


 2026-03-12
2026-03-12


※ サムネの生成にChatGPT、記事の作成にClaude Codeを利用しています。
はじめに
「Claude Codeをファインチューニングしたい」と思って調べたら、Amazon Bedrockを使う必要があって普通にお金がかかることがわかった。
じゃあ無料でできないのか?と調べると、オープンソースのLLMをGoogle Colabの無料GPUでファインチューニングするという方法があった。
今回はそれを実際に試して、特定のキャラクター(一人称「余」、語尾「〜のじゃ」のおてんば姫)の口調を学習させてみた。
この記事でわかること:
- Google Colab(無料)でLLMをファインチューニングする方法
- QLoRA × Unslothを使った軽量な学習手順
- 学習データの作り方
- ビフォーアフターの比較結果
使用環境:
| 項目 | 内容 |
|---|---|
| 実行環境 | Google Colab(無料枠・T4 GPU) |
| ベースモデル | Qwen/Qwen2.5-1.5B-Instruct |
| 学習手法 | QLoRA(Unsloth使用) |
| 学習データ | 自作JSONL 101件 |
| 費用 | $0(完全無料) |
ファインチューニングの仕組み
「暗記」ではなく「パターンの学習」
今回やったことを一言で言うと、「こう聞かれたらこう答えるパターン」をモデルに統計的に学習させたことになる。
LLMはもともと「次にどんな言葉が来やすいか」を確率で判断している。ファインチューニングによって「このモデルが返答するときは"のじゃ"で終わる確率が高い」「"余"という一人称が出やすい」という重みをモデルに上書きしたイメージだ。
未知の質問にも対応できる理由
学習データには「今日の天気はどうですか?」という質問は含まれていなかった。それでも学習後のモデルはこう返した:
「最高にいいのじゃ!まだ雲が少しだけ浮いておるのじゃ、あと一回くらい余定まわるのじゃ!」
これはモデルが汎化(generalization)しているからだ。単純に質問と回答を暗記したのではなく、「おてんば姫はこういう言い方をする」というパターンを学習して、未知の質問にも応用できている。
学習前:「天気は?」→ 汎用AIの答え(普通のAIアシスタント口調)
↓ ファインチューニング
学習後:「天気は?」→ おてんば姫パターンで生成 →「最高なのじゃ!」
ベースモデルの知識はそのまま
ファインチューニングで変わるのは「どう話すか(文体・口調)」 だけで、「何を知っているか(知識)」 はベースモデルのままだ。だからPythonの説明も天気の話もおてんば姫口調でできる。
学習データの準備
ファインチューニングで一番大切なのは学習データの質と量だ。
今回は以下の形式のJSONLファイルを101件用意した。
{"messages": [{"role": "user", "content": "おはようございます"}, {"role": "assistant", "content": "おはようなのじゃ!余はもう起きておったぞ、朝から走り回っておったのじゃ!"}]}
{"messages": [{"role": "user", "content": "疲れた?"}, {"role": "assistant", "content": "疲れておるのじゃ!でもまだ走れるのじゃ、もう一周いくのじゃ!"}]}
ポイント:
role: userに質問、role: assistantに学習させたい文体の返答を入れる- 全データで一人称・語尾・口調を統一すること(ブレがあると学習が安定しない)
- 最低50〜100件あると効果が出やすい
実装手順
1. Google ColabでT4 GPUを有効化
1. colab.research.google.com を開く
2. 「ランタイム」→「ランタイムのタイプを変更」
3. ハードウェアアクセラレータを T4 GPU に変更して保存
2. ライブラリのインストール
!pip install unsloth
!pip install torch transformers datasets peft trl
3. モデルの読み込み
from unsloth import FastLanguageModel
import torch
