


 2026-04-24
2026-04-24
目次

- 1. はじめに
- 2. VLMを民生用GPUで動かすために:量子化とLoRAの概要
- VLMとVRAMの壁
- 2つの軽量化技術
- 検証環境とロードマップ
- 3. まず結論:AI初学者の方はここだけ読めばOK
- 問題:最新AIは「重すぎて手元で動かせない」
- 解決策:2つの「軽量化」技術でメモリを節約する
- 実際に試したらどうなったか?
- 詳しく知りたい方へ
- 4. 専門用語の解説
- 量子化(Quantization)
- データ型とVRAMの関係
- 主要手法の比較
- 実装例:BitsAndBytesによる4-bit量子化
- LoRA(Low-Rank Adaptation)
- なぜVLMでLoRAなのか
- LoRAの仕組み
- VLM特有の考察:どこにAdapterを差し込むか
- 実装例:PEFTライブラリを使ったLoRA適用
- 実装Tips・ハマりどころ
- 精度のトレードオフへの対策
- PEFTライブラリ活用のコツ
- ハマりどころ集
- 5. 詳細な結論・まとめ
- 量子化形式の比較検証
- 学習時のメモリ消費比較
- 実用事例:遺失物管理システムにおける自動カテゴリ分類
- 推論時間とLoRAのオーバーヘッド
- 全体のまとめ
- 6. 参考
1. はじめに
はじめまして、今年新卒入社した松島明寛です。
高専では5年間、ソフトウェア開発とAI研究に取り組みました。4年次はカリキュラムのロボット開発プロジェクトでソフトウェア開発とプロジェクトマネージャを担当。5年次はAI系の研究室に所属し、DCON(ディープラーニングコンテスト)への参加や複数のシステム開発を経験しました。その中でも特に力を入れたのが、VLM(Vision Language Model:視覚言語モデル)を活用したシステム開発です。画像とテキストを組み合わせた認識タスクを日々試行錯誤し、「手元のGPUでいかに実用的なモデルを動かすか」という問いと向き合い続けてきました。
AIやソフトウェア開発を通じて私が一番好きなのは、「限られた環境で工夫を重ねてものを動かす瞬間」です。高価な機材やクラウド環境が整っていなくても、知識と試行錯誤で乗り越えられる問題は多い――そう実感できた学生時代でした。研究室では「手元にある環境でいかに最大限のパフォーマンスを引き出すか」を問い続けており、それが今回ご紹介するVRAM節約の取り組みの原点にもなっています。
この春からはエンジニアとして、現場に根ざしたAI活用に取り組んでいきます。研究で培ったノウハウを実際のプロダクトや業務システムに活かしていくことが当面の目標です。
さて、自己紹介はこのくらいにして、本題に入ります。
「最新のVLMを試したいけれど、クラウドGPUを借り続けるのはコストが気になる...」「手元のRTX 3060や4080で、どこまで実用的な推論や学習ができるんだろう?」
そんな悩みを持つエンジニアの方に向けて、私が卒業研究から実務にかけて試行錯誤した「VRAM節約の最適解」を共有します。
民生用GPU(RTX 4080)でVLMを動かすために量子化とLoRAを活用する全体像
2. VLMを民生用GPUで動かすために:量子化とLoRAの概要
VLMとVRAMの壁
