


 2024-04-08
2024-04-08


はじめまして!
2024年に入社した 小西 健太郎(こにし けんたろう) です。
私は、電気通信大学大学院の情報学専攻というところで、主に自然言語処理の研究を行っていました。今回は初めてのブログ執筆ということで、自身の研究とも関連があり世の中のトレンドでもあるChatGPTに関連した内容について、書いてみようと思います。ChatGPT(をはじめとする生成AI)の土台であるAttention機構について、「生成AI気になるけどよくわからない」みたいな方に、自身の超ざっくりとした理解を共有できたらなと!
昨今の生成AIブーム
近年、OpenAIのChatGPTやAnthoropicのClaude、GoogleのGeminiのような生成AIが多数リリースされていますよね。日本企業もこぞって生成AIの開発を行っていますが、生成AIって何がそんなに凄いんでしょうか?
生成AIの凄いとこ
生成AIができること、いろいろあります。
- Web検索
- テキスト翻訳
- テキスト要約
- 画像生成 etc...
ですが、一応これらはちょっと前のAIでも全然可能だったんです。ただ、少し前までのAIは「AIモデルAはテキスト翻訳用でAIモデルBは画像認識用」といった具合で、モデルごとに限定的なタスクを扱うことしかできませんでした。また、使用するにあたり、少なからずAIに関する知識も必要でした。生成AIの凄いところはここを解決した点で、ご存じの通り、AIを利用した あれこれ を1つのモデルで誰もが簡単にできます。また、日々の業務や研究など、複雑かつ内容の精度が必要とされるタスクにも利用できるほど便利なものになり、ユーザーが爆発的に増えた要因となっています。
そんな生成AIの中身、気になりませんか?
前述のとおり、いろいろできる生成AIですが、どうやって成り立っているのか気になりませんか?
私自身、大学の研究で生成AIを使っており、その際にその内部機構をいろいろと勉強したのですが、複雑な内容で理解にかなり苦しみました(笑)。そこで、以降では生成AIの仕組みをざっくりと誰にでもわかるように説明していけたらなと思います。
※当記事では、処理の抽象的な理解を目的としています。誤解を恐れず、細かい点を省いた説明となっていることをご了承ください。
生成AIの学習の流れを大まかに理解しよう
基本的に、生成AIの学習はAIモデルに対して、大量の文章を入力することで単語や文としての意味、文章全体の繋がりであったりを学習させます。具体的には、文をトークン(単語のような認識でOK)単位に分けて、その一部を隠した状態のものをAIモデルに渡します。そしてAIは、その隠れた部分にどういったトークンが入るかを予測することで、単語や文等の意味を学習していきます。
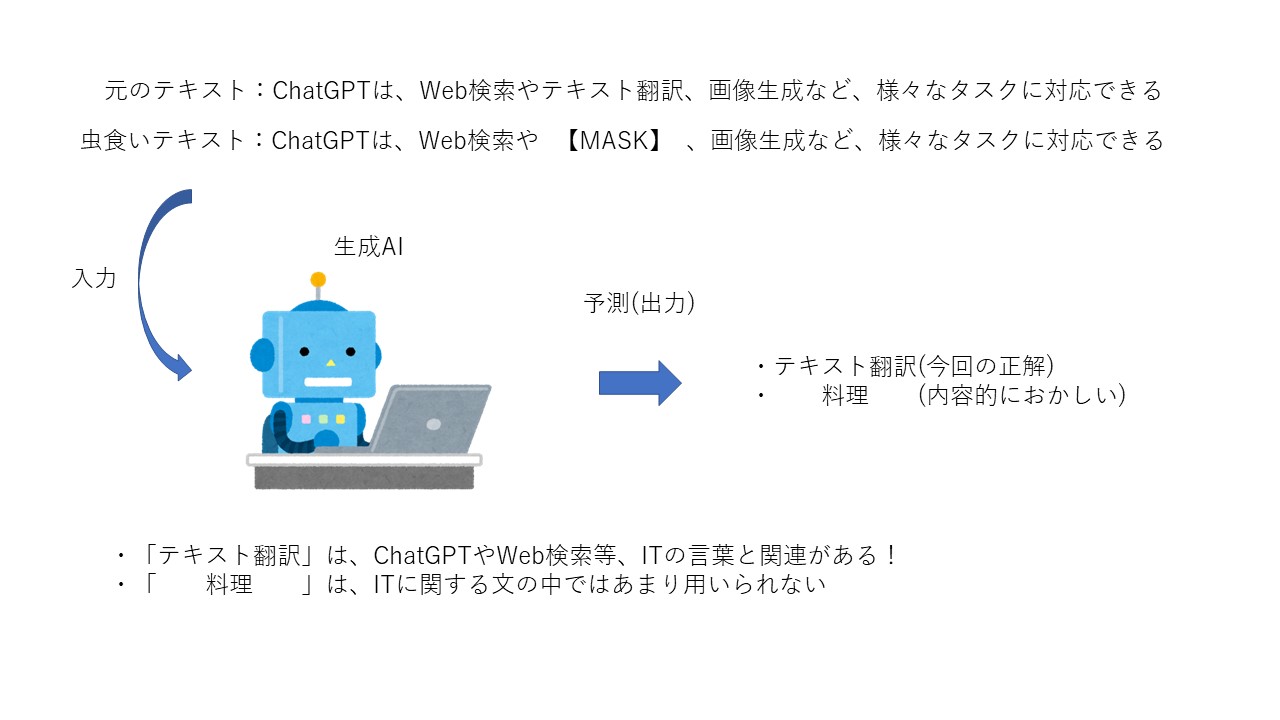
こんなんでホントにAIの学習ができるの?って思いませんか。僕も学習当時は不思議に思ったのですが、自分をAIモデルとして同じことをやった想定をすると結構納得できるかなと思います。
上の虫食い部分に入るトークンって、皆さんも予測できませんか?
完全に一致しないにしても、似たような意味であったり同じようなジャンルや括りのトークンで予測できたのではないかと思います。この予測の際に、皆さんはその言葉をよくするにあたって、どのようなことを考えましたか?
テキストの虫食いになっていない部分を基に、どんなトークンが入れば文として適切であるかやまとまりが良いかを考えて予測したと思います。経験則的にどうやら人間は、虫食いになっていないトークンの意味や繋がりから、虫食い部分のトークンを補完できるようになっているらしいです。
生成AIも同じで、テキスト全体の意味を考え、虫食い部分に入るトークンを予測する過程でトークンの意味や他のトークンとの繋がり、文全体の意味であったりを学習し、理解できるようになっていきます。
次に、この学習自体はどうやって行っているのかについて説明していきます。
