






7月の頭に、FPSもしないのにGeforce RTX 4070を買ったので、少しでもその性能を活かすことをするGPU有効活用シリーズの第1弾。
イラストも描けない、Live2Dなんてもっとできない自分がAIの力を最大限に活用していわゆるバ美肉してみようというブログです。
今回は、Vtuberとして最低限の要素(体があって、動かせる)を満たす前編となります。
後編は動作検証がまだできてないのでしばらくお待ちください こちら。
イラスト編
なにはともあれ、まずは体を用意しなければ何も始まりません。
イラスト生成といえばこれ!なStable-Diffusionを使います。
動作環境
動作環境は以下の通りです。
- Windows11
- WSL2
- Docker
- Geforce RTX 4070
はい、Dockerで動かします。ということでStable-DiffusionをDockerで動かせるようにしたリポジトリをクローンしてきましょう。
LIve2Dできないんじゃね?と思う方。ご安心ください。このあと動かす編でどうにかします。
動作準備
こちらのリポジトリを使えば簡単に起動できます。リンク先のwikiタブにあるSetupの通りに実行していきます。
2回目のdocker compose --profileではautoを選択します。
最初は2つのモデルがデフォルトでダウンロードされますが、今回は別のモデルを使用します。
使用するモデルはこちらのリポジトリにあるShiratakiMix-add-VAE.safetensorsです。
2D風の画風に特化したマージモデルです。
と紹介されています。
ダウンロードしたら、リポジトリのdata/models/Stable-Diffusonに配置します。
左上にある青いリサイクルマークみたいなボタンを押すとモデル一覧がリロードされるので、先ほどダウンロードしたShiratakiMix-add-VAE.safetensorsを選択します。
各種設定
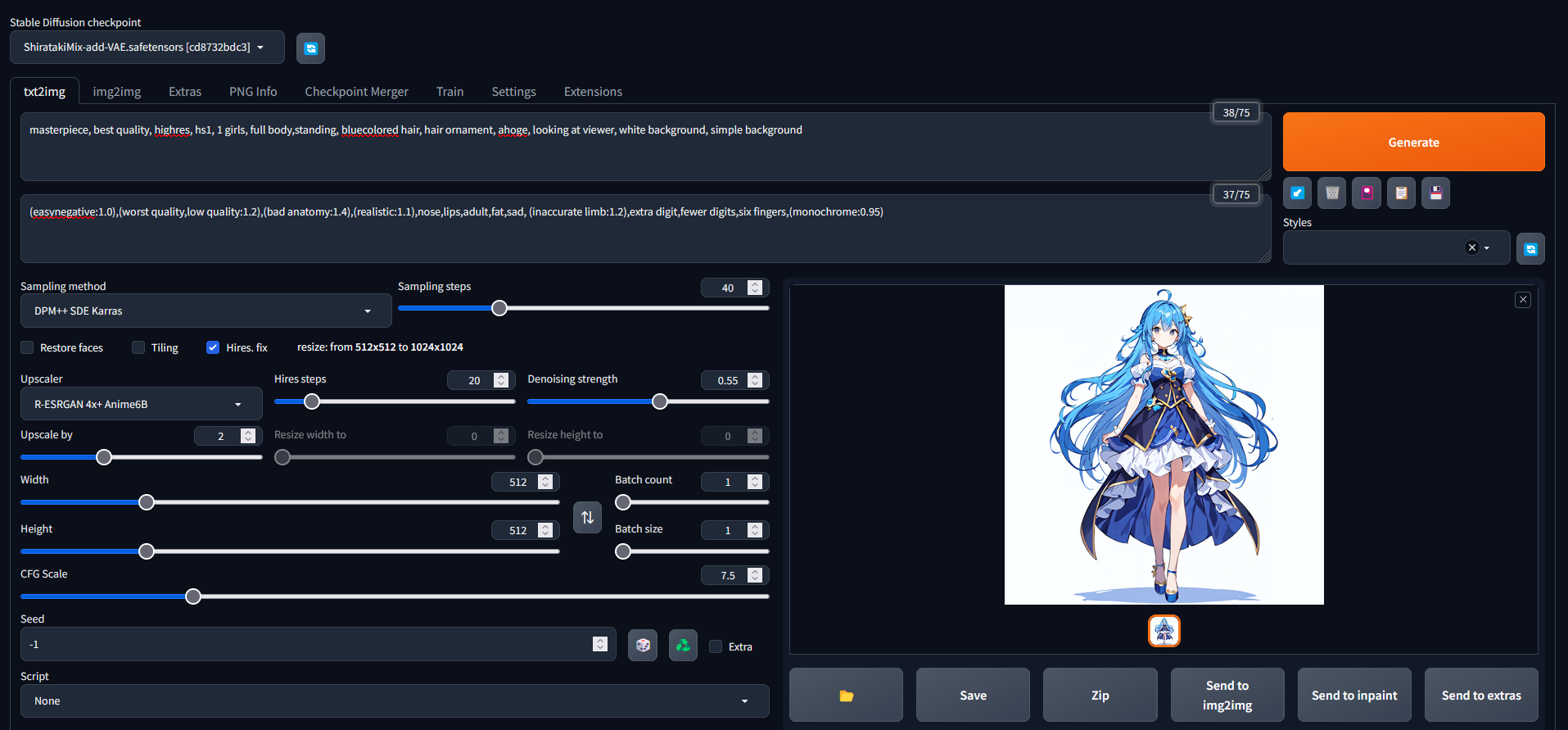
では、ここからは呪文のお時間です。いろんなところを見ながら割と適当にやったのでたぶんもっといいプロンプトもあると思います。
masterpiece, best quality, highres, hs1, 1 girls, full body,standing, bluecolored