


 2022-07-11
2022-07-11

目次

- インデックスの基本構文
- クラスター化インデックス
- 非クラスター化インデックス
- 付加列インデックス
- インデックス付きの主キー
- インデックスの有効化・無効化
- インデックスの削除
- 実行プランのSeek or Scan
- 実際にインデックスを作成して、実行プランを確認する
- クラスター化インデックスを使用した検索
- 非クラスター化インデックスを使用した検索
- クラスター化インデックス・非クラスター化インデックスの両方を使用した検索
- インデックスが適用されない検索条件
- インデックスの作成手順
- Step1. プライマリキーを作成する
- Step2. ユニークキーを作成する
- Step3. 非クラスター化インデックスの設計をする
- Step4. 付加列インデックスの設計をする
こんにちは、あおいです。
NASDAQの下げ幅と保有株の含み損の額に動じなくなりました。慣れって怖いですね。
さて、DBのパフォーマンスチューニングでインデックスの作成は非常に重要です。
前回の記事では、インデックスの仕組みについて紹介させていただきました。
SQL Serverのインデックスの仕組みを理解する | cloud.config Tech Blog
そこで、今回はSQL Serverでインデックスを作成して検索を高速化する方法について紹介したいと思います。
インデックスの基本構文
クラスター化インデックス
CREATE CLUSTERED INDEX [インデックス名]
ON [テーブル名] ([列名] ASC)
GO
-- ASCは省略可能
-- 複数カラムの指定可能
-- クラスター化インデックスは1つのテーブルに1つまでしか作成できない
CREATE CLUSTERED INDEX [インデックス名]
ON [テーブル名] ([列名1],[列名2])
GO非クラスター化インデックス
CREATE NONCLUSTERED INDEX [インデックス名]
ON [テーブル名] ([列名])
GO
-- NONCLUSTEREDを指定しない場合、デフォルトで非クラスター化インデックスになる
-- 複数カラムの指定可能
CREATE INDEX [インデックス名]
ON [テーブル名] ([列名1],[列名2])
GO付加列インデックス
CREATE NONCLUSTERED INDEX [インデックス名]
ON [テーブル名] ([列名])
INCLUDE ([列名1],[列名2])
GOインデックス付きの主キー
-- 既存テーブルに非クラスター化インデックス付き主キーを作成する
ALTER TABLE [テーブル名]
ADD CONSTRAINT [インデックス名] PRIMARY KEY NONCLUSTERED (
[列名1],
[列名2]
)
GO
-- テーブル作成時、主キーとクラスター化インデックスを作成する
CREATE TABLE [テーブル名] (
[列名1] [データ型] NOT NULL,
[列名2] [データ型],
[列名3] [データ型],
CONSTRAINT [インデックス名] PRIMARY KEY CLUSTERED (
[列名1]
)
)
GOインデックスの有効化・無効化
-- インデックスを有効化する
ALTER INDEX [インデックス名]
ON [テーブル名] REBUILD
-- インデックスを無効化する
ALTER INDEX [インデックス名]
ON [テーブル名] DISABLEインデックスの削除
DROP INDEX [インデックス名] ON [テーブル名]
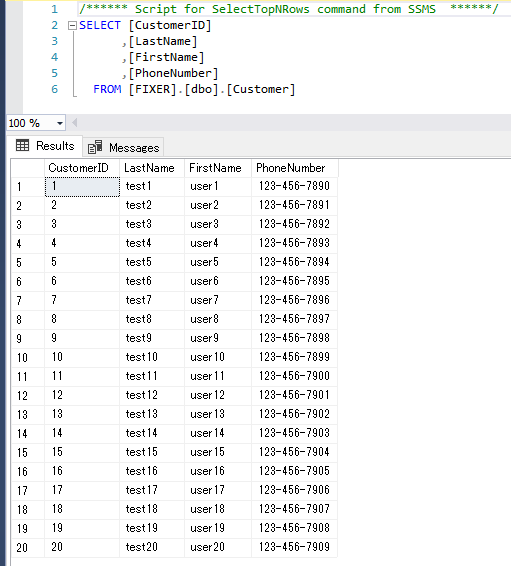
以下のCustomerテーブルに対して、インデックスを作成します。
実行プランのSeek or Scan
SSMSのクエリ実行画面にて、[実際の実行プランを含める]オプションをONにした状態でクエリを実行します。実行後、[実行プラン]タブが表示されるので、実行プランの経路図で「Seek or Scan」を確認します。
SeekとScanは以下の認識で大丈夫です。
Seek = ピンポイント検索
(例) 100万件のデータから条件に合致するデータを1件のみ読み込む
Scan = 全件検索
(例) 100万件のデータを全て読み込む

