


 2026-05-29
2026-05-29
目次

- はじめに
- AIエージェントとは何か?
- 生成AIの進化の歴史
- エージェントの本質:Plan → Action → Feedback のループ
- エージェントとワークフローの違い
- エージェントを支える技術
- 1. Reasoning / Chain of Thought(CoT)
- 2. Tool Use / Function Calling
- 3. ReAct(Reasoning + Acting)
- 4. MCP(Model Context Protocol)
- 主要なエージェント開発フレームワーク
- Strands Agentsのコード例
- AIコーディングエージェントの進化
- Level 1:プログラムによる補完
- Level 2:インラインAI補完
- Level 3:自律的なエージェントコーディング
- Level 4:長期・並列・マルチエージェント
- Amazon Bedrock AgentCoreとは
- AgentCoreのコンポーネント
- AgentCore Managed Harness(Preview)
- エージェント開発のライフサイクル
- Step 1:要件定義
- Step 2:PoC(概念実証)
- Step 3:プロダクション化
- Step 4:運用と改善
- エージェントの評価方法
- 【実践】Strands AgentsでAIエージェントを作ってみよう
- 事前準備
- ステップ1:まず3行でエージェントを動かす
- ステップ2:Web検索ツールを持たせてみる
- ステップ3:MCPサーバーのツールを借りる
- ステップ4:マルチエージェントに挑戦
- 【実践】AgentCoreにデプロイしてみよう
- AgentCore SDK でエージェントをAPIサーバー化
- スターターツールキットでデプロイ
- Streamlitでフロントエンドを作成して動作確認
- 運用監視:AgentCoreオブザーバビリティ
- まとめ
目次
- はじめに:生成AIの進化とAIエージェントの登場
- AIエージェントとは何か?
- エージェントを支える技術:Reasoning・Tool Use・ReAct・MCP
- 主要なエージェント開発フレームワーク
- AIコーディングエージェントの進化
- Amazon Bedrock AgentCoreとは
- エージェント開発のライフサイクル
- 【実践】Strands AgentsでAIエージェントを作ってみよう
- 【実践】AgentCoreにデプロイしてみよう
- まとめ
はじめに
