






こんにちは、原です。
FIXER Rookies Advent Calendar 2023開催!ということで今回は、高専5年次から趣味で学習していたRISC-Vを実装した、簡単なCPU作成を行っていこうと思います。
完全に知識ゼロの状態から学び始めたので、間違った解釈をしている部分があるかもしれませんが、その時は優しく指摘していただけると嬉しいです 🙏
また、本ブログはディジタル回路設計とコンピュータアーキテクチャ[RISC-V版]を基に書かれています。初心者でも理解しやすいように丁寧に解説されているので、興味があれば是非買ってみてください!
RISC-Vってなんぞ
RISC-V公式サイトには以下のように書かれています。
RISC-V is an open standard Instruction Set Architecture (ISA) enabling a new era of processor innovation through open collaboration.
(RISC-Vはオープン・スタンダードな命令セットアーキテクチャ(ISA)で、オープンなコラボレーションを通じてプロセッサの新時代の革新を可能にします。)
引用:About RISC-V
上記の通り、命令セットアーキテクチャ(以下ISA)の一種です。あいえすえー...って何?となるかもしれませんが、これはインターフェースとして定義されている、プロセッサが理解可能な命令の集合体です。x86やMIPS、Armなどが有名ですね。
RISC-V最大の特徴としては、オープンソースで開発・提供されている点が挙げられます。これにより、ライセンス料を支払うことなく誰でも利用可能であるうえ、簡単にRISC-Vを活用した派生品を作ることができます。
CPU作成の準備
CPUを作るといっても、トランジスタを一から組み立てて...とやるわけではありません。それができる人間がいたらぜひ会ってみたいですね。
今回は、SystemVerilogというハードウェア記述言語(HDL)を用いて、WSL上でCPUを作成していきます。
SystemVerilogを用いることで、プログラミング言語を扱うかのように、コードによってハードウェアを作成することができます!凄いですね。
コンパイルとシミュレーションには、今回はIcarus Verilogというシミュレータを使うため、事前にインストールしていきます。
aptを使おうと思ったのですが、バージョンが古いことによるコンパイル時の制約が出てしまうみたいです。
そのため今回は、公式ドキュメントのInstallation Guideを参考に手動でインストールしていきます。
git clone https://github.com/steveicarus/iverilog.git
cd iverilog
sh autoconf.sh
./configure
make
sudo make installまた、GTKWaveという波形ビューワもインストールしておきます。
これは、Icarus Verilogが出力した波形データを可視化するために必要なものです。
こちらはaptでインストールしていきます。
sudo apt install gtkwaveテストプログラムの実行
これで最低限の準備は整いました。試しに適当なコードを書いて実行してみます。
今回はANDとORを計算するテストプログラムAND_OR_TEST.svを作成していきます。