近年のVLMは目覚ましい進化を遂げています。LLaVA、Qwen-VL、InternVL、Phi-3 Visionなど、マルチモーダルな理解能力を持つモデルが次々と登場しています。しかし、その進化には代償があります。パラメータ数の爆発的な増大です。
フル精度(FP32/FP16)で動かそうとすると、7Bパラメータのモデルでも14〜32GB以上のVRAMが必要になります。H100(80GB VRAM)やA100を持つ研究機関や大企業ならともかく、個人や中小規模の開発現場では現実的ではありません。
でも、諦めるのはまだ早いです。
2つの軽量化技術
この記事では、手元のRTX 40x0シリーズ(VRAM 16GB前後)で最新VLMを動かし、さらに自分のタスクに特化させるための二つの軽量化技術を実践的に解説します。
- 量子化(Quantization):モデルの重みを低精度なデータ型に変換することで、推論時のVRAM消費を1/4以下に削減する技術です。精度をほぼ維持したまま、大幅にメモリを節約できます。
- LoRA(Low-Rank Adaptation):モデル全体を再学習する代わりに、「差分」だけを学習する技術です。学習対象のパラメータ数が全体の1%未満になるため、VRAM消費を大幅に抑えた追加学習が可能になります。
この2つを組み合わせたQLoRAにより、60GB以上のVRAMが必要だった学習が、RTX 4080(16GB)で現実的に行えるようになります。
検証環境とロードマップ
本記事の検証は以下の環境を前提としています。
| 項目 | 内容 |
|---|---|
| GPU | NVIDIA GeForce RTX 4080 (VRAM 16GB) |
| OS | Ubuntu 22.04 LTS |
| CUDA | 12.1 |
| Python | 3.10 |
| PyTorch | 2.2.x |
| Transformer | 4.40.x |
対象モデルはQwen2.5-VL-7B(Alibaba製、日本語対応も良好)を使用しました。
```
フル精度での推論(VRAM不足)
↓
[Step 1] 量子化でVRAM使用量を削減 → 推論可能に
↓
[Step 2] LoRAで特定タスクに追加学習 → 精度向上
```
3. まず結論:AI初学者の方はここだけ読めばOK
「AIやGPUの話はよく分からない…」という方のために、まず難しい用語を使わずに結論だけお伝えします。技術的な詳細は次のセクション以降で丁寧に解説しますので、興味のある方はそちらへどうぞ。
問題:最新AIは「重すぎて手元で動かせない」
最近の画像認識AIはとても賢くなっていますが、その分「動かすために必要なメモリ(VRAM)」も膨大になっています。一般的なゲーミングPC(VRAM 16GB程度)では、最新AIをそのまま動かすことはほぼできません。
PCのRAMに例えると、「RAM 16GBのPCで、30GB以上のメモリを必要とするソフトを起動しようとしている」ような状況です。
解決策:2つの「軽量化」技術でメモリを節約する
この記事では、次の2つの技術でその問題を解決します。
- 量子化:AIの計算精度を少し落とす代わりに、必要なメモリを最大で元の1/4以下に圧縮する技術です。ほとんど性能を落とさずに大幅な軽量化が実現できます。