2025年、生成AIの世界で最も注目されているキーワードが「AIエージェント」です。ChatGPTが世間を席巻した2022年末からわずか数年で、AIは「質問に答えるアシスタント」から「自律的にタスクを実行するエージェント」へと急速に進化しています。
本記事では、社内で開催された「AWSによるAIエージェント開発入門ワークショップ」の内容をもとに、AIエージェントの基本的な考え方から、Strandsを用いた実装、AWS上へのデプロイまでの流れを解説します。
AIエージェントとは何か?
生成AIの進化の歴史
AIエージェントを理解するには、生成AIがどのように進化してきたかを振り返ることが重要です。
| 時期 | 技術 | 概要 |
|---|---|---|
| 〜2022年 | 言語モデル(LLM) | テキスト生成・理解の基盤 |
| 2022〜2023年 | RAG(検索拡張生成) | 外部知識を参照して回答精度を向上 |
| 2023〜2024年 | Tool Use / Function Calling | 外部ツールを呼び出せるようになる |
| 2024〜2025年 | 推論モデル(Reasoning Models) | 複雑な問題解決、計画、多段推論が向上 |
| 2025年〜 | AIエージェント | 自律的にタスクを計画・実行 |
エージェントの本質:Plan → Action → Feedback のループ
AIエージェントの核心は、次の3つのステップを繰り返す自律的なループにあります。
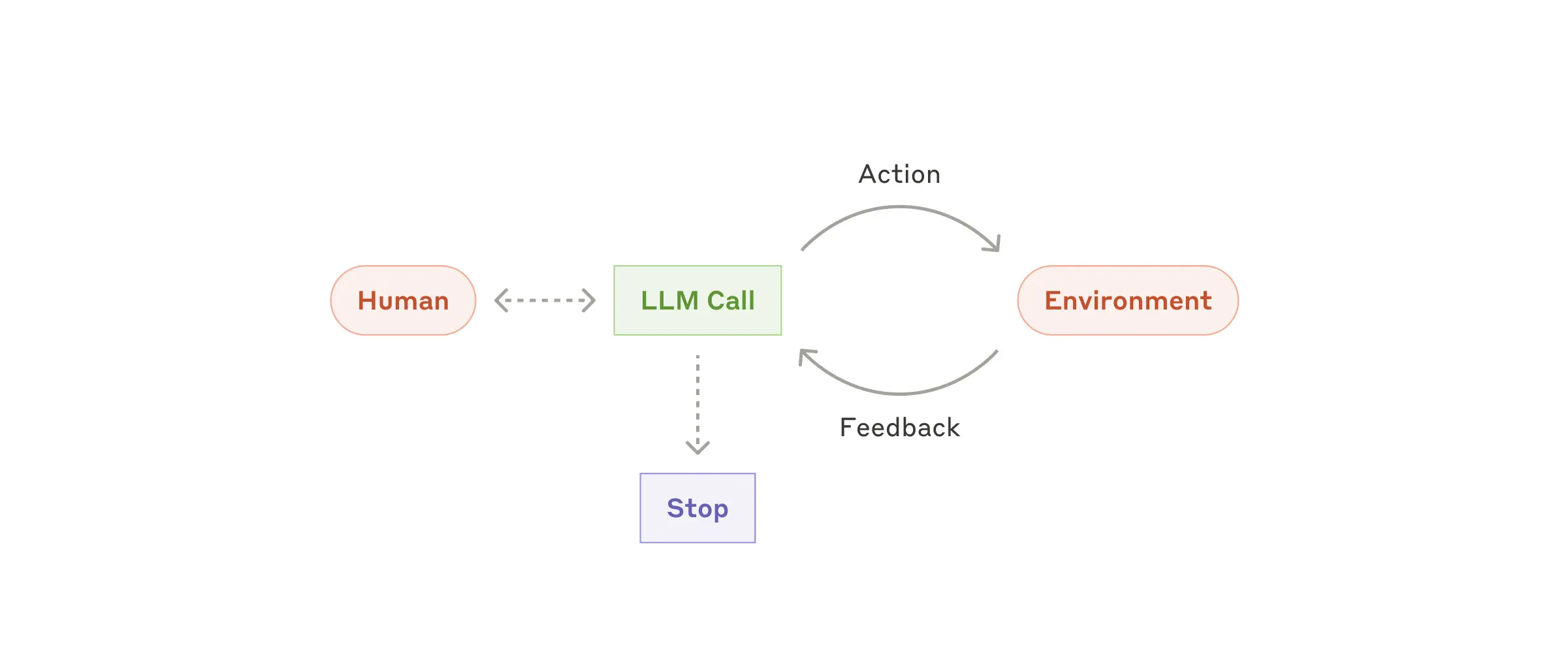
引用元:https://www.anthropic.com/engineering/building-effective-agents
- Plan(計画):目標を達成するために何をすべきかを考える
- Action(行動):ツールを呼び出したり、コードを実行したりする
- Feedback(観察):実行結果を受け取り、次のアクションに活かす
このループを繰り返すことで、エージェントは複雑なタスクを段階的に解決していきます。
エージェントとワークフローの違い
よく混同されますが、エージェントとワークフローは明確に異なります。
- ワークフロー(Workflow):人間があらかじめ定義したフローに従ってLLMが動作する(決定論的)
- エージェント(Agent):LLM自身が動的に判断を下し、次のアクションを決定する(非決定論的)
ワークフローは予測可能で安定している反面、柔軟性に欠けます。エージェントは自律性が高い分、予期しない動作をする可能性もあります。用途に応じて使い分けることが重要です。
エージェントを支える技術
1. Reasoning / Chain of Thought(CoT)
Reasoning(推論)とは、LLMに「答えを出す前に、思考過程を言語化させる」技術です。
