






※こちらの記事は、「FIXER Rookies Advent Calendar 2022」 8日目の記事となります
はじめに
こんにちは!三瀬と申します。
アドカレは学生時代に身内のコミュニティでやっていたのですが、どれも好きな作品や概念をゆるく布教し散らかすものだったので、TechなBlogのアドカレは初めてです。
2年前にSummer Pocketsにハマりまくって聖地巡礼したレポ記事を書いていた時が一番輝いていたかもしれない。
本題ですが、私は「アイドルマスター シャイニーカラーズ」の応援に力を注いでおります。
楽曲のコンセプトや衣装のビジュアル、カードイラストの構図など魅力的な点を挙げればキリがないのですが、個人的に一番♰良い♰と思っているのは、数々のシナリオです。
今年に入って国語辞典レベルに分厚いシナリオブックが発売されるほど力が入っており、時には笑わせつつ時には想像を120度くらい上回ってくる激重展開を見せてくるなど、アイドルに対して多角的な視点で攻めてくるシナリオが毎度のように刺さっています。
そんな私の最近の悩みなのですが、シナリオを自分で解釈する力が衰えてきました。
雰囲気では色々と見出せるものの、感想が中々言語化できずに他人の考察ブログに解釈を委ねてしまうことも多々あります。
もっと深い考察力を身につけるために、そのシナリオの特徴を手軽に可視化できないか.....
と考えたので、今回は自然言語処理ライブラリの「GiNZA」を使って文章を様々な方法で解析してみました。
また、形態素解析したデータを用いてワードクラウドも作ってみようと思います。
GiNZAとは
詳しくは公式ドキュメントをご参照ください。
簡単に説明すると、日本語に特化した自然言語処理のオープンソースライブラリです。「spaCy」という、文章のトークナイズやベクトル化を行うための高度な自然言語処理ライブラリを用いて学習されています。雑にまとめると、日本語に対して割と何でもできます。
百聞はなんとやらなので、早速使っていきましょう。
解析に用いる文章はシャイニーカラーズの推しシナリオを....収集することは難しいので今回は宮沢賢治さんの「やまなし」を使っていきます。クラムボンがかぷかぷわらうやつ。
「やまなし」の本文は青空文庫さんから取得しました。
では実際に使ってみましょう
使用言語はPythonで、ノートブック上での実行を想定しています。
まずは必要なモジュールおよび日本語フォント(後々ワードクラウドに使うため)をインストールしていきます。
Python!pip install ja-ginza
!pip install wordcloud
!apt-get -y install fonts-ipafont-gothic
モジュールをインストールできたら、さっそく「やまなし」本文を取得し、GiNZAモデルをspaCyに読み込ませて解析して、トークンごとに表示させてみましょう。
Pythonimport spacy
# 「やまなし」の取得
with open('/content/drive/My Drive/yamanashi.txt', encoding="shift-jis") as f:
yamanashi = f.read()
# GiNZAモデルのロード
nlpja = spacy.load('ja_ginza')
# 「やまなし」の解析
doc = nlpja(yamanashi)
for token in doc
print(token.i ,token.text , token.pos_ , token.tag_)実行結果は以下のようになっています。1657トークンあったので最初の一文分だけ抜粋しました。
0 小さな ADJ 連体詞
1 谷川 PROPN 名詞-固有名詞-人名-姓
2 の ADP 助詞-格助詞
3 底 NOUN 名詞-普通名詞-一般
4 を ADP 助詞-格助詞
5 写し VERB 動詞-一般
6 た AUX 助動詞
7 二 NUM 名詞-数詞
8 枚 NOUN 接尾辞-名詞的-助数詞
9 の ADP 助詞-格助詞
10 青い ADJ 形容詞-一般
11 幻燈 ADJ 名詞-普通名詞-一般
12 です AUX 助動詞
13 。 PUNCT 補助記号-句点分解されたトークンのテキストおよび、品詞の種類が表示されていますね。
次に、spaCyの可視化用の拡張機能である「displaCy」を使って、文中の重要な要素となりうるエンティティを強調表示してみます。
Pythonfrom spacy import displacy
# エンティティを強調させる
displacy.render(doc, style="ent",jupyter=True)
こんな感じ。抽出された各エンティティの種類が「Animal」「Dish」等表示されています。
「やまなし」における蟹達は主要人物なのですが食事(Dish)扱いされているのと、最初の谷川がPersonで出てきているのがちょっと面白い。
次に、せっかく形態素解析したデータがあるので名詞のみを抜き出してワードクラウドにしてみましょう。
Pythonには入力した単語リストをワードクラウドに起こす「WordCloud」というライブラリがあるのでそちらを使っていきます。
Pythonfrom wordcloud import WordCloud
import matplotlib.pyplot as plt
# 名詞・固有名詞のみ抽出
nounWords = []
for token in doc:
if token.pos_ in ['NOUN', 'PROPN']:
nounWords.append(token.text)
# ワードクラウドに出力
wc = WordCloud(width=800, height=600, background_color='white', font_path='/usr/share/fonts/opentype/ipafont-gothic/ipag.ttf').generate(' '.join(nounWords))
plt.figure(figsize=(18,15))
plt.imshow(wc)
plt.axis('off') # 目盛りを非表示にする
plt.show()実行結果は以下のようになります。

