


 2026-05-15
2026-05-15


1. はじめに
GitHub Copilot、Notion AI——エンジニアであれば一度は耳にしたことがあるAIエージェント。日常的に活用しながらも、その内部的な動作まで深く意識する機会は、意外と少ないのではないでしょうか。
今回、4月末にAWSのエンジニアの方が開催されたハンズオンに参加し、実際にAIエージェントを作る貴重な体験をさせていただきました。本記事では、その内容から1歩踏み込んだものをご紹介します。
今回の記事は、下記の資料をもとに作成しています。
AWSでAIエージェント構築に入門! StrandsをAgentCoreにデプロイしてみよう
2. AIエージェントの動作
上記のハンズオンで作成した、AIエージェントに「本日のニュースを教えて」と入力した際の動作を確認していきます。

入力を行うと下の画像の通りにニュースをまとめ始めます。


最終的には上記のようにニュースを短くまとめて出力されます。
3. セッションの確認方法
- 検索欄に、Amazon Bedrock AgentCoreを入力します。
- Amazon Bedrock AgentCoreをクリックすると上記の画面が表示されます。
- 「オブザーバビリティ」をクリックします。
 |  |
- Bedrock AgentCore オブザーバビリティの下にある「すべての機能」をクリックします。
- セッション一覧から確認をしたい「セッションID」をクリックします。
- トレース一覧から確認したい「トレースID」をクリックします。
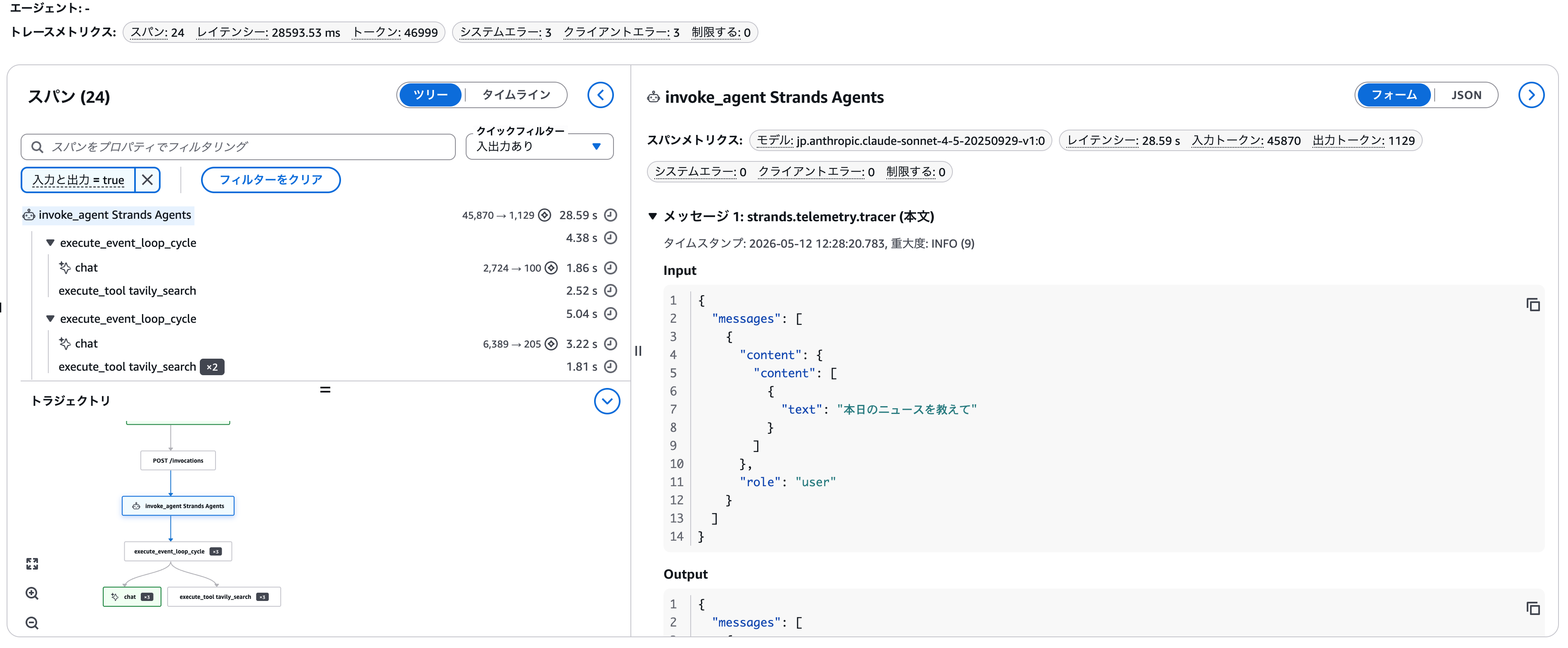
任意のセッションの任意のトレースが確認できます。
4. トラジェクトリの各項目解説
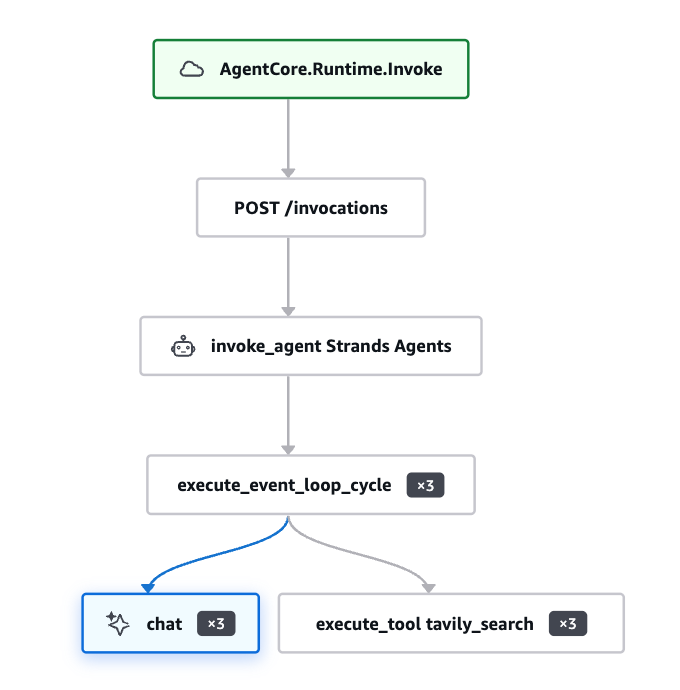
開いていただくと上記のような画面が表示され、左下に上記の画像と同じものが確認できます。
今回説明していくのは、左下のトラジェクトリとそれに対応する右側の詳細についてです。
まず、トラジェクトリに表示されている各項目の意味を説明します。
| 項目 | 意味 | 実際にやっていること |
|---|---|---|
| AgentCore.Runtime.Invoke | AgentCore Runtime を呼び出す | AWS Bedrock AgentCore 上でエージェント実行を開始し、Runtime環境を立ち上げる |
| POST /invocations | 実行APIへHTTP POST送信 | ユーザー入力(JSONメッセージ)を Runtime に送信する |
| invoke_agent Strands Agents | Strands Agent を起動 | エージェント全体を制御し、Claudeやツール利用の流れを管理する |
| execute_event_loop_cycle | Agent思考ループを1周実行 | 「考える → ツール必要判断 → 実行 → 再判断」を1サイクル処理する |