たとえば、「9.11と9.9はどちらが大きい?」という質問に対して、単純に答えを出すだけでなく「整数部分は同じ9。小数点以下を比べると、9.11は0.11、9.9は0.90なので9.9の方が大きい」と考えさせることで、精度が劇的に向上します。
Chain of Thought(CoT)はこの手法を系統的に活用するアプローチで、複雑な数学の問題や論理パズルなど、ステップバイステップの思考が必要なタスクで特に効果を発揮します。
2. Tool Use / Function Calling
LLMは本来、学習データに含まれる知識しか持ちません。しかしFunction Calling(ツール使用)の仕組みを使うことで、LLMは外部ツールを呼び出してリアルタイムの情報や外部サービスの機能を活用できるようになります。
// ツール定義の例
{
"name": "get_stock_price",
"description": "指定した株式のティッカーシンボルの株価を取得します",
"parameters": {
"type": "object",
"properties": {
"ticker": {
"type": "string",
"description": "株式のティッカーシンボル(例:AMZN)"
}
},
"required": ["ticker"]
}
}LLMはこのスキーマを見て、「株価が必要な場面ではこのツールを呼び出せばよい」と判断し、適切な引数を生成してツールを実行します。
[Tool Use の流れ]
- LLM にタスクとツールの説明や使い方を渡す
- LLM がツールの利用を判断し、ツール実行クエリを渡す
- ツールが実行されて(ツール実行のための仕組みが別で必要)、結果が返る
- 結果を LLM に渡す
3. ReAct(Reasoning + Acting)
2023年のICLR論文で提案されたReActフレームワークは、「推論(Reasoning)」と「行動(Acting)」を組み合わせたアプローチです。
エージェントは次のサイクルで動作します:
- Thought(思考):「現在の状況から、次に何をすべきか?」
- Action(行動):ツールを呼び出す
- Observation(観察):ツールの実行結果を受け取る
- Thought → Action → Observation → ... を繰り返す
このサイクルにより、エージェントは環境から情報を取得しながら柔軟にタスクを進めることができます。
4. MCP(Model Context Protocol)
2024年11月にAnthropicがオープンソースとして公開したMCP(Model Context Protocol)は、AIとツールを繋ぐための統一規格です。