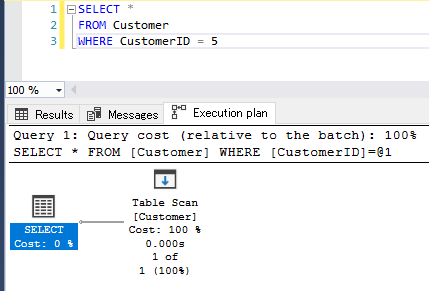
上記はインデックスを作成していない状態で検索処理をしています。
このような場合は「Table Scan」となり、テーブル全てのデータを読み込んでいるので、非常に検索処理が遅いです。インデックスを作成して「Seek」にすることが望ましいです。
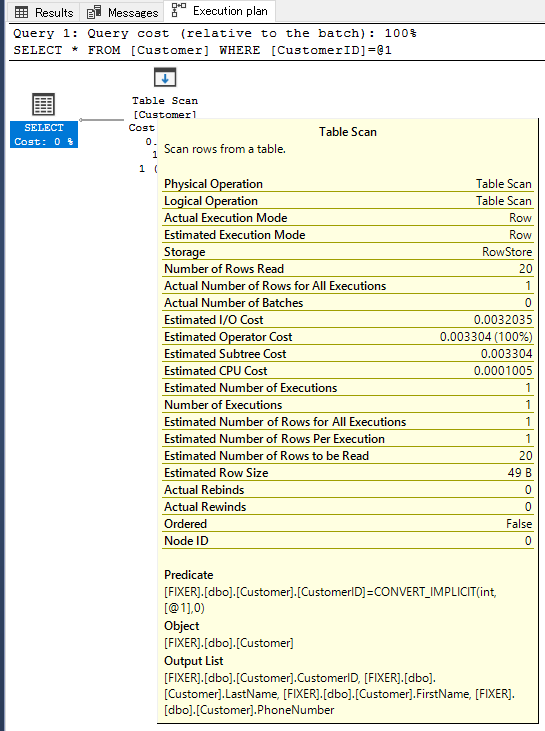
また、アイコンをマウスオーバーすると、 I/Oコスト・実行時間などの情報も表示されるので、パフォーマンスのチューニングに活用できます。
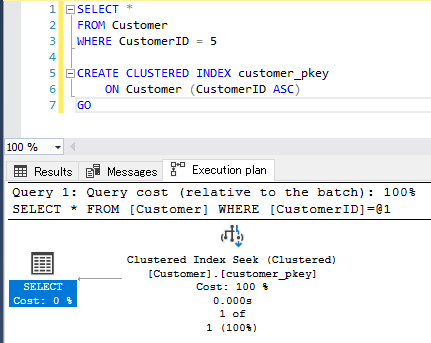
実際にインデックスを作成して、実行プランを確認する
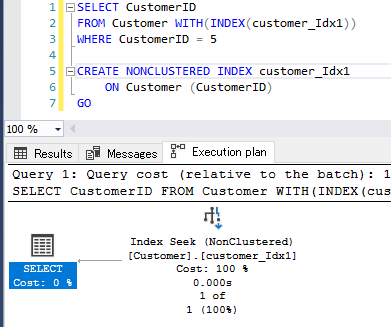
クラスター化インデックスを使用した検索
B-Treeの終端のリーフノードには実表データが格納されているので、キー参照やRID Lookupが発生しません。
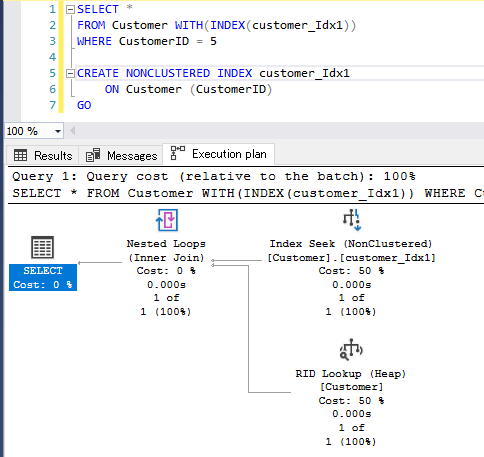
非クラスター化インデックスを使用した検索
B-Treeの終端のリーフノードにはインデックス項目とRIDのみが存在します。
左の場合、CustomerIDがインデックス項目に該当するので、CustomerIDだけの取得はRID Lookupが発生しません。
右の場合、*(アスタリスク)で全ての列項目を取得しようとしているので、RID Lookupが発生します。
クラスター化インデックス・非クラスター化インデックスの両方を使用した検索
B-Treeの終端のリーフノードにはインデックス項目とクラスター化インデックスのキー列が含まれています。
*(アスタリスク)で全ての列項目を取得しようとしているので、キー参照が発生します。
ただし、CustomerIDとPhoneNumberを取得項目にした場合はリーフノードの読み込みで完結するので、キー参照は発生しません。