- LoRA:AIをゼロから再学習するのではなく、「変更した部分だけ」を学習させる技術です。学習に必要なメモリを大幅に減らしながら、特定の用途に特化した追加学習ができます。
この2つを組み合わせると、以下のことが手元のゲーミングGPU1枚で実現できます。
| やりたいこと | 必要VRAM (目安) | 使う技術 |
|---|---|---|
| 最新AIで画像を認識したい | 約6GB | 量子化 (4-bit) |
| さらに高速に推論したい | 約8GB | AWQ / GPTQ |
| 自分のデータを追加学習させたい | 約12GB | QLoRA (量子化 + LoRA) |
実際に試したらどうなったか?
卒業研究で落とし物を自動分類するシステムに本技術を適用した結果、VRAM 16GBのゲーミングGPU(RTX 4080)で、OpenAIやAnthropicのような大手クラウドAIに肉薄する精度を達成しました。
> 結論:「高価なサーバー用GPUがなくても、工夫次第で最新AIは手元で動かせる」
詳しく知りたい方へ
「仕組みが気になる」「実際のコードを見たい」「どこでハマりやすいか知りたい」という方は、このまま次のセクションへ進んでください。各技術の詳細な仕組み・実装例・検証結果を順番に解説しています。
4. 専門用語の解説
量子化(Quantization)
データ型とVRAMの関係
量子化とは、モデルの重みを表現するデータ型を高精度から低精度に変換する技術です。
| データ型 | ビット数 | メモリ (7Bモデル) | 備考 |
|---|---|---|---|
| FP32 | 32bit | ~28GB | フル精度 |
| FP16 / BF16 | 16bit | ~14GB | 通常の学習・推論 |
| INT8 | 8bit | ~7GB | 軽量化の入り口 |
| NF4 / INT4 | 4bit | ~3.5GB | RTX 4080でも余裕 |
NF4(Normal Float 4)は、量子化後の精度劣化を最小化するよう設計された4bitフォーマットで、`bitsandbytes`ライブラリで実装されています。
主要手法の比較
| 手法 | 導入の手軽さ | 推論速度 | 精度 | 特徴 |
|---|---|---|---|---|
| BitsAndBytes (4-bit / 8-bit) | ★★★ | ★★ | ★★★ | コード数行で即適用可能 |
| AWQ | ★★ | ★★★ | ★★★ | 重みの重要度を考慮した量子化 |
| GPTQ | ★★ | ★★★ | ★★ | 高速推論に特化 |
最初の一歩としてはBitsAndBytesが圧倒的に手軽です。
実装例:BitsAndBytesによる4-bit量子化
Python```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from PIL import Image
# 量子化の設定
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 4-bit量子化を有効化
bnb_4bit_compute_dtype=torch.bfloat16, # 計算はBF16で実施
bnb_4bit_use_double_quant=True, # ダブル量子化でさらにVRAM削減