hair, hair ornament, ahoge, looking at viewer, white background, simple background続いてネガティブプロンプトやSteps数などの設定です。これらはモデルの配布元が推奨設定を出していたので、そのまま流用しましした。
ネガティブプロンプト
Negative prompt: (easynegative:1.0),(worst quality,low quality:1.2),(bad anatomy:1.4),(realistic:1.1),nose,lips,adult,fat,sad, (inaccurate limb:1.2),extra digit,fewer digits,six fingers,(monochrome:0.95)その他設定
Steps: 40, Sampler: DPM++ SDE Karras, CFG scale: 7.5, Seed: 2439170984, Size: 512x512, Model hash: cd8732bdc3, Model: ShiratakiMix-add-VAE, Denoising strength: 0.55, Hires upscale: 2, Hires steps: 20, Hires upscaler: R-ESRGAN 4x+ Anime6B, Version: v1.5.1このような画像が出力されました。

背景透過編
これで体が用意できたので、動かして(フェイストラッキングして)いきます。
が、その前に背景が邪魔なので透過します。
適当な背景透過サイトを使ってもいいのですが、今回はGPU有効活用シリーズなのでローカルで、rembgというツールを使用します。
リポジトリのREADME.meにdockerを使う場合の例があるのでそれを使いましょう
docker run danielgatis/rembg i path/to/input.png path/to/output.pngで背景透過します。
実行結果は以下の通りです。

このブログ書いてるときにStable-Diffusionの拡張機能にrembgがあることを知ったので、もし真似する人がいたら背景透過は拡張機能でやった方が楽だと思います。
最後にデフォルトだと1024×1024なので上半身が見えるように512×512にリサイズして準備完了です。
動かす編
