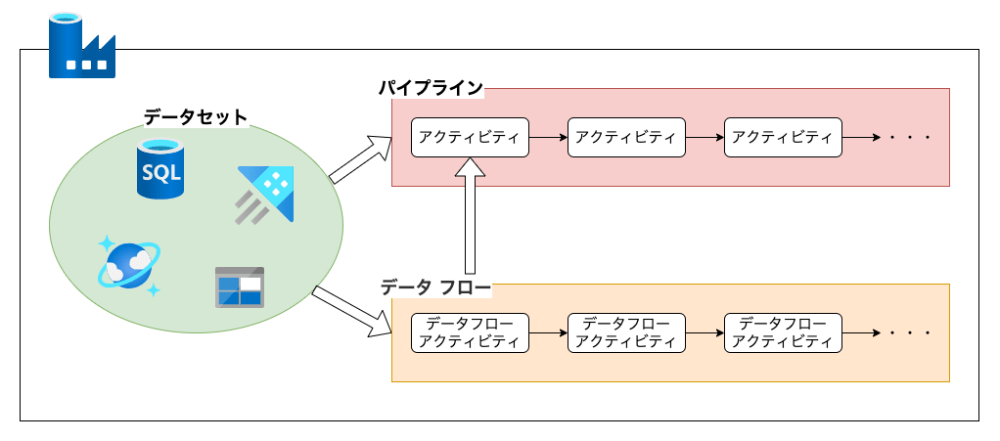
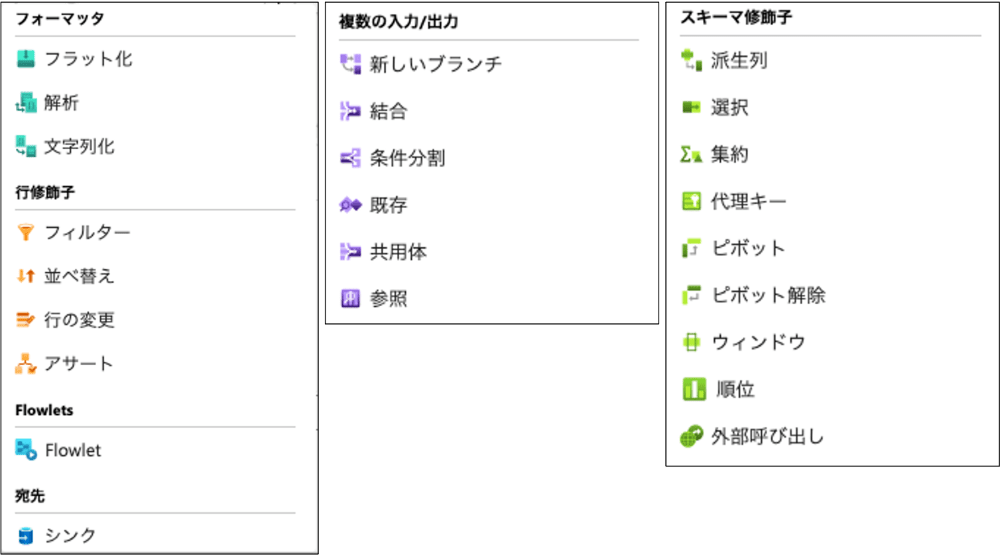
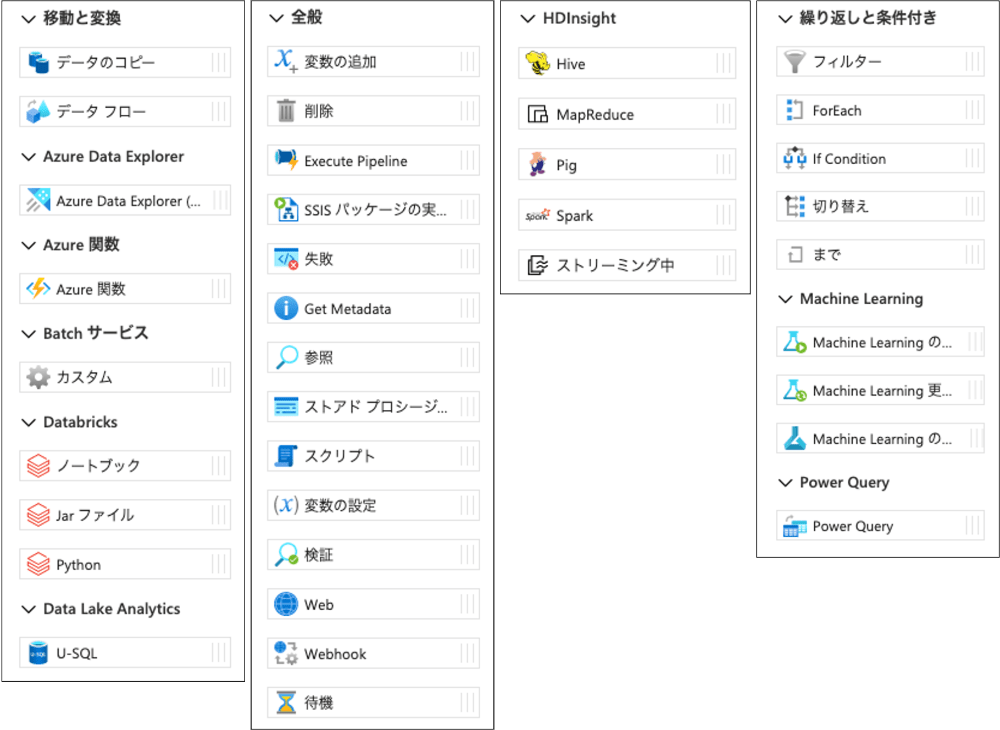
データセットで各種データサービスと連携し、データ フローとパイプラインではアクティビティという処理のパーツを繋げるブロックプログラミングでデータの入力、加工、出力します。データ フローとパイプラインにはそれぞれ下のようなアクティビティがあります。このステップではこれらを作成して動かしてみましょう。
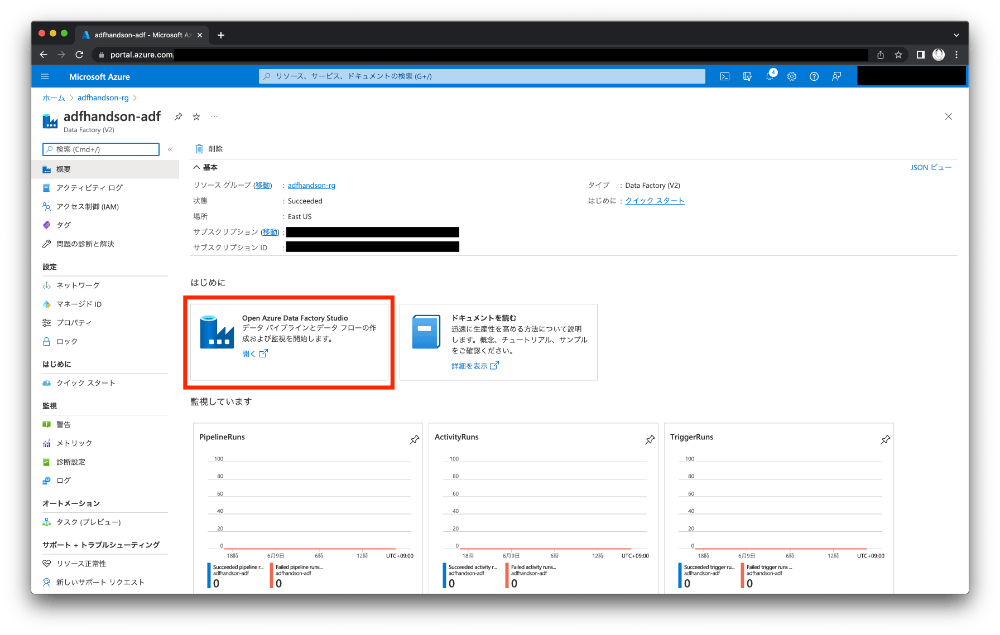
Azure Portalで作成したData Factoryを見ると、Data Factory StudioというData Factoryを操作することができるポータルがあります。ここから以降の作業を行います。
2.1. データセットを作成する