よく「AIツール接続のUSB Type-C」と例えられます。これまでAIと各種サービスを繋ぐには、それぞれ個別の実装が必要でした。MCPが登場したことで、一度MCP対応のサーバーを作れば、あらゆるMCP対応クライアント(Claude、Cursor、その他のAIツール)から利用できるようになります。
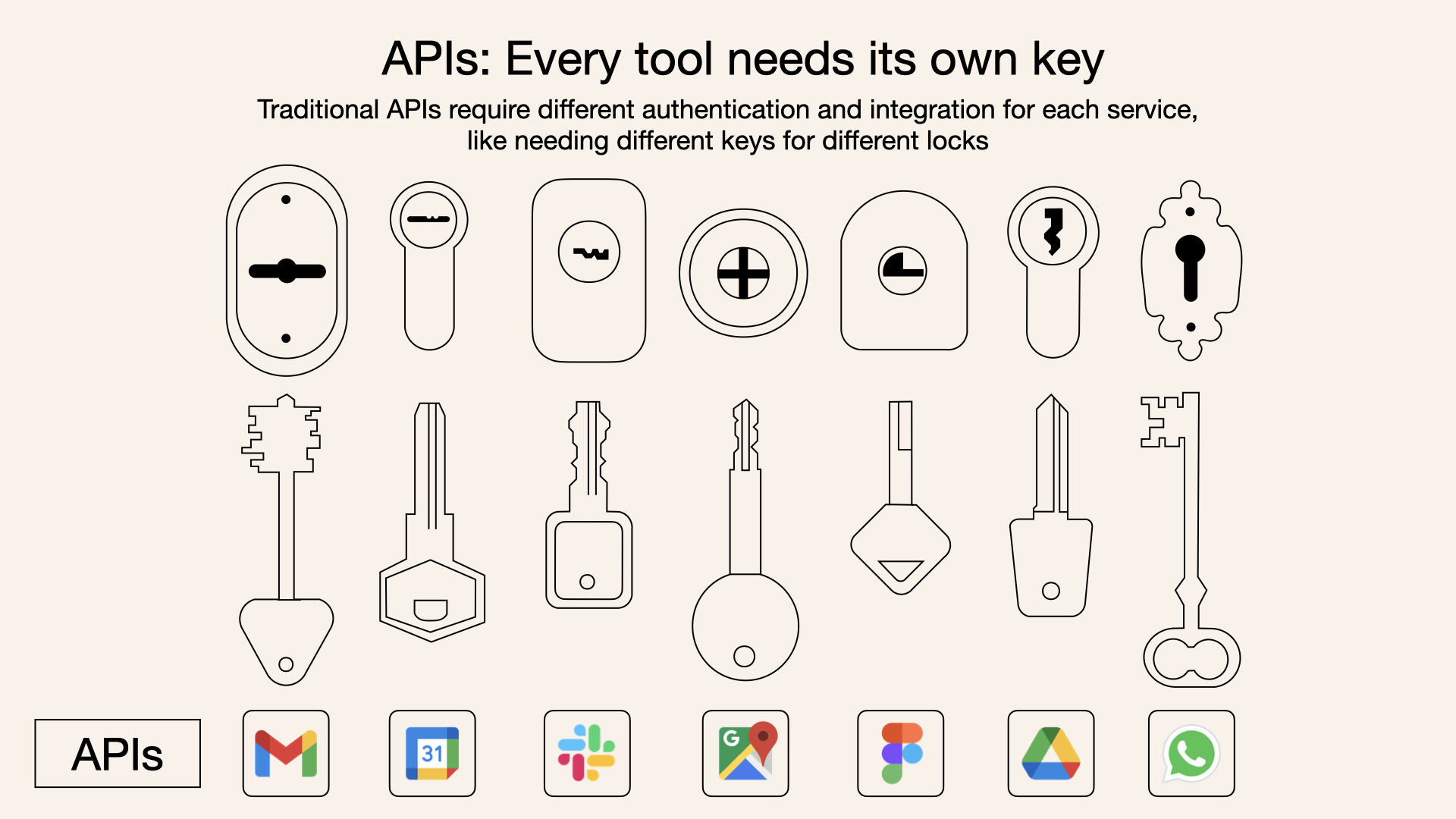
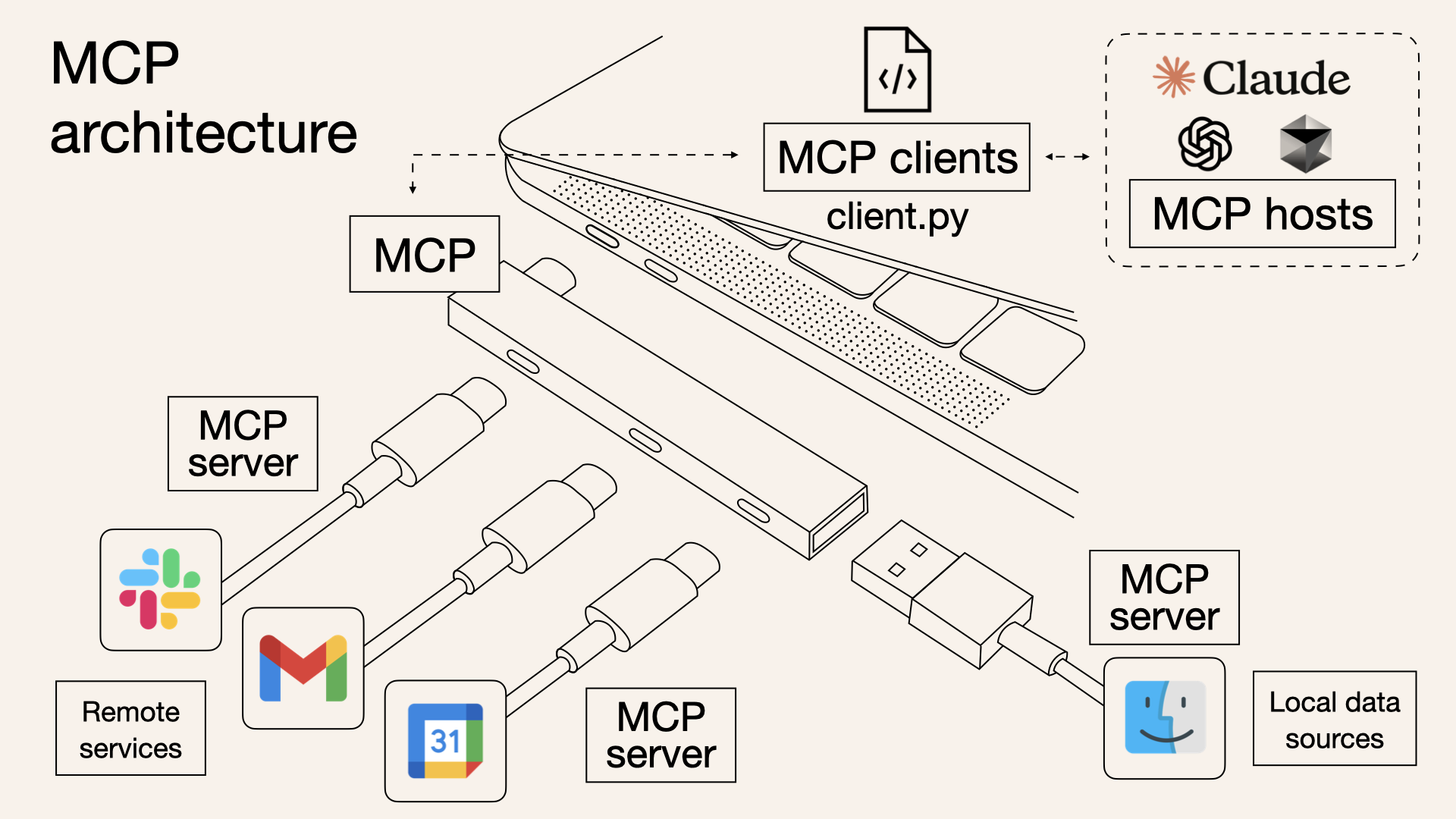
引用元:https://norahsakal.com/blog/mcp-vs-api-model-context-protocol-explained/
MCPの登場により、エコシステム全体でツールの再利用性が劇的に向上しました。
主要なエージェント開発フレームワーク
2025年現在、エージェント開発のためのフレームワークは急増しています。代表的なものを整理しました。
| フレームワーク | 提供元 | 特徴 |
|---|---|---|
| Strands Agents | AWS(OSS) | シンプルなAPIで短いコードから始められる |
| LangGraph | LangChain | グラフベースの柔軟なワークフロー定義 |
| OpenAI Agents SDK | OpenAI | OpenAIモデルとの親和性が高い |
| Claude Agent SDK | Anthropic | Claudeとの深い統合 |
| Google ADK | Geminiモデルとの連携 | |
| Microsoft AutoGen | Microsoft | マルチエージェント会話の設計に強み |
Strands Agentsのコード例
AWSがオープンソースで公開したStrands Agentsは、最小限のコードからエージェントを作れるシンプルさが特徴です。
最もシンプルなエージェント:
Pythonfrom strands import Agent
agent = Agent() agent("何か面白いことを言って!")システムプロンプトを設定したエージェント:
Pythonagent = Agent( model=model, system_prompt="""
あなたは AcmeCorp 社の出張予約エージェントです。
従業員が会社のポリシーに準拠した出張を予約できるよう支援してください。
""", ) agent("あなたは何ができますか?")カスタムツールを追加する:
Pythonfrom strands import Agent, tool
@tool def sum(a: int, b: int) -> int: """Adds two numbers.