さて、背景透過もできたのでこんどこそいよいよフェイストラッキングです。
パーツ分けも何もしていないイラストですが、これを動かす技術があります。
最近のテクノロジーはすごいですね。
動作環境
- Windows11
- Python3.10
- Geforce RTX 4070
動かす編ではDockerは使いません。最初はDockerでやろうとしたのですが、どうも動作が不安定でよくウインドウがフリーズしたのでホストマシンで動かすことにしました。
というわけでiFacialMocap Powered by NVIDIA Broadcast(以下iFacialMocapと表記)とtalking-head-anime-3-demo(以下talking-head-animeと表記)を使います。
前者は普通のWebカメラでフェイストラッキングするためのソフトウェアで、後者はトラッキングの情報をもとにただのイラストを動かせるようにするプログラムです。
iFacialMocapは有料ソフトですが、8月いっぱいはMicrsoft Storeで無料で入手できるので使うかもしれない人は今のうちにダウンロードしておくと吉でしょう。
では、それぞれを実行する準備をしてきます。
iFacialMocapは前提条件としてNvidia AR SDKが必要です。リンク先から自分のGPUにあったもの(今回はRTX40シリーズ)をダウンロードしてインストールします。
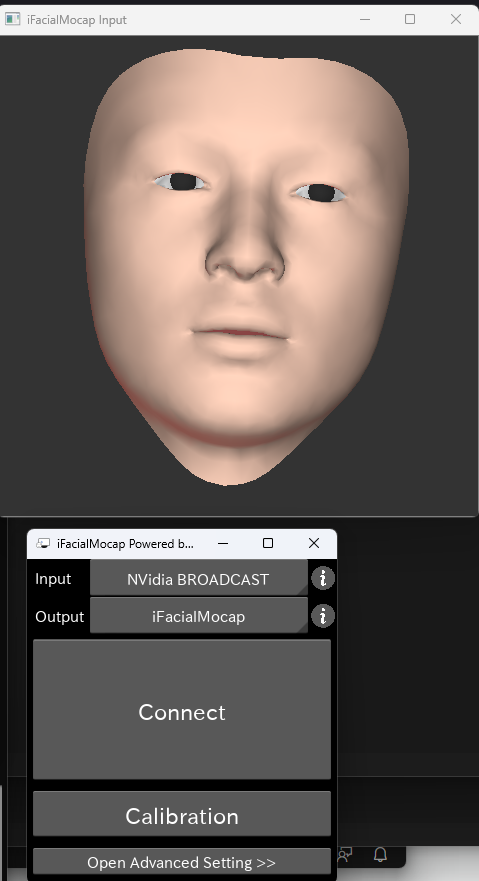
インストールできたらiFacialMocapを起動します。すると以下のような2つのウインドウが立ち上がるのでInputがNVdia BROADCAST、OutputがiFacialMocapになっていることを確認してConnectをクリックします。
続いて、talking-head-animeを実行します。
pipで以下のライブラリをインストールして
- Python >= 3.8
- PyTorch >= 1.11.0 with CUDA support
- SciPY >= 1.7.3
- wxPython >= 4.1.1
- Matplotlib >= 3.5.1
python tha3/app/ifacialmocap_puppeteer.py を実行します。
するとこの画像のようなウインドウが立ち上がるので
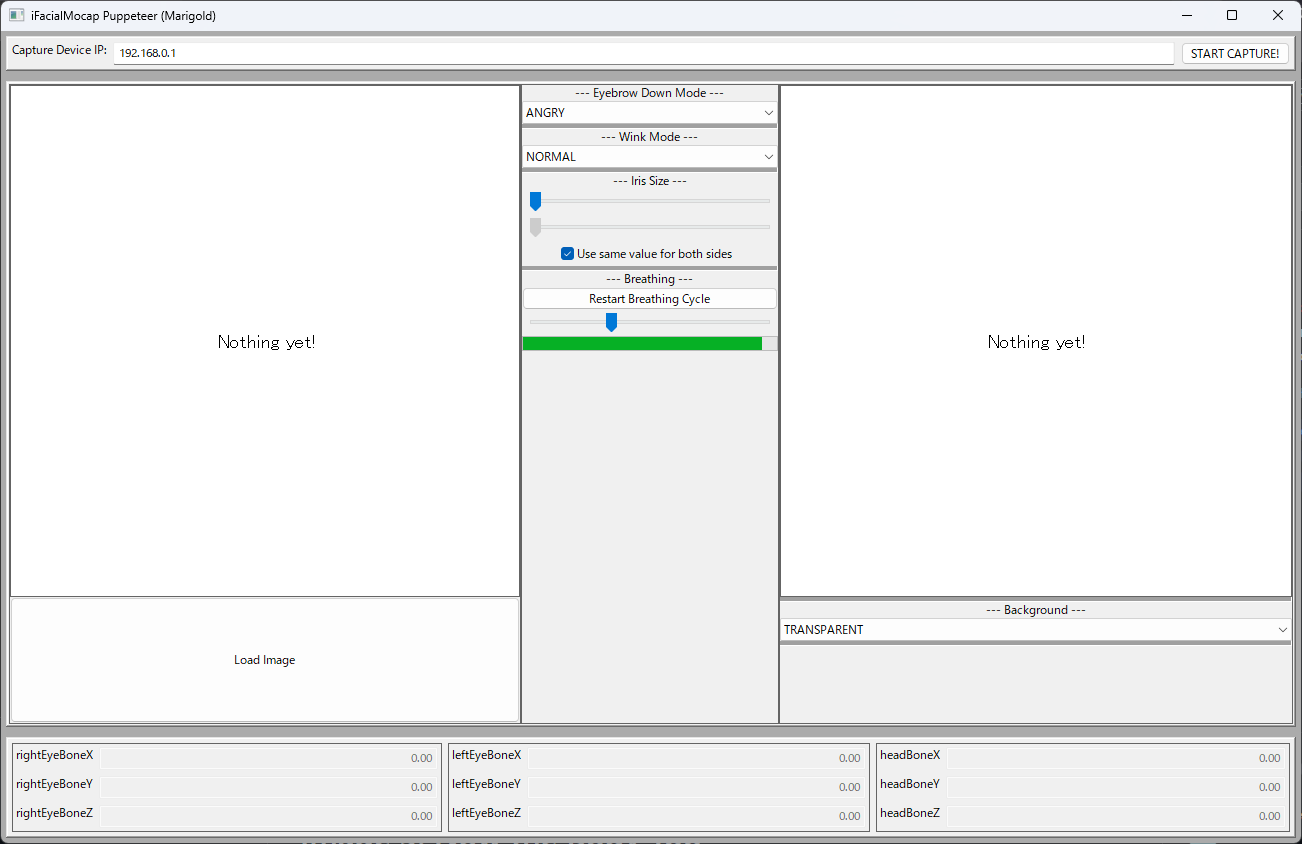