module AND(
input wire a,
input wire b,
output wire and_out,
output wire or_out
);
assign and_out = a & b;
assign or_out = a | b;
endmodule
module AND_OR_TEST();
reg a, b;
wire and_out;
wire or_out;
AND dut(
.a(a),
.b(b),
.and_out(and_out),
.or_out(or_out)
);
initial begin
$dumpfile("sv_test.vcd");
$dumpvars(0, dut);
a = 0; b = 0;
#10
a = 0; b = 1;
#10
a = 1; b = 0;
#10
a = 1; b = 1;
#10
$finish;
end
endmodule
次に、このプログラムを以下のようにして実行していきます。
iverilog -g 2012 -o sv_test ./AND_OR_TEST.sv
./sv_test実行結果

sv_testが実行され、成果物が生成されました。これで実行は成功です。
次に、GTKWaveを使って波形を見ていきましょう。波形を見るには、VCD(Value Change Dump)形式のファイルを利用します。
今回のAND_OR_TEST.svでは、$dumpfileを用いてsv_test.vcdを生成するようにしているため、これを利用します。
gtkwave ./sv_test.vcdこれで、GTKWaveでsv_test.vcdファイルを開くことができます。
そのままでは何も表示されていないため、画面に表示する信号を選択してあげることで、その波形を観察することができます。
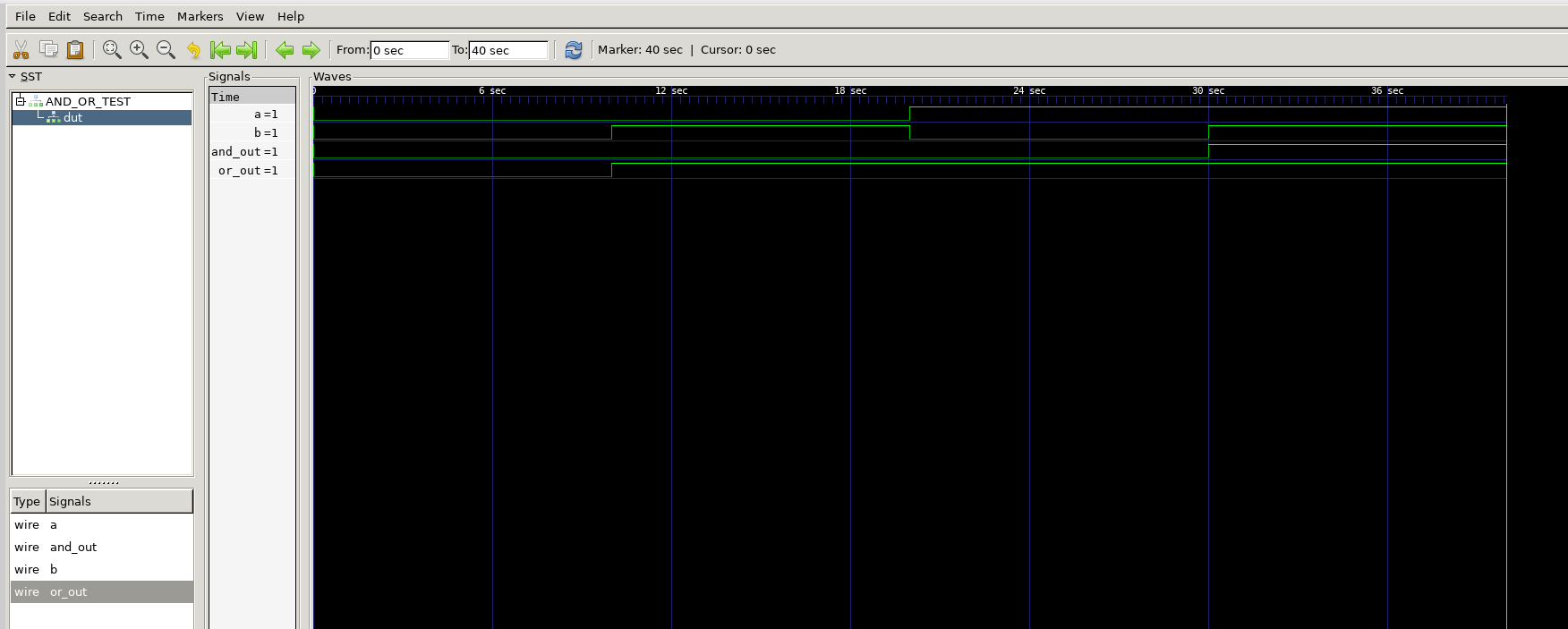
しっかりとANDとORが取れていることが分かりますね。これで波形を観察できるようになりました!👏
CPUを作ろう
それではRISC-Vアーキテクチャを実装したCPUを作っていきたいと思います。
今回は、命令パイプラインを実装した簡単な演算を行うパイプラインプロセッサを作成しました。
命令のフェッチ(呼び出し)からレジスタへのライトバック(書き込み)といった一連の処理を
- IF (Instruction Fetch)
- 命令キャッシュからの命令読み出し
- ID (Instruction Decode / register read)
- 制御信号の生成
- レジスタの参照
- EX (EXecution)
- 実行
- MEM (MEMory access)
- store(メモリへの書き込み)
- load(メモリの読み出し)
- WB (Write Back)
- レジスタへの書き込み
という5ステージに分割し、それぞれの間をパイプラインレジスタで接続することで、スループット(単位時間当たりの処理能力)を向上させることができます。
今回は作成したCPUで実行する対象として、R形式と呼ばれる種類の命令を実行するようなアセンブリを用意しました。
.section .text
.global _start
_start:
# define the immediate
# t0 = 2
addi t0, x0, 2
# t1 = 4
addi t1, x0, 4
# t2 = -1
addi t2, x0, -1