Args:
a: first number
b: second number
""" return a + b
agent = Agent(tools=[sum])@tool デコレータをつけるだけで、Pythonの関数をエージェントが使えるツールとして登録できます。型ヒントとdocstringから自動的にJSONスキーマが生成されるため、追加の設定が不要です。
AIコーディングエージェントの進化
AIはコーディングの世界にも大きな変革をもたらしています。コーディングエージェントは4つのレベルで整理できます。
Level 1:プログラムによる補完
IDEの自動補完や構文チェックなど、従来の静的解析ツール。AIではなくルールベースのシステムです。
Level 2:インラインAI補完
GitHub Copilotに代表される、コードを書きながらAIがリアルタイムで提案するスタイル。コンテキストを理解した補完が可能です。
Level 3:自律的なエージェントコーディング
Claude Codeに代表される段階です。エージェントが自律的にコードを書き、テストし、バグを修正するサイクルを回せる。人間はハイレベルな指示を与えるだけでよいです。
Level 4:長期・並列・マルチエージェント
複数のエージェントが並列で作業し、長期にわたるプロジェクトを協調して進める段階。2025年現在、研究・実用化が急速に進んでいる領域です。
Claude CodeはAmazon Bedrockでも利用可能になっており、AWSのインフラ上でAnthropicのモデルを使ったコーディングエージェントを活用できます。
Amazon Bedrock AgentCoreとは
AWSが提供するAmazon Bedrock AgentCoreは、AIエージェントをプロダクションレベルで運用するためのインフラサービス群です。
AgentCoreのコンポーネント
Amazon Bedrock AgentCore
│
├── Runtime(実行環境)
│ エージェントのコードを安全・スケーラブルに実行
│
├── Memory(メモリ管理)
│ 会話履歴や長期記憶の管理
│
├── Identity(認証・認可)
│ エージェントの権限管理とセキュリティ
│
├── Gateway(ゲートウェイ)
│ 外部APIやサービスへの安全な接続
│
├── Code Interpreter(コードインタープリタ)
│ エージェントがコードを動的に実行
│
├── Browser(ブラウザ)
│ Webブラウジング機能
│
└── Observability(可観測性)
ログ・メトリクス・トレースの収集と可視化AgentCore Managed Harness(Preview)
2026年4月22日にプレビューとして発表されたAgentCore Managed Harnessは、エージェントのオーケストレーションコードを書かずに、設定を埋めるだけでエージェントをデプロイできる仕組みです。
「どのモデルを使うか」「どのツールを使うか」「メモリをどう管理するか」といった設定を記述するだけで、実行基盤がすべて自動的に構築されます。
エージェント開発のライフサイクル
エージェントの開発は、4つのステップで進めるのが推奨されています。
Step 1:要件定義
最初に明確にすべきことは:
- 何を自動化・改善したいのか?(ユースケースの特定)
- 成功の基準は何か?(精度、速度、コスト)
- どのくらいのリスクが許容されるか?(人間の確認ステップが必要か)
ポイント:エージェントが間違えたときに何が起きるかを考え、適切なヒューマン・イン・ザ・ループの設計が重要です。
Step 2:PoC(概念実証)
まず小さく試すことが鉄則です。
- 利用可能なツールとモデルを選定する
- シンプルなプロトタイプを素早く構築する
- 想定通りに動くかを評価する
Step 3:プロダクション化
PoCが成功したら、本番環境への投入に向けて以下を整備します:
- 信頼性:エラーハンドリング・リトライ・フォールバック
- スケーラビリティ:負荷に応じたスケーリング
- セキュリティ:認証・認可・入力検証
- コスト管理:トークン使用量の最適化
Step 4:運用と改善
プロダクションに出してからが本番です。
- 観察:ログやトレースでエージェントの動作を監視
- 評価:定期的にパフォーマンスを評価
- 改善:失敗ケースを分析してプロンプトやツールを改善
エージェントの評価方法
エージェントの品質を測るためには、体系的な評価が必要です。
- データセット作成:期待する入力と出力のペアを収集する
- LLM-as-a-Judge:別のLLMを評価者として使う(人手評価のスケーリング)
- 人間による評価:重要な判断は最終的に人間が確認する
LLM-as-a-Judgeは、大量のアウトプットを効率的に評価できる手法として注目されています。ただし、評価モデル自体のバイアスに注意が必要です。
【実践】Strands AgentsでAIエージェントを作ってみよう
理論を学んだら、実際に手を動かしてみましょう。ここでは、AWSのOSSフレームワーク「Strands Agents」を使ったエージェント構築のハンズオンを紹介します。
参考:AWSでAIエージェント構築に入門! StrandsをAgentCoreにデプロイしてみよう(Qiita / @minorun365)
事前準備
- AWSアカウント(新規作成推奨)
- GitHubアカウント
- GitHub Codespaces を開発環境として使用(ローカル環境の構築不要)
まずGitHubで新規プライベートリポジトリを作成し、Codespacesを起動します。次に .env ファイルを作成してAWSの認証情報を記入します。
# .env ファイルの内容 AWS_ACCESS_KEY_ID=(AWSアクセスキー)
AWS_SECRET_ACCESS_KEY=(AWSシークレットアクセスキー)
AWS_DEFAULT_REGION=ap-northeast-1AWSのAmazon BedrockでAnthropicモデルを有効化し、必要な権限のみを付与した IAM ユーザーまたは IAM ロールを用意します。
ステップ1:まず3行でエージェントを動かす
Pythonfrom dotenv import load_dotenv
from strands import Agent
load_dotenv()
agent = Agent("jp.anthropic.claude-haiku-4-5-20251001-v1:0") agent("JAWS-UG主催のAI Builders Dayはどこで開催される?")pip install strands-agents python-dotenv
python 1_agent.py実行すると、エージェントは答えようとしますが、新しいイベント情報はモデルの学習データに含まれていないため「最新情報を確認できません」と返答します。これがツールなしのエージェントの限界です。
ステップ2:Web検索ツールを持たせてみる
Web検索サービス「Tavily」のAPIキーを取得し、.env に追記します。
Pythonimport os
from dotenv import load_dotenv
from strands import Agent, tool