| chat | LLM(Chat Model)を実行 | Claudeへ入力を送り、推論・回答生成・検索必要判断を行う |
| execute_tool tavily_search | Tavily検索ツールを実行 | Tavily APIへ検索クエリを送り、Web検索結果を取得する |
4-1. AgentCore.Runtime.Invoke
AWS Bedrock AgentCore Runtime に「このAIエージェント処理を開始してください」と伝える、初期設定のようなものです。
具体的には以下のことを行っています。
- Runtime環境の立ち上げ:エージェントが動作するための実行環境を準備します
- エージェントの初期化:今回使用するエージェントの設定や権限の確認を行います
- 処理の受け付け開始:ユーザーからの入力を受け取れる状態にします
イメージとしてはアプリを起動したときに裏側で行われる準備処理に近いものです。
4-2. POST /invocations
今回だと以下の入力を送信して実行を要求しています。
Python{
"messages": [
{
"role": "user",
"content": "本日のニュースを教えて"
}
]
}- role : メッセージの送信者を表します。
userの場合はユーザーからの入力であることを示します - content : 実際にユーザーが入力したテキストです
この形式でメッセージを送ることでAgentCoreが「誰が」「何を」送ったのかを正確に把握できるようになっています。
またこの形式はChatGPTやClaudeなどの多くのLLMで共通して使われている形式です。
4-3. invoke_agent Strands Agents
POST /invocationsで入力を受け取ったあと、AIエージェントの思考が始まります。
ここではStrands Agentsが今回の場合だとClaudeを利用して思考、Tavilyによる検索、思考のループなどを行っています。
4-4. execute_event_loop_cycle
1つのサイクルでは以下のことを実行します。
- Claudeに考えさせる
- Tool必要か判断
- Tool実行
- 結果を見る
- 次どうするか決める
ここでexecute_event_loop_cycleに表示されているx3の意味を説明します。
Strands Agentによって先ほど入力された内容がまず1回思考されます。
その結果Strands Agentは検索結果をまとめたものを見て1回の検索では情報が不足していることを判断しました。その結果再度思考を実行して結果のクオリティを上げています。このループこそがAIエージェントの中核と言っても過言ではありません。
4-5. Chat
Python{
"messages": [
{
"role": "user",
"content": "本日のニュースを教えて"
}
]
