






7月の頭に、FPSもしないのにGeforce RTX 4070を買ったので、少しでもその性能を活かすことをするGPU有効活用シリーズの第1弾。
前編で最低限の要素は満たしたので、今回は音声に関することをやっていく後編となります。
ボイチェン編
動作環境
動作環境は以下の通りです。
- Windows11
- WSL2
- Docker
- Geforce RTX 4070
ここに関してはAIとは違うような気がしますが、GPU有効活用シリーズということでお許しください。
せっかくかわいい体を手に入れたからには声もかわいいものにしたい!
てなわけでボイスチェンジャーを導入していきます。
このリポジトリを使っていきましょう。例によって環境構築はWSLとDockerで行います。
vcllientのREADME.mdにはDockerイメージのビルド手順から書いていますが、デフォルトでリモートのイメージを使うようになっているので必要ありません。
クローンしたリポジトリの直下に移動して、
- chmod u+x start_docker.sh; ./start_docker.sh
- bash start_docker.sh
のどちらかを実行します。
すると、諸々のダウンロードが始まります。しばらく待つとコンソールに
[Voice Changer] MMVC_SocketIOApp initializing... doneと表示されるのでブラウザでhttps://localhost:18888 にアクセスします。
この際に気をつけることですが、VC Client for DockerのREADME.mdでは、Chromeのみサポート と表記されています。Chromium系のブラウザ(Edge,Operaなど)であれば動作すると思いますが、FIrefoxでは動かなかったので注意してください。(1敗)
今回はこれのためだけにChromeをインストールしたくなかったので、Edgeでアクセスしています。
先ほどのリンクにアクセスすると、デフォルトではオレオレ証明書を使ったhttpsなので画像のような警告が出ます。