from tavily import TavilyClient
load_dotenv()
@tool
def search(query): """Web検索を実行するツール"""
tavily = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
return tavily.search(query)
agent = Agent(
model="apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
tools=[search] )
agent("JAWS-UG主催のAI Builders Dayはどこで開催される?")pip install tavily-python
python 2_tool.py今度はエージェントが自律的に検索ツールを複数回呼び出し、イベントの開催場所を正確に答えてくれます。ReActループが実際に動いているのが確認できます。
AWSコミュニティイベントの「JAWS-UG主催のAI Builders Day」の開催場所について調べてみます。検索機能を使って情報を取得します。
Tool #1: search
検索結果からは、JAWS-UG主催のAI Builders Dayの正確な開催場所が明確に示されていません。検索結果に「AI Builders Day」についての言及はありますが、具体的な会場情報がありません。より具体的に検索してみましょう。
Tool #2: search
まだ明確な情報が見つかりません。より直接的に「AI Builders Day」のイベントページを探してみましょう。
Tool #3: search
より具体的な情報を探すため、イベントページの詳細を確認しましょう:
Tool #4: search
最初の検索結果に会場情報がありそうです。より詳細な情報を確認するためにイベントページの内容を確認します:
Tool #5: search
検索結果から情報が確認できました。JAWS-UG主催のAI Builders Dayの開催場所について以下の通りお伝えします:
JAWS-UG主催のAI Builders Dayは、「池袋サンシャインシティ ワールドインポートマートビル 展示ホールA」で開催されます。
住所:〒170-8630 東京都豊島区東池袋3-1
このイベントは、AWSで生成AIアプリを作る日本の「ビルダー」たちを盛り上げるための国内最大規模の開発者向けイベントとして開催されます。connpassのイベントページでも確認できる情報です。
ステップ3:MCPサーバーのツールを借りる
自分でツールを実装しなくても、公開されているMCPサーバーのツールをそのまま使えます。ここでは「AWS Knowledge MCPサーバー」を使ってAWSドキュメントを検索させてみます。
Pythonfrom dotenv import load_dotenv
from strands import Agent
from strands.tools.mcp import MCPClient
from mcp.client.streamable_http import streamablehttp_client
load_dotenv() # AWSが公開しているMCPサーバーに接続
mcp = MCPClient(
lambda: streamablehttp_client("https://knowledge-mcp.global.api.aws")
)
with mcp:
agent = Agent(
model="apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
tools=mcp.list_tools_sync()
)
agent("Bedrock AgentCoreのランタイムってどんな機能?一言で説明して。")エージェントはAWSドキュメントを検索・参照した上で回答してくれます。
bash
bash
pip install strands-agents-tools
python 3_mcp.pyAWS Bedrock AgentCoreのランタイムについて調べたいですね。AWS Bedrock Agentについての情報を検索してみます。
Tool #1: aws___search_documentation
AWS Bedrock AgentCoreランタイムについての情報が見つかりましたので、詳細を確認するために主要なページを読んでみます。
Tool #2: aws___read_documentation
AWS Bedrock AgentCore Runtimeを一言で説明すると:
AWS Bedrock AgentCore Runtimeは、任意のフレームワークやモデルを使用したAIエージェントを安全かつスケーラブルに実行するための、セキュアでサーバーレスな目的特化型の実行環境です。
主な特徴は:
- フレームワークに依存しない設計(LangGraph、Strands、CrewAIなど対応)
- 最長8時間までの長時間実行サポート
- セッション分離による安全性の確保
- 100MBの大型ペイロード処理能力
- 使用量ベースの料金体系
- 組み込み認証機能
- エージェント特化の可観測性
ステップ4:マルチエージェントに挑戦
「Agent-as-Tools」パターンを使って、複数のエージェントを協調させてみます。監督者エージェントが、計算専門エージェントと俳句専門エージェントをツールとして呼び出します。
Python# 必要なライブラリをインポート
from dotenv import load_dotenv
from strands import Agent, tool
from strands_tools import calculator
# .envファイルから環境変数を読み込む
load_dotenv()
# サブエージェント1を定義
@tool
def math_agent(query: str):
agent = Agent(
model="apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
system_prompt="ツールを使って計算を行ってください",
tools=[calculator]
)
return str(agent(query))
# サブエージェント2を定義
@tool
def haiku_agent(query: str):
agent = Agent(
model="jp.anthropic.claude-haiku-4-5-20251001-v1:0",
system_prompt="与えられたお題で五・七・五の俳句を詠んで"
)
return str(agent(query))
# 監督者エージェントの作成と実行
orchestrator = Agent(
model="jp.anthropic.claude-sonnet-4-5-20250929-v1:0",
system_prompt="与えられた問題を計算して、答えを俳句として詠んで",
tools=[math_agent, haiku_agent]
)
orchestrator("十円持っている太郎くんが二十円もらいました。今いくら?")