bnb_4bit_quant_type="nf4", # NF4フォーマットを使用
)
model_id = "Qwen2.5-VL-7B" # Hugging Face上のモデルID
# 量子化設定を渡してモデルをロード
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto", # GPUへの自動割り当て
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
```LoRA(Low-Rank Adaptation)
なぜVLMでLoRAなのか
学習方法には大きく二つのアプローチがあります。
Full Fine-tuning(全パラメータ更新)
- 7Bモデルの場合、学習時に60〜80GB以上のVRAMが必要
- 民生用GPUでは実質不可能
LoRA(Low-Rank Adaptation)
- 差分のみを学習するため、VRAM消費を大幅に削減
- 元のモデルの重みは凍結されるため、壊滅的忘却を抑制
LoRAの仕組み
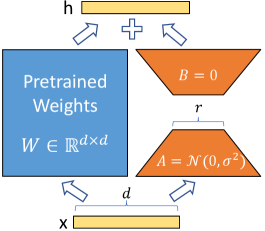
LoRAは、事前学習済みの重み行列 W を直接更新する代わりに、低ランクの差分行列 W′= W + ΔW = W + BA を学習します。
W′ = W + ΔW = W + BA
ここで、B ∈ ℝ^(d×r)、A ∈ ℝ^(r×k)、ランク r ≪ min(d, k) です。
例えば d =k=4096、r=16 の場合、更新パラメータ数は元の行列の約0.78%に削減されます。
> (注釈) この低ランク行列 A, B だけを更新することで、学習対象をモデル全体の0.43%まで削減しています。
LoRAの仕組み:事前学習済み重みWに低ランク行列AとBの積(ΔW=BA)を加算する差分学習のアーキテクチャ図
VLM特有の考察:どこにAdapterを差し込むか
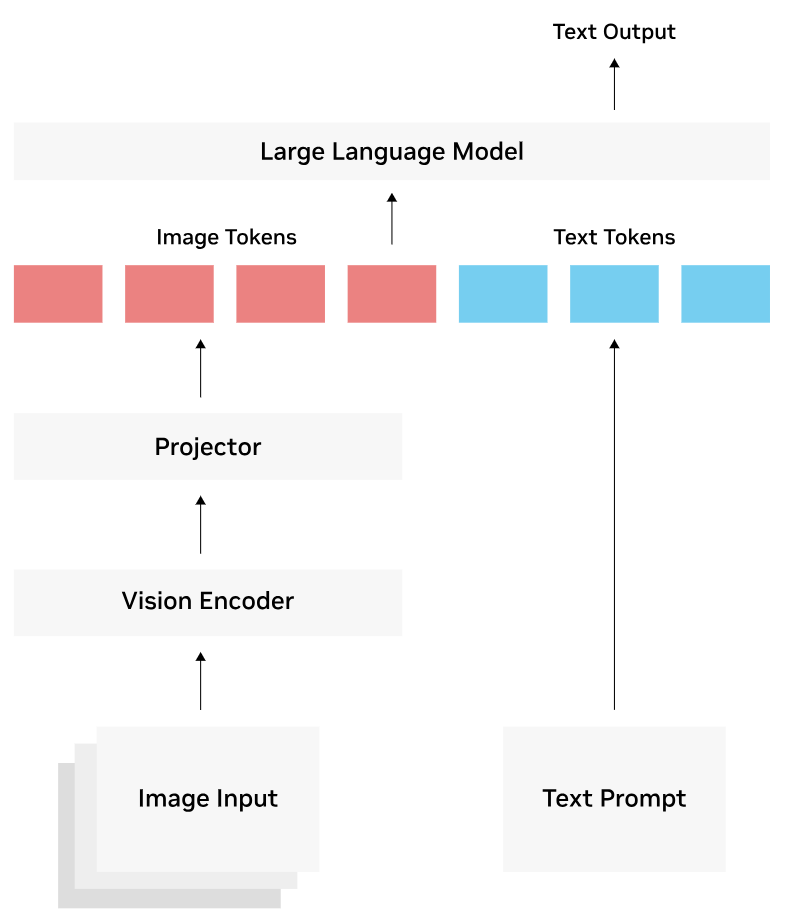
VLMは通常、以下の3コンポーネントで構成されます。
```
[画像入力] → [Vision Encoder(CLIP等)] → [Projector層] → [LLM(言語モデル)]
```LoRAを差し込む場所による効果の違いは以下の通りです。
| 対象 | 効果 | 注意点 |
|---|---|---|
| LLM部分のみ | 言語的な回答スタイルの調整に有効 | ビジョン理解は変わらない |
| Projector層のみ | 画像→テキスト変換の改善 | 学習データが少ないと不安定 |
| LLM + Projector | 最もバランスが良い | 学習時間が増加 |
| Vision Encoder | 特定ドメイン画像への対応 | 事前学習の汎用性が失われるリスク |
VLMアーキテクチャ(Vision Encoder・Projector・LLM)とLoRAアダプターを挿入する各コンポーネントの概略図
今回は以下の理由からLLM部分とProjector層の両方にLoRAを適用しました。
- Projector層:視覚情報をLLMが理解できるトークンへ変換する要の層であり、ドメイン特化画像への適応に直結します。