Data Factoryのデータセットとして、SQLデータベースとBLOBストレージを登録します。
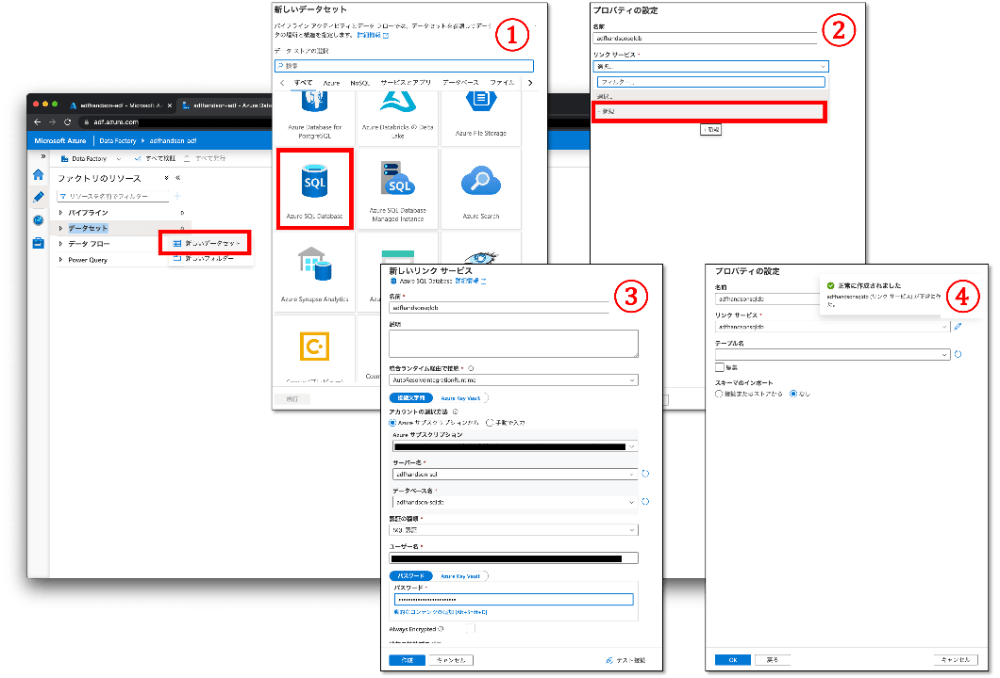
「データセット」の[新しいデータセット]からSQLデータベースを選択します。「プロパティの設定」から「リンクサービス」で[新規]を選択し、先ほど作成したデータベースの情報を入力して作成します。「テーブル名」は空欄にしたまま[OK]をクリックします。
同じ要領でBLOBストレージも登録します。
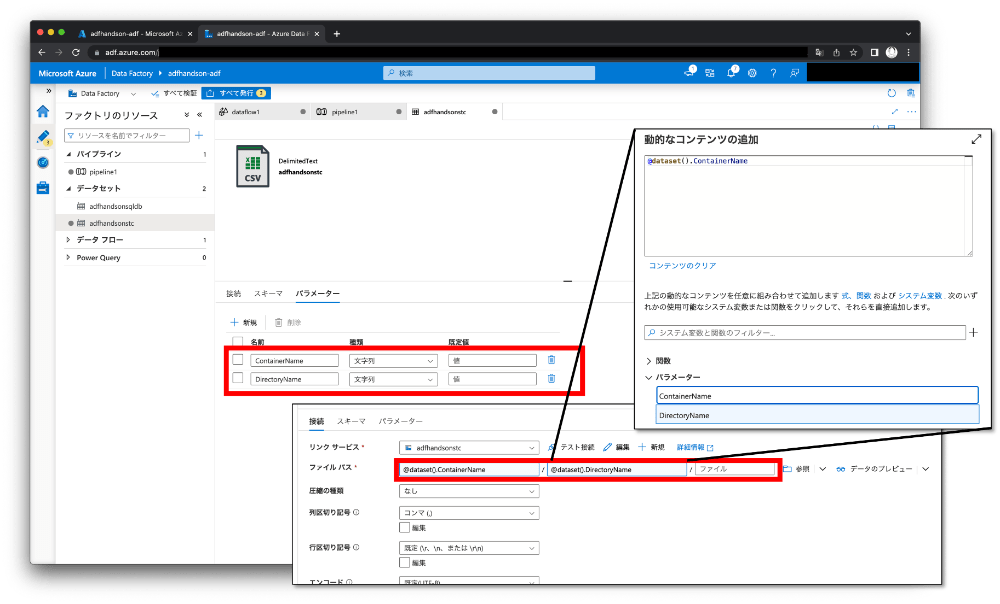
BLOBストレージの「Deliminated File」を選択します。また、この後のステップで使うパラメーターを作成します。「パラメーター」でContainerNameとDirectoryNameを作成し、「接続」の「ファイルパス」に「動的なコンテンツ」の追加から先ほどのパラメーターを設定します。
2.2. データ フローを作成する