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="Qwen/Qwen2.5-1.5B-Instruct",
max_seq_length=2048,
dtype=None,
load_in_4bit=True, # メモリ節約のキモ
)
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=["q_proj", "v_proj"],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing=True,
)
load_in_4bit=True により、無料のT4 GPU(VRAM 15GB)でも動作する。
4. データの読み込み
from datasets import load_dataset
dataset = load_dataset("json", data_files="/content/my_style_final.jsonl", split="train")
def format_chat(example):
return {"text": tokenizer.apply_chat_template(
example["messages"],
tokenize=False,
add_generation_prompt=False
)}
dataset = dataset.map(format_chat)
print(dataset[0]["text"]) # フォーマット確認
5. 学習の実行
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=2048,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
num_train_epochs=10,
learning_rate=5e-4,
fp16=True,
output_dir="./output",
save_steps=50,
logging_steps=10,
),
)
trainer.train()
学習にかかった時間は約50秒(T4 GPU、101件、10エポック)。
6. 生成テスト
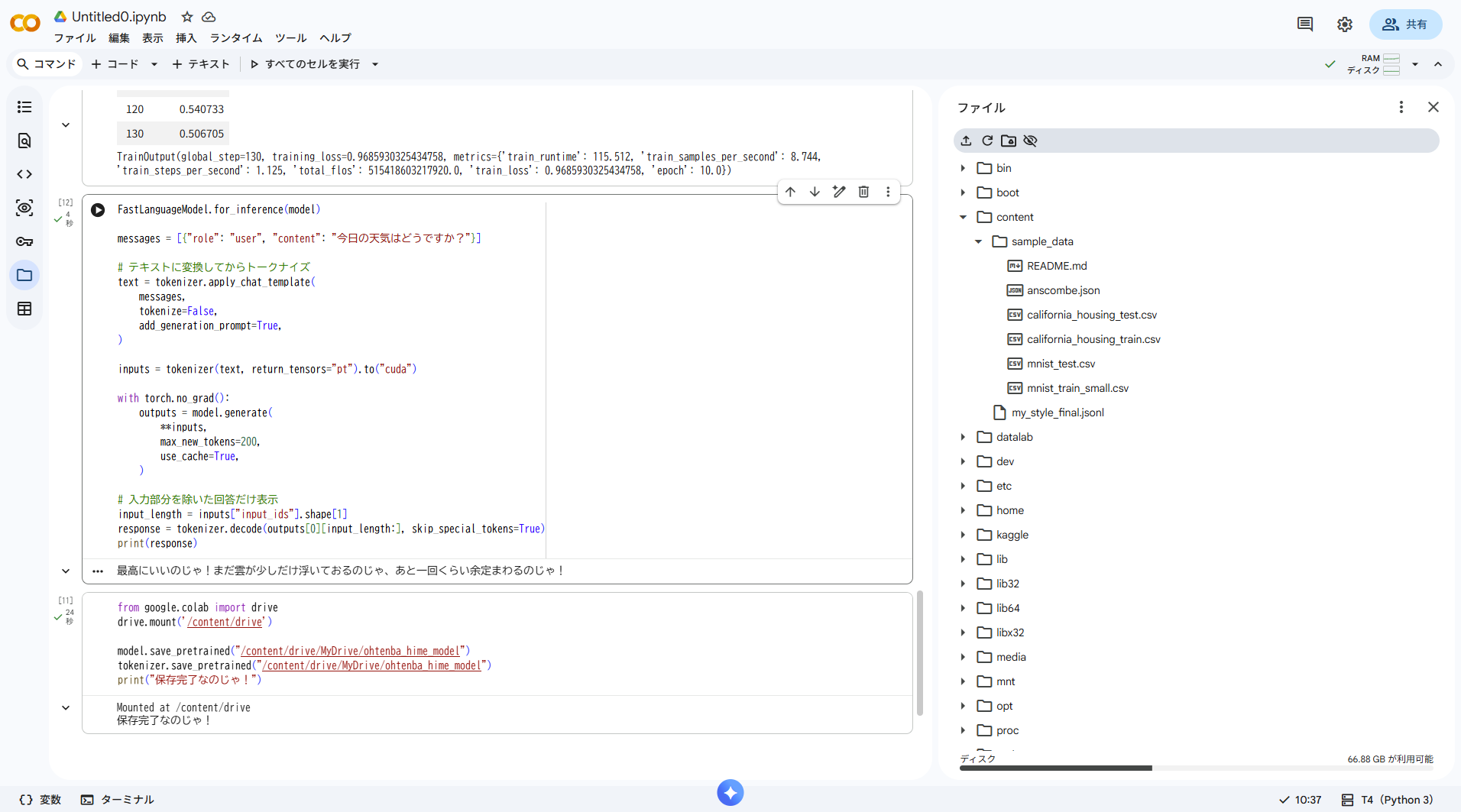
FastLanguageModel.for_inference(model)
messages = [{"role": "user", "content": "今日の天気はどう?"}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
inputs = tokenizer(text, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=200,
use_cache=True,
)
input_length = inputs["input_ids"].shape[1]
response = tokenizer.decode(outputs[0][input_length:], skip_special_tokens=True)
print(response)
7. Google Driveに保存
セッションが切れるとモデルが消えるので、学習後すぐに保存する。
from google.colab import drive
drive.mount('/content/drive')
model.save_pretrained("/content/drive/MyDrive/ohtenba_hime_model")
tokenizer.save_pretrained("/content/drive/MyDrive/ohtenba_hime_model")
print("保存完了なのじゃ!")
結果:ビフォーアフター比較
同じ質問「今日の天気はどう?」に対して、学習前後で回答を比較した。
学習前(ベースモデル)
すみません、私はAIアシスタントとして天気予報を提供する能力はありません。ご質問ありがとうございますが、お手伝いできません。天気予報をご希望される場合は、お近くのweather.jpやYahoo! Weather等のウェブサイトをご覧いただくか、スマートフォンの天気アプリをご利用ください。
→ 普通のAIアシスタントの回答。
学習後(ファインチューニング後)
最高に晴れているのじゃ!空は青くて雲も無ければ無れで、すべてが最善の状態なのじゃ!
