





こんにちは、あおいです。
そろそろ、QQQやSPYDあたりのETFの買い増しでもしようかしら。
さて、SQL Serverにおけるのデータ構造のアーキテクチャって知ってますか?
以下の記事に分かりやすい概略図が記されています。
SQL Serverにおけるインデックスの再構成と再構築の性能比較 | ZOZO TECH BLOG
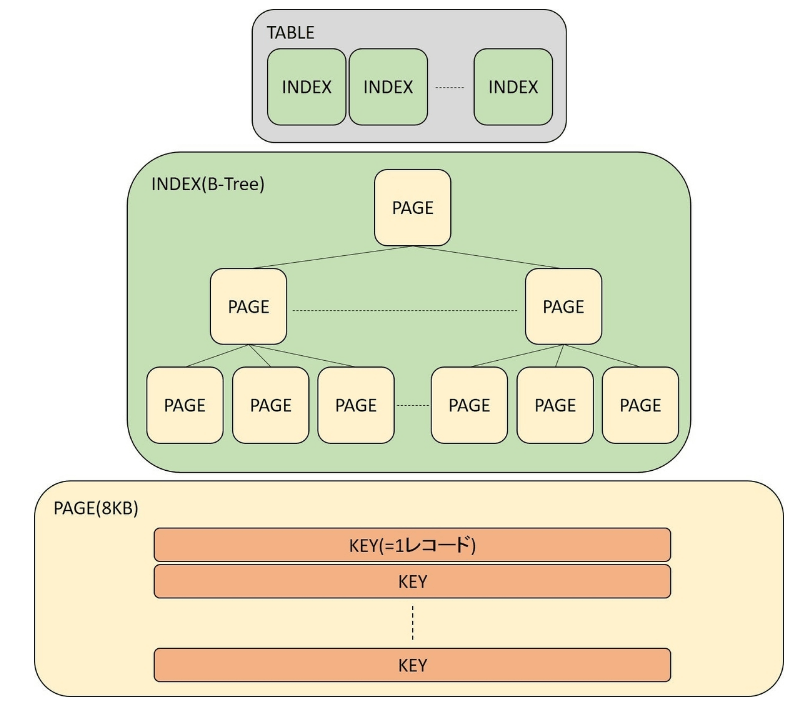
テーブルは、1つ以上のインデックスから構成されます。インデックスは、ページというデータの集合体でB-Tree構造を形成します。ページとは、8KBの物理的な連続領域で各ページに実際のレコードが格納されています。
と言っても、なんかイメージつきにくいですよね。分かる人にはもう分かると思いますが。
実際のデータの中身を覗けば、イメージがかなり湧くと思います。
そこで、今回はSQL ServerでインデックスのB-Tree構造を確認する方法を紹介したいと思います。
まず、任意のデータベース名とテーブル名を指定した上で、以下のクエリを実行してみてください。
-- インデックスの構造を確認するクエリ
DECLARE @DB_ID int, @Object_ID int
set @DB_ID = DB_ID('データベース名')
set @Object_ID = OBJECT_ID('テーブル名')
SELECT
