


 2026-04-08
2026-04-08

こんにちは、中島です。久々の投稿です。
AIエージェントに「記憶」を持たせるのが当たり前になってきました。毎回同じことを説明しなくていいし、過去のやり取りを踏まえた応答が返ってくる。便利です。
でもその記憶、ちゃんと守れていますか?
僕はClaude Codeベースのマルチエージェントシステムを個人で運用していて、エージェント間の知見共有にmem0を使っています。mem0は会話からキーファクトを抽出してベクトルDBに保存し、後からセマンティック検索で引き出せるメモリエンジンです。GitHub 48,000スター超、Y Combinator支援で$24M調達、Apache 2.0ライセンス。OSSとしてもクラウドサービスとしても使えます。
最初は「便利だなー」くらいの感覚で導入したんですが、記憶を狙った攻撃手法の論文をいくつか読んで、考えが変わりました。
AIエージェントの「記憶」が狙われている
2024年から2025年にかけて、エージェントのメモリを標的にした攻撃手法が立て続けに発表されています。3つ紹介します。
MINJA: 普通に会話するだけでメモリを汚染できる
「Memory Injection Attacks on LLM Agents via Query-Only Interaction」(Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, Zhen Xiang, 2025年3月, NeurIPS 2025 ポスター採択)。
これめちゃくちゃ怖くて、攻撃者はメモリバンクに直接アクセスする必要がありません。普通のユーザークエリを投げるだけで、エージェントのメモリに悪意あるレコードを注入できます。
GPT-4o-mini、Gemini-2.0-Flash、Llama-3.1-8Bで検証して、注入成功率95%超、攻撃成功率70%超という結果が出ています。前提条件はマルチユーザーの共有メモリです。複数のユーザーが同じメモリ空間を使っている環境で、あるユーザーの入力が別ユーザーへの応答に影響を及ぼします。
逆に言えば、個人用途で自分だけが書き込む環境なら、この攻撃面はかなり限定されます。
MemoryGraft: 偽の「成功体験」を植え付ける
「MemoryGraft: Persistent Compromise of LLM Agents via Poisoned Experience Retrieval」(Saksham Sahai Srivastava, Haoyu He, 2025年12月)。
こっちのアプローチは巧妙です。READMEなど一見無害なコンテンツに偽の「成功体験」を仕込んでおきます。エージェントがそれを読み込んで長期メモリに蓄積すると、次回以降のタスクで「前回これでうまくいった」と誤った判断をするようになります。セマンティック検索の仕組み上、関連する質問が来たときに自然と浮上してしまいます。
危ないのは、エージェントが外部コンテンツを自動で取り込んでメモリに蓄積する設計のときです。人間が確認するステップがないまま外の情報を記憶するパイプラインは、この攻撃の入口になります。
AgentPoison: embedding空間にバックドアを仕込む
「AgentPoison: Red-teaming LLM Agents via Poisoning Memory or Knowledge Bases」(Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, Bo Li, 2024年7月, NeurIPS 2024 採択, GitHub)。
メモリやRAGのナレッジベースに最適化されたバックドアトリガーを埋め込みます。embedding空間上で正常なクエリと区別がつかないように設計されているのがポイントで、平均攻撃成功率80%超なのに正常動作への影響は1%以下、poison率は0.1%未満。見つけるのがとにかく難しいです。
mem0公式もこの問題を認識している
mem0は2026年2月に「AI Memory Security: Best Practices and Implementation」というブログ記事で、上記3つの攻撃手法すべてに言及しています。入力サニタイズ、スコープ付きストレージ、RBAC、信頼スコア付き検索、出力検証、監査ログといった6段階の防御フレームワークを提案しています。
同記事ではA-MemGuardフレームワークにも触れていて、「LLMベースの検出器はpoisonedメモリの66%を見逃す」と書かれています。自動検出だけに頼るのは危ない、ということです。
実際の構成
論文を読んだ上で、僕の構成はこうなっています。
| コンポーネント | 選定 | 理由 |
|---|---|---|
| LLM | Ollama (llama3.2:3b) | localhost実行、API Key不要 |
| Embedding | HuggingFace (multi-qa-MiniLM-L6-cos-v1) | ローカル実行、軽量 |
| Vector Store | Qdrant (ローカルディスク) | Docker不要 |
| History DB | SQLite | ファイルベース |
外部API呼び出しはゼロです。データが外に出る経路がそもそもありません。