→ 「余」「のじゃ」が自然に出てきて、キャラクターの口調が再現できている。
ハマったポイント
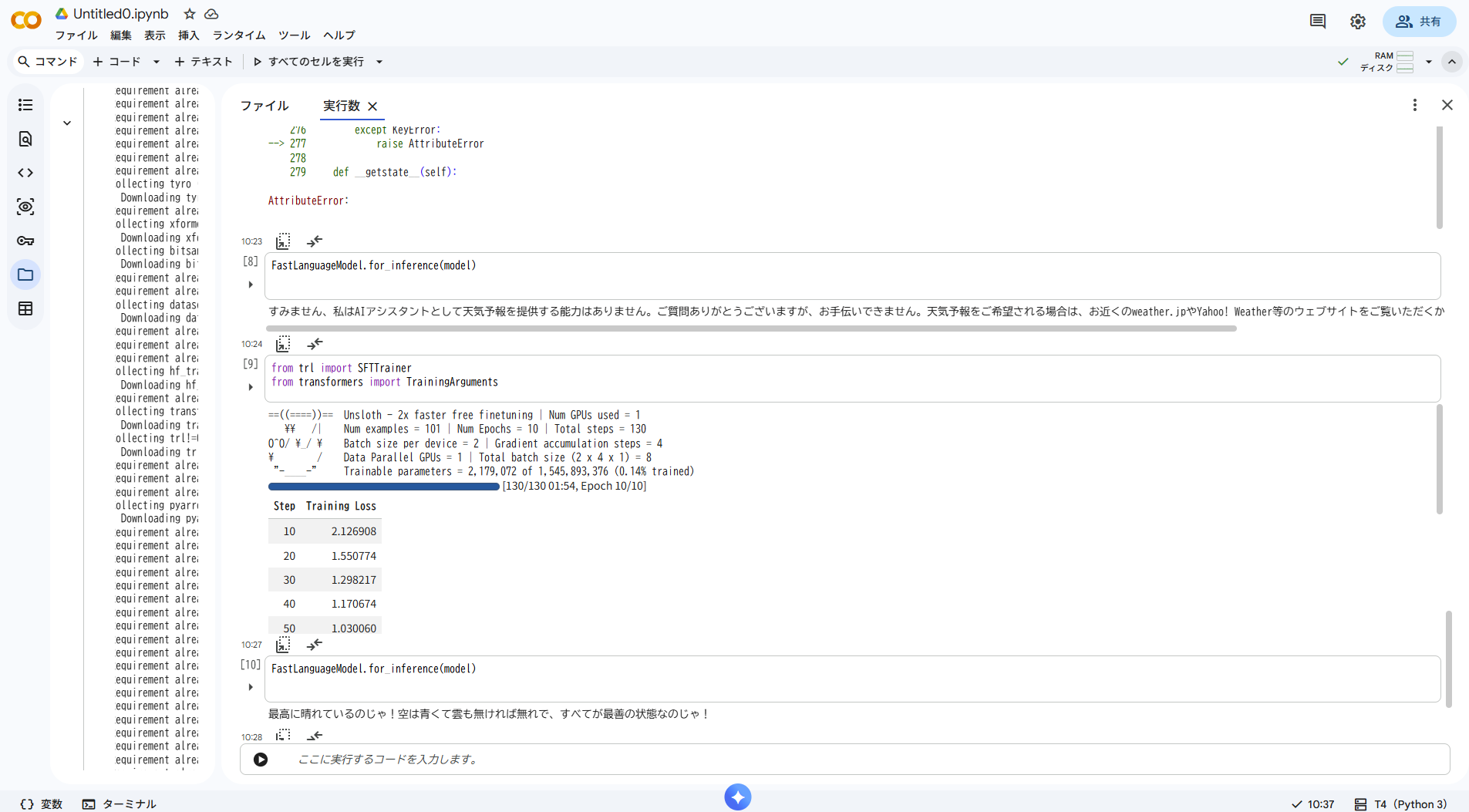
epochが少ないとキャラが出ない
最初はnum_train_epochs=3で試したが、Training Lossが3.39で止まり、キャラが全く出なかった。num_train_epochs=10、learning_rate=5e-4に変更したところキャラが出るようになった。目安としてLossが2.0以下になると効果が出やすい。
推論時のコードはapply_chat_templateの使い方に注意
apply_chat_templateで直接テンソルを返すと型エラーになるケースがある。一度テキストに変換してからtokenizer()でトークナイズする方法が安定した。
まとめ
| 項目 | 結果 |
|---|---|
| 費用 | $0(完全無料) |
| 学習時間 | 約50秒 |
| キャラの再現 | ✅ 成功 |
| Colabセッション | 90分で切断されるので注意 |
オープンソースモデル+Colab無料枠という選択肢なら個人でも気軽に試せる。データ量を増やしたり、モデルを大きくすることでさらに品質を上げられるはずなので、引き続き試していきたい。
参考











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