データフローではパイプラインの中でアクティビティとして使用できるデータの操作を定義できます。
ここでは、SQLデータベースからデータ一覧を取得し、3教科の合計点が高い順に並び替えてcsvファイルに出力するデータ フローを作ってみましょう。
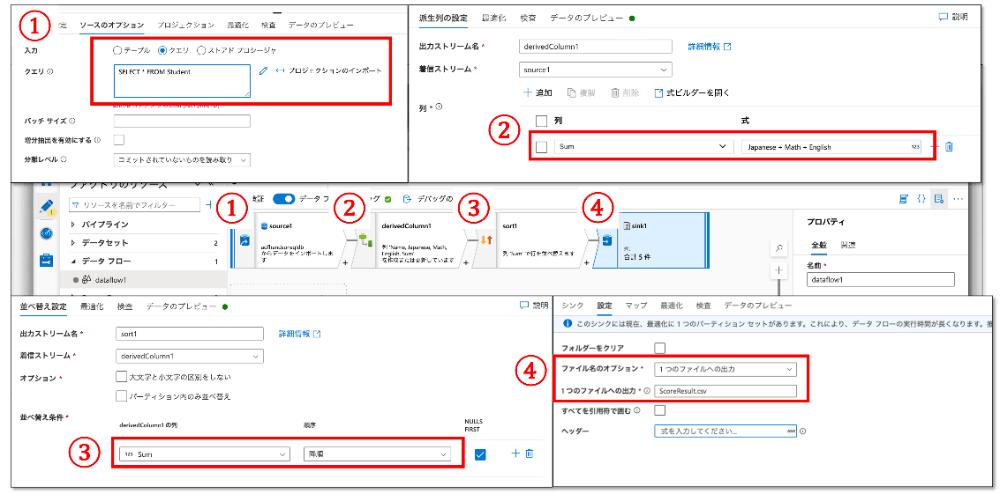
新しいデータ フローを作成し、データソースを追加します。「ソースのオプション」では「入力」で[クエリ]を選択し、下のStudentテーブルのデータを取得するクエリを入力します。その後、[プロジェクションのインポート]を行います。
SELECT * FROM Student次に「派生列」アクションを追加し、「派生列の設定」でJapanese + Math + Englishという式のSumを列を追加します。その次は「並び替え」アクションを追加し、「並び替え設定」でSumの降順に設定します。