name, index_id, index_type_desc, index_depth, index_level, page_count, record_count, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (@DB_ID, @Object_ID, NULL , NULL, 'DETAILED') as A
JOIN sys.objects as B with(nolock) on A.object_id = B.object_id
ORDER BY index_id, index_level DESC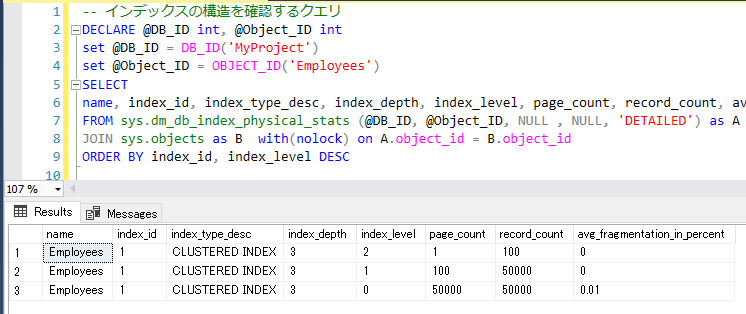
インデックスの各階層ごとにページ数やレコード数を取得しています。
今回の場合、クラスター化インデックスが3階層の構造でレコード数が全件5万となっています。
次に、以下のDBCC INDコマンドを実行して、ページの連続性の確認を確認してみます。
-- ツリー構造を確認する
-- インデックスで使用しているページIDリストを取得
DBCC IND(データベース名, テーブル名, 1)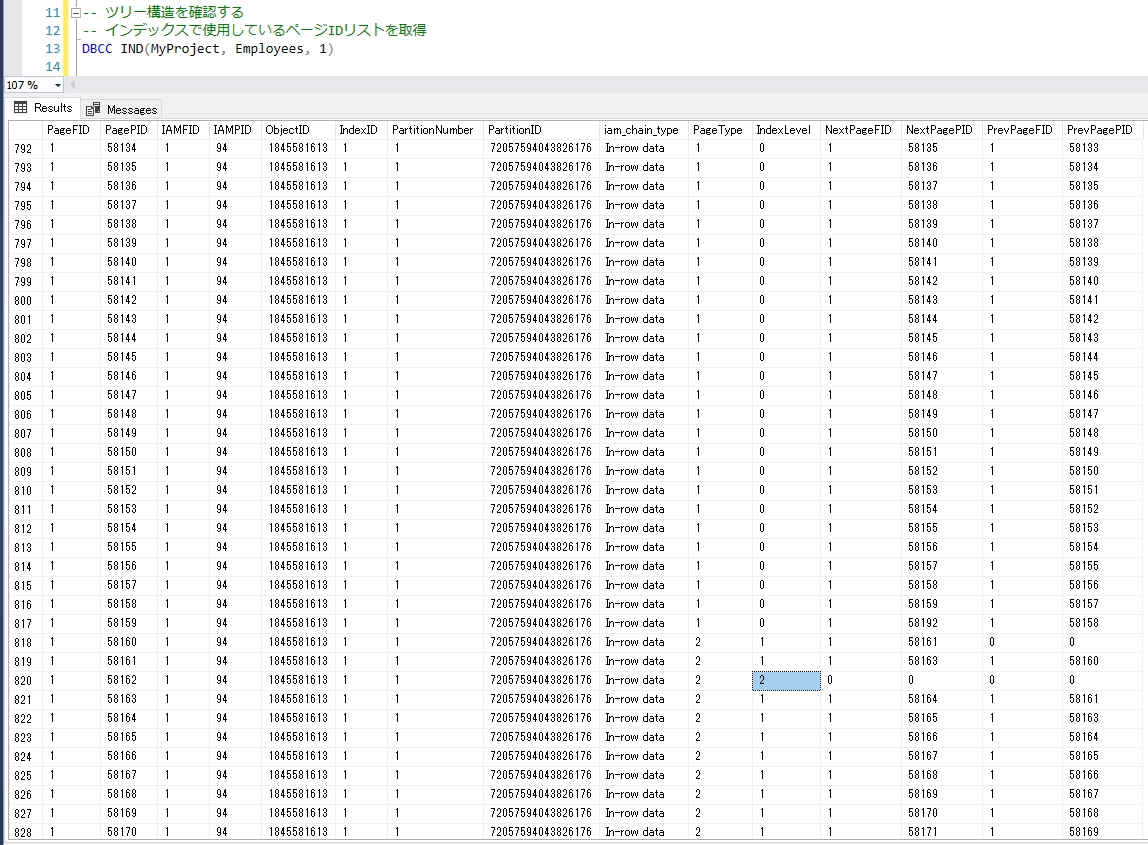
全てのページ情報を取得しています。
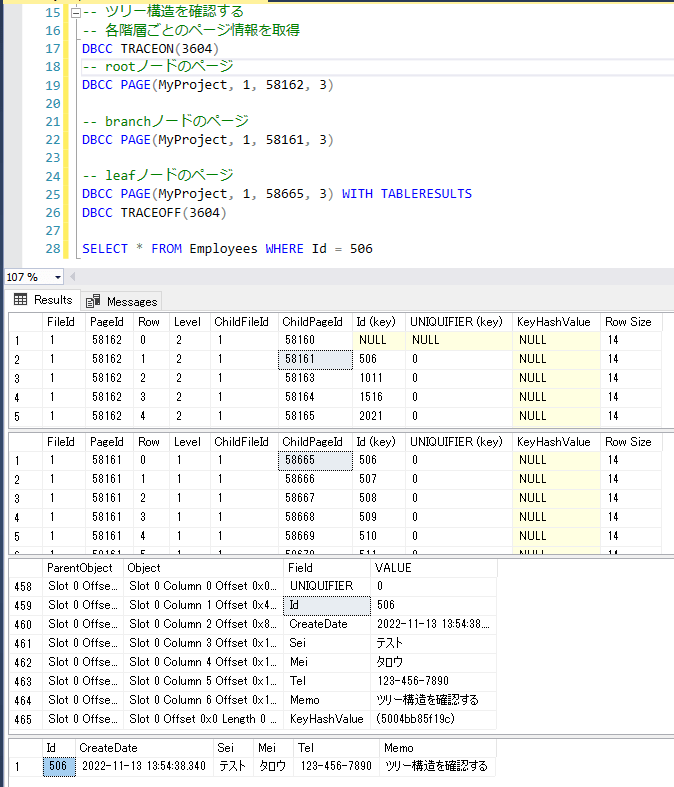
また、index_levelを確認すると、root(2)ノードのデータは1つのみで、大半はleaf(0)ノードのデータであることが分かります。
最後に、各階層ごとのページ情報に対してPageIDを指定して確認してみます。