- LLM部分:複雑な遺失物カテゴリ(431クラス)の階層構造を理解させるために、言語的な推論能力の調整が必要です。
実装例:PEFTライブラリを使ったLoRA適用
Python```python
from peft import LoraConfig, get_peft_model, TaskType
# LoRAの設定
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8, # ランク数(小さいほど軽量、大きいほど表現力が高い)
lora_alpha=16, # スケーリング係数(通常はr×2を目安に)
lora_dropout=0.05,
target_modules=[ # LoRAを適用するモジュール名
"q_proj",
"v_proj",
"k_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
bias="none",
)
# 量子化済みモデルにLoRAを適用(QLoRA)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# trainable params: 8,388,608 || all params: 6,746,804,224 || trainable%: 0.1244
```実装Tips・ハマりどころ
精度のトレードオフへの対策
4-bit量子化では一定の精度劣化が生じます。これを軽減するための工夫を紹介します。
ダブル量子化の活用
Python```python
BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True, # 量子化定数自体もさらに量子化
...
)
```追加で約0.1〜0.4 bits/パラメータの削減効果があります。
重要な層はFP16のまま残す
Python```python
# 出力層はフル精度で保持
model.lm_head = model.lm_head.to(torch.float16)
```PEFTライブラリ活用のコツ
学習後のモデル保存と読み込み
Python```python
# LoRAアダプターのみ保存(軽量!数十〜数百MB)
model.save_pretrained("./lora_adapter")
# 推論時:ベースモデル + アダプターを組み合わせる
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto",
)
model = PeftModel.from_pretrained(base_model, "./lora_adapter")
```ベースモデル(数GB〜十数GB)はそのまま共有し、タスク特化の差分だけを数十MBで配布・切り替えできるのがLoRAの大きな利点です。
ハマりどころ集
その"auto"、実は危険かも? device_map の落とし穴
最初は便利だと思って `auto` に任せていたのですが、一部のレイヤーがCPUに逃げてしまい、学習速度が極端に落ちる現象に見舞われました。学習時は迷わずGPU 0に固定することをお勧めします。
Python```python
# 学習時はGPUを明示指定
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map={"": 0}, # GPU 0に全て乗せる