# add
# s2 = 2 + 2 = 4
add s2, t0, t0
# sub
# s3 = 2 - 4 = -2
sub s3, t0, t1
# or
# s4 = 0x100 | 0x010 = 0x110 = 6
or s4, t1, t0
# and
# s5 = 0x100 & 0x110 = 0x100 = 4
and s5, s2, s4
# slt
# s6 = 2 < 4 = 1
slt s6, t0, t1
# s6 = 2 < 2 = 0
slt s6, t0, t0
# s6 = -2 < -1 = 1
slt s6, s3, t2
# xor
# s7 = 0x110 ^ 0x100 = 0x010 = 2
xor s7, s4, s5
# shift instruction
# s8 = -12 (FFFF FFF4)
addi s8, x0, -12
# srl : s9 = s8 >> 2 (3FFF FFFD)
srl s9, s8, t0
# sll : s10 = s8 << 1 (FFFF FFE8)
sll s10, s8, s6
# sra : s11 = s8 >>> 2 (FFFF FFFD)
sra s11, s8, t0
.end:
beq x0, x0, .end補足:addiとbeqに関しては、それぞれI形式、B形式と呼ばれ、本来他の命令とは種類が異なるのですが、前者は即値を扱うため、後者は命令の終了のため例外的に使用しています。
| 命令の名前 | 定義 | 実行する内容 | 備考 |
|---|---|---|---|
| Add | add rd, rs1, rs2 | rd = rs1 + rs2 | |
| Add immediate | addi rd, rs1, imm | rd = rs1 + imm | immは即値、リテラルのようなもの |
| Subtract | sub rd, rs1, rs2 | rd = rs1 - rs2 | |
| OR | or rd, rs1, rs2 | rd = rs1 | rs2 | |
| AND | and rd, rs1, rs2 | rd = rs1 & rs2 | |
| XOR | xor rd, rs1, rs2 | rd = rs1 ^ rs2 | |
| Set less than | slt rd, rs1, rs2 | rd = (rs1 < rs2) | |
| Shift left logical | sll rd, rs1, rs2 | rd = rs1 << rs24:0 | 4:0は5bit幅を示す |
| Shift right logical | srl rd, rs1, rs2 | rd = rs1 >> rs24:0 | 最上位ビットを0で埋める(論理シフト) |
| Shift right arithmetic | sra rd, rs1, rs2 | rd = rs1 >>> rs24:0 | 最上位ビットをシフトする前のビットで埋める(算術シフト) |
| Branch equal | beq rs1, rs2, offset | if (rs1 == rs2) pc += offset | pcは次に実行する命令アドレス(プログラムカウンタ) |
RISC-Vアーキテクチャでは、32個のレジスタの集合体を保持したレジスタセットと呼ばれるものがあり、アセンブリ内にあるsやtはその名前、xは番号を示します。