>>>蟹<<< 。クラムボンが一番大きいと思っていたのですが、思ったより小さいのと2つに分裂してる。。。?
とまあこんな感じに、ワードクラウドに起こせば頻出単語を可視化できるので、「やまなし」を知らない人が見ても「蟹や魚が出てくるし海の物語なんだろうな」といったことが一瞬で理解できるようになります。
あとどのようなロジックでこの図を作っているかは分かっていないのですが個人的には「魚」の字の中に色々入りこんでるのがツボ。
あとは、GiNZAで解析したデータはトークンごとにベクトルが格納されており、また文全体のベクトルを見ることができるので、各名詞句のベクトルと文ベクトルのコサイン類似度を比較することで、どの部分が「やまなし」にとって最も重要なのかを計算してみましょう。
コサイン類似度は自分で計算...するまでもなく、計算してくれるメソッドがあるのでそちらを使っていきます。無敵か?
PythonimportantWords = []
for chunk in doc.noun_chunks: # noun_chunks:doc内の名詞句のみを抽出したもの
importantWords.append((chunk.text, chunk.similarity(doc))) # similarity:コサイン類似度
results_sorted = sorted(importantWords,key=lambda x: x[1],reverse=True)[:10]
for r in results_sorted:
print(r)名詞句を抜き出し、そのベクトルと文ベクトルのコサイン類似度トップ10を表示しています。実行結果は以下のようになりました。
('『どうだ、やっぱりやまなしだよ、よく熟している、いい匂い', 0.9320004679796187)
('やまなしだ、流れて行くぞ、ついて行って見よう、ああいい匂い', 0.9267387871148288)
('『おいしそうだね、お父さん', 0.9251385850881367)
('しんとして、ただ、いかにも遠く', 0.8837090568466569)
('『こわいよ、お父さん', 0.8773322329375216)
('『こわいよ、お父さん', 0.8773322329375216)
('はっきりとその青いもの', 0.8426294263237305)
('『吐いてごらん', 0.83770652203728)
('いいかい、そら', 0.8133060431426966)
('来る、それからひとりでにおいしいお酒', 0.8061618611524769)'『こわいよ、お父さん' が2つあるな...と思ったけど純粋に文中に2回出てきているだけでした。
類似度の上位3つほどを見る限り、ベクトル的に「やまなし」の中で重要なのは最後のやまなしが流れてくるシーンなのでしょうか。4位以下と比べてもかなり高くなっています。
とまあ、文中の重要な要素の判定に対して絶対的な材料になるわけでは無いのですが、参考程度にはセリフや表現の雰囲気が掴めてくると思います。
まとめ
今回紹介したようなものだと既に文章をペッと貼り付けるだけで表示してくれるツールがWeb上にごろごろ転がっている気がするのですが(少なくともワードクラウドは調べたらあった)、GiNZA等をうまく活用できれば自分が可視化したいものを無限通りに生み出せると思います。
いい感じに自分のニーズに合った分析をして、解釈材料として役立てられたら嬉しくなれそうですね。
ちなみに今回「やまなし」を選んだ理由ですが、自分が知っている文学作品の中で最も雰囲気がシャイニーカラーズのシナリオに近いと思っているからです。
おまけ
突然ですが、推しに近い文章を書きたいと思ったことはありますでしょうか。
オタクとしての生活を歩んでいるうちに、気がついたら普段の会話でキャラクターの発言や構文を真似て喋ってしまうことが多々あります。
しかし本当に自分は推しに近い発言ができているのでしょうか...
と考えたので、おまけとしてGiNZAを使って自分がインプットした発言が推しキャラの発言とどれだけ類似しているのかを計測してみました。
多分深層学習にかけた方が確実にいい精度が出せると思うのですが、まあ思いつきなのでやってみましょう。
比較に使う発言は担当アイドルのセリフを...収集することは難しいので、「走れメロス」の主人公 メロスの発言を使用していきます。
Pythonmeros = ['何かあったのか、二年まえに此の市に来たときは、夜でも皆が歌をうたって、まちは賑やかであった筈だが',
'なぜ殺すのだ。',
'たくさんの人を殺したのか。',
'おどろいた。国王は乱心か。',
'呆あきれた王だ。生かして置けぬ。',
'市を暴君の手から救うのだ。',
'人の心を疑うのは、最も恥ずべき悪徳だ。王は、民の忠誠をさえ疑って居られる。',
'なんの為の平和だ。自分の地位を守る為か。',
(中略)
'私だ、刑吏!殺されるのは、私だ。メロスだ。彼を人質にした私は、ここにいる!',
'私を殴れ。ちから一ぱいに頬を殴れ。私は、途中で一度、悪い夢を見た。君がもし私を殴ってくれなかったら、私は君と抱擁する資格さえ無いのだ。殴れ。',
'ありがとう、友よ。'
]
# セリフの入力・解析
dialogue = input()
myDoc = nlpja(dialogue)
# メロスのセリフとの文ベクトルのコサイン類似度を測定
merosSimilarity = []
for merosDia in meros :
merosDoc = nlpja(merosDia)
merosSimilarity.append(merosDoc.similarity(myDoc))
# 平均
print(sum(merosSimilarity) / len(merosSimilarity))何通りかの発言と類似度を比較していきましょう。

低くもなく近いという訳でもなく。1文1文と平均を取っているので当然なのですが安易にセリヌンティウスと入れても高くなる訳ではないですね。

いい線いってそう。メロスの主人公気質が週刊的な少年の心とマッチしているように思えます。
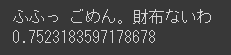
終。
参考文献











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