)
```勾配チェックポイントとキャッシュ
学習時に勾配チェックポイントを有効化する場合、`model.config.use_cache = False` を設定しないとエラーが発生します。
Python```python
model.config.use_cache = False # 学習時は必ず無効化
model.enable_input_require_grads()
```VRAM断片化
多数の画像を評価ループで回すと、見かけ上の使用量以上にVRAMが逼迫します。ループごとに `gc.collect()` と `torch.cuda.empty_cache()` を呼び出すことで、断片化を抑制しました。
Python```python
import gc
import torch
gc.collect()
torch.cuda.empty_cache()
```5. 詳細な結論・まとめ
量子化形式の比較検証
モデルを民生用GPUで動かす際、最初のハードルは「量子化形式」の選択です。今回は `bitsandbytes` を利用し、Qwen2.5-VL-7Bを用いて複数の量子化形式で精度(遺失物カテゴリ分類)と推論速度を比較検証しました。
| 量子化形式 | 大分類精度 | 平均推論時間 | 特徴 |
|---|---|---|---|
| 4-bit NF4 | 63.50% | 2.602秒 | 精度・速度ともに最高バランス |
| 8-bit | 63.23% | 3.366秒 | 精度は高いが、推論がやや重い |
| 4-bit FP4 | 58.80% | 2.582秒 | 速度優先だが、精度の落ち込みが顕著 |
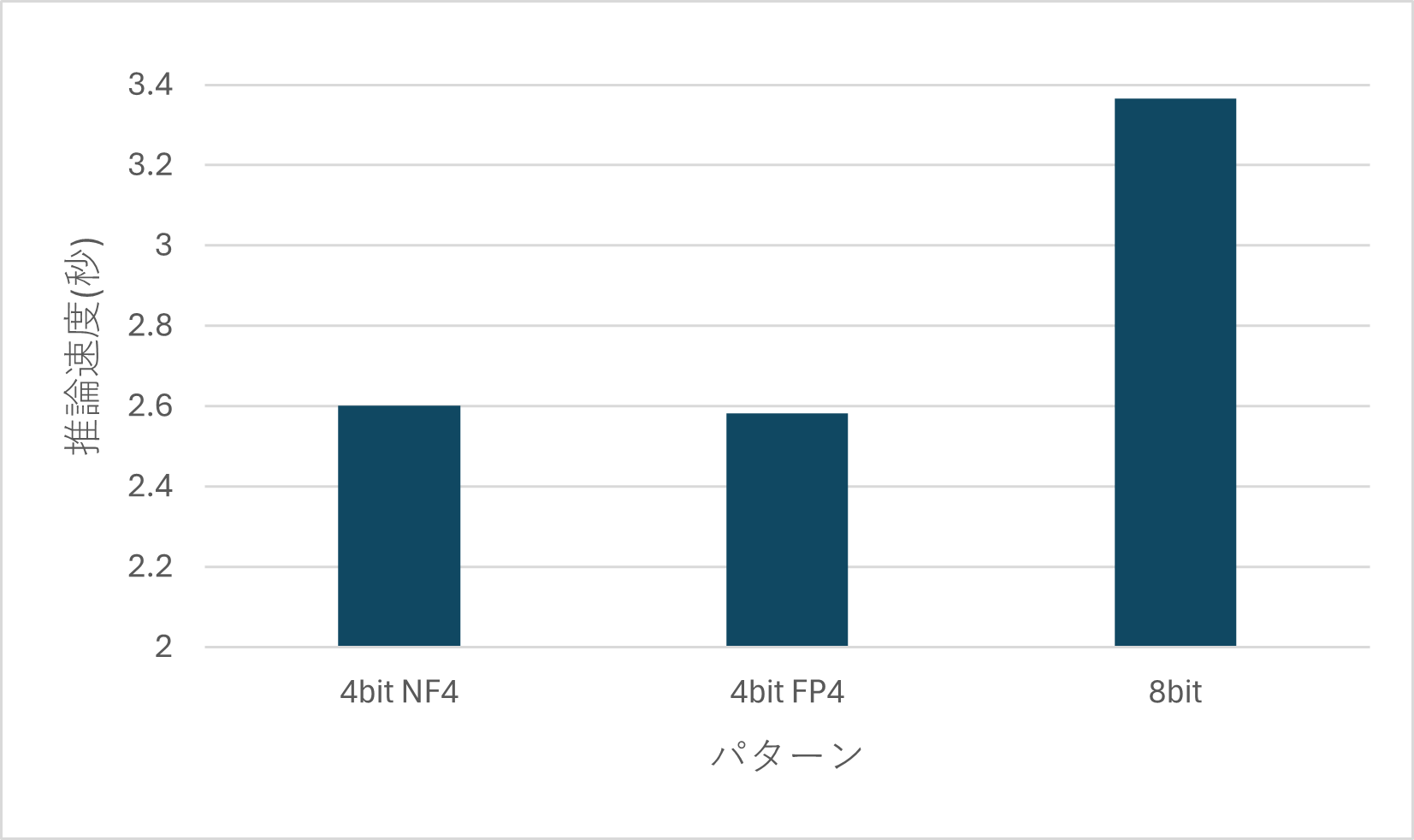
NF4・8-bit・FP4の精度(遺失物カテゴリ分類)と平均推論時間の比較棒グラフ
検証の結果、重みの分布を考慮した NF4(Normal Float 4) が、VRAMを約5.4GBまで抑えつつ、8-bit以上の精度を維持できる最適解であることが分かりました。
> 💡 結論:Qwen2.5-VLにおける量子化の最適解
> 精度と速度のトレードオフを検証した結果、4-bit NF4がVRAMを約5.4GBに抑えつつ、8-bitを凌ぐ精度を維持できる「最もバランスの良い形式」であることが分かりました。
学習時のメモリ消費比較
Qwen2.5-VL-7B、バッチサイズ1、画像解像度は未設定(Qwen2.5-VLは動的解像度に対応しているため)での計測:
| 手法 | 学習時VRAM | 学習可能パラメータ |
|---|---|---|
| Full Fine-tuning (FP16) | ~60GB | 7B (100%) |
| LoRA (FP16) | ~24GB | ~8.4M (0.12%) |
| QLoRA (4-bit + LoRA) | ~12GB | ~8.4M (0.12%) |
QLoRA(量子化 + LoRA)の組み合わせで、RTX 4080でも追加学習が可能になります。
実用事例:遺失物管理システムにおける自動カテゴリ分類
- 学習データ:拾得物画像 約8,000枚(撮影, Webスクレイピング + 半自動アノテーション)