この中でも特に、x0は常に定数0を保持する特別なレジスタとなります。
つまり上記のアセンブリは、t0~2とs2~11にそれぞれ演算結果を代入しているものとなります。
今回はこのアセンブリを読み込ませてCPUを実行してみます。
ちなみに今回作成したコード全体の記載に関しては、ここに記すには余白が狭すぎるため断念しました。
???「本当に申し訳ない。」
その代わり、重要な部分のみピックアップして紹介していきます。
ALU
always_comb begin
case (alu_control)
4'b0000 : alu_result = srca + srcb;
4'b0001 : alu_result = srca - srcb;
4'b0010 : alu_result = srca & srcb;
4'b0011 : alu_result = srca | srcb;
4'b0100 : alu_result = srca ^ srcb;
4'b0101 : alu_result = {{31{1'b0}} , {$signed(srca) < $signed(srcb)}};
4'b0111 : alu_result = $signed(srca) << srcb[4:0];
4'b1000 : alu_result = $signed(srca) >> srcb[4:0];
4'b1001 : alu_result = $signed(srca) >>> srcb[4:0];
4'b1010 : alu_result = {{31{1'b0}} , {srca==srcb}};
default: begin
alu_result = 32'hDEADBEEF;
$display("Unknown ALU command.");
end
endcase
zero = alu_result == 0;
endこれは、ALU(Arithmetic Logic Unit、算術論理演算装置)と呼ばれるものの一部です。
外部からの信号alu_controlに応じて、2種類の入力srca、srcbを用いて様々な演算を行う装置です。
今回はalu_controlを4bit幅で定義したため、24 = 16種類の演算に対応しています。
パイプラインレジスタ
// write to ID/EX registers
always_ff @(posedge clk) begin
if (rst | flush_e) begin
rd_e <= 0;
pc_e <= 0;
imm_ext_e <= 0;
(以下略)
end else begin
rd_e <= rd_d;
pc_e <= pc_d;
imm_ext_e <= imm_ext_d;
(以下略)
end
endこれは、パイプラインレジスタの実装部分です。例として今回は、IDステージ/EXステージ間のパイプラインを示しています。
always_ffとはflip-flop、つまりクロック同期で動作することを表しています。また、posedge clkと指定することで、クロックの立ち上がりエッジで動作することを指定しています。if-else文内にあるXXX_dとXXX_eという変数は、それぞれIDステージとEXステージにあることを示します。つまりこの回路は、IDステージからEXステージに受け渡す値を決定しているものとなります。