インデックスが適用されない検索条件
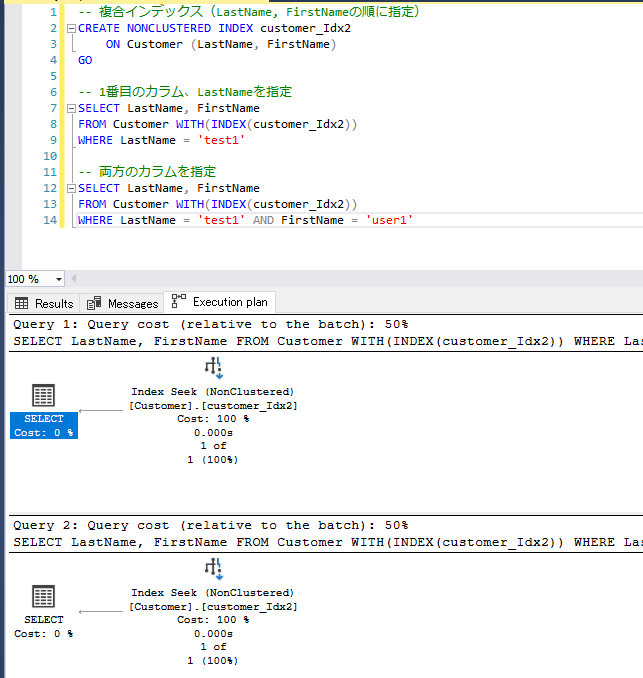
インデックスが効かない検索条件に、LIKE検索の後方一致・部分一致や関数使用パターン等が挙げられますが、本記事では複合インデックスの場合を紹介します。

1番目あるいは両方のカラムキーを検索条件に指定すると、Seekとなりピンポイントで検索できています。
2番目のカラムキーを検索条件に指定すると、Scanとなり全件を見てしまいます。
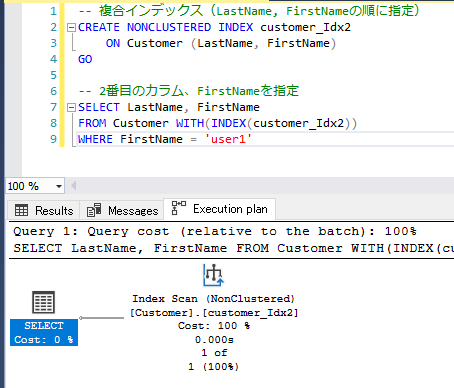
複合インデックス作成時、まず1番目のカラムキーのLastNameが順番に並び替えられます。FirstNameはLastNameを基準に並び替えがされるので、順序はバラバラになっています。つまり、FirstNameの「DD」で検索をしても、結局全て見ないと分からないのでScanになります。
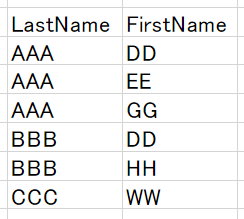
この構造を理解していないと、見当違いのインデックスを作成してしまうので注意が必要です。
最後にインデックスを作成する手順をまとめると以下の通りになります。
インデックスの作成手順
Step1. プライマリキーを作成する
テーブルを作成したら、まずはプライマリキーを作成する。自動的にクラスター化インデックスが作成されます。意味の無い連番をプライマリキーにするのは絶対にやめましょう。
Step2. ユニークキーを作成する
必要の場合、ユニークキーを作成します。自動的に非クラスター化インデックスが作成されます。
Step3. 非クラスター化インデックスの設計をする
SQLを作成したら、必ず実行プランから「Seek」になっていることを確認しましょう。
Step4. 付加列インデックスの設計をする
どうしてもパフォーマンス改善が見込まれない場合、付加列インデックスを使用します。内部構造的にデータの2重持ちになり、データ容量を圧迫するので、あまり安易に多用してはいけません。
今回はSQL Serverのインデックスを作成して検索を高速化する方法について紹介させていただきました。
次回の記事では、断片化率に応じてインデックスを再構築する方法について紹介します。
SQL Serverで断片化率に応じてインデックスの再構築・再構成をする | cloud.config Tech Blog
参考記事
CREATE INDEX(Transact-SQL)- SQL Server | Microsoft Docs
付加列インデックスの作成 | Microsoft Docs
SQL Serverのインデックスの理解を深める | Qiita
【SQL Server】クラスター化インデックスと非クラスター化インデックス | Hatena Blog
クラスター化インデックスは主キーにつけない方がいいかも | Hatena Blog








![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)