- ベースモデル:Qwen2.5-VL-7B(4-bit量子化)
- 学習手法:QLoRA(r=8、Alpha=16、エポック数3)
- 学習可能パラメータ:約20.19M(ベースモデルのわずか0.43%)
パラメータ効率についても特筆すべき点があります。今回の設定(LoRAランク `r=8`)では、学習対象となるパラメータ数はわずか20.19Mであり、モデル全体の0.43%に過ぎません。これにより、本来なら60GB以上のVRAMを要する学習が、RTX 4080(16GB)環境で12GB程度の消費に収まり、現実的な時間での微調整が可能となりました。
学習の結果、特定の分類体系(遺失物管理)に対する深い理解を確認できました。特に難易度の高い小分類(431クラス)において、顕著な成果が得られています。
- ベースモデル(4-bit):42.00%
- LoRA適用後モデル:49.20%(+7.2ポイント向上)
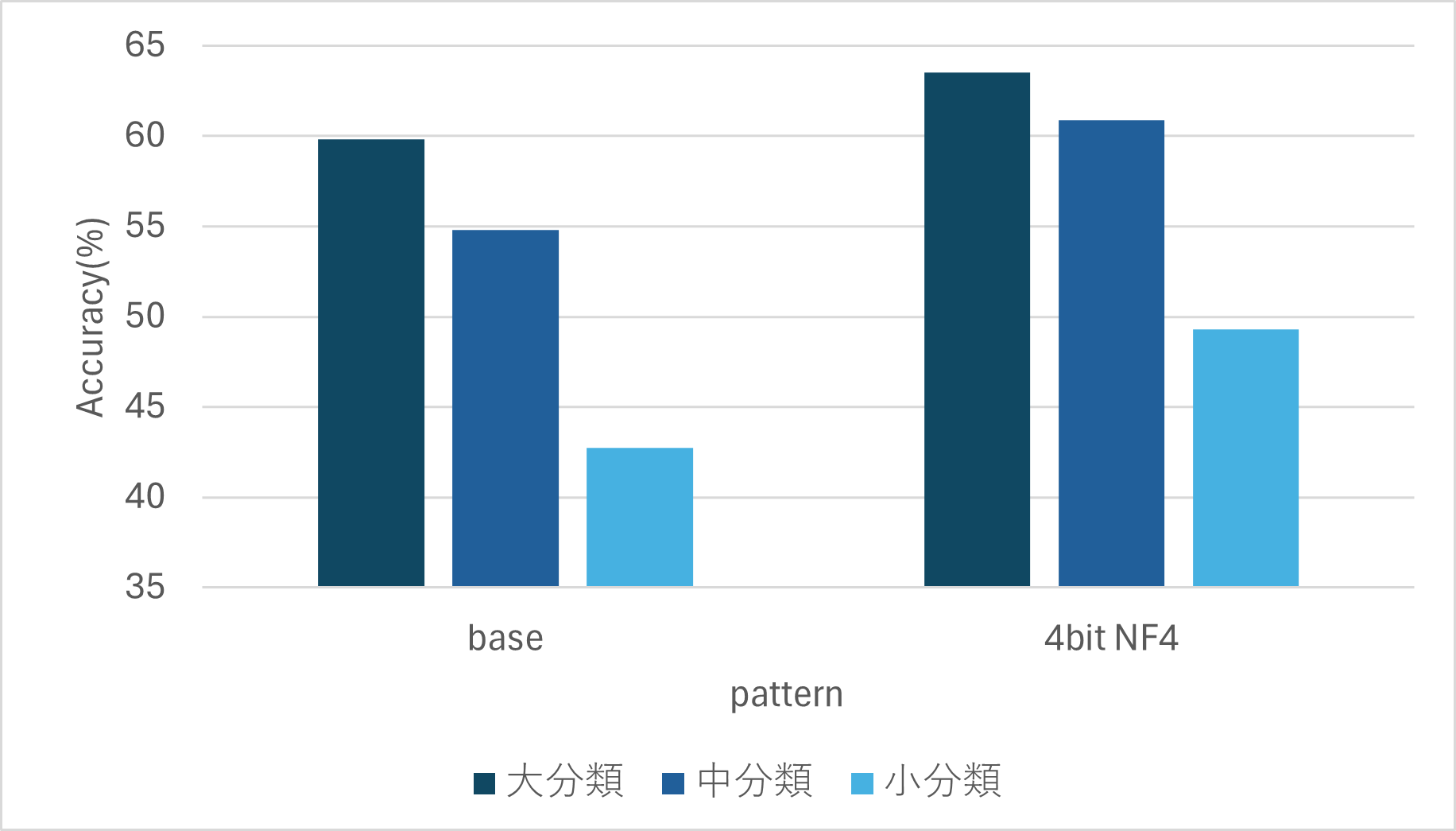
QLoRA適用前後のVLM精度比較:ベースモデル42.00%からLoRA適用後49.20%へ向上した精度グラフ
興味深いのは、この「民生用GPU上の7Bモデル」が、Claude 3.5 Sonnet(精度51.23%)などの巨大なクローズドモデルに肉薄する性能を発揮した点です。特定ドメインに絞ったLoRAチューニングは、計算リソースの制約をモデルの「専門性」でカバーできる強力な武器になります。
推論時間とLoRAのオーバーヘッド
LoRA適用による推論時間の変化を計測したところ、合計時間は約26%(0.6066秒→0.7650秒)増加しました。増加の主な要因はモデル生成(generate)ステップの計算コストであり、精度向上とのトレードオフとして考慮する必要があります。
全体のまとめ
量子化とLoRAを組み合わせることで、RTX 4080(VRAM 16GB)という民生用GPUでも、最新VLMの推論と追加学習が現実的に可能であることを確認しました。
私は、「最高のマシンがなくても、知恵と工夫で最新技術を現場に届ける」のがエンジニアの醍醐味だと考えています。
今後も研究や実装で得た知見をこのブログで発信していく予定です。
6. 参考
- [Hugging Face - BitsAndBytes Integration](https://huggingface.co/docs/transformers/quantization/bitsandbytes)
- [PEFT: Parameter-Efficient Fine-Tuning](https://github.com/huggingface/peft)
- [QLoRA: Efficient Finetuning of Quantized LLMs](https://arxiv.org/abs/2305.14314)
- [LLaVA: Large Language and Vision Assistant](https://llava-vl.github.io/)
- [Qwen-VL](https://github.com/QwenLM/Qwen-VL)











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