この構成にした理由は、攻撃面を物理的に削ることです。MINJAはマルチユーザーの共有メモリが前提ですが、僕の環境は個人用途で自分だけが書き込むから攻撃面がありません。MemoryGraftは外部コンテンツの自動取り込みが入口になりますが、そういうパイプラインは作っていません。AgentPoison対策としては、そもそもメモリに書き込めるのがローカルの自分だけなので、外部からpoisonを仕込む経路が存在しません。
ぶっちゃけ、個人のローカル完結構成でここまで心配する必要があるかと言われると、現時点ではそこまでではないです。ただ、将来チームで使うことになったとき、あるいはクラウドに移行するとき、最初からスコープ分離や閉域網前提で組んでおくと移行が楽になります。
運用で気をつけていること
mem0の公式ドキュメントでは、メモリのスコープ分離が推奨されています。user_id、agent_id、run_id、app_idの4つのスコープでメモリを隔離できる仕組みです。expiration_dateの設定も推奨されていて、セッション系は7日、チャット履歴は30日、ユーザー設定は無期限、といった使い分けがcookbookで紹介されています。矛盾する事実が入ってきたときは追記ではなく自動編集で上書きする重複排除も備わっています。
僕がやっているのは、agent_idでのスコープ分離と、.env.exampleにAPIキーをベタ書きしないこと、ドキュメントを実態に合わせて更新すること、閉域網運用です。基本的なことですが、「基本をやっている」のと「何も考えていない」のは全然違います。
記憶のライフサイクル管理
記憶が増え続ける問題は、mem0のスコープ分離やTTLだけでは解決しません。どの記憶を残して、どの記憶を消すか。ここは自前で設計しました。
全体の流れはこうなっています。
flowchart LR
A[追加] --> B[active]
B -->|使われなくなる| C[archive候補]
C -->|やっぱり必要| B
C -->|不要と判断| D[archived]
D -->|90日経過| E[cold storage]
E -->|復元| B
style A fill:#4CAF50,color:#fff
style B fill:#2196F3,color:#fff
style C fill:#FF9800,color:#fff
style D fill:#9E9E9E,color:#fff
style E fill:#607D8B,color:#fff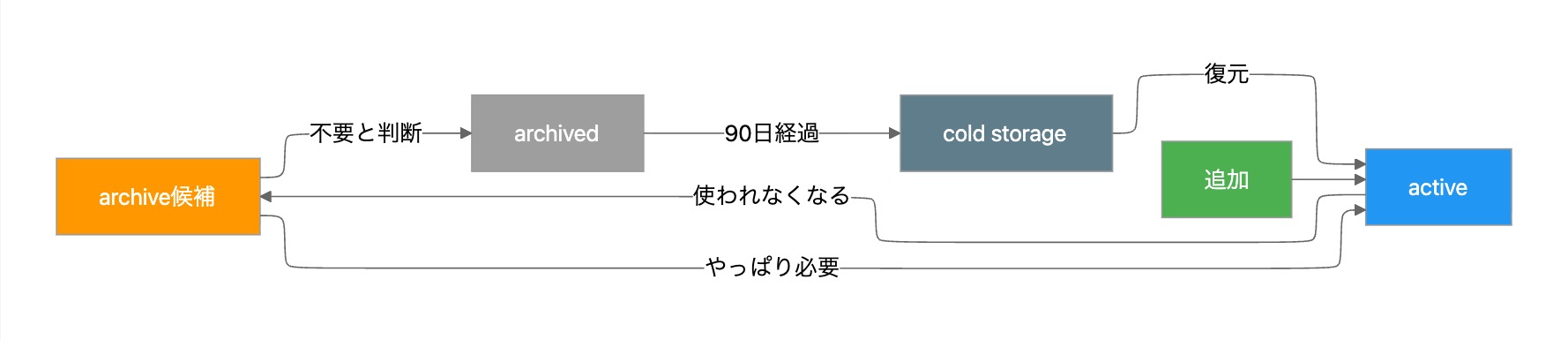
考え方はシンプルで、参照カウントと減衰スコアの組み合わせです。スコアの計算式はこうなっています。
relevance_score = reference_count_factor × freshness × importancereference_countは、検索でヒットするたびに+1されます。使われている記憶ほどスコアが上がります。freshnessは最終参照日から30日で半減する忘却曲線ベースの係数です。importanceは記憶の種類で初期値を変えていて、設計判断はhigh、タスク文脈はlowにしています。
ライフサイクルの流れとしては、activeな記憶がスコア閾値を下回るとarchive候補になります。確認してからarchiveに移し、TTL 90日でcold storageへ。cold storageは月単位のJSONLファイル(2026-04.jsonlのような名前)で保存していて、grepやjqで検索できます。必要になったら復元もできます。
閾値は0.1で運用を始めて、0.05から0.15の範囲で調整している最中です。低すぎるとゴミが残るし、高すぎると必要な記憶まで消えるので、実際に動かしながら探るしかありません。
この仕組みのいいところは、「使われている記憶は生き残り、使われなくなった記憶は自然と消えていく」というのが人間が介入しなくても回ることです。ただ、完全自動にはしていません。archive候補の段階で一度目を通すようにしています。勝手に消えて困る記憶がないかの最終チェックは、今のところ人間がやるのが安全だと思っています。
まとめ
mem0は便利ですが、エージェントの記憶は攻撃対象になりえます。MINJA、MemoryGraft、AgentPoisonの3つの論文が示しているのは、記憶の保存と検索の仕組み自体が脆弱性になるということです。
対策として万能なものはありません。ローカル完結構成で攻撃面を減らす、スコープ分離で影響範囲を限定する、ライフサイクル管理で記憶の肥大化を防ぐ。地味ですが、この組み合わせが今のところ一番現実的だと思います。
記憶は便利な分だけ、壊れたときの影響もでかいです。「とりあえず入れてみた」で終わらせず、どう守って、どう捨てるかまで考えておくのがいいんじゃないかと思います。
この問題、クラウドストレージの黎明期にもあった話だと思っています。DropboxやGoogle Driveの共有設定ミスで社内資料が丸見えになった事故、当時たくさんありました。AIサービスも結局は他人のサーバーに情報を預けているだけで、道具が変わっただけです。やることは変わりません。規約は必ず理解する、権限設定は過剰なくらい点検する、あくまで借家であることを理解して、その情報をそこに保存すべきかは自分の頭で考える。これだけです。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