if文の条件にあるrstとはリセット信号を表し、flush_eはフラッシュと呼ばれる処理を行うために必要となります。フラッシュについて詳しくは解説しませんが、「都合の悪い状態に陥らないようにするためのもの」くらいの認識で大丈夫です。このどちらかがHighの時は、値を受け渡さずにすべて初期化するように指定しています。
レジスタファイル
always_ff @(negedge clk) begin
if (rst) begin
for (int i = 0; i < 32; i++) begin
regfile[i] <= 32'h0;
end
end else begin
if (we3 && addr3 != 0) begin
regfile[addr3] <= wd3;
end
end
endこれは、レジスタファイルと呼ばれるレジスタの集合で、その中でも書き込みを行っている部分になります。
パイプライン同様、rstがHighならすべての要素を初期化し、そうでない場合に条件を満たすなら書き込みを行っています。
これ自体に特殊な実装は行っていないのですが、注目してほしいのはこの処理が実行されるタイミングです。
今回のプロセッサは、基本的に立ち上がりエッジで実行していますが、ここだけnegedge、つまり立ち下がりエッジで実行しています。
その理由は、レジスタファイルが読み出しと書き込みを同時に実行可能だからです。
例を考えてみましょう。例えば、以下のような命令があったとします。
addi x1, x0, 0x123
nop // 何もしないことを意味する
nop
add x2, x0, x1この命令は、x1に0x123を書き込み、その3サイクル後にx0とx1の加算結果をx2に書き込む処理となります。
上記の命令を実行したときにレジスタファイルが使用されるタイミングを考えると、以下のようになります。
| clk経過数(サイクル) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| addi命令のステージ | IF | ID | EX | MEM | WB | |||
| add命令のステージ | IF | ID | EX | MEM | WB |
太字の部分がレジスタファイルが使用されるタイミングです。5サイクル目に、addiとaddで同時にレジスタファイルを使用していることが分かります。レジスタファイルは読み出しと書き込むを同時に実行可能なため、これらは同じサイクルで処理されます。
ここで、このサイクルで各命令が参照するレジスタ番号に注目してみましょう。addiはx1に書き込みを行っているのに対し、add命令はx0とx1から値を読み出しています。
これは非常に良くない状態です。なぜなら、x1に0x123が書き込まれていないタイミングでx1を参照してしまう可能性があるからです。これをRAW(Read After Write)ハザードと呼びます。ちなみに自分も一回これの沼にハマりました。
そこで、立ち上がりエッジで読み出しが始まる前の立ち下がりエッジ時に書き込みを行うことで、読み出し時には書き込み後のデータを扱うことができるため、RAWハザードを回避することができます。
レッツ実行
それでは実際に実行を行っていきます。今回の実行にはriscv-gnu-toolchainというクロスコンパイラを用いており、コンパイルに加えていくつか他のコマンドを入力する必要があったため、Makefileを作成して実行する形式にしました。Makefileの詳細は長くなりすぎてしまうため、今回は割愛します。