以下のコマンドを実行します。
pip install strands-agents-tools
python 4_multi_agent.py実行結果:
この問題を数学で解いた後、結果を俳句にします。
まずは計算してみましょう:
Tool #1: math_agent
太郎くんの所持金を計算しましょう。
太郎くんは最初に10円持っていて、そこに20円もらったので、合計金額を計算します。
Tool #1: calculator
太郎くんは今30円持っています。では、この答え(30円)を俳句にしてみましょう:
Tool #2: haiku_agent
## 太郎くんの三十円
三十円
夢広がる
駄菓子屋で
問題の答えは30円です。その結果を俳句にしました:
三十円
夢広がる
駄菓子屋で
監督者が役割分担を判断し、サブエージェントを呼び出して協働する様子がわかります。
【実践】AgentCoreにデプロイしてみよう
ローカルで動いたエージェントを本番環境で動作させます。AgentCoreを使えば、インフラの悩みなしにエージェントをデプロイできます。
AgentCore SDK でエージェントをAPIサーバー化
Strandsで実装したエージェントを、AgentCore SDKを用いてAPIとして呼び出せる形にします。
Python# 必要なライブラリをインポート
from strands import Agent
from strands.tools.mcp.mcp_client import MCPClient
from mcp.client.streamable_http import streamablehttp_client
from bedrock_agentcore.runtime import BedrockAgentCoreApp
# AgentCoreランタイム用のAPIサーバーを作成
app = BedrockAgentCoreApp()
# エージェント呼び出し関数を、APIサーバーのエントリーポイントに設定
@app.entrypoint
async def invoke_agent(payload, context):
# フロントエンドで入力されたプロンプトとAPIキーを取得
prompt = payload.get("prompt")
tavily_api_key = payload.get("tavily_api_key")
### この中が通常のStrandsのコード ----------------------------------
# Tavily MCPサーバーを設定
mcp = MCPClient(lambda: streamablehttp_client(
f"https://mcp.tavily.com/mcp/?tavilyApiKey={tavily_api_key}"
))
# MCPクライアントを起動したまま、エージェントを呼び出し
with mcp:
agent = Agent(
model="apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
tools=mcp.list_tools_sync()
)
# エージェントの応答をストリーミングで取得
stream = agent.stream_async(prompt)
async for event in stream:
yield event
### ------------------------------------------------------------
# APIサーバーを起動
app.run()
スターターツールキットでデプロイ
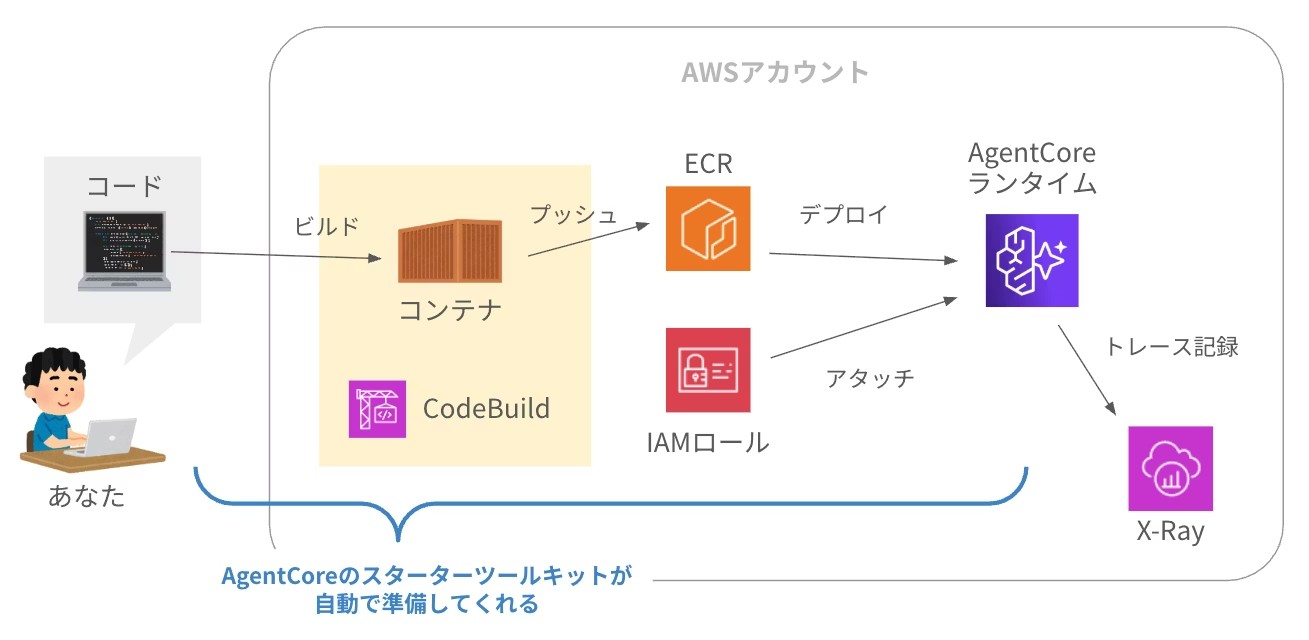
AgentCore専用のCLIツール「スターターツールキット」を使えば、コマンド数回でデプロイが完了します。
strands-agent
bedrock-agentcore# スターターツールキットをインストール
pip install bedrock-agentcore-starter-toolkit
# デプロイ設定(ウィザード形式、全部Enterで OK)
agentcore configure --entrypoint tavily_agent.py
# デプロイ実行(約1分でデプロイ完了)
agentcore launchウィザードでは以下が自動設定されます。
- ECRリポジトリの自動作成
- IAM実行ロールの自動作成
- CodeBuildによるコンテナビルド(Docker不要)
- 短期メモリ(セッション内会話履歴)の自動有効化
デプロイ完了後に表示される「Agent ARN」をメモしておきます。
Streamlitでフロントエンドを作成して動作確認
PythonのUIライブラリ「Streamlit」でチャット画面を作り、デプロイしたエージェントに接続します。
Python# 必要なライブラリをインポート
import os, boto3, json
import streamlit as st
from dotenv import load_dotenv
# .envファイルから環境変数をロード
load_dotenv(override=True)
# サイドバーで設定を入力
with st.sidebar:
agent_runtime_arn = st.text_input("AgentCoreランタイムのARN")
tavily_api_key = st.text_input("Tavily APIキー", type="password")
# タイトルを描画
st.title("なんでも検索エージェント")
st.write("Strands AgentsがMCPサーバーを使って情報収集します!")