- 上のCapture device IPを127.0.0.1にして"START CAPTURE!"をクリック
- 左下のLoad Imageをクリックして先ほど背景透過、リサイズした画像を選択
これで無事Stable-Diffusionで生成したイラストを動かすことができました。
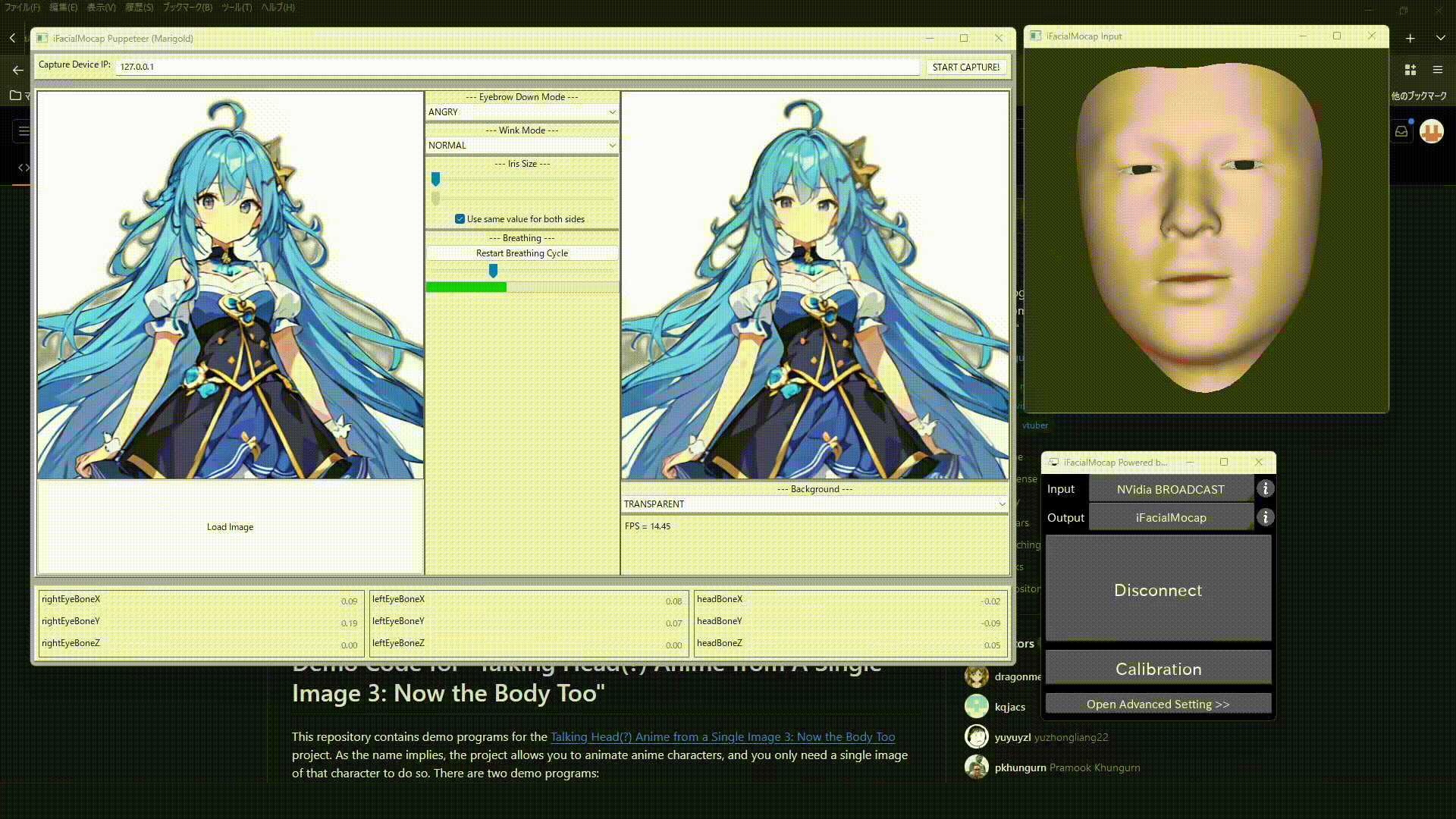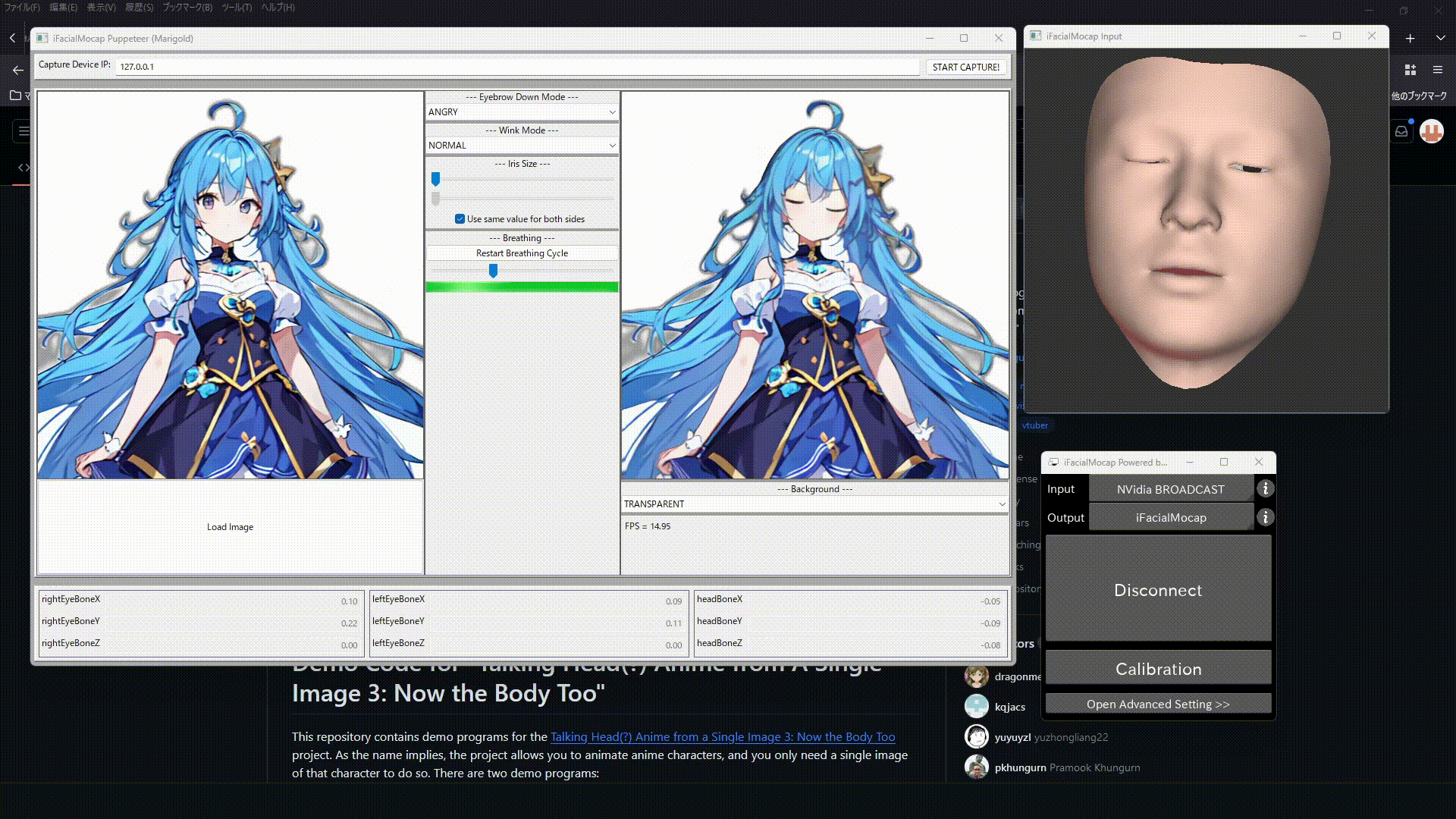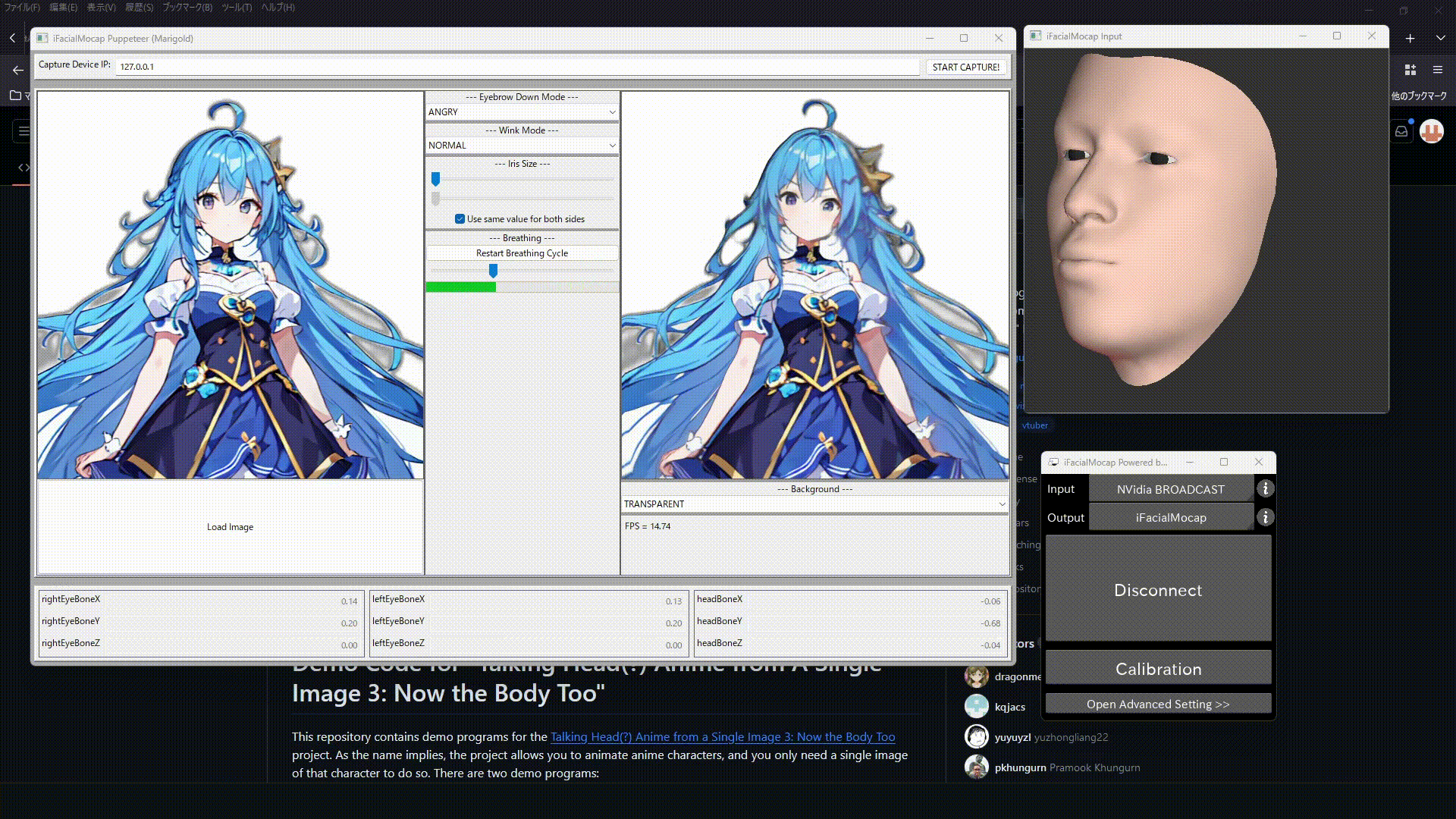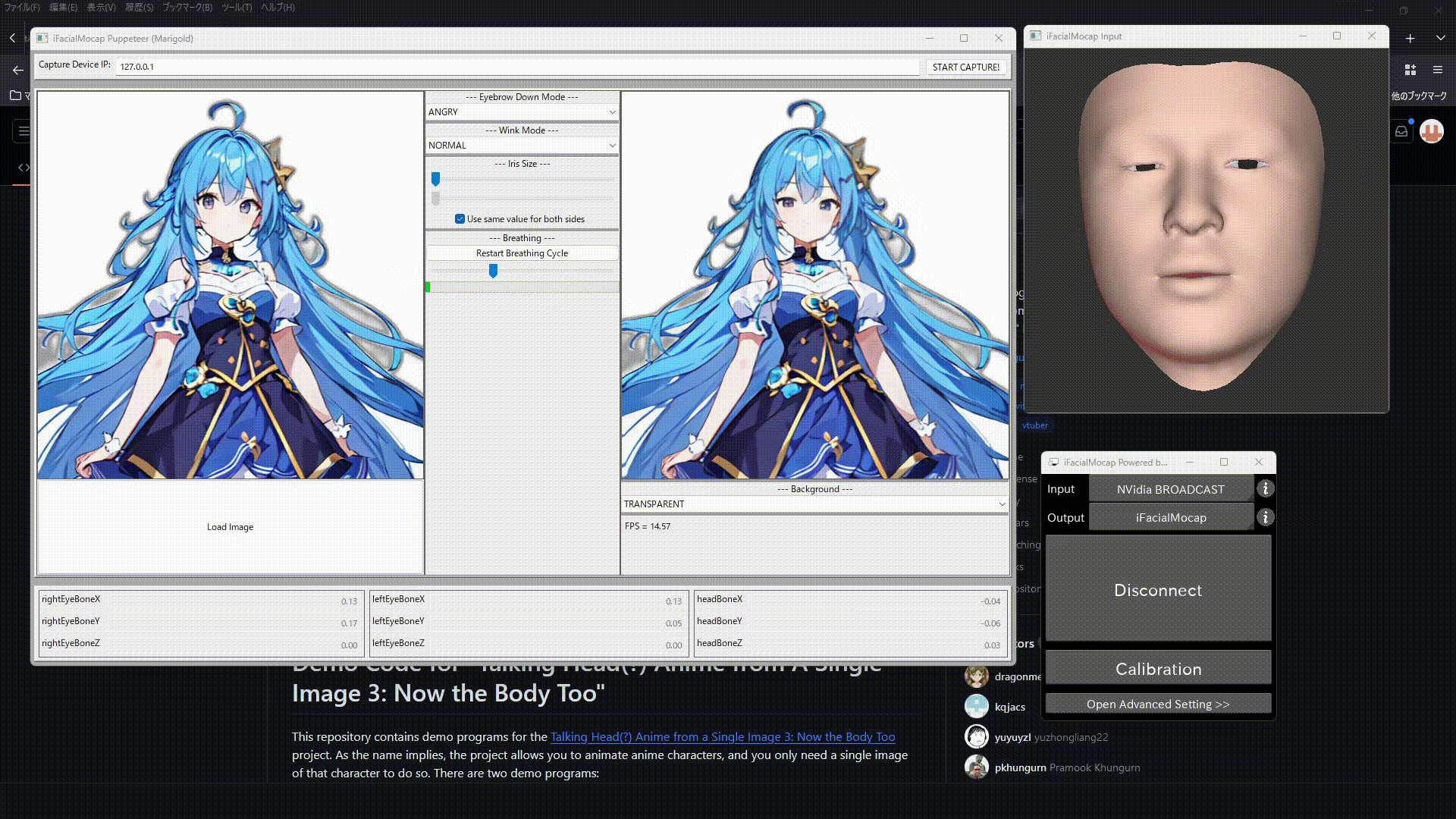
最後に
AIの力によってまったくイラストが描けない人間でも最低限Vtuberになれる要素がそろいました。
この後は、声をVの体にあうようなものに変えたり(ボイスチェンジャー)、BGMを作ったり(Text to Music)を予定しています。
それではまた、後編でお会いしましょう。











![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