Makefileを作成したら、以下のコマンドで実行します。
make test TARGET=<(.Sを除く)アセンブリのファイル名>実行が完了したら、GTKWaveで波形を観察していきます。
gtkwave ./<出力ファイル>.vcd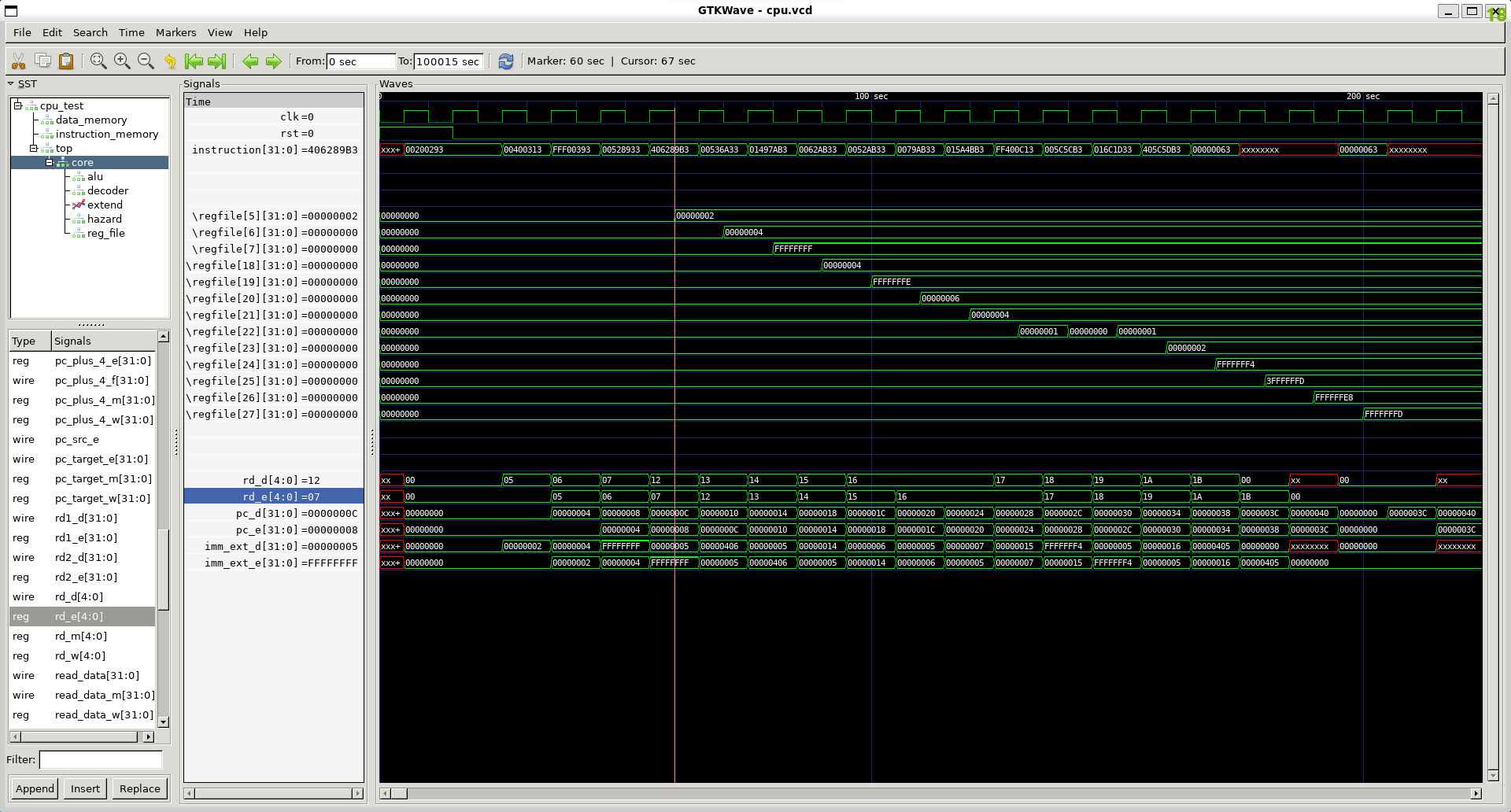
instructionがフェッチされた命令を表し、\regfile[XX][31:0]となっているものがレジスタです。数字はレジスタセットの番号に対応しています。
今回使用しているレジスタの対応表は以下の通りです。
| レジスタの名前 | レジスタ番号 | 備考 |
|---|---|---|
| t0 ~ t2 | \regfile[5] ~ \regfile[7] | 即値の保存用 |
| s2 ~ s11 | \regfile[18] ~ \regfile[27] | s8のみ即値 |
これを先ほどのアセンブリと見比べると、確かに期待した値が格納されていることが分かります。
また、ID/EX間の信号についても表示してみました。これを見ると、確かに1サイクル後に次のステージへ(XXX_dからXXX_eへ)値が渡されていることが分かります。
レジスタへのWBに関しても、他が立ち上がりエッジで実行されているのに対して、書き込みは半clk早い立ち下がりエッジで実行していることが読み取れます(わかりやすいように、適当な立ち下がり時に線を引いてあります)。
ということで、R形式の演算を行うパイプラインプロセッサが完成しました!
ちなみに、どこでどの命令がフェッチされているかは、RISC-V Instruction Encoder/Decoderというサイトを使ってデコードすることで確認できます。
試しに最初にフェッチされている命令「0x00200293」をデコードしてみると、

このように表示され、これはアセンブリ内の「addi t0, x0, 2」と一致することが分かります。
まとめ
今回は、RISC-Vアーキテクチャ実装した、簡単な演算を行うパイプラインプロセッサを作成していきました。
最初は分からないことだらけでしたが、一歩ずつ着実に設計していって、最終的に自分の目で動作していることが確認できるとやっぱり楽しいですね!
余談ですが、今回CPUを自作しようとなったきっかけの一つにOpenMPWシャトルプロジェクトが開催される、というものがあります。
これは、Efabless社がGoogleをスポンサーとして開催しているもので、オープンソース且つ一定の基準を満たしたCPUの設計図を作成・提出すれば、抽選で当たった人に「完全無料で」オリジナルのCPUが手に入るというものになります。激アツですね!
今回自分は高専時代の友人二名と協力して、本ブログで作成したR形式以外の命令の実装、UART通信の実装など、様々な機能を実装を行いました!
惜しくも期限内にビルドが間に合わず、今回抽選に参加することは叶わなかったものの、本プロジェクトは定期的に開催しているとのことなので、次回開催時にはリベンジしたいと考えています!💪
それでは、本記事はここで締めたいと思います。
最後までお読みいただきありがとうございました!









![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
