






まずは軽く自己紹介
初めまして!私、北海道は釧路、大楽毛(読み方わからない方は各自で調べてみてください。北海道には難読地名がゴロゴロあります。)にある釧路高専から新卒でFIXERに参りました佐藤 侑哉(さとう ゆうや)と申します!
高専での研究内容としましては、高専本科の時は旅行ルートを求めるために最適化問題と格闘し、専攻科時代は自然言語処理と機械学習を用いて、新生児の虐待の兆候を掴む研究に携わっていました!(大それたことはやっていませんが…)
研究以外に高専時代には哲学(ニーチェとか)を少しかじってみたり、そこから2次大戦時の政治体制について触れてみたり、神々をポ〇モン感覚で使役する某ゲームの影響で世界各地の神話に手を出してみたりと、広く浅く興味のあることを学んでおりました!全く高専らしくないですね。自分でもそう思います。
高専時代はクラスメイトほどは技術に触れずに他のことばかりやっていた私ですが、FIXERでは日々の業務に全力で取り組み様々な技術に触れ、好きと感じる技術を見つけていきます!(特にクラウドには全力で取り組んでいきます)どうぞよろしくお願いします!
本題。自然言語処理って?
さて、今回私が最初に執筆するブログ記事の内容は「自然言語処理って何?」です。
なぜこのテーマを選んだのかというと、先ほども申し上げました通り私が研究で使った技術がこれであるためです。技術をテーマにすると語れることがこれしかないのです…
そしてもう一つ、ここ数か月、自然言語処理技術を用いたあるサービスが世間を大きく賑わせているからです。
最近、皆さんもこのサービスの存在は一度は目にした、そうでなくとも風の噂程度には聞いたことはあるのではないでしょうか。