}上記のJSONがAgent CoreからClaudeに送られ、どう処理すべきかが問われます。
そうするとClaudeは
- 意味理解
- 推論
- 検索必要判断
- 回答生成
先ほどのサイクルだと4-4のサイクルにおける1.2.4.5のステップを実施しています。
今回ですと検索必要判断において最新のニュースという部分からモデル知識では限界があることを判断してTavilyに投げる判断をしています。またここで検索する際のクエリを作成しています。
4-6. execute_tool tavily_search
ここではClaudeが作成したクエリをPOSTし、複数のニュースサイトの情報を取得して返却しています。その結果として、先ほどのchatを確認すると
Python"gen_ai.usage.input_tokens": 36757,Claudeに渡された情報量が多いことを表しています。
ここだけ聞くと大きいことは分かりますが、あまりピンとこないかと思いますので補足しますと、ざっくり日本語では1トークン=1文字前後になります。
| 例 | おおよその量 |
|---|---|
| 短いチャット1往復 | 100〜500 tokens |
| 長めのブログ記事1本 | 2,000〜5,000 tokens |
| 小説1章 | 5,000〜10,000 tokens |
| 技術記事10本分 | 30,000〜50,000 tokens |
| 文庫本1冊 | 100,000〜150,000 tokens |
こうみると情報量が圧倒的に多いことが分かります。
Tavilyから返された検索結果をClaudeが確認した結果、情報がまだ不足していると判断し、追加で2回の検索が行われました。
その後、十分な情報が揃った時点でClaudeが最終回答を作成し、出力につながります。
5. 処理の全体フロー
ここまでの処理を整理すると以下のような流れになります。
PythonUser
↓
POST /invocations
↓
invoke_agent
↓
event_loop_cycle #1
↓
chat(Claude)
↓
検索必要判断
↓
execute_tool tavily_search
↓
MCP通信
↓
Tavily検索
↓
検索結果
↓
chat(Claude)
↓
追加検索判断
↓
execute_tool tavily_search
↓
検索結果統合
↓
最終回答生成
↓
レスポンス返却6. 補足 +α
今回の処理にはTavilyが使われましたが、質問の内容によっては追加検索が必要のないものがあります。
その際はトラジェクトリが一部変わってきます。内容的には減っているだけですので、今回紹介した内容だけで動作を追うことができます。
よければご自身で試して違いを探してみてください。本記事で補完できなかった部分まで、理解を深めていただけると思います。










![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