実際の生成AIの学習
現在、世の中には様々な生成AIモデルがありますが、それを構成している最小要素は基本的に一緒です!
生成AIは、主にAttention機構というパーツを複雑に組み合わせることで、様々なタスクに対応できる能力を獲得しています。世の生成AIモデルは、その組み合わせ方が違ったり、そこにちょっとした異なるパーツが追加されていたり、学習データが違ったり... といったことが違いとなっており、各企業はその違いによって生まれる性能差を競っている感じです。
このAttention機構の処理が結構難しいのですが、この記事ではこの部分を皆さんに馴染みの深いものに置き換えて説明ができたらと思います!
やっていることはWeb検索と似てる!
本題の部分です。生成AIはトークンの意味をどうやって学習してるの???というところ。個人的には、皆さんおなじみのWeb検索に対応付けてあげるとシンプルな理解ができると思っています。
これは普段、インターネットを使って何か調べ物をするとき、Google ChromeだったりSafariであったりを使って、知りたい内容を言葉で入力して検索する、あの流れのまんまをイメージしてください。検索すると世の中に大量にある情報の中から、知りたい内容に対する答えとなるWebページがいろいろと表示されますよね?
そもそものWeb検索の方法についてもざっくりと説明すると、世にあるWebページにはその内容を示すようなタグ付けのようなことがなされており、検索ワードとWebページのタグの内容に関連が強いページほど、検索結果の上位に並べられるようになっています。
生成AIの学習もあんな感じです。前述の「生成AIの学習の流れを大まかに理解しよう」の内容を思い出してください。生成AIは虫食いテキストの虫食い部分を予測することで学習を行っていました。この流れをWebに置き換えたイメージが以下の通りです。
- 世の中にある大量の情報-世の中にある大量のトークン
- 検索ワード-テキストの虫食いになっていない部分
- Webページにおけるページ-同じような(完全一致ではない)トークンで構成される大量の文
- 検索結果の上位にあるWebページ-みんなに予測される(されやすい)トークン
上のイメージに基づいて説明すると、
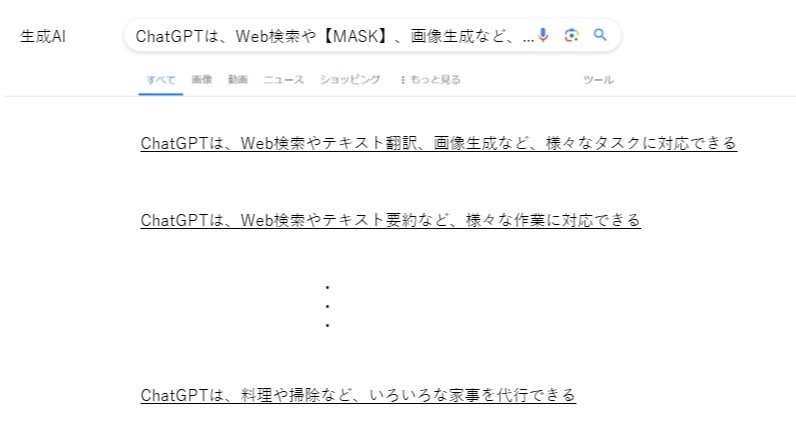
- テキストの虫食いになっていない部分でWeb検索を行う
- 同じようなトークンで構成される大量の文(Webページ)の中から、虫食いテキストと近しい文(Webページ)が検索結果の上位に現れる
- 検索結果の文を上から見ていき、知りたかった虫食い部分に入るべきだったトークン(知りたい内容)が見つかる
といった流れです。検索結果を見ていく中で、目的のトークンが見つかった場合、その文を構成するトークンは目的のトークンとの関連が強いことが分かり、逆に見つからない場合は関連が弱いことが分かります。生成AIの学習ではこれをとてつもない回数繰り返すことで、トークン間の繋がりを学習し、それによって特定のトークンの意味を学習していきます。そして人間のように、人間が提示してきたテキストの内容に対して、適切な回答やタスクを行えるように進化していく、というのが生成AIの超抽象的な理解になっています!
まとめ
まず、ここまで長く拙い説明を読んで下さり、ありがとうございました。
細かい部分を突きだすと、上の説明は至らない点がたくさんあると思いますが、初学者が生成AIを学習するにあたっては、このくらいフワッとした内容の方が収まりがいいように思います。これを第一歩として、生成AIの学習に興味を持ったり、実際に自分で勉強をしてみてより深い理解を得たりや発展した開発にチャレンジしてくれる人がいたら、とても嬉しいことだなと思います。
個人的に特に参考になった書籍や論文を以下にまとめておきますので、気になった方はチェックしてみてください!











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