そうです。あのChatGPTです。
人類の現代文明を大きく変える可能性があるこのAI技術、コイツの基礎の1つには自然言語処理があります。
それ以外にも自動翻訳や予測変換など、現代には欠かせない様々なサービスになくてはならないのが自然言語処理技術です。
この記事では、そんな自然言語処理という技術の概念、基礎についてお話しする内容となっています。
最初に断っておきますが、本記事では自然言語処理の具体的な技術、手法、ライブラリには踏み込みません。
あくまでも、我々が普段何気なく文字を打ち込む裏側にはこのような技術が動いているんだ、ということをふんわりと知っていただければ幸いです。
そもそも自然言語って?
さて、この記事を少し読んでみて、「自然言語」という言葉が聞き慣れない、という方もいるかもしれません。
ここはWikipediaから引用してみることにしましょう。
自然言語(しぜんげんご、英: natural language)とは、言語学や論理学、計算機科学の専門用語で、「英語」・「中国語」・「日本語」といった「○○語」の総称。つまり普通の「言語」のこと。人間が意思疎通のために日常的に用いる言語であり、文化的背景を持っておのずから発展してきた言語。
私が特に補足するまでもなくシンプルですね。
プログラミング言語や論理式など、人間が通常の会話で話すことを目的とせずに作られた言語が「人工言語」
そうではなく、私たちが普段話す言語のすべてが「自然言語」なんですね!
自然言語処理の概要、その流れ
「自然言語」が何かわかったところで、自然言語処理とは何か、という部分に進んでいきましょう。
ここもWikipediaから引用してみましょう。
自然言語処理(しぜんげんごしょり、英語: natural language processing、略称:NLP)は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野である。
我々が使っている言語をコンピュータに処理させる技術である、と書いています。
なるほど。この記述だけを見ると、「へー!コンピュータって日本語や英語わかるんだー!」と思われる方もいるかもしれません。
ですがこれは目に見える結果として合っていても、技術的には少し違います。コンピュータは本質的に、我々が普段使っている言語を理解しているわけではありません。
コンピュータは日本語の単語の意味も、文法もわからなければ、単語の区切りがどこかすらわからないのです。
ではどのようにしてコンピュータは自然言語を理解したかのように予測変換や自動翻訳を行い、果てにはchatgptのように自然言語を操るのか。この過程は大きく4つのステップに分かれます。
- 形態素解析
- 構文解析
- 意味解析
- 文脈解析
では早速この4ステップの解説に移りたいのですが、その前に。
自然言語処理を実際に行うには、自然言語の情報が格納されたデータベースが不可欠です。(人間が親や本の言葉から言語を覚えるのと同じです。)これは「コーパス」と呼ばれます。
コンピュータ内に保存された「コーパス」には、様々な文章ごとの単語の品詞や文章の係り受けなどが、コンピュータにも理解できる形で格納されています。
コンピュータはこの「コーパス」を参照しながら、「これまでコーパスに格納されたデータを見る限りこうだろう」という感じで自然言語を読み解いていきます。
ではここからは、この4つのステップについて触れていくこととしましょう。
形態素解析
まずは形態素解析です。
早速「形態素」という聞き慣れない単語が現れました。Wikipediaで調べてみましょう。
形態素(けいたいそ、英: morpheme)とは、言語学の用語で、意味をもつ表現要素の最小単位。ある言語においてそれ以上分解したら意味をなさなくなるところまで分割して抽出された、音素のまとまりの1つ1つを指す。
ざっくりまとめると「単語」です。ひとまずそのような認識でOKです。(厳密にいうと、形態素は品詞を持つことができる最小単位です。)
形態素解析とは、文章を形態素ごとに分析し、それの品詞を特定する処理です。
では、「私は同僚と名古屋に行った」という文章を形態素解析してみましょう。
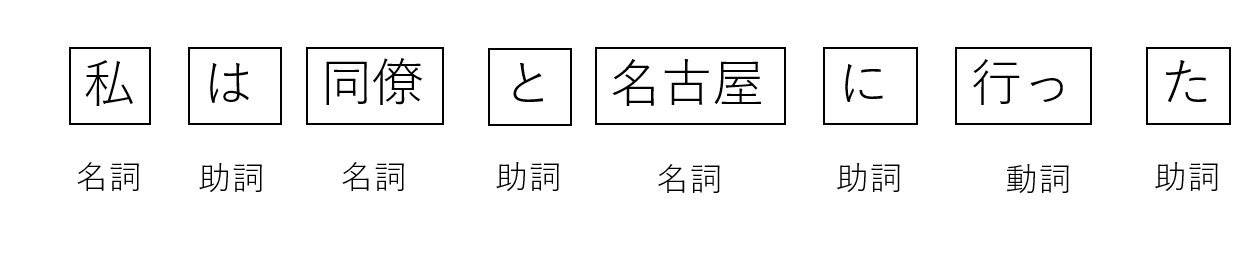
英語のように単語間に空白がある言語ならよいのですが、日本語のように空白がない(「ここではきものをぬいでください」のような言葉遊びが可能ですからね。)言語では困難を極めます。
構文解析
文章を単語ごとに区切った後には、それぞれの単語ごとのつながりをコンピュータに理解させていきます。
この構文解析では、係り受けや修飾など、単語(形態素)同士のつながりを特定する処理を行います。
日本語の場合いくつか手法はありますが、ここでは係り受けを用いた例を紹介します。
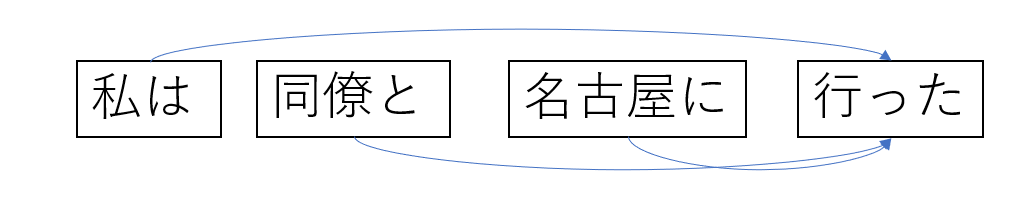
この文では、「行った」が、それ以外の単語を受けていることがわかります。
この処理を通して初めて、ある一文の中の単語ごとのつながりについてコンピュータが理解することができました。
意味解析
意味解析では、コンピュータに文章の意味について理解させます。
「いや、ここまで分かれば文章の意味ぐらい分かるのでは?」と思う人もいると思いますが、論理的にはこの文章は2つの意味にとることができます。
- 「私」と「同僚」が「名古屋」に行ったのか?
- 「私」が「同僚」と「名古屋」に行ったのか?
いや2.なわけはないだろう、とも思いますが、それは人間がこれまでの経験から予測しているだけです。
可能性がある以上、文法や日本語の知識を持たないコンピュータはどちらかを取捨選択しなければならないのです。
この意味解析では、コーパスを用いて意味を1つに絞る処理を行います。
コーパスを用いると、以下のことがわかります。
- 「私」と「同僚」は同じ「人を指す名詞」であり、関係性が高い
- 「同僚」と「名古屋」は逆に「人」と「地名」であるため、関係性が低い
このことから、「私」と関係性の高い「同僚」が同じ主語である可能性が高いことがわかるため、この文章は1.の意味であるということがわかります。
文脈解析
この1文だけの理解はもう終わりなのですが、これが複数の文章となると、複数文章の中でどのような意味を持つかということを把握する必要があります。これが文脈解析です。代名詞が誰を指しているかなどを特定します。
複数文がないため例は示せませんが、人間でも間違うことのある処理です。そのため、非常に困難を極めます。
最後に
コンピュータが自然言語を扱う過程を見てきましたが、いかがでしたでしょうか。
素人が書いたため正確ではないかもしれませんが、この記事を読んで、自然言語処理について少しでも知っていただければ幸いです。
高専時代はあまり技術に触れてこなかったため大したことは書けませんでしたが、今後は様々な技術を吸収し、定期的にブログを執筆していきたいと考えていますので、どうぞよろしくお願いします!











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