最後に「シンク」アクションを追加し、「設定」で「ファイル名のオプション」に[1つのファイルへの出力]、「1つのファイルへの出力」で ScoreResult.csv というファイル名を設定してみます。「シンク」ではBLOBストレージを設定します。
これでデータ フローの完成です。
2.3. パイプラインを作成する
最後にパイプラインです。新しいパイプラインを作成し、先ほどのデータフローを追加します。「設定」で「データ フロー」で先ほど作成したデータ フローを選択し、パラーメーターのContainerNameとDirectoryNameにファイルの出力先を入力します。ここまで出来たら[すべて発行]でここまでの作業を保存します。
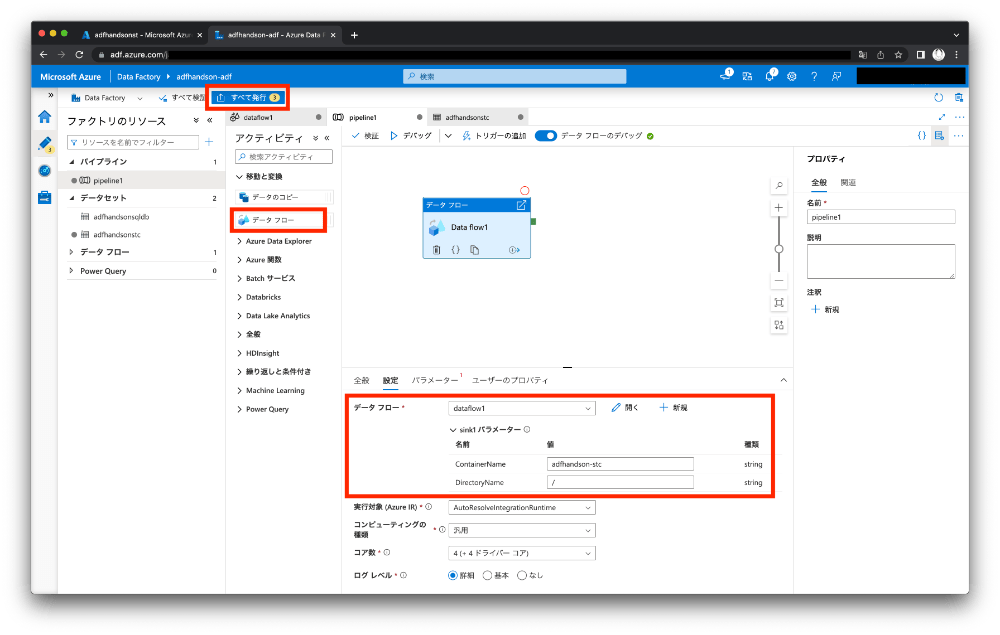
2.4. 動かしてみる
パイプラインの画面で[デバッグ]を実行し、実際にパイプラインを動作させてファイルが出力されているか確認してみましょう。処理が正常に完了したらストレージアカウントのコンテナーを確認し、作成されたファイルを確認してみましょう。中身にデータが入っていたら完成です。
3.お片付け
全て終わったら下のコマンドでリソースグループごと削除できます。
Remove-AzResourceGroup -ResourceGroupName "adfhandson-rg"まとめ
今回はData Factoryを触ってみようということで、簡単なパイプラインを作成する手順を紹介しました。アクティビティ一覧を見てわかるように、できる操作の種類は豊富なのでかなり複雑なデータ操作もブロックを並べることで実装できて非常に便利なリソースです。どんどん活用してみてください。
また、これは余談ですがAzureの製品はYouTubeチャンネルやTwitterアカウントがあるんですよね(全部かどうかは未確認)。更新頻度はまちまちですが、気になる製品の情報を収集するにはいいかもしれないですね。
参考











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