ローカルのDockerで動かしており、問題ないので詳細設定から localhostに進む(安全ではありません)をクリックします。
下のようなページになればひとまず成功です。
編集ボタンを押すと次のようにモデルを選ぶ画面になります。
最初は何も入ってないのでサンプルを使いましょう。
1番上のサンプルをクリックします。すると一覧が出てくるので
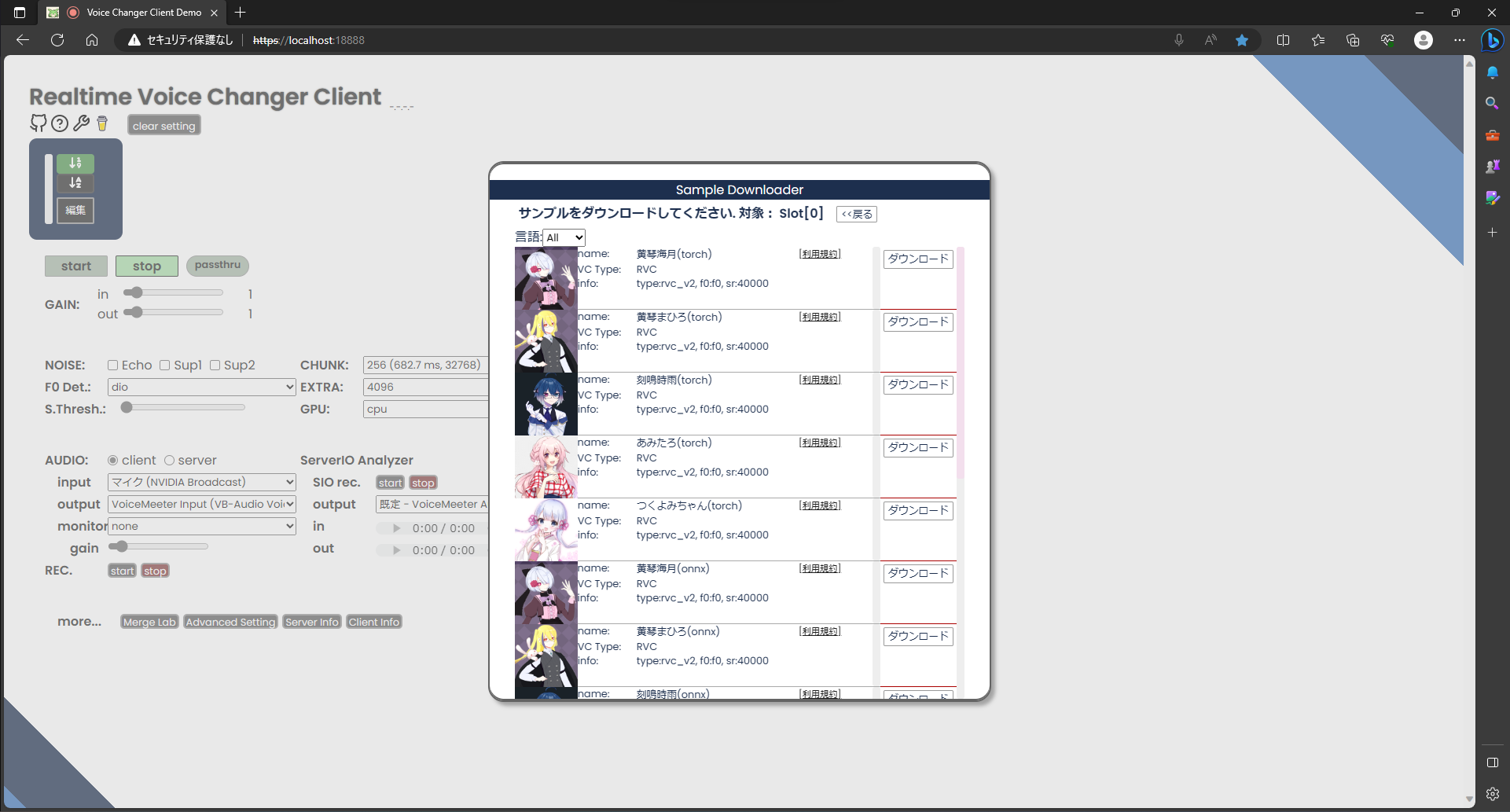
今回は試しにつくよみちゃんを使ってみましょう。つくよみちゃんのアイコンをクリックします。
モデル選択画面につくよみちゃんが追加されているのでアイコンをクリックします。
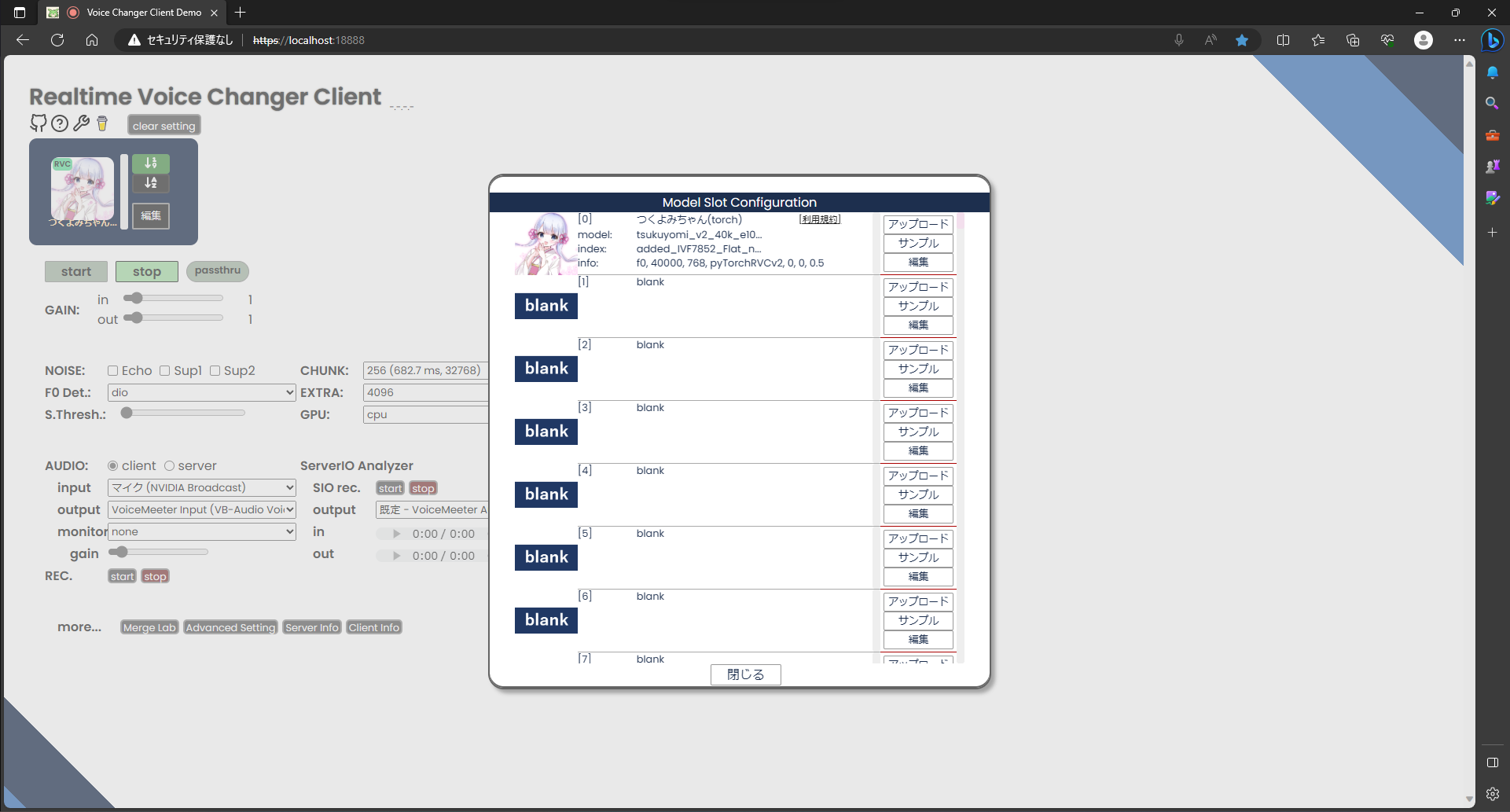
大きなアイコンとGAIN、TUNE、INDEXなどのバーが表示されたら、左下のAUDIOのInputとOutputを調整してstartを押すとボイスチェンジが始まります。
実際にやってみた動画です。
動画内でも話していますが、ちょっとクオリティが残念なことになっています。
しかし安心してください。これはRVCの本領からはかけ離れたものです。
それでは、ちゃんと設定しましょう。
今回は男性が女性の声に変換するので、TUNEの値を16~18あたりに変更します。
個人やモデルによってどの値が最適かは変わってくるのでよさげな値に頑張って調整して下さい(変更はリアルタイムで反映されます)。
TUNEを調整したバージョンがしたの動画になります。
デフォルトとは大違いにかわいい声になりました。
ネット上で配布されているものや自分で学習したモデルは、モデル選択画面でアップロードを押すと同じように追加することができます。
BGM編
ここまでで、Vの体が動く、Vの見た目にあった声が出せるまでできたわけですが、せっかくならBGMもAIの力で作ってみよう!
ということでBGM編です。ここに関してはさらっとやっていきます。
動作環境はボイチェン編と同じなので省略します。
続いて使用するリポジトリです。音楽生成のフレームワークである、MusicgenとAudiogenの2つが使えるAudiocraft_plusを使います。