DBCC PAGEでページ情報をダンプするには、トレースフラグ 3604 を有効にする必要があります。
-- ツリー構造を確認する
-- 各階層ごとのページ情報を取得
DBCC TRACEON(3604)
-- rootノードのページ
DBCC PAGE(データベース名, 1, [PageID], 3)
-- branchノードのページ
DBCC PAGE(データベース名, 1, [PageID], 3)
-- leafノードのページ
DBCC PAGE(データベース名, 1, [PageID], 3) WITH TABLERESULTS
DBCC TRACEOFF(3604)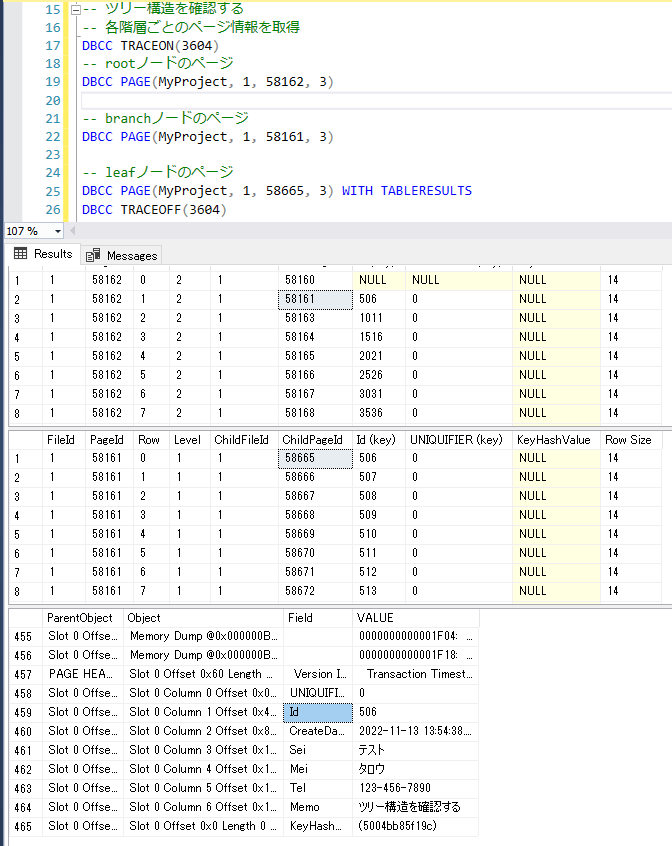
Levelがindex_levelの各階層を示しており、ChildPageIDをもとに各階層をたどると、最も階層が低いリーフノードに実データが格納されていることが分かります。
また、実際にページ情報のダンプ結果とSELECT結果を照らし合わせてみると、レコード情報が一致します。
今回はSQL ServerでインデックスのB-Tree構造を確認する方法を紹介させていただきました。
実際に、中身のデータを覗くことで、冒頭で紹介したインデックスのアーキテクチャの概略図やB-Tree構造の仕組みがイメージしやすくなったかと思います。本記事が少しでも読者の皆様のお役に立てれば幸いです。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