# チャットボックスを描画
if prompt := st.chat_input("メッセージを入力してね"):
# ユーザーのプロンプトを表示
with st.chat_message("user"):
st.markdown(prompt)
# エージェントの回答を表示
with st.chat_message("assistant"):
# AgentCoreランタイムを呼び出し
agentcore = boto3.client('bedrock-agentcore')
payload = json.dumps({
"prompt": prompt,
"tavily_api_key": tavily_api_key
})
response = agentcore.invoke_agent_runtime(
agentRuntimeArn=agent_runtime_arn,
payload=payload.encode()
)
### ここから下はストリーミングレスポンスの処理 ------------------------------------------
container = st.container()
text_holder = container.empty()
buffer = ""
# レスポンスを1行ずつチェック
for line in response["response"].iter_lines():
if line and line.decode("utf-8").startswith("data: "):
data = line.decode("utf-8")[6:]
# 文字列コンテンツの場合は無視
if data.startswith('"') or data.startswith("'"):
continue
# 読み込んだ行をJSONに変換
event = json.loads(data)
# ツール利用を検出
if "event" in event and "contentBlockStart" in event["event"]:
if "toolUse" in event["event"]["contentBlockStart"].get("start", {}):
# 現在のテキストを確定
if buffer:
text_holder.markdown(buffer)
buffer = ""
# ツールステータスを表示
container.info("🔍 Tavily検索ツールを利用しています")
text_holder = container.empty()
# テキストコンテンツを検出
if "data" in event and isinstance(event["data"], str):
buffer += event["data"]
text_holder.markdown(buffer)
elif "event" in event and "contentBlockDelta" in event["event"]:
buffer += event["event"]["contentBlockDelta"]["delta"].get("text", "")
text_holder.markdown(buffer)
# 最後に残ったテキストを表示
text_holder.markdown(buffer)
### ------------------------------------------------------------------------------
pip install streamlit
streamlit run frontend.pyサイドバーにARNとTavily APIキーを入力すれば、クラウド上のエージェントとチャットできます。
運用監視:AgentCoreオブザーバビリティ
デプロイしたエージェントの動作はCloudWatchと連携したトレース機能で可視化できます。
AWSマネジメントコンソール → Bedrock AgentCore → エージェントランタイム → オブザーバビリティ から確認できます。各リクエストのトレースIDをクリックすると、エージェントがどのツールを何回呼び出したか、各ステップの所要時間などを細かく確認できます。LLMOpsツール(Langfuseなど)の簡易版が自動で使えるイメージです。
まとめ
本記事では、AWSのAI Agent Workshopの内容をもとに、AIエージェントの全体像を解説しました。
重要なポイントの整理:
- AIエージェントは Plan → Action → Feedback のループで自律的に動作します。
- ReAct・Reasoning・Tool Use・MCP がエージェントを支える主要技術です。
- MCPはAIのUSB Type-C — ツール接続の標準規格として急速に普及中です。
- Strands Agents なら数行のコードでエージェントが動く、GitHub Codespacesで簡単に試せます。
@toolデコレータ一つで関数がエージェントのツールになります。- MCPサーバーを使えば他者が公開したツールをそのまま借りられます。
- マルチエージェント(Agent-as-Tools) パターンで役割分担した協調動作が実現できます。
- Amazon Bedrock AgentCore × スターターツールキットで、インフラ知識なしでデプロイ完了できます。
- 開発は 要件定義 → PoC → 本番化 → 運用改善 のサイクルで進める
2025年はAIエージェント元年と言われますが、技術の進歩は2026年以降もさらに加速することが予想されます。今こそエージェント開発の基礎を押さえ、実際に手を動かして試してみるのが最善の学習方法です。
まずはGitHub Codespacesを起動して、pip install strands-agents から始めてみてください。最初の3行エージェントが動いた瞬間の感動を、ぜひ体感してみてください🚀









![Microsoft Power BI [実践] 入門 ―― BI初心者でもすぐできる! リアルタイム分析・可視化の手引きとリファレンス](/assets/img/banner-power-bi.c9bd875.png)
![Microsoft Power Apps ローコード開発[実践]入門――ノンプログラマーにやさしいアプリ開発の手引きとリファレンス](/assets/img/banner-powerplatform-2.213ebee.png)
![Microsoft PowerPlatformローコード開発[活用]入門 ――現場で使える業務アプリのレシピ集](/assets/img/banner-powerplatform-1.a01c0c2.png)