このリポジトリにもDockerfileがあるのでDockerで環境構築していきましょう。
自分が使っているcompose.ymlは以下の通りです。
version: '3'
services:
audiocraft_plus:
build: .
command: python3 app.py --listen 0.0.0.0
tty: true
container_name: audiocraft_plus
working_dir: /app
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [ gpu ]
volumes:
- ./:/app
ports:
- 7860:7860
environment:
- NO_PROXY=localhost
これをリポジトリのルート(Dockerfileなどと同じ場所)に配置して
docker compose upを実行するとコンテナが起動します。To create a public link, set `share=True` in `launch()`. が表示されれば準備OKです。
Running on local URL: http://0.0.0.0:7860と表示されていますが、このアドレスではアクセスできません。http://localhost:7860でアクセスできます。
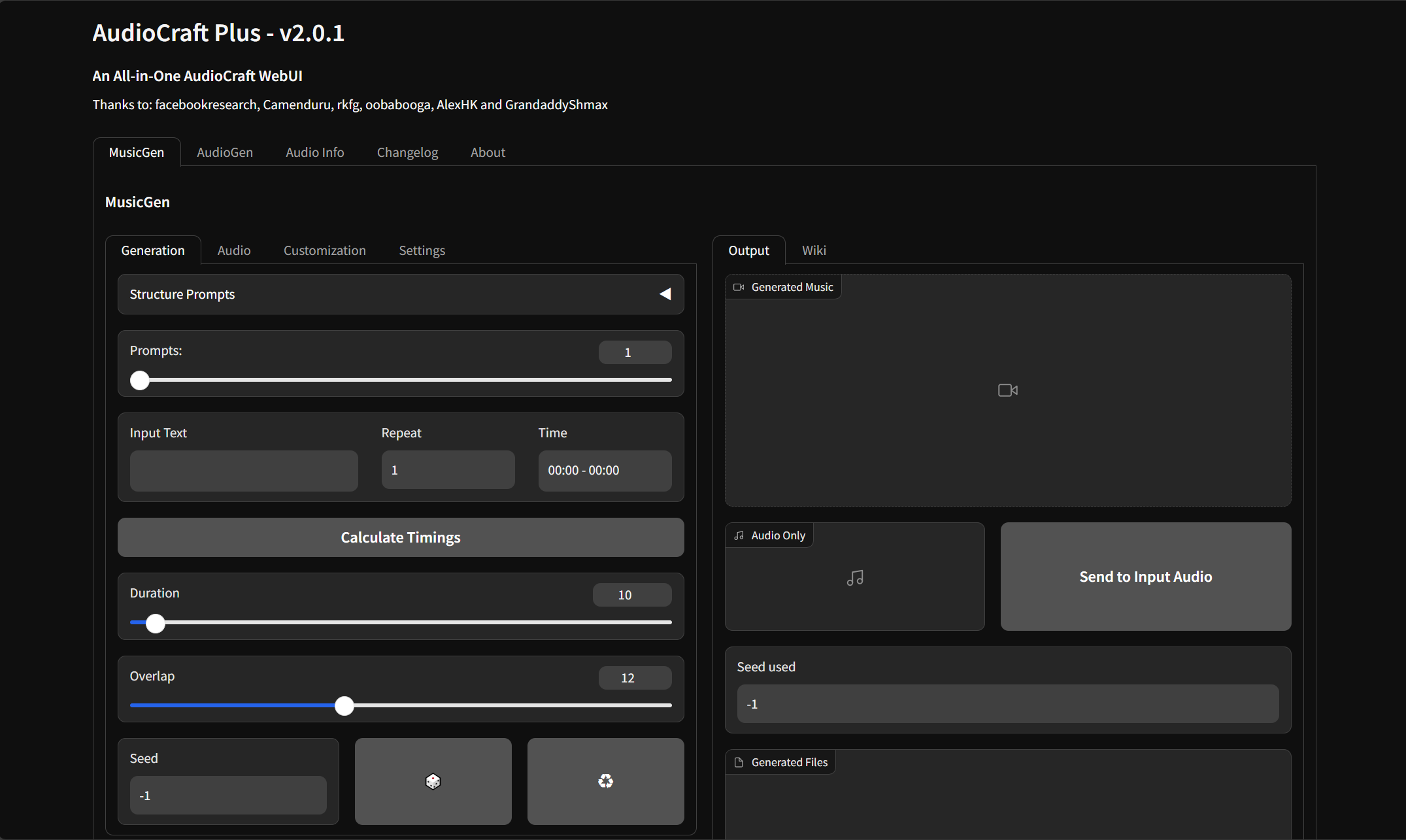
上部のタブでMusicgenとAudiogenを切り替えることができます。
どちらも基本の手順は同じで、
- Input Textにプロンプトを入力してcalculate Timingsをクリック
- Durationで生成する音声の長さを設定し、Generateをクリック
で生成することができます。
今回は両方で同じプロンプトを使って生成してみました。
Stable-diffusionと違ってあまりプロンプトのノウハウが見つからなかったのでChatGPTに適当に作ってもらいました。
使用したプロンプトは以下の通りです。
Please create a BGM with a tranquil afternoon ambiance that lasts about 300 seconds and can loop seamlessly. This music should be easy to relax to and incorporate sounds of nature and gentle musical instruments. Including sounds like bird chirping or a gentle breeze can add a more realistic atmosphere. Aim to compose a pleasing loop that listeners can enjoy listening to repeatedly.それぞれの生成結果です。
Audiogenは生成に約1500秒かかりました。
Musicgenは生成に約300秒かかりました。
初回生成時はさらにモデルのダウンロードを行うのでRTX4070といえどもかなり時間がかかりました。
さて、生成結果ですが、Musicgenの方は(プロンプトに沿ったものかどうか置いておくとして)それなりに音楽として成立しているように思えます。
一方でAudiogenではMusicgenの5倍も時間がかかったうえでちょっと聞くに堪えないものになってしまいました。
なのでBGMに関してはMusicgenの方を使うのがよさそうですね。
最後に
前編でVの体と動きを、後編で声とBGMを、AI(GPU)の力で生成することができました。
これで、(高性能のGPUさえあれば)簡単にVtuberになることができます。
ただ、1点注意する点として、ただでさえGPUをゴリゴリ使っているので、配信だけならまだしも負荷の高いゲームも一緒に起動するのはかなりしんどいのでお気を付けください。
それではGPU有効活用シリーズ第2弾でお会いしましょう。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